【python爬虫】8.温故而知新
文章目录
- 前言
- 回顾前路
- 代码实现
- 体验代码
- 功能拆解
- 获取数据
- 解析提取数据
- 存储数据
- 程序实现与总结
前言
Hello又见面了!上一关我们学习了爬虫数据的存储,并成功将QQ音乐周杰伦歌曲信息的数据存储进了csv文件和excel文件。
学到这里,说明你已经成功入门了Python爬虫!
今天就让我用一个实操项目带你复习之前1-7关所学的知识。这个项目爬取的主题是:美国总统特朗普……
美国总统特朗普之前频上热搜,出于好奇,我对他的相关时事在今日头条网站上进行了爬取,发现他果然是语出惊人。
相信你对这个项目一定充满了期待,但在此之前,按照国际惯例,我们先来回顾一下之前的知识。
回顾前路
在前面,我们所有学习的知识都可以用【项目实现】和【知识地图】两张图来说清。
【项目实现】: 任何完成项目的过程,都是由以下三步构成的。
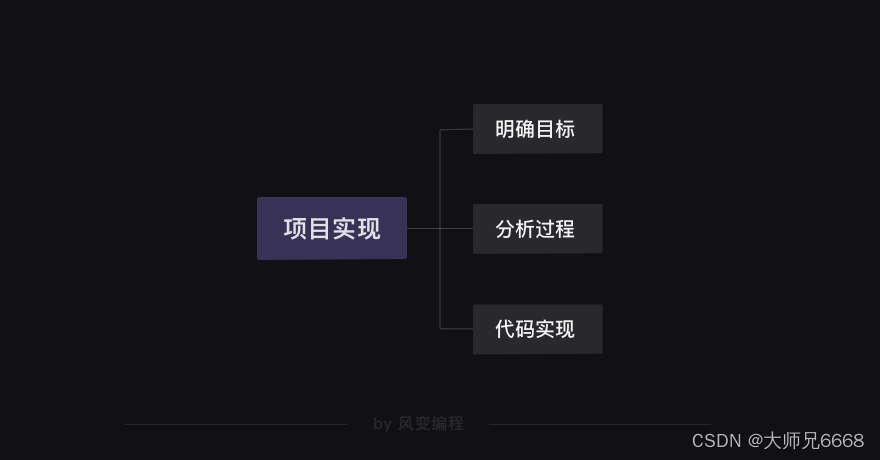
先需要明确自己的目标是什么,然后分析一下如何实现这个目标,最后就可以去写代码了。
当然,这不是一个线性的过程,而可能出现“代码实现”碰壁后然后折返“分析过程”,再“代码实现”的情形。
接下来是【知识地图】:前面7关所讲的爬虫原理,在本质上,是一个我们所操作的对象在不断转换的过程。

总体上来说,从Response对象开始,我们就分成了两条路径,一条路径是数据放在HTML里,所以我们用BeautifulSoup库去解析数据和提取数据;另一条,数据作为Json存储起来,所以我们用response.json()方法去解析,然后提取、存储数据。
你需要根据具体的情况,来确定自己应该选择哪一条路径。
也可以参考图片上的注释,帮助自己去回忆不同对象的方法和属性。不过,老师还是希望你能把这个图记在心里。
好啦,1-7关的内容就梳理完成啦~
接下来到我们今天的任务了,在头条中爬取一下关于特朗普的相关信息。
代码实现
体验代码
了解时事最快的渠道莫过于新闻了,而将各个新闻网数据自动收集起来的今日头条也就这么顺理成章成为我们的今日目标了。
在这里我决定以头条上搜索特朗普:的结果作为我们爬虫爬取的目标。
代码已经写好了,我们先来体验一下效果吧。
阅读下面的代码,然后点击运行。提示:由于网址反爬策略升级的问题,如果本地运行代码报错,请及时留言求助。
import requests
import csv# 新建csv文件并打开文件
file = open('articles.csv', 'w', newline='', encoding='utf-8')
writer = csv.writer(file)# 写入表头
writer.writerow(['标题', '链接'])# 设置爬取链接
url = 'https://www.toutiao.com/api/search/content/'# 设置 offset 的起始值为 0
offset = 0# 循环三页
while offset < 60:# 封装参数params = {'aid': '24', 'app_name': 'web_search', 'offset': offset, 'keyword': '特朗普:', 'count': '20'}# 发送请求,并把响应内容赋值给变量 resres = requests.get(url, params=params)# 使用 json 方法将响应结果读成字典articles = res.json()# 取出 data 对应的值data = articles['data']# 遍历 data 内容for i in data:# 判断这行内容是不是文章if i.get('article_url'):# 取出这行内容,放到列表里row = [i['title'], i["article_url"]]# 打印内容print(row)# 写入这行内容writer.writerow(row)# 换页offset = offset+20# 关闭文件
file.close()可以看到最近特朗普相关新闻的标题与链接都被爬取下来了。
接下来就跟着我一步步来实现这个代码吧。
功能拆解
写代码时我们首先要明确目标,毕竟任何代码都是为了解决问题而去写的。
这次我们的任务是专门爬取找特朗普热点新闻的链接和标题。爬取多少呢,先定一个小目标,爬它60条左右吧。
注:爬取几万条数据当然是可以的,不过毕竟参加课程的同学有很多,每个人都去爬个一千条数据都有着百万爬取量了,如此高频的访问会给对方的服务器造成相当大的压力。为了不竭泽而渔,我们需要控制好在课堂里的爬取数量。
有了目标,接下来我们就需要分析如何去实现它了。
爬虫的本质是通过代码来模拟真人访问浏览器的过程,所以想一想,如果不借助代码的话,我们一般会如何去查看60条今日头条上特朗普相关新闻呢?
1.打开浏览器。
2.打开今日头条网页。
3.在今日头条中搜索"特朗普:",查看搜索结果。
4.点击网页下方的翻页,直到加载出60条数据。
5.打开60个网页,对它们的网址和标题不断进行复制粘贴保存到本地。
我们用爬虫来模拟爬取时也可以根据这些步骤来。
1.在今日头条中搜索"特朗普:",爬取当前界面的数据。
2.解析当前界面数据,分析如何提取出需要的新闻标题和链接。
3.点击加载更多,爬取其中60条数据。
4.将爬取到的数据保存起来。
那么我们先开始获取数据吧。
获取数据
特朗普发言相关新闻的URL在这里:https://www.toutiao.com/search/?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%EF%BC%9A

这是我做这个项目时,网站显示的内容。
我们直接点击右键——检查——element,来查找一下数据存放标签的规律吧。
可以发现界面上所有的新闻标题都是class属性为title-box标签里的文本内容。
当然还有许多其他的提取方法,不过我们可以先尝试爬取一下。
# 导入模块
import requests
from bs4 import BeautifulSoup# 发起请求,将响应的结果赋值给变量res。
url='https://www.toutiao.com/search/?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%EF%BC%9A'
res=requests.get(url)
# 用bs进行解析
bstitle=BeautifulSoup(res.text,'html.parser')
# 提取我们想要的标签和里面的内容
title=bstitle.find_all(class_='title-box')
# 打印title
print(title)
运行的结果是一个空列表,这是为什么呢?
一次性写完爬虫代码固然让人舒畅,不过最终运行代码结果和我们预期目标不符时就很尴尬了。
所以在写代码时妙用print语句就很有必要了,这可以很好的帮助我们监测程序运行的过程。
在这里我们可以分别print一下网页源代码和网页访问状态码来查看一下我们爬取的内容与状态。
# 引入requests和bs
import requests
from bs4 import BeautifulSoup# 发起请求,将响应的结果赋值给变量res。
url='https://www.toutiao.com/search/?keyword=%E7%89%B9%E6%9C%97%E6%99%AE%EF%BC%9A'
res=requests.get(url)
# 用bs进行解析
bstitle=BeautifulSoup(res.text,'html.parser')
# 打印网页源代码
print(res.text)
# 检查状态码
print(res.status_code)
可以发现网页返回状态码是200,说明访问网页成功了,不过爬取出来的内容似乎和我们在网页上看到的不太一样。
出现这种情况,往往说明网页本身是动态网页,需要的数据不在初始的HTML中。
之后你们在实际爬取网站的过程中也可以基于这点来判断:当你直接爬取界面上看到的url,打印出网页访问状态码和网页源代码,当爬取的状态码是200,网页源码内容却与直接从网页上看到的不符时,那么就说明网页是动态网页。
当然,还有一个更加方便的方法,我们可以直接在谷歌浏览器里看出网页是否是动态的。


如果preview和网页上看到的内容一致,那么就是静态网页,反之,则是动态网页。
静态网页我们直接爬取当前浏览器上显示的网页就可以了,而对于动态网页,我们的处理就是四步走:右键检查——network——xhr——刷新界面,然后来查找我们需要的数据存放在哪个xhr文件中。

面对一堆xhr文件该如何快速找到自己想要的那个呢?
对于经验丰富的爬虫工程师来说,看xhr之中的文件名可以更快看出数据在哪。
对于现在的我们来说,可以逐个点开xhr文件,通过查看它们的preview来确定数据所在的xhr位置。
这个方法虽然简单,但却很有效。
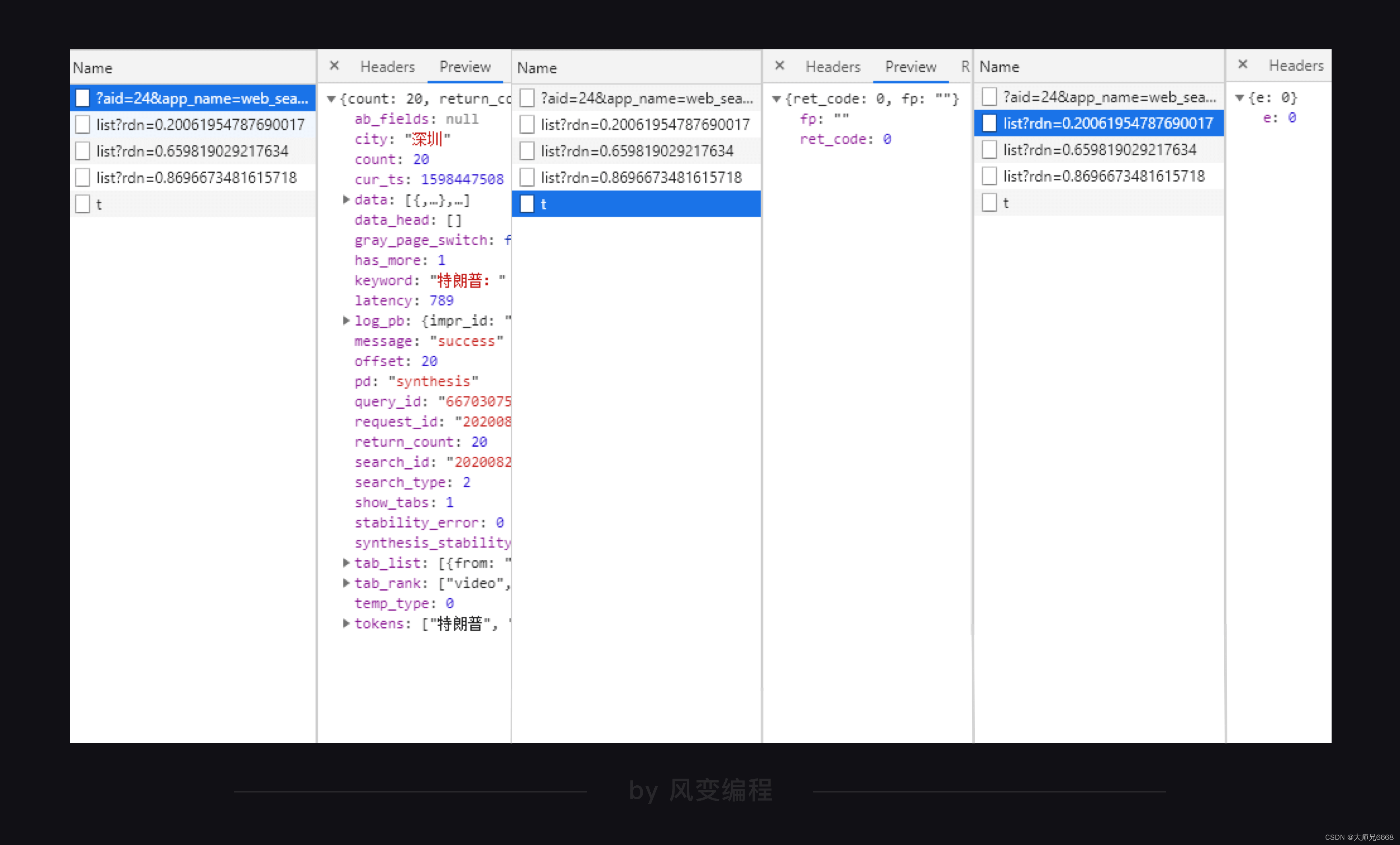
在头条网的三个xhr中,可以很明显的通过preview来看到,我们想要的数据肯定在第一个xhr里,毕竟另外两个xhr里的内容一眼就看穿了。
接下来就是在这个xhr里找到我们想要的新闻标题与链接的位置规律,并将它们提取出来。
解析提取数据
浏览一下这个xhr的preview,通过在preview里搜索在界面上看到的新闻标题来查看这个json文件的结构。

搜索到的每一个标题存放的位置都有很多,为了方便,我们直接通过xhr文件中data大列表里每个字典的title键来提取。
关于网址我们也如法炮制,在preview中搜索url关键词。

好了,找到数据了,我们先将这一页的20个数据爬取下来吧!
还记得如何爬取xhr里对应文件的内容吗?
爬取的网址在Headers中General标题下的Request URL里,其中的url在?问好之前的就是我们爬取的网址。
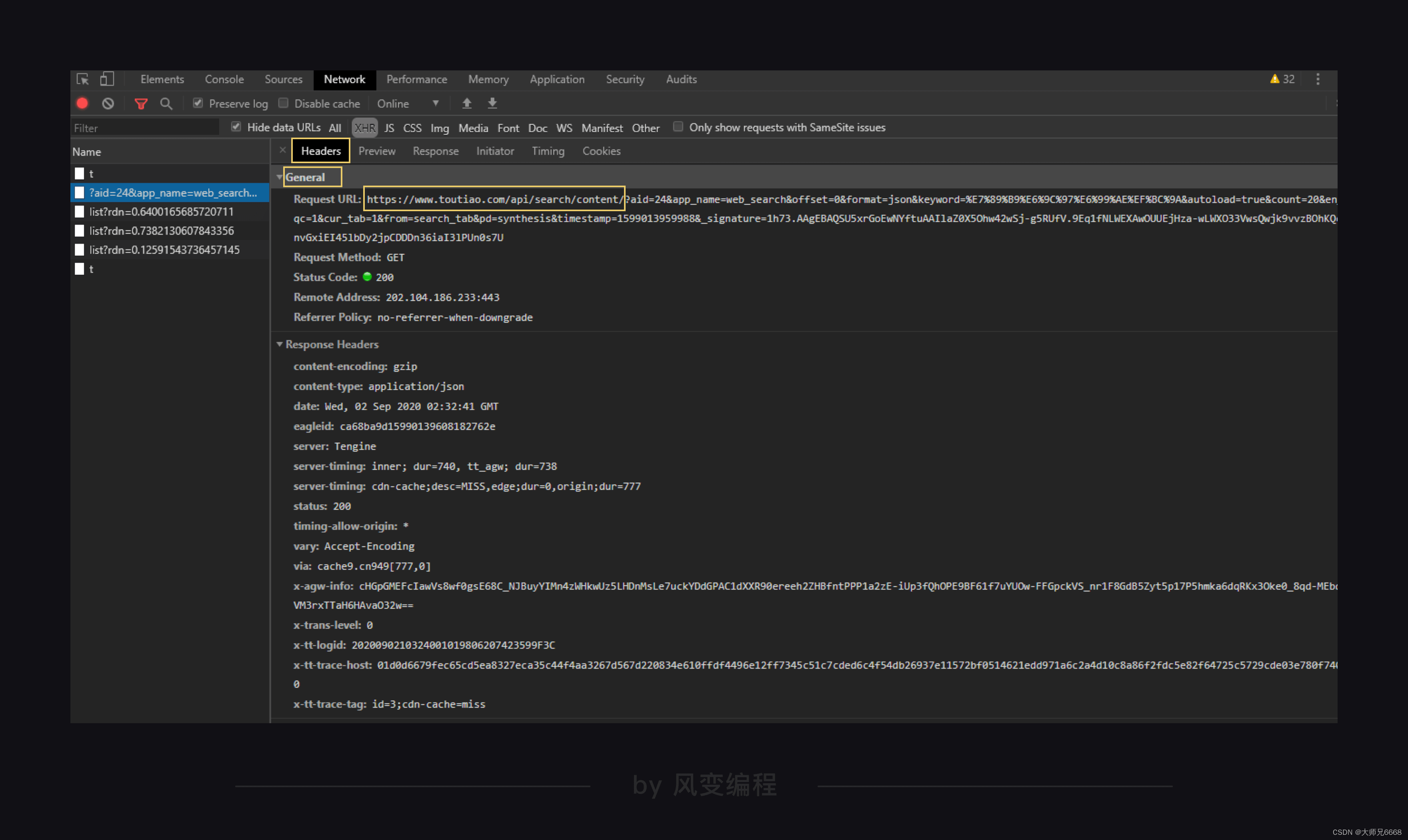
?问号之后的是params,params是一种访问网页所带的参数,这种参数的结构,会和字典很像,有键有值,键值用=连接;每组键值之间,使用&来连接。
关于params可以翻到General最下面看到,可以直接复制到代码中。
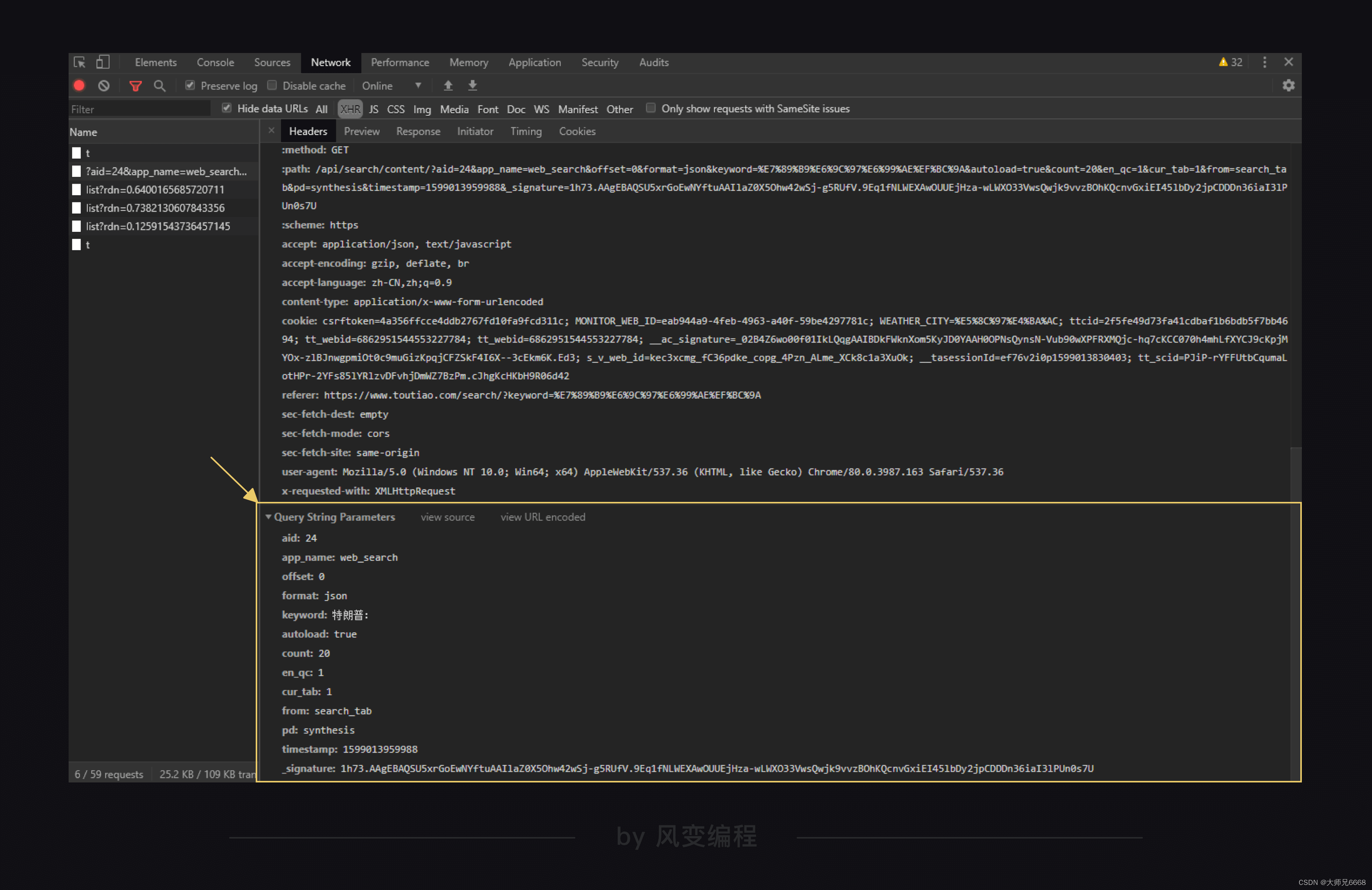
记得将直接复制的params转化成字典,字典里每个键值要用逗号隔开。
不断手动加逗号引号的过程似乎很麻烦。
好吧,到了第8关了,也是时候该教你了。
学完这一关就去让你的助教来教你如何将网页上复制的params直接转化成字典的方法吧。
现在,还是老老实实手动转化一遍,因为接下来我们还要继续分析params里部分参数的作用。
# 导入模块
import requestsurl = "https://www.toutiao.com/api/search/content/"# 封装params变量
params = {'aid':'24',
'app_name':'web_search',
'offset':'0',
'format':'json',
'keyword':'新疆棉花',
'autoload':'true',
'count':'20',
'en_qc':'1',
'cur_tab':'1',
'from':'search_tab',
'pd':'synthesis',
'timestamp':'1616756202046',
'_signature':'_02B4Z6wo00f01.cp-ewAAIDAR9gVJnLDqF.3Df1AAJ2h1CoOpRhZZIWXdVjhrG9mY19M0c1RxNSsZ4ViJcNfwF6bsV8e9npvQeENNWcL9cis4wlCeXgdbeIf0W2R.lsi-gP3omstdNnUbJdKec'}# 发送请求,并把响应内容赋值到变量res里面
res = requests.get(url,params=params)# 定位数据
articles=res.json()
data=articles['data']# 遍历data列表,提取出里面的新闻标题与链接
for i in data:list1=[i['title'],i["article_url"]]print(list1)
运行结果:
Traceback (most recent call last):File "/home/python-class/classroom/apps-2-id-5f56e7f9300055000153a220/93/main.py", line 30, in <module>for i in data:
TypeError: 'NoneType' object is not iterable
阿欧,运行出错了。我们来看看报错,KeyError,根据我们的经验,这一般是因为字典中没有要查找的key才会报这个错误。
于是我们在回去仔细检查我们爬取的json文件。
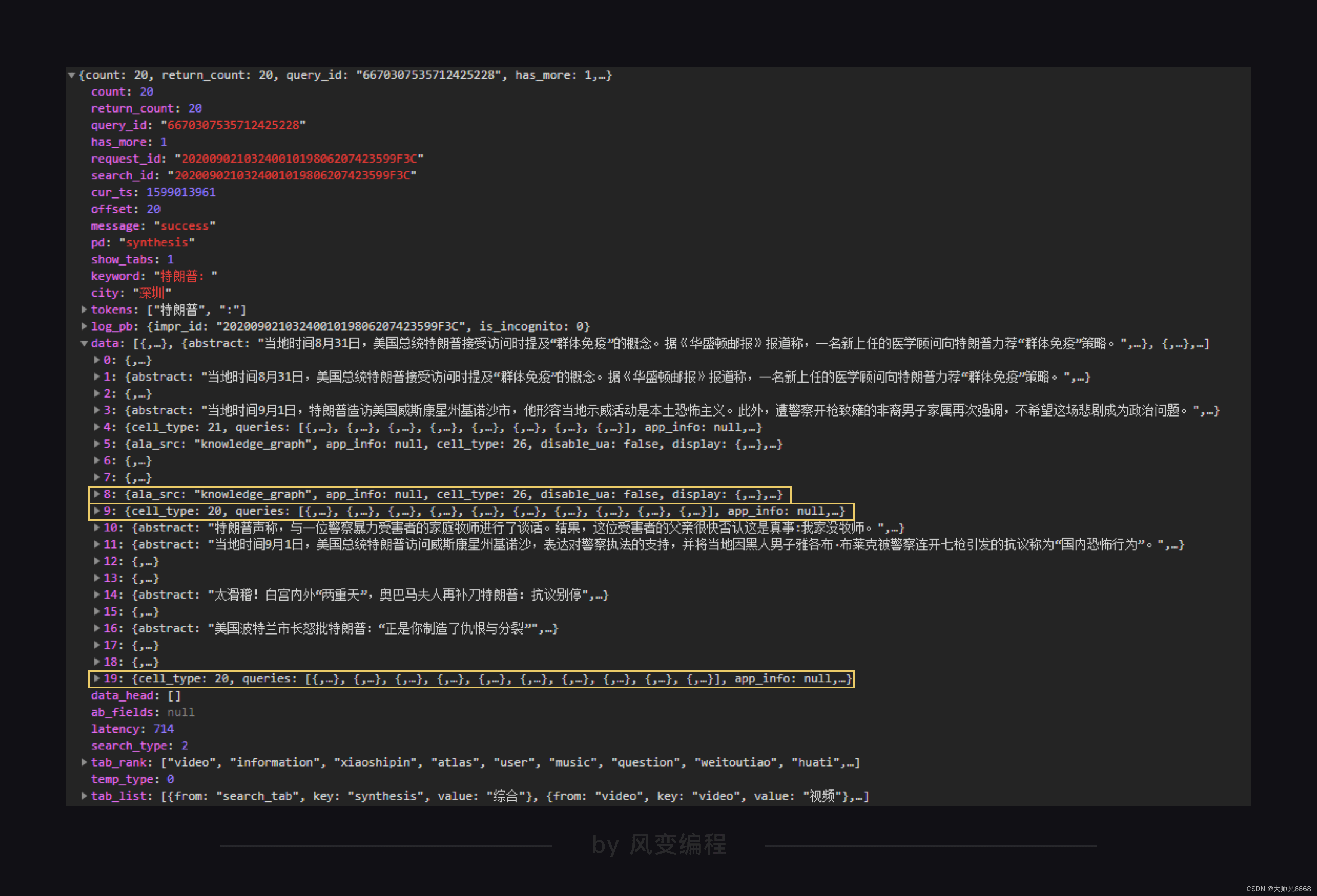
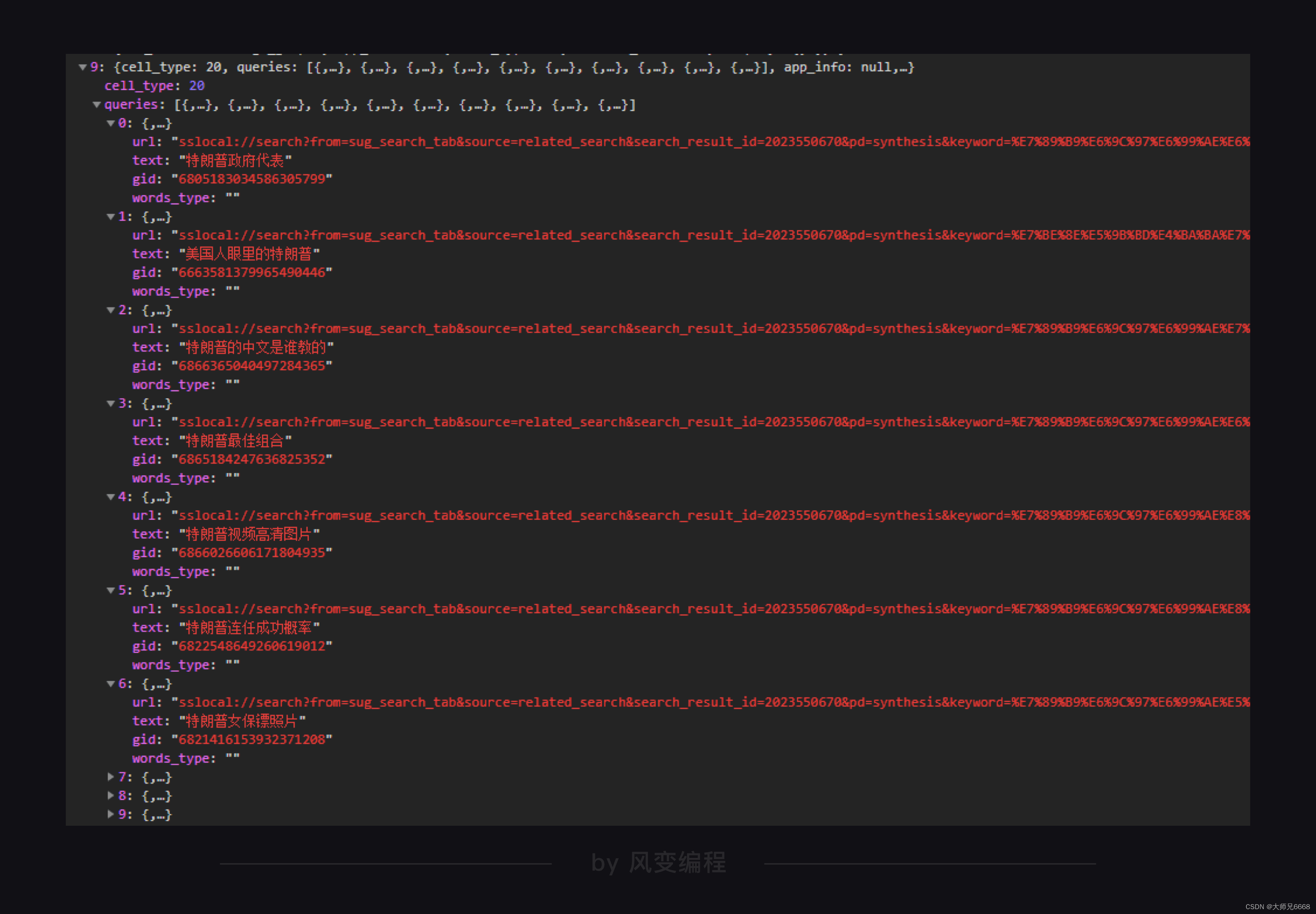
结果发现data里的列表有两种,一种是界面包含的新闻信息,一种是特朗普相关周边新闻。
差不多每10个字典里就有一个是特朗普相关周边新闻。
在这些相关周边新闻的字典里,是没有title这个键的。
第4关爬取豆瓣时我们也遇到过类似的问题,爬取下来的列表中有些不是我们想要的元素。
当时我们是用if判断来解决的,在这我们可以尝试用try语句来解决这个问题。
参考答案:(在except后面你可以print任意内容来提示自己这里遇到了特殊列表。)
# 导入模块
import requests# 定义url,params等变量
url = "https://www.toutiao.com/api/search/content/"
params = {'aid': '24', 'app_name': 'web_search', 'offset': 0, 'keyword': '特朗普:', 'count': '20'}# 发送请求,并把响应内容赋值到变量res里面
res = requests.get(url,params=params)# 定位数据
articles=res.json()
data=articles['data']# 遍历列表,提取出里面的新闻标题与链接
for i in data:try:list1=[i['title'],i["article_url"]]print(list1)except:print("此处无银三百两")
接下来我们就需要爬取更多的内容了。
我们尝试人工加载更多数据,会发现xhr里有新的文件跳出来了,查看发现就是新加载出来的20条数据。
仔细对比一下两个xhr的params,发现只有offset参数有些变化,从0变成了20,所以offset这个参数应该是代表一个起始值,代表从哪一篇开始爬取。
如何验证我们的想法呢?当然是上代码了,将offset参数改成0,10,20分别运行一个查看一下最终的结果。
请你运行下面的代码,看到终端提示"通过input来改变offset参数吧"后,输入你想要设置的offset参数(0,10,20)。
import requests
from bs4 import BeautifulSoup
url='https://www.toutiao.com/api/search/content/'
offset = input("通过input来改变offset参数吧")
headers={'sec-ch-ua':'"GoogleChrome";v="89","Chromium";v="89",";NotABrand";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/89.0.4389.90Safari/537.36',
'x-requested-with':'XMLHttpRequest'}
params={'aid':'24',
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':'新疆棉花',
'autoload':'true',
'count':'20',
'en_qc':'1',
'cur_tab':'1',
'from':'search_tab',
'pd':'synthesis',
'timestamp':'1616756202046',
'_signature':'_02B4Z6wo00f01.cp-ewAAIDAR9gVJnLDqF.3Df1AAJ2h1CoOpRhZZIWXdVjhrG9mY19M0c1RxNSsZ4ViJcNfwF6bsV8e9npvQeENNWcL9cis4wlCeXgdbeIf0W2R.lsi-gP3omstdNnUbJdKec'}
res=requests.get(url,headers=headers,params=params)
target=res.json()['data']
for item in target:try:t_title=item['title']print(t_title)except KeyError:pass
运行结果:
通过input来改变offset参数吧20
不容抹黑!关于新疆棉花的六个事实
新疆棉花年产520万吨,占全国产量87%!中国:我们自己都不够用
新疆以前并没有很多棉花,为什么现在成为了主要产棉区?
新疆棉花成为“众矢之的”!为何我国进口棉花却增67%?真相了
播种面积下降,产量却增加!新疆棉花为啥这么牛?
新疆棉花,不是美国刀下的凉粉
“天下棉仓”新疆,棉花为何如此优质?竟然掌控了全球棉花定价
BCI要让新疆的棉花“凉凉”?新疆长绒棉:中国自己还不够用
新疆棉花为啥产量高、质量好?其实,主要原因有三个
上千年种植史、产量全国第一、世界顶级品质……新疆棉花到底有多强?
“抵制新疆棉花”引发众怒:央视起底幕后推手
被打压的新疆棉花,究竟有多牛?
新疆棉花为何被下毒手?背后隐藏美国一盘大棋,若屈服将一败涂地
新疆的棉花好在哪?6张图带你一探究竟
反å»对新疆棉花的抹黑,中国八点破解之道
我们新疆的棉花,是最纯洁、最温暖的花
新疆棉花稳霸热搜!这些冷知识你了解吗?
科普一下,新疆棉花究竟有多厉害,掌握了全球棉花定价权
新华全媒+丨新疆的棉花是怎样种出来的
为什么是新疆?从“人权”到禁新疆棉花,背后的黑手到底看中什么不出预料,offset果然可以控制从哪篇新闻开始爬。
继续分析params。在一堆英文中,keyword键对应的中文参数特朗普:格外的显眼。
我们也可以合理推断出keyword参数可以控制我们搜索的内容。
为了保险起见,我们还是通过代码来测试一遍吧。跟修改offset一样,我们通过input来控制传入的keyword参数。
请你运行下面的代码,看到终端提示"你想要搜索什么新闻呢?"后,输入你想要搜索的新闻关键字。
# 导入模块
import requests# 定义url,keyword,params等变量
url = "https://www.toutiao.com/api/search/content/"
keyword = input("你想要搜索什么新闻呢?")
params = {'aid': '24', 'app_name': 'web_search', 'offset': 0, 'keyword': keyword, 'count': '20'}# 发送请求,并把响应内容赋值到变量res里面
res = requests.get(url,params=params)# 定位数据
articles=res.json()
data=articles['data']# 遍历列表,提取出里面的新闻标题与链接
for i in data:try:list1=[i['title'],i["article_url"]]print(list1)except:pass
你搜索了什么内容呢🤭?
接下来我们要找到控制数据爬取量的参数了,这个xhr里有20条数据,巧了,count的参数就是20,那么肯定就是它了。
什么,这不严谨,那么老规矩,我们还是通过input来控制count参数来验证一下吧。
请运行下面的代码,看到终端提示"你想要搜索多少条新闻呢?"后,输入一个大于0的数字。
import requests
from bs4 import BeautifulSoup
url='https://www.toutiao.com/api/search/content/'
offset = input("通过input来改变offset参数吧")
keyword=input('请输入关键词搜索新闻:')
headers={'sec-ch-ua':'"GoogleChrome";v="89","Chromium";v="89",";NotABrand";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/89.0.4389.90Safari/537.36',
'x-requested-with':'XMLHttpRequest'}
params={'aid':'24',
'app_name':'web_search',
'offset':offset,
'format':'json',
'keyword':keyword,
'autoload':'true',
'count':'50',
'en_qc':'1',
'cur_tab':'1',
'from':'search_tab',
'pd':'synthesis',
'timestamp':'1616756202046',
'_signature':'_02B4Z6wo00f01.cp-ewAAIDAR9gVJnLDqF.3Df1AAJ2h1CoOpRhZZIWXdVjhrG9mY19M0c1RxNSsZ4ViJcNfwF6bsV8e9npvQeENNWcL9cis4wlCeXgdbeIf0W2R.lsi-gP3omstdNnUbJdKec'}
res=requests.get(url,headers=headers,params=params)
target=res.json()['data']
for item in target:try:t_title=item['title']print(t_title)except KeyError:pass
运行结果:
通过input来改变offset参数吧20
请输入关键词搜索新闻:解体
假如印度发生解体,会怎么分?这里进行设想,可能有两个“斯坦”
苏联为何主动解体?主要原因有4点,其中一个和中国有关
苏联为什么突然解体,解体后的苏联给这个世界带来了什么?
阀门解体_爱酷网
十大最终解体的巨头组合:听说过7个以上,妥妥20年的老球迷
南斯拉夫解体成六国,都过得好吗?
大国的崩溃:1991年苏联解体,为何会选在圣诞节这一天?
苏联为何解体?被西方话语忽悠步入陷阱,苏联崩溃解体是必然结局
苏联解体_出国留学网
解体无弹窗_解体(枭神live)_笔趣阁
张召忠:强大的苏联为什么解体?切尔诺贝利核爆炸是一个转折点
揭秘苏联解体内幕:戈尔巴乔夫激进改革,酿成大祸!
曾经强大无比的苏联到底为什么会解体?一罐鱼子酱揭示了真相
苏联解体视频_美篇
解体的解释|读音|近反义词-百科
美国:国家解体,实际上已经开始了
51年就分崩离析!奥匈帝国作为列强,为什么解体的速度如此之快?
苏联为什么会解体?普京终于吐露真实看法,又一次称赞中国
如何使用循环改变offset参数呢?我这里给给出一种思路:
# 定义offset变量
offset = 0# 判断offset是否小于60,如果小于则每次增加20,当offset大于等于60时结束循环
while offset < 60:offset += 20
现在,你可以尝试通过判断offset是否小于60(大于60则退出循环)来爬取60条数据。
import requests
from bs4 import BeautifulSoup
url='https://www.toutiao.com/api/search/content/'
offset = int(input("通过input来改变offset参数吧"))
keyword=input('请输入关键词搜索新闻:')
headers={'sec-ch-ua':'"GoogleChrome";v="89","Chromium";v="89",";NotABrand";v="99"',
'sec-ch-ua-mobile':'?0',
'sec-fetch-dest':'empty',
'sec-fetch-mode':'cors',
'sec-fetch-site':'same-origin',
'user-agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/89.0.4389.90Safari/537.36',
'x-requested-with':'XMLHttpRequest'}
while offset < 60:offset += 20params={'aid':'24','app_name':'web_search','offset':str(offset),'format':'json','keyword':keyword,'autoload':'true','count':'50','en_qc':'1','cur_tab':'1','from':'search_tab','pd':'synthesis','timestamp':'1616756202046','_signature':'_02B4Z6wo00f01.cp-ewAAIDAR9gVJnLDqF.3Df1AAJ2h1CoOpRhZZIWXdVjhrG9mY19M0c1RxNSsZ4ViJcNfwF6bsV8e9npvQeENNWcL9cis4wlCeXgdbeIf0W2R.lsi-gP3omstdNnUbJdKec'}res=requests.get(url,headers=headers,params=params)target=res.json()['data']for item in target:try:t_title=item['title']print(t_title)except KeyError:pass
真棒,应该不会是偷懒直接将count参数改成60吧。
存储数据
获取、解析、提取数据都完成了。最后,我们需要将得到的数据存储下来。
我们目前学会的储存数据方法有excel和csv两种。
因为上一关的案例中我们是用excel来存储的,所以这一关我们就来试试csv。
还记得csv存储的格式吗?
先用open函数的写入模式新建csv表格,再用csv.writer()函数创建一个writer对象。
将要写的一行数据存入列表,每一列内容用逗号隔开。
调用writer对象的writerow()方法将列表里的内容写入。
比如我需要新建一个csv文件,往这个csv文件第一行写入两列内容,第一行第一列写入标题,第一行第二列写入链接。
那么代码应该是这样的:
# 导入模块
import csv# 新建csv表格
csv_file=open('articles.csv','w',newline='',encoding='utf-8')# 往csv表格写入内容
writer = csv.writer(csv_file)
list2=['标题','链接']
writer.writerow(list2)# 关闭csv文件
csv_file.close()
下面你来根据注释,将上面有关csv存储的代码添加到下面的爬虫代码之中。
程序实现与总结
import requests
# 引用csv
import csv
# 调用open()函数打开csv文件,传入参数:文件名“articles.csv”、写入模式“w”、newline=''。
with open('./articles.csv','w',newline='')as f:
# 用csv.writer()函数创建一个writer对象。writer=csv.writer(f)
# 创建一个列表result_list=[]
# 调用writer对象的writerow()方法,可以在csv文件里写入一行文字 “标题”和“链接”和"摘要"。writer.writerow(['标题','链接','摘要'])
# 设置offset的起始值为0
offset=0
url='https://www.toutiao.com/api/search/content/'
# 循环三页
while offset < 60:headers={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'}# 封装参数params = {'aid': '24', 'app_name': 'web_search', 'offset': offset, 'keyword': '特朗普:', 'count': '20'}# 发送请求,并把响应内容赋值给变量 resres = requests.get(url, params=params)# 使用 json 方法将响应结果读成字典articles = res.json()# 取出 data 对应的值data = articles['data']# 遍历 data 内容for i in data:# 判断这行内容是不是文章if i.get('article_url'):# 取出这行内容,放到列表里row = [i['title'], i["article_url"]]# 打印内容print(row)# 写入这行内容writer.writerow(row)# 换页offset = offset+20# 关闭文件
file.close()
怎么样,是不是将我们开头看到的代码自己一步步写出来了呢?
在这一关里,我们对之前的知识进行了复习,并且通过今日头条这个网站来加深巩固了爬取动态网页的方法。
我们学会了如何去分析动静态网页的方法,如何去通过preview查找xhr里数据存放在哪个文件中。
你之后也许会自己去爬各种动态网页,它们的xhr或许更多,一个个点开查看起来更加费力。
不过这个过程并不枯燥,深入研究动态网页的xhr就像是在挖掘宝藏,一些不会显示在界面上的数据也许不经意间就被你找了出来。
我们深入分析了params的部分关键参数的作用。
其实这些params参数的命名就跟你自己写代码时命名的变量一样,都是写这个网页的程序员命名的,但程序员为了方便自己记忆一般也是基于一些英文命名规则来的。
比如一般控制翻页的参数无非是page,p,pagenum这些。
当然,英文基础不好也不需要多么担心,我们依旧可以通过改变代码里params里的参数来检测它们的作用。
关于爬虫的基础知识我们就已经告一段落了。
下一关不见不散咯!
相关文章:
【python爬虫】8.温故而知新
文章目录 前言回顾前路代码实现体验代码功能拆解获取数据解析提取数据存储数据 程序实现与总结 前言 Hello又见面了!上一关我们学习了爬虫数据的存储,并成功将QQ音乐周杰伦歌曲信息的数据存储进了csv文件和excel文件。 学到这里,说明你已经…...

vue3组合式api 父子组件数据同步v-model语法糖的用法
V-model 大多数情况是用在 表单数据上的, 但它不止这一个作用 父子组件的数据同步, 有一个 语法糖 v-model,这个方法简化了语法, 在elementplus中,都有很多地方使用, 所以我们要理解清楚 父组件 使用 v-mod…...
环境异常总结
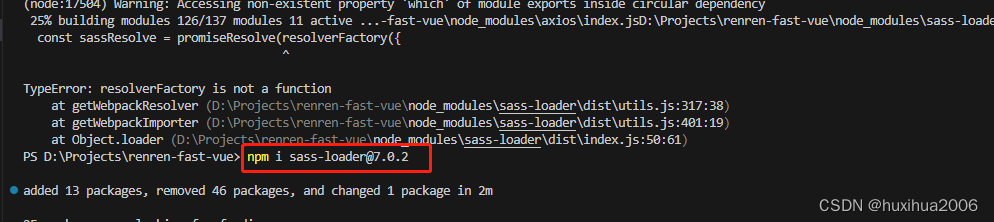
1.vue项目 npm run dev 运行时报错:webpack-dev-server --inline --progress --config build/webpack.dev.conf.js 不是内部或外部命令 原因:webpack-dev-server存在问题 解决方案:指定 webpack-dev-server 低版本号 方法: 删除 …...
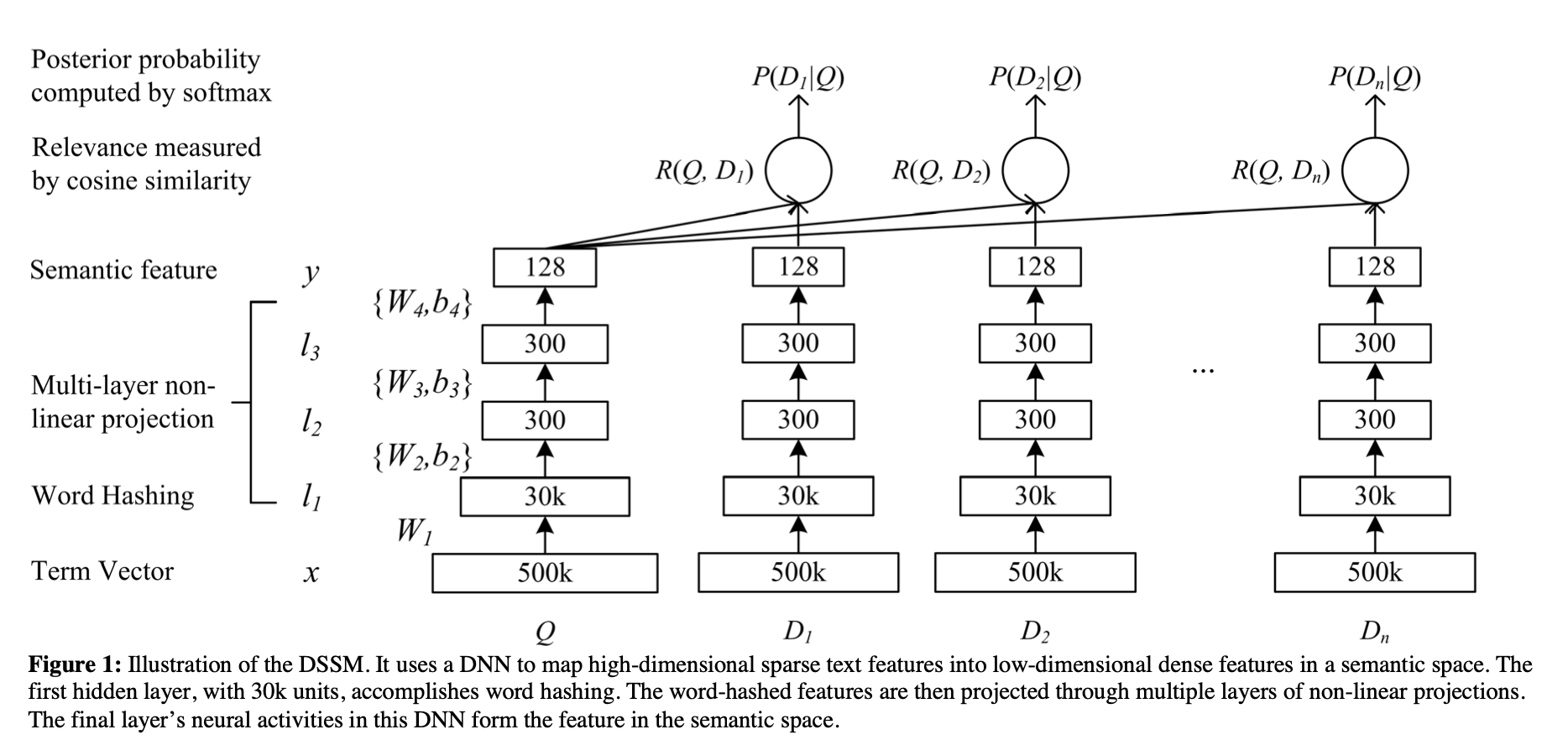
[论文笔记]DSSM
引言 这是DSSM论文的阅读笔记,后续会有一篇文章来复现它并在中文数据集上验证效果。 本文的标题翻译过来就是利用点击数据学习网页搜索中深层结构化语义模型,这篇论文被归类为信息检索,但也可以用来做文本匹配。 这是一篇经典的工作,在DSSM之前,通常使用传统机器学习的…...

Skip Connection——提高深度神经网络性能的利器
可以参考一下这篇知乎所讲 https://zhuanlan.zhihu.com/p/457590578 长跳跃连接用于将信息从编码器传播到解码器,以恢复在下采样期间丢失的信息...
EXCEL中点击单元格,所在行和列都改变颜色
在日常工作中,尤其是办公室工作人群,尝尝需要处理大量的数据,在对数据进行修改时,时长发生看错行的事情,导致数据越改越乱,因此,我常用的一种方法就是选中单元格时,所在行、列标记为…...
)
HAProxy(一)
四层负载均衡与七层负载均衡区别 四层负载均衡和七层负载均衡是两种不同的负载均衡方式,主要区别在于负载均衡的层级及其所支持的协议不同。 四层负载均衡,也称为传输层负载均衡,工作在 OSI 模型的传输层(第四层)&am…...
LeetCode--HOT100题(46)
目录 题目描述:114. 二叉树展开为链表(中等)题目接口解题思路代码 PS: 题目描述:114. 二叉树展开为链表(中等) 给你二叉树的根结点 root ,请你将它展开为一个单链表: 展开后的单链…...

深度探索JavaScript中的原型链机制
🏆作者简介,黑夜开发者,全栈领域新星创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月csdn上海赛道top4。 🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责…...
一种基于WinDump自动抓包实现方法
本发明的技术方案包括以下步骤和组件: 配置抓包参数:设置抓包的IP、端口以及过滤包大小等参数,以控制抓取的数据范围。循环自动抓包:利用WinDump工具实现循环自动抓包功能,类似于记录日志的方式保留抓包数据。当抓包数…...

taro 支付宝/微信小程序/h5 上传 - base64的那些事儿
支付宝小程序临时path转base64 - 基础库2.0以下 function getImageInfo(path) {return new Promise(resolve > {my.getImageInfo({src: path,success: res > {resolve(res)}})}) } export async function getBase64InAlipay({ id, path }) {const { width, height } awa…...

java之SpringBoot基础、前后端项目、MyBatisPlus、MySQL、vue、elementUi
文章目录 前言JC-1.快速上手SpringBootJC-1-1.SpringBoot入门程序制作(一)JC-1-2.SpringBoot入门程序制作(二)JC-1-3.SpringBoot入门程序制作(三)JC-1-4.SpringBoot入门程序制作(四)…...
Vue-Router 一篇搞定 Vue3
前言 在 Web 前端开发中,路由是非常重要的一环,但是路由到底是什么呢? 从路由的用途上讲 路由是指随着浏览器地址栏的变化,展示给用户不同的页面。 从路由的实现原理上讲 路由是URL到函数的映射。它将 URL 和应用程序的不同部分…...

深度解读智能媒体服务的重组和进化
统一“顶设”的智能媒体服务。 邹娟|演讲者 大家好,首先欢迎各位来到LVS的阿里云专场,我是来自阿里云视频云的邹娟。我本次分享的主题为《从规模化到全智能:智能媒体服务的重组与进化》。 本次分享分为以上四部分,一是…...
亲测有效!Win7中如何安装高版本的NodeJS
正常情况下,Win7支持的Node.js最高版本是V13.14,但在开发过程中,有不少Vue项目或其他需要依赖Node环境的项目,对Node版本要求都比较高。对此,我们要么重装操作系统到Win8以上,要么就得想办法在Win7中安装高…...
用法)
Python基础__with open()用法
1、open与with open区别 open()完成后必须调用close()方法关闭文件,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的,由于文件读写时都有可能产生IOError,一旦出错&…...

深入理解 JavaScript 对象、属性、解构和增强语法
ECMA-262将对象定义为一组属性的无序集合。 1 内部属性描述 1.1 数据属性 [[Configurable]]:可配置性,直接定义在对象的属性该特性默认为true,表示可以对属性进行删除、修改等操作。[[Enumerable]]:可枚举性,直接定…...
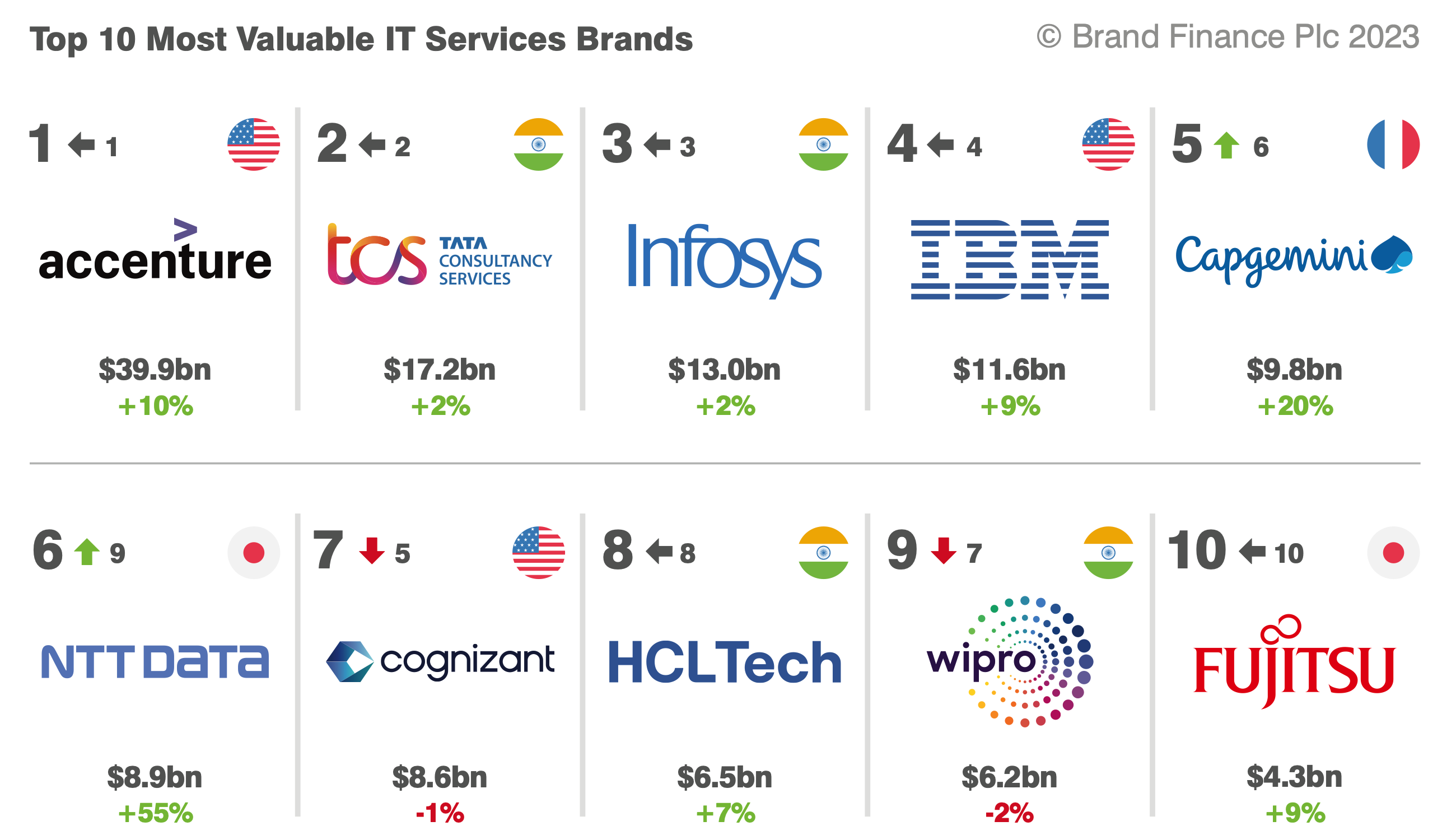
2023年IT服务行业研究报告
第一章 行业概况 1.1 定义 IT服务行业是一个广泛的术语,涵盖了所有提供技术支持和服务的公司。这些服务包括系统集成,云计算服务,软件和硬件支持,网络服务,咨询服务,以及一系列其他类型的技术服务。此外&…...

腾讯云服务器镜像TencentOS Server有用过的吗?
腾讯云服务器镜像TencentOS Server操作系统有用过的吗?踩过坑吗?TencentOS性能和稳定性如何?TencentOS Server与CentOS保持兼容,在稳定性、性能、容器基础设施等核心能力方面做了全面的增强和优化,能为企业提供稳定高可…...

小区村庄集中生活废水处理设备厂家直销价格
小区村庄集中生活废水处理设备厂家直销价格 设备的构造 1、填料 该填料选用特制塑料和树脂组成,结构科学、新颖、填料比表面积达1000m2/m3,比重轻0.97g/cm3,不堵塞、易挂膜。 该填料是由纤细球体,网络外壳和通心多孔柱体组成的球形…...

ncmdump终极指南:5分钟解锁网易云音乐NCM加密文件
ncmdump终极指南:5分钟解锁网易云音乐NCM加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾在网易云音乐下载了心爱的歌曲,却发现只能在特定客户端播放?当你想在车载音响、智能音箱…...

Codex SQL迁移终极指南:数据库架构变更的自动化革命
Codex SQL迁移终极指南:数据库架构变更的自动化革命 在当今快速迭代的软件开发环境中,数据库架构变更是每个开发团队都必须面对的挑战。传统的手动SQL迁移过程不仅耗时耗力,还容易出错。Codex作为一款革命性的聊天驱动开发工具,通…...

NumPy 2.4.6 快速版发布:修复 2.4.5 回归问题,支持 Python 3.11 - 3.14
NumPy 2.4.6 快速版本现已发布,修复了 2.4.5 版本中的回归问题,支持 Python 3.11 - 3.14 版本,本次共合并 4 个拉取请求。版本发布背景 在 NumPy 2.4.5 版本使用过程中发现了回归问题,为了及时解决这些问题,开发团队迅…...

给程序员和数据分析师的气象学入门:搞懂城市边界层,让你的天气API数据不再‘失真’
给程序员和数据分析师的气象学入门:搞懂城市边界层,让你的天气API数据不再‘失真’ 当你在调用天气API时,是否遇到过这样的困惑:明明获取的是同一个城市的温度数据,为什么市中心的气温总比郊区高出几度?为什…...

在macOS上轻松运行Windows应用:Whisky完整使用指南
在macOS上轻松运行Windows应用:Whisky完整使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Apple Silicon Mac上直接运行Windows软件和游戏,又不想…...

Windows字体自由:noMeiryoUI终极指南,轻松自定义系统界面字体
Windows字体自由:noMeiryoUI终极指南,轻松自定义系统界面字体 【免费下载链接】noMeiryoUI No!! MeiryoUI is Windows system font setting tool on Windows 8.1/10/11. 项目地址: https://gitcode.com/gh_mirrors/no/noMeiryoUI 你是否厌倦了Win…...

如何快速掌握3DS硬件检测:面向初学者的完整3DSident使用指南
如何快速掌握3DS硬件检测:面向初学者的完整3DSident使用指南 【免费下载链接】3DSident PSPident clone for 3DS 项目地址: https://gitcode.com/gh_mirrors/3d/3DSident 你是否曾好奇自己的Nintendo 3DS内部藏着什么秘密?想知道它的制造日期、电…...

UML类图实战:从设计到代码的精准映射
1. 为什么需要从UML类图到代码的精准映射? 第一次接触UML类图时,我总觉得它像是一张"纸上谈兵"的设计稿。直到在实际项目中踩过几次坑才明白,类图与代码之间的精准映射能力,是区分普通程序员和架构师的关键技能之一。 …...

函数依赖的核心概念解析[数据库原理]
函数依赖的定义与核心概念 函数依赖(Functional Dependency,简称FD)是关系数据库理论中用于描述属性间数据约束的核心概念。它定义了一个关系模式(Relation Schema)中,一个属性(或属性组&#…...

思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程
思源宋体TTF格式终极指南:免费商用中文字体的完整使用教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目寻找既专业又免费的中文字体而烦恼吗?…...