【C++】快速排序的学习和介绍
前言
本篇文章我们先会学习快速排序这个算法,之后我们会学习sort这个函数
分治算法
在学习快速排序之前,我们先来学习一下分治算法,快速排序就是分治算法的一种,下面是分治算法的介绍,
分治算法,就是”分而治之“
分为分解、治理和合并这三个步骤
后面我们学习快速排序也是从这三个步骤入手
简单来说,分治算法就是将一个大问题分解成许多小的问题,
又因为这些小的问题的解决方案与大问题相同,只是规模更小而已
所以当子问题划分得足够小时,就可以用很简单的方法来解决原本看起来很复杂的大问题。
通过上面的学习,我们可以看出,快速排序就是分治算法中的一种
快速排序算法(可优化版本)
基本步骤
分解
首先将数组中的一个元素作为pivot(轴点 / 基准点,可以理解为分界点)
之后从最左侧的元素和最右侧的元素开始遍历,比轴点大的放到最右侧,比轴点小的就放到最左侧
对于轴点的选择
我们可以选择数组首元素作为轴点,或者最后一个元素,又或者是数组中的任意一个元素
治理
一次排序完成后,分别对轴点左侧和右侧的剩余元素进行排序(使用递归重复上面的步骤)
合并
将最终排序好的各个子串合并到一起,就实现了快速排序这个算法

基本思想就是这样,下面,让我们来逐步实现
分步实现
排序一次
首先以首元素作为基准点(一般都是第一个元素),赋值给pivot变量,数组最左侧元素下标赋值给left变量,最右侧下标赋值给right这个变量
然后,从右向左开始逐个与轴点比较,当其小于轴点时,将这个元素与这个串中left下标指向的元素位置互换,left向右移动一位
然后,从左向右开始逐个与轴点比较,当其大于轴点时,将这个元素与这个串中right指向的那个元素互换,right向左移动一位
重复二三步,直到left与right重合,一次排序完成
对分割后的子串进行排序
排序完一次之后,轴点左侧的元素比轴点小,右侧的元素比轴点大,
之后,分别对左侧的子串和右侧的子串进行排序,
此处需要使用递归,直到传入的参数:left==right时,开始回归,又因为函数返回类型是void,那么也就可以理解为函数调用结束,数组排序完成
例子图解
下面,通过对一个数组进行排序,来更生动的去学习这个算法
以数组6 1 2 7 9 3 4 5 10 8为例
下面只解释第一次排序的过程
选取轴点
首先,选取首元素6,作为轴点,进行第一次排序,如图所示

从右向左开始排序
从8开始向左逐个查找,查找到5的时候,发现5比轴点小,那么就将5这个元素与轴点(也就是left下标指向的元素)互换,left++,向右移动一位(跳过已经排序完的元素),right变为轴点所在的下标
如图:
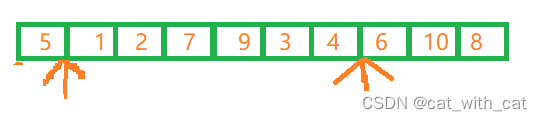
从右向左排序
从left所指向的元素开始与轴点比较,当遇到比轴点大的就与轴点互换,然后right–,向左移动一位(跳过已经排序完的元素),left变为轴点所在的下标

继续排序
重复以上两步:先从右侧开始向左查找,替换、再从左向右开始查找,替换
当left和right重合时,说明本次查找完成
递归查找剩下的子串
通过上面的学习,我们可以知道,对与一个串的排序,其基本操作是一样的,只不过规模大小不同罢了,这就是分治算法中提到的分解与治理
代码实现
基本步骤和具体思路都介绍完了,剩下的就是通过代码去实现它了
函数主体
int main()
{int a[10001];int N;cout << "请输入要排序的元素个数" << endl;cin >> N;cout << "请输入要排序的元素" << endl;for (int i = 0; i < N; i++){cin >> a[i];}cout << endl;//可有可无,此处换行只是为了美观Quicksort(a, 0, N - 1);cout << "排序后的数组结果" << endl;for (int i = 0; i < N; i++){cout << a[i] << " ";//这里输入一个空格也是为了美观,方便阅读}cout << endl;return 0;
}
Quicksort函数就是实现递归排序的函数
Quicksort函数
void Quicksort(int* r, int left, int right)
{int mid = 0;if (left < right){mid = part(r, left, right);Quicksort(r, left, mid - 1);Quicksort(r, mid + 1, right);}
}part函数是实现一次排序的函数
part函数
part函数是实现一次排序的函数,并且part函数返回的是一次排序完成后的新的基准值(就是left和right下标重合的位置)
int part(int* r, int left, int right)
{int i = left;int j = right;int pivot = r[left];//选择首元素作为基准点while (i < j){while (i<j && r[j]>pivot)//从右向左查找小于基准点的元素{j--;}if (i < j){swap(r[i++], r[j]);//交换基准点和left下标的元素,并且left下标向右移动一位}while (i < j && r[i] <= pivot)//从左向右查找大于基准点的元素{i++;}if (i < j){swap(r[i], r[j--]);交换基准点和right下标的元素,并且right下标向左移动一位}return i;//返回的是最终划分完成后人(即left和right重合)的新的基准点,//作为字串的left或right的下标}}swap函数
在part函数中,为了更快捷的将两个元素互换,我们使用到了swap函数,下面,就对swap函数做一个简单的介绍
swap(a, b);
这个函数很厉害,
它不仅可以交换整型、浮点型
它还可以交换结构体(当然,成员个数得一样)
下面给一个交换结构体的例子
#include<iostream>
#include<string>
#include<algorithm>//sort函数包含的头文件
using namespace std;
//定义一个学生类型的结构体
typedef struct student
{string name; //学生姓名int achievement; //学生成绩
} student;//用来显示学生信息的函数
void show(student * stu, int n)
{for (int i = 0; i < n; i++){cout << "姓名:" << stu[i].name << '\t' << "成绩:" << stu[i].achievement << endl;}
}int main()
{student stu1[] = { {"李四",87},{"王二",100} };student stu2[] = { {"22",2},{"33",3} };cout << "交换前:" << endl;show(stu1, 3);show(stu2, 3);swap(stu1, stu2);cout << "交换后:" << endl;show(stu1, 3);show(stu2, 3);return 0;
}并且,使用swap函数,不用担心精度的损失
补充说明
对于排序方式的解释
对于为什么要先从右向左开始查找,同学们可能会有疑惑,那么我们不妨试一试先从左向右查找,看看结果如何
还是以“6 1 2 7 9 3 4 5 10 8”这个数组为例子
第一次排序时:
我们先让left从左边开始,遇到小于等于6的继续走,大于6的停下,于是left停在了7的位置;
再让right从右边走,小于6的时候停下,于是right停在5的位置;
这个时候left < right
于是7和5交换位置变成“6 1 2 5 9 3 4 7 10 8”;
继续上面的操作,9和4交换,变成“6 1 2 5 4 3 9 7 10 8”,继续,left先移动,停在了9的位置,这个时候left == right了,那么这一轮就比较完了,最后需要交换left和pivot位置的数(基准数归位),
这个时候,6与9交换,变成了下面的序列:“9 1 2 5 4 3 6 7 10 8”,
这个序列并不是完成了一轮处理之后,基准数左边的都比基准数小,右边的都比它大。所以这样先从左边开始搜索得不到正确结果的。
因此,我们可以得到下面的结论:当基准数选择最左边的数字时,那么就应该先从右边开始搜索;当基准数选择最右边的数字时,那么就应该先从左边开始搜索。不论是从小到大排序还是从大到小排序!
快速排序的优化
其实,我们不需要每次遇到比轴点大 / 比轴点小的元素就与轴点进行交换,可以直接将这两个元素交换,再移动left与right直到二者相等,这就完成了一次排序
再将轴点更新为left下标所在的位置,进行递归排序
至于具体的代码,我还没想明白,在此只是提出这个思路,之后再去实现
快速排序与冒泡排序
冒泡排序我们都知道,这里就不再重复叙述
快速排序与冒泡排序相比,快速排序的优点是
快速排序的每次交换是跳跃式的,就是距离很大
当轴点左侧的元素大于轴点时,会被直接放到右侧right指针所指向的位置,这样交换时跨越的距离是很大的,
而冒泡排序,每次只能是相邻的两个元素进行比较,这样就比较低效了
结语
关于快速排序这个算法知识就介绍到这里了,希望大家都有所收获,我们下篇文章见~
相关文章:
【C++】快速排序的学习和介绍
前言 本篇文章我们先会学习快速排序这个算法,之后我们会学习sort这个函数 分治算法 在学习快速排序之前,我们先来学习一下分治算法,快速排序就是分治算法的一种,下面是分治算法的介绍, 分治算法,就是”…...
第九章 动态规划part12(代码随想录)
309.最佳买卖股票时机含冷冻期 1. 确定dp数组(dp table)以及下标的含义 dp[i][j],第i天状态为j,所剩的最多现金为dp[i][j]。 2. 确定递推公式 拆分卖出股票状态是因为冷冻期前一天一定是具体卖出股票状态。 状态一 dp[i][0]&…...
ssm珠宝首饰交易平台源码和论文
ssm珠宝首饰交易平台源码和论文101 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 随着科学技术的飞速发展,各行各业都在努力与现代先进技术接轨,通过科技手段提高自身的优势&a…...
交互设计都有哪些准则?
UI交互设计的本质不是完全基于用户的需求,而是交互设计师需要学习根据用户描述的产品形式来了解用户需要什么。 在交互设计过程中,遵循科学交互设计的本质是整个交互设计过程的重要组成部分,这与产品使用过程中给用户带来的体验密切相关。本…...

【MySQL】从哪几个角度分析数据库失败的原因?
总体评估MySQL服务器感谢 💖 总体评估 当发现数据库出现问题时,我们首先应该从全局的角度考虑架构中的所有组件。包括: 服务器(数据库和应用程序) 存储:存储故障可能导致关键信息丢失网络接口:…...

Spring Boot 的核心注解SpringBootApplication
SpringBootApplication 包括的注解 SpringBootConfiguration 组合了 Configuration 注解,实现配置文件的功能。 EnableAutoConfiguration 打开自动配置的功能,也可以关闭某个自动配置的选项, 例如:java 如关闭数据源自动配置功…...
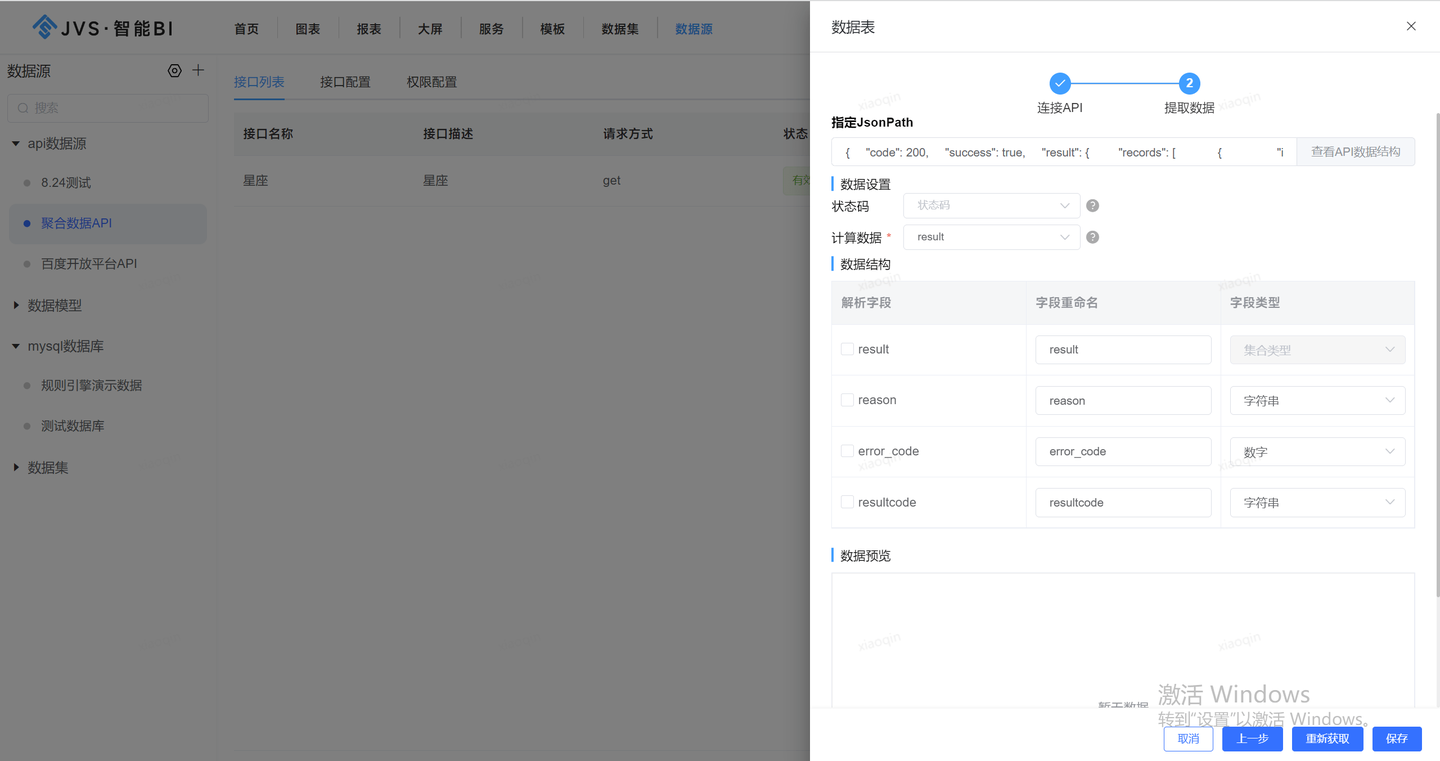
自助式数据分析平台:JVS智能BI功能介绍(一)数据源
一、数据源配置 数据源概述 数据源是JVS-智能BI支持多种数据形态的基础,核心的目标是将不同的数据来源通过统一接入,实现将不同的数据实现统一的数据加工、数据应用。目前JVS-智能BI主要支持3种形态的数据:数据库、API、离线文件。 界面介…...

CSS魔术师Houdini,用浏览器引擎实现高级CSS效果
开门见山,直接上货 🔍 CSS Houdini是什么? “Houdini”一词引用自“Harry Houdini”,他是一位20世纪的著名魔术师,亦被称为史上最伟大的魔术师、逃脱术师及特级表演者。 我们都知道,浏览器在渲染网页显示样…...
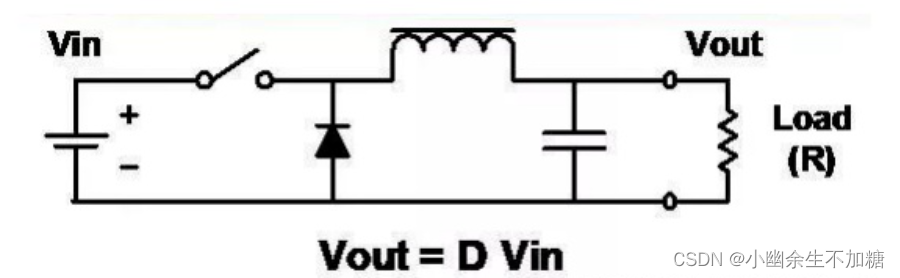
DC/DC开关电源学习笔记(二)开关电源的分类
(二)开关电源的分类 1.DC/DC类开关电源2.AC/DC变换器3.电路结构分类4.功率开关管分类5.电路拓扑分类 根据变换方式,电源产品有下列四大类; (1):第一大类:AC/DC开关电源; …...
conda创建python虚拟环境
1.查看当前存在那些虚拟环境 conda env list conda info -e 2.conda安装虚拟环境 conda create -n my_env_name python3.6 2.1在anaconda下改变python版本 当前3.7 安装3.7 conda create -n py37 python3.7 conda activate py37 conda create -n py37 python3.7conda a…...

Python 操作 MongoDB 数据库介绍
MongoDB 是一款面向文档型的 NoSQL 数据库,是一个基于分布式文件存储的开源的非关系型数据库系统,其内容是以 K/V 形式存储,结构不固定,它的字段值可以包含其他文档、数组和文档数组等。其采用的 BSON(二进制 JSON &am…...

【ES6】Generator 函数
Generator 函数是 ES6 引入的一种新的函数类型,它既可以生成一个序列,又可以在某个条件下停止执行,并在需要时恢复执行。Generator 函数非常适合处理那些需要按需计算的场景,例如处理大数据、生成随机数等。 Generator 函数的基本…...
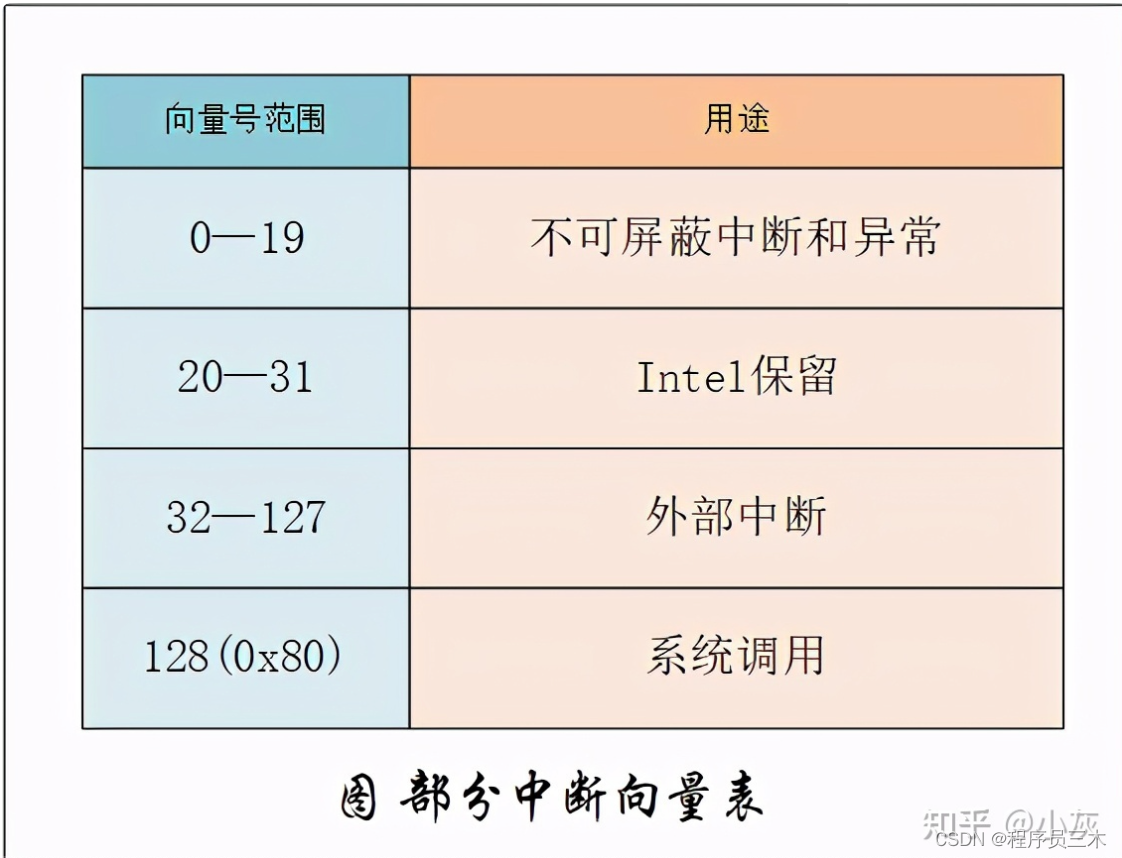
「操作系统」1. 基础
前言:操作系统基础八股文 文章目录 一 、操作系统基础1.1 什么是操作系统?1.2 什么是系统调用1.3 什么是中断 🚀 作者简介:作为某云服务提供商的后端开发人员,我将在这里与大家简要分享一些实用的开发小技巧。在我的职…...

Docker安装Oracl数据库!
安装Docker 查看是否安装docker: yum list installed | grep docker 安装docker: yum -y install docker 启动docker: systemctl start docker 查看docker启劝状态: systemctl status docker 查看docker版本: docker --version 设置docker开机自启动: systemctl en…...


leecode 数据库:1158. 市场分析 I
数据导入: SQL Schema: Create table If Not Exists Users (user_id int, join_date date, favorite_brand varchar(10)); Create table If Not Exists Orders (order_id int, order_date date, item_id int, buyer_id int, seller_id int); Create tab…...
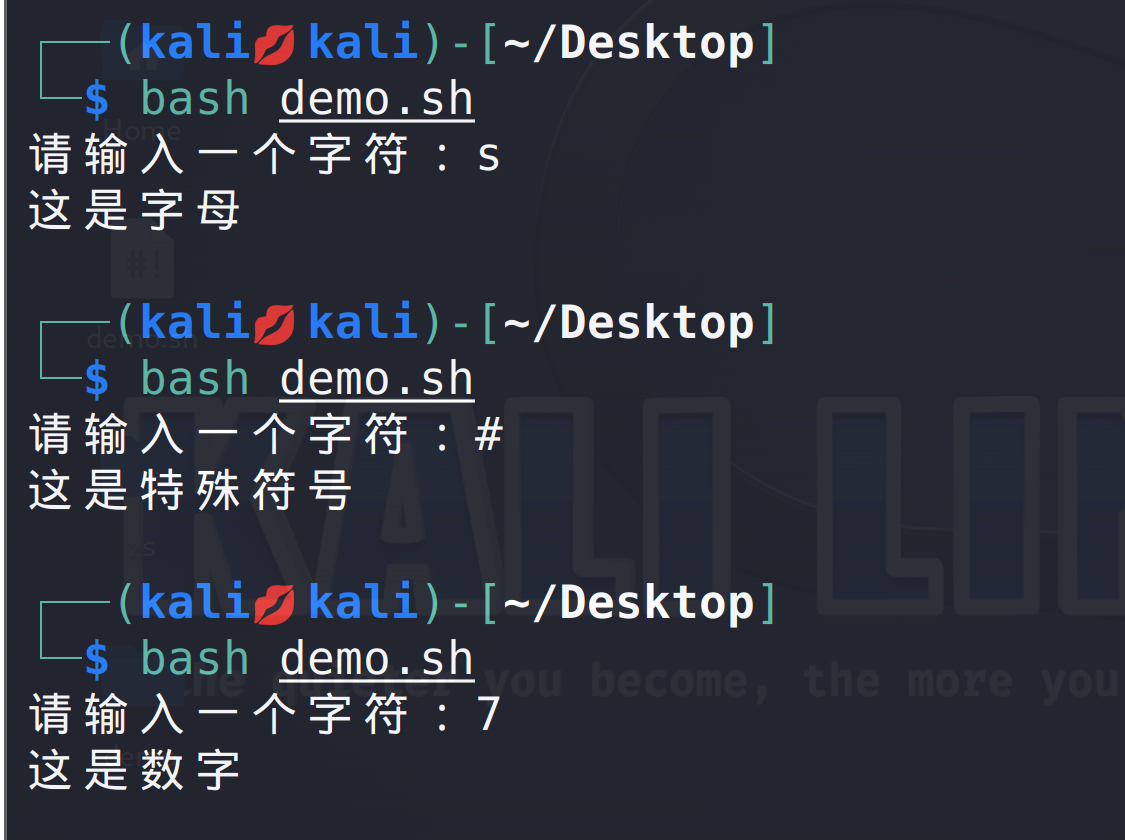
简单shell脚本的编写
文章目录 简单使用shell脚本参数判断整数的比较运算符字符串的比较运算shell脚本流程控制shell脚本循环for循环批量添加用户批量ping IP地址检测同一局域网,多台主机存活情况检测同一局域网,多台主机存活情况多线程检测主机存活情况 while循环case选择语…...

汽车售后接待vr虚拟仿真实操演练作为岗位培训的重要工具和手段
汽车虚拟仿真教学软件是一种基于虚拟现实技术的教学辅助工具。它能够模拟真实的汽车环境和操作场景,让学生能够通过虚拟仿真来学习和实践汽车相关知识和技能。与传统的教学方式相比,汽车虚拟仿真教学软件具有更高的视觉沉浸感和互动性,能够更…...
登录校验-Filter-登录校验过滤器
目录 思路 登录校验Filter-流程 步骤 流程图 登录校验Filter-代码 过滤器类 工具类 测试登录 登录接口功能请求 其他接口功能请求 前后端联调 思路 前端访问登录接口,登陆成功后,服务端会生成一个JWT令牌,并返回给前端࿰…...

Vue3列表竖向滚动(包含使用swiper的翻页效果)
一、使用element-plus表格进行滚动: 可以满足的需求:表格一行一行竖向滚动,类似走马灯。 不能满足的需求:表格分页竖向滚动,有翻页的效果。 代码: <template><el-table:data"tableData"…...

AI从业者的“薪资真相”:不同方向、不同级别AI从业者的薪资水平
在人工智能技术飞速渗透各行业的当下,AI领域已成为软件测试从业者跨界转型的热门方向。相较于测试岗位相对稳定但涨幅平缓的薪资体系,AI行业的薪资结构呈现出极强的分层性与差异性。对于具备技术基础的测试从业者而言,深入了解AI领域的薪资逻…...

给工程师的傅里叶变换:从信号处理到图像压缩,用Python代码理解核心推导
给工程师的傅里叶变换:从信号处理到图像压缩,用Python代码理解核心推导 当你在Spotify上听歌时,算法如何从嘈杂环境中分离人声?手机拍照时,JPEG压缩为何能大幅减小文件体积却保持清晰?这些看似不相关的技术…...

从CLIP到车辆检索:解锁ViT大模型在跨摄像头ReID中的实战潜力
1. 当CLIP遇上车辆检索:ViT大模型的跨界实战 第一次看到CLIP模型在车辆重识别任务上的表现时,我对着屏幕上的mAP 84.5数据反复确认了三遍。这就像给一辆普通家用车换上了F1赛车的引擎,性能提升简单粗暴。传统ReID方法需要精心设计网络结构、调…...
)
别只傻等候补了!用Bypass分流抢票监控12306“捡漏”全攻略(含微信通知设置)
别只傻等候补了!用Bypass分流抢票监控12306"捡漏"全攻略(含微信通知设置) 春节临近,当你在12306官网上看到心仪车次显示"候补"或"无票"时,是否已经放弃希望?其实,…...

Grounding DINO实战评测:对比GLIP、OV-DETR,在COCO和LVIS数据集上到底强在哪?
Grounding DINO技术解析:多模态开放集检测的突破与实践 在计算机视觉与自然语言处理的交叉领域,开放集目标检测正经历着前所未有的技术革新。传统检测模型受限于预定义类别集的桎梏,而新一代多模态大模型通过融合视觉与语言信号,实…...

如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南
如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 你是否…...
)
从‘班级-学生’数据实战出发:手把手教你用R语言的lme4包搞定多层线性模型(MLM/HLM)
从班级-学生数据实战:R语言lme4包多层线性模型全流程解析 当研究者面对具有层级结构的数据时(如学生嵌套于班级、员工嵌套于公司),传统线性回归的独立性假设往往被打破。多层线性模型(Multilevel Linear Models, MLM&a…...

VSCode + Modelsim 搭建Verilog开发环境:除了语法检查,还能这样玩?
VSCode与ModelSim深度集成:打造高效Verilog开发工作流 在数字电路设计领域,Verilog作为硬件描述语言的标准之一,其开发效率直接影响项目进度。传统开发模式中,工程师需要在多个工具间频繁切换——编辑器用于编码,Model…...

WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎
WebPlotDigitizer技术架构深度解析:计算机视觉驱动的图表数据提取引擎 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 在科…...

RTOS任务通知:轻量级通信机制的原理、应用与性能优化
1. 项目概述:为什么RTOS应用需要“任务通知”在嵌入式实时操作系统(RTOS)的世界里,任务间的通信与同步是决定系统效率、响应速度和稳定性的基石。传统的通信机制,如信号量、消息队列、事件标志组,我们早已驾…...