聊聊检索增强,LangChain一把梭能行吗?
背景
ChatGPT诞生之初,大家仿佛从中看到了未来:可以拿着大语言模型(LLM)这把锤子,锤遍业务上的钉子。其中最被看好的场景,莫过于搜索,不仅是微软、谷歌、百度这样的大公司将LLM用到自己的搜索业务中,Github上也有很多知识库、文档问答相关的优秀开源项目,究其本质,是通过检索相关知识来增强LLM的回答效果。
搭建一个检索增强pipeline其实很简单,“embedding模型+向量检索+LLM”这一套组合拳就足够,而且LangChain中都已经封装好了,简单写几行代码调用就能收工下班!但如果认真去分析最终回复的效果,就会发现这个pipeline只完成了工作的冰山一角,而本文,会展开聊聊冰山之下的秘密。
分片+检索+回答
首先需要对整体的流程进行概述:
-
文本分片。不同格式的原始数据,需要转成文本。因为文本在后续的操作中会拼接到prompt中,所以对于过长的文本,需要进行分片,控制在一定的长度之内。
-
文本检索。离线阶段,可以将文档片段都进行embedding,将embedding向量存储到向量数据库中;在线阶段,将用户query的embedding向量在向量数据库中进行检索,返回TopK的相关文档。
-
LLM回答。将TopK的相关文档组织成prompt,请求LLM得到最终的回答。
这三个步骤环环相扣,每一个环节的错误都会层层传递到后续的环节。下面会分别介绍这三个环节中可能会碰到的挑战。
![图来源于[3],”分片“对应图中第1、2步,”检索“对应第3、4步,”回答“对应第5步](https://img-blog.csdnimg.cn/img_convert/99f2d55bcac5bcc1f617ef1f92205158.png)
图来源于[3],”分片“对应图中第1、2步,”检索“对应第3、4步,”回答“对应第5步
文本分片
文本数据抽取
且不论多模态数据,单单是文本数据的存储格式,常见的就有:TXT、Word、PDF、Latex、CSV、Excel、HTML、Markdown……不同格式的数据要转成纯文本,需要话费不少功夫,即使是Langchain-Loaders[1]已经提供了多种格式的文本提取接口,但对于复杂格式的文件,提取效果依然不太理想,如PDF。这时候就需要投入更多精力来进行数据清洗,否则会直接影响到最终的效果。
语义完整性
Langchain-Doc Transformers[2]中介绍了按照长度、指定符号(句号、换行符)这些简单的规则进行文本分片的方法,但用这些方法得到的分片很多情况下会有语义不完整的问题,比如:
-
文档格式转换(如PDF无法识别段落)出问题
-
整体语义蕴含在长文本中
-
当文档编写者不遵守语法,胡乱断句换行
-
……
为了保证语义的完整性,可以尝试以下方案:
-
使用模型(比如Bert)进行分片,而不是简单的依靠规则切分。
-
对文档进行摘要,这样可以大幅缩短文档的篇幅,保证语义的完整性。
-
使用LLM根据文档构造多个QA pair,由于LLM可接受的prompt长度会大于文本片段的长度,通过这种方法得到QA pair能够将距离较远的信息有结构地组织到一起,控制在可接受的长度内。
文本检索
过滤无关文本片段
如果只是取检索结果的TopK拼接到后续LLM的Prompt中,那TopK中难免会有和用户问题不相关的结果,所以需要进行过滤,尽量保证给的LLM的都是相关的文本片段。
常用的过滤方式就是根据相关性分数过滤了,可以选择一个阈值,丢弃相关性低于该阈值的文档。这么做的前提,需要Embedding模型最好满足以下要求:
-
Embedding模型返回的向量最好是归一化后的,这样使用内积或欧氏距离表示相关性时,取值都在固定范围内,容易选择阈值。
-
Embedding模型最好做过**校准(Calibration)**。校准这一操作在CTR预估中很常见,主要是因为训练时一般采用pairwise,同时也主要会使用AUC、NDCG这类排序类型的评价指标,比如A>B>C,模型预测ABC的分数为[0.1, 0.2, 0.3]或[0.7, 0.8, 0.9]在评价指标上是一样的,但这样不利于选取合适的阈值来过滤无关文本,所以需要加上校准这一步骤。
多轮问答下的检索Query
假设用户前后的两个问题是:”颐和园在哪里?“、”门票多少钱?“。但如果单看第二个问题,无法知道用户想问的是哪里的门票。所以,如果只用最新的query来检索,会造成上下文依赖丢失的问题。
针对这个问题,可以尝试以下解法:
-
增加一个模型(比如:Bert),用户判断当前的query和历史的query是否有上下文依赖关系,维护一个依赖关系链,如果有,则将依赖链上的query拼接起来用于文本检索,否则只需将最新的query用于检索即可。
-
让LLM根据近几轮的问答生成检索query,发挥LLM的通用性。
LLM回答
Prompt
用什么样的Prompt才能让LLM输出满意的结果呢?首先来看一个常用来做检索增强的Prompt:
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{context}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.Here is the chat histories between human and assistant, inside <histories></histories> XML tags.
<histories>
{{histories}}
</histories>human:{{question}}
ai:
以上这个Prompt,将相关文档、历史对话、用户问题都放进去了,看着是个很强的baseline。但如果你用的LLM不是强如ChatGPT,而只是6B、13B规模的开源模型,你会发现这个Prompt的效果不够稳定,经常出现Badcase。
我认为它最致命的缺点是没有采用对话的形式。之前在介绍ChatGPT的三步走方案时提到了,在第二、三步时训练数据的格式是对话的形式,所以,如果将Prompt能够保持对话的形式,效果应该能更好,下面是一个示例。关于Chatgpt是如何组织对话的,可以参考以往的这篇文章。
[{"role":"system","content":"""
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{context}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question."""},{"role":"user","content":"histories_user_1"},{"role":"assistant","content":"histories_assistant_1"},...{"role":"user","content":"question"},
]
礼貌拒答
即使有了检索增强,也不见得LLM能答上所有问题,相反,我们更希望LLM在没有把握的时候,选择有礼貌地拒答,所谓有礼貌,在很多场景中是和”人设“相关的,比如落地的场景是企业助手、电商客服等。想要实现人设和拒答的效果,主要的工作是在调优Prompt上。Prompt工程这活儿,感觉只能起到锦上添花的作用,效果想要更上一层楼还是得使用更强的LLM。
写在最后
创新到普及之间,技术到产品之间,可用到好用之间,存在着一道隐秘的GAP。篇幅有限,以上的一些经验,无法覆盖到方方面面,欢迎大家一起来讨论!
Reference
[1] Langchain-Loaders
[2] Langchain-Doc Transformers
[3] Langchain-Question Answering
相关文章:
聊聊检索增强,LangChain一把梭能行吗?
背景 ChatGPT诞生之初,大家仿佛从中看到了未来:可以拿着大语言模型(LLM)这把锤子,锤遍业务上的钉子。其中最被看好的场景,莫过于搜索,不仅是微软、谷歌、百度这样的大公司将LLM用到自己的搜索业…...

【力扣】343. 整数拆分 <动态规划、数学>
【力扣】343. 整数拆分 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k > 2 ),并使这些整数的乘积最大化。返回可以获得的最大乘积 。 示例 1: 输入: n 2 输出: 1 解释: 2 1 1, 1 1 1。 示例 2: 输入: n 10 输出:…...
)
数据结构--5.1图的存储结构(十字链表、邻接多重表、边集数组)
目录 一、十字链表(Orthogonal List) 二、邻接多重表 三、边集数组 四、深度优先遍历 一、十字链表(Orthogonal List) 重新定义顶点表结点结构: datafirstInfirstOut 重新定义边表结构结点: tailV…...

mac上 Kratos 配置 protoc
前言 protoc 是 protobuf 文件(.proto)的编译器,可以借助这个工具把 .proto 文件转译成各种编程语言对应的源码,包含数据类型定义、调用接口等。 protoc 在设计上把 protobuf 和不同的语言解耦了,底层用 c 来实现 protobuf 结构的存储&#x…...
【c++5道练习题】①
目录 一、有限制的累加 二、计算日期到天数转换 三、仅仅反转字母 四、 字符串的第一个唯一字符 五、字符串最后一个单词的长度 一、有限制的累加 题述: 求123...n,要求不能使用乘除法、for、while、if、else、switch、case等关键字以及条件判断语句…...

最佳实践:TiDB 业务读变慢分析处理
作者:李文杰 网易游戏计费 TiDB 负责人 在使用或运维管理 TiDB 的过程中,大家几乎都遇到过 SQL 变慢的问题,尤其是查询相关的读变慢问题。读变慢的问题大部分情况下都遵循一定的规律,通过经验的积累可以快速的定位和优化ÿ…...

【ES6】Getter和Setter
JavaScript中的getter和setter方法可以用于访问和修改对象的属性。这些方法可以通过使用对象字面量或Object.defineProperty()方法来定义。 以下是使用getter和setter方法的示例: <!DOCTYPE html> <script>const cart {_wheels: 4,get wheels(){retu…...

3DS Max中绘制圆锥箭头
3DS Max中绘制圆锥箭头 绘制结果绘制过程步骤一:绘制立体圆锥方法1方法2 步骤二:圆锥体调参(模型尺寸设置)1圆锥体参数说明2圆锥体参数调整 步骤三:绘制圆柱体步骤四:圆柱体调参步骤五:圆锥与圆…...

虚拟机Ubuntu20.04 网络连接器图标开机不显示怎么办
执行以下指令: sudo service network-manager stop sudo rm /var/lib/NetworkManager/NetworkManager.state sudo service network-manager start...
你真的知道什么是USB Server吗?一分钟了解
很多公司都在用USB Server,效率大幅提高,但也还有不少人不知道USB Server到底是什么、干嘛用的。 USB Serve是帮助企业远程连接和集中管控USB设备的服务器 它的主要用途就是异地远程连接USB。 如,虚拟化环境的加密狗、前置机连接࿰…...
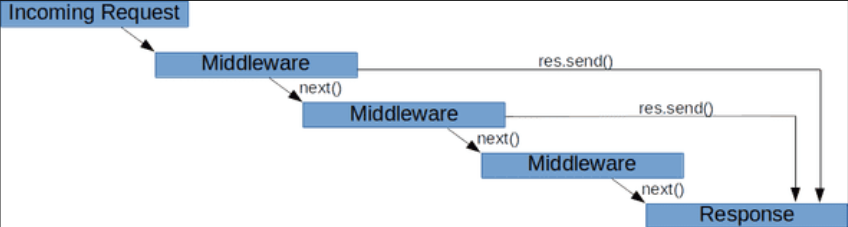
Node.js 中间件是怎样工作的?
express自带路由功能,可以侦听指定路径的请求,除此之外,express最大的优点就是【中间件】概念的灵活运用,使得各个模块得以解耦,像搭积木一样串起来就可以实现复杂的后端逻辑。除此之外,还可以利用别人写好…...
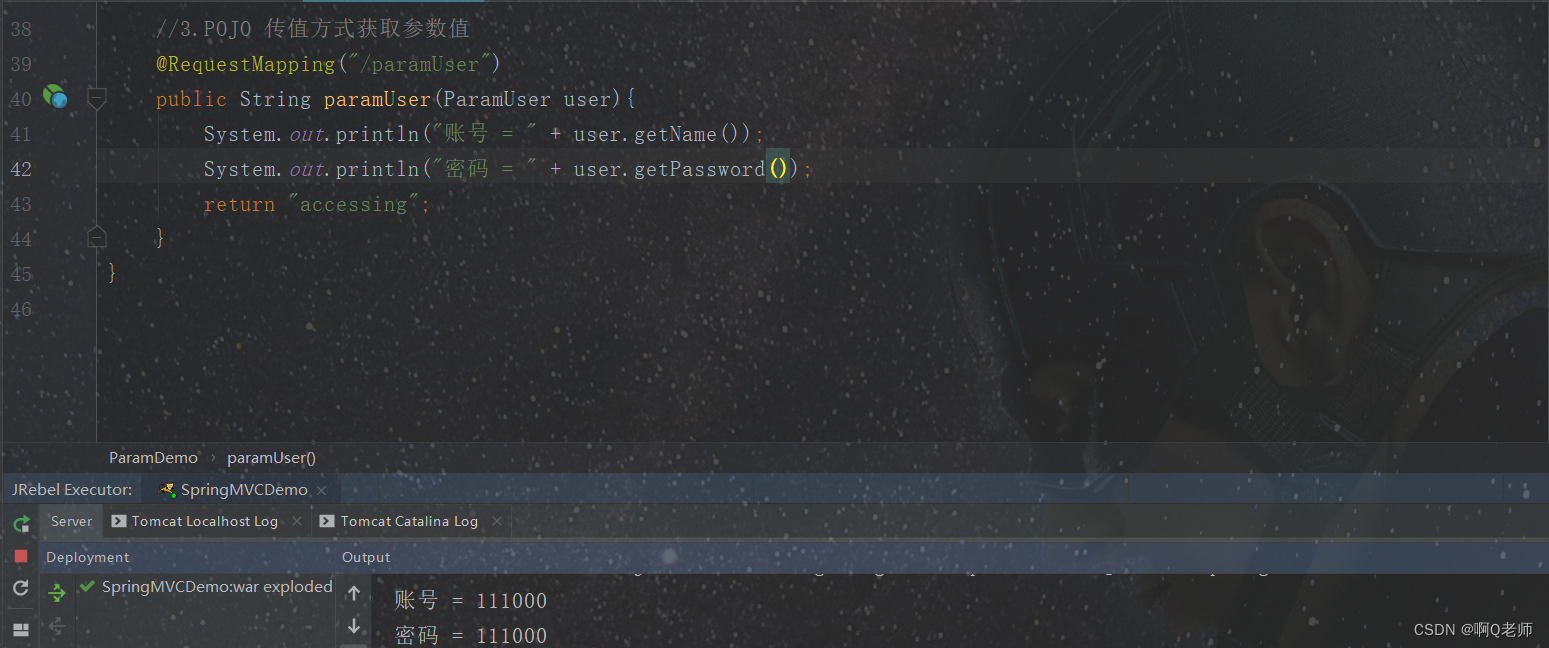
Spring MVC: 请求参数的获取
Spring MVC 前言通过 RequestParam 注解获取请求参数RequestParam用法 通过 ServletAPI 获取请求参数通过实体类对象获取请求参数附 前言 在 Spring MVC 介绍中,谈到前端控制器 DispatcherServlet 接收客户端请求,依据处理器映射 HandlerMapping 配置调…...

别再头疼反弹Shell失败了,这篇文章带你找到问题根源
别再头疼反弹Shell失败了,这篇文章带你找到问题根源 在渗透测试中,反弹shell失败的原因可以有多种。以下是一些常见的原因: **1.防火墙和网络过滤器:**目标系统可能配置了防火墙或网络过滤器,以限制对外部系统的连接…...
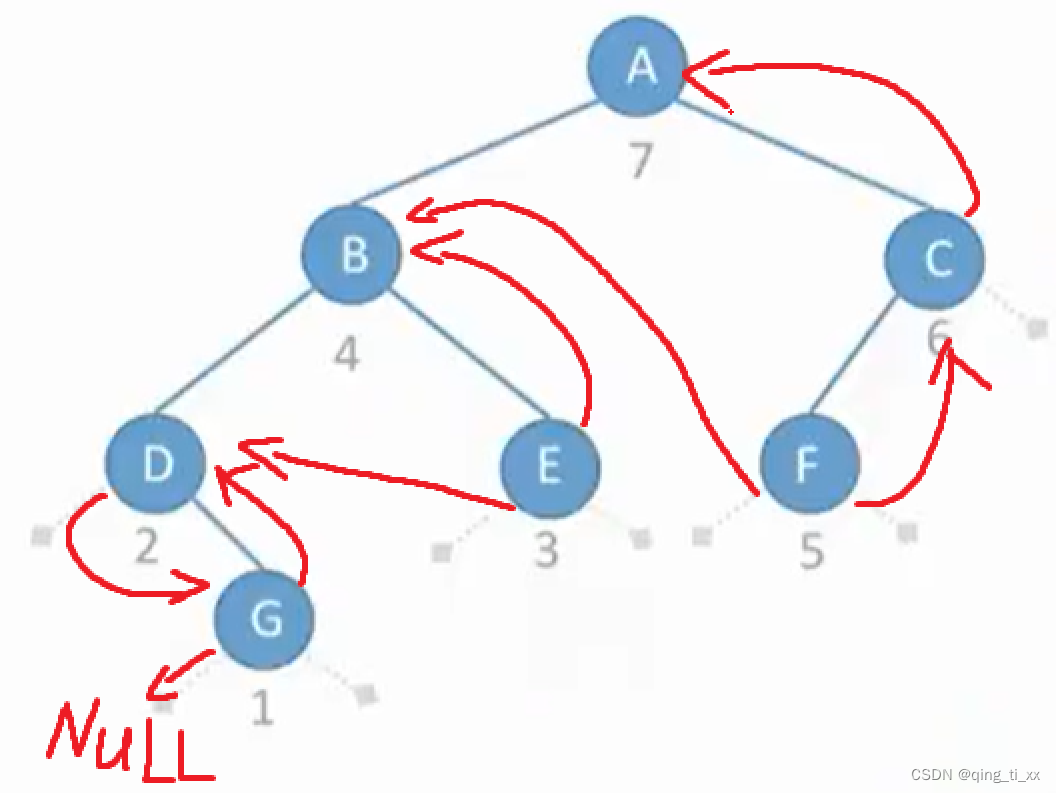
第五章 树与二叉树 四、线索树(手算与代码实现)
一、定义 1.线索树是一种二叉树,它在每个节点上增加了两个指针,分别指向其前驱和后继。 2.这些指针称为“线索”,因此线索树也叫做“线索化二叉树”。 3.在线索树中,所有的叶子节点都被线索化,使得遍历树的过程可以…...

服务器前后端学习理解
个人兴趣,突然想起来记录一下 1. 背景 想做一个最简单的网页,点击按钮后,访问服务器的redis数据库,读取一个为hello的值并显示 首先用js写了一个脚本,使用redis包,读取到了数据,并使用consol.l…...
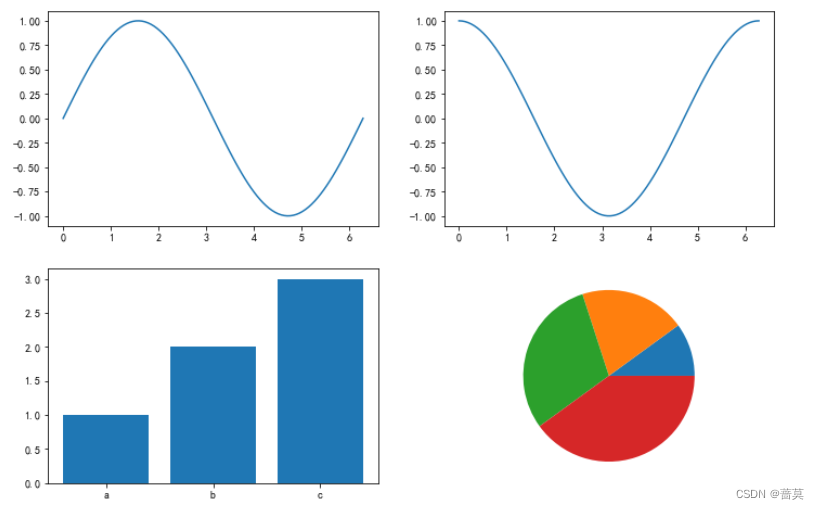
python-数据分析-numpy、pandas、matplotlib的常用方法
一、numpy import numpy as np1.numpy 数组 和 list 的区别 输出方式不同 里面包含的元素类型 2.构造并访问二维数组 使用 索引/切片 访问ndarray元素 切片 左闭右开 np.array(list) 3.快捷构造高维数组 np.arange() np.random.randn() - - - 服从标准正态分布- - - …...
ChatGPT⼊门到精通(5):ChatGPT 和Claude区别
⼀、Claude介绍 Claude是Anthropic开发的⼀款⼈⼯智能助⼿。 官⽅⽹站: ⼆、Claude能做什么 它可以通过⾃然语⾔与您进⾏交互,理解您的问题并作出回复。Claude的主要功能包括: 1、问答功能 Claude可以解答⼴泛的常识问题与知识问题。⽆论是历史上的某个事件,理科…...
ChatGPT 总结数据分析的所有知识点
ChatGPT功能非常多,特别是对某个行业,某个方向,某个技术进行总结那是相当专业的。 如下图。 直接用一个指令便总结出来数据分析当中的所有知识点内容。 AIGC ChatGPT ,BI商业智能, 可视化Tableau, PowerBI, FineReport, 数据库Mysql Oracle, Office, Python ,ETL Ex…...
hadoop-HDFS
1.HDFS简介 2.1 Hadoop分布式文件系统-HDFS架构 2.2 HDFS组成角色及其功能 (1)Client:客户端 (2)NameNode (NN):元数据节点 管理文件系统的Namespace元数据 一个HDFS集群只有一个Active的NN ÿ…...

0202hdfs的shell操作-hadoop-大数据学习
文章目录 1 进程启停管理2 文件系统操作命令2.1 HDFS文件系统基本信息2.2 介绍2.3 创建文件夹2.4 查看指定文件夹下的内容2.5 上传文件到HDFS2.6 查看HDFS文件内容2.7 下载HDFS文件2.8 HDFS数据删除操作 3 HDFS客户端-jetbrians产品插件3.1 Big Data Tools 安装3.2 配置windows…...

英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南
英雄联盟LCU工具集LeagueAkari:终极自动化游戏助手完整指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit LeagueAkari是一款基于…...

3步掌握TEdit地图编辑器:泰拉瑞亚终极创作工具完全指南
3步掌握TEdit地图编辑器:泰拉瑞亚终极创作工具完全指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you c…...
)
Linux 系统编程 文件篇 (二)
[TOC] Linux 系统编程 文件篇 (二) 1 open 函数介绍 1.1 标记位 上一篇的结尾,我们讲到了我们用的打开文件的库函数其实是封装了,这个 open 的系统调用,然后解释了这个 open 函数的 这个标记位,flags 是一个…...

版本控制系统核心功能解析:从历史追踪到团队协作的四大基石
1. 项目概述:从ICO到VCS,一次版本控制的深度对话在软件开发的日常里,我们经常听到“版本控制”这个词,它就像是程序员们的时光机和后悔药。但具体到工具上,Git、SVN、Mercurial……选择很多,而“VCS ICO”这…...

自动化测试的未来:AI测试会取代人工测试吗
一、AI浪潮下的测试行业变局在软件测试行业的发展历程中,自动化测试的出现曾被视为提升效率的关键转折点,而如今,AI技术的深度介入,正在将这场变革推向新的高度。从AI自动生成测试用例,到智能预测高风险代码模块&#…...

STM32串口转RS-485双机通信:硬件设计、软件驱动与调试全解析
1. 项目概述:从串口到485,双机通信的工业级实现搞嵌入式开发,尤其是用STM32做控制,串口通信(UART)绝对是绕不开的基础。但如果你想把两个STM32板子连起来,距离稍微远一点,或者环境里…...

面试题目总结
面试心态 越是置自己于低位,就越难获得面试官的青睐。面试官其实更喜欢逻辑清晰,不卑不亢,带点锋芒的应聘者。 不要以通过面试为目的,不然很难摆脱被凝视的状态。要以自我成长与提升为中心。要记住,每一次面试不是成功…...

FDTD Solutions 8.0 保姆级上手教程:从软件安装到第一个仿真结果
FDTD Solutions 8.0 零基础实战指南:从安装到首个完整仿真 当你第一次打开FDTD Solutions 8.0时,那些复杂的工具栏和陌生的术语可能会让你望而却步。作为一款专业的光学仿真软件,它确实有着陡峭的学习曲线——但别担心,这正是本文…...

GitHub神级项目推荐:30+款AI编程工具系统提示词全公开,Cursor/Manus/Devin/Windsurf内部指令一网打尽
前言 为什么同样用GPT-4o,别人的Cursor写代码又快又准,你的却经常出bug?为什么Windsurf的Cascade能自主完成复杂重构,你的AI却只会写简单函数?答案不在模型本身,而在每家AI公司视为核心机密的系统提示词&am…...
)
别再怕模型不准了!用MATLAB的musyn命令搞定鲁棒控制器设计(附D-K迭代详解)
用MATLAB的musyn命令实现工业级鲁棒控制器设计实战指南 在控制系统的实际工程应用中,模型不确定性就像房间里的大象——人人都知道存在,却常常选择忽视。直到某天,精心设计的控制器在真实环境中表现失常,工程师们才意识到那些被忽…...