【Pytorch笔记】1. tensor的创建
参考视频:
深度之眼官方账号:01-02-张量简介与创建
torch.tensor()
b = torch.tensor(data, dtype=None, device=None, requires_grad=False, pin_memory=False)
data:创建的tensor的数据来源,可以是list或numpy
dtype:数据类型,默认与data一致
device:所选设备,cuda/cpu
requires_grad:是否需要梯度
pin_memory:是否存在锁页内存(与转换效率有关,通常设置为False)
import numpy as np
import torcharr = np.ones((3, 3))
print("ndarray的数据类型:", arr.dtype)
t = torch.tensor(arr)
# t = torch.tensor(arr, device='cuda')
print(t)
输出:
ndarray的数据类型: float64
tensor([[1., 1., 1.],[1., 1., 1.],[1., 1., 1.]], dtype=torch.float64)
torch.from_numpy(ndarray)
功能:从numpy创建tensor
注意:从torch.from_numpy创建的tensor与原ndarray共享内存,当修改其中一个的数据,另一个也会被改动。
import numpy as np
import torcharr = np.array([[1, 2, 3], [4, 5, 6]])
t = torch.from_numpy(arr)
print(t)
arr[0, 0] = 7
print(t)
输出:
tensor([[1, 2, 3],[4, 5, 6]], dtype=torch.int32)
tensor([[7, 2, 3],[4, 5, 6]], dtype=torch.int32)
torch.zeros()
功能:根据给定size创建全0的tensor
torch.zeros(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
*size:创建的tensor的尺寸
out:输出到哪个tensor当中
dtype:创建的tensor中内容的类型
layout:tensor在内存中的分布方式,目前支持torch.strided和torch.sparse_coo
device:所在设备,gpu/cpu
requires_grad:是否需要梯度
import torcht = torch.zeros((3, 3)) #不使用out参数创建
tt = torch.tensor([2.])
torch.zeros((3, 3), out=tt) #使用out参数输出到已有tensor
print(t, '\n', tt)
输出:
tensor([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])tensor([[0., 0., 0.],[0., 0., 0.],[0., 0., 0.]])
有一点需要注意,如果像这样使用:
t = torch.tensor([2.])
p = torch.zeros((3, 3), out=t)
那么t和p会指向同一个地址。
torch.zeros_like()
功能:根据input的形状创建全0的tensor。
torch.zeros_like(input,dtype=None,layout=None,device=None,requires_grad=False)
input:创建新的tensor所用的形状的基准,生成的tensor和input的形状相同。
注:input只能为tensor,不能是np.array。
其余参数和torch.zeros()相同。
import numpy as np
import torchdata = torch.tensor(np.array([[1, 2], [3, 4]]))
t = torch.zeros_like(data)
print(t)
输出:
tensor([[0, 0],[0, 0]], dtype=torch.int32)
torch.ones()
功能:根据给定size创建全1的tensor,与torch.zeros()基本一样。
torch.ones(*size, out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
torch.ones_like()
功能:根据input的形状创建全1的tensor,与torch.zeros_like()基本一样。
torch.ones_like(input, dtype=None,layout=None,device=None,requires_grad=False)
torch.full()
功能:根据给定size创建tensor,元素全部赋值为fill_value。
torch.full(size,fill_value,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
fill_value:传入的参数,full()将创建好的tensor全部赋值为fill_value。
import numpy as np
import torcht = torch.full(size=(3, 3), fill_value=4)
print(t)
输出:
tensor([[4, 4, 4],[4, 4, 4],[4, 4, 4]])
torch.arange()
功能:创建等差的一维tensor。
torch.arange(start=0,end,step=1,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
范围是[start, end),左闭右开的,step为步长。其他的参数与上面的函数一样。
import numpy as np
import torcht = torch.arange(start=3, end=6, step=1)
print(t)
输出:
tensor([3, 4, 5])
torch.linspace()
功能:创建均分的1维tensor。
linspace: Linear space,类比下面的logspace。
torch.linspace(start=0,end,steps=100,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
范围是[start, end],是闭区间(和arange不同)。steps为生成的tensor的长度。
import numpy as np
import torcht = torch.linspace(start=2, end=10, steps=4)
print(t)
输出:
tensor([ 2.0000, 4.6667, 7.3333, 10.0000])
torch.logspace()
功能:创建对数均分的1维tensor。
logspace: Log space,类比上面的linspace。
torch.logspace(start,end,steps=100,base=10.0,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
start、end、steps与linspace相同。base指对数函数的底,默认为10。
和linspace不同的是,我们通过start, end, steps枚举出来的数列,是tensor的内容外面要套一个 l o g b a s e log_{base} logbase。反过来讲,我们枚举的就是以base为底的那些幂数。
可以参考下面的代码:
import numpy as np
import torcht = torch.logspace(start=1, end=3, steps=3, base=10.0)
print(t)
输出:
tensor([ 10., 100., 1000.])
torch.eye()
功能:创建单位对角矩阵,是2维tensor。默认为方阵。
torch.eye(n,m=None,out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
n、m:矩阵行数、列数。通常我们只需要设置n。
import numpy as np
import torcht = torch.eye(n=3)
p = torch.eye(n=3, m=4)
print(t)
print(p)
输出:
tensor([[1., 0., 0.],[0., 1., 0.],[0., 0., 1.]])
tensor([[1., 0., 0., 0.],[0., 1., 0., 0.],[0., 0., 1., 0.]])
torch.normal()
功能:根据给定的均值 μ \mu μ和标准差 σ \sigma σ,通过 N ( μ , σ ) N(\mu,\sigma) N(μ,σ)生成对应尺寸的随机数(具体如何对应尺寸,下面会有说明)。
torch.normal(mean,std,out=None)
mean:均值;std:标准差。
均值和标准差的类型,既可以是float,也可以是tensor。此时出现了4种情况,先看示例代码。
import numpy as np
import torcht1 = torch.normal(mean=2, std=3, size=(2, 3))
print("t1:\n", t1)
t2 = torch.normal(mean=torch.arange(1., 3.), std=torch.arange(3., 5.))
print("t2:\n", t2)
t3 = torch.normal(mean=1., std=torch.arange(1., 5.))
print("t3:\n", t3)
t4 = torch.normal(mean=torch.arange(1., 4.), std=2.)
print("t4:\n", t4)
输出:
t1:tensor([[-0.1495, 0.2061, 3.0486],[ 6.1257, 1.6023, 1.1515]])
t2:tensor([-5.4967, 7.4201])
t3:tensor([ 3.3218, 0.7347, -3.6644, 3.4812])
t4:tensor([2.2250, 1.1026, 0.9171])
mean和std都是float
见示例代码中t1。
此时我们必须要再加一个参数size,表示我们要生成的tensor的尺寸。生成的t1中每一个元素都是由 N ( m e a n , s t d ) N(mean,std) N(mean,std)生成的一个随机数。
mean和std都是tensor
见示例代码中t2。
经过尝试,需要mean和std的shape相同,这样生成的tensor的对应位置就是由mean和std中对应位置的均值和标准差随机出来的数。
mean是float,std是tensor
见示例代码中t3。
生成的tensor和std的shape相同,对应的位置是由mean、std中的对应位置的标准差随机出来的数。
mean是tensor,std是float
见示例代码中t4。
生成的tensor和mean的shape相同,对应的位置是由mean中的对应位置的均值、std随机出来的数。
torch.randn()
功能:生成标准正态分布 N ( 0 , 1 ) N(0,1) N(0,1)。
torch.randn(*size, out=None,dtype=None,layout=torch.strided,device=None,requires_grad=False)
import numpy as np
import torcht = torch.randn((2, 3))
print(t)
输出:
tensor([[ 0.2370, -1.4351, -0.0624],[ 0.7974, 1.2915, -1.0052]])
torch.randn_like()
功能:生成与给定tensor同样尺寸的标准正态分布tensor。(类比torch.zeros_like()和torch.ones_like())
import numpy as np
import torchtmp = torch.ones((2, 3))
t = torch.randn_like(tmp)
print(t)
输出:
tensor([[-0.3384, -0.8061, 0.7020],[ 0.1602, 0.6525, -0.6860]])
torch.rand()、torch.rand_like()
功能:在区间[0,1)上生成均匀分布,示例略。
torch.randint()、torch.randint_like()
功能:在区间[low, high)生成整数均匀分布。
torch.randperm()
功能:生成从0到n-1的随机排列,n是张量的长度。
torch.randperm(n,out=None,dtype=torch.int64,layout=torch.strided,device=None,requires_grad=False)
import numpy as np
import torcht = torch.randperm(5)
print(t)
输出:
tensor([3, 2, 1, 0, 4])
torch.bernoulli()
功能:以input为概率,生成伯努利分布(0-1分布,两点分布)
torch.bernoulli(input,*,generator=None,ont=None)
input为概率值,为tensor。
import numpy as np
import torchp = torch.rand((3, 3))
t = torch.bernoulli(p)
print("p:\n", p)
print("t:\n", t)
输出:
p:tensor([[0.6881, 0.7921, 0.4212],[0.6857, 0.4809, 0.4009],[0.2400, 0.5160, 0.1303]])
t:tensor([[1., 1., 1.],[1., 1., 0.],[0., 0., 0.]])
相关文章:

【Pytorch笔记】1. tensor的创建
参考视频: 深度之眼官方账号:01-02-张量简介与创建 torch.tensor() b torch.tensor(data, dtypeNone, deviceNone, requires_gradFalse, pin_memoryFalse)data:创建的tensor的数据来源,可以是list或numpy dtype:数据…...

Maven 基础之安装和命令行使用
Maven 的安装和命令行使用 1. 下载安装 下载解压 maven 压缩包(http://maven.apache.org/) 配置环境变量 前提:需要安装 java 。 在命令行执行如下命令: mvn --version如出现类似如下结果,则证明 maven 安装正确…...

运动耳机需要具备哪些功能、挂耳式运动蓝牙耳机推荐
作为运动爱好者,长时间的运动很容易枯燥,所以我会选择佩戴耳机来缓解运动的枯燥感,一款好的运动耳机可以让运动变得更加激情,还可以更好的享受运动的乐趣。 但现在的运动耳机产品实在是五花八门,到底什么样的运动蓝牙耳…...
【MCU】SD NAND芯片之国产新选择
文章目录 前言传统SD卡和可贴片SD卡传统SD卡可贴片SD卡 实际使用总结 前言 随着目前时代的快速发展,即使是使用MCU的项目上也经常有大数据存储的需求。可以看到经常有小伙伴这样提问: 大家好,请问有没有SD卡芯片,可以直接焊接到P…...
java 多线程
01.多线程类java.lang.Thread 这里继承Thread类的方法是比较常用的一种,如果说你只是想起一条线程。没有什么其它特殊的要求,那么可以使用Thread.(笔者推荐使用Runable,后头会说明为什么)。下面来看一个简单的实例&…...
ConsoleApplication17_2项目免杀(Fiber+VEH Hook Load)
加载方式FiberVEH Hook Load Fiber是纤程免杀,VEH是异常报错,hook使用detours来hook VirtualAlloc和sleep,通过异常报错调用实现主动hook 纤程Fiber的概念:纤程是比线程的更小的一个运行单位。可以把一个线程拆分成多个纤程&#…...
【Vue3 知识第五讲】条件渲染、列表渲染知识详解
文章目录 一、条件渲染1.1 概述1.2 演示代码 二、列表渲染2.1 使用 指令 v-for 遍历数组2.2 **使用 指令 v-for 遍历对象** 十、案例作业十一、总结 在前端开发过程中,条件和循环是经常被用到的逻辑。vue中封装了自己的组件渲染指令,可以更加方便的帮助开…...

vite+vue3从0开始搭建一个后管项目【学习随记二】
创建项目安装插件可以去【学习随记一】看下 1.路由配置 **文件路径是router/index.ts** import { createRouter, createWebHistory } from vue-router import { UserStore, userMenu } from /pinia import routes from ./routes import MainRouter from ./MainRouterconst ro…...

Linux的内存理解
建议 Mysql机器 尽量不要硬swap,如果是ssd磁盘还好。Free命令 free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存 输出简介: Mem 行(第二行)是内存的使用情况。Swap 行(第三行)是交换空间的使用情况。total 列显示系统总的可用物理内存和交换…...
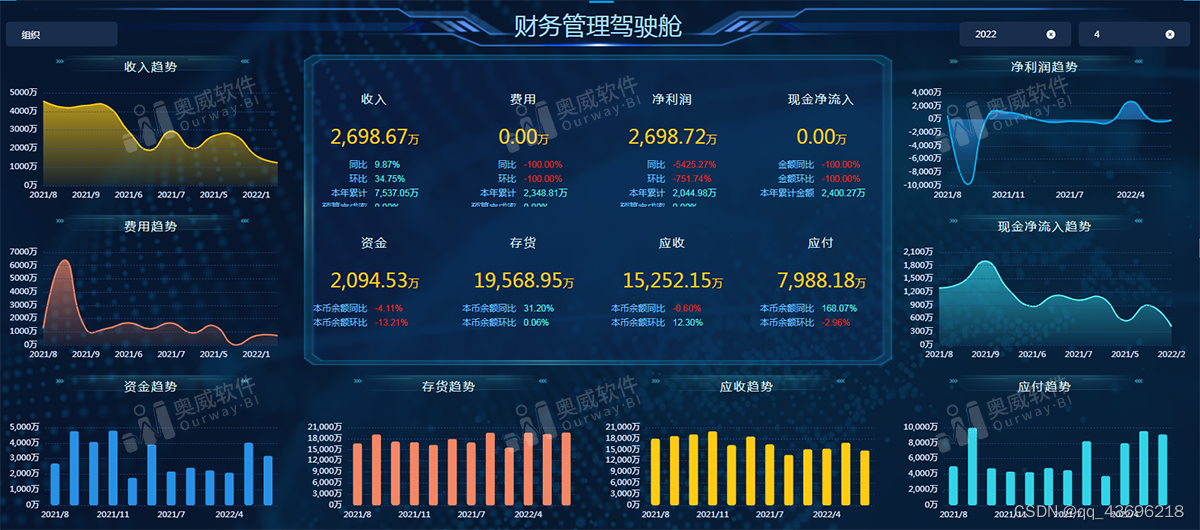
财务数据分析?奥威BI数据可视化工具很擅长
BI数据可视化工具通常是可以用户各行各业,用于不同主题的数据可视化分析,但面对财务数据分析这块难啃的骨头,能够好好地完成的,还真不多。接下来要介绍的这款BI数据可视化工具不仅拥有内存行列计算模型这样的智能财务指标计算功能…...

趣味微项目:玩转Python编程,轻松学习快乐成长!
💂 个人网站:【工具大全】【游戏大全】【神级源码资源网】🤟 前端学习课程:👉【28个案例趣学前端】【400个JS面试题】💅 寻找学习交流、摸鱼划水的小伙伴,请点击【摸鱼学习交流群】 在学习Python编程的旅程…...

总结安卓Preference使用过程中注意的问题
近期在做新项目中接触到了Preference,这是一种用户界面元素,用于存储和展示应用程序的各种设置和用户偏好。该控件几年前google就已经发布了只是一直没机会应用,其实用起来还是挺方便的,使用过程中遇到了几个问题在此记录下。 1、…...

Laf 中大猫谱:让每一只流浪猫都有家
猫谱简介 中大猫谱是一款辅助校园流浪猫救助的开源小程序项目,服务端使用 Laf 云开发。 猫谱主要功能包括:猫咪信息登记、照片分享、拍照识猫、公告和留言等。项目创立的初衷,是解决校园猫猫交流群里的一个常见问题:问猫猫是谁。…...

uniapp 使用mqtt 报错 socketTask onOpen is not a function
1. 报错的解决方法 在man.js文件添加这个 // #ifndef MP // 处理 wx.connectSocket promisify 兼容问题,强制返回 SocketTask uni.connectSocket (function(connectSocket) {return function(options) {console.log(options)options.success options.success ||…...
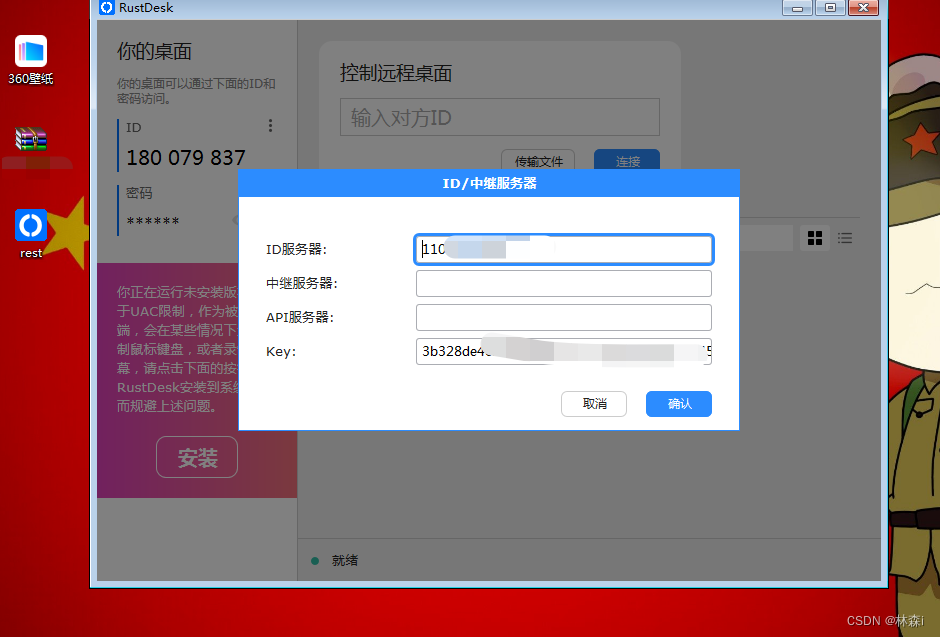
Docker部署RustDesk Server 设置开机自启
三、Docker安装 Docker官方和国内daocloud都提供了一键安装的脚本,使得Docker的安装更加便捷。 官方的一键安装方式: curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun 国内 daocloud一键安装命令: curl -sSL https://…...

ESLint如何在vue3项目中配置和使用
目录 问题描述: 配置: 注意: 问题描述: 在用vite创建vue3项目时已经选择了添加ESLint,创建完成后使用 pnpm install命令(或者npm i)安装了项目依赖之后,ESLint在项目中需要怎样配…...

Frida-hook:微信数据库的破解
Frida-hook:微信数据库的破解 Frida-hook:微信数据库的破解1. 准备条件2. 用frida获取key2.1 静态分析微信apk文件2.2 frida hook: 3. 用sqlcipher打开数据库: Frida-hook:微信数据库的破解 我们可以从root过的手机中,找到微信相关数据库&am…...
【Unity每日一记】WheelColider组件汽车游戏的关键
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:uni…...
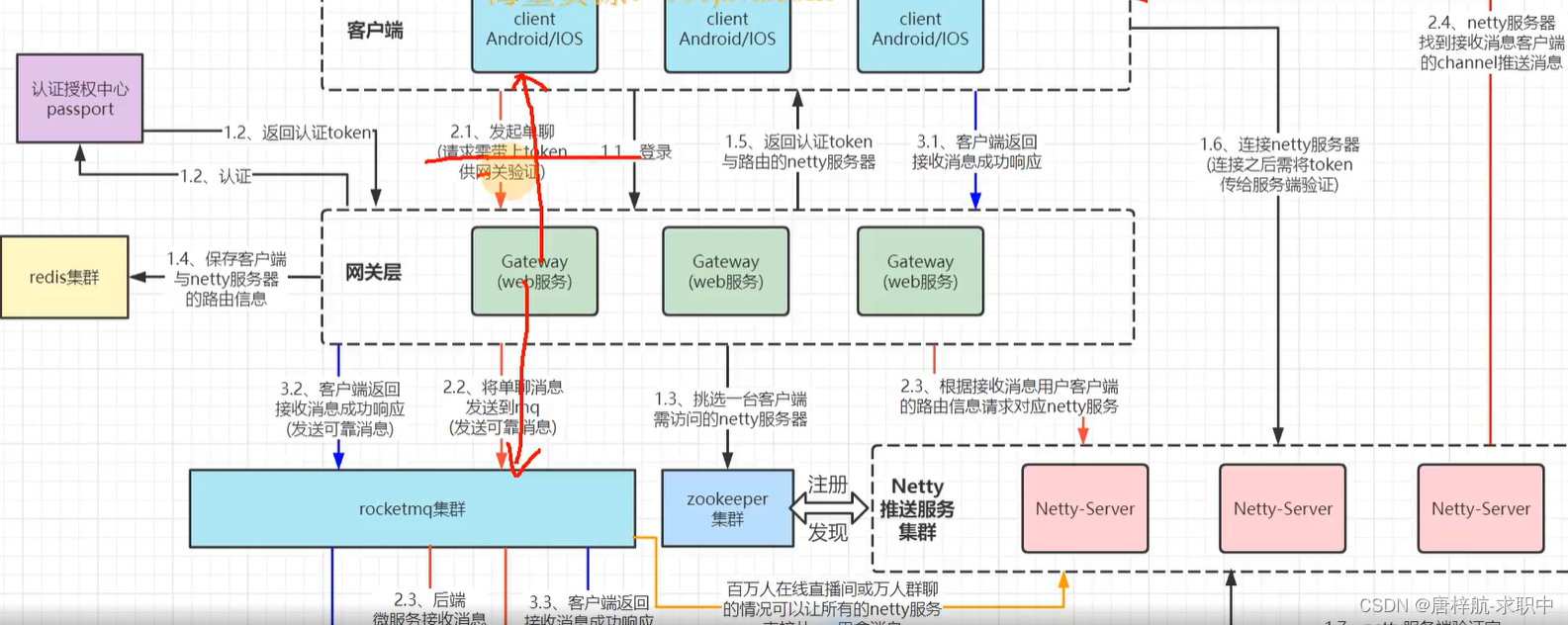
项目-IM
tim-server tim-server启动类实现CommandLineRunner接口,重写run()方法 run()方法开启一个线程,创建zk持久父节点,创建临时顺序子节点,将netty-server信息写入 1.1 用户登录 1.2 gateway向认证授权中心请求token 1.3 从zookee…...

2023年口腔医疗行业研究报告
第一章 行业概况 1.1 定义 口腔医疗行业是以口腔医疗服务消费为基础,包含医疗及消费双重属性,是 为满足口腔及颌面部疾病的预防和诊疗、口腔美容等需求提供相关医疗服务的行业。 该行业的主要参与者包括口腔保健专业人员(如牙医、口腔外科…...

C++内存对齐与布局优化
C内存对齐与布局优化内存对齐是编译器为了提高内存访问效率而采用的策略。理解内存对齐规则对于优化结构体大小和提高程序性能至关重要。结构体的内存布局受对齐规则影响,可能包含填充字节。#include #includestruct Unaligned { char a; int b; char c; };struct A…...

远程办公三年,我摸索出一套不被“隐形加班”吞噬的方法
作为一名有着三年远程办公经验的软件测试工程师,我深知“隐形加班”如同温水煮青蛙,在不知不觉中吞噬着我们的私人时间与生活热情。从最初的“随时待命”到如今能精准划清工作与生活的界限,我总结出了一套切实可行的方法,希望能帮…...

关注模块 API
关注用户 POST /api/v1/relations/followHeaders:Authorization: Bearer {token}Request: {"user_id": "target_user_id" }Response: {"code": 0,"data": {"relation_type": "following"} }接口语义设计 POST /…...

Pure Live:3大平台聚合,打造你的专属纯净直播空间
Pure Live:3大平台聚合,打造你的专属纯净直播空间 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否厌倦了在多个直播应用间来回切换?…...

Midjourney中画幅风格不生效?5个致命配置错误正在 silently 毁掉你的成片率
更多请点击: https://kaifayun.com 第一章:Midjourney中画幅风格失效的真相与底层机制 Midjourney 中的中画幅(Medium Format)风格常被用户以 --style medium-format 或关键词 medium format film 调用,但大量实测表…...

选对服务商事半功倍!2026 全国头部综合型设计搭建会展服务商核心优势解读
本文详解 2026 年全国各大会展中心全国头部综合型设计搭建会展服务商的核心优势与价值,核心定义为全国头部综合型设计搭建会展服务商是指具备全产业链整合能力、全国化服务网络、丰富的行业经验与强大的技术实力,能够为客户提供一站式、全流程会展设计搭…...

制造业的AI智能体,为什么“部署方式”比“功能有多强”更关键?
和几位制造业IT负责人的交流中,有一个现象值得关注:他们最担心的不是AI智能体“能不能用”,而是“怎么部署”。 这和前两年的讨论方向明显不同。2024年前后,行业还在争论AI智能体到底有没有用、能在哪些场景落地。到了2026年&…...

揭秘Midjourney V6蒸汽波出图失败率高达63%的底层原因:3步绕过平台封禁,稳定生成霓虹故障美学
更多请点击: https://codechina.net 第一章:蒸汽波美学的数字幽灵:Midjourney V6封禁机制本质解构 蒸汽波(Vaporwave)以低保真采样、CRT扫描线、80年代商业图腾与数字怀旧为视觉语法,其美学内核恰恰在于对…...

OpenClaw+Hermes +Vibe Coding本地部署|论文自动化|知识工作流
在人工智能快速重塑科研范式的背景下,大语言模型、Agent系统与自动化科研工作流,正在深刻改变文献阅读、代码开发、数据分析、论文写作与科研协作的底层方式。面对模型快速迭代、工具形态持续演进的新局面,科研人员亟需从“会使用AI”进一步升…...

Python 3 简介
Python 3 简介 引言 Python 是一种广泛使用的编程语言,以其简洁的语法和强大的库支持而闻名。Python 3 是 Python 编程语言的最新主要版本,自 2008 年发布以来,它已经成为了许多开发者和企业首选的编程语言之一。本文将简要介绍 Python 3 的特点、应用领域以及学习资源。 …...