实录分享 | Alluxio在AI/ML场景下的应用
欢迎来到【微直播间】,2min纵览大咖观点
本次分享主要包括五个方面:
- 关于Alluxio;
- 盘点企业在尝试AI时面临的挑战;
- Alluxio在技术栈中的位置;
- Alluxio在模型训练&模型上线场景的应用;
- 效果对比:使用Alluxio前 VS 使用Alluxio后。
一、关于Alluxio
Alluxio——数据编排平台,一个高性能的数据接入层。
二、盘点企业在尝试AI时面临的挑战
1、GPU短缺;
2、模型上线慢;
3、GPU使用率低。
三、Alluxio在技术栈中的位置
√ Alluxio不是一个持久化的存储层,持久化存储比较依赖云上S3 Storage、Ceph或者是HDFS这种分布式存储;
√ Alluxio在AI领域是一个高性能的接入层;
√ Alluxio对Pytorch、TensorFlow的IO性能做了很多优化;
√ 再往上就是Ray或者是MLFlow这种AI/ML的编排层。
四、Alluxio在模型训练&模型上线场景的应用
√ 在需要的位置启动GPU集群;
√ 在现有数据湖上构建AI/ML;
√ 消除数据拷贝,降低成本/复杂度;
√ 实现更快的模型部署上线。
五、效果对比:使用Alluxio前 VS 使用Alluxio后
√ 使用前:用于数据加载的时间超过80%,GPU使用率不足20%;
√ 使用后:数据加载过程耗费的时间从82%减少到1% ,GPU利用率从17%提升到93%。
以上仅为大咖演讲概览,完整内容点击视频观看:

【点击观看】
附件:大咖分享文字版完整内容可见下文
一、关于Alluxio

模型训练热度越来越高,借着这个热度我们也来分享一下Alluxio在AI/ML场景下的应用。相信大家对Alluxio、Spark等生态都已经非常了解了,但我还是想再具体介绍一下,Alluxio提供了一个虚拟层——数据编排层,它不仅提供了一个更高性能的数据接入层,而且在大数据框架上下游 - 包括从存储到上层计算引擎中间的接入、数据访问的性能与易用方面都有很多优化。

Alluxio——数据编排平台,一个高性能的数据接入层。
项目诞生:
Alluxio(曾用名Tachyon)最初是UC Berkeley AMP实验室中Apache Spark的姐妹项目,研究如何使用分布式技术统一管理对外内存,为Apache Spark应用提供内存级数据访问加速。项目由李浩源(当时为AMP实验室在读博士)负责,并由同实验室其他师生参与。
Alluxio最初是聚焦在大数据方面,和Spark、Presto等计算引擎结合得非常紧密,从2020年开始到现在,我们看到AI场景下有很多问题是现在这个系统框架没有办法解决的或者说现在结合的方案还比较昂贵,所以我们在做大数据技术栈的同时,也同步开始做AI场景前沿技术的探索,到今天已经形成了一个比较产品化的方案,可以提供给大家使用。今天我们就结合所接触到的国内外公司在AI场景下遇到的挑战,做一个系统分享:
二、盘点企业在尝试AI时面临的挑战

1. GPU短缺
其实从几年前我们就发现,不管是在云上使用GPU还是自己购买GPU搭建IDC(数据仓库),AI基础设施都比较困难,原因大概可以分为3种情况:
1、很多公司无法买到GPU;
2、部分公司即使买到了GPU,量也不是很大,很难满足业务需求;
3、部分公司或许可以在阿里云或者腾讯云上买到GPU,但如何把这些GPU形成一个系统的计算池,供上层业务使用,是比较困难的。
2. 模型上线慢
公司现有数仓/存储方案较陈旧,很难迭代,进行GPU训练后,如何把模型上线到推理的集群中,是必不可少的一个环节,也是困难重重的一个环节:
√ 很多数仓、底层的存储都还是公司里比较传统的存储方案,比如HDFS,可能十几年前就开始用了,现在很难调整存储的设置;
√ 数据在云上,限流情况严重,使用限制较多。
后面我们也会深入聊一下,如何解决这个问题。
3. GPU使用率低
现在很多公司模型训练过程GPU利用率普遍比较低,当然这个不是Alluxio一家就能解决的问题,我们所看到的现象是:企业的数据大多在数仓中,这些数据如何引入GPU集群,存在非常多的挑战。后面我们也会分享一下在不同云厂商、国内外的大型企业中,Alluxio是如何解决这一问题的。

前面所提到的更多都是业务的压力或者是商业上业务决策的压力,这些压力反映到基础上对工程人员来说就会变成技术压力,为了能够更快进行模型开发,我们其实是有一些期望的:
1、更快的模型开发时间;
2、更频繁的模型数据更新;
3、更高的准确性和可追溯性;
4、适应快速增长的数据集。
这些压力反映到技术侧大概可以概括为3点:
1. 广泛的数据拷贝任务管理
比如以我们现在的应用,如何做这套系统,很多时候需要进行一些复杂的数据拷贝任务,从数据仓库往GPU的训练集群中进行数据拷贝,无论是拷贝到本地的NAS、NFS系统,或者是拷贝到本地的磁盘中进行数据管理,都是比较复杂的。
2. 专用存储
为了满足AI场景的需求,对性能的要求会比较高,可以这么理解:20-30年前,GPU是和HPC(高性能计算)一起发展起来的,所以那时候大家普遍倾向于要有一套IB的网络,并且是有一套高性能存储(全闪)支撑业务的发展,其实现在在云上或者是IDC里,我们发现这个问题是非常难解决的,因为大部分公司/云上设施没有办法提供这么高的专用存储支持模型训练或者是模型分发的任务。
3. 云和基础设施成本失控
模型上线以后,随着业务规模的增长,云和基础设施的成本是非常容易失控的,我们看到非常多的场景,比如3年增加5倍的云上成本都是很正常的。
三、Alluxio在技术栈中的位置

在进入详细技术讨论之前,再系统介绍一下Alluxio在AI/ML技术栈中的位置。
首先,Alluxio不是一个持久化的存储层,我们的持久化存储比较依赖云上S3 Storage、Ceph或者是HDFS这种分布式存储,这些都是Alluxio下面的一个接口,它们是一个持久化的存储层,和Alluxio不是同一个概念。
再往上,Alluxio在AI领域是一个高性能的接入层,因为对于持久化存储层来讲,大部分公司追求的是价格和性能效率,而这个效率就意味着要有一个非常便宜的存储池,可以存储很多资源,并不期望有一套非常昂贵的高性能存储来做持久化存储,之所以会这样是因为我们在很多互联网厂商或者是传统企业看到他们的数据量有几百个PB甚至是EB级别的,但同时需要训练的数据并没有那么多,可能就是几十个TB,甚至高一点的也就1PB左右,如果可以把这些数据放到一个高性能存储向上进行对接,对用户来说这个性价比是非常低的,所以我们比较依赖这种持久化存储层做一个非常简单的对接,或者现在已经有了持久化存储层,我们不改变它的架构,可以直接进行数据对接。
再往上,我们对Pytorch、TensorFlow的IO性能做了非常多优化,包括缓存策略、调度的优化/如何与它对接、Kubernetes的部署,后面我们会详细介绍如何对接。
再往上就是Ray或者是MLFlow这种AI/ML的编排层。
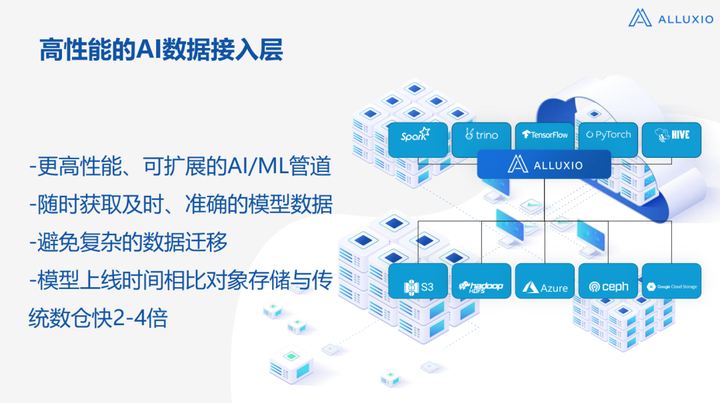
这是一个比较清晰的示意图,因为我们Alluxio是一个从大数据场景发展起来的公司,到现在我们做AI已经有大概4-5年的时间,在这4-5年时间里,我们从使用Alluxio的客户/用户环境中看到的价值是有非常多的,大概可以总结成4点:
1. 更高性能、可扩展的AI/ML管道
我们不改变现有的集群部署,比如已有的对象存储、HDFS等,同时又想扩展业务,这里其实有两个关键点:
√ 一般大数据和AI两个Team虽然是在一个大的架构下,但其实技术栈是非常不同的,比如大数据技术栈会有Spark、Trino、Hive、HBase等,向下对接的是HDFS、云上的一些对象存储等,这些数据是一直在的,数据量可能有几百个PB甚至是EB级别的,同时需要搭建一个AI Infra的平台,AI的技术栈其实是Pytorch、TensorFlow,下面对接的比较多的是对象存储,比如Ceph、MinIO等,其它的会有一些专用的存储,比如提供NFS、NAS的这些系统向上对接;
√ 其实这两个系统的存在就产生了对接的问题,就是数据在数仓中,但是处理是到AI Infra里,这就变成一套非常复杂的系统了,而Alluxio可以帮助打通这套系统,不需要每次都进行非常复杂的数据迁移。
2. 随时获取及时、准确的模型数据
模型的数据从训练集群出来,需要先落到存储中,然后再向上拉取到推理集群,这个过程很多时候是非常复杂的,比如Data Pipeline,我们之前沟通的很多互联网公司都有一个临时的checkpoint store,然后还有一个持久化的checkpoint store,他们进行低性能和高性能的互相拉取是一个非常复杂的过程。
3. 避免复杂的数据迁移
4. 模型上线时间相比对象存储与传统数仓快2-4倍
底层的存储一般都是对象存储或者是传统HDFS,比如传统的HDFS大家都是给大量数据存储设计的,这个不是为了性能而设计的,大部分情况是为了保障容错,同时针对云上的存储,在跟诸多云厂商交流后了解到,他们很多情况下没办法直接在云上用对象存储支持AI的业务,原因在于限流的问题,拉取数据的速度很快,所以没办法处理。
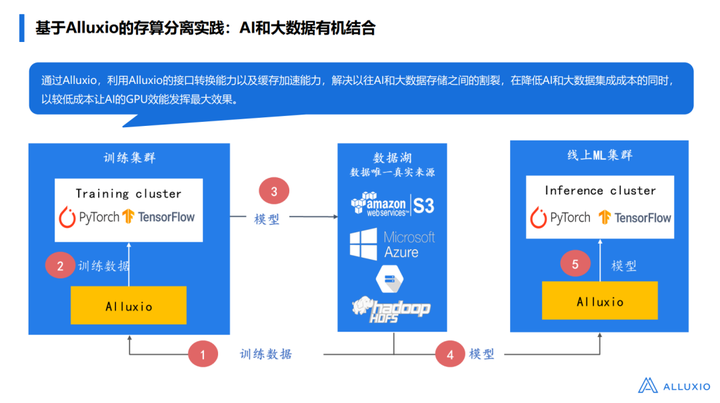
下面我们详细讲一下Alluxio是如何做这套系统的,里面有很多场景的沉淀,此处和大家分享一下Alluxio架构这么设计的初衷:
首先我们在很多互联网厂商看到,大部分的客户/用户,他们的数据大概率是在数据湖中(有90-95%),他们的数据并不是以一个单独的数据集群来做这个事,而是有非常多的数据,包括传统的Hive Meta store、现在比较流行的数据湖里的数据,同时还有很多Streaming Data的数据直接进来,也有很多非结构化的数据是放在数据湖里的。
那么Alluxio是如何在其中发挥作用的呢?
现在比较流行的就是用Spark或者Ray的架构,把这个数据预处理完,放回数据湖中,后面的TensorFlow、Pytorch会拉取这里的数据进行训练,比如看左边这个图,如果不用Alluxio拉取数据会产生什么问题呢?
比如原来的数仓用的是HDFS集群,AI训练会用一个Ceph的集群:
√ 首先要把处理好/未处理好的数据拉到Ceph的集群中,再向上serving这些拉取的data,在这里就会出现一些问题:首先这套拉取的流程会非常复杂,很多公司会自己开发一套数据管理系统完成,会有几套不同的流程在里边,比如我们用meta store对应这些表/数据在哪里;
√ 其次需要增量的拉取数据;
√ 最后需要对数据进行检验,查看是否有问题。
这套流程下来从拉取到可用有很长的延迟,所以我们就想用Alluxio缓存的功能帮助大家解决这个问题。
首先,我们可以预先将部分数据加载到 Alluxio 中,放到更靠近计算的存储中,从而降低带宽消耗。同时,即使没有预加载数据,Alluxio 的缓存机制也能帮助快速拉取数据到训练集群中。这种方式类似于股票交易中的 T+1(T+0)交易,即从一开始访问数据的瞬间,数据就可以被迅速提供,不需要等待数小时再传递数据上去,从而节省了大量时间。
其次,Alluxio 还能减少用户自行开发而产生的数据治理问题。如果用户已经有一套数据治理系统,我们也提供了多种 API,包括原始数据更新的 API,方便用户进行定制化开发。
此外,我们还着重关注:在训练集群上如何降低成本并提高效率。在过去,很多公司使用高性能的存储集群进行训练,但这种成本可能非常昂贵,限制了业务的扩展。我们发现,如果仅在 GPU 计算节点上配备磁盘,与 GPU 集群整体成本相比,这个成本通常不会超过 3- 5%。此外,许多公司拥有大量存储资源,但如何充分利用这些资源仍然是一个挑战。
Alluxio 在这方面提供了很多结合点。我们可以将 Alluxio 集群直接部署到训练节点上,这样的消耗非常小(约 30-40GB 内存),却能提供高性能的训练支持。用户只需要付出整个计算集群成本的 3- 5%,就可以充分利用 GPU 集群,帮助用户克服IO瓶颈去达到 GPU 100% 使用率。
除了训练集群,我们也特别关注推理集群的成本和效率问题。随着推理集群的扩展,成本可能远高于训练集群。因此,我们致力于解决如何快速将训练产生的模型部署到线上集群的问题。
在传统方式中,训练结果会写回到一个 Ceph 存储,然后线上集群可能位于同一个或不同的 IDC 中,涉及到复杂的管理。很多公司会开发一套自己的存储网关(storage Gateway)来解决跨域或跨 IDC 的问题,但是网关有个表问题,他解决的是一个跨域或者是跨IDC问题,但实际上 没有解决的是高性能和跨域的问题,简单理解就是可以把训练集群和线上的ML打通,但如果在AWS里这个Gateway是完全没有办法支撑推理集群的,比如扩展到100个甚至1000个节点的推理集群后,上线的时候会抖动的非常厉害,再比如:Alluxio可以在2-3分钟内把整个模型全都部署到推理集群上面,一般这种系统需要耗费的时间是它的10倍,而且它的P95和P99会非常长。
四、Alluxio在模型训练&模型上线场景的应用

接下来会详细讲解不同场景中,Alluxio是如何做的:
第一个就是我们之前说到的问题,在GPU非常短缺的情况下,我们看到的公司其实之前都不是多云战略,不是IDC融合或者是云上、本地都有的架构,但为了满足GPU资源的部署,很多时候被迫变成这样,举个例子,我们看到很多客户/用户,数据都是在AWS上,根本就不想用Azure、Google Cloud等其他云,但我们今年就发现一个问题,Azure把所有GPU都买了,在这种情况下其实很难说在AWS上可以找到所有集群,然后我们所看到的这些集群就必须在Azure里,就必须得有个方法直接去访问AWS里的数据,这个问题就导致如果直接去获取,数据性能就会非常低,如果是在网络带宽非常低的情况下,GPU的利用率通常不会超过10%,好一点的网络(比如有专线)情况下,可以达到20-30%。
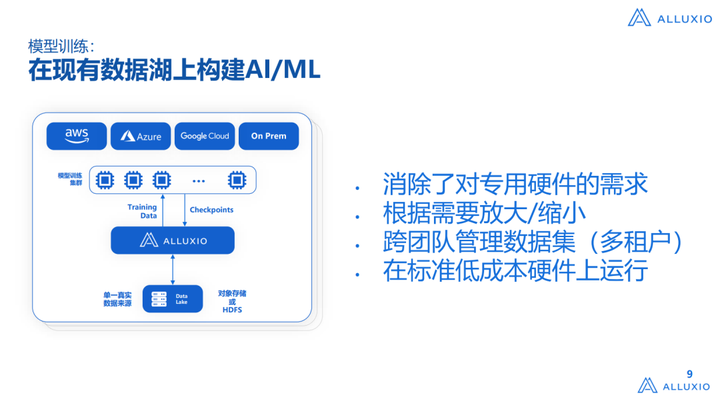
第二个问题是如果要建一个多集群数据管理是非常复杂的,包括要保证数据的一致性,如何更新、拉取这些数据,但对Alluxio来说,我们做了很多的集成,就可以直接使用Alluxio解决这些问题。其次就是我们不希望大家专门买一套硬件解决方案,在加入Alluxio之前,我所在的实验室是一直在做HPC的,HPC有一个很大的问题就是他的成本非常高,买1套HPC通常可以买10套Hadoop硬件,或者是云上的存储硬件,所以如果需要购买一套专有的硬件搭建AI Infra 架构,是事倍功半的,成本非常昂贵,看到这个场景后,我们提出还是希望可以直接在数据湖上构建AI和ML的数据通路,可以不更改存储系统,同时可以利用已有的,不需要额外购买IDMA这种硬件,就可以支撑训练的需求,这是我们的愿景。同时不用考虑和原数仓中任务进行数据隔离的问题(所谓隔离就是需要进行数据迁移,然后运行成两套非常独立的系统,这对数据的拉取、获取是非常有问题的)。

上图就是前面提到的,Alluxio提供的一些功能,比如自动数据湖加载/卸载、更新数据功能,从而提高数据工程团队的生产力,一个比较常见的场景就是:如果基于原有的系统搭建,加一个Ceph,基本时间线会拉长到3-6个月,在国外公司拉长到6个月以上是非常常见的,但是用了Alluxio整套系统拉取后,基本就可以在1-2个月内把整个Data Pipeline建起来,如果大家感兴趣可以去详细了解一下知乎的应用案例,里边有非常详细的解读,告诉大家如何去搭建这套系统。
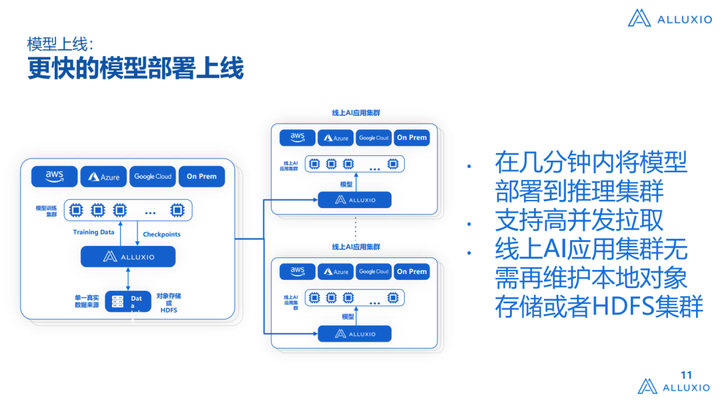
上图是我们前面提到的另一个问题:模型部署受限于底层的存储,包括带宽的问题,还受限于IDC不同位置的问题,我们Alluxio可以做一个多云多架构,不管是从公有云到私有云,还是不同公有云之间进行模型部署,都会非常快速的解决这个问题,我们会提供一个高并发的缓存系统,支持业务高并发拉取。

稍微总结一下,Alluxio在AI架构中处于怎样的位置?Alluxio帮助大家解决什么问题?
√ 第一个就是降低改造和适配的成本,帮助大家更聚焦在模型上线的逻辑上;
√ 第二个就是消除了专用存储架构,比如原来必须要用NAS、NFS这些系统来做的,用了Alluxio之后就不再需用,Alluxio和下面原来已有的HDFS,对象存储配合就可以搭建AI平台;
√ 第三个就是我们需要添加缓存,就可以把GPU利用率提高到较高的水平;
√ 第四个就是满足公司自由部署GPU的需求,不管是云上还是云下买的GPU,不论数据在哪,都可以实现很高效的数据适配,后面会提供一个具体案例。
五、效果对比:使用Alluxio前 VS 使用Alluxio后
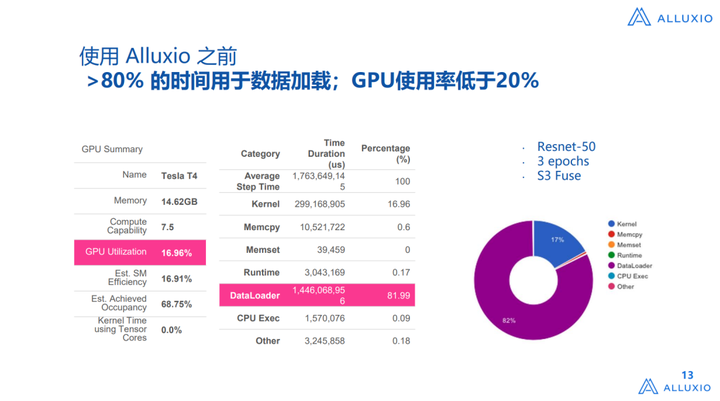
这个是我们从tensor board中拉下来的数据,相信很多做AI Infra的工程师都会用这个系统。我们发现其实在云上有一个比较大的问题,比如我们用S3 Fuse,就可以直接到S3 Fuse拉取,这是过去几年的常见用法,比如本地有一个磁盘,把这个数据拉取回来向上进行模型训练,要么进行一个拷贝任务放在本地,或者是用一个类似Fuse接口的暴露,把数据拉到本地,然后再向上提供服务,如果用这种方式来做,DataLoader的占比是非常高的,如果对AI这套架构比较了解,他的DataLoader是这么来做的,从存储系统中把数据拉到CPU memory,CPU进行prepsacing或者resacing处理,然后把数据放到CPU Memory后GPU再进行处理,在云上大家后面两个还行,因为一般CPU和GPU的配比是比较合理的,然后Memory的配比也是比较合理的,问题就会比较小,但是基于原来是在云存储中,存在向CPU中拉取的问题,导致在DataLoader的第一个阶段中性能是非常差的,虽然是个异步的过程,但是性能需要等待前步完成才行,因为可以看到这个DataLoader比例可以占到80%多,GPU使用率才在17%左右,这是用Resnt-50——一个非常标准的benchmark来测的。

我们把Alluxio部署上以后,DataLoader的时间是降到了1%以下,GPU的利用率提高到了93%,当然不是说不能更高,但其实GPU的利用率一方面是受限于IO,另一方面还受限于CPU的性能,所以这是非常高的利用率了。

此外,最近我们在AI场景下也推出了一些项目,包括这个《Alluxio助力模型训练计划》,其实现在很多大模型已经运行在Alluxio之上,把Alluxio作为一个高性能数据接入层来用,我们在2023年7月1日-9月30日期间也会开放给大家一个报名计划,可以有3个月专业团队1V1的技术支持,帮助大家构建大模型训练或者是比较流行的动模态的训练场景。
关于作者

想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点击进入【Alluxio智库】:

相关文章:
实录分享 | Alluxio在AI/ML场景下的应用
欢迎来到【微直播间】,2min纵览大咖观点 本次分享主要包括五个方面: 关于Alluxio;盘点企业在尝试AI时面临的挑战;Alluxio在技术栈中的位置;Alluxio在模型训练&模型上线场景的应用;效果对比࿱…...

Streamlit 讲解专栏(十二):数据可视化-图表绘制详解(下)
文章目录 1 前言2 使用st.vega_lite_chart绘制Vega-Lite图表2.1 示例1:绘制散点图2.2 示例2:自定义主题样式 3 使用st.plotly_chart函数创建Plotly图表3.1 st.plotly_chart函数的基本用法3.2 st.plotly_chart 函数的更多用法 4 Streamlit 与 Bokeh 结合进…...
Dockerfile 使用教程
1.Dockerfile 1.1 什么是Dockerfile Dockerfile可以认为是 Docker镜像的描述文件,是由一系列命令和参数构成的脚本 。主要作用是 用来构建docker镜像的构建文件 。 通过架构图可以看出通过DockerFile可以直接构建镜像 1.2 Dockerfile解析过程 构建镜像步骤…...
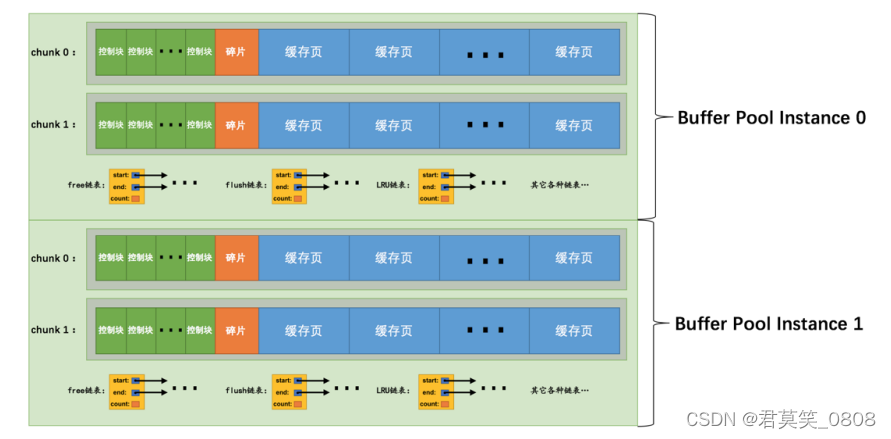
InnoDB的Buffer
一、Buffer内存结构 MySQL 服务器启动的时候就向操作系统申请了一片连续的内存,默认128M,可通过从参数修改。 [server] innodb_buffer_pool_size 268435456 1.1 控制块 控制块包括该页所属的 表空间编号、页号、缓存页在 Buffer Pool 中的地址、链表…...

普洛斯常熟东南数据中心获LEED金级认证及IDCC绿色算力基础设施奖
近日,普洛斯常熟东南数据中心获得美国绿色建筑评估标准体系LEED v4 BDC(建筑设计与建造)金级认证,并获评IDCC2023长三角区域绿色算力基础设施奖。以可持续发展理念为核心,该数据中心从设计规划、开发建设,到…...

RabbitMQ 启动及参数说明
/usr/local/lib/erlang/erts-10.4/bin/beam.smp -W w -A 128 -MBas ageffcbf -MHas ageffcbf -MBlmbcs 512 -MHlmbcs 512 -MMmcs 30 -P 1048576 -t 5000000 -stbt db -zdbbl 128000 -K true – -root /usr/local/lib/erlang -progname erl – -home /var/lib/rabbitmq – -pa /…...

Vite打包性能优化及填坑
最近在使用 Vite4.0 构建一个中型前端项目的过程中,遇到了一些坑,也做了一些项目在构建生产环境时的优化,在这里做一个记录,以便后期查阅。(完整配置在后面) 上面是dist文件夹的截图,里面的内容已经有30mb了ÿ…...
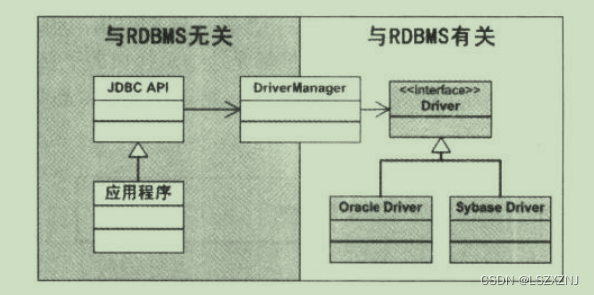
JDBC使用了哪种设计模式
JDK中提供了操作数据库的接口,比如 java.sql.Driver java.sql.Connection java.sql.Statement java.sql.PreparedStatement 不同的数据库厂商提供操作自己数据库的驱动包, 比如mysql public class Driver extends NonRegisteringDriver implements jav…...
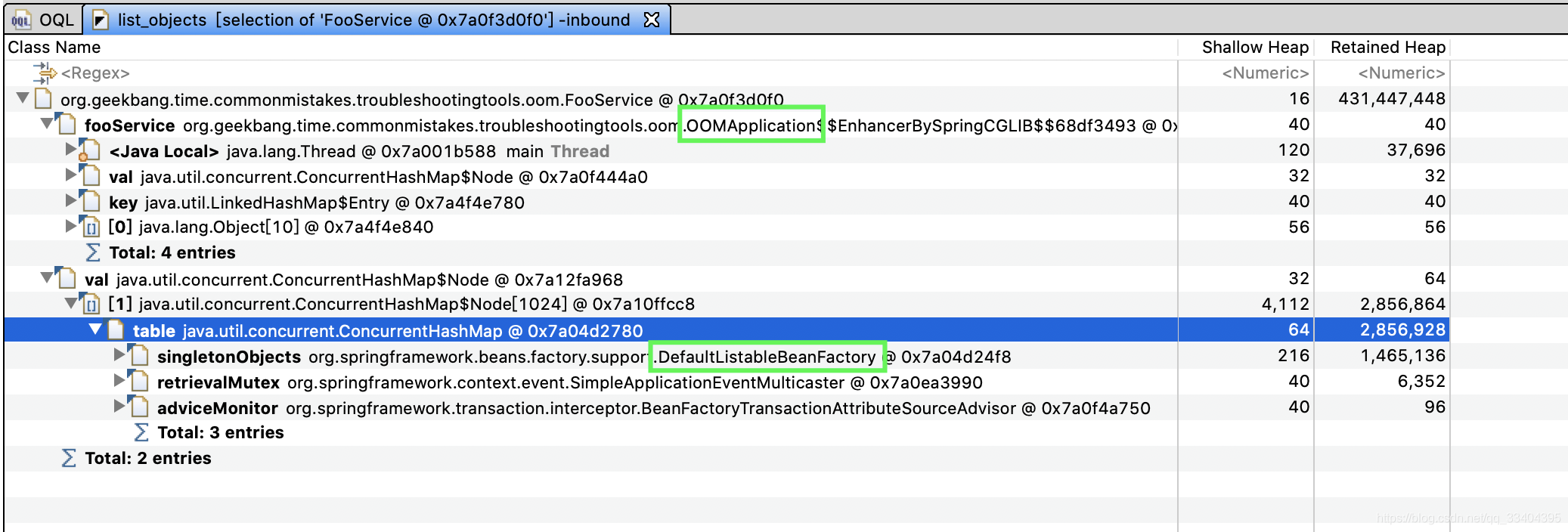
JVM-性能优化工具 MAT
一、MAT下载和安装 1、概述 MAT(Memory Analyzer Tool)工具是一款功能强大的]ava堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况。MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用…...

Python Flask flasgger api文档[python/flask/flasgger]
首先需要安装依赖: pip install flasgger封装swagger.py文件,代码如下: from flasgger import Swagger swagger Swagger() 然后在主应用中(项目入口文件)加入以下代码: from flask import Flask from …...
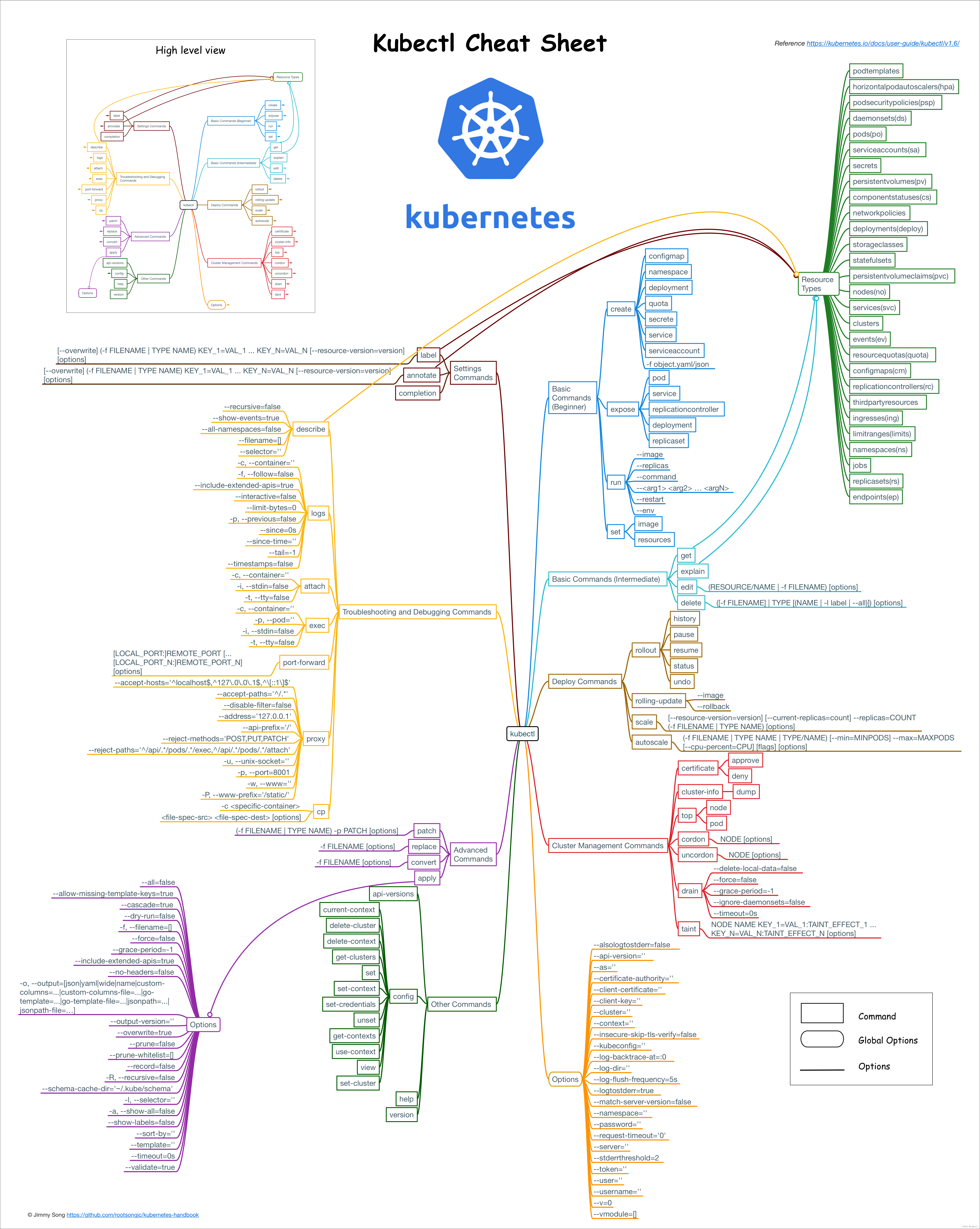
k8s常见命令
基础知识 1,deployment和pod关系 一个pod里面好几个container,deployment是针对这个pod的配置文件,比如设置这个pod有几个副本 2,ip地址 node有ip,pod也有ip。 node的ip用于集群内部和外部访问,pod用于…...

Unity3d C#实现调取网络时间限制程序的体验时长的功能
前言 如题的需求应该经常在开发被提到,例如给客户体验3–5天的程序,到期后使其不可使用,或者几年的使用期限。这个功能常常需要使用到usb加密狗来限制,当然这也的话就需要一定的硬件投入。很多临时提供的版本基本是要求软件来实现…...
常静相伴:深度解析C++中的const与static关键字
个人主页:北海 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:C/C🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!ǹ…...
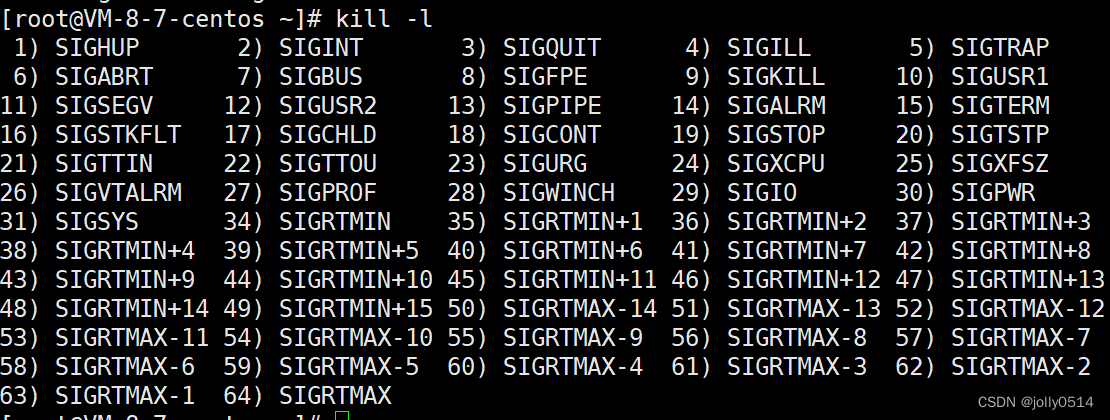
Linux入门之进程信号|信号产生的方式
文章目录 一、信号入门 1.linux信号的基本概念 2.使用kill -l 命令可以查看系统定义的信号列表 3.信号处理常见方式 二、产生信号 1.通过终端按键产生信号 2.通过调用系统函数向进程发信号 3.由软条件产生信号 4.硬件异常产生信号 1. /0异常 2.模拟野指针 一、信号入门…...
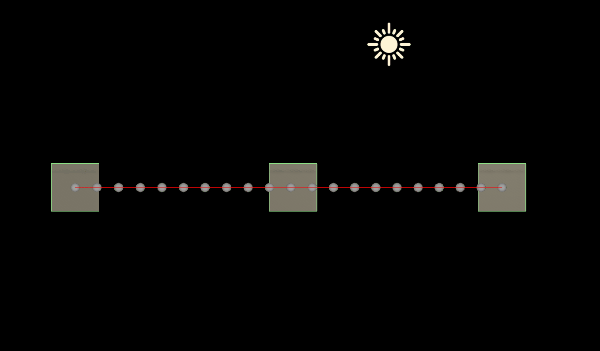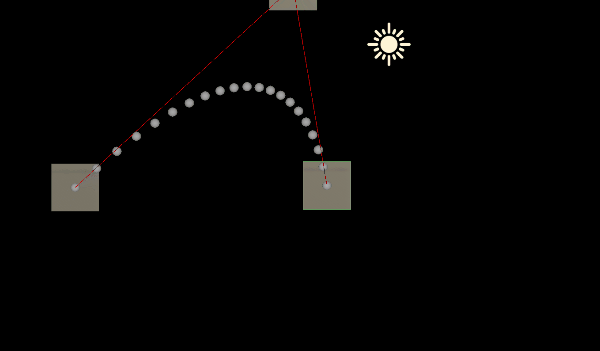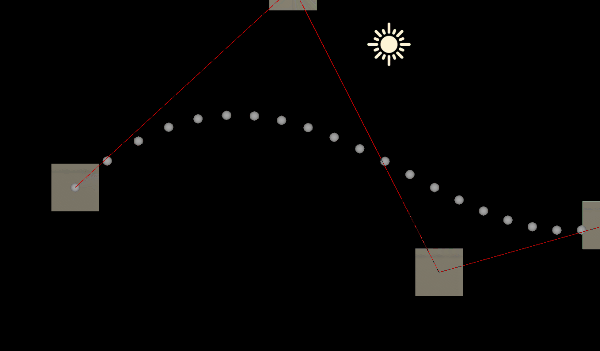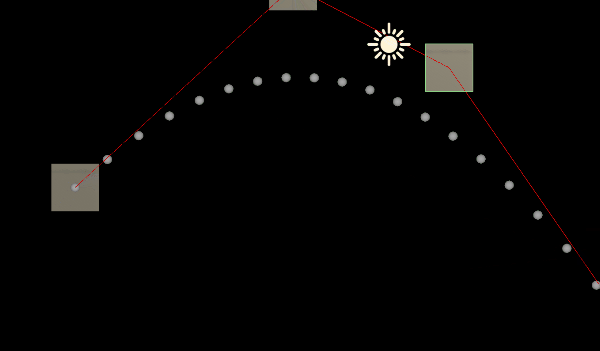
Unity中的数学基础——贝塞尔曲线
一:前言 一条贝塞尔曲线是由一组定义的控制点P0到 Pn,n1为线性,n2为二次......第一个和最后一个控制点称为起点和终点,中间的控制点一般不会位于曲线上 获取两个点之间的点就是通过线性插值( Mathf.Lerp)…...

大数据平台安全主要是指什么安全?如何保障?
大数据时代已经来临,各种数据充斥着我们的生活与工作。随着数据的多样性以及复杂性以及大量性,大数据平台诞生了。但对于大数据平台大家都不是很了解,有人问大数据平台安全主要是指什么安全?如何保障? 大数据平台安全…...
Flutter的未来与趋势,23年还学吗?
随着移动应用市场的不断扩大,跨平台开发框架的需求也越来越大。Flutter框架可以帮助开发者在不同平台上快速开发高质量的移动应用程序,这种趋势将进一步推动Flutter的发展和普及。 作为一名前端开发工程师,学习Flutter框架是非常有必要的。因…...
RHCE——十三、Shell自动化运维编程基础
Shell 一、为什么学习和使用Shell编程二、Shell是什么1、shell起源2、查看当前系统支持的shell3、查看当前系统默认shell4、Shell 概念 三、Shell 程序设计语言1、Shell 也是一种脚本语言2、用途 四、如何学好shell1、熟练掌握shell编程基础知识2、建议 五、Shell脚本的基本元素…...

深入理解AMBA总线协议(AXI总结篇)
AXI总线已经是AMBA总线中最常见,使用最频繁的总线,并且没有之一。 可以说AXI总线已经成为了片上总线中最重要的协议,本篇文章打算花一些篇幅,帮大家总结一下AXI总线的学习重点、学习难点,以帮助大家更好更快的掌握AXI…...
)
建立无需build的react单页面应用SPA框架(2)
react-18.1.0,rc-easyui-1.2.9,babel-7.17.11 SPA还要处理的问题: (一)tabs切换事件通知 tabs切换时,自己的框架需要处理组件的生命周期,要有active/deactive,让组件能知道何时创…...

RAG架构全解析:从基础到高级,打造你的企业级知识库问答系统!
本文详细介绍了RAG(Retrieval-Augmented Generation)架构的多种变体,从基础的Naive RAG和Standard RAG开始,逐步深入到Advanced RAG、Hybrid Search RAG、Rerank型RAG、文档增强型RAG、Agentic RAG、Router RAG、GraphRAG、RAPTOR…...

奇迹 MU 荣耀出征 新区开区 最新地址官方正版下载
《奇迹 MU 荣耀出征》是正版授权的复古魔幻 MMORPG 手游,完美复刻端游 1.03H 黄金版本核心玩法,逐光娱手游官网https://www.gw648.com提供官方正规下载渠道,带你重回艾瑞西亚大陆,再续荣耀传奇。 官方正版下载渠道 《奇迹 MU 荣耀…...

大模型实战:AgentScope ReActAgent 多智能体框架实战指南,小白程序员必备收藏!
本文介绍了如何利用 AgentScope 框架及其新版本 Spring AI Alibaba 来构建基于大模型的多智能体应用。文章首先强调了从单智能体优先原则出发,然后详细阐述了 AgentScope 支持的多智能体模式,包括 Pipeline、Routing、Skills、Subagents、Supervisor、Ha…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...

【大模型12步学习路线 · 第12步 · ③IC验证实战篇】Veri-Copilot v1.0 大结局:多模态 RAG 让 LLM “看懂“ Spec 时序图
【大模型12步学习路线 第12步 ③IC验证实战篇】Veri-Copilot v1.0 大结局:多模态 RAG 让 LLM “看懂” Spec 时序图,DATE 2027 投稿前 checklist + 12 步系列收官 系列定位:「大模型正确学习顺序」12 步系列 第 12 步 多模态 的 ③IC 验证实战篇,也是整个 36 篇系列的最后一…...

深入解析Android进程与线程间通信机制:原理、实践与优化
引言 在Android开发中,进程与线程间通信(IPC)是构建高性能、高稳定性应用的核心技术。无论是多进程协作(如系统服务、插件化框架)还是多线程并发(如UI线程与后台任务),高效的通信机制直接决定了应用的流畅性与资源利用率。本文将围绕Binder机制、Handler机制、共享内存…...

全球化2.0 | ZStack亮相印尼云计算与数据中心大会 以新一代云底座助力数字印尼建设
近日,由 W.Media 主办的印尼云计算和数据中心大会(Indonesia Cloud & Data Center Convention 2026)在雅加达举行。云轴科技 ZStack受邀参会,与来自印尼及国际数据中心行业的专业人士共同探讨企业云底座的最新进展与未来趋势。…...

CG-75B 七参数微型气象传感器 超声波测量原理 集成 一体化
产品概述七参数微型气象传感器是一款利用发送的声波脉冲,基于超声波原理研发的风速风向测量仪器,测量接收端的时间或频率(多普勒变换)差别来计算风速和风向。该传感器可以同时测量风速,风向的瞬时数值,支持…...

如何用Python快速接入Taotoken平台调用多款大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多款大模型 对于希望便捷使用多种大语言模型的开发者而言,逐一对接不同厂商的AP…...

如何快速掌握uesave:Unreal引擎存档编辑的完整指南
如何快速掌握uesave:Unreal引擎存档编辑的完整指南 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave uesave是一款专门用于处理Unreal引擎游戏存档文件的开源…...