Python 之 Pandas DataFrame 数据类型的行操作和常用属性和方法汇总
文章目录
- 一、DataFrame 行操作
- 1. 标签选取
- 2. 数值型索引和切片
- 3. 切片操作多行选取
- 4. 添加数据行
- 4.1 追加字典
- 4.2 追加列表
- 5. 删除数据行
- 二、常用属性和方法汇总
- 1. 转置
- 2. axes
- 3. dtypes
- 4. empty
- 5. columns
- 6. shape
- 7. values
- 8. head() & tail()
- 9. 修改列名 rename()
- 10. info() 函数
- 11. df. sort_index() 函数
- 12. df.sort_values() 函数
- DataFrame 是 Pandas 的重要数据结构之一,也是在使用 Pandas 进行数据分析过程中最常用的结构之一,可以这么说,掌握了 DataFrame 的用法,你就拥有了学习数据分析的基本能力。
- 在开始之前,我们需要先引入 numpy 和 pandas 库。
import numpy as np
import pandas as pd
一、DataFrame 行操作
- 在我们理解了前文的列索引操作后,行索引操作就变的简单。
- 具体列索引操作详见 Python 之 Pandas DataFrame 数据类型的简介、创建的列操作。
1. 标签选取
- 行操作需要借助 loc 属性来完成:按标签或布尔数组访问一组行和列。
- 首先,我们定义一个字典,作为初始数据,创建 DataFrame 数据结构。
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print("===========df原始数据========")
print(df)
#===========df原始数据========
# one two
# a 1.0 1
# b 2.0 2
# c 3.0 3
# d NaN 4
- 然后,我们确定标签为 b 的数据。
print("===========标签为b的数据========")
print(df.loc['b'])
#===========标签为b的数据========
#one 2.0
#two 2.0
#Name: b, dtype: float64
- 这里需要注意的是,loc 允许接受两个参数分别是行和列。
- 例如,我们选取 b 行 one 列交叉的数据。
df.loc['b',"one"]
#2.0
- 除此之外,行和列还可以使用切片。
- 例如,标签为 b 的行到标签为 d 的行, 对应标签为 one 的列。
- 这里需要注意的是,使用行标签切片,是包含结束的行。
df.loc['b':'d',"one"] # 注意
#b 2.0
#c 3.0
#d NaN
#Name: one, dtype: float64
- 用过 loc 索引的行和列与 numpy 整数数组索引的区别如下,loc 是通过标签进行取值,他有两个参数,第一个代表行,第二个代表列。
df.loc[['a','b'],["one","two"]]
# one two
#a 1.0 1
#b 2.0 2
- 我们可以通过 np.arange( ).reshape( ) 生成一个从 0 到 1 的三行四列的指定元素数组,然后调用其中第一行和第一列,第三行和第四列分别相交的数据。
s = np.arange(12).reshape((3,4))
s
#array([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
s[[0,2],[0,3]]
#array([ 0, 11])
2. 数值型索引和切片
- 使用数据型索引,需要使用 iloc 属性。
- 直接使用索引,会优先查找的是列标签,如果找不到会报错,列没有位置索引。
- 可以使用 iloc,行基于整数位置的按位置选择索引。
- 例如,我们指定 data 数据,然后定义行标签,通过字典创建 DataFrame。
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
index = ["rank1", "rank2", "rank3", "rank4"]
df = pd.DataFrame(data, index=index)
df
# Name Age
#rank1 关羽 28
#rank2 刘备 34
#rank3 张飞 29
#rank4 曹操 42
- 然后,我们取得位置索引为 2 的数据。
df.iloc[2]
#Name 张飞
#Age 29
#Name: rank3, dtype: object
- 我们也可以同时取得位置索引分别为 0 和 2 的数据。
df.iloc[[0,2]]
Name Age
rank1 关羽 28
rank3 张飞 29
- 我们也可以选择行索引为 0,列索引为 1 的数据。
df.iloc[0,1]
#28
- 这里需要注意的是,loc 使用的是标签索引,iloc 使用的是位置索引,两者不能混用,比如在 loc 中使用位置索引,或者在 iloc 中使用标签索引。
- 常见有如下的错误写法:loc 当中使用了 1 这个位置索引,iloc 当中使用了 Name 这个标签索引。
#df.loc[1,"Name"]
#df.iloc[1,"Name"]
3. 切片操作多行选取
- 可以直接使用数值型切片操作行,和使用 iloc 同样的结果。
- 例如,我们指定 data 数据,然后定义行标签,通过字典创建 DataFrame。
data = {'Name':['关羽', '刘备', '张飞', '曹操'],'Age':[28,34,29,42]}
index = ["rank1", "rank2", "rank3", "rank4"]
df = pd.DataFrame(data, index=index)
df
# Name Age
#rank1 关羽 28
#rank2 刘备 34
#rank3 张飞 29
#rank4 曹操 42
- 然后,我们取得取得位置索引从 1 到 3 的行,但是不包含第 3 行的数据。
print("=====df.iloc[1:3]:=======")
print(df.iloc[1:3])
#=====df.iloc[1:3]:=======
# Name Age
#rank2 刘备 34
#rank3 张飞 29
- 我们使用切片可以直接提取行。
print("=====df[1:3]:=======")
print(df[1:3])
#=====df[1:3]:=======
# Name Age
#rank2 刘备 34
#rank3 张飞 29
4. 添加数据行
- 使用 append() 函数,可以将新的数据行添加到 DataFrame 中,该函数会在行末追加数据行.
- 其语法模板如下:
df.append(other, ignore_index=False, verify_integrity=False, sort=False)
- 将 other 追加到调用者的末尾,返回一个新对象。other 行中不在调用者中的列将作为新列添加。
- 其参数含义如下:
- other 表示 DataFrame 或 Series/dict 类对象,或这些对象的列表。
- ignore_index 默认为 False,如果为 True 将不适用 index 标签。
- verify_integrity 默认为 False ,如果为 True,则在创建具有重复项的索引时引发 ValueError。
- sort 表示排序。
- 例如,我们可以生成一个指定数据的数组,并于后续的操作观察。
data = {'Name':['关羽', '刘备', '张飞', '曹操'], 'Age':[28, 34, 29, 42],"Salary":[5000, 8000, 4500, 10000]}
df = pd.DataFrame(data)
df
# Name Age Salary
# 0 关羽 28 5000
# 1 刘备 34 8000
# 2 张飞 29 4500
# 3 曹操 42 10000
4.1 追加字典
- 我们在行末新加一个数据行,此时,我们需要添加 ignore_index=True,否则会报错。例如下述操作。
d2 = {"Name":"诸葛亮", "Age":30}
df3 = df.append(d2)
print(df3)
- 错误提示:Can only append a Series if ignore_index=True or if the Series has a name。
- 这是因为仅当 ignore_index=True 或序列有名称时,才能追加序列。
d2 = {"Name":"诸葛亮", "Age":30}
df3 = df.append(d2, ignore_index=True) # 需要添加
print(df3)
# Name Age Salary
#0 关羽 28 5000.0
#1 刘备 34 8000.0
#2 张飞 29 4500.0
#3 曹操 42 10000.0
#4 诸葛亮 30 NaN
- 或者 Series 数据当中有 name。
d2 = {"Name":"诸葛亮", "Age":30}
s = pd.Series(d2, name="a")
print(s)
df3 = df.append(s)
print(df3)
#Name 诸葛亮
#Age 30
#Name: a, dtype: object
# Name Age Salary
#0 关羽 28 5000.0
#1 刘备 34 8000.0
#2 张飞 29 4500.0
#3 曹操 42 10000.0
#a 诸葛亮 30 NaN
4.2 追加列表
- 如果 list 是一维的,则以列的形式追加。
- 如果 list 是二维的,则以行的形式追加。
- 如果 list 是三维的,只添加一个值。
- 这里需要注意的是,使用 append 可能会出现相同的 index,想避免的话,可以使用 ignore_index=True。
- 首先,我们生成输出数据数组,便于后续的观察操作。
data = [[1, 2, 3, 4],[5, 6, 7, 8]]
df = pd.DataFrame(data)
print(df)
# 0 1 2 3
#0 1 2 3 4
#1 5 6 7 8
- (1) 当 list 是一维的,则以列的形式追加。
a_l = [10,20]
df3 = df.append(a_l)
print(df3)
# 0 1 2 3
#0 1 2.0 3.0 4.0
#1 5 6.0 7.0 8.0
#0 10 NaN NaN NaN
#1 20 NaN NaN NaN
- (2) 当 list 是二维的,则以行的形式追加。
a_l = [[10,"20",30],[2,5,6]]
df4 = df.append(a_l)
print(df4)
# 0 1 2 3
#0 1 2 3 4.0
#1 5 6 7 8.0
#0 10 20 30 NaN
#1 2 5 6 NaN
- 此时,我们会发现行标签有点不太对,因此我们使用 ignore_index=True。
print("=========使用:ignore_index=True===========")
df5 = df.append(a_l,ignore_index=True) # 需要添加
print(df5)
#=========使用:ignore_index=True===========
# 0 1 2 3
#0 1 2 3 4.0
#1 5 6 7 8.0
#2 10 20 30 NaN
#3 2 5 6 NaN
- 在这里需要注意的是,append 不改变原数据,是生成一个新数据。
5. 删除数据行
- 可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。示例如下:
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print("=======源数据df=======")
print(df)
#=======源数据df=======
# a b
#0 1 2
#1 3 4
#0 5 6
#1 7 8
- 注意此处调用了 drop() 方法,drop 默认不会更改源数据,而是返回另一个dataframe来存放删除后的数据。
- (1) drop 函数默认删除行,列需要加 axis = 1。
- (2) 当 inplace 为 False 时不会修改源数据,为 True 时会修改源数据。
df1 = df.drop(0)
print("=======修改后数据df1=======")
print(df1)
=======修改后数据df1=======
# a b
#1 3 4
#1 7 8
二、常用属性和方法汇总
| 名称 | 属性&方法描述 |
|---|---|
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型。 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True |
| columns | 返回DataFrame所有列标签 |
| shape | 返回一个元组,获取行数和列数,表示了 DataFrame 维度。 |
| size | DataFrame中的元素数量。 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |
| rename() | rename(columns=字典) ,修改列名 |
| info() | 可以显示信息,例如行数/列数,总内存使用量,每列的数据类型以及不缺少值的元素数 |
| sort_index() | 默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。 |
| sort_values() | 既可以根据列数据,也可根据行数据排序 |
- 我们先生成一个初始数据数组,用以后续的观察操作。
data = {'Name':['关羽', '刘备', '张飞', '曹操'], 'Age':[28, 34, 29, 42],"Salary":[5000, 8000, 4500, 10000]}
df = pd.DataFrame(data)
df
# Name Age Salary
#0 关羽 28 5000
#1 刘备 34 8000
#2 张飞 29 4500
#3 曹操 42 10000
1. 转置
- 返回 DataFrame 的转置,也就是把行和列进行交换,但是源数据是不会发生任何变化的。
df.T0 1 2 3
Name 关羽 刘备 张飞 曹操
Age 28 34 29 42
Salary 5000 8000 4500 10000
2. axes
- 返回一个行标签、列标签组成的列表。
print(df.axes)
[df.index,df.columns]
#[RangeIndex(start=0, stop=4, step=1), Index(['Name', 'Age', 'Salary'], dtype='object')]
3. dtypes
- 返回 Series 每一列的数据类型。示例如下:
df.dtypes
Name object
Age int64
Salary int64
dtype: object
4. empty
- 返回一个布尔值,判断输出的数据对象是否为空,若为 True 表示对象为空。
df.empty
#False
- 我们创建一个空的 DataFrame。
empty_df = pd.DataFrame()
empty_df.empty
#True
- 如果给 DataFrame 数据类型直接判断真假,则会报错:
The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().。
5. columns
- 返回 DataFrame 所有列标签。
df.columns
#Index(['Name', 'Age', 'Salary'], dtype='object')
- 我们也可以通过 df.columns 的个数获取 DataFrame 当中列的个数。
len(df.columns)
#3
df.columns.size
#3
6. shape
- 返回一个元组,获取行数和列数,表示了 DataFrame 维度。
df.shape
#(4,3)
row_num,column_num = df.shape
print(row_num,column_num )
#4 3
7. values
- 以 ndarray 数组的形式返回 DataFrame 中的数据。
df.values
#array([['关羽', 28, 5000],
# ['刘备', 34, 8000],
# ['张飞', 29, 4500],
# ['曹操', 42, 10000]], dtype=object)
8. head() & tail()
- 我们可以使用 head() 获取前几行数据。
df.head(3)
# Name Age Salary
#0 关羽 28 5000
#1 刘备 34 8000
#2 张飞 29 4500
- 我们也可以使用 tail() 获取后几行数据。
df.tail(3)
# Name Age Salary
#1 刘备 34 8000
#2 张飞 29 4500
#3 曹操 42 10000
9. 修改列名 rename()
- 其语法模板如下:
DataFrame.rename(index=None, columns=None, inplace=False)
- 其参数含义如下:
- index 表示修改后的行标签。
- columns 表示修改后的列标签。
- inplace 表示默认为 False,不改变源数据,返回修改后的数据,True 更改源数据。
- 先输出原始数据,便于操作和观察。
df
# Name Age Salary
#0 关羽 28 5000
#1 刘备 34 8000
#2 张飞 29 4500
#3 曹操 42 10000
- 我们可以修改变量 df 的行标签。
df.rename(index={1:"row2", 2:"row3"})
df
# Name Age Salary
#0 关羽 28 5000
#row2 刘备 34 8000
#row3 张飞 29 4500
#3 曹操 42 10000
- 我们可以修改变量 df 的列标签。
df.rename(columns = {"Name":"name", "Age":"age"})
df
# name age Salary
#0 关羽 28 5000
#1 刘备 34 8000
#2 张飞 29 4500
#3 曹操 42 10000
- 如果我需要修改源数据的话,添加 inplace 参数。
df.rename(index={1:"row2", 2:"row3"}, columns = {"Name":"name", "Age":"age"}, inplace=True)
df
# name age Salary
#0 关羽 28 5000
#row2 刘备 34 8000
#row3 张飞 29 4500
#3 曹操 42 10000
10. info() 函数
- 用于打印 DataFrame 的简要摘要,显示有关 DataFrame 的信息,包括索引的数据类型 dtype 和列的数据类型 dtype,非空值的数量和内存使用情况。
- 首先,我们创建一组数据,将数据追加到 df 数据中。
data = {"name":"诸葛亮","age":30}
df = df.append(data, ignore_index =True)
df
# name age Salary
#0 关羽 28 5000.0
#1 刘备 34 8000.0
#2 张飞 29 4500.0
#3 曹操 42 10000.0
#4 诸葛亮 30 NaN
- 然后使用 info() 函数。
df.info()
#<class 'pandas.core.frame.DataFrame'>
#RangeIndex: 5 entries, 0 to 4
#Data columns (total 3 columns):
## Column Non-Null Count Dtype
#--- ------ -------------- -----
#0 name 5 non-null object
#1 age 5 non-null int64
#2 Salary 4 non-null float64
#dtypes: float64(1), int64(1), object(1)
#memory usage: 248.0+ bytes
- 我们来看一看都有些什么信息:
- (1) <class ‘pandas.core.frame.DataFrame’> 表示数据类型为 DataFrame。
- (2) RangeIndex: 5 entries, 0 to 4 表示有 5 条数据(也就是 5 行),索引为 0-4。
- (3) Data columns (total 3 columns) 表示该数据帧有 3 列。
- (4)# 表示索引号,不用太在意。
- (5) column 表示每列数据的列名。
- (6) Non-Null count 表示每列数据的数据个数,缺失值 NaN 不作计算。可以看出上面 Salary 列数据有缺失值。
- (7) Dtype 表示数据的类型。
- (8) dtypes 表示float64(1), int64(1), object(1): 数据类型的统计。
- (9) memory usage 表示 248.0+ bytes: 该数据帧占用的运行内存(RAM)。
11. df. sort_index() 函数
- 默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
- 其语法模板如下:
sort_index(axis=0, ascending=True, inplace=False)
- 其参数含义如下:
- axis:0 表示按照行名排序;1 表示按照列名排序。
- ascending:默认 True 升序排列;False 降序排列。
- inplace:默认 False,否则排序之后的数据直接替换原来的数据。
- 需要注意的是,df.sort_index() 可以完成和 df.sort_values() 完全相同的功能,但 python 更推荐用只用 df.sort_index() 对根据行标签和根据列标签排序,其他排序方式用 df.sort_values()。
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
df
# b a c
#2 1 4 1
#0 2 3 3
#1 2 2 8
#3 3 1 2
- 我们默认按行标签升序排序,或 df.sort_index(axis=0, ascending=True)。
df.sort_index()
# b a c
#0 2 3 3
#1 2 2 8
#2 1 4 1
#3 3 1 2
- 我们按列标签升序排序
df.sort_index(axis=1)
# a b c
#2 4 1 1
#0 3 2 3
#1 2 2 8
#3 1 3 2
12. df.sort_values() 函数
- 既可以根据列数据,也可根据行数据排序。
- 其语法模板如下:
DataFrame.sort_values(by, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')
- 其参数含义如下:
- by:str or list of str;如果 axis=0,那么 by=“列名”;如果 axis=1,那么 by=“行名”。
- axis:{0 or ‘index’, 1 or ‘columns’},default 0,默认按照列排序,即纵向排序;如果为 1,则是横向排序。
- ascending:布尔型,True 则升序,如果 by=[‘列名1’,‘列名2’],则该参数可以是 [True, False],即第一字段升序,第二个降序。
- inplace:布尔型,是否用排序后的数据框替换现有的数据框。
- na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
- 需要注意的是,必须指定 by 参数,即必须指定哪几行或哪几列;无法根据 index 名和 columns 名排序(由.sort_index()执行)。
- 我们先生成源数据。
df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
df
# b a c
#2 1 4 1
#0 2 3 3
#1 3 2 8
#3 2 1 2
- (1) 按 b 列升序排序。
- 等同于 df.sort_values(by=‘b’,axis=0)。
df.sort_values(by='b')
print(df)
# b a c
#2 1 4 1
#0 2 3 3
#3 2 1 2
#1 3 2 8
- (2) 先按 b 列降序,再按 a 列升序排序。
- 等同于 df.sort_values(by=[‘b’,‘a’],axis=0,ascending=[False,True])。
df.sort_values(by=['b','a'],ascending=[False,True])
print(df)
# b a c
#1 3 2 8
#3 2 1 2
#0 2 3 3
#2 1 4 1
- (3) 按行 3 升序排列。
df.sort_values(by=3,axis=1)
print(df)
# a b c
#2 4 1 1
#0 3 2 3
#1 2 3 8
#3 1 2 2
- (4) 按行 3 升序,行 0 降排列。
df.sort_values(by=[3,0],axis=1,ascending=[True,False])
print(df)
# a b c
#2 4 1 1
#0 3 3 2
#1 2 8 3
#3 1 2 2
- 需要注意的是,指定多列(多行)排序时,先按排在前面的列(行)排序,如果内部有相同数据,再对相同数据内部用下一个列(行)排序,以此类推。
- 如果内部无重复数据,则后续排列不执行。即首先满足排在前面的参数的排序,再排后面参数。
相关文章:

Python 之 Pandas DataFrame 数据类型的行操作和常用属性和方法汇总
文章目录一、DataFrame 行操作1. 标签选取2. 数值型索引和切片3. 切片操作多行选取4. 添加数据行4.1 追加字典4.2 追加列表5. 删除数据行二、常用属性和方法汇总1. 转置2. axes3. dtypes4. empty5. columns6. shape7. values8. head() & tail()9. 修改列名 rename()10. inf…...

MacOS下载钉钉直播回放视频的Python最新解决方案
tags: Python MacOS Tips 写在前面 之前写过一篇关于用Charles抓包下载钉钉直播回放视频的方法, 那会还是可以直接通过FFmpeg下载m3u8链接并且直接合并的, 但是现在直接上FFmpeg会出现403, 所以还是用别的方法来做吧. 后来发现抓包找到的m3u8不是加密视频流, 那就直接下载ts…...
2023年测试人跳槽新功略,涨薪10K+
软件测试是如何实现涨薪的呢?很多人眼中的软件测试岗位可能是简单的,技术含量不是那么高,就是看看需求、看业务、设计文档、然后点一点功能是否实现,再稍微深入一点就是测试下安装部署时会不会出现兼容性问题,以及易用…...
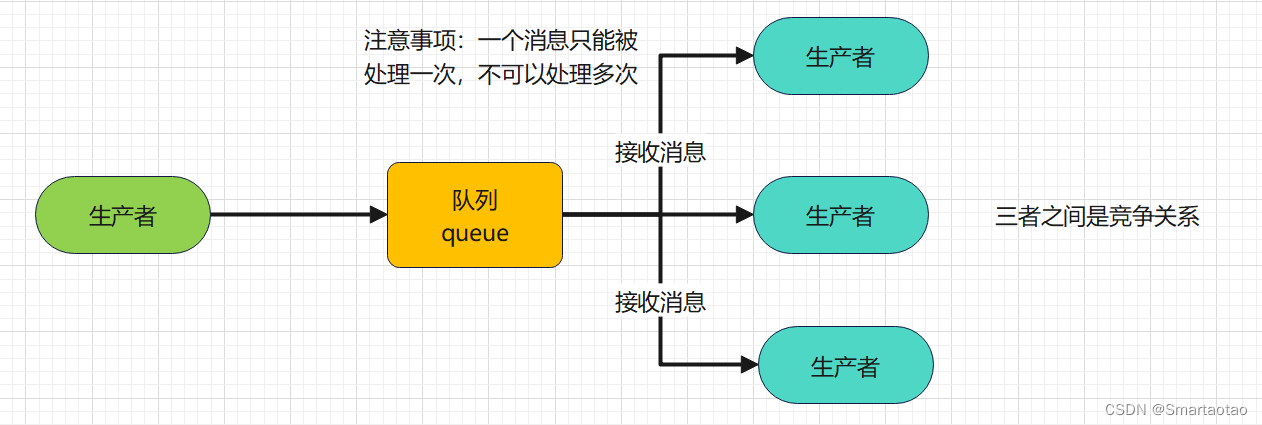
RabbitMQ之Work Queues
Work Queues 工作队列(又称任务队列)的主要思想是避免立即执行资源密集型任务,而不得不等待它完成。相反我们安排任务在之后执行。我们把任务封装为消息并将其发送到队列。在后台运行的工作进程将弹出任务并最终执行作业。当有多个工作线程时,这些工作线程将一起处理这些任务…...
CRM哪家好?这5个CRM管理系统很好用!
CRM哪家好?这5个CRM管理系统很好用! CRM(Customer Relationship Management)即客户关系管理,能够帮助提高客户的价值、满意度、赢利性和忠实度,缩减销售周期和销售成本、增加收入、寻找扩展业务所需的新的市场和渠道,…...

国内ce认证机构有哪些 国内十大CE认证机构排名 做ce认证的公司推荐
CE认证,是任何企业的任何产品走进欧盟市场的硬性要求。挑选CE认证机构,一定要认准拥有正规资质的机构/企业,例如中国质量认证中心CQC、CVC威凯、CTI华测检测,以及TV南德认证、安博检测、万泰认证等。本文中,MaiGoo小编…...

多If函数封装的策略
在工作中我们经常遇到有多个if的判读函数,这是一件很正常的事情,如下: let order function (orderType, isPay, count) {if (orderType 1) {// 充值 500if (isPay true) {// 充值成功console.log(中奖100元)} else {if (count > 0) {c…...

238. 银河英雄传说
Powered by:NEFU AB-IN Link 文章目录238. 银河英雄传说题意思路代码238. 银河英雄传说 题意 有一个划分为 N列的星际战场,各列依次编号为 1,2,…,N 有 N艘战舰,也依次编号为 1,2,…,N,其中第 i号战舰处于第 i列。 有 T条指令,每…...
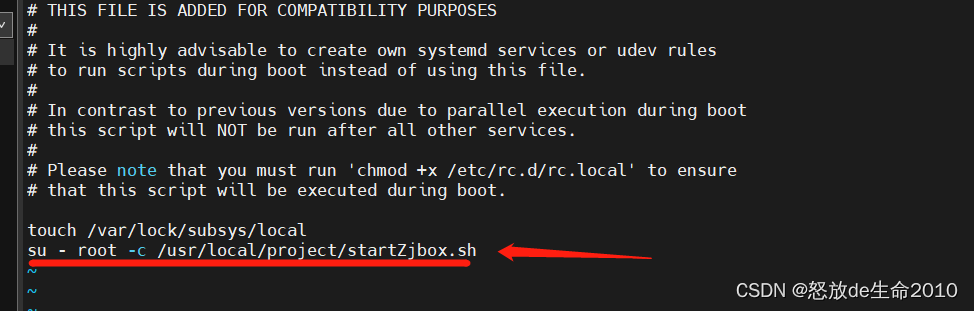
centos7 开机自启动自定义脚本
centos7 开机自启动自定义脚本背景配置自启动jar1.首先书写自启动脚本2.在rc.local中加入脚本reboot测试docker版本的自启动背景 项目中有遇到2个问题, 1: 使用java启动jar包 2: docker容器中自启动个服务。 这2个都要使用linux的开机自启动问…...
【Linux】动静态库的制作
🌠 作者:阿亮joy. 🎆专栏:《学会Linux》 🎇 座右铭:每个优秀的人都有一段沉默的时光,那段时光是付出了很多努力却得不到结果的日子,我们把它叫做扎根 目录👉动静库和静…...
数据备份学习笔记2
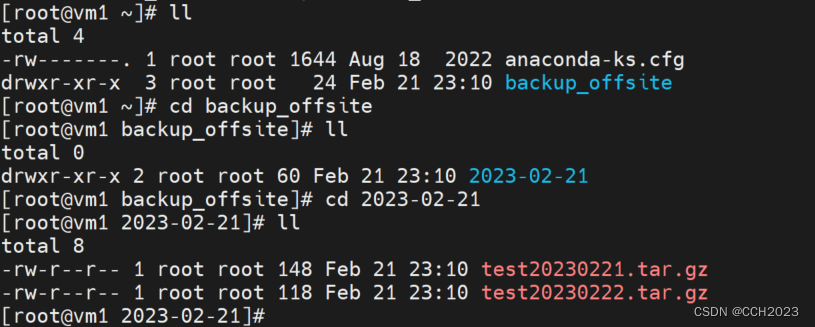
Linux实现本地备份的命令: mkdir -p /root/backup/date "%Y-%m-%d" tar -zcvPf /root/backup/date "%Y-%m-%d"/test20230221.tar.gz /root/test20230221/ 我们再看下tar命令选项: tar -czvf txt3.tar.gz txt3 tar -xvf txt4.tar.g…...

webRTC
WebRTC是一种实时通信技术,可以在浏览器中实现音频、视频和数据的实时传输。WebRTC使用标准的API和协议,如RTCPeerConnection和RTCDataChannel等,可以实现点对点通信和多方会议等多种应用场景。WebRTC可以应用于Web前端、移动端和桌面端等多种…...

用Python搓一个黑洞
文章目录简介单位制观测绘图简介 黑洞图像大家都知道,毕竟前几年刚发布的时候曾火遍全网,甚至都做成表情包了。 问题在于,凭什么认为这就是黑洞的照片,而不是一个甜甜圈啥的给整模糊了得到的呢?有什么理论依据吗&…...
Spring MVC常用功能及注解
目录 一、什么是Spring MVC 1.1 Spring MVC定义 1.2 MVC定义 1.3 MVC和Spring MVC的关系 1.4 Spring MVC的作用 二、Spring MVC的使用 2.1 Spring MVC的创建和连接 2.1.1 RequestMapping注解 2.1.2 GetMapping注解 2.1.3 PostMapping注解 2.2 获取参数 2.2.1 获取单…...

shell 编程
文章目录一、shell 编程1.1. 脚本执行1.2. 变量1.3. 特殊变量1.4. 运算符1.5. for 循环1.6. while 循环1.7. case 语句1.8. read 命令1.9. if 判断1.10. 判断语句1.11. 自定义函数1.12. 脚本调试二、sed2.1. sed 选项2.2. sed function2.3. sed 删除(d 命令…...
Leetcode.1401 圆和矩形是否有重叠
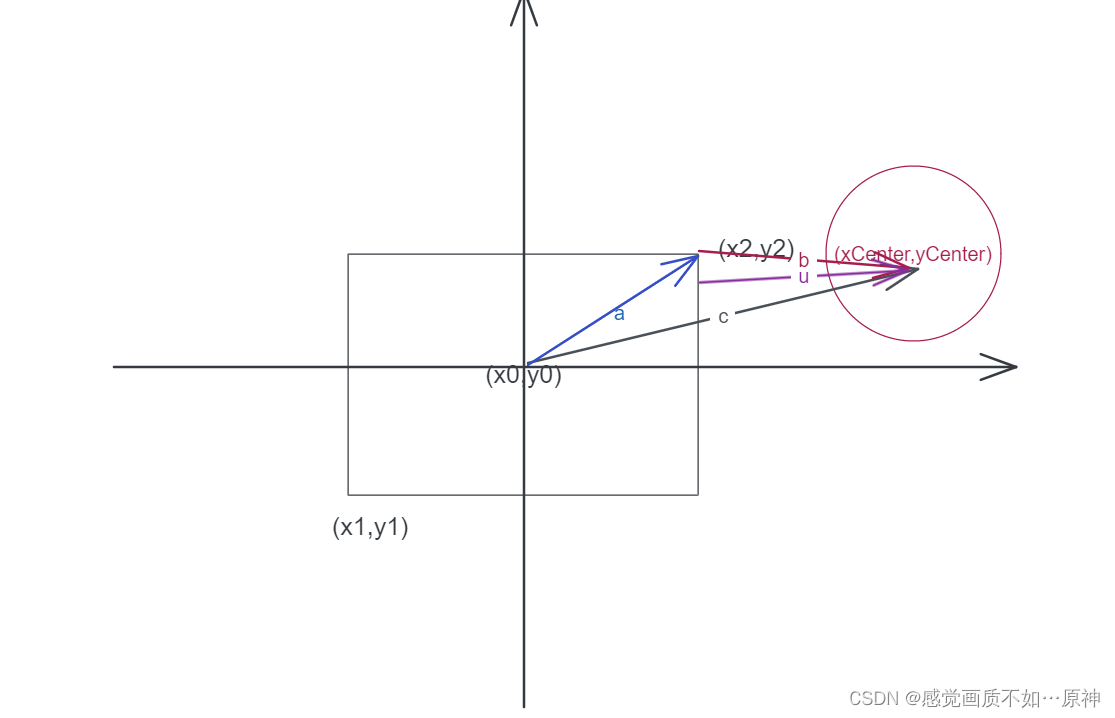
题目链接 Leetcode.1401 圆和矩形是否有重叠 Rating : 1709 题目描述 给你一个以 (radius, xCenter, yCenter)表示的圆和一个与坐标轴平行的矩形 (x1, y1, x2, y2),其中 (x1, y1)是矩形左下角的坐标,而 (x2, y2)是右上角的坐标。 如果圆和矩…...
CHAPTER 3 Web Server - httpd配置(二)
Web Server - httpd配置二3.1 httpd配置3.1.1 基于用户的访问控制3.1.2 basic认证配置示例:1. 添加用户2. 添加网页文件3. 定义安全域4. 修改父目录权限5. 访问效果6. 在配置文件中定义一个".htaccess"隐藏文件7. 添加组3.1.3 虚拟主机1. 构建方案2. 基于…...
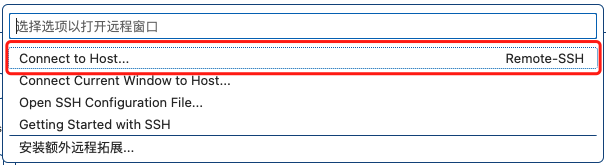
VSCode 连接 SSH 服务器
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/129133964 配置VSCode 下载VSCode:https://code.visualstudio.com/ 安装 Remote - SSH: 点击右下角蓝色图标: 连接服务器: 即可。 默认连接:ssh chen…...

如何选择靠谱的插画培训课程
如何选择靠谱的插画培训课程,今天教你3个维度选择一个靠谱的插画培训班! 插画培训机构课程: 1.选择插画培训班时,要先考察课程,看看课程内容是否符合自己的需求,是否有助于提高插画技术。课程设置应该灵活…...
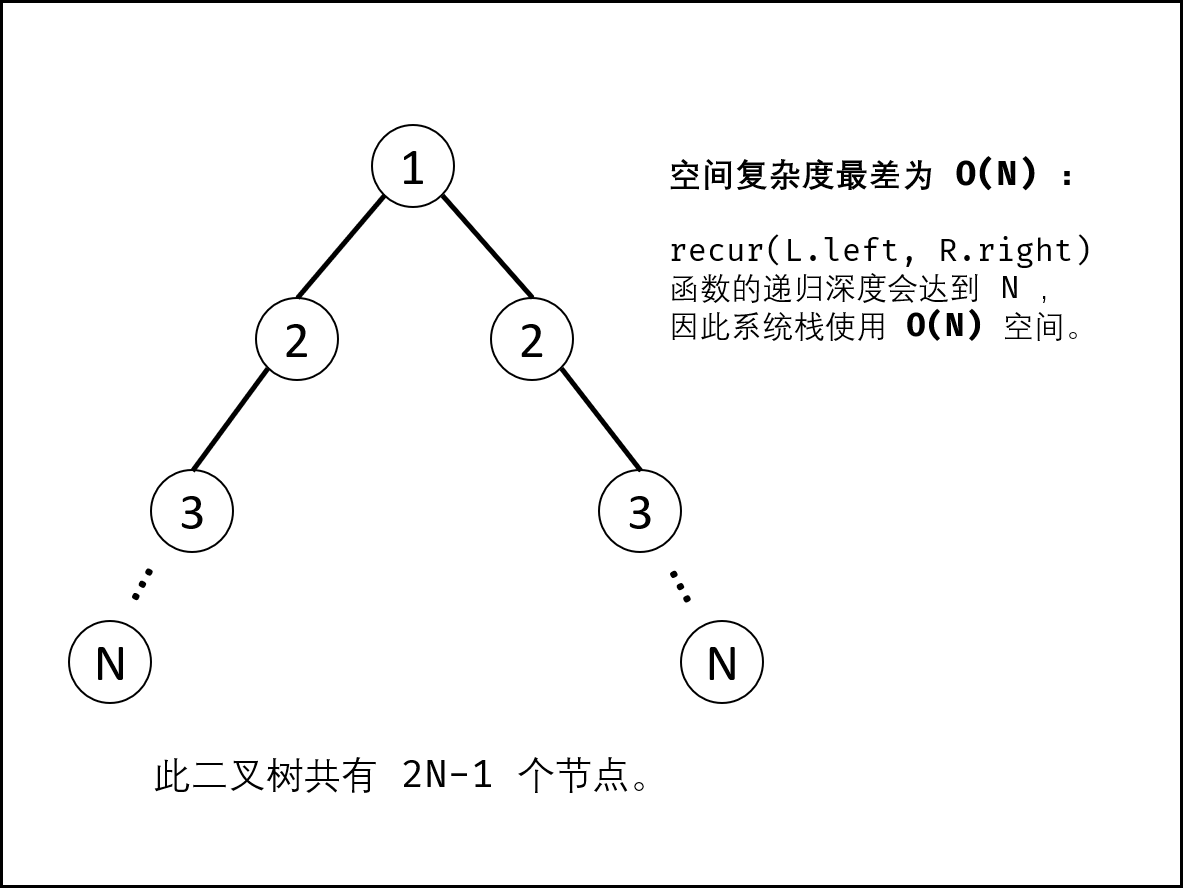
剑指 Offer 28. 对称的二叉树
剑指 Offer 28. 对称的二叉树 难度:easy\color{Green}{easy}easy 题目描述 请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。 例如,二叉树 [1,2,2,3,4,4,3] 是对称的。 但是下…...

AI智能体架构设计:从成本黑洞到价值引擎的解耦之道
1. 从成本黑洞到价值引擎:为什么你的AI智能体架构正在吞噬预算又到了季度技术复盘会,财务那边递过来的云账单和工程人力成本,是不是又让你倒吸一口凉气?你看着报表上那个名为“AI智能体平台”的项目,它的资源消耗曲线几…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳
D3KeyHelper:暗黑3玩家的智能按键助手,告别重复操作疲劳 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 你是否曾在《暗黑破坏…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...