卷积神经网络实现运动鞋识别 - P5
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:Pytorch实战 | 第P5周:运动鞋识别
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
- 环境设置
- 包引用
- 训练设备
- 数据准备
- 图像解压后的路径
- 打印图像的参数
- 展示图像
- 图像的预处理
- 创建数据集
- 获取数据集的分类
- 打乱数据的顺序,生成批次
- 模型设计
- 模型训练
- 训练函数
- 评估函数
- 循环迭代部分
- 模型效果展示
- 训练过程图表展示
- 载入最佳模式,随机选择图像进行预测
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim # 优化器
import torch.nn.functional as F # 可以静态调用的方法from torchvision import datasets, transforms # 数据集创建、数据预处理方法
from torch.utils.data import DataLoader # DataLoader可以将数据集封装成批次数据import matplotlib.pyplot as plt
import numpy as np
from PIL import Image # 加载图片预览使用的库
from torchinfo import summary # 可以打印模型实际运行时的图
import copy # 深拷贝使用的库
import pathlib, random # 文件夹遍历和随机数
训练设备
# 声明一个全局设备对象,方便后面将数据和模型拷贝到设备中
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
图像解压后的路径
train_path = 'train'
test_path = 'test'
打印图像的参数
train_pathlib = pathlib.Path(train_path)
train_image_list = list(train_pathlib.glob('*/*'))
for _ in range(5):print(np.array(Image.open(str(random.choice(train_image_list)))).shape)

重复执行了多次,返回结果都是(240, 240, 3),可以确定图像的大小统一为240,240,在数据加载的过程中可以不对图像做缩放处理。
展示图像
plt.figure(figsize=(20, 4))
for i in range(20):image = random.choice(train_image_list)plt.subplot(2, 10, i+1)plt.axis('off')plt.imshow(Image.open(str(image)))plt.title(image.parts[-2])

至此我们对数据集中的图像有了一个初步的了解。接下来就是准备训练数据。
图像的预处理
定义一些图像的预处理方法,例如将图像读取并转为pytorch的tensor对象,然后对图像的数值做归一化处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
创建数据集
train_dataset = datasets.ImageFolder(train_path, transform=transform)
test_dataset = datasets.ImageFolder(test_path, transform=transform)
获取数据集的分类
class_names = [key for key in train_dataset.class_to_idx]
print(class_names)
打乱数据的顺序,生成批次
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
使用3x3的卷积核,最大的通道数到256,每次卷积操作后,就紧跟一个池化层,一共使用了4个卷积层和4个池化层。最后使用了三层全连接网络来做分类器。
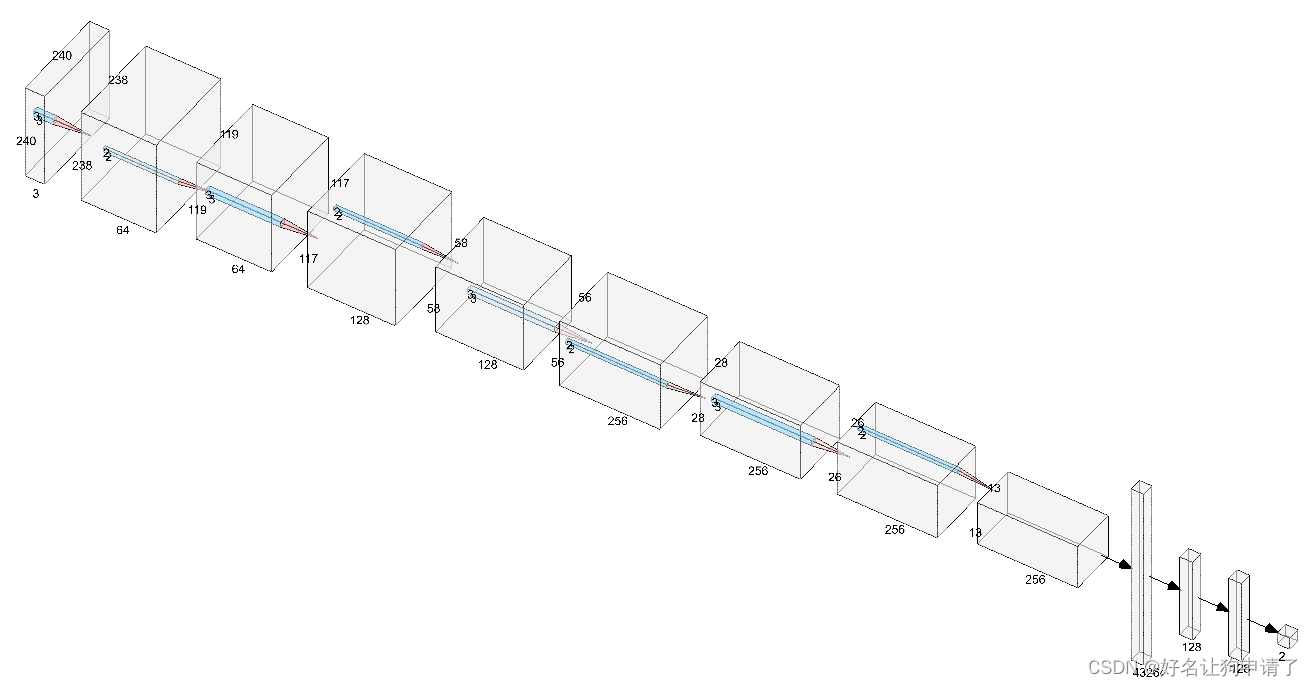
class Network(nn.Module):def __init__(self, num_classes):super().__init__()self.conv1 = nn.Conv2d(3, 64, 3)self.bn1 = nn.BatchNorm2d(64)self.conv2 = nn.Conv2d(64, 128, 3)self.bn2 = nn.BatchNorm2d(128)self.conv3 = nn.Conv2d(128, 256, 3)self.bn3 = nn.BatchNorm2d(256)self.conv4 = nn.Conv2d(256, 256, 3)self.bn4 = nn.BatchNorm2d(256)self.maxpool = nn.MaxPool2d(2)self.fc1 = nn.Linear(13*13*256, 128)self.fc2 = nn.Linear(128, 128)self.fc3 = nn.Linear(128, num_classes)self.dropout = nn.Dropout(0.5)def forward(self, x):# 240 -> 238x = F.relu(self.bn1(self.conv1(x)))# 238 -> 119x = self.maxpool(x)# 119 -> 117x = F.relu(self.bn2(self.conv2(x)))# 117 -> 58x = self.maxpool(x)# 58 -> 56x = F.relu(self.bn3(self.conv3(x)))# 56 -> 28x = self.maxpool(x)# 28 -> 26x = F.relu(self.bn4(self.conv4(x)))# 26 -> 13x = self.maxpool(x)x = x.view(x.size(0), -1)x = self.dropout(x)x = F.relu(self.dropout(self.fc1(x)))x = F.relu(self.dropout(self.fc2(x)))x = self.fc3(x)return x
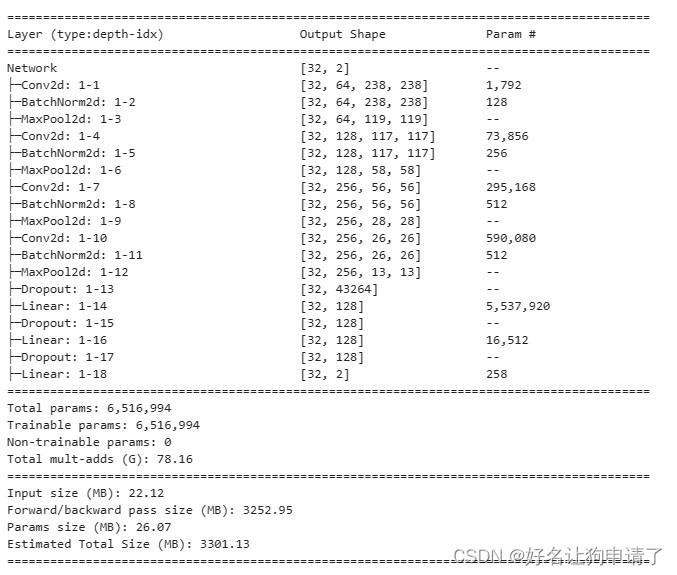
model = Network(len(class_names)).to(device)summary(model, input_size=(32, 3, 240, 240))
模型训练
模型训练过程中,每个epoch都会对全部的训练集进行一次完整的遍历,所以可以封装一些训练和评估方法,将业务逻辑和循环分开
训练函数
def train(train_loader, model, loss_fn, optimizer):size = len(train_loader.dataset)num_batches = len(train_loader)train_loss, train_acc = 0, 0for x, y in train_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss /= num_batchestrain_acc /= sizereturn train_loss, train_acc
评估函数
def test(test_loader, model, loss_fn):size = len(test_loader.dataset)num_batches = len(test_loader)test_loss, test_acc = 0, 0for x, y in test_loader:x, y = x.to(device), y.to(device)pred = model(x)loss = loss_fn(pred, y)test_loss += loss.item()test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batchestest_acc /= sizereturn test_loss, test_acc
循环迭代部分
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch:0.92**(epoch //2))
# 创建学习率的衰减
epochs = 50train_loss, train_acc = [], []
test_loss, test_acc = [], []
best_acc = 0
for epoch in range(epochs):model.train()epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)model.eval()with torch.no_grad():epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)scheduler.step() # 每次迭代调用一次,自动做学习率衰减# 如果当前评估的学习率更好,就保存当前模型if best_acc < epoch_test_acc:best_acc = epoch_test_accbest_model = copy.deepcopy(model)# 记录历史记录train_loss.append(epoch_train_loss)train_acc.append(epoch_train_acc)test_loss.append(epoch_test_loss)test_acc.append(epoch_test_acc)# 打印每个迭代的数据print(f"Epoch:{epoch+1}, TrainLoss: {epoch_train_loss:.3f}, TrainAcc: {epoch_train_acc*100:.1f}, TestLoss: {epoch_test_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}")# 打印本次训练的最佳正确率
print(f'training finished, best_acc is {best_acc*100:.1f}')# 将最佳模型保存到文件中
torch.save(model.state_dict(), 'best_model.pth')

模型效果展示
训练过程图表展示
画一个拆线图,观察训练过程中损失函数和正确率的变化趋势
plt.figure(figsize=(20,5))epoch_range = range(epochs)plt.subplot(1,2, 1)
plt.plot(epoch_range, train_loss, label='train loss')
plt.plot(epoch_range, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')plt.subplot(1,2,2)
plt.plot(epoch_range, train_acc, label='train accuracy')
plt.plot(epoch_range, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')
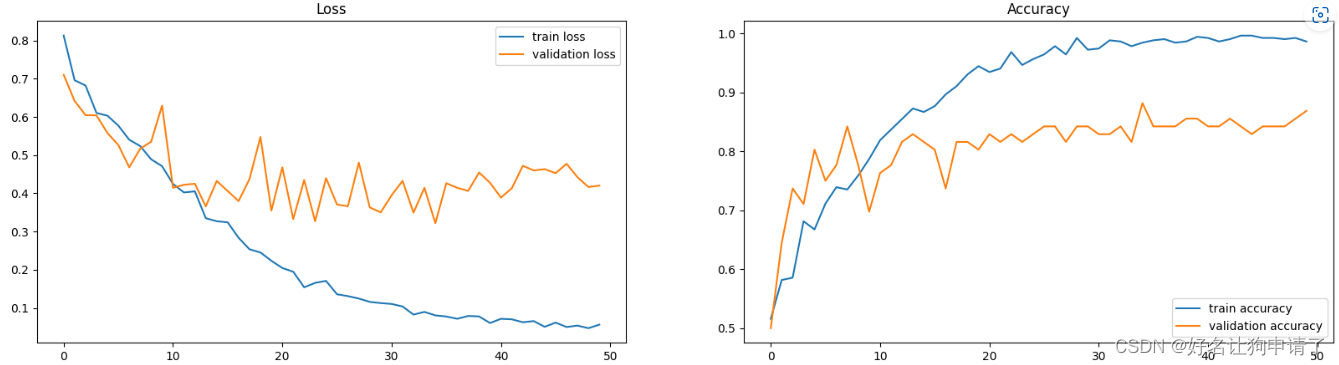
可以看出模型在最后基本已经收敛,最佳准确率是88.2%,满足了挑战任务。
载入最佳模式,随机选择图像进行预测
model.load_state_dict(torch.load('best_model.pth'))
model = model.to(device)test_pathlib = pathlib.Path(test_path)image_list = list(test_pathlib.glob('*/*'))image_path = random.choice(image_list)
image = transform(Image.open(str(image_path)))
image = image.unsqueeze(0)
image = image.to(device)pred = model(image)plt.figure(figsize=(5,5))
plt.axis('off')
plt.imshow(Image.open(str(image_path)))
plt.title(f'real: {image_path.parts[-2]}, predict: {class_names[pred.argmax(1).item()]}')

上次运行上面的预测任务,发现正确率还不错。
总结与心得体会
- 整个模型设计的思路其实是模仿了vgg16模型,在卷积层的数量和通道上做了简化。轻量级的任务可以首先试着减少池化层间的卷积次数,减少模型中最大的特征图的通道数
- 对图像的归一化操作很重要。在没有归一化前,模型的最佳正确率只能达到80%,推测可能是因为未做归一化的图像值域范围太大,不方便收敛,归一化后,原始图像中的输入特征值范围变成0~1,模型的权重变化更易作用到特征上。
相关文章:
卷积神经网络实现运动鞋识别 - P5
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍦 参考文章:Pytorch实战 | 第P5周:运动鞋识别🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录…...
C#安装“Windows 窗体应用(.NET Framework)”
目录 背景: 第一步: 第二步: 第三步: 总结: 背景: 如下图所示:在Visual Studio Installer创建新项目的时候,想要添加windows窗体应用程序,发现里面并没有找到Windows窗体应用(.NET Framework)模板,快捷搜索也没有发现&#…...
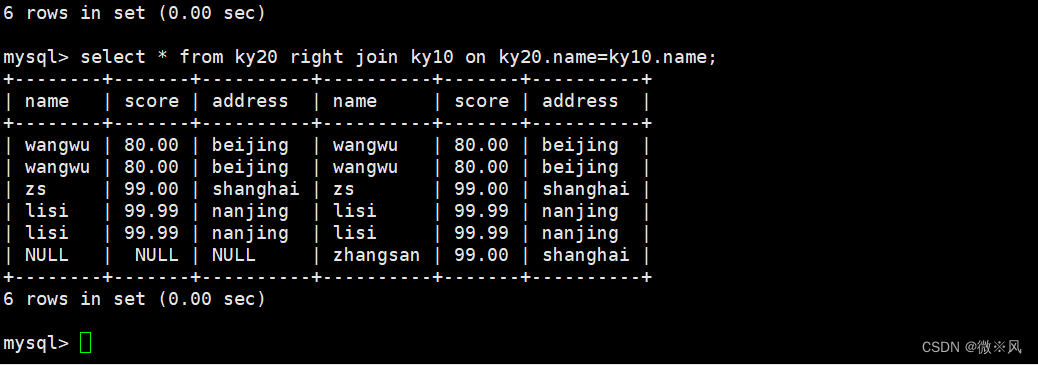
SQL高阶语句
目录 1、概念 1.1、概述 1.2、常见的MySQL高阶语句的概念: 1.3、 SQL高阶语句的作用 2、常用查询 2.1、按关键字排序 2.1.1、概述和作用 2.1.2、 (1)语法 2.1.3、模板表:ky30 编辑2.1.4、分数按降序排列 2.1.5、ORDER…...

【交换机】如何通过Web方式登陆交换机
一、华为交换机web登陆配置 Web网管是一种对交换机的管理方式,它利用交换机内置的Web服务器,为用户提供图形化的操作界面。用户可以从终端通过HTTPS登录到Web网管,对交换机进行管理和维护,同时也非常方便。 一、配置思路ÿ…...
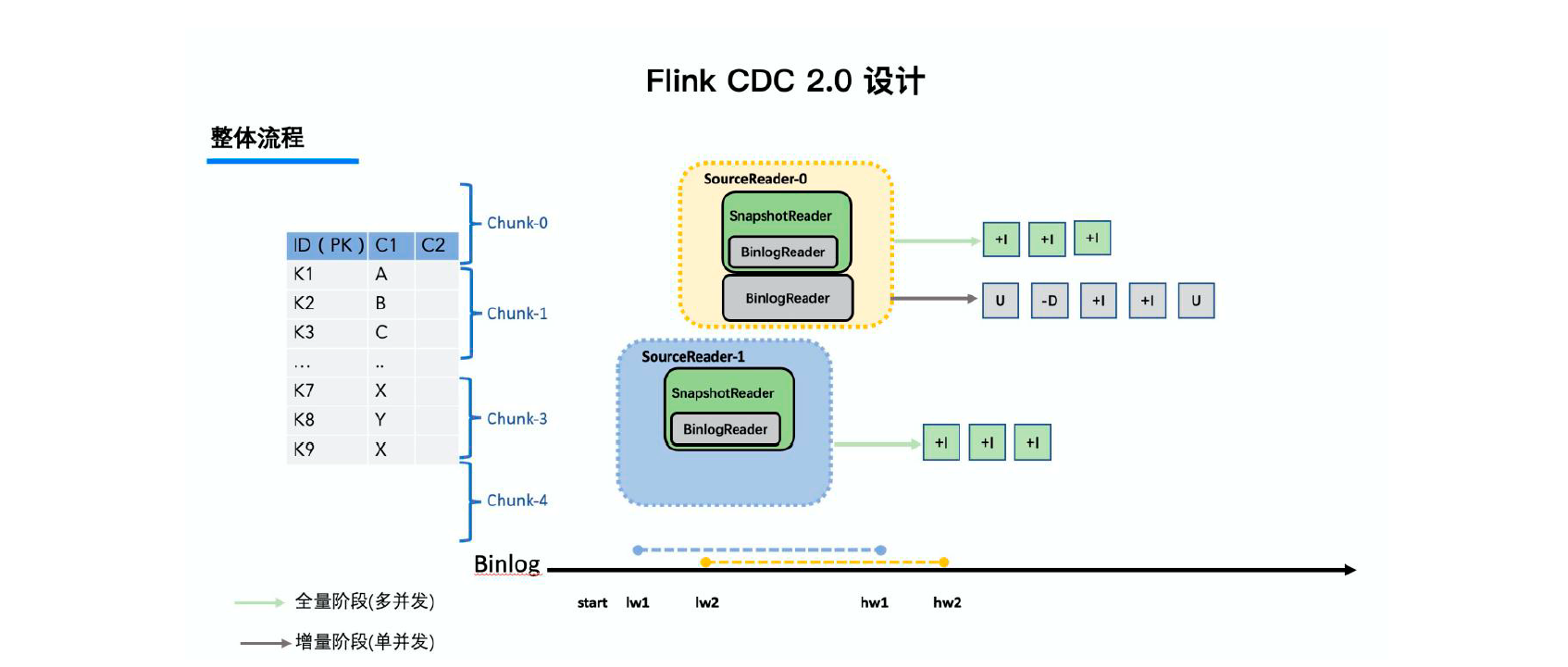
Flink CDC学习笔记
第一章 CDC简介 1.1 什么是CDC CDC (Change Data Capture 变更数据获取)的简称。核心思想就是,检测并获取数据库的变动(增删查改),将这些变更按发生的顺序记录下来,写入到消息中间件以供其它服务进行订…...

NEOVIM学习笔记
GitHub - blogercn/nvim-config: A pretty epic NeoVim setup 一直使用vim,每次到了新公司都要配置半天,而且常常配置失败,很多插件过期不好用。偶然看到别人的NEO VIM,就试着用了一下,感觉还不错。 用来开发和阅读C代…...

Docker三剑客之docker-compose
docker-compose 是 Docker 生态系统中的一个重要成员,它允许开发人员使用一个简单的配置文件来定义和运行多个 Docker 容器。通过 docker-compose,你可以定义应用程序的各个组件、容器之间的依赖关系以及网络配置,从而实现在一个命令中启动、…...

单调队列
目录 一,单调队列 二,模板实现 三,OJ实战 剑指 Offer 59 - I. 滑动窗口的最大值 一,单调队列 单调队列是双端队列的拓展,支持尾部插入,双端删除,其中的数据始终维持单调性,从而…...

effective c++ 笔记
TODO:还没看太懂的篇章 item25 item35 模板相关内容 文章目录 基础视C为一个语言联邦以const, enum, inline替换#define尽可能使用constconst成员函数 确定对象使用前已被初始化 构造、析构和赋值内含引用或常量成员的类的赋值操作需要自己重写不想使用自动生成的函…...

【送书活动】深入浅出SSD:固态存储核心技术、原理与实战
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 「推荐专栏」: ★java一站式服务 ★ ★ React从入门到精通★ ★前端炫酷代码分享 ★ ★ 从0到英雄,vue成神之路★ ★ uniapp-从构建到提升★ ★ 从0到英雄ÿ…...
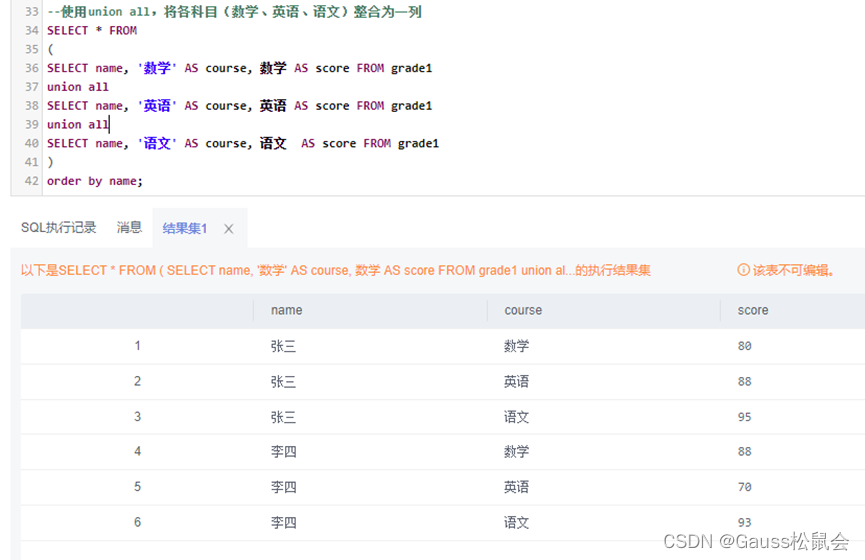
GaussDB数据库SQL系列-行列转换
一、前言 二、简述 1、行转列概念 2、列转行概念 三、GaussDB数据库的行列转行实验示例 1、行转列示例 1)创建实验表(行存表) 2)静态行转列 3)行转列(结果值:拼接式) 4&…...

美国陆军网络司令部利用人工智能增强网络攻防和作战决策能力
源自: 奇安网情局 声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。 “人工智能技术与咨询…...

Notion团队协作魔法:如何玩转数字工作空间?
Notion简介 Notion已经成为现代团队协作的首选工具之一。它不仅仅是一个笔记应用,更是一个强大的团队协作平台,能够满足多种工作场景的需求。 Notion的核心功能 Notion提供了丰富的功能,如文档、数据库、看板、日历等,满足团队的…...

视频云存储/安防监控/AI视频智能分析平台新功能:人员倒地检测详解
人工智能技术已经越来越多地融入到视频监控领域中,近期我们也发布了基于AI智能视频云存储/安防监控视频智能分析平台的众多新功能,该平台内置多种AI算法,可对实时视频中的人脸、人体、物体等进行检测、跟踪与抓拍,支持口罩佩戴检测…...

解决RabbitMQ报错Stats in management UI are disabled on this node
文章目录 问题描述:解决步骤:进入容器后,cd到以下路径修改 management_agent.disable_metrics_collector false退出容器重启rabbitmq容器 问题描述: linux 部署 rabbitmq后,打开rabbitmq管理界面。点击channels&#…...

【重点】【NAND】聊聊固态硬盘SSD的寿命及其影响因素
固态硬盘是由主控芯片、存储颗粒芯片组成的闪存设备,固体硬盘的英文简称是SSD,如果是移动用的固态硬盘,则其英文简称为PSSD。 固态硬盘SSD分工业级和消费级等,目前,工业级固态硬盘SSD通常采用MLC闪存,而消…...

数据库约束
文章目录 1. 简介2. 代码演示3. 外键约束4. 外键删除和更新行为 1. 简介 概念:约束时作用于表中子段上的规则,用于限制存储在表中的shuju目的:保证数据库中数据的正确、有效性和完整性分类: 约束描述关键字非空约束限制该字段不…...

Unity实现MQTT服务器
首先下载MqttNet:MqttNet下载地址 解压好后使用vs打开,并生成.dll文件(我这里下载的是4.1.2.350版本) 然后再/Source/MQTTnet/bin/Debug/net452 文件夹中找到生成的文件 新建unity工程,创建Plugins文件夹࿰…...

Linux(centos) 下 Mysql 环境安装
linux 下进行环境安装相对比较简单,可还是会遇到各种奇奇怪怪的问题,我们来梳理一波 安装 mysql 我们会用到下地址: Mysql 官方文档的地址,可以参考,不要全部使用 https://dev.mysql.com/doc/refman/8.0/en/linux-i…...
决策树(Decision Tree)
决策树的定义: 分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点(node)和有向边(directed edge)组成。结点有两种类型: 内部结点(internal node)和叶结点(leaf node࿰…...

终极指南:119,376个英语单词发音MP3音频一键下载完整教程 [特殊字符]
终极指南:119,376个英语单词发音MP3音频一键下载完整教程 🎧 【免费下载链接】English-words-pronunciation-mp3-audio-download Download the pronunciation mp3 audio for 119,376 unique English words/terms 项目地址: https://gitcode.com/gh_mir…...

宝塔面板301重定向保姆级教程:从WWW跳转到Nginx/Apache配置文件修改,一篇搞定
宝塔面板301重定向深度实战:Nginx与Apache配置文件高阶玩法 当你发现宝塔面板的图形界面无法满足某些特殊重定向需求时,直接修改服务器配置文件才是真正的解决方案。本文将带你深入Nginx和Apache的配置世界,摆脱图形界面的限制,实…...

RuoYi-Vue-Plus项目实战:用WebSocket实现‘服务端通知’功能,我踩了这些坑
RuoYi-Vue-Plus实战:WebSocket服务端通知功能深度解析与避坑指南 在当今企业级应用开发中,实时通信已成为提升用户体验的关键要素。当产品经理提出"后台操作成功时前端实时弹窗提示"的需求时,作为技术负责人的你该如何选择技术方案…...

告别踩坑!手把手教你用Cobalt Strike 4.7在Kali Linux上快速搭建团队服务器并上线第一台主机
Kali Linux环境下Cobalt Strike 4.7团队服务器部署与主机上线实战指南 在渗透测试和红队演练中,Cobalt Strike作为一款成熟的商业框架,其团队协作功能和丰富的攻击模拟能力备受安全从业者青睐。本文将基于Kali Linux系统,详细解析Cobalt Stri…...

别再只把 AI 当聊天框了!探索 Google DeepMind 的 `agy` 命令行工具与人机协同新姿势
别再只把 AI 当聊天框了!探索 Google DeepMind 的 agy 命令行工具与人机协同新姿势 在 AI 辅助编程(AI Coding)卷到飞起的今天,大部分开发者最习惯的可能还是在 IDE 侧边栏里装个插件,或者在网页端和 AI 缝缝补补地复制…...

KaTrain围棋AI训练终极指南:5步从入门到精通
KaTrain围棋AI训练终极指南:5步从入门到精通 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 想要快速提升围棋水平却找不到合适的训练方法?KaTrain作为一款…...

如何用Matlab SPOD工具快速分析流体动力学模态:完整指南
如何用Matlab SPOD工具快速分析流体动力学模态:完整指南 【免费下载链接】spod_matlab Spectral proper orthogonal decomposition in Matlab 项目地址: https://gitcode.com/gh_mirrors/sp/spod_matlab 你是不是经常面对海量的流体动力学数据感到无从下手&a…...

WebShell-Bypass-Guide preg_replace函数RCE漏洞利用指南
WebShell-Bypass-Guide preg_replace函数RCE漏洞利用指南 【免费下载链接】WebShell-Bypass-Guide 从零学习Webshell免杀手册 项目地址: https://gitcode.com/gh_mirrors/we/WebShell-Bypass-Guide WebShell-Bypass-Guide是一份从零学习Webshell免杀的实用手册ÿ…...
适合全体毕业生)
口碑最好的AI论文工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
论文选题没思路、文献检索耗时长、开题报告写不出、初稿逻辑混乱、查重反复修改、答辩PPT难打磨?面对论文写作的重重难关,作为学术新手、应届生或本科硕士毕业生,你是否也感到力不从心?论文流程复杂、环节繁多、上手门槛高&#x…...

开源数字微流控平台OpenDrop:3步打造你的微型生物实验室
开源数字微流控平台OpenDrop:3步打造你的微型生物实验室 【免费下载链接】OpenDrop Open Source Digital Microfluidics Bio Lab 项目地址: https://gitcode.com/gh_mirrors/ope/OpenDrop 你是否曾梦想在桌面上建立一个完整的生物实验室?OpenDrop…...