技术实践|Hive数据迁移干货分享
导语
Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低学习成本,十分适合对数据仓库进行统计分析。
近几年,随着行业内数据体量的不断增大,再加上国产化的趋势下,很多企业都开始着手对自己已有的大数据平台进行扩容、升级、产品更换等一系列操作,以期可以赶上潮流。因此,就会有很多项目需要进行数据库迁移,本文主要总结了一些在项目上遇到Hive迁移时,可以使用的方式方法,供大家参考借鉴。
目录
● 1. Hive迁移类型
● 2. Hive迁移步骤
● 3. Hive迁移实施步骤
● 4. 结语
1. Hive迁移类型
■ 表和数据整体迁移
一般在企业进行大数据平台产品的升级更换(如国产化)、机房搬迁、物理机转向云平台等情况下,会进行整库迁移,那么此时Hive迁移建议使用表和数据整体迁移的方式进行迁移。
■ 表和数据分步迁移
一般在企业进行数据库改造、历史数据库区域创建、业务条线改造等,或是数据库出现瓶颈的情况下,会进行部分数据迁移,那么此时Hive迁移建议使用表和数据分步迁移的方式进行迁移。
2. Hive迁移步骤
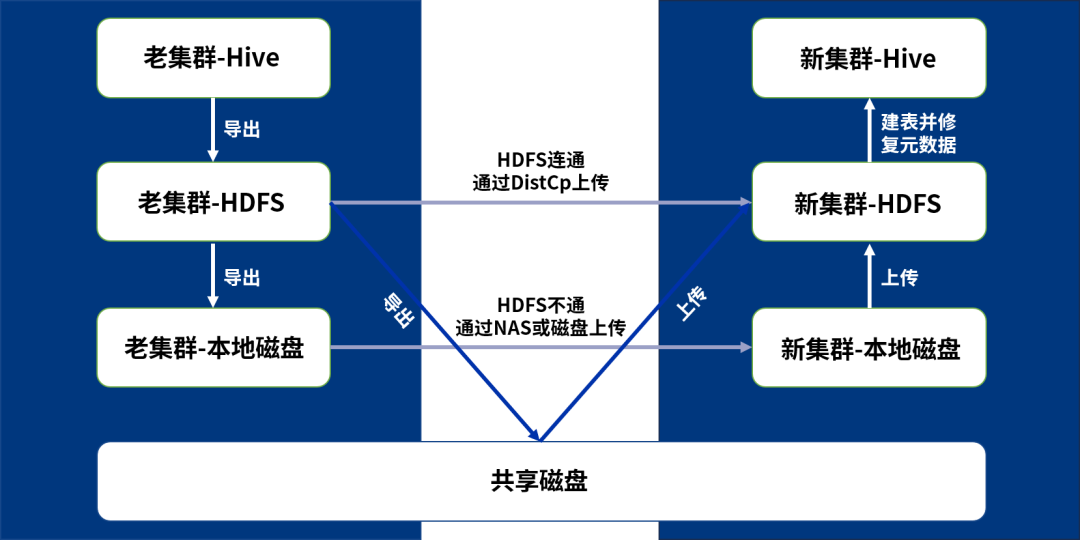
(1)将表和数据从老集群Hive导出到老集群HDFS
(2)将表和数据从老集群HDFS导出到老集群本地磁盘或共享磁盘
(3)将表和数据从老集群本地磁盘复制到新集群本地磁盘(如共享磁盘此步骤省略)
(4)将表和数据从新集群本地磁盘或共享磁盘上传到新集群HDFS
(5)修复新集群Hive数据库元数据
如果老集群HDFS和新集群HDFS连通,可使用DistCp工具跨集群复制,跳过中间步骤,直接执行第5步。
3. Hive迁移实施步骤
■ 新集群和服务器检查
#查看本地空间使用情况是否足够
df -h#查看HDFS集群使用情况是否满足
hadoop dfsadmin -report#查找Hive库存储位置
hadoop fs -find / -name warehouse#查看Hive库占用情况
hadoop fs -du -h /user/hive/warehouse■ 表和数据整体迁移
一般Hive整体迁移时使用HDFS文件迁移,然后再进行数据表与数据文件关联即可,新老集群Hive版本即使不一致的情况下也支持该步骤,详细操作步骤如下:
老集群备份
# 罗列迁移表清单
cat <<EOF > /home/data/backup/hive_sel_tables.hql
use <db_name>;
show tables;
EOF# 清洗迁移表清单
beeline -f /home/data/backup/hive_sel_tables.hql \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/data/backup/hive_table_list.txt# 拼接建表语句命令及清洗无用字符
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "show create table <db_name>.%s;\n",$1,$1}' \
| sed "s/|//g" \
| sed "s/+/'/g" \
| grep -v "tab_name" \
> /home/data/backup/hive_show_create_table.hql# 导出建表语句
beeline -e /home/data/backup/hive_show_create_table.hql>/home/data/backup/hive_table_ddl.sql# 清洗建表语句
sed -i 's/^|//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/|$//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/-//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/+//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/createtab_stmt//g' /home/data/backup/hive_table_ddl.sql
sed -i 's/.*0: jdbc:hive2:.*/;/' /home/data/backup/hive_table_ddl.sql
sed -i '/^$/d' /home/data/backup/hive_table_ddl.sql# 拼接修复Hive元数据语句
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "msck repair table archive.%s;\n",$1,$1}' \
| sed "s/|//g" \
| sed "s/+/'/g" \
| grep -v "tab_name" \
> /home/data/backup/hive_repair_table.hql# 将Hive在HDFS中的文件导出到HDFS临时目录
hadoop fs -get /user/hive/warehouse/<db_name> /tmp# HDFS集群连通时使用DistCp进行拷贝
hadoop distcp hdfs://scrNameNode/tmp/<db_name> hdfs://user/hive/warehouse/<db_name># HDFS集群不连通,导出HDFS文件到本地磁盘或者共享NAS
hadoop fs -get /tmp/<db_name> /home/data/backup/# 如果是共享磁盘忽略此步
scp -r /home/data/backup/ root@targetAP:/home/data/backup/新集群恢复
# 登录生产环境Hive并创建表
beeline -f /home/data/backup/hive_table_ddl.sql>>/home/data/backup/hive_table_ddl.log# 检查新集群数据库新表是否创建成功
beeline
use <db_name>
show tables;# 将数据文件上传到HDFS的Hive存储路径下
hadoop fs -put /home/data/backup/<db_name> /user/hive/warehouse/<db_name># 关联Hive表和数据
beeline -f /home/data/backup/hive_repair_table.hql# 查看HDFS所有目录检查是否都导入成功
hadoop fs -lsr /home# 查看所有表大小,验证新旧表大小是否一致
hadoop fs -du -h /user/hive/warehouse/<db_name>■ 表和数据分步迁移
一般Hive分步迁移时使用Import和Export,新老集群Hive版本不一致的情况下也支持该步骤。
Export工具导出时会同时导出元数据和数据;
Import工具会根据元数据自行创建表并导入数据。
老集群备份
# 罗列迁移表清单
cat <<EOF > /home/data/backup/hive_sel_tables.hql
use <db_name>;
show tables;
EOF# 罗列要迁移的表清单
beeline -f /home/data/backup/hive_sel_tables.hql\
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /home/data/backup/hive_table_list.txt# 生成导出脚本
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "export table <db_name>.%s to |/tmp/<db_name>/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/data/backup/hive_export_table.hql# 生成导入脚本
cat /home/data/backup/hive_table_list.txt \
| awk '{printf "import table <db_name>.%s from |/tmp/<db_name>/%s|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /home/data/backup/hive_import_table.hql# 创建HDFS导出目录
hadoop fs -mkdir -p /tmp/<db_name>/# 导出表结构到数据到HDFS
beeline -f /home/data/backup/hive_export_table.hql#HDFS集群连通时使用DistCp进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp# HDFS集群不连通,导出HDFS文件到本地磁盘或者共享NAS
hadoop fs -get /tmp/<db_name> /home/data/backup/# 如果是共享磁盘忽略此步
scp -r /home/data/backup/ root@targetAP:/home/data/backup/新集群恢复
# 创建HDFS导出目录
hadoop fs -mkdir -p /tmp/<db_name>/#上传到目标HDFS
hadoop fs -put /home/data/backup/<db_name> /tmp# 导入到目标Hive
beeline -f /home/data/backup/hive_import_table.hql# 查看HDFS所有目录检查是否都导入成功
hadoop fs -lsr /home# 查看所有表大小,验证新旧表大小是否一致
hadoop fs -du -h /user/hive/warehouse/<db_name>4. 总结
Hive的数据迁移其实有多种方式,根据需求不同采用的迁移方式也不尽相同,每种迁移的优势也是不同的,其中数据量是影响迁移的重要因素之一。
在数据量不大的情况下,Hive迁移一般常用的方式是使用Export、Import进行数据和元数据的导出导入,Export会将数据和元数据写到一起,并且元数据在恢复时是直接关联数据的,不需要再做其他的操作。同时还直接关联分区,不需要再使用MSCK进行分区修复。需要注意的一点的是,Import和Export在进行数据恢复的时候,只会关注到表层的文件夹,不用和旧集群的文件路径一摸一样。
在数据量比较大的情况下,建议使用整体迁移的方式,这样Hive迁移的速度较快,但是注意要保证新旧集群数据目录的一致性。
相关文章:
技术实践|Hive数据迁移干货分享
导语 Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低…...
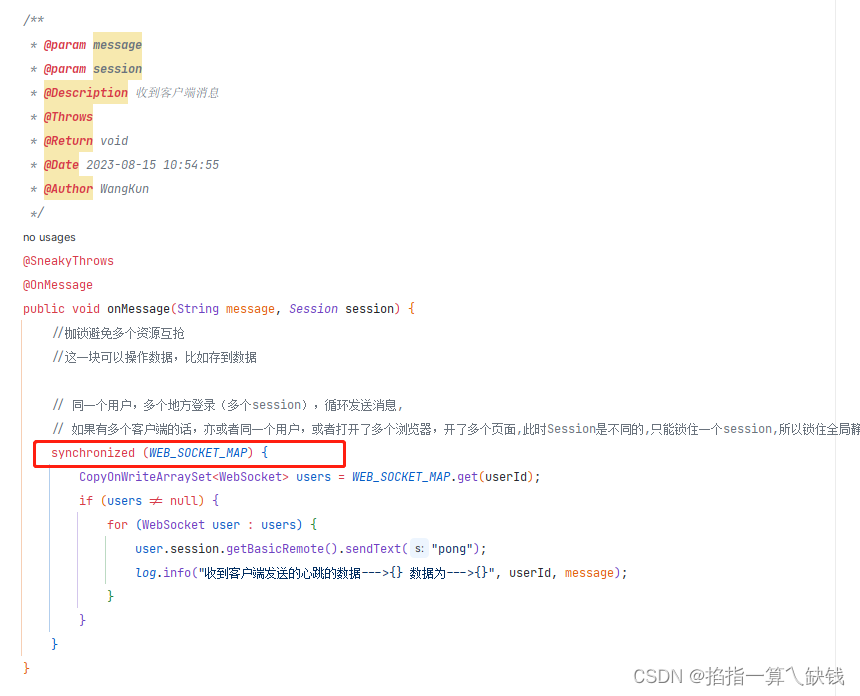
The remote endpoint was in state [TEXT_FULL_WRITING]
报这个错是因为在websocket接收与发送消息时,资源互抢造成的,有很多帖子说将session锁住, 但是同一个账号多个客户端登陆的时候,session是不同的,所以只能锁住一个session,还是出现这个问题。 解决办法&a…...

微信小程序ios下,border显示不全兼容问题解决
小程序在ios系统中,如果border小于1px的情况下,border就可能显示不全(可能少了上下左右任意一边) 只需要加一个::after或::before伪类,使用绝对定位定在原来元素上边就不会产生问题了! .d_card_line1_tag {padding: 1rpx 14rpx;…...

《Effective C++中文版,第三版》读书笔记6
条款32:确定你的public继承塑模出is-a关系 简单知识点回顾(若不知道那就是扫盲了): is-a关系:子类public继承父类。比如说Apublic继承了B。我们可以说A是B的一种特殊情况 has-a关系:指的是一种组合关系&…...
【Docker 】Docker 客户端,容器使用,启动容器,启动已停止运行的容器,停止一个容器,进入容器
作者简介: 辭七七,目前大一,正在学习C/C,Java,Python等 作者主页: 七七的个人主页 文章收录专栏: 七七的闲谈 欢迎大家点赞 👍 收藏 ⭐ 加关注哦!💖…...
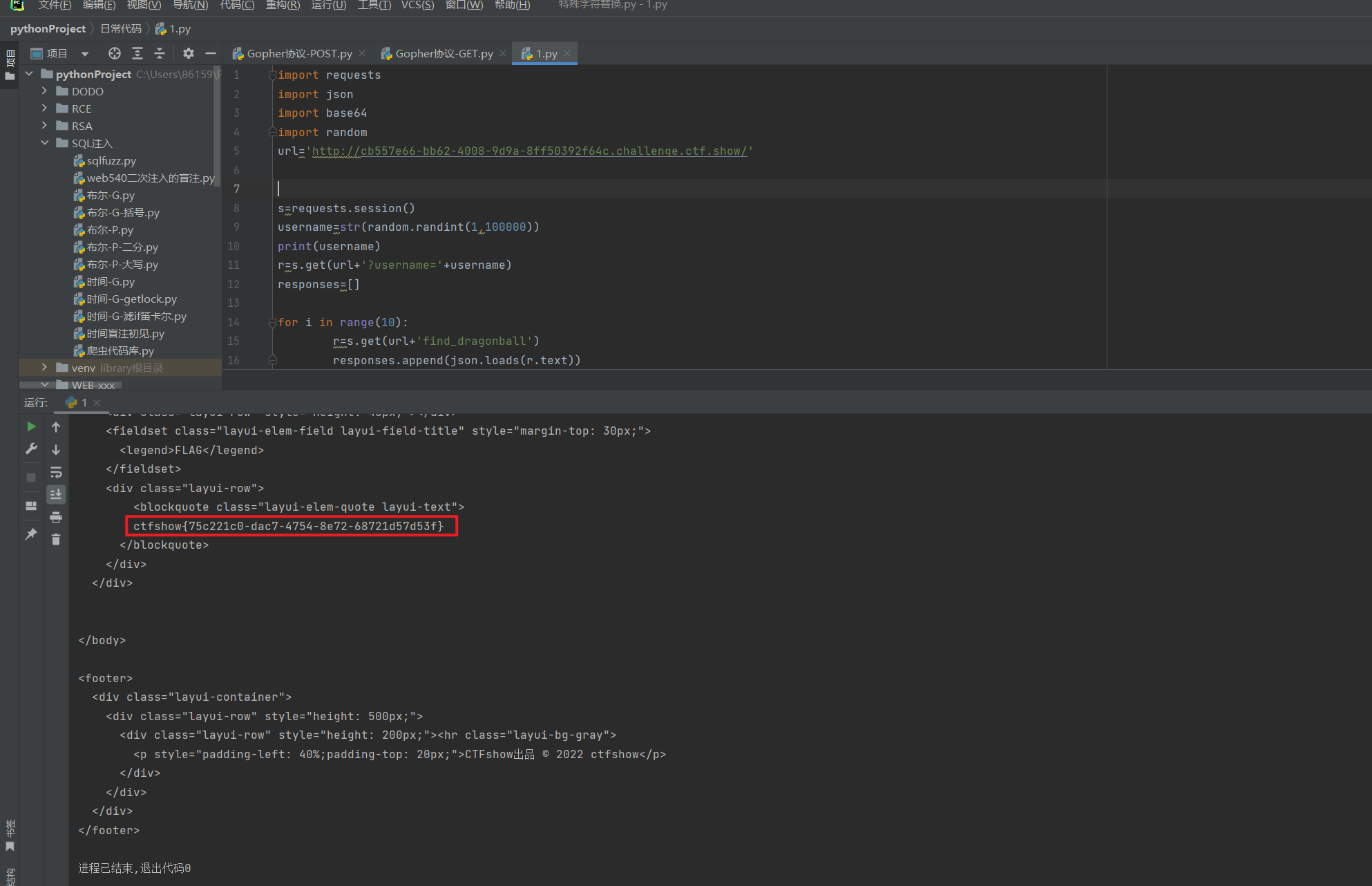
CTFshow 菜狗杯 web方向 全
文章目录 菜狗杯 web签到菜狗杯 web2 c0me_t0_s1gn菜狗杯 我的眼里只有$菜狗杯 抽老婆菜狗杯 一言既出菜狗杯 驷马难追菜狗杯 TapTapTap菜狗杯 Webshell菜狗杯 化零为整菜狗杯 无一幸免菜狗杯 无一幸免_FIXED菜狗杯 传说之下(雾)菜狗杯 算力超群菜狗杯 算…...

深入理解sql:进阶版
目录 背景举例子查询和嵌套查询:联合查询(UNION和UNION ALL):窗口函数:CTE(公共表达式):索引优化:事务隔离级别和锁定:性能优化:存储过程和函数&a…...

day31 | 455.分发饼干、376. 摆动序列、53. 最大子序和
目录: 解题及思路学习 455. 分发饼干 假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。 对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸&#…...

C# textBox 右键菜单 contextMenuStrip
需求: 想在上图空白处可以右键弹出菜单,该怎么做呢? 1.首先,拖出一个 ContextMenuStrip。 随便放哪里都行,如下: 2.在textBox里关联这个“右键控件”即可,如下: 最终效果如下: 以上…...
TCP拥塞控制详解 | 7. 超越TCP
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems …...
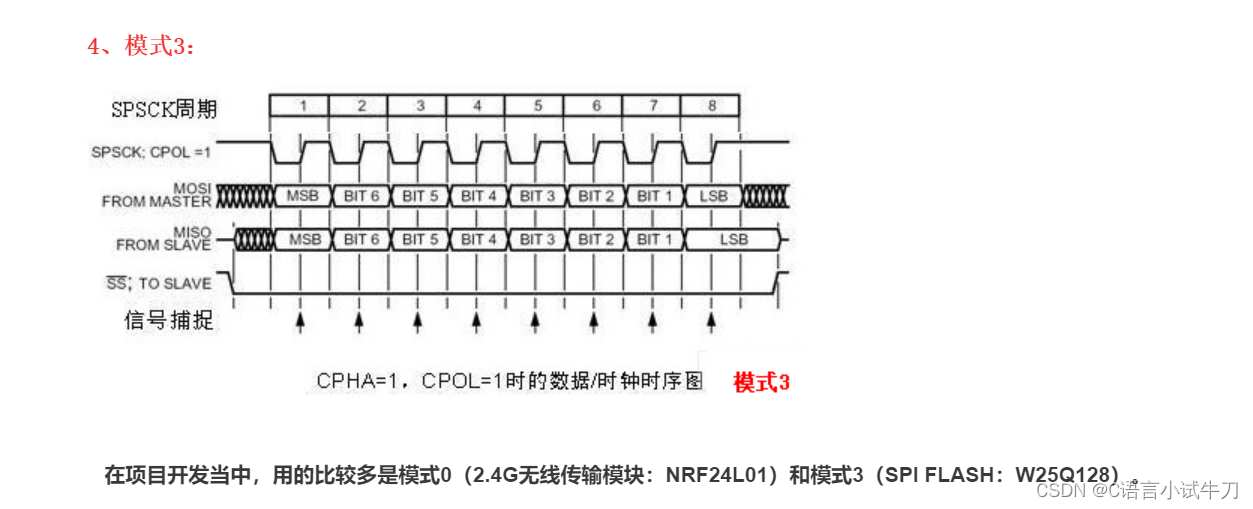
stm32之26.spi外设
...
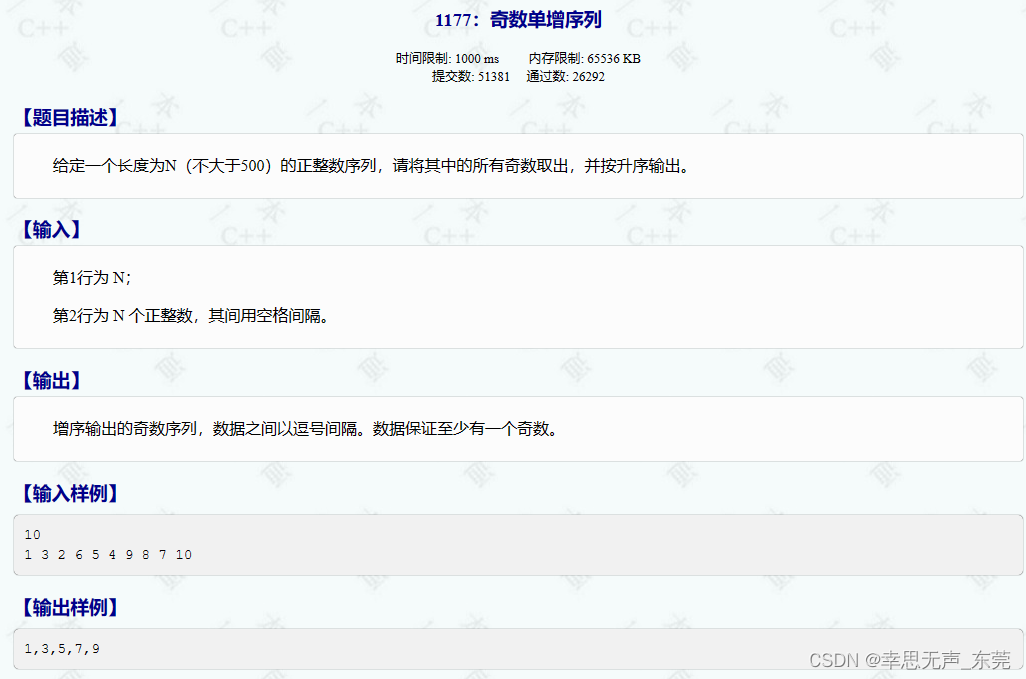
C++信息学奥赛1177:奇数单增序列
#include<bits/stdc.h> using namespace std; int main(){int n;cin>>n; // 输入整数 n,表示数组的大小int arr[n]; // 创建大小为 n 的整型数组for(int i0;i<n;i) cin>>arr[i]; // 输入数组元素for(int i0;i<n;i){ // 对数组进行冒泡排序f…...
Java的数组是啥?
1.数组是啥? 数组是一块连续的内存,用来存储相同类型的数据 (1)如何定义数组? 1.int[] array {1,2,3,4} new int[]{1,2,3,4};//这里的new是一个关键字,用来创建对象 2.数组就是一个对象 动态初始化 …...
)
我的私人笔记(安装hadoop)
1.安装hadoop01环境 注需安装最小安装和使用英文界面 2.安装群集 // 获得网关IP:192.168.80.2 获得子网掩码:255.255.255.0 // 获得网段:[起始IP地址]192.168.128 --- [结束IP地址]192.168.80.254 // 计划集群的ip和主机名 //192.168.80.…...
【板栗糖GIS】——360浏览器的下载图标隐藏在内部不方便,怎么修改
目录 1. 设置前的本来样子 2. 登录360的皮肤中心 3. 使用se13的经典皮肤 最近edge浏览器最近使用bilibili和notion都非常卡,时不时崩溃,不得不换浏览器使用,试来试去360浏览器最得我心,只不过广告太多,调教也是花了…...

SpringMVC之文件上传和下载
文章目录 前言一、文件下载二、文件上传总结 前言 实现下载文件和上传文件的功能。 一、文件下载 使用ResponseEntity实现下载文件的功能 RequestMapping("/testDown") public ResponseEntity<byte[]> testResponseEntity(HttpSession session) throws IOEx…...

简单了解OSI网络模型
目录 一、协议是什么? 二、OSI七层模型 三、TCP/IP五层模型 一、协议是什么? 协议顾名思义就是通过大家伙一起协商讨论达成的统一规则和标准。网络协议就是规定用户数据信息如何在网络上传播以及实现某种网络技术所要遵循的统一标准和规则。 二、OSI…...

服务网格实施周期缩短 50%,丽迅物流基于阿里云 ACK 和 ASM 的云原生应用管理实践
作者:王夕宁、 刘强、 华相 公司介绍 丽迅物流是百丽旗下专注于时尚产业、为企业提供专业物流及供应链解决方案的服务商。其产品服务主要包括城市落地配、仓配一体、干线运输及定制化解决方案。通过自研智能化物流管理平台,全面助力企业合作集约化发展…...

bpmnjs Properties-panel拓展(属性设置篇)
最近有思考工作流相关的事情,绘制bpmn图的工具认可度比较高的就是bpmn.js了,是一个基于node.js的流程图绘制框架。初始的框架只实现了基本的可视化,想在xml进行客制化操作的话需要拓展,简单记录下几个需求的实现过程。 修改基础 …...

Debian系统上通过NFS挂载远程服务器硬盘
步骤 1:配置远程服务器 在拥有硬盘内容的远程服务器上,进行以下配置: 安装NFS服务器软件: sudo apt-get update sudo apt-get install nfs-kernel-server编辑NFS服务器配置文件 /etc/exports,添加需要共享的目录及其权…...
与返回值)
Python运算符:比较运算符(等于不等等于大于小于)与返回值
Python运算符:比较运算符(等于不等等于大于小于)与返回值📚 本章学习目标:深入理解比较运算符(等于不等等于大于小于)与返回值的核心概念与实践方法,掌握关键技术要点,了…...

图文实操|飞书联动 OpenClaw,搭建智能电脑操控体系
OpenClaw 飞书机器人配置教程|一键对接飞书,聊天下达 AI 指令 适配版本:OpenClaw(小龙虾)前置要求:已部署 OpenClaw Windows 端(Win10/Win11 均可),未部署可先下载一键部…...

2026年第二次答辩前论文降AI攻略:二次答辩AIGC超标4.8元彻底解决完整处理方案
2026年第二次答辩前论文降AI攻略:二次答辩AIGC超标4.8元彻底解决完整处理方案 关于第二次答辩论文降AI,我总结了一个最重要的教训:别只降标红段落,要全文处理。 之前逐段降,整体检测还是超标。换成全文上传ÿ…...

CANN/asc-devkit:__float2float_rn类型转换函数
__float2float_rn 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitco…...

如何快速掌握UESave:3个高效编辑游戏存档的秘诀
如何快速掌握UESave:3个高效编辑游戏存档的秘诀 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave 你是否曾因游戏存档损坏而失去珍贵的游戏进度?是…...

Co-IP/MS:蛋白免疫共沉淀质谱分析服务
免疫共沉淀质谱法(Co-IP/MS)是一种由免疫共沉淀技术联用质谱技术的蛋白互作研究技术,具备高分辨率鉴定和精确定量蛋白质复合物中每个组分的优势。Co-IP/MS使用靶向目标蛋白的特异性抗体,选择性地捕获目标蛋白质与其相互作用的分子…...
:7类发音错误+5个未公开参数修复方案)
ElevenLabs印地文语音质量崩塌真相(印地语TTS失效深度溯源):7类发音错误+5个未公开参数修复方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs印地文语音质量崩塌的全局现象与影响评估 近期,ElevenLabs平台在印地语(Hindi)TTS合成任务中出现系统性语音质量退化,表现为音素错读、韵律断裂…...
: 硬件规格和安装准备)
在骁龙 X2 Elite 上安装 Hermes Agent(1): 硬件规格和安装准备
系列导读 为什么 骁龙Snapdragon X2 Elite 是 Hermes Agent 的最佳搭档?本文是《在骁龙 X2 Elite 上安装 Hermes Agent》系列的第一篇。你将了解 骁龙 X2 Elite 的强大硬件规格、Hermes Agent 的核心能力,以及安装前的准备工作。 一、为什么选择骁龙 X2 …...
)
团队协作效率翻倍:手把手教你用TortoiseGit管理多分支与查看提交日志(图文详解)
团队协作效率翻倍:TortoiseGit多分支管理与提交日志深度实战 在敏捷开发团队中,代码版本控制如同乐团的指挥棒,而TortoiseGit则是让每个开发者都能直观参与这场协奏的图形化利器。不同于初学者需要从安装配置起步,本文面向已经掌握…...
)
Linux mkdir、rmdir 命令详解——目录的创建与删除(新手零踩坑)
前言在Linux操作中,目录是文件的“容器”,想要管理文件,首先要学会创建和删除目录。mkdir(创建目录)和rmdir(删除目录)是最基础的目录操作命令,用法简单但有细节,尤其是r…...