我的私人笔记(安装hadoop)
1.安装hadoop01环境
注需安装最小安装和使用英文界面
2.安装群集
// 获得网关IP:192.168.80.2 获得子网掩码:255.255.255.0
// 获得网段:[起始IP地址]192.168.128 --- [结束IP地址]192.168.80.254
// 计划集群的ip和主机名
//192.168.80.151 hadoop01
//192.168.80.152 hadoop02
//192.168.80.153 hadoop03
在hadoop01中操作
1.修改主机名:
hostnamectl set-hostname hadoop01
2.配置网卡:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#修改
BOOTPROTO=static
ONBOOT=yes
#添加
IPADDR=192.168.80.151
GATEWAY=192.168.80.2
NETMASK=255.255.255.0
DNS1=119.29.29.29
DNS2=8.8.8.8
3.修改映射文件
vi /etc/hosts
# 添加
192.168.80.151 hadoop01
192.168.80.152 hadoop02
192.168.80.153 hadoop03
4.永久关闭防火墙
systemctl disable firewalld.service
//systemctl status firewalld.service 查看防火墙状态
//systemctl start firewalld.service 开启防火墙
//systemctl stop firewalld.service 关闭防火墙
reboot // 重启虚拟机
5.修改映射文件
//到此电脑中输入
C:\Windows\System32\drivers\etc
//添加
192.168.80.151 hadoop01
192.168.80.152 hadoop02
192.168.80.153 hadoop03
6.远程连接
打开SecureCRT >> 文件 >> 连接 >> 新建会话
// 修改
主机名: hadoop01 // hadoop01指的是主机名
用户名: root
//点连接然后输入您用户的密码即可登录
7.创建文件夹
mkdir /opt/software /opt/servers
8.切换工作目录
cd /opt/software
9.上传jdk和hadoop
10.解压JDK和Hadoop
tar -zxvf /opt/software/jdk-8u65-linux-x64.tar.gz -C /opt/servers
tar -zxvf /opt/software/hadoop-2.7.4.tar.gz -C /opt/servers/
11.重命名文件夹
mv /opt/servers/jdk1.8.0_65/ /opt/servers/jdk
mv /opt/servers/hadoop-2.7.4/ /opt/servers/hadoop
12.配置环境变量
vi /etc/profile
# 在文件末尾添加
export JAVA_HOME=/opt/servers/jdk
export HADOOP_HOME=/opt/servers/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
13.刷新环境变量
source /etc/profile
14.验证JDK和Hadoop是否安装成功
//验证JDK,能看到版本号说明安装成功
java -version
//验证Hadoop,能看到版本号说明安装成功
hadoop version
15.切换工作目录
cd /opt/servers/hadoop/etc/hadoop/
16.编辑core-site.xml
vi core-site.xml
# <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/servers/hadoop/data/tmp</value>
</property>
# </configuration>
17.编辑hdfs-site.xml
vi hdfs-site.xml
# <configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
# </configuration>
18.编辑mapred-site.xml
//复制模板并重命名
cp mapred-site.xml.template mapred-site.xml
//编辑文件
vi mapred-site.xml
# <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
# </configuration>
19.编辑yarn-site.xml
vi yarn-site.xml
# <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
# </configuration>
20.编辑slaves
vi slaves
// 删除 localhost
// 添加
hadoop01
hadoop02
hadoop03
21.编辑hadoop-env.sh
vi hadoop-env.sh
// 修改
export JAVA_HOME=/opt/servers/jdk
关机
poweroff
22.选中hadoop01虚拟机 >> 管理 >> 克隆 >> 下一页 >> 下一页 >> 创建完整克隆 >> 修改虚拟机名称及位置 >> 完成
// 需要两台虚拟机,所以我们要克隆2次
开启虚拟机 hadoop01 hadoop02 hadoop03
23.在hadoop02中操作
设置主机名
hostnamectl set-hostname hadoop02
编辑网卡
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改 设置成你的hadoop02 IP地址
IPADDR=192.168.80.152
重启虚拟机
reboot
24.在hadoop03中操作
设置主机名
hostnamectl set-hostname hadoop03
编辑网卡
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改 设置成你的hadoop03 IP地址
IPADDR=192.168.80.153
重启虚拟机
reboot
25.在hadoop01中操作
//生成机器间通信的密钥对,输入命令,直接按4个回车
ssh-keygen -t rsa
//创建authorized_keys文件
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
//修改authorized_keys文件权限为600
chmod 600 ~/.ssh/authorized_keys
//验证SSH是否安装成功
ssh localhost
第一次登陆需要输入yes
//分发公钥,在分发过程中需输入yes和分发对象机器的登录密码
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop02
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop03
26.开启集群
hdfs namenode -format
start-dfs.sh、start-yarn.sh 或 start-all.sh
27.验证
hadoop01:
1732 NameNode
1996 ResourceManager
2253 Jps
hadoop02:
1538 SecondaryNameNode
1642 NodeManager
1486 DataNode
1742 Jps
hadoop03
1683 Jps
1487 DataNode
1583 NodeManager
//在WEB中查看集群信息
打开浏览器中输入:
http://hadoop01:50070
http://hadoop01:8088
28.停止集群
stop-dfs.sh、stop-yarn.sh 或 stop-all.sh
相关文章:
)
我的私人笔记(安装hadoop)
1.安装hadoop01环境 注需安装最小安装和使用英文界面 2.安装群集 // 获得网关IP:192.168.80.2 获得子网掩码:255.255.255.0 // 获得网段:[起始IP地址]192.168.128 --- [结束IP地址]192.168.80.254 // 计划集群的ip和主机名 //192.168.80.…...
【板栗糖GIS】——360浏览器的下载图标隐藏在内部不方便,怎么修改
目录 1. 设置前的本来样子 2. 登录360的皮肤中心 3. 使用se13的经典皮肤 最近edge浏览器最近使用bilibili和notion都非常卡,时不时崩溃,不得不换浏览器使用,试来试去360浏览器最得我心,只不过广告太多,调教也是花了…...

SpringMVC之文件上传和下载
文章目录 前言一、文件下载二、文件上传总结 前言 实现下载文件和上传文件的功能。 一、文件下载 使用ResponseEntity实现下载文件的功能 RequestMapping("/testDown") public ResponseEntity<byte[]> testResponseEntity(HttpSession session) throws IOEx…...

简单了解OSI网络模型
目录 一、协议是什么? 二、OSI七层模型 三、TCP/IP五层模型 一、协议是什么? 协议顾名思义就是通过大家伙一起协商讨论达成的统一规则和标准。网络协议就是规定用户数据信息如何在网络上传播以及实现某种网络技术所要遵循的统一标准和规则。 二、OSI…...

服务网格实施周期缩短 50%,丽迅物流基于阿里云 ACK 和 ASM 的云原生应用管理实践
作者:王夕宁、 刘强、 华相 公司介绍 丽迅物流是百丽旗下专注于时尚产业、为企业提供专业物流及供应链解决方案的服务商。其产品服务主要包括城市落地配、仓配一体、干线运输及定制化解决方案。通过自研智能化物流管理平台,全面助力企业合作集约化发展…...

bpmnjs Properties-panel拓展(属性设置篇)
最近有思考工作流相关的事情,绘制bpmn图的工具认可度比较高的就是bpmn.js了,是一个基于node.js的流程图绘制框架。初始的框架只实现了基本的可视化,想在xml进行客制化操作的话需要拓展,简单记录下几个需求的实现过程。 修改基础 …...

Debian系统上通过NFS挂载远程服务器硬盘
步骤 1:配置远程服务器 在拥有硬盘内容的远程服务器上,进行以下配置: 安装NFS服务器软件: sudo apt-get update sudo apt-get install nfs-kernel-server编辑NFS服务器配置文件 /etc/exports,添加需要共享的目录及其权…...
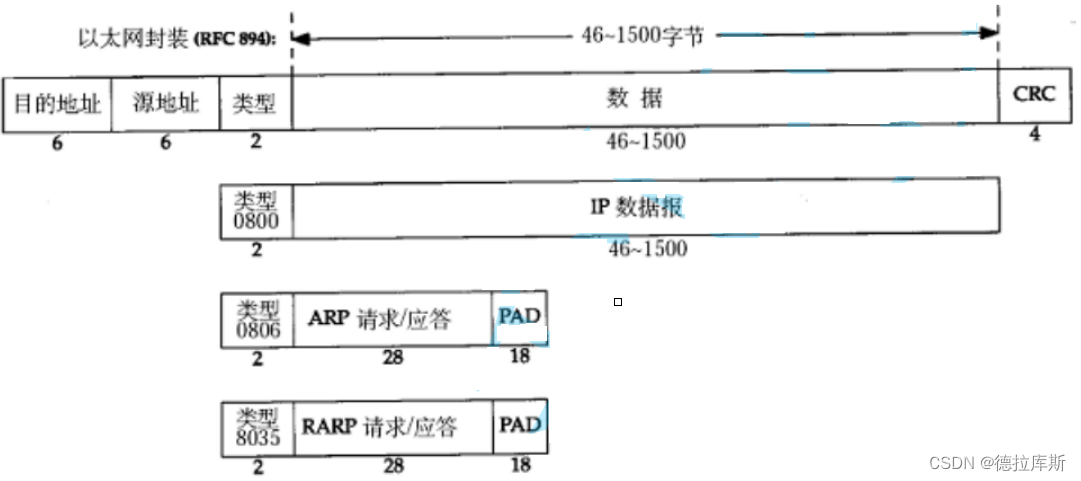
【Linux】以太网协议以及MTU
以太网协议 数据链路层的功能以太网的数据格式MTUMTU对IP协议的影响MTU对UDP协议的影响MTU对TCP协议的影响 数据链路层的功能 数据链路层的主要功能是:控制链路。包括数据链路的建立、链路的维护和释放。MAC寻址也是它的功能,寻址是指计算机网卡的MAC地…...
UE5打完包后,启动程序不能全屏
最近看到ue5的打包程序后不能默认自动全屏,效果如下,发现并不是全屏的,而且就算点击放大也不是全屏 解决办法:设置如下之后在打包就可以了 但是会一直打印错误的日志,不过这个不影响使用...

财务部发布《企业数据资源相关会计处理暂行规定》
导读 财务部为规范企业数据资源相关会计处理,强化相关会计信息披露,根据《中华人民共和国会计法》和相关企业会计准则,制定了《企业数据资源相关会计处理暂行规定》。 加gzh“大数据食铁兽”,回复“20230828”获取材料完整版 来…...

引用(个人学习笔记黑马学习)
1、引用的基本语法 #include <iostream> using namespace std;int main() {int a 10;//创建引用int& b a;cout << "a " << a << endl;cout << "b " << b << endl;b 100;cout << "a "…...

卷积神经网络实现运动鞋识别 - P5
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍦 参考文章:Pytorch实战 | 第P5周:运动鞋识别🍖 原作者:K同学啊 | 接辅导、项目定制🚀 文章来源:K同学的学习圈子 目录…...
C#安装“Windows 窗体应用(.NET Framework)”
目录 背景: 第一步: 第二步: 第三步: 总结: 背景: 如下图所示:在Visual Studio Installer创建新项目的时候,想要添加windows窗体应用程序,发现里面并没有找到Windows窗体应用(.NET Framework)模板,快捷搜索也没有发现&#…...
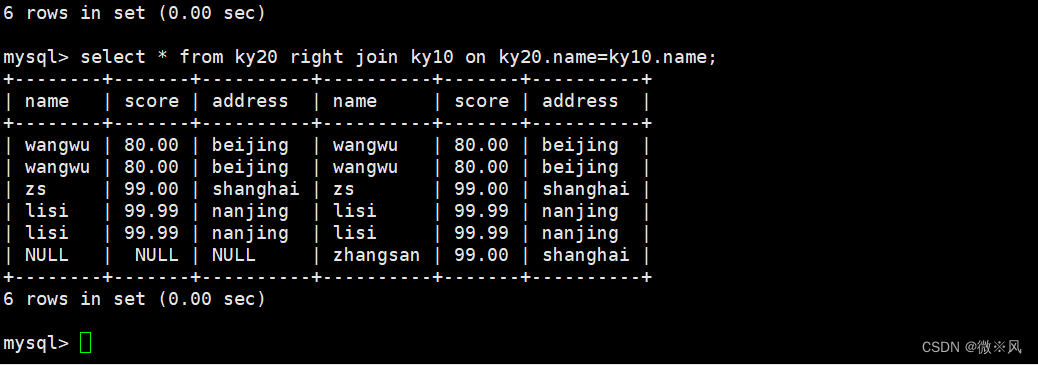
SQL高阶语句
目录 1、概念 1.1、概述 1.2、常见的MySQL高阶语句的概念: 1.3、 SQL高阶语句的作用 2、常用查询 2.1、按关键字排序 2.1.1、概述和作用 2.1.2、 (1)语法 2.1.3、模板表:ky30 编辑2.1.4、分数按降序排列 2.1.5、ORDER…...

【交换机】如何通过Web方式登陆交换机
一、华为交换机web登陆配置 Web网管是一种对交换机的管理方式,它利用交换机内置的Web服务器,为用户提供图形化的操作界面。用户可以从终端通过HTTPS登录到Web网管,对交换机进行管理和维护,同时也非常方便。 一、配置思路ÿ…...
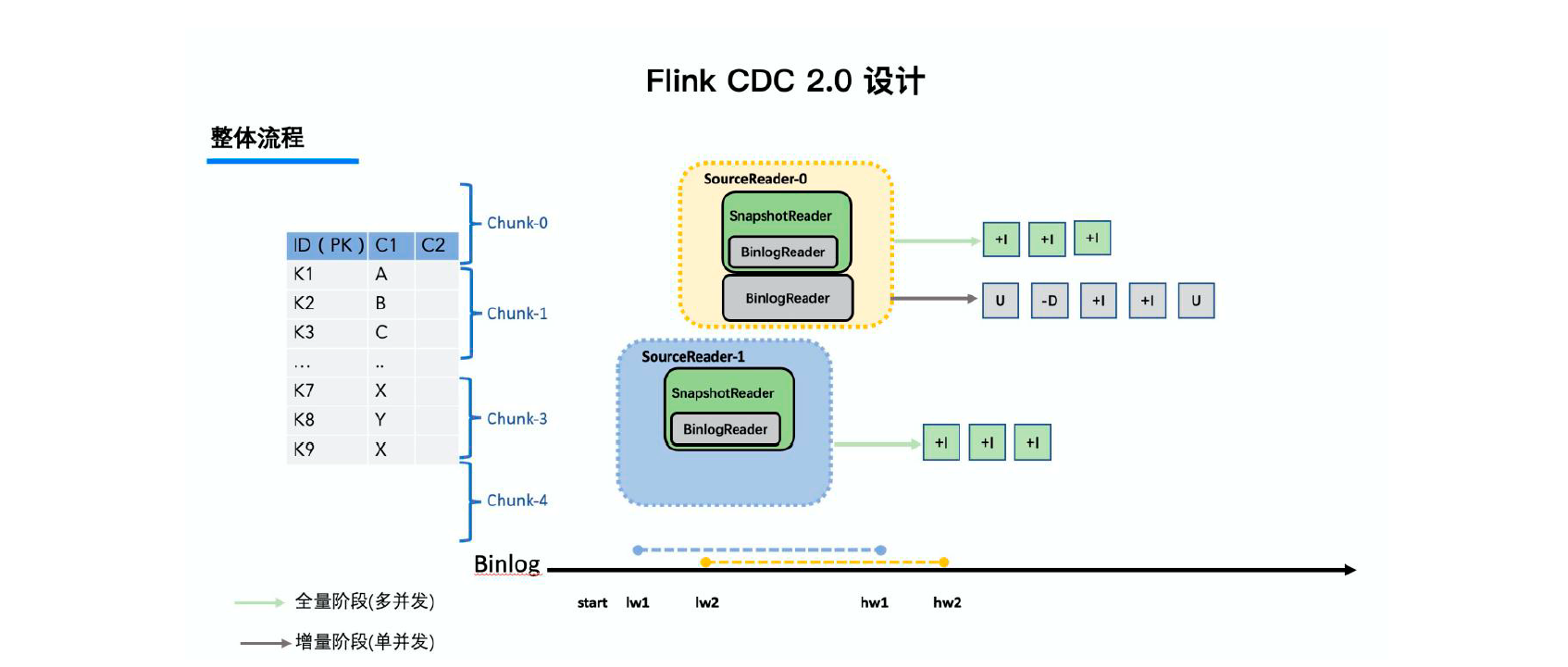
Flink CDC学习笔记
第一章 CDC简介 1.1 什么是CDC CDC (Change Data Capture 变更数据获取)的简称。核心思想就是,检测并获取数据库的变动(增删查改),将这些变更按发生的顺序记录下来,写入到消息中间件以供其它服务进行订…...

NEOVIM学习笔记
GitHub - blogercn/nvim-config: A pretty epic NeoVim setup 一直使用vim,每次到了新公司都要配置半天,而且常常配置失败,很多插件过期不好用。偶然看到别人的NEO VIM,就试着用了一下,感觉还不错。 用来开发和阅读C代…...

Docker三剑客之docker-compose
docker-compose 是 Docker 生态系统中的一个重要成员,它允许开发人员使用一个简单的配置文件来定义和运行多个 Docker 容器。通过 docker-compose,你可以定义应用程序的各个组件、容器之间的依赖关系以及网络配置,从而实现在一个命令中启动、…...

单调队列
目录 一,单调队列 二,模板实现 三,OJ实战 剑指 Offer 59 - I. 滑动窗口的最大值 一,单调队列 单调队列是双端队列的拓展,支持尾部插入,双端删除,其中的数据始终维持单调性,从而…...

effective c++ 笔记
TODO:还没看太懂的篇章 item25 item35 模板相关内容 文章目录 基础视C为一个语言联邦以const, enum, inline替换#define尽可能使用constconst成员函数 确定对象使用前已被初始化 构造、析构和赋值内含引用或常量成员的类的赋值操作需要自己重写不想使用自动生成的函…...

为什么我强烈推荐大学生打CTF!看完你就懂了!
前言 写这个文章是因为我很多粉丝都是学生,经常有人问: 感觉大一第一个学期忙忙碌碌的过去了,啥都会一点,但是自己很难系统的学习到整个知识体系,很迷茫,想知道要如何高效学习。 这篇文章我主要就围绕两点…...

[QA]插件式测试用例生成工具:LLM Test Case Tool 的设计与实现
一句话介绍:QA 在需求分析和测试设计中常用的能力沉淀到浏览器插件里:用户在阅读 PRD 时,可以直接在页面右下角调用 Workee,完成摘要、大纲、疑点、测试点、测试用例、UAT 用例和多页面分析。 1. 背景:为什么还需要这个…...

软件测试的“测开分离”趋势,是机遇还是陷阱
一、测开分离:软件测试行业的新变局在软件测试行业的发展历程中,角色的边界一直在悄然演变。从早期手工测试独挑大梁,到自动化测试兴起后测试人员开始涉足简单代码编写,再到如今测试开发工程师岗位的独立,测试与开发的…...

避坑指南:华为云Stack OBS 3.0对象存储部署,小型化与标准化方案到底怎么选?
华为云Stack OBS 3.0部署选型实战:小型化与标准化方案深度对比 当企业级用户面对华为云Stack OBS 3.0对象存储部署时,第一个关键决策点往往出现在架构形态的选择上——是采用轻量灵活的小型化方案,还是选择高扩展性的标准化部署?这…...
)
从单摆到机械臂:拉格朗日方程在机器人控制中的三个实战应用(附MATLAB/Simulink模型)
从单摆到机械臂:拉格朗日方程在机器人控制中的三个实战应用(附MATLAB/Simulink模型) 在机器人控制领域,动力学建模是连接理论设计与实际应用的关键桥梁。拉格朗日方程作为一种基于能量的分析方法,能够优雅地处理复杂系…...

智慧铁路列车车辆和人员检测数据集VOC+YOLO格式5059张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):5059标注数量(xml文件个数):5059标注数量(txt文件个数):5059标注类别…...

如何快速搭建Sunshine游戏串流:面向新手的完整指南
如何快速搭建Sunshine游戏串流:面向新手的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾想过在客厅的电视上流畅玩PC游戏,或者在平板上享…...

CentOS 7上编译glibc 2.28踩坑全记录:从gcc、make升级到最终成功
CentOS 7编译glibc 2.28实战:从工具链升级到系统兼容性破解 当你在CentOS 7服务器上部署最新开发工具时,突然弹出/lib64/libc.so.6: version GLIBC_2.28 not found的报错,这就像一记闷棍——系统基础库已无法满足现代软件需求。本文将带你经…...

树莓派CM4刀片服务器设计:从电源管理到集群部署全解析
1. 项目概述:当树莓派计算模块遇上“刀片式”设计如果你和我一样,是个树莓派的老玩家,从最初的Model B一路玩到最新的5代,那你肯定对树莓派计算模块(Compute Module,简称CM)又爱又恨。爱的是它把…...

ComfyUI Manager 架构设计与性能优化:从插件管理到系统集成的完整解决方案
ComfyUI Manager 架构设计与性能优化:从插件管理到系统集成的完整解决方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and e…...