ViT论文Pytorch代码解读
ViT论文代码实现
论文地址:https://arxiv.org/abs/2010.11929
Pytorch代码地址:https://github.com/lucidrains/vit-pytorch
ViT结构图
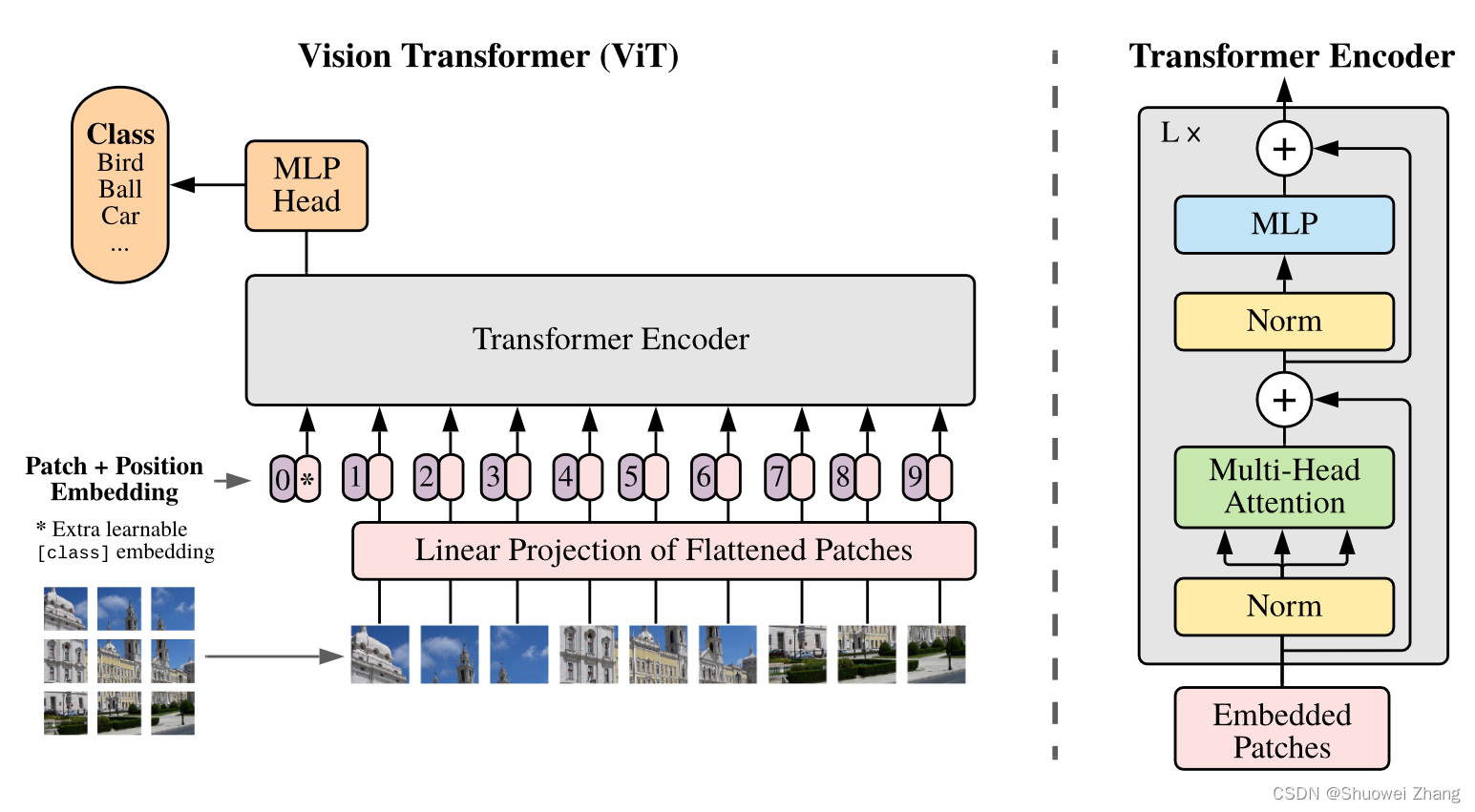
调用代码
import torch
from vit_pytorch import ViTdef test():v = ViT(image_size = 256, patch_size = 32, num_classes = 1000, dim = 1024, depth = 6, heads = 16, mlp_dim = 2048, dropout = 0.1,emb_dropout = 0.1)img = torch.randn(1, 3, 256, 256)preds = v(img)print(preds.shape)assert preds.shape == (1, 1000), 'correct logits outputted'if __name__ == '__main__':test()
ViT结构
class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool='cls', channels=3,dim_head=64, dropout=0., emb_dropout=0.):super().__init__()# 将image_size和patch_size都转换为(height, width)形式image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)# 检查图像尺寸是否可以被patch尺寸整除assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'# 计算图像中的patch数量num_patches = (image_height // patch_height) * (image_width // patch_width)# 计算每个patch的维度(即每个patch的元素数量)patch_dim = channels * patch_height * patch_width# 确保池化方式是'cls'或'mean'assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'# 将图像转换为patch嵌入的操作self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width), # 图像切分重排,后文有注释# 注:此时的维度为[b, h*w/p1/p2, p1*p2*c]:[批处理尺寸、图像中patch的数、每个patch的元素数量]nn.LayerNorm(patch_dim), # 对patch进行层归一化nn.Linear(patch_dim, dim), # 使用线性层将patch的维度从patch_dim转化为dimnn.LayerNorm(dim), # 对结果进行层归一化)self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 初始化位置嵌入self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # 初始化CLS token(用于分类任务的特殊token)self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) # 定义Transformer模块self.pool = pool # 设置池化方式('cls'或'mean')self.to_latent = nn.Identity() # 设置一个恒等映射(在此实现中不改变数据,但可以在子类或其他变种中进行修改)self.mlp_head = nn.Linear(dim, num_classes) # 定义MLP头部,用于最终的分类def forward(self, img):x = self.to_patch_embedding(img) # 第一步,将图片切分为若干小块# 此时维度为:[b, h*w/p1/p2, dim]b, n, _ = x.shape# 第二步,设置位置编码cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b=b) # 将cls_token复制b个 # (为每个输入图像复制一个CLS token,使输入批次中的每张图像都有一个相应的CLS token)x = torch.cat((cls_tokens, x), dim=1) # 将CLS token与patch嵌入合并; cat之后,原来的维度[1,64,1024],就变成了[1,65,1024]x += self.pos_embedding[:, :(n + 1)] # 原数据和位置编码直接进行相加操作,即完成结构图中的【Patch + Position Embedding】操作x = self.dropout(x)# 第三步,Transformer的Encoder结构x = self.transformer(x)x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0] # 根据所选的池化方式进行池化x = self.to_latent(x) # 将数据传递给恒等映射return self.mlp_head(x) # 使用MLP头部进行分类Rearrange解释:
y = x.transpose(0, 2, 3, 1)
可以写成:y = rearrange(x, ‘b c h w -> b h w c’)
关于pos_embedding和cls_token的逻辑讲解:
如图所示,红色框框出的部分。
图像被切分为多个小块之后,经过self.to_patch_embedding中的Rearrange,原本的[b,c,h,w]维度变为[b, h*w/p1/p2, p1*p2*c]。
再经过线性层nn.Linear(patch_dim, dim),维度变为[b, h*w/p1/p2, dim]。
输出结果即为上图中黄色框标出的部分的粉色条(不包括紫色条,是因为此处还没进行Position Embedding操作)。
继续往下走,进行torch.cat((cls_tokens, x), dim=1),此时将x与cls_tokens进行concat操作,得到红色框框出的所有粉色条(在原本的基础上增加了带*号的粉色条)。
记下来的x += self.pos_embedding[:, :(n + 1)]操作就是将x与pos_embedding直接进行相加,用图表示出来就是上图中整个红色框框出的部分了(紫色条就是传说中的pos_embedding)。
举一个有数字的例子:
原本输入图像维度为[1, 3, 256, 256],dim设置为1023,经过self.to_patch_embedding后维度变为:[1,64,1024],cls_tokens的维度为:[1,1,1024],经过concat操作后,x的维度变为[1,65,1024],然后经过pos_embedding加操作后,维度依然是[1,65,1024],因为在设置变量pos_embedding时的维度就是torch.randn(1, num_patches + 1, dim)。
~这个解释应该够清晰了吧!~
Transformer Encoder结构
# 定义前馈神经网络
class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(# Vit_base: dim=768,hidden_dim=3072nn.LayerNorm(dim),nn.Linear(dim, hidden_dim), # 将输入从dim维映射到hidden_dim维nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim), # 将隐藏状态从hidden_dim维映射回到dim维nn.Dropout(dropout) )def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * heads # 64*8=512 # 计算内部维度project_out = not (heads == 1 and dim_head == dim) # 判断是否需要投影输出,投影输出就是是否需要经过线性层# 如果只有一个attention头并且其维度与输入相同则不需要投影输出,否则需要。self.heads = headsself.scale = dim_head ** -0.5 # 缩放因子,通常是头维度的平方根的倒数self.norm = nn.LayerNorm(dim)self.attend = nn.Softmax(dim=-1) # softmax函数用于最后一个维度,计算注意力权重self.dropout = nn.Dropout(dropout)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False) # 一个线性层生成Q, K, V# 判断是否需要投影输出self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):x = self.norm(x)qkv = self.to_qkv(x).chunk(3, dim=-1) # 用线性层生成QKV,并在最后一个维度上分块;相当于写3遍nn.Linearq, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv) # 将[batch_size, sequence_length, heads_dimension] 转换为 [batch_size, number_of_heads, sequence_length, dimension_per_head]dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale # 计算Q和K的点乘,然后进行缩放# q: [batch_size, number_of_heads, sequence_length, dimension_per_head]# k转置后:[batch_size, number_of_heads, sequence_length, dimension_per_head] -> [batch_size, number_of_heads, dimension_per_head, sequence_length]# q和k点乘后:[batch_size, number_of_heads, sequence_length, sequence_length]attn = self.attend(dots) # 使用softmax函数获取注意力权重attn = self.dropout(attn)# 使用注意力权重对V进行加权out = torch.matmul(attn, v) out = rearrange(out, 'b h n d -> b n (h d)') # 使用rearrange函数重新组织输出的维度return self.to_out(out) # 投影输出(如果需要)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.norm = nn.LayerNorm(dim)self.layers = nn.ModuleList([])for _ in range(depth): # depth设置为几层,就重复几次self.layers.append(nn.ModuleList([Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout),FeedForward(dim, mlp_dim, dropout=dropout)]))def forward(self, x):for attn, ff in self.layers: # 残差x = attn(x) + xx = ff(x) + xreturn self.norm(x)
如上就是ViT的整体结构了。
附:完整代码
import torch
from torch import nnfrom einops import rearrange, repeat
from einops.layers.torch import Rearrange# helpersdef pair(t):return t if isinstance(t, tuple) else (t, t)# classesclass FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(# Vit_base: dim=768,hidden_dim=3072nn.LayerNorm(dim),nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads=8, dim_head=64, dropout=0.):super().__init__()inner_dim = dim_head * heads # 64*8=512project_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5self.norm = nn.LayerNorm(dim)self.attend = nn.Softmax(dim=-1)self.dropout = nn.Dropout(dropout)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):x = self.norm(x)qkv = self.to_qkv(x).chunk(3, dim=-1) # 相当于写3遍nn.Linearq, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=self.heads), qkv)# 将[batch_size, sequence_length, heads_dimension] 转换为 [batch_size, number_of_heads, sequence_length, dimension_per_head]dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale# q: [batch_size, number_of_heads, sequence_length, dimension_per_head]# k转置后:[batch_size, number_of_heads, sequence_length, dimension_per_head] -> [batch_size, number_of_heads, dimension_per_head, sequence_length]# q和k点乘后:[batch_size, number_of_heads, sequence_length, sequence_length]attn = self.attend(dots)attn = self.dropout(attn)out = torch.matmul(attn, v)out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout=0.):super().__init__()self.norm = nn.LayerNorm(dim)self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([Attention(dim, heads=heads, dim_head=dim_head, dropout=dropout),FeedForward(dim, mlp_dim, dropout=dropout)]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn self.norm(x)class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool='cls', channels=3,dim_head=64, dropout=0., emb_dropout=0.):super().__init__()image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width)patch_dim = channels * patch_height * patch_widthassert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=patch_height, p2=patch_width), # 图像切分重排nn.LayerNorm(patch_dim),nn.Linear(patch_dim, dim),nn.LayerNorm(dim),)# Rearrange解释:# y = x.transpose(0, 2, 3, 1)# 可以写成:y = rearrange(x, 'b c h w -> b h w c')self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))self.cls_token = nn.Parameter(torch.randn(1, 1, dim))self.dropout = nn.Dropout(emb_dropout)self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)self.pool = poolself.to_latent = nn.Identity()self.mlp_head = nn.Linear(dim, num_classes)def forward(self, img):x = self.to_patch_embedding(img)b, n, _ = x.shapecls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b=b) # 数字编码,将cls_token复制b个x = torch.cat((cls_tokens, x), dim=1) # cat之后,原来的维度[1,64,1024],就变成了[1,65,1024]x += self.pos_embedding[:, :(n + 1)]x = self.dropout(x)x = self.transformer(x)x = x.mean(dim=1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x)return self.mlp_head(x)附:训练代码
model = ViT(dim=128,image_size=224,patch_size=32,num_classes=2,transformer=efficient_transformer,channels=3,
).to(device)# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)for epoch in range(epochs):epoch_loss = 0epoch_accuracy = 0for data, label in tqdm(train_loader):data = data.to(device)label = label.to(device)output = model(data)loss = criterion(output, label)optimizer.zero_grad()loss.backward()optimizer.step()acc = (output.argmax(dim=1) == label).float().mean()epoch_accuracy += acc / len(train_loader)epoch_loss += loss / len(train_loader)with torch.no_grad():epoch_val_accuracy = 0epoch_val_loss = 0for data, label in valid_loader:data = data.to(device)label = label.to(device)val_output = model(data)val_loss = criterion(val_output, label)acc = (val_output.argmax(dim=1) == label).float().mean()epoch_val_accuracy += acc / len(valid_loader)epoch_val_loss += val_loss / len(valid_loader)print(f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n")相关文章:
ViT论文Pytorch代码解读
ViT论文代码实现 论文地址:https://arxiv.org/abs/2010.11929 Pytorch代码地址:https://github.com/lucidrains/vit-pytorch ViT结构图 调用代码 import torch from vit_pytorch import ViTdef test():v ViT(image_size 256, patch_size 32, num_cl…...

Harbor查看密码
已经登录过的harbor 查看密码 cat /root/.docker/config.json {"auths": {"172.28.120.140": {"auth": "YWRtaW43QDIwMTg"}}使用base64解码...

Boa服务器与Cgi简介
Boa是一个单任务的HTTP服务器,Boa只能依次完成用户的请求,而不会fork出新的进程来处理并发连接请求。Boa支持CGI。Boa的设计目标是速度和安全,这很符合嵌入式的需要,他的特点就是可靠性和可移植性。 Boa的作用: 负责h…...
入门vue——创建vue脚手架项目 以及 用tomcat和nginx分别部署vue项目(vue2)
入门vue——创建vue脚手架项目 以及 用tomcat和nginx分别部署vue项目(vue2) 1. 安装npm2. 安装 Vue CLI3. 创建 vue_demo1 项目(官网)3.1 创建 vue_demo1 项目3.1.1 创建项目3.1.2 解决 sudo 问题 3.2 查看创建的 vue_demo1 项目3…...
)
oracle中的(+)
一、()为何意? oracle中的()是一种特殊的用法,()表示外连接,并且总是放在非主表的一方。 二、举例 左外连接: select A.a,B.a from A LEFT JOIN B ON A.bB.b; 等价于 select A.a,B.…...

五种永久免费 内网穿透傻瓜式使用
方法一(使用qydev) 官网:点击访问 1、官网 页面:找到客户端下载 2、找到自己电脑或者运行平台对应的版本(我的是windows 64位) 3、下载完成后解压到 自己熟悉的文件内保存,解压后,暂时不管她,继续第4步 4、登录官网…...
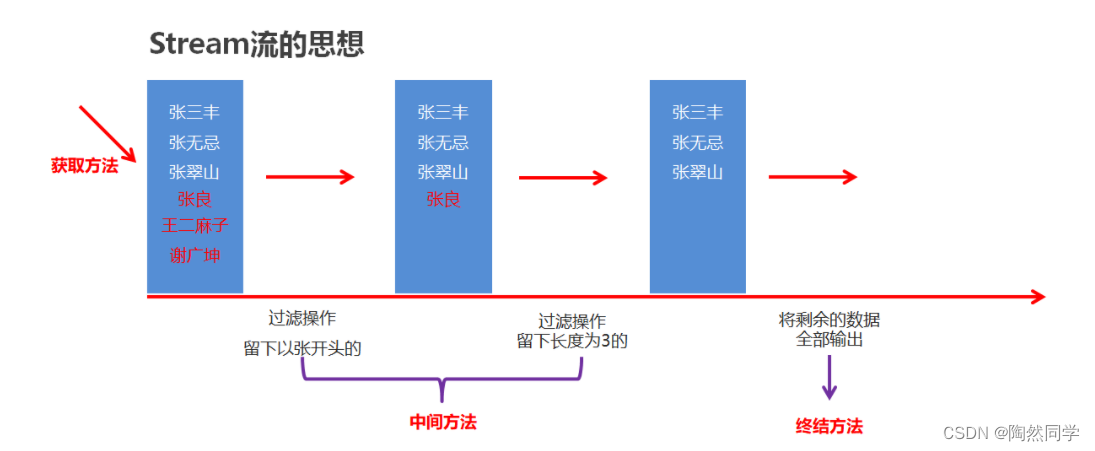
【Java基础增强】Stream流
1.Stream流 1.1体验Stream流【理解】 案例需求 按照下面的要求完成集合的创建和遍历 创建一个集合,存储多个字符串元素 把集合中所有以"张"开头的元素存储到一个新的集合 把"张"开头的集合中的长度为3的元素存储到一个新的集合 遍历上一步得…...

reduxreact-redux
redux redux组成部分:state,action,reducer,store store主要职责: 维持应用的state 提供getState()方法获取state 提供dispatch()方法发送action 通过subscribe()来注册监听 通过subscribe()返回值来注销监听 用法: action:必须要有return返…...

go中的并发
goruntine(协程) 每一个并发的执行单元叫做一个goruntine,要编写一个并发任务,可以在函数名前加go关键字,就能使这个函数以协程的方式运行, 如:go 函数名(函数参数)、 如果函数有返回值&…...
开启EMQX的SSL模式及SSL证书生成流程
生成证书 首先:需要安装Openssl 以下是openssl命令 生成CA证书 1.openssl genrsa -out rootCA.key 2048 2.openssl req -x509 -new -nodes -key rootCA.key -sha256 -days 3650 -subj "/CCN/STShandong/Ljinan/Oyunding/OUplatform/CNrootCA" -out ro…...

4 | Java Spark实现 WordCount
简单的 Java Spark 实现 WordCount 的教程,它将教您如何使用 Apache Spark 来统计文本文件中每个单词的出现次数。 首先,确保您已经安装了 Apache Spark 并设置了运行环境。您需要准备一个包含文本内容的文本文件,以便对其进行 WordCount 分析。 代码 package com.bigdat…...
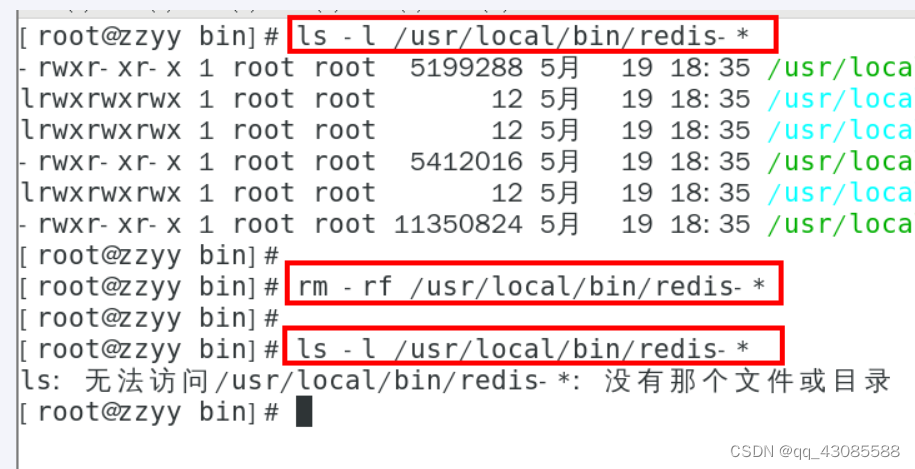
Redis7安装
1. 使用什么系统安装redis 由于企业里面做Redis开发,99%都是Linux版的运用和安装,几乎不会涉及到Windows版,上一步的讲解只是为了知识的完整性,Windows版不作为重点,同学可以下去自己玩,企业实战就认一个版…...

Nginx vs Tomcat:一个高性能Web服务器和Java应用服务器的对决
Nginx vs Tomcat:一个高性能Web服务器和Java应用服务器的对决 Nginx和Tomcat都是常见的Web服务器解决方案,但它们在设计、适用场景以及性能方面存在一些显著差异。本文将比较这两个解决方案,并探讨它们各自的优势。 1. 设计理念 Nginx&…...

终端登录github两种方式
第一种方式 添加token,Setting->Developer Setting 第二种方式SSH 用下面命令查看远程仓库格式 git remote -v 用下面命令更改远程仓库格式 git remote set-url origin gitgithub.com:用户名/仓库名.git 然后用下面命令生成新的SSH秘钥 ssh-keygen -t ed2…...
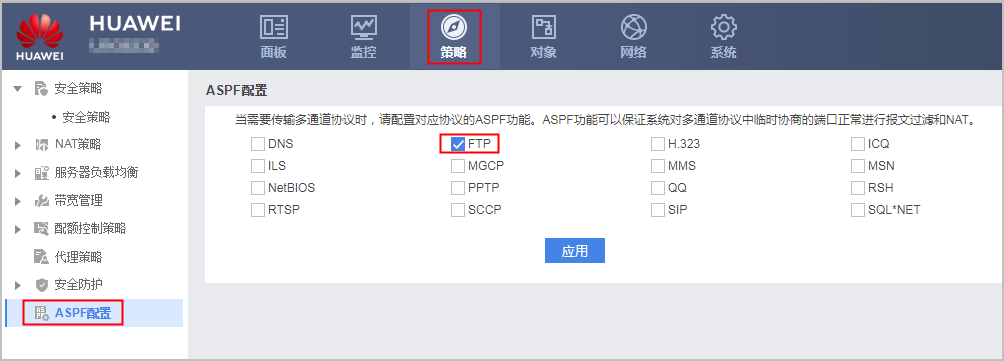
【防火墙】防火墙NAT Server的配置
Web举例:公网用户通过NAT Server访问内部服务器 介绍公网用户通过NAT Server访问内部服务器的配置举例。 组网需求 某公司在网络边界处部署了FW作为安全网关。为了使私网Web服务器和FTP服务器能够对外提供服务,需要在FW上配置NAT Server功能。除了公网…...
《算法竞赛·快冲300题》每日一题:“简化农场”
《算法竞赛快冲300题》将于2024年出版,是《算法竞赛》的辅助练习册。 所有题目放在自建的OJ New Online Judge。 用C/C、Java、Python三种语言给出代码,以中低档题为主,适合入门、进阶。 文章目录 题目描述题解C代码Java代码Python代码 “ 简…...

【二等奖方案】大规模金融图数据中异常风险行为模式挖掘赛题「冀科数字」解题思路
第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束,大赛官方竞赛平台DataFountain(简称DF平台)正在陆续释出各赛题获奖队伍的方案思路,欢迎广大数据科学家交流讨论。 本方案为【大规模金融图数据中…...
方法查询速度比较)
C# List与HashSet的contains()方法查询速度比较
List 和HashSet同时查询40万条数据,谁的效率更高? //**1.下面是List底层源码**public boolean contains(Object o) {//如果查到我们想要查询的值则返回一个true,否则返回false,return indexOf(o) > 0;//这里是调用了indexOf方…...
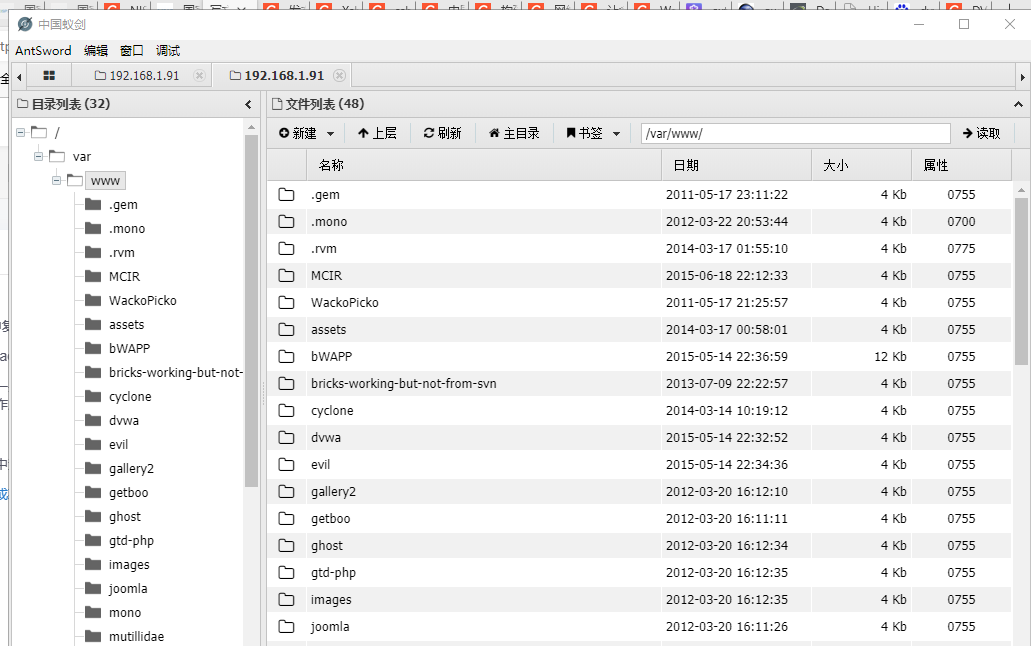
命令执行漏洞复现攻击:识别威胁并加强安全
环境准备 这篇文章旨在用于网络安全学习,请勿进行任何非法行为,否则后果自负。 一、攻击相关介绍 原理 主要是输入验证不严格、代码逻辑错误、应用程序或系统中缺少安全机制等。攻击者可以通过构造特定的输入向应用程序或系统注入恶意代码ÿ…...

Keepalived实现服务器的高可用性
目录 背景方案简介KeepalivedHeartbeat Keepalived技术介绍Keepalived通信方式时间同步 Keepalived配置案例Keepalived日志配置Keepalived服务配置全局配置段VRRP配置段Keepalived服务启动 服务异常检测 背景 在实际应用中,为了提高服务器的高可用性,往…...

Betaflight飞控固件终极指南:2026年开源无人机控制解决方案
Betaflight飞控固件终极指南:2026年开源无人机控制解决方案 【免费下载链接】betaflight Open Source Flight Controller Firmware 项目地址: https://gitcode.com/gh_mirrors/be/betaflight Betaflight是一款专注于飞行性能的开源飞控固件,专为多…...

【AI Agent部署】Claude Code + Ollama/CC Switch 部署指南
Windows11 Claude Code 简单的配置指南方式一和方式二中也是两种Claude Code的安装方式 方式一:NPM 全局安装 依赖Node环境适合原本就用Node开发的用户容易出现全局包路径冲突 方式二:Winget 原生安装(推荐新方案) 无任何依赖&am…...

深度掌握GB28181视频监控API:构建高效国标协议的3个核心技巧
深度掌握GB28181视频监控API:构建高效国标协议的3个核心技巧 【免费下载链接】wvp-GB28181-pro 基于GB28181-2016、部标808、部标1078标准实现的开箱即用的网络视频平台。自带管理页面,支持NAT穿透,支持海康、大华、宇视等品牌的IPC、NVR接入…...

三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南
三小时搞定百年乐谱数字化:Audiveris光学音乐识别技术实战指南 【免费下载链接】audiveris Latest generation of Audiveris OMR engine 项目地址: https://gitcode.com/gh_mirrors/au/audiveris 你是否曾面对堆积如山的古典乐谱束手无策?那些泛黄…...

My-TODOs:免费开源跨平台桌面待办清单应用终极指南
My-TODOs:免费开源跨平台桌面待办清单应用终极指南 【免费下载链接】My-TODOs A cross-platform desktop To-Do list. 跨平台桌面待办小工具 项目地址: https://gitcode.com/gh_mirrors/my/My-TODOs 你是否经常忘记重要任务?是否在多个待办应用间…...

通过Hermes Agent自定义供应商配置接入Taotoken多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Hermes Agent自定义供应商配置接入Taotoken多模型 对于使用Hermes Agent构建智能体应用的开发者而言,直接对接单一…...

内网规划练习
本文基于172.16.0.0/16 内网规划,实现双核心交换机互为备份,整合 VLAN、MSTP、VRRP、Eth-Trunk、DHCP 中继、NAT outbound 等技术,满足 PC 自动获取 IP、内网互通、访问公网及 ISP 环回的全业务需求。一、网络需求与规划内网地址:…...

魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案
魔兽争霸3兼容性修复终极指南:告别闪退卡顿的智能解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3这款经典游戏在…...

HarmonyOS 6 Chip 组件:设置默认后缀图标使用文档
文章目录代码默认后缀图标核心配置1. 启用默认关闭图标2. 显示优先级规则3. 关联配置项代码解析1. 启用默认后缀图标2. 不冲突条件3. 整体结构总结默认后缀图标即 Chip 内置关闭图标,由系统提供样式、尺寸、交互逻辑,无需配置图片资源,只需开…...

3分钟解锁:让魔兽争霸3在现代Windows系统上完美运行的完整指南
3分钟解锁:让魔兽争霸3在现代Windows系统上完美运行的完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Wind…...