R语言对综合社会调查GSS数据进行自举法bootstrap统计推断、假设检验、探索性数据分析可视化|数据分享...
全文链接:https://tecdat.cn/?p=33514
综合社会调查(GSS)是由国家舆论研究中心开展的一项观察性研究。自 1972 年以来,GSS 一直通过收集当代社会的数据来监测社会学和态度趋势。其目的是解释态度、行为和属性的趋势和常量。从 1972 年到 2004 年,GSS 的目标人群是居住在家庭中的成年人(18 岁以上)(点击文末“阅读原文”获取完整代码数据)。
相关视频
本篇文章旨在帮助客户使用R语言对GSS数据进行自举法bootstrap统计推断、假设检验以及探索性数据分析可视化。首先,我们将简要介绍GSS数据集的特点和背景。然后,我们将详细说明自举法bootstrap的原理和应用,以及如何利用R语言进行自举法bootstrap分析。接着,我们将探讨假设检验的概念和步骤,并展示如何使用R语言进行假设检验分析。最后,我们将介绍数据可视化的重要性,并演示如何使用R语言生成图表和可视化结果。
第 1 部分:数据
1994 年以前,全球住户抽样调查几乎每年进行一次(1979 年、1981 年或 1992 年因资金限制除外)。此后,全球抽样调查在偶数年进行,采用双重抽样设计。这主要是通过面对面的访谈完成的。2002 年,全球抽样调查开始使用计算机辅助个人访谈(CAPI)。此外,当难以安排与被抽样调查对象进行面对面面谈时,也会通过电话进行面谈。从 1972 年到 1974 年的调查中,采用了修正概率抽样法(整群配额抽样法)。从 1975 年到 2002 年,全球住户抽样调查采用了完全概率住户抽样,使每个住户被纳入调查的概率相等。因此,全球住户抽样调查对住户一级的变量进行了自加权。为了保持设计的无偏性,全球住户抽样调查开始采用两阶段子抽样设计。
加载数据
load("C:/gs.data")第2部分:研究问题
我们想了解工作满意度与受访者是自营职业者还是为他人工作之间是否存在关系。我们的分析将侧重于《政府统计调查》报告。为此,我们将回答以下问题:
对自己的工作感到满意的个体经营者和对自己的工作感到满意的个体经营者的人口比例是否存在差异?
对工作非常满意的自雇人的平均家庭收入(经通货膨胀调整后)是否高于对工作非常满意的为他人工作的人?
对工作非常满意的自营职业人和对工作非常满意的为他人工作的人的典型家庭收入(如果与平均家庭收入不同)是多少?两者的典型家庭收入是否存在差异?兴趣:就我个人而言,由于我做出了转行的决定,我一直在想,工作满意度是取决于就业状况,还是仅仅取决于所从事工作的性质,而不论是为他人工作还是自营职业。此外,出于好奇,我还想知道自营职业者和为他人工作的成年人对工作真正满意的平均/典型家庭收入。
第 3 部分:探索性数据分析
在本分析中,我们将剔除所有缺失结果(所有 NA)。为便于分析
gssc <- gss %>%filter(year == "2012") %>%select(satjob, wrkslf, coninc, income06)使用 summary(gssc) 查看数据摘要,使用 str(gssc) 查看数据结构。了解变量的组成值(类型和结构)将有助于我们进行分析。
str(gssc)
summary(gssc)
为了回答我们的研究问题,我们希望了解自营职业受访者以及为他人工作的受访者中对其工作感到满意(非常满意和比较满意)和不满意(非常不满意和有点不满意)的人数和比例。
首先,我们要找到计数:
gssc %>% filter(!is.na(wrkslf), !is.na(satjob)) %>% group_by(wrkslf) %>% count(satjob)
然后,我们利用上述结果创建一个或然率表。
conting.table <- as.table(conting)
conting.table
我们可以使用镶嵌图和柱状图来直观地显示上述结果。
mosaicplot(contingcolor = "skyblue")
点击标题查阅往期内容
R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)
左右滑动查看更多
01
02
03
04
gssc %>%filter(!is.na(satjob), !is.na(wrkslf)) %>%ggp.y = element_blank(), axis.ticks.y = element_blank())
超过 50%的个体经营者对自己的工作非常满意,约 50%的为他人工作的人也对自己的工作非常满意。
conting.table %>%prop.taround(3)
自雇受访者中对工作非常不满意的比例很低,仅为 1.3%,而为他人工作的受访者中有 3.4% 对工作非常不满意。
对工作满意的自雇人与对工作满意的为他人工作的人的比例
gssc <- gssc %>% mutate(lsatjob =gssc %>% filter(!is.n
我们感兴趣的是对工作满意的自雇受访者和为他人工作的受访者的比例。
gssc %>% filter(!is.na(wrkslf),= "Satisfied")/n())
收入、就业状况与工作满意度之间的关系
在为他人工作的受访者和自营职业者中,对工作感到满意的人占很大比例。我们将研究收入水平与就业状况(自营职业和为他人工作)对工作满意度的关系。正如我们在研究问题中指出的,我们的重点是对工作非常满意的受访者的平均家庭收入。
Plot1 <- gssc %>%filter(wrkslf == "Self-Employed", !is.na(satjob), !is.na(income06)) %>%
grid.arrange(Plot1, Plot2, ncol = 2,
从柱状图中我们可以看出,对于两种就业状况的受访者而言,随着家庭总收入水平的增加,对工作非常满意和一般满意的受访者人数都在增加,只有少数人对工作 "有点不满意"(收入在 11 万美元以上的自雇受访者除外)。
让我们更清楚地了解家庭总收入中对工作非常满意的自营职业受访者和为他人工作的受访者。
gssc %>%filter(satjob == "Very Satis), axis.ticks.x = element_blank())
我们希望评估对工作非常满意的两种就业状况下的平均家庭收入(通货膨胀调整后)。为此,我们绘制了直方图和方框图,并进行了汇总统计,以确定数据的形状、中心和变异性。
请记住,在 155 名自营职业受访者中,有 97 人对自己的工作非常满意;在 1276 名为他人工作的受访者中,有 626 人对自己的工作非常满意(见上文的或然率表)。
p3 <- gssc %>%filter(satjob == "Very Satisfied", wrkslf == "Self-Employed", !is.na(coninc)) %>%
两个样本分布都向右强烈倾斜,典型的家庭收入将是分布的中位数。IQR 可以最好地解释这两个分布的变异性。
我们绘制一个方框图来直观显示样本的情况:
gssc %>%filter(satjob ==
如前所述,这两个分布均呈强烈的右偏态,离群值均高于 150 000 元。
让我们对这两个样本进行汇总统计。
gssc %>%filter(satjob == "Very Satisfied",nc, 0.75))
gssc %>%filter(satjob == "Very
对工作非常满意的自雇人士的典型家庭收入为 51 705 元,家庭收入变数为 70 855 元。收入较低的 25% 的人的收入为 21,065 元,75% 的人的收入为 91,920 元。他们的平均家庭收入为 70,911.8元。
gssc %>%filter(satjob
count(wrkslf)
为他人工作的人对自己的工作非常满意,其典型家庭收入为 42,130 元,家庭收入变数为 55,535 元,低于自营职业的人。他们中收入最低的 25%的人的收入为 21 065 元(与自雇者相同),75%的人的收入为 76 600 元,低于自雇者。他们的平均家庭收入为 56 165.08 元。
在下一节中,我们将了解对工作非常满意的个体经营者的平均家庭收入是否高于为他人工作且对工作非常满意的个体经营者的平均家庭收入。我们还将进行假设检验,以估计他们的典型收入是否存在差异。
第 4 部分:推断
工作满意度与就业状况之间的关系(自营职业者和为他人工作的受访者) 为了回答 "工作满意度与就业状况之间是否存在关系 "这一问题,我们将对其独立性进行卡方检验(对于两个分类变量,至少有 1 个大于 2 个水平的变量)。
我们将定义检验假设:H0(什么也没发生):工作满意度和就业状况是独立的。工作满意度不会因受访者的就业状况而变化。HA(有事发生):工作满意度和就业状况互为因果。工作满意度确实因受访者的就业状况而异。然后,检查是否存在以下条件
chisq<- chisq.tchisq
在 5%的显着水平上,P 值小于 0.05,因此我们拒绝 H0。因此,数据提供了令人信服的证据,表明工作满意度确实因受访者的就业状况而异,但我们还需要确认所有预期计数是否都有至少 5 个案例。
#Expected Counts
chisq$expected
对工作非常不满意的自雇受访者的预期人数比 5 人少 0.13 人。我们可以忽略它,因为它近似于 5(显著性数字),它只是一个单元格,而我们的数据是一个 2 乘 4 的表格,我们可以接受上面的卡方检验结果,但我们有可能出现类型 1 错误(拒绝零假设,而实际上零假设是真的)。我们可以继续使用推论函数进行详细的卡方分析,或者为了更确定结果,将最后两行折叠为 "不满意 "行,然后进行推论检验,或者直接使用自举检验。我们将采用后两种建议,以确保满足样本量条件并减少类型 1 错误。
bootstrap自举法
由于上述原因,我们将使用引导法来检验我们的假设,即就业状况和工作满意度是相关的。
gssc %>%alternative = "greater", boot_method = "perc", nsim = 15000)
由于 p 值低于 0.05,我们拒绝零假设,从而证实了上述皮尔逊卡方检验的结论。我们将继续使用建议中的另一种方法来确认我们的结果。
因预期计数小于 5 而折叠单元格
创建一个新变量 csatjob 并添加到数据帧 gssc 中。
gssc <- gssc %>% Satisfied", "Dissatisfied")))找出观察到的计数。预期计数和或然率表将显示在我们的 "推断 "结果中。
gssc %>% filter(!is.na(wrkslf), !is.na(csatjob)) %>% group_by(wrkslf) %>% count(csatjob)
因此,我们将继续进行假设检验,即由于所有条件都已满足,就业状况和工作满意度在 5%的显著性水平上存在关联。
gssc %>%filter(!ialternative = "greater")
p 值小于我们之前的结果,因此减少了类型 1 错误的可能性。因此,在 5%的显著水平上,p 值小于 0.05,所以我们拒绝 H0。因此,数据提供了令人信服的证据,证明工作满意度和就业状况如前所述是相互依赖的。
对工作感到满意的自营职业者与对工作感到满意的为他人工作者之间的差异
我们想了解对自己的工作感到满意的自雇人与对自己的工作感到满意的为他人工作的人之间的人口比例是否存在差异。请点击查看上面的数据。
从我们的数据来看,91.6% 的自雇受访者对自己的工作感到满意,87.1% 的为他人工作的受访者对自己的工作感到满意。
首先,我们将使用 95% 的置信区间来估计差异。
相关参数:对工作感到满意的所有自雇人与对工作感到满意的为他人工作的人之间的差异。
点估计值:对工作感到满意的(抽样)自雇受访者与对工作感到满意的(抽样)为他人工作的受访者之间的差异。
我们检查是否满足比较两个独立比例的条件。
独立性:随机抽样:两个人群都是随机抽样的;10% 的受访者对工作满意。
gssc %>%filter(!is.na(lsatj
我们有 95% 的把握认为,对工作感到满意的自雇人的总体比例比对工作感到满意的为他人工作的人的总体比例少 0.27% 到多 9.2%。
那么,根据我们上面计算出的置信区间,我们是否应该预期在对工作感到满意的广大自雇人和对工作感到满意的为他人工作的人的人口比例之间会发现显著差异(在同等显著性水平下)?
p自营职业者 - p其他人 = (-0.0027 , 0.092)
H0:p自营职业者 - 其他人
空值包含在区间内,因此我们无法拒绝 H0。因此,上述问题的答案是否定的。从我们的数据来看,对自己的工作感到满意的自雇人和对自己的工作感到满意的为他人工作的人之间的人口比例没有显著差异。
我们将通过在 5%的显著性水平上进行假设检验来确认上述结果,以评估对工作满意的自雇人和对工作满意的为他人工作的人之间是否存在差异。
让我们为检验定义假设:
H0:p自雇=p其他人。
对工作满意的自雇人与对工作满意的为他人工作的人的人口比例相同。
HA: p= p其他人。
对工作满意的自雇人与对工作满意的为他人工作的人的人口比例存在差异。
然后,检查是否满足进行假设检验(比较两个比例)的推理条件:
独立性:组内满足:随机抽样:两个人群都是随机抽样;两个人群都满足 10%的条件。因此,对工作满意的自雇抽样受访者相互独立,而对工作满意的为他人工作的受访者(抽样)也相互独立:我们预计对工作满意的自雇抽样受访者和对工作满意的为他人工作的受访者(抽样)不会相互依赖。
样本大小/偏斜:我们需要集合比例来检查成功-失败条件(成功条件- n*p^pool >= 10,失败条件- n(1 - p^pool) >= 10)。
phat_pool
155 * phat_pool
155 * (1 - phat_pool)
# Someone else: success
1276 * phat_pool
1276 * (1 - phat_pool)
自营职业者和其他人都符合抽样规模/偏斜条件。我们可以假定,两个比例之差的抽样分布接近正态。
因此,我们可以继续进行假设检验,因为所有条件都已满足。
gssc %>%filter(!is.na(lsatjob), !is.na(wrkslf)) %>%inference(y = lsatjob, x = wrkslf, type = "ht", statistic = "proportion", success = "Satisfied", method = "theoretical", alternative = "twosided")
p 值大于 0.05,因此我们无法拒绝零假设。数据没有提供强有力的证据表明,对工作满意的个体经营者与对工作满意的个体经营者的人口比例不同。这与置信区间法得出的结论一致。
对工作非常满意的自雇人和对工作非常满意的为他人工作的人的平均和典型家庭收入的差异。
我们想了解对工作非常满意的自雇人的平均家庭收入(经通胀调整后)实际上是否高于为他人工作且对工作非常满意的人。请点击查看以上数据。
根据我们的数据,对工作非常满意的自雇受访者的平均家庭收入为 70,911.8 元,而为他人工作且对工作非常满意的受访者的平均家庭收入为 56,165.08 元。
首先,我们将使用 90% 的置信区间来估计差异。我们选择 90% 的置信区间是为了使我们的研究结果与假设检验一致,而假设检验在 5% 的显著水平下是单侧的。
相关参数:对工作非常满意的所有自雇人士与对工作非常满意的为他人工作的自雇人士的平均家庭收入之差。
点估计值:对工作非常满意的抽样自雇人与对工作非常满意的(抽样)为他人工作的人的平均家庭收入之差。
我们检查是否满足比较两个独立均值的条件。
独立性:组内满足:随机抽样:两个人群都是随机抽样;两个人群都满足 10% 的条件。因此,对工作满意的自雇受访者和对工作满意的为他人工作的受访者(样本)的家庭收入是相互独立的:两组之间相互独立(非配对)。
样本大小/偏斜:两个分布都向右强烈倾斜;81 和 578 的样本量使得使用 t 分布对每个均值分别建模是合理的。
所有条件都已满足,因此我们将使用 90% 的置信区间来估计差异。
gssc %>%filter(satjob == "
根据上述结果,我们有 90% 的把握认为,对工作非常满意的广大自雇人的平均家庭收入(经通胀调整后)比对工作非常满意的为他人工作的人的平均家庭收入多 2,635.08 元至 26,858.36 元。
那么,根据上述我们计算出的置信区间,我们是否应该预计对工作非常满意的广大自雇人和对工作非常满意的为他人工作的人的平均家庭收入之间存在显著差异(在同等显著性水平下)?
自营职业者 - 为他人工作者 = (2635.0838 , 26858.362)
该值不在置信区间内;我们拒绝 H0。因此,上述问题的答案是肯定的。从我们的数据来看,对工作非常满意的自雇人的平均家庭收入高于对工作非常满意的为他人工作的人的平均家庭收入。
我们将在 5%的显著性水平上进行假设检验,以评估对工作非常满意的个体经营者的平均家庭收入是否高于对工作非常满意的为他人工作的个体经营者的平均家庭收入,从而证实上述结果。
让我们定义一下检验假设:
H0:自营职业者 = 为他人工作者。对工作非常满意的自雇人的平均家庭收入高于为他人工作且对工作非常满意的自雇人。
HA:自营职业者 > 为他人工作者。对工作非常满意的自雇人的平均家庭收入高于对工作非常满意的为他人工作的人的平均家庭收入。
比较两个独立均值的推论条件已经满足,因此我们继续进行假设检验。
gssc %>%filter(satjob =
p 值小于 0.05,因此我们拒绝零假设。数据提供了令人信服的证据,表明对工作非常满意的个体经营者的平均家庭收入高于为他人工作且对工作非常满意的个体经营者。这与置信区间法得出的结论一致。
对工作非常满意的自雇人与对工作非常满意的为他人工作的人的典型家庭收入对比
如前所述,典型家庭收入就是收入中位数。因此,我们将使用 Bootstrap 方法(用于比较中位数)来估计对工作非常满意的自雇人和对工作非常满意的为他人工作的人的典型家庭收入是否存在差异。
根据我们的数据,对工作非常满意的自雇受访者的典型家庭收入为 51 705 元,而为他人工作且对工作非常满意的受访者的典型家庭收入为 42 130 元。
我们将用 95%的置信区间来估计典型家庭收入的差异,并用标准误差法进行 5%显著水平的假设检验。如前所述,所有条件均已满足。
相关参数:对工作非常满意的所有个体经营者的典型家庭收入之差
点估计值:被抽样调查的对工作非常满意的自雇人的典型家庭收入与被抽样调查的对工作非常满意的为他人工作的人的典型家庭收入之间的差异。
95% 置信区间的bootstrap引导法
gssc %>%filter(satjob =nsim = 15000, boot_method = "se")
根据上述结果,我们有 95% 的把握认为,对工作非常满意的广大自雇人的典型家庭收入(经通胀调整后)比对工作非常满意的为他人工作的人少 4,583.73 元,多 23,733.73 元。
那么,根据上述我们计算出的置信区间,我们是否应该期望在对工作非常满意的广大自雇人和对工作非常满意的为他人工作的人的平均家庭收入之间发现显著差异(在同等显著性水平下)?
Pop_medianself-employed - Pop_mediansomeone else = (-4583.7323 , 23733.7323)
H0:Pop_median-self-employed - Pop_medsomeone else = 0。
0 在置信区间内;我们无法拒绝 H0。因此,上述问题的答案是否定的。从我们的数据来看,对自己的工作非常满意的广大自雇人和对自己的工作非常满意的为他人工作的人的典型家庭收入之间没有显著差异。
我们将在 5%的显著性水平上进行假设检验,利用 Bootstrap 方法来评估对工作非常满意的自雇人和对工作非常满意的为他人工作的人的典型家庭收入是否存在差异,从而证实上述结果。
让我们定义一下检验假设:
H0:Pop_med-self-employed = Pop_medsomeone else。对工作非常满意的自雇人与对工作非常满意的为他人工作的人的典型家庭收入相同。
HA: Pop_med-self-employed != Pop_medsomeone else。对工作非常满意的自雇人与对工作非常满意的为他人工作的人的典型家庭收入存在差异。
gssc %>%filter(satjob =, nsim = 15000, boot_method = "se")
p 值大于 0.05,因此我们无法拒绝零假设。数据没有提供强有力的证据表明,对工作非常满意的个体经营者的典型家庭收入与为他人工作且对工作非常满意的个体经营者的典型家庭收入有所不同。这与上文(自举bootstrap法)置信区间法得出的结论一致。
第五部分:结论
经过分析和推论,我们对 2012 年得出以下结论(如每个推论后所述):
数据提供了令人信服的证据,表明工作满意度确实因受访者的就业状况(自营职业和为他人工作)而异。它们之间存在依赖关系。
数据没有提供有力证据表明,对工作满意的自雇人与对工作满意的为他人工作的人的人口比例不同。
数据提供了令人信服的证据,证明对工作非常满意的自雇人的平均家庭收入高于对工作非常满意的为他人工作的人的平均家庭收入。4 数据没有提供有力证据表明,对工作非常满意的自雇人的典型家庭收入与为他人工作且对工作非常满意的人的典型家庭收入不同。
参考资料
David M Diez, Christopher D Barr and Mine Cetinkaya-Rundel. "OpenIntro Statistics, Third Edition". (2016).
本文中分析的数据分享到会员群,扫描下面二维码即可加群!
点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言对综合社会调查GSS数据进行自举法bootstrap统计推断、假设检验、探索性数据分析可视化》。
点击标题查阅往期内容
数据分享|PYTHON用决策树分类预测糖尿病和可视化实例
基于R语言股票市场收益的统计可视化分析
R语言数据可视化分析案例:探索BRFSS数据
R语言空气污染数据的地理空间可视化和分析:颗粒物2.5(PM2.5)和空气质量指数(AQI)
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言计算资本资产定价模型(CAPM)中的Beta值和可视化
R语言主成分分析(PCA)葡萄酒可视化:主成分得分散点图和载荷图
R语言时变向量自回归(TV-VAR)模型分析时间序列和可视化
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言对布丰投针(蒲丰投针)实验进行模拟和动态可视化生成GIF动画
R语言信用风险回归模型中交互作用的分析及可视化
R语言生存分析可视化分析
R语言线性回归和时间序列分析北京房价影响因素可视化案例
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言动态可视化:绘制历史全球平均温度的累积动态折线图动画gif视频图
R语言动态图可视化:如何、创建具有精美动画的图
R语言中生存分析模型的时间依赖性ROC曲线可视化
![]()
相关文章:
R语言对综合社会调查GSS数据进行自举法bootstrap统计推断、假设检验、探索性数据分析可视化|数据分享...
全文链接:https://tecdat.cn/?p33514 综合社会调查(GSS)是由国家舆论研究中心开展的一项观察性研究。自 1972 年以来,GSS 一直通过收集当代社会的数据来监测社会学和态度趋势。其目的是解释态度、行为和属性的趋势和常量。从 197…...
LeetCode 刷题第四轮 Offer I + 类型题
目录 剑指 Offer 04. 二维数组中的查找 剑指 Offer 29. 顺时针打印矩阵 剑指 Offer 09. 用两个栈实现队列 剑指 Offer 30. 包含min函数的栈 剑指 Offer 10- I. 斐波那契数列 [类型:记忆优化 递归 / 动态规划] 剑指 Offer 10- II. 青蛙跳台阶问题 [类型&am…...
LabVIEW计算测量路径输出端随机变量的概率分布密度
LabVIEW计算测量路径输出端随机变量的概率分布密度 今天,开发算法和软件来解决计量综合的问题,即为特定问题寻找最佳测量算法。提出了算法支持,以便从计量上综合测量路径并确定所开发测量仪器的测量误差。测量路径由串联的几个块组成&#x…...
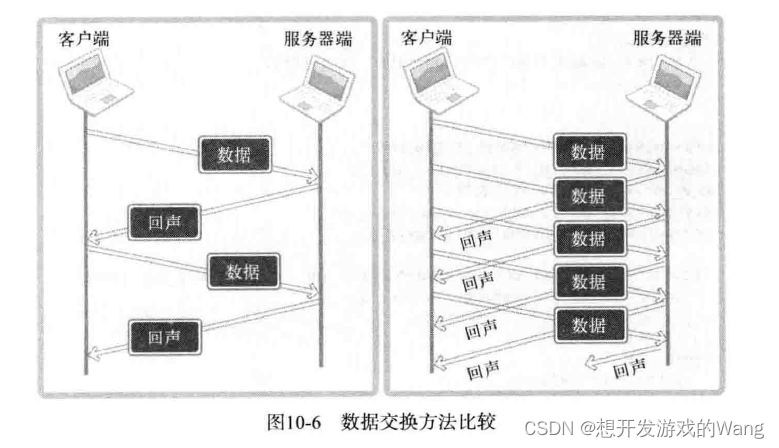
[C++ 网络协议] 多进程服务器端
具有代表性的并发服务器端实现模型和方法: 多进程服务器:通过创建多个进程提供服务。✔ 多路复用服务器:通过捆绑并统一管理I/O对象提供服务。 多线程服务器:通过生成与客户端等量的线程提供服务。 目录 1. 进程的概念及应用 1.…...
李宏毅 2022机器学习 HW2 strong baseline 上分路线
strong baseline上分路线 baseline增加concat_nframes (提升明显)增加batchnormalization 和 dropout增加hidden layer宽度至512 (提升明显) 提交文件命名规则为 prediction_{concat_nframes}[{n_hidden_layers}{dropout}_bn].c…...

伦敦银交易时间怎么选择?
伦敦银和伦敦金都是全球性的交易品种,一般的现货贵金属交易平台,都可以同时经营这两个品种,而且它们的交易时间是一致的,以香港市场的平台为例,基本上交易时间都会从北京周一的早上7点,延续到周六凌晨5点左…...

解决FreeRTOS程序跑不起来,打印调试却提示“Error:..\FreeRTOS\port\RVDS\ARM_CM3\port.c,244“的方法
前言 今天来分享一个不会造成程序编译报错,但会使程序一直跑不起来,并且通过调试会发现有输出错误提示的错误例子分析,话不多说,我们就直接开始分析~ 首先,我们说过这个例子在编译时候没有明示的错误提示,…...
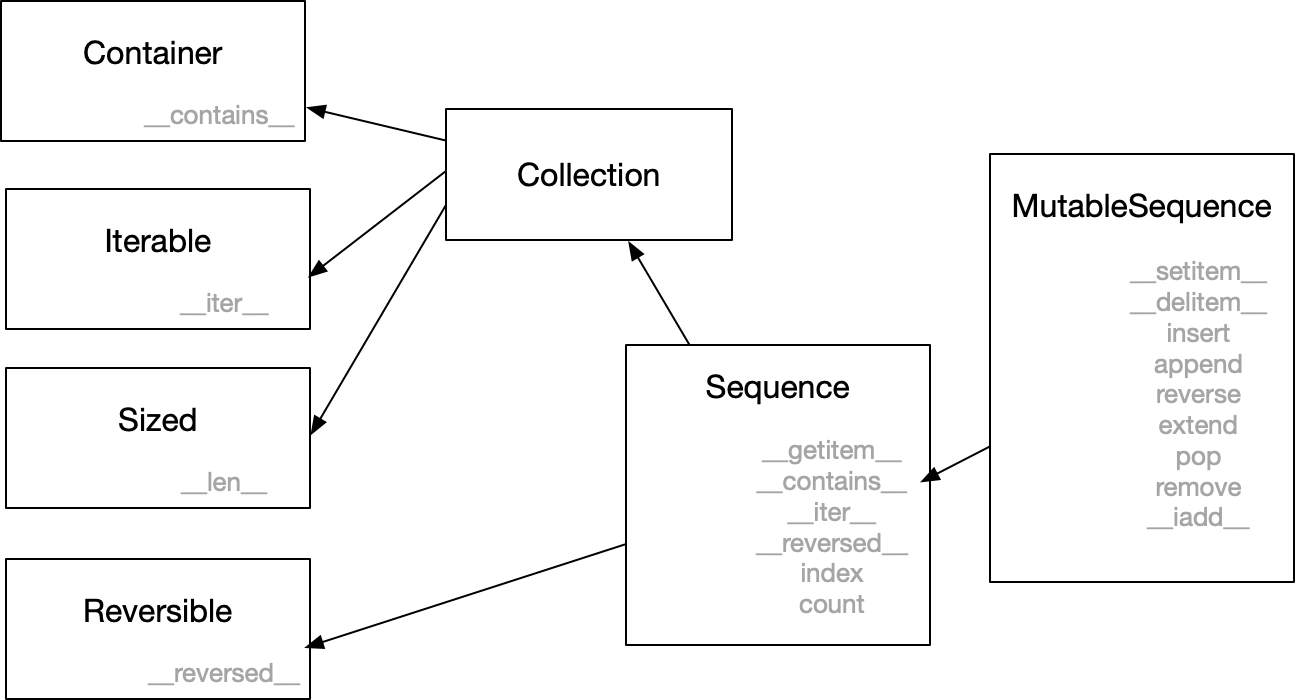
Python序列类型
序列(Sequence)是有顺序的数据列,Python 有三种基本序列类型:list, tuple 和 range 对象,序列(Sequence)是有顺序的数据列,二进制数据(bytes) 和 文本字符串&…...
【python爬虫】5.爬虫实操(歌词爬取)
文章目录 前言项目:寻找周杰伦分析过程代码实现重新分析过程什么是NetworkNetwork怎么用什么是XHR?XHR怎么请求?json是什么?json数据如何解析?实操:完成代码实现 一个总结一个复习 前言 这关让我们一起来寻…...
浅探Android 逆向前景趋势~
前段时间,我和朋友偶然间谈起安卓逆向,他问我安卓逆向具体是什么,能给我们带来什么实质性的东西,我也和朋友大概的说了一下,今天在这里拿出来和大家讨论讨论,也希望帮助大家来了解安卓逆向。 谈起安卓逆向…...
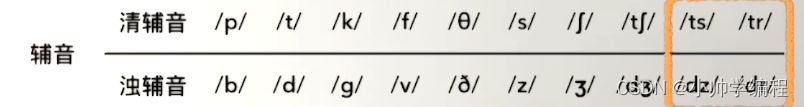
国际音标学习笔记
目录 1.单元音2.双元音3.辅音4.音节5.自然拼读法则5.1辅音字母的音标 1.单元音 我觉得单纯的音标并不好记住,所以就跟着老师整,根据单词记住音标的发音,以下是我的理解 音标对应的单词汉化iis衣əer饿ɔorigin奥u/ʊwoman五ʌart啊eanything哎…...

Azure - AzCopy学习
使用 AzCopy 将本地数据迁移到云存储空间 azcopy login 创建存储账号 ./azcopy login --tenant-id 40242385-c249-4746-95dc-4a0b64d49dc5这里的—tenant-id 在下面的地方查看:目录 ID;需要拥有Storage Blob Data Owner 的权限账号下可能会有很多目录&am…...
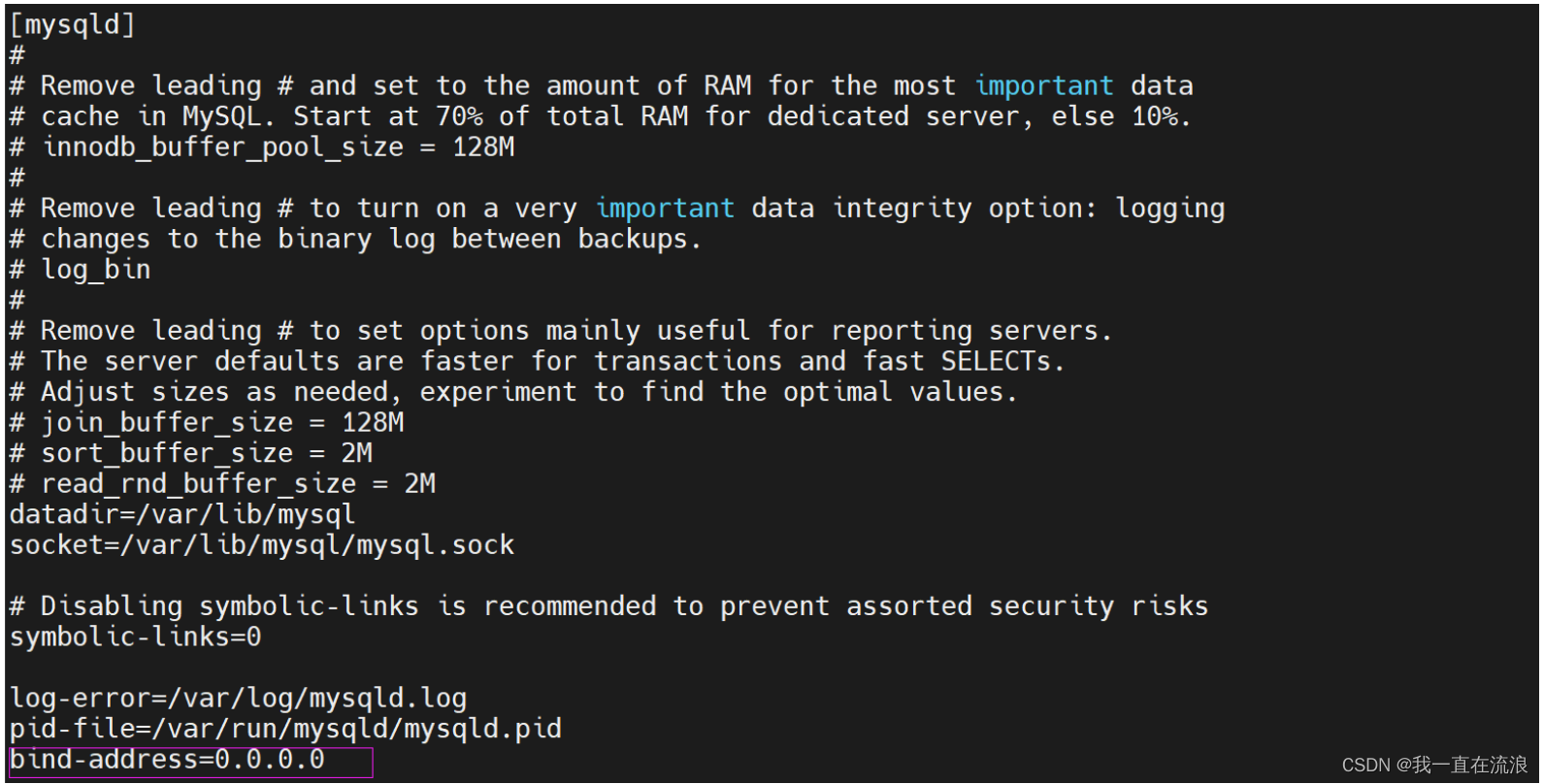
解决无法远程连接MySQL服务的问题
① 设置MySQL中root用户的权限: [rootnginx-dev etc]# mysql -uroot -pRoot123 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO root% IDENTIFIED BY Root123 WITH GRANT OPTION; mysql> select host,user,authentication_string from user; -…...

mybatiplus代码生成器
目录 1.pom文件引入 2.引入模板引擎 3.注意 新版本,老版本配置和用法都不太一样,此处暂不展示;另外也可以尝试一下MyBatis-Flex 总之mybatisplus有的或者收费的,它都有MyBatis-Flex 是什么 - MyBatis-Flex 官方网站 1.pom文件…...
(三、循环存在问题))
leetcode分类刷题:哈希表(Hash Table)(三、循环存在问题)
1、当需要快速判断某元素是否出现在序列中时,就要用到哈希表了。 2、本文针对的总结题型为给定的序列或需要构造的序列中是否存在循环,与 160. 相交链表、 141. 环形链表、142. 环形链表 II的题型一样。 202. 快乐数 这道题还考察如何对正整数求解各个位…...
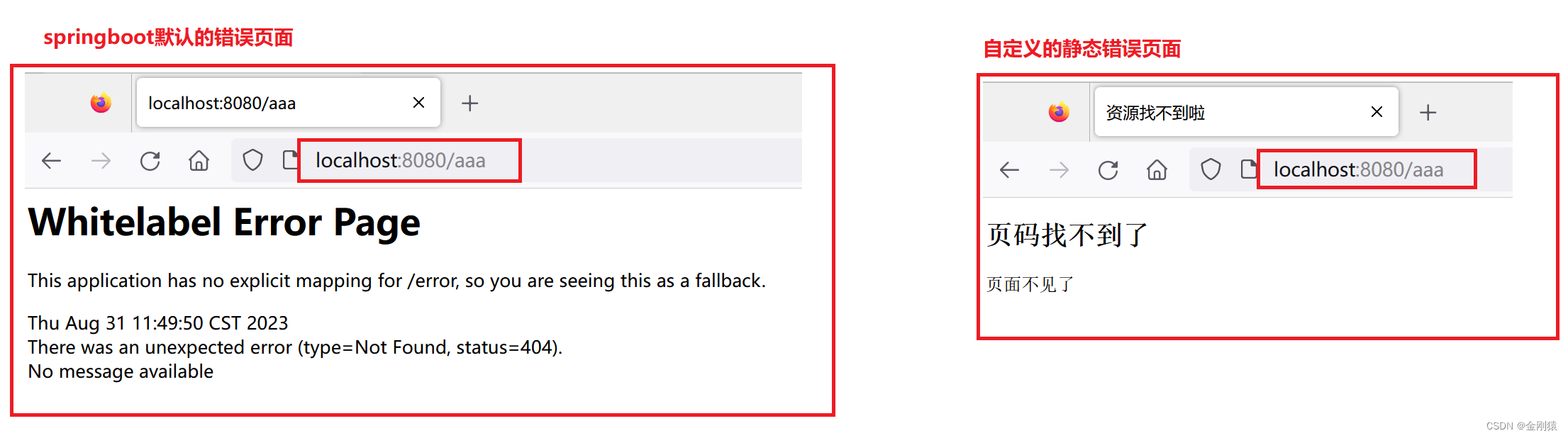
43、基于 springboot 自动配置的 spring mvc 错误处理,就是演示项目报错后,跳转到自定义的错误页面
Spring MVC 的错误处理:基于 SpringBoot 自动配置之后的 Spring MVC 错误处理。 就是访问方法时出错,然后弄个自定义的错误页面进行显示。 ★ 两种错误处理方式 方式一: 基于Spring Boot自动配置的错误处理方式,只要通过属性文件…...

干货分享,现代列式数据库系统如何设计与实现? | StoneData 论文选读
作者:袁洋 | StoneData 技术架构师 审核:王博 论文链接:columnstoresfntdbs.pdf (harvard.edu) 列存四先驱和 MIT 知名教授 Samuel Madden 于 2013 年在某期刊上写的一篇当时列存相关技术的综述。文章还挺全面也很经典,通过剖析三…...

说说构建流批一体准实时数仓
分析&回答 基于 Hive 的离线数仓往往是企业大数据生产系统中不可缺少的一环。Hive 数仓有很高的成熟度和稳定性,但由于它是离线的,延时很大。在一些对延时要求比较高的场景,需要另外搭建基于 Flink 的实时数仓,将链路延时降低…...

北京筑龙受邀出席中物联“采购供应链中国行—走进雄安”活动
日前,“采购供应链中国行—走进雄安”活动在河北雄安新区成功举办,来自30家相关单位的50余名领导和代表参加了本次活动。活动由中国物流与采购联合会公共采购分会主办,中国物流与采购联合会采购委、中国雄安集团有限公司、河北雄安新区招标投…...

【Tkinter界面:练习-01】窗口-部件-布局
一、说明 python在用户界面开发中,其中有QT5,和Tkinter;对于实际项目,界面需要高大上,因此用QT5,对于开发人员的演示程序,或简单程序中,不建议QT5;用Tkinter已经足够。本…...
)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例)
告别ifconfig!用ip命令和ethtool搞定Linux网卡状态排查(附实战案例) 在Linux服务器运维中,网络故障排查是最常见的任务之一。记得去年深夜处理一次线上事故时,面对一台突然失联的数据库服务器,我习惯性地敲…...

历年各批次“重点小巨人”企业全面分析报告
国家级重点专精特新“小巨人”企业是专注于细分市场、创新能力强、市场占有率高、掌握关键核心技术、质量效益优的“排头兵”企业。自政策实施以来,重点“小巨人”已逐步成为我国培育新质生产力、推进新型工业化、提升产业链供应链韧性与安全水平的核心抓手。从工业…...

别再装ModelSim了!用HDLBits网页版5分钟搞定Verilog仿真和波形图
5分钟极速验证:用HDLBits网页版替代传统Verilog仿真工具 在图书馆公用电脑上突然有了个FPGA设计灵感,却发现自己没装ModelSim?公司电脑没有管理员权限,无法安装Vivado Simulator?别急着放弃——打开浏览器,…...

Static-Program-Analysis-Book中间表示解析:构建高效静态分析器的核心技术
Static-Program-Analysis-Book中间表示解析:构建高效静态分析器的核心技术 【免费下载链接】Static-Program-Analysis-Book Getting started with static program analysis. 静态程序分析入门教程。 项目地址: https://gitcode.com/gh_mirrors/st/Static-Program-…...

为什么你的Midjourney作品总像“褪色胶片”?深度解析--seed稳定性+--style-raw+色彩语义嵌入的黄金三角模型
更多请点击: https://kaifayun.com 第一章:为什么你的Midjourney作品总像“褪色胶片”?——问题本质与视觉诊断 你是否反复生成同一组提示词,却总得到泛黄、低对比、边缘发虚的图像?这不是设备问题,也不是…...

进口与国产扁线电感参数PK:Coilcraft SER2918H-103KL vs TONEVEE ZER2918-H103K
在大电流电源设计领域,扁线电感因低直流电阻、高饱和电流及良好的散热性能,成为 DC-DC 转换器、VRM 及工业控制等场景的核心器件。美国 Coilcraft(线艺)作为国际品牌,其 SER2900 系列长期占据高端市场;国产…...

Unity ASE全屏风沙Shader实战:从光学建模到跨平台优化
1. 这不是“加个粒子就完事”的风沙——为什么全屏风沙在Unity里是个硬骨头“Unity之ASE实现全屏风沙效果”——看到这个标题,很多刚接触Shader Graph或Amplify Shader Editor(ASE)的美术向程序员第一反应是:“不就是叠个噪波UV动…...

C语言内联函数与宏的深度解析:性能、安全与工程实践
1. 项目概述:为什么我们需要关注内联与宏?在C语言的日常开发中,尤其是性能敏感或嵌入式领域的项目里,我们经常面临一个选择:为了实现一个简单的、频繁调用的功能,是写一个函数,还是用一个宏来搞…...

ZYNQ平台开源EtherCAT主站部署与实时运动控制优化实践
1. 项目概述与核心价值最近在做一个基于ZYNQ的工业运动控制项目,客户对多轴同步的实时性和抖动要求非常高,传统的脉冲或总线方案在复杂轨迹规划下显得有些力不从心。经过一番调研和选型,最终决定上马EtherCAT总线。作为工业以太网领域的“性能…...

手写一个AI代码审查员:Claude Agent SDK + MCP 深度实战
引言2026年5月,Anthropic做了一件意味深长的事:把 Claude Code SDK 改名为 Claude Agent SDK。改名背后是一个判断——这不再是"帮你写代码的工具",而是一个能自主读代码、分析逻辑、修改文件、跑测试、甚至提PR的AI Agent编排框架…...