基于Django 框架搭建的机器学习在线平台源代码+数据库,实现KNN、ID3、C4.5、SVM、朴素贝叶斯、BP神经网络等算法及流程管理
结果展示(Kmeans):


完整代码下载地址:基于Django 框架搭建的机器学习在线平台源代码+数据库
python机器学习之 K-邻近算法
@简单的理解:[ 采用测量不同特征值之间的距离方法进行分类 ]
-
优点 :精度高、对异常值不敏感、无数据输入假定
-
缺点 :计算复杂度高,空间复杂度高;
-
适应数据范围 :数值型、标称型;
文章目录
- 结果展示(Kmeans):
- python机器学习之 K-邻近算法
- kNN简介
- k-近邻算法的一般流程
- python导入数据
- python处理数据
- 处理步骤
- 决策树
- @[toc]
- 计算给定数据集的信息熵
- 划分数据集
- 构建递归决策树
- 结果输出
- 结果分析
kNN简介
kNN 原理 :存在一个样本数据集合,也称作训练集或者样本集,并且样本集中每个数据都存在标签,即样本集实际上是 每条数据 与 所属分类 的 对应关系。
核心思想 :若输入的数据没有标签,则新数据的每个特征与样本集中数据对应的特征进行比较,该算法提取样本集中特征最相似数据(最近邻)的分类标签。
k :选自最相似的k个数据,通常是不大于20的整数,最后选择这k个数据中出现次数最多的分类,作为新数据的分类。
k-近邻算法的一般流程
sequenceDiagram1.收集数据:可以使用任何方法。
2.准备数据:距离计算所需的数值,最好是结构化的数据格式。
3.分析数据:可以使用任何方法。
4.训练算法:此不走不适用于k-近邻算法。
5.测试算法:计算错误率。
6.使用算法:首先需要输入样本数据和结构化的输出结果,然后运行k-近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类之行后续的处理。
###example1
python导入数据
from numpy import *
import operatordef createDataSet():group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])labels = ['A','A','B','B']return group,labels
python处理数据
#计算已知类别数据集中的点与当前点之间的距离(欧式距离)
#按照距离递增次序排序
#选取与当前点距离最小的K个点
#确定前K个点所在类别的出现频率
#返回前k个点出现频率最高的类别最为当前点的预测分类
#inX输入向量,训练集dataSet,标签向量labels,k表示用于选择最近邻的数目
def clissfy0(inX,dataSet,labels,k):dataSetSize = dataSet.shape[0]diffMat = tile(inX,(dataSetSize,1)) - dataSetsqDiffMat = diffMat ** 0.5sqDistances = sqDiffMat.sum(axis=1)distances = sqDistances ** 0.5sortedDistIndicies = distances.argsort()classCount = {}for i in range(k):voteLabel = labels[sortedDistIndicies[i]]classCount[voteLabel] = classCount.get(voteLabel,0) + 1sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)return sortedClassCount[0][0]
####python数据测试
import kNN
from numpy import *dataSet,labels = createDataSet()
testX = array([1.2,1.1])
k = 3
outputLabelX = classify0(testX,dataSet,labels,k)
testY = array([0.1,0.3])
outputLabelY = classify0(testY,dataSet,labels,k)print('input is :',testX,'output class is :',outputLabelX)
print('input is :',testY,'output class is :',outputLabelY)
####python结果输出
('input is :', array([ 1.2, 1.1]), 'output class is :', 'A')
('input is :', array([ 0.1, 0.3]), 'output class is :', 'B')
###example2使用k-近邻算法改进约会网站的配对效果
处理步骤
1.收集数据:提供文本文件
2.准备数据:使用python解析文本文件
3.分析数据:使用matplotlib画二维扩散图
4.训练算法:此步骤不适用与k-近邻算法
5.测试算法:使用提供的部份数据作为测试样本
6:使用算法:输入一些特征数据以判断对方是否为自己喜欢的类型
####python 整体实现
#coding:utf-8
from numpy import *
import operator
from kNN import classify0
import matplotlib.pyplot as pltdef file2matrmix(filename):fr = open(filename)arrayLines = fr.readlines()numberOfLines = len(arrayLines)returnMat = zeros((numberOfLines,3))classLabelVector = []index = 0for line in arrayLines:line = line.strip()listFromLine = line.split('\t')returnMat[index,:] = listFromLine[0:3]classLabelVector.append(int(listFromLine[-1]))index +=1return returnMat,classLabelVectordef autoNorm(dataSet):minVals = dataSet.min(0)maxVals = dataSet.max(0)ranges = maxVals - minValsnormDataSet = zeros(shape(dataSet))m = dataSet.shape[0]normDataSet = dataSet - tile(minVals,(m,1))normDataSet = normDataSet/tile(ranges,(m,1))return normDataSet,ranges,minValsdef datingClassTest():hoRatio = 0.10datingDataMat,datingLabels = file2matrmix('datingTestSet2.txt')normMat,ranges,minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(m * hoRatio)errorCount = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)print('the classifier came back with: %d, the real answer is: %d' %(classifierResult,datingLabels[i]))if (classifierResult != datingLabels[i]):errorCount += 1.0print('the total error rate is: %f' %(errorCount / float(numTestVecs)))def classifyPerson():resultList = ['not at all','in small doses','in large doses']percentTats = float(raw_input('percentage of time spent playing video games?'))ffMiles = float(raw_input('frequent flier miles earned per year?'))iceCream = float(raw_input('liters of ice cream consumed per year?'))datingDataMat,datingLabels = file2matrmix('datingTestSet2.txt')normMat,ranges,minVals =autoNorm(datingDataMat)inArr = array([ffMiles,percentTats,iceCream])classifierResult = classify0((inArr - minVals) / ranges,normMat,datingLabels,3)print('you will probably like this person:',resultList[classifierResult - 1])datingDataMat,datingLabels = file2matrmix('datingTestSet2.txt')
classifyPerson()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0 * array(datingLabels),15.0 * array(datingLabels))
plt.show()
###K-最近邻算法总结
k近邻算法是最简单有效的分类算法,必须全部保存全部数据集,如果训练数据集很大,必须使用大量的存储空间,同时由于必须对数据集中的每个数据计算距离值,实际使用可能非常耗时。
k近邻算法无法给出任何数据的基础结构信息,我们无法知晓平均实例样本和典型实例样本具有神秘特征。
决策树
###决策树简介
决策树 流程图正方形代表判断模块,椭圆形代表终止模块,从判断模块引出的左右箭头称作分支,它可以到达另一个判断模块活着终止模块。
决策树 [优点]:计算复杂度不高,输出结果易于理解,对于中间值的缺失不敏感,可以处理不相关特征数据。
决策树[缺点]:可能会产生过度匹配的问题。
决策树[适用数据类型]:数值型和标称型。
文章目录
- 结果展示(Kmeans):
- python机器学习之 K-邻近算法
- kNN简介
- k-近邻算法的一般流程
- python导入数据
- python处理数据
- 处理步骤
- 决策树
- @[toc]
- 计算给定数据集的信息熵
- 划分数据集
- 构建递归决策树
- 结果输出
- 结果分析
文章目录
- 结果展示(Kmeans):
- python机器学习之 K-邻近算法
- kNN简介
- k-近邻算法的一般流程
- python导入数据
- python处理数据
- 处理步骤
- 决策树
- @[toc]
- 计算给定数据集的信息熵
- 划分数据集
- 构建递归决策树
- 结果输出
- 结果分析
###决策树的一般流程
(1)收集数据:可以使用任何方法。
(2)准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
(3)分析数据:可以使用任何方法,构造树完成之后,我们需要检验图形是否符合预期。
(4)训练算法:构造树的数据结构。
(5)测试算法:使用经验树计算错误率。
(6)使用算法:使用于任何监督学习算法。
###信息增益
划分数据集的最大原则:将无序的数据集变的有序。
判断数据集的有序程度:信息增益(熵),计算每个特征值划分数据集后获得的信息增益,获得信息增益最高的特征就是最好的选择。
信息增益[公式]:
H = − ∑ i = 1 n p ( x i ) l o g 2 p ( x i ) H = - \sum_{i=1}^np(x_i)log_2p(x_i) H=−i=1∑np(xi)log2p(xi)
其中n是分类的数目。
###python决策树
计算给定数据集的信息熵
from math import logdef calcShannonEnt(dataSet):numEntries = len(dataSet)labelCounts = {}for featVec in dataSet:currentLabel = featVec[-1]if currentLabel not in labelCounts.keys():labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1shannonEnt = 0.0for key in labelCounts:prob = float(labelCounts[key]) / numEntriesshannonEnt -= prob * log(prob,2)return shannonEntdef createDataSet():dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no'],]labels = ['no surfacing','flippers']return dataSet,labelsmyDat,labels = createDataSet()
print(myDat)
print(labels)
shannonEnt = calcShannonEnt(myDat)
print(shannonEnt)
划分数据集
import dtree
def splitDataset(dataSet,axis,value):retDataSet = []for featVec in dataSet:if featVec[axis] == value:reducedFeatVec = featVec[:axis]reducedFeatVec.extend(featVec[axis+1:])retDataSet.append(reducedFeatVec)return retDataSetmyData,labels = dtree.createDataSet()
print(myData)
retDataSet = splitDataset(myData,0,1)
print(retDataSet)
retDataSet = splitDataset(myData,0,0)
print(retDataSet)
####选择最好的数据划分方式
def chooseBestFeatureToSplit(dataSet):numFeatures = len(dataSet[0]) - 1baseEntropy = dtree.calcShannonEnt(dataSet)bestInfoGain = 0.0bestFeature = -1for i in range(numFeatures):featList = [example[i] for example in dataSet]uniqueVals = set(featList)newEntropy = 0.0for value in uniqueVals:subDataSet = splitDataset(dataSet,i,value)prob = len(subDataSet)/float(len(dataSet))newEntropy += prob * dtree.calcShannonEnt(subDataSet)infoGain = baseEntropy - newEntropyif(infoGain > bestInfoGain):bestInfoGain = infoGainbestFeature = ireturn bestFeaturemyData,labels = dtree.createDataSet()
print('myData:',myData)
bestFeature = chooseBestFeatureToSplit(myData)
print('bestFeature:',bestFeature)
#####结果输出
('myData:', [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']])
('bestFeature:', 0)
#####结果分析
运行结果表明第0个特征是最好用于划分数据集的特征,即数据集的的第一个参数,比如在该数据集中以第一个参数特征划分数据时,第一个分组中有3个,其中有一个被划分为no,第二个分组中全部属于no;当以第二个参数分组时,第一个分组中2个为yes,2个为no,第二个分类中只有一个no类。
###递归构建决策树
工作原理:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于2个,因此可能存在大于2个分支的数据集划分,在第一次划分后,数据将被传向树分支的下一个节点,在这个节点上我们可以再次划分数据。
递归条件:程序遍历完所有划分数据集的属性,或者没个分支下的所有实例都具有相同的分类。
构建递归决策树
import dtree
import operator
def majorityCnt(classList):classCount = {}for vote in classList:if vote not in classCount.keys():classCount[vote] = 0classCount[vote] +=1sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)return sortedClassCount[0][0]def createTree(dataSet,labels):classList = [example[-1] for example in dataSet]if classList.count(classList[0]) == len(classList):return classList[0]if len(dataSet[0]) == 1:return majorityCnt(classlist)bestFeat = chooseBestFeatureToSplit(dataSet)bestFeatLabel = labels[bestFeat]myTree = {bestFeatLabel:{}}del(labels[bestFeat])featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:subLabels = labels[:]myTree[bestFeatLabel][value] = createTree(splitDataset(dataSet,bestFeat,value),subLabels)return myTreemyData,labels = dtree.createDataSet()
print('myData:',myData)
myTree = createTree(myData,labels)
print('myTree:',myTree)
结果输出
('myData:', [[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']])
('myTree:', {'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}})
结果分析
myTree 包含了树结构信息的前套字典,第一个关键字no surfacing是第一个划分数据集的特征名称,值为另一个数据字典,第二个关键字是no surfacing特征划分的数据集,是no surfacing的字节点,如果值是类标签,那么该节点为叶子节点,如果值是另一个数据字典,那么该节点是个判断节点,如此递归。
###测试算法:使用决策树执行分类
####使用决策树的分类函数
import treeplotter
import dtree
def classify(inputTree,featLabels,testVec):firstStr = inputTree.keys()[0]secondDict = inputTree[firstStr]featIndex = featLabels.index(firstStr)for key in secondDict.keys():if testVec[featIndex] == key:if type(secondDict[key]).__name__=='dict':classLabel = classify(secondDict[key],featLabels,testVec)else:classLabel = secondDict[key]return classLabelmyDat,labels = dtree.createDataSet()
print(labels)
myTree = myTree = treeplotter.retrieveTree(0)
print(myTree)
print('classify(myTree,labels,[1,0]):',classify(myTree,labels,[1,0]))
print('classify(myTree,labels,[1,1]):',classify(myTree,labels,[1,1]))
#####结果输出
['no surfacing', 'flippers']
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}, 3: 'maybe'}}
('classify(myTree,labels,[1,0]):', 'no')
('classify(myTree,labels,[1,1]):', 'yes')
####存储决策树
由于决策树的构造十分耗时,所以用创建好的决策树解决分类问题可以极大的提高效率。因此需要使用python模块pickle序列化对象,序列化对象可以在磁盘上保存对象,并在需要的地方读取出来,任何对象都可以执行序列化操作。
#使用pickle模块存储决策树
import pickle
def storeTree(inputTree,filename):fw = open(filename,'w')pickle.dump(inputTree,fw)fw.close()def grabTree(filename):fr = open(filename)return pickle.load(fr)
###决策树算法小结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。首先我们需要测量集合数据中的熵即不一致性,然后寻求最优方案划分数据集,直到数据集中的所有数据属于同一分类。决策树的构造算法有很多版本,本文中用到的是ID3 ,最流行的是C4.5和CART。
相关文章:
基于Django 框架搭建的机器学习在线平台源代码+数据库,实现KNN、ID3、C4.5、SVM、朴素贝叶斯、BP神经网络等算法及流程管理
结果展示(Kmeans): 完整代码下载地址:基于Django 框架搭建的机器学习在线平台源代码数据库 python机器学习之 K-邻近算法 简单的理解:[ 采用测量不同特征值之间的距离方法进行分类 ] 优点 :精度高、对异常…...
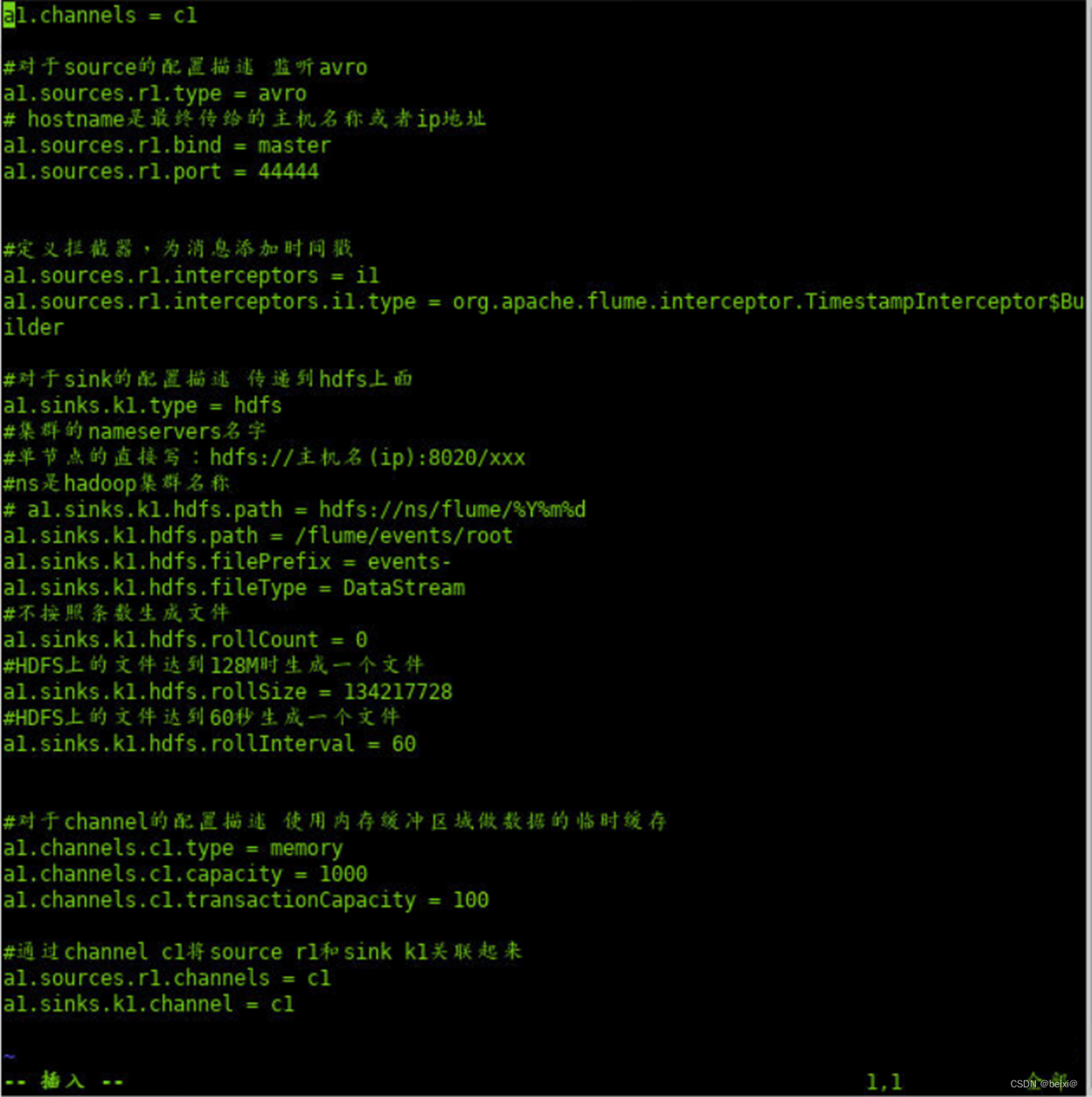
大数据组件-Flume集群环境搭建
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

想系列服务迁移专有云效实操
想系列服务迁移专有云效实操 1注册应用 查看jenkins脚本是否需要修改代码编译路径 gemdale_jenkins/maven3-service/k8s-image/maven3-service-deploy.sh Jenkins上的打包路径 service_tgt_path s e r v i c e w s / t a r g e t / service_ws/target/ servicews/target/ser…...
)
2020 牛客多校第三场 C Operation Love (叉积判断顺逆时针)
2020 牛客多校第三场 (叉积判断顺逆时针) Operation Love 大意: 给出一个手型 , 每个手型都有 20 个点 ,手型有可能旋转后给出 , 但不会放大和缩小 . 手型点集有可能顺时针给出也可能逆时针给出 , 判断给出的是左手还…...

基于OFDM的水下图像传输通信系统matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 function [rx_img] func_TR(tx_img, num_path, pathdelays, pathgains, snr) rng(default); …...
Docsify + Gitalk详细配置过程讲解
💖 作者简介:大家好,我是Zeeland,开源建设者与全栈领域优质创作者。📝 CSDN主页:Zeeland🔥📣 我的博客:Zeeland📚 Github主页: Undertone0809 (Zeeland)&…...

React中的setState的执行机制
文章目录 前言setState是什么?更新类型批量更新后言 前言 在 React 中,setState 是用于更新组件状态的方法。它是一个异步操作 值得注意的是,由于 setState 是异步的,所以在调用 setState 后立即访问 this.state 可能得到的还是旧的状态值。…...
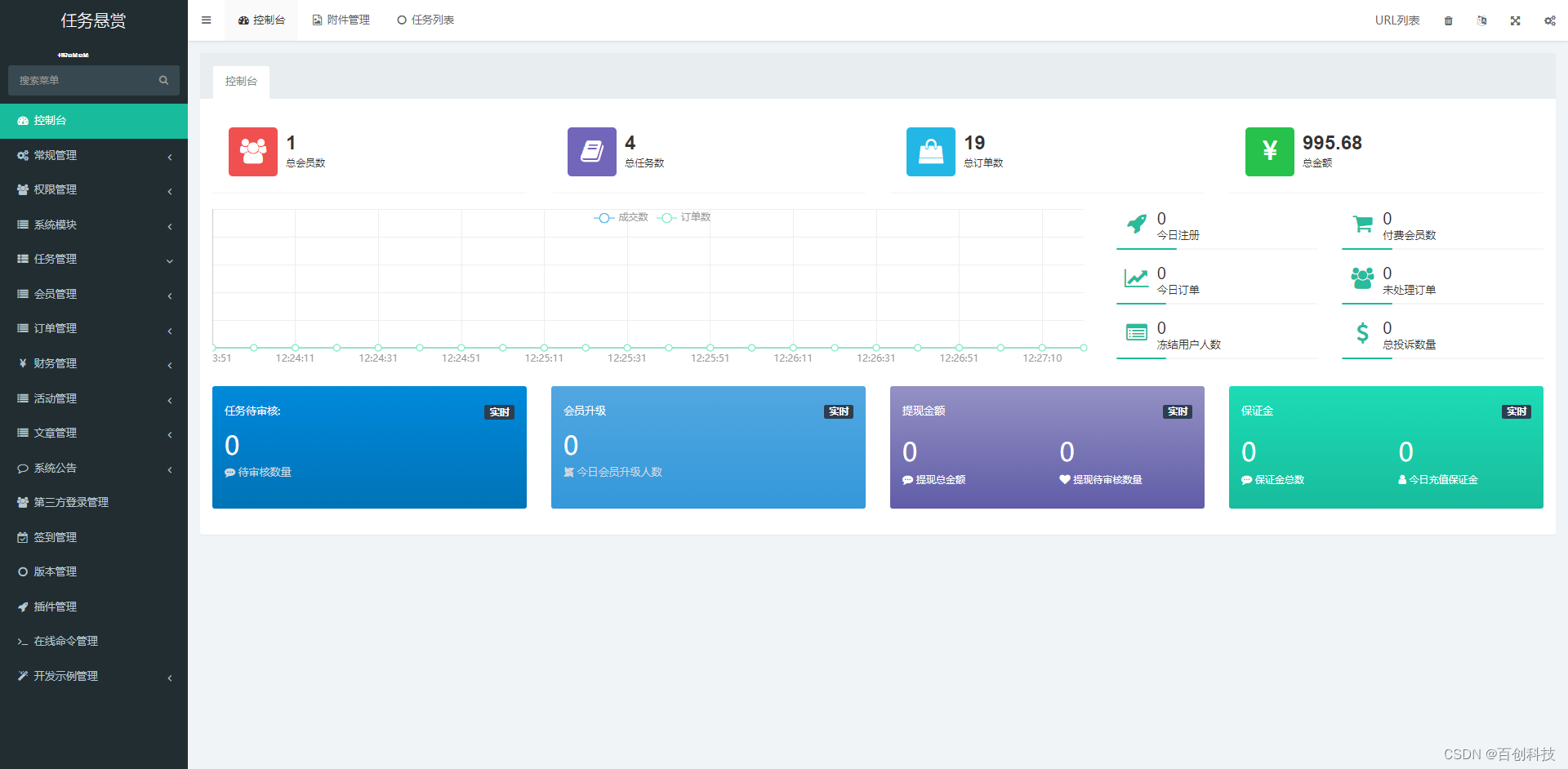
2023最新任务悬赏平台源码uniapp+Thinkphp新款悬赏任务地推拉新充场游戏试玩源码众人帮威客兼职任务帮任务发布分销机
新款悬赏任务地推拉新充场游戏试玩源码众人帮威客兼职任务帮任务发布分销机制 后端是:thinkphpFastAdmin 前端是:uniapp 1.优化首页推荐店铺模块如有则会显示此模块没有则隐藏。 2修复首页公告,更改首页公告逻辑。(后台添加有公…...
微服务事务管理(Dubbo)
Seata 是什么 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。 一、示例架构说明 可在此查看本示例完整代码地址&#x…...

Springboot整合ClickHouse
一、快速开始 1、添加依赖 <dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>clickhouse-jdbc</artifactId><version>0.3.1-patch</version> </dependency> <dependency><groupId>com.alibaba&…...
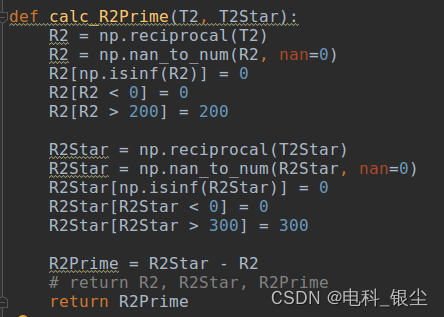
【材料整理】-- Python、Matlab中常用调试代码,持续更新!
文章目录 Python、Matlab中常用调试代码,持续更新!一、Python常用调试代码:二、Matlab常用调试代码: Python、Matlab中常用调试代码,持续更新! 一、Python常用调试代码: 1、保存.mat文件 from…...

什么是同源策略(same-origin policy)?它对AJAX有什么影响?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 同源策略(Same-Origin Policy)与 AJAX 影响⭐ 同源策略的限制⭐ AJAX 请求受同源策略影响⭐ 跨域资源共享(CORS)⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记…...

视频汇聚/视频云存储/视频监控管理平台EasyCVR接入海康SDK协议后无法播放该如何解决?
开源EasyDarwin视频监控/安防监控/视频汇聚EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多路视频流&#…...
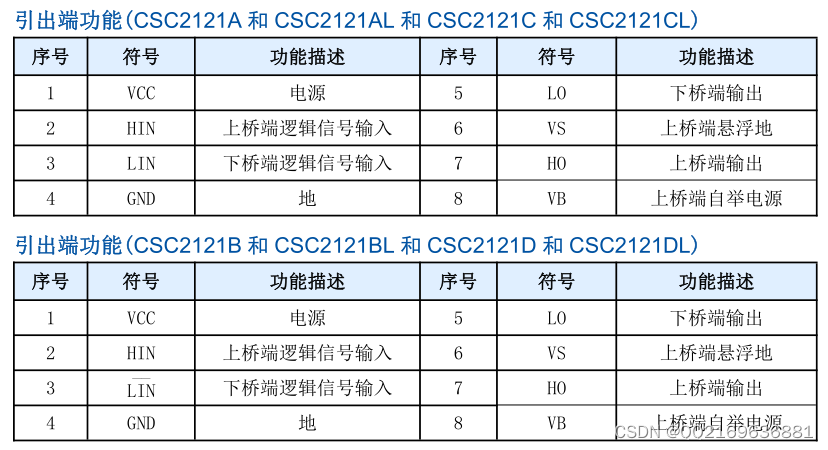
CSC2121A
半桥架构的栅极驱动电路CSC2121A CSC2121系列是一款高性价比的半桥架构的栅极驱动专用电路,用于大功率MOS管、IGBT管栅极驱动。IC内部集成了逻辑信号处理电路、死区时间控制电路、欠压保护电路、电平位移电路、脉冲滤波电路及输出驱动电路,专用于无刷电…...

高级进程编程-系统调用-创建守护进程
系统调用 API 参考:用时现查 如何在Linux下的进行多进程编程(初步) - 知乎 (zhihu.com)。 Linux 下系统调用的三种方法_海风林影的博客-CSDN博客。 linux系统调用(持续更新....)_tiramisu_L的博客-CSDN博客。 通过 glibc 提供的库函数、…...

Redis之发布订阅
一、Redis的发布订阅 Redis的发布与订阅功能由PUBLISH、SUBSCRIBE、PSUBSCRIBE等命令组成。通过执行SUBSCRIBE命令,客户端可以订阅一个或多个频道,从而成为这些频道的订阅者(subscriber):每当有其他客户端向被订阅的频…...

交换机 路由器的常见指令
常用的指令 交换机和路由器是网络中最常见的设备之一,它们都有一些常用的指令。下面是它们的常用指令和解释: 交换机常用指令 show interfaces:显示交换机上的所有接口信息,包括状态、速率、错误信息等。show mac-address-tabl…...

Matlab 基本教程
1 清空环境变量及命令 clear all % 清除Workspace 中的所有变量 clc % 清除Command Windows 中的所有命令 2 变量命令规则 (1)变量名长度不超过63位 (2)变量名以字母开头, 可以由字母、数字和下划线…...

现浇钢筋混泥土楼板施工岗前安全VR实训更安全高效
建筑行业天天与钢筋混凝土砼在,安全施工便成了企业发展的头等大事。 当今社会,人人都奉行生命无价,安全至上。可工地安全事故频繁发生,吞噬掉多少宝贵生命。破坏了多小个家庭?痛定死痛,为了提高施工人员的安全意识。 …...
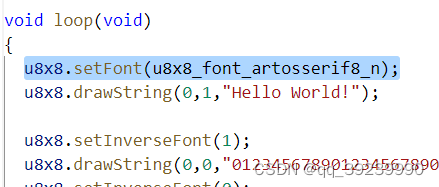
ARDUINO STM32 SSD1306
STM32F103XX系列SPI接口位置 在ARUDINO 下,(不需要设置引脚功能,不需要开启时钟设置,ARDUINO已经帮我们处理了) stm32f103c6t6 flash不足,不足以运行U8G2,产生错误 改用U8X8,后将字体改为u8x8_…...
)
为什么 HDFS 文件一旦写入就不能修改,只能追加或删除(HDFS 设计哲学:一次写入,多次读取)
HDFS采用"一次写入,多次读取"的设计哲学,不支持文件内容修改。这种设计通过简化数据一致性机制、提高吞吐量和优化批处理场景性能,实现了高效的大数据处理。虽然不能直接修改文件,但支持追加、删除和覆盖操作。Hive等工…...
)
ElevenLabs甘肃话语音合成技术解析(西北方言TTS工程化白皮书)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs甘肃话语音合成技术概览 ElevenLabs 是全球领先的语音合成平台,原生支持英语、西班牙语、法语等数十种主流语言,但**不直接内置甘肃话(属中原官话秦陇片&a…...

vscode使用claude code接入deepseek教程
1 在VSCode拓展商城中搜索Claude Code for VS Code,安装2 快捷键Ctrl“,”,进入设置,选择拓展,选择Claude Code。接着往下拉找到Environment Variables,点击下方的“在settings.json中编辑”,将…...

Windows 11系统优化终极指南:用Win11Debloat免费让你的电脑飞起来
Windows 11系统优化终极指南:用Win11Debloat免费让你的电脑飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...
)
自动化测试常用函数(操作测试对象)
上一篇我们学会了怎么用Selenium定位页面元素,接下来就是要对元素进⾏操作了。常⻅的操作有点击、提交、输⼊、清除、获取⽂本。点击:元素.click()输入:元素.send_keys("内容")清空:元素.clear()拿标签间文字:元素.text…...

python代码编译成库
一、项目结构如下:your_project/ ├── match/ │ ├── __init__.py # 空文件,声明为包 │ └── matcher.py # 包含 compete_image 类 ├── stitch/ │ ├── __init__.py # 空文件,声明为包 │ └── total…...

Buck电路纹波太大?可能是你的电容和ESR没选对!三种RC场景下的实战分析与选型指南
Buck电路纹波优化实战:电容与ESR选型的三维决策框架 实验室里示波器屏幕上那条本该平滑的直流输出波形,此刻却像心电图般剧烈起伏——这是每位电源工程师都经历过的"纹波焦虑"时刻。当我们面对Buck电路输出纹波超标问题时,传统定性…...
)
保姆级教程:在Ubuntu 18.04 + ROS Melodic上搞定Intel RealSense D415深度相机驱动(附固件升级避坑指南)
从零搭建ROS Melodic环境:Intel RealSense D415深度相机全流程配置指南 第一次将Intel RealSense D415深度相机连接到Ubuntu 18.04系统时,我遇到了驱动不兼容、固件版本冲突、USB连接不稳定等一系列问题。经过多次尝试和调试,终于总结出一套…...

STL转STEP格式转换终极指南:5分钟掌握专业3D模型转换技巧
STL转STEP格式转换终极指南:5分钟掌握专业3D模型转换技巧 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到过这样的困扰?精心设计的3D打印模型在STL格式下…...
)
别再手动敲命令了!用Kuboard-Spray v1.2.4图形化搞定K8s集群(附CentOS 7.9避坑实录)
图形化利器Kuboard-Spray v1.2.4:三分钟搭建生产级K8s集群的避坑指南 当你在凌晨三点盯着满屏的kubeadm init报错信息时,是否想过Kubernetes集群部署还能更简单?去年我们团队在客户现场部署一套生产环境时,传统命令行方式让我们在…...