Apache Hudi初探(三)(与flink的结合)--flink写hudi的操作(真正的写数据)
背景
在之前的文章中Apache Hudi初探(二)(与flink的结合)–flink写hudi的操作(JobManager端的提交操作) 有说到写hudi数据会涉及到写hudi真实数据以及写hudi元数据,这篇文章来说一下具体的实现
写hudi真实数据
这里的操作就是在HoodieFlinkWriteClient.upsert方法:
public List<WriteStatus> upsert(List<HoodieRecord<T>> records, String instantTime) {HoodieTable<T, List<HoodieRecord<T>>, List<HoodieKey>, List<WriteStatus>> table =initTable(WriteOperationType.UPSERT, Option.ofNullable(instantTime));table.validateUpsertSchema();preWrite(instantTime, WriteOperationType.UPSERT, table.getMetaClient());final HoodieWriteHandle<?, ?, ?, ?> writeHandle = getOrCreateWriteHandle(records.get(0), getConfig(),instantTime, table, records.listIterator());HoodieWriteMetadata<List<WriteStatus>> result = ((HoodieFlinkTable<T>) table).upsert(context, writeHandle, instantTime, records);if (result.getIndexLookupDuration().isPresent()) {metrics.updateIndexMetrics(LOOKUP_STR, result.getIndexLookupDuration().get().toMillis());}return postWrite(result, instantTime, table);}
- initTable
初始化HoodieFlinkTable - preWrite
在这里几乎没什么操作 - getOrCreateWriteHandle
创建一个写文件的handle(假如这里创建的是FlinkMergeAndReplaceHandle),这里会记录已有的文件路径,后续FlinkMergeHelper.runMerge会从这里读取数
注意该构造函数中的init方法,会创建一个ExternalSpillableMap类型的map来存储即将插入的记录,这在后续upsert中会用到 - HoodieFlinkTable.upsert
这里进行真正的upsert操作,会调用FlinkUpsertDeltaCommitActionExecutor.execute,最终会调用到BaseFlinkCommitActionExecutor.execute,从而调用到FlinkMergeHelper.newInstance().runMergepublic void runMerge(HoodieTable<T, List<HoodieRecord<T>>, List<HoodieKey>, List<WriteStatus>> table,..) {final boolean externalSchemaTransformation = table.getConfig().shouldUseExternalSchemaTransformation();HoodieBaseFile baseFile = mergeHandle.baseFileForMerge();if (externalSchemaTransformation || baseFile.getBootstrapBaseFile().isPresent()) {readSchema = baseFileReader.getSchema();gWriter = new GenericDatumWriter<>(readSchema);gReader = new GenericDatumReader<>(readSchema, mergeHandle.getWriterSchemaWithMetaFields());} else {gReader = null;gWriter = null;readSchema = mergeHandle.getWriterSchemaWithMetaFields();}wrapper = new BoundedInMemoryExecutor<>(table.getConfig().getWriteBufferLimitBytes(), new IteratorBasedQueueProducer<>(readerIterator),Option.of(new UpdateHandler(mergeHandle)), record -> {if (!externalSchemaTransformation) {return record;}return transformRecordBasedOnNewSchema(gReader, gWriter, encoderCache, decoderCache, (GenericRecord) record);});wrapper.execute();。。。mergeHandle.close();}- externalSchemaTransformation=
这里有hoodie.avro.schema.external.transformation配置(默认是false)用来把在之前schame下的数据转换为新的schema下的数据 - wrapper.execute()
这里会最终调用到upsertHandle.write(record),也就是UpdateHandler.consumeOneRecord方法被调用的地方
如果keyToNewRecords报班了对应的记录,也就是说会有uodate的操作的话,就插入新的数据,public void write(GenericRecord oldRecord) {...if (keyToNewRecords.containsKey(key)) {if (combinedAvroRecord.isPresent() && combinedAvroRecord.get().equals(IGNORE_RECORD)) {copyOldRecord = true;} else if (writeUpdateRecord(hoodieRecord, oldRecord, combinedAvroRecord)) {copyOldRecord = false;}writtenRecordKeys.add(key); }}
writeUpdateRecord 这里进行数据的更新,并用writtenRecordKeys记录插入的记录 - mergeHandle.close()
这里的writeIncomingRecords会判断如果writtenRecordKeys没有包含该记录的话,就直接插入数据,而不是更新public List<WriteStatus> close() {writeIncomingRecords();...}...protected void writeIncomingRecords() throws IOException {// write out any pending records (this can happen when inserts are turned into updates)Iterator<HoodieRecord<T>> newRecordsItr = (keyToNewRecords instanceof ExternalSpillableMap)? ((ExternalSpillableMap)keyToNewRecords).iterator() : keyToNewRecords.values().iterator();while (newRecordsItr.hasNext()) {HoodieRecord<T> hoodieRecord = newRecordsItr.next();if (!writtenRecordKeys.contains(hoodieRecord.getRecordKey())) {writeInsertRecord(hoodieRecord);}}}
- externalSchemaTransformation=
总结一下upsert的关键点:
mergeHandle.close()才是真正的写数据(insert)的时候,在初始化handle的时候会把记录传导writtenRecordKeys中(在HoodieMergeHandle中的init方法)mergeHandle的write() 方法会在写入数据的时候,如果发现有新的数据,则会写入新的数据(update)
写hudi元数据
这里的操作是StreamWriteOperatorCoordinator.notifyCheckpointComplete方法
public void notifyCheckpointComplete(long checkpointId) {...final boolean committed = commitInstant(this.instant, checkpointId);...
}...
private boolean commitInstant(String instant, long checkpointId){...doCommit(instant, writeResults);...
}...
private void doCommit(String instant, List<WriteStatus> writeResults) {// commit or rollbacklong totalErrorRecords = writeResults.stream().map(WriteStatus::getTotalErrorRecords).reduce(Long::sum).orElse(0L);long totalRecords = writeResults.stream().map(WriteStatus::getTotalRecords).reduce(Long::sum).orElse(0L);boolean hasErrors = totalErrorRecords > 0;if (!hasErrors || this.conf.getBoolean(FlinkOptions.IGNORE_FAILED)) {HashMap<String, String> checkpointCommitMetadata = new HashMap<>();if (hasErrors) {LOG.warn("Some records failed to merge but forcing commit since commitOnErrors set to true. Errors/Total="+ totalErrorRecords + "/" + totalRecords);}final Map<String, List<String>> partitionToReplacedFileIds = tableState.isOverwrite? writeClient.getPartitionToReplacedFileIds(tableState.operationType, writeResults): Collections.emptyMap();boolean success = writeClient.commit(instant, writeResults, Option.of(checkpointCommitMetadata),tableState.commitAction, partitionToReplacedFileIds);if (success) {reset();this.ckpMetadata.commitInstant(instant);LOG.info("Commit instant [{}] success!", instant);} else {throw new HoodieException(String.format("Commit instant [%s] failed!", instant));}} else {LOG.error("Error when writing. Errors/Total=" + totalErrorRecords + "/" + totalRecords);LOG.error("The first 100 error messages");writeResults.stream().filter(WriteStatus::hasErrors).limit(100).forEach(ws -> {LOG.error("Global error for partition path {} and fileID {}: {}",ws.getGlobalError(), ws.getPartitionPath(), ws.getFileId());if (ws.getErrors().size() > 0) {ws.getErrors().forEach((key, value) -> LOG.trace("Error for key:" + key + " and value " + value));}});// Rolls back instantwriteClient.rollback(instant);throw new HoodieException(String.format("Commit instant [%s] failed and rolled back !", instant));}
}主要在commitInstant涉及动的方法doCommit(instant, writeResults)
如果说没有错误发生的话,就继续下一步:
这里的提交过程和spark中一样,具体参考Apache Hudi初探(五)(与spark的结合)
其他
在flink和spark中新写入的文件是在哪里分配对一个的fieldId:
//Flink中
BucketAssignFunction 中processRecord getNewRecordLocation 分配新的 fieldId//Spark中
BaseSparkCommitActionExecutor 中execute方法 中 handleUpsertPartition 涉及到的UpsertPartitioner getBucketInfo方法
其中UpsertPartitioner构造函数中 assignInserts 方法涉及到分配新的 fieldId
相关文章:
(与flink的结合)--flink写hudi的操作(真正的写数据))
Apache Hudi初探(三)(与flink的结合)--flink写hudi的操作(真正的写数据)
背景 在之前的文章中Apache Hudi初探(二)(与flink的结合)–flink写hudi的操作(JobManager端的提交操作) 有说到写hudi数据会涉及到写hudi真实数据以及写hudi元数据,这篇文章来说一下具体的实现 写hudi真实数据 这里的操作就是在HoodieFlinkWriteClient.upsert方法: public …...
)
解释 Git 的基本概念和使用方式(InsCode AI 创作助手)
Git 是一种分布式版本控制系统,它允许多个用户协同工作并对项目进行版本控制。下面是 Git 的基本概念和使用方式: 基本概念: 仓库(Repository):存储代码和版本历史记录的地方。 提交(Commit&a…...

【QT】信号和槽(15)
前面的内容说了很多不同的控件如何使用,今天来看下QT的核心,信号与槽(Signals and slots)! 简单理解一下,就是我们的信号与槽连接上了之后,发射一个信号给到槽,槽函数接收到了这个信…...
)
EFLK日志平台(filebeat-->kafka-->logstash-->es-->kiabana)
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。 安装顺序 1.安装es 7.17.12 2.安装kibana 7.17.12 3.安装x-pack 保证以上调试成功后开始下面…...
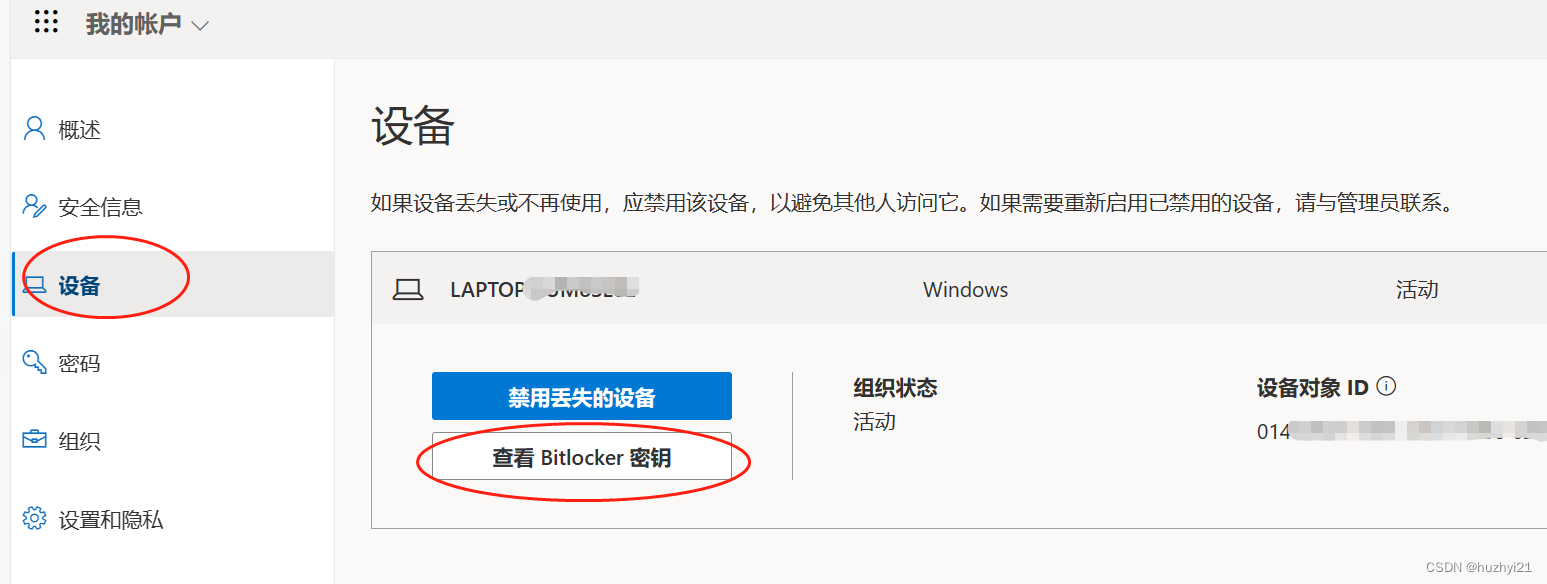
C盘扩容遇到的问题(BitLocker解密、)
120G的C盘不知不觉的就满了,忍了好久终于要动手了。 尽管电脑-管理--磁盘管理里可以进行磁盘大小调整,但由于各盘都在用,不能够连续调整,所以选用DiskGenius。 # DiskGenius调整分区大小遇到“您选择的分区不支持无损调整容量” …...
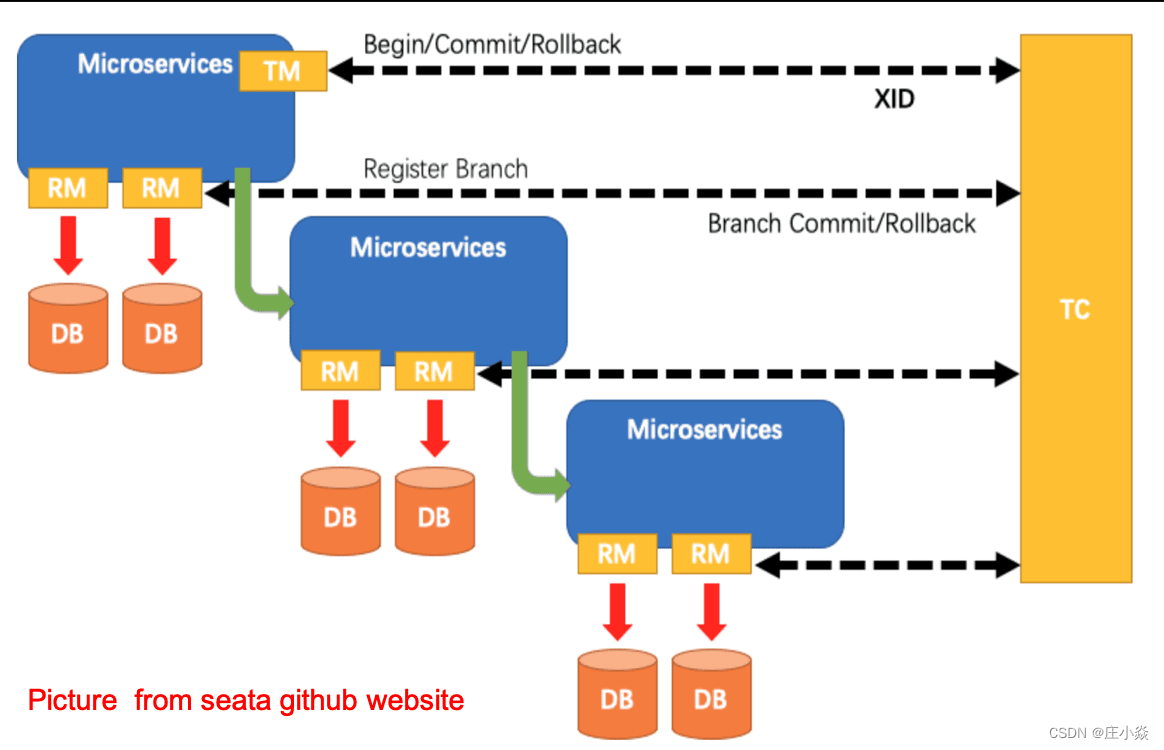
ShardingSphere——柔性事务SEATA原理
摘要 Apache ShardingSphere集成了 SEATA 作为柔性事务的使用方案,本文主要介绍其实现ShardingSphere中柔性事务SEATA原理原理。帮助你更好的理解ShardingSphere原理。同时帮助大家更好的使用柔性事务SEATA原理。 一、Seata柔性事务 Apache ShardingSphere 集成了…...
)
Introducing GlobalPlatform(一篇了解GP)
安全之安全(security)博客目录导读 TEE之GP(Global Platform)认证汇总 目录 一、GP简介 二、GP新的重点领域是什么? 三、认证程序和培训<...

Ubuntu 18.04上无法播放MP4格式视频解决办法
ubuntu18.04系统无法播放MP4格式视频,提示如下图所示: 解决办法: 1、首先,确保ubuntu系统已完全更新。可使用以下命令更新软件包列表:sudo apt update,然后使用以下命令升级所有已安装的软件包:…...

科技驱动产业升级:浅谈制造型企业对MES系统的应用
在科技不断进步的背景下,制造型行业也在持续发展,但随之而来的挑战也不断增加。传统的管理方式已经无法满足企业的需求,因此许多制造型企业开始寻找新的管理模式。制造执行系统(MES)作为先进的制造信息技术之一&#x…...
智能化新十年,“全栈智能”定义行业“Copilot智能助手”
“智能化转型是未来十年中国企业穿越经济周期的利器”,这是联想集团执行副总裁兼中国区总裁刘军在去年联想创新科技大会上做出的判断,而2023年正值第四次工业革命第二个十年的开端,智能化是第四次工业革命的主题。2023年初,基于谷…...

Docker资源控制cgroups
文章目录 一、docker资源控制1、资源控制工具2、Cgroups四大功能 二、CPU 资源控制1、设置CPU使用率上限2、CPU压力测试3、Cgroups限制cpu使用率4、设置CPU资源占用比(设置多个容器时才有效)5、设置容器绑定指定的CPU 三、对内存使用的限制四、对磁盘IO配…...

通过python 获取当前局域网内存在的IP和MAC
通过python 获取当前局域网内存在的ip 通过ipconfig /all 命令获取局域网所在的网段 通过arp -d *命令清空当前所有的arp映射表 循环遍历当前网段所有可能的ip与其ping一遍建立arp映射表 for /L %i IN (1,1,254) DO ping -w 1 -n 1 192.168.3.%i 通过arp -a命令读取缓存的映射表…...

解决D盘的类型不是基本,而是动态的问题
一、正确的图片 1.1图片 1.2本人遇到的问题 二、将动态磁盘 转为基本盘 2.1 基本概念,动态无法转化为基本,不是双向的,借助软件 网址:转换动态磁盘到普通磁盘_检测到计算机本地磁盘为动态分区_卫水金波的博客-CSDN博客 2.2分区…...
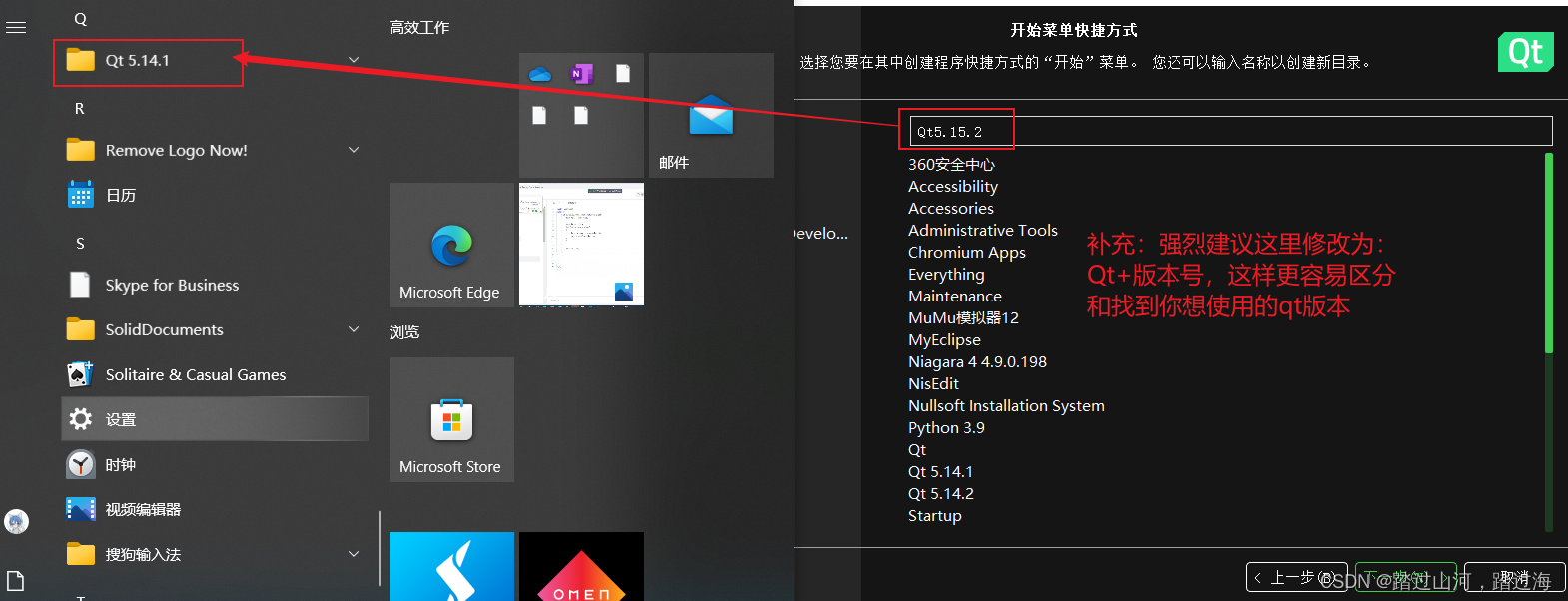
如何判断自己的qt版本呢?
如何判断自己的qt版本呢? 前情提要很简单,按照如下图所示,即可查看当前打开的qtCreator的版本如何打开5.15.2版本的qtCreator呢?安装教程 前情提要 我的电脑已经安装了qt5.14.1,然后我又安装了qt5.15.2,我想尝试一下同一台电脑能否适应两个版本的qt? 当我安装完成qt5.15.2后…...

【文心一言大模型插件制作初体验】制作面试错题本大模型插件
文心一言插件开发初体验 效果图 注意:目前插件仅支持在本地运行,虽然只能自用,但仍然是一个不错的选择。(什么?你说没有用?这不可能!文心一言app可以支持语音,网页端结合手机端就可…...

ROS 2官方文档(基于humble版本)学习笔记(二)
ROS 2官方文档(基于humble版本)学习笔记(二) 理解节点(node)ros2 runros2 node list重映射(remap)ros2 node info 理解话题(topic)rqt_graphros2 topic listr…...

excel中公式结合实际的数据提取出公式计算的分支
要在Excel中使用公式结合实际数据提取分支信息,您可以使用一些文本函数和条件函数来实现这个目标。以下是一个示例,假设您有一个包含银行交易描述的列A,想要从中提取分支信息: 假设交易描述的格式是"分行名称-交易类型"…...

3D模型优化实战:LowPoly、纹理烘焙及格式转换
在快节奏的游戏和虚拟/增强现实 (VR/AR) 世界中,3D 模型的优化在提供引人入胜的体验方面发挥着关键作用。 这门学科不仅仅是创造令人着迷的图形结构; 这是视觉质量和游戏流畅性之间的平衡问题,确保细致而流畅的游戏环境。 通过低多边形建模等…...

genome comparison commend 2 MCMCtree
仅本人练习使用!!后续会逐渐修改!! mcmctree估算物种分歧时间 - 简书 https://www.cnblogs.com/bio-mary/p/12818888.html 估算系统树分歧时间 —— paml.mcmctree,r8s | 生信技工 http://www.chenlianfu.com/?p2948 4. 使用PAM…...

Linux安装JenkinsCLI
项目简介安装目录 mkdir -p /opt/jenkinscli && cd /opt/jenkinscli JenkinsCLI下载 wget http://<your-jenkins-server>/jnlpJars/jenkins-cli.jar # <your-jenkins-server> 替换为你的 Jenkins 服务器地址 JenkinsCLI授权 Dashboard-->Configure Glob…...

告别手动抓瞎:用vmp3-import-fix-x86和Universal Import Fixer搞定VMP3.5壳的IAT修复
VMP3.5壳IAT修复的高效工具链实践指南 逆向工程领域里,VMProtect始终是令人又爱又恨的存在。特别是3.5版本引入的IAT混淆机制,让不少安全研究员在深夜调试时抓狂。传统手动修复不仅耗时耗力,还容易遗漏关键调用。经过多次实战验证࿰…...

超参数调优效率提升300%:Advisor与传统调参工具深度对比
超参数调优效率提升300%:Advisor与传统调参工具深度对比 【免费下载链接】advisor Open-source implementation of Google Vizier for hyper parameters tuning 项目地址: https://gitcode.com/gh_mirrors/ad/advisor 在机器学习模型开发中,超参数…...

高工独家报告|谁在收割2026智驾市场红利?440万辆背后的芯片大洗牌
高工智能汽车研究院发布《2026年中国市场智能汽车SoC芯片行业分析报告》。报告立足中国乘用车市场,基于乘用车前装量产数据库,全面解析智能驾驶SoC(含前视一体机、域控制器及高阶自动驾驶辅助芯片)与智能座舱SoC(含端侧…...

【芯片测试】:SmarTest 开发环境入门
SmarTest 开发环境入门:Eclipse IDE 集成与工作区管理系列: Advantest V93000 SmarTest 8 核心概念解析|第 1 篇(共 8 篇) 适合读者: 初次接触 SmarTest 的测试工程师、ATE 软件开发者前言 很多工程师第一次…...
)
TI C2000 DSP开发笔记:除了IQMath,F28377D的定点计算还有这些隐藏技巧(含FFT/FIR函数初探)
TI C2000 DSP开发笔记:F28377D定点计算高阶技巧与FFT/FIR实战解析 在嵌入式信号处理领域,定点计算一直是平衡性能与精度的关键选择。TMS320F28377D作为TI C2000系列中的高性能DSP控制器,其IQMath库提供的定点计算能力远超基础算术运算范畴。本…...

别再死记硬背POC了!深入理解Struts2漏洞家族史与OGNL表达式攻防演进
从OGNL表达式到漏洞家族史:Struts2安全攻防演进全景剖析 在Java Web安全领域,Struts2框架的漏洞史堪称一部活教材。许多安全工程师能够熟练使用工具复现S2-045、S2-057等著名漏洞,却对漏洞背后的技术原理和演进逻辑一知半解。这种知其然而不知…...

3步解锁安全镜像烧录:Balena Etcher让系统部署零风险
3步解锁安全镜像烧录:Balena Etcher让系统部署零风险 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher 还在为制作系统启动盘而烦恼吗?你是…...

Shader Graph边缘光原理与实战:从菲涅尔效应到世界空间法线
1. 为什么边缘光不是“加个描边”那么简单——从美术需求到Shader本质的错位“给模型加个边缘光”,听起来像Unity编辑器里拖个组件、点几下鼠标就能搞定的事。我第一次接到这个需求时,美术同学在评审会上甩出一张《原神》角色截图,指着雷电将…...

Logback 日志框架使用与配置指南
1. Logback 核心概念与架构 Logback 是 Java 生态中最主流的日志框架之一,其配置体系主要围绕以下三个核心概念展开: Logger(日志记录器):负责捕获日志事件。它通过 name 属性(通常是包名或类名)…...

实测 Taotoken 多模型聚合调用的响应延迟与稳定性体感
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 实测 Taotoken 多模型聚合调用的响应延迟与稳定性体感 在将大模型能力集成到实际应用的过程中,开发者除了关注功能实现…...