Hadoop 3.2.4 集群搭建详细图文教程
目录
一、集群简介
二、Hadoop 集群部署方式
三、集群安装
3.1 集群角色规划
3.2 服务器基础环境准备
3.2.1 环境初始化
3.2.2 ssh 免密登录(在 hadoop01 上执行)
3.2.3 各个节点上安装 JDK 1.8 环境
3.3 安装 Hadoop
3.4 Hadoop 安装包目录结构
3.5 编辑 Hadoop 配置文件
3.5.1 hadoop-env.sh
3.5.2 core-site.xml
3.5.3 hdfs-site.xml
3.5.4 mapred-site.xml
3.5.5 yarn-site.xml
3.5.6 workers
3.6 分发同步安装包
3.7 配置 Hadoop 环境变量
3.8 NameNode format(格式化操作)
3.9 Hadoop 集群启动关闭
3.9.1 手动逐个进程启停
3.9.2 shell 脚本一键启停
3.9.3 Hadoop 集群启动日志
3.10 Hadoop Web UI 页面
3.10.1 配置 windows 域名映射
3.10.3 访问 YARN 集群 UI 页面
四、Hadoop 初体验
4.1 HDFS 初体验
4.1.1 shell 命令操作
4.1.2 Web UI 页面操作
4.2 MapReduce+YARN 初体验
4.2.1 执行 Hadoop 官方自带的 MapReduce 案例
一、集群简介
Hadoop 集群包括两个集群:HDFS 集群、YARN 集群。两个集群逻辑上分离、通常物理上在一起;两个集群都是标准的主从架构集群。
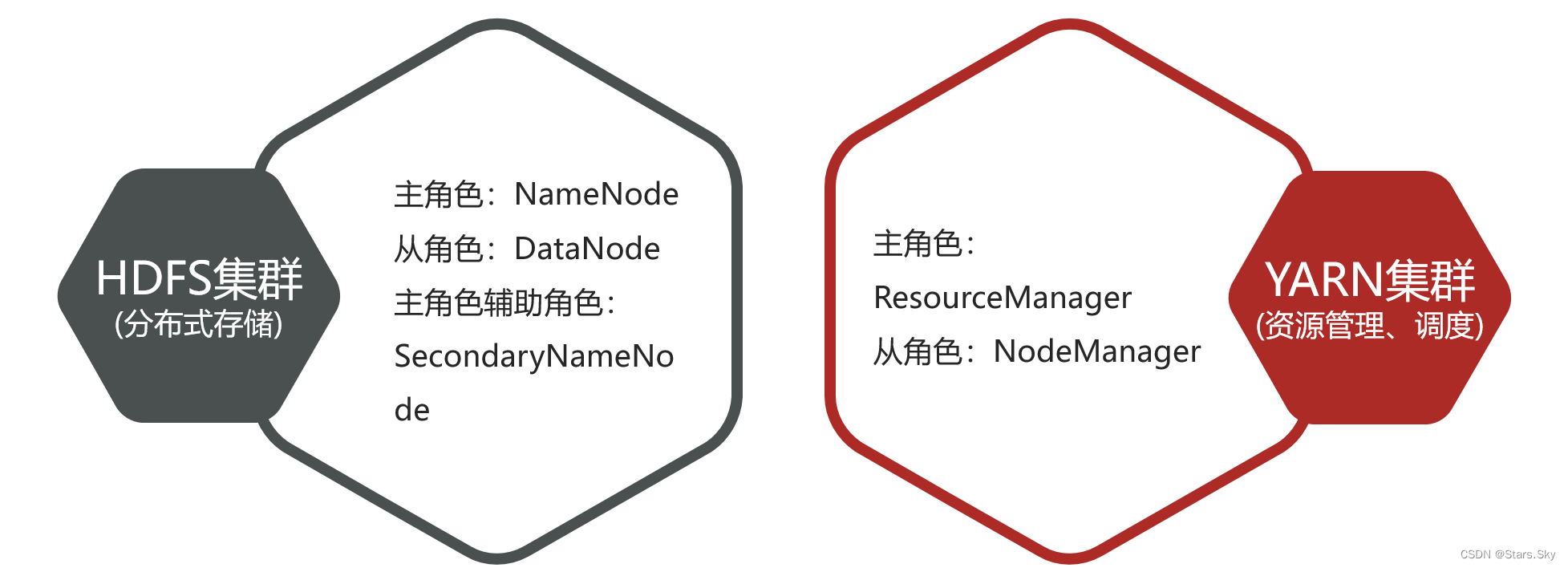
- 逻辑上分离
两个集群互相之间没有依赖、互不影响
- 物理上在一起
某些角色进程往往部署在同一台物理服务器上
- MapReduce 集群呢?
MapReduce 是计算框架、代码层面的组件,没有集群之说
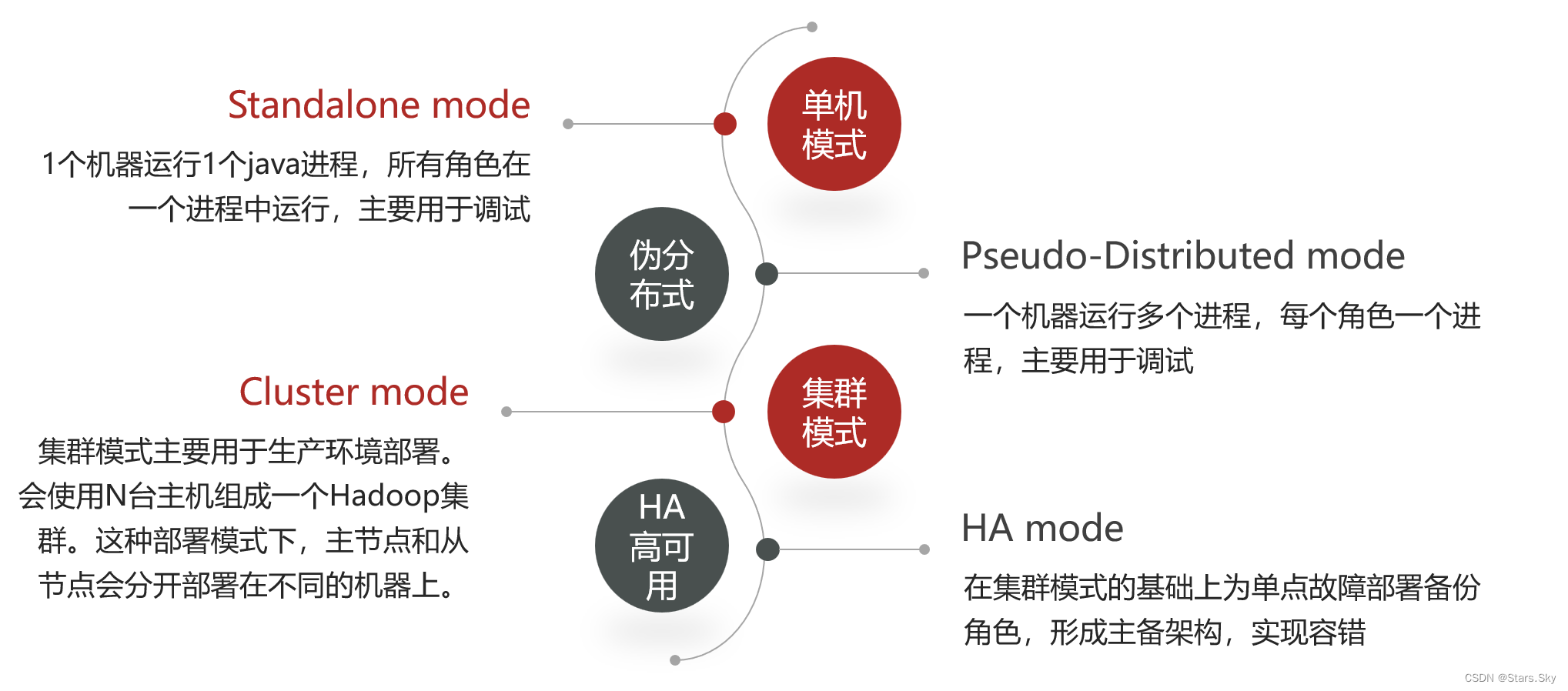
二、Hadoop 集群部署方式
三、集群安装
3.1 集群角色规划
集群模式主要用于生产环境部署,需要多台主机,并且这些主机之间可以相互访问。本次是在 Centos 7.6 搭建集群模式,以三台主机为例,以下是集群规划:
| 各节点 IP | 各节点名称 | 运行角色 | 各节点资源规划 |
| 192.168.170.136 | hadoop01 | NameNode、DataNode、ResourceManager、NodeManager | 2 cpu / 4 G |
| 192.168.170.137 | hadoop02 | SecondaryNamenode、DataNode 、NodeManager | 2 cpu / 4 G |
| 192.168.170.138 | hadoop03 | DataNode 、NodeManager | 2 cpu / 4 G |
3.2 服务器基础环境准备
3.2.1 环境初始化
给三台机器进行环境初始化,特别是需要做好 Hosts 映射:CentOS 7 初始化系统_centos7初始化_Stars.Sky的博客-CSDN博客
3.2.2 ssh 免密登录(在 hadoop01 上执行)
# 4 个 回车,生成公钥、私钥
[root@hadoop01 ~]# ssh-keygen # 推送到各个节点
[root@hadoop01 ~]# ssh-copy-id root@hadoop01
[root@hadoop01 ~]# ssh-copy-id root@hadoop02
[root@hadoop01 ~]# ssh-copy-id root@hadoop03
3.2.3 各个节点上安装 JDK 1.8 环境
Linux 部署 JDK+MySQL+Tomcat 详细过程_一键部署jdk mysql tomcat_Stars.Sky的博客-CSDN博客
3.3 安装 Hadoop
hadoop 3.2.4 官方下载地址:Apache Downloads
# 创建统一工作目录(3 台机器)
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/server # 软件安装路径
[root@hadoop01 ~]# mkdir -p /bigdata/hadoop/data # 数据存储路径
[root@hadoop01 ~]# mkdir -p /bigdata/softwares # 安装包存放路径# 上传、解压安装包(hadoop01)
[root@hadoop01 ~]# cd /bigdata/softwares/
[root@hadoop01 /bigdata/softwares]# ls
hadoop-3.2.4.tar.gz
[root@hadoop01 /bigdata/softwares]# tar -zxvf hadoop-3.2.4.tar.gz -C /bigdata/hadoop/server/
3.4 Hadoop 安装包目录结构
[root@hadoop01 /bigdata/softwares]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# ls
hadoop-3.2.4
[root@hadoop01 /bigdata/hadoop/server]# cd hadoop-3.2.4/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share 3.5 编辑 Hadoop 配置文件
3.5 编辑 Hadoop 配置文件
3.5.1 hadoop-env.sh
文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME 是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# pwd
/bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop # 在文件最后面直接添加下面内容
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hadoop-env.sh
# 配置 JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_381
# 设置用户以执行对应角色 shell 命令
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root3.5.2 core-site.xml
hadoop 的核心配置文件,有默认的配置项 core-default.xml。core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim core-site.xml
<configuration>
<!-- 默认文件系统的名称。通过 URI 中 schema 区分不同文件系统。-->
<!-- file:///本地文件系统 hdfs:// hadoop分布式文件系统 gfs://。-->
<!-- hdfs 文件系统访问地址:http://nn_host:8020。-->
<property><name>fs.defaultFS</name><value>hdfs://hadoop01:8020</value>
</property>
<!-- hadoop 本地数据存储目录 format 时自动生成 -->
<property><name>hadoop.tmp.dir</name><value>/bigdata/hadoop/data/tmp</value>
</property>
<!-- 在 Web UI 访问 HDFS 使用的用户名。-->
<property><name>hadoop.http.staticuser.user</name><value>root</value>
</property>
</configuration>3.5.3 hdfs-site.xml
HDFS 的核心配置文件,主要配置 HDFS 相关参数,有默认的配置项 hdfs-default.xml。hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim hdfs-site.xml
<configuration>
<!-- 设定 SNN 运行主机和端口 -->
<property><name>dfs.namenode.secondary.http-address</name><value>hadoop02:9868</value>
</property>
</configuration>3.5.4 mapred-site.xml
MapReduce 的核心配置文件,Hadoop 默认只有个模板文件 mapred-site.xml.template,需要使用该文件复制出来一份 mapred-site.xml 文件。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim mapred-site.xml
<configuration>
<!-- mr 程序默认运行方式。yarn 集群模式 local 本地模式-->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<!-- MR App Master 环境变量。-->
<property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR MapTask 环境变量。-->
<property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!-- MR ReduceTask 环境变量。-->
<property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>3.5.5 yarn-site.xml
YARN 的核心配置文件,在该文件中的 <configuration> 标签中添加以下配置。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim yarn-site.xml <!-- yarn集群主角色RM运行机器。-->
<property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MR程序。-->
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 每个容器请求的最小内存资源(以MB为单位)。-->
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value>
</property>
<!-- 每个容器请求的最大内存资源(以MB为单位)。-->
<property><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property>
<!-- 容器虚拟内存与物理内存之间的比率。-->
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>4</value>
</property>3.5.6 workers
workers 文件里面记录的是集群主机名。一般有以下两种作用:
- 配合一键启动脚本如 start-dfs.sh、stop-yarn.sh 用来进行集群启动。这时候 slaves 文件里面的主机标记的就是从节点角色所在的机器。
- 可以配合 hdfs-site.xml 里面 dfs.hosts 属性形成一种白名单机制。
dfs.hosts 指定一个文件,其中包含允许连接到 NameNode 的主机列表。必须指定文件的完整路径名,那么所有在 workers 中的主机才可以加入的集群中。如果值为空,则允许所有主机。
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim workers
hadoop01
hadoop02
hadoop033.6 分发同步安装包
在 hadoop01 机器上将 Hadoop 安装包 scp 同步到其他机器:
[root@hadoop01 /bigdata/hadoop]# cd /bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop02:/bigdata/hadoop/server/
[root@hadoop01 /bigdata/hadoop/server]# scp -r hadoop-3.2.4 root@hadoop03:/bigdata/hadoop/server/
3.7 配置 Hadoop 环境变量
在三台机器上配置 Hadoop 环境变量:
[root@hadoop01 /bigdata/hadoop/server]# vim /etc/profile
# hadoop
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin# 重新加载环境变量
[root@hadoop01 /bigdata/hadoop/server]# source /etc/profile# 验证环境变量是否生效
[root@hadoop01 /bigdata/hadoop/server]# hadoop3.8 NameNode format(格式化操作)
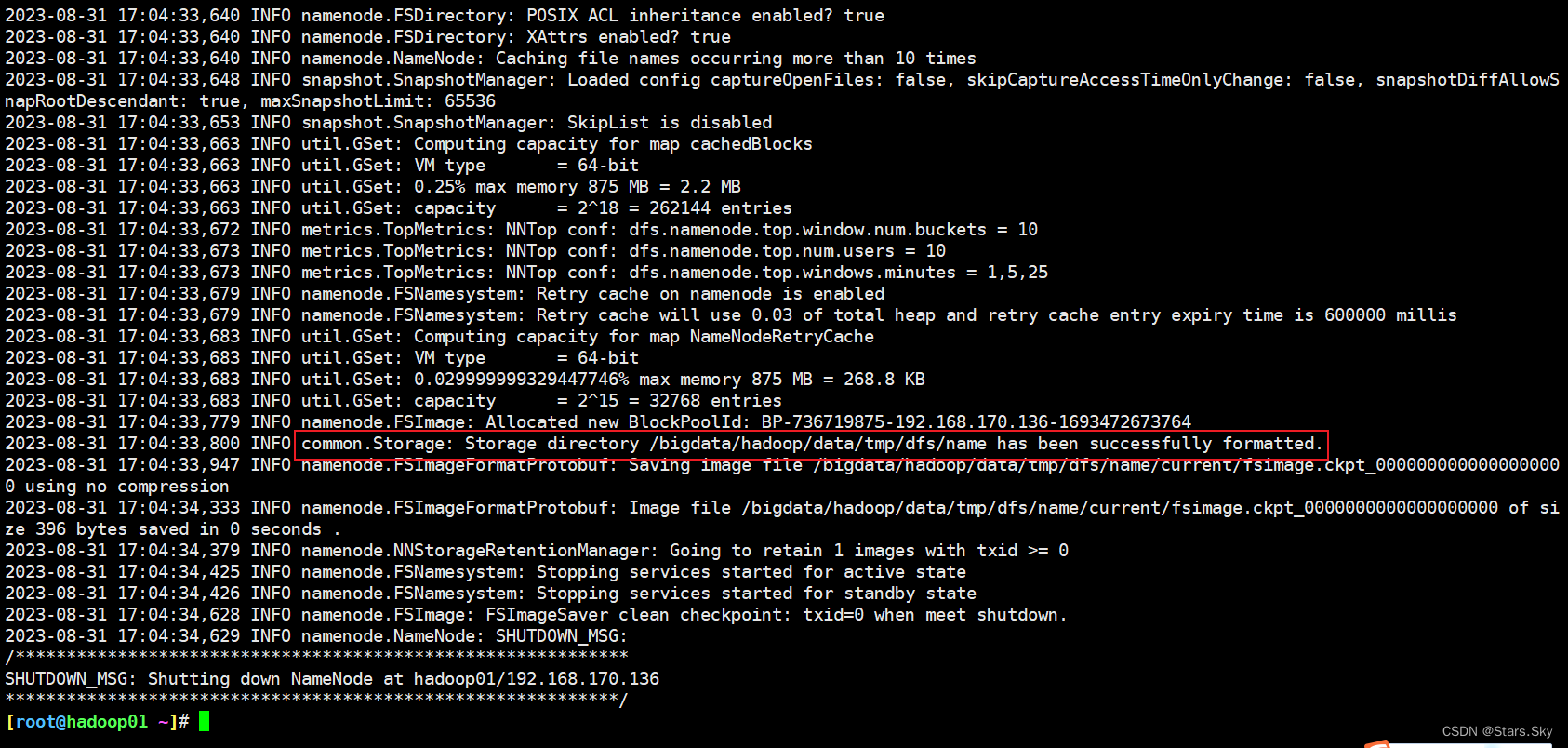
首次启动 HDFS 时,必须对其进行格式化操作。format 本质上是初始化工作,进行 HDFS 清理和准备工作。
# 仅在 hadoop01 上执行
[root@hadoop01 ~]# hdfs namenode -format[root@hadoop01 ~]# ll /bigdata/hadoop/data/tmp/dfs/name/current/
总用量 16
-rw-r--r-- 1 root root 396 8月 31 17:04 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 8月 31 17:04 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 8月 31 17:04 seen_txid
-rw-r--r-- 1 root root 218 8月 31 17:04 VERSION
fsimage_0000000000000000000:这是文件系统镜像(File System Image),包含了HDFS的整个文件系统结构(如目录和文件元数据)的一个快照。fsimage_0000000000000000000.md5:这是与fsimage文件对应的MD5校验和,用于验证文件完整性。seen_txid:这个文件保存了NameNode最后一次启动后见到(即处理过)的最大事务ID。VERSION:这个文件包含了与NameNode相关的各种版本和配置信息,比如Hadoop的版本号,布局版本等。
3.9 Hadoop 集群启动关闭
3.9.1 手动逐个进程启停
每台机器上每次手动启动关闭一个角色进程。
- HDFS 集群
hdfs --daemon start namenode|datanode|secondarynamenodehdfs --daemon stop namenode|datanode|secondarynamenode- YARN 集群
yarn --daemon start resourcemanager|nodemanageryarn --daemon stop resourcemanager|nodemanager3.9.2 shell 脚本一键启停
在 hadoop01 上,使用软件自带的 shell 脚本一键启动。前提:配置好机器之间的 SSH 免密登录和 workers 文件。
- HDFS 集群
start-dfs.sh
stop-dfs.sh
- YARN 集群
start-yarn.sh
stop-yarn.sh
- Hadoop 集群
start-all.sh
stop-all.sh
[root@hadoop01 ~]# start-all.sh
Starting namenodes on [hadoop01]
上一次登录:五 9月 1 14:24:35 CST 2023pts/0 上
Starting datanodes
上一次登录:五 9月 1 14:25:14 CST 2023pts/0 上
Starting secondary namenodes [hadoop02]
上一次登录:五 9月 1 14:25:17 CST 2023pts/0 上
Starting resourcemanager
上一次登录:五 9月 1 14:25:23 CST 2023pts/0 上
Starting nodemanagers
上一次登录:五 9月 1 14:25:30 CST 2023pts/0 上3.9.3 Hadoop 集群启动日志
# 启动完毕之后可以使用 jps 命令查看进程是否启动成功
[root@hadoop01 ~]# jps
22337 NodeManager
21798 DataNode
22203 ResourceManager
22669 Jps
21662 NameNode[root@hadoop02 ~]# jps
21114 NodeManager
21005 DataNode
21213 Jps[root@hadoop03 ~]# jps
21010 DataNode
21219 Jps
21119 NodeManager# Hadoop 启动日志
[root@hadoop01 ~]# ll /bigdata/hadoop/server/hadoop-3.2.4/logs/
总用量 184
-rw-r--r-- 1 root root 36069 8月 31 17:54 hadoop-root-datanode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-datanode-hadoop01.out
-rw-r--r-- 1 root root 43819 8月 31 17:54 hadoop-root-namenode-hadoop01.log
-rw-r--r-- 1 root root 692 8月 31 17:54 hadoop-root-namenode-hadoop01.out
-rw-r--r-- 1 root root 40045 8月 31 17:55 hadoop-root-nodemanager-hadoop01.log
-rw-r--r-- 1 root root 2264 8月 31 17:55 hadoop-root-nodemanager-hadoop01.out
-rw-r--r-- 1 root root 47741 8月 31 17:55 hadoop-root-resourcemanager-hadoop01.log
-rw-r--r-- 1 root root 2280 8月 31 17:54 hadoop-root-resourcemanager-hadoop01.out
-rw-r--r-- 1 root root 0 8月 31 17:04 SecurityAuth-root.audit
drwxr-xr-x 2 root root 6 8月 31 17:54 userlogs3.10 Hadoop Web UI 页面
3.10.1 配置 windows 域名映射
- 以管理员身份打开 C:\Windows\System32\drivers\etc 目录下的 hosts 文件
- 在文件最后添加以下映射域名和 ip 映射关系

3.10.2 访问 HDFS 集群 UI 页面
地址:http://namenode_host:9870
其中 namenode_host 是 namenode 运行所在机器的主机名或者 ip。
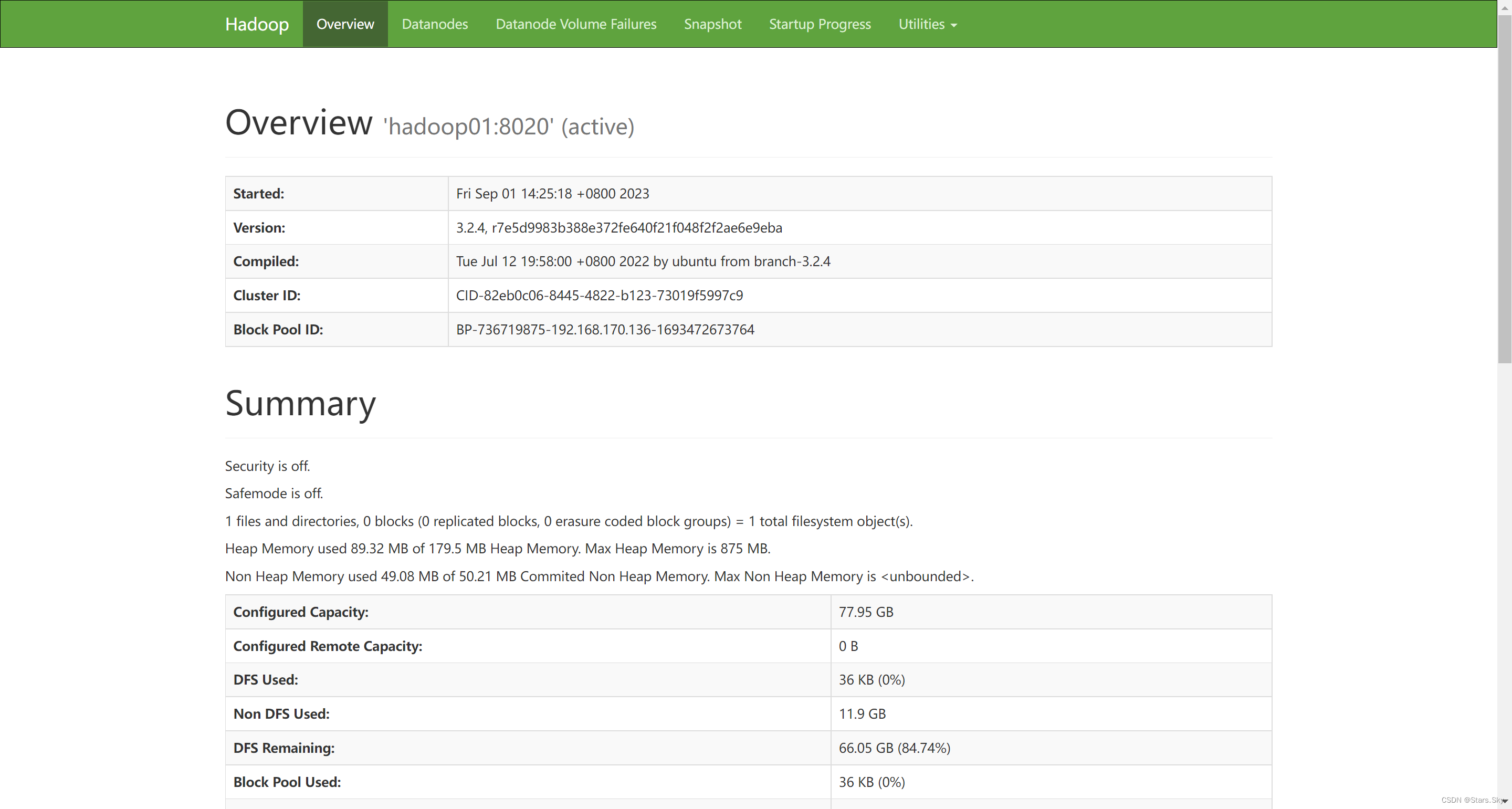
HDFS 文件系统 Web 页面浏览:

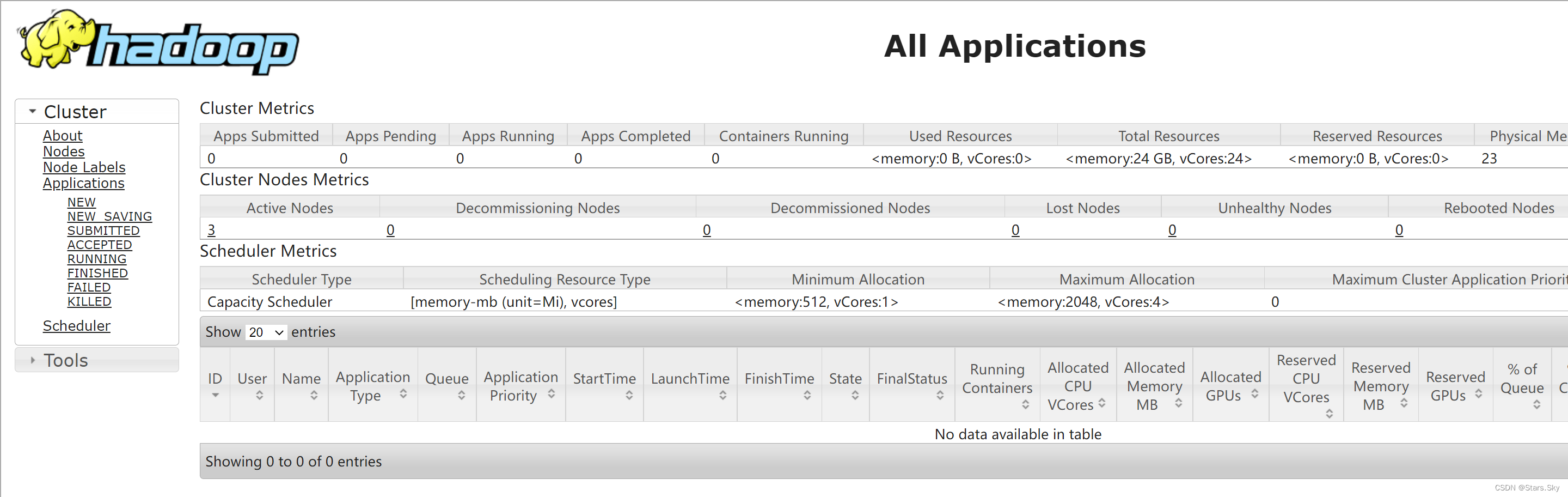
3.10.3 访问 YARN 集群 UI 页面
地址:http://resourcemanager_host:8088
其中 resourcemanager_host 是 resourcemanager 运行所在机器的主机名或者 ip。
四、Hadoop 初体验
4.1 HDFS 初体验
4.1.1 shell 命令操作
[root@hadoop01 ~]# hadoop fs -mkdir /test1
[root@hadoop01 ~]# hadoop fs -put jdk-8u381-linux-x64.tar.gz /test1
[root@hadoop01 ~]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2023-09-01 14:43 /test14.1.2 Web UI 页面操作
 4.2 MapReduce+YARN 初体验
4.2 MapReduce+YARN 初体验
4.2.1 执行 Hadoop 官方自带的 MapReduce 案例
评估圆周率 π 的值:
[root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce/
[root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/mapreduce]# hadoop jar hadoop-mapreduce-examples-3.2.4.jar pi 2 4

相关文章:
Hadoop 3.2.4 集群搭建详细图文教程
目录 一、集群简介 二、Hadoop 集群部署方式 三、集群安装 3.1 集群角色规划 3.2 服务器基础环境准备 3.2.1 环境初始化 3.2.2 ssh 免密登录(在 hadoop01 上执行) 3.2.3 各个节点上安装 JDK 1.8 环境 3.3 安装 Hadoop 3.4 Hadoop 安装包目…...

STL的学习之一
1)STL扫盲 1)C标准库和标准模板库是不一样的 2)标准模板库是用泛型编程方式编写的函数或者类库; 3) SGI STL linux一般用,P.J.Plauger STL,visual2017 windows用 STL六大组件 : 容器,迭代器 STL 算法(说白了就是函数…...

如何使用Python进行数据科学实验?
使用Python进行数据科学实验通常需要以下步骤: 以上仅为使用Python进行数据科学实验的基本步骤,具体实验过程会根据具体问题和数据集的特点而有所不同。可以进一步学习和探索相关的数据科学和机器学习技术,以提高实验的效果和表现。 安装Pyt…...

华为数通方向HCIP-DataCom H12-821题库(拖拽题,知识点总结)
以下是我在现有题库中整理的需要重点关注的考点内容,如有遗漏小伙伴可以留言补充。...

第三课:C++实现PDF去水印
PDF去水印是一项非常复杂的任务,需要一定的计算机图形学知识和技术,也需要使用到一些专业的工具库。以下是一种可能的实现方法: 首先,需要将PDF文件解析成一系列图形元素,包括文字、矢量图形等。可以使用开源库Poppler或MuPDF来解析PDF文件。 接下来,需要判断PDF文件是否…...

实现Android分布式协同办公:将待办事件App与本地Web服务结合
AndServer AndServer 是 Android 平台的 Web Server 和 Web Framework,它基于编译时注解提供了类似 SpringMVC 的注解和功能。 Github :https://github.com/yanzhenjie/AndServer使用文档:https://yanzhenjie.com/AndServer/业务需求 实现待办事件APP本地启动Web服务,将本…...

VMware12.1.1安装Centos7
VMware12.1.1安装Centos7 1、下载相关软件 1.1 Centos7下载 官方下载链接: http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1511.iso 1.2 VMware Workstation下载 VMware Workstation 12.1.1官方原版下载: https://dow…...

bazel构建原理
调度模型 传统构建系统有很多是基于任务的,例如 Ant,Maven,Gradle。用户可以自定义"任务"(Task),例如执行一段 shell 脚本。用户配置它们的依赖关系,构建系统则按照顺序调度。 基于 Task 的调度…...

matlab 点云的二进制形状描述子
目录 一、功能概述1、算法概述2、主要函数3、参考文献二、代码示例三、结果展示四、参数解析输入参数名称-值对应参数输出参数五、参考链接本文由CSDN点云侠原创,...
MongoDB实验——在Java应用程序中操作 MongoDB 数据
在Java应用程序中操作 MongoDB 数据 1. 启动MongoDB Shell 2. 切换到admin数据库,使用root账户 3.开启Eclipse,创建Java Project项目,命名为MongoJava File --> New --> Java Project 4.在MongoJava项目下新建包,包名为mo…...
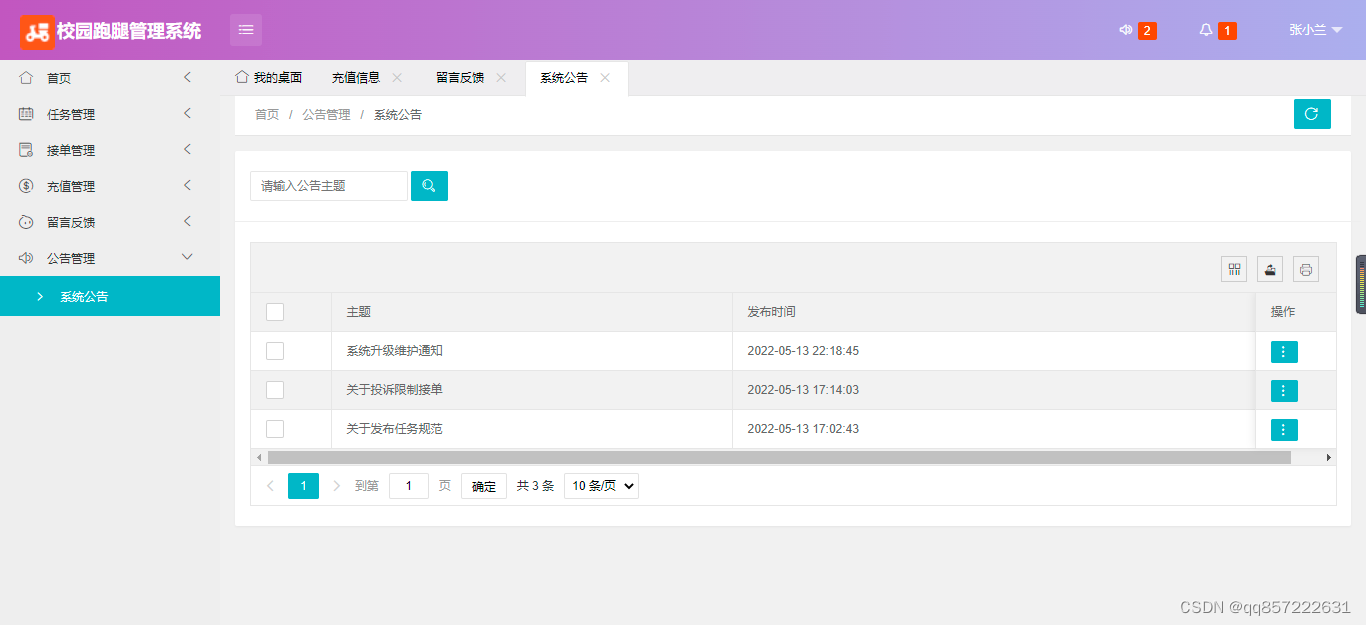
java+springboot+mysql校园跑腿管理系统
项目介绍: 使用javaspringbootmysql开发的校园跑腿管理系统,系统包含超级管理员,系统管理员、用户角色,功能如下: 超级管理员:管理员管理;用户管理(充值);任…...

ubuntu20.04 server 安装后磁盘空间只有一半的处理
这里扩展:/dev/mapper/ubuntu–vg-ubuntu–lv rootbook:/data# df -h Filesystem Size Used Avail Use% Mounted on udev 3.9G 0 3.9G 0% /dev tmpfs 795M 1.2M 79…...

〔017〕Stable Diffusion 之 常用模型推荐 篇
✨ 目录 🎈 模型网站🎈 仿真系列🎈 国风系列🎈 卡通动漫系列🎈 3D系列🎈 一些好用的lora模型🎈 模型网站 由于现在大模型超级多,导致每种画风的模型太多,那么如何选择最好最适合的模型,成了很多人头疼的问题由于用的大部分都是1.5的模型,所以优先下载 safete…...
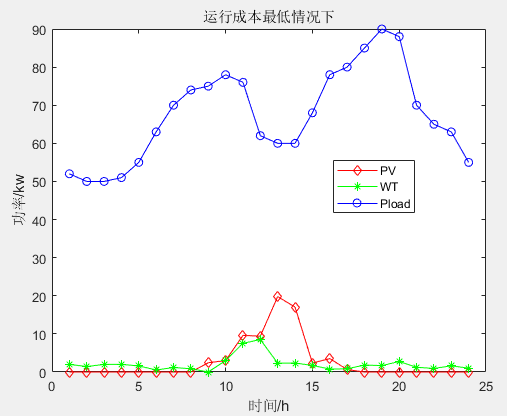
多目标应用:基于多目标人工蜂鸟算法(MOAHA)的微电网多目标优化调度MATLAB
一、微网系统运行优化模型 参考文献: [1]李兴莘,张靖,何宇,等.基于改进粒子群算法的微电网多目标优化调度[J].电力科学与工程, 2021, 37(3):7 二、多目标人工蜂鸟算法MOAHA 多目标人工蜂鸟算法(multi-objective artificial hummingbird algorithm&…...

【HTML5】HTML5 特性
HTML5 特性 1. 语义化标签 <header>:表示网页或某个区域的页眉部分,通常包含网站的标志、导航菜单等内容。<nav>:表示导航区域,用于包含网站的主要导航链接。<main>:表示网页的主要内容区域&#…...

【FreeRTOS】互斥量的使用与逐步实现
在FreeRTOS中,互斥量是一种用于保护共享资源的同步机制。它通过二进制信号量的方式,确保在任意时刻只有一个任务可以获取互斥量并访问共享资源,其他任务将被阻塞。使用互斥量的基本步骤包括创建互斥量、获取互斥量、访问共享资源和释放互斥量…...
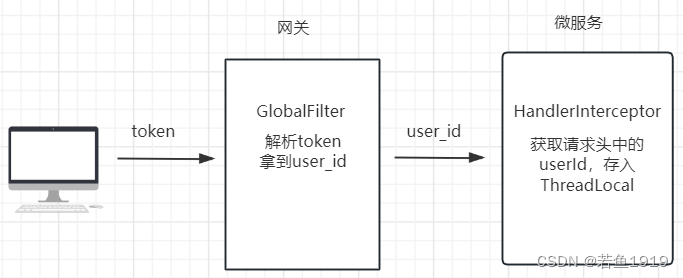
Spring-Cloud-Openfeign如何传递用户信息?
用户信息传递 微服务系统中,前端会携带登录生成的token访问后端接口,请求会首先到达网关,网关一般会做token解析,然后把解析出来的用户ID放到http的请求头中继续传递给后端的微服务,微服务中会有拦截器来做用户信息的…...

OpenCV(十一):图像仿射变换
目录 1.图像仿射变换介绍 仿射变换: 仿射变换矩阵: 仿射变换公式: 2.仿射变换函数 仿射变换函数:warpAffine() 图像旋转:getRotationMatrix2D() 计算仿射变换矩阵:getAffineTransform() 3.demo 1.…...
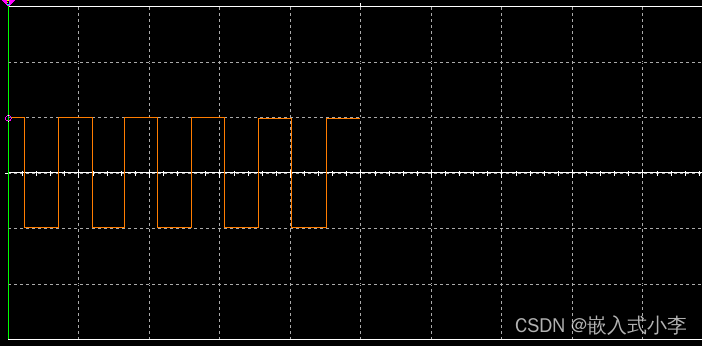
多路波形发生器的控制
本次波形发生器,主要使用运算放大器、NE555以及一些其他的电阻电容器件来实现。整体电路图如下所示: 产生的三角波如下: 正弦波如下 方波如下: 运算放大器(Operational Amplifier,简称OP-AMP)是…...

[C/C++]天天酷跑超详细教程-中篇
个人主页:北海 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏✨收录专栏:C/C🤝希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!ǹ…...

服务器末级缓存管理优化与Garibaldi架构解析
1. 服务器末级缓存管理的核心挑战 在现代服务器架构中,末级缓存(Last-Level Cache, LLC)作为CPU与主存之间的关键缓冲层,其管理效率直接影响系统整体性能。传统LLC管理面临一个根本性矛盾:随着核心数量增加和负载多样化,有限的缓存…...

紧急提醒!项目管理人员不要乱签字,否则真会坐牢!
在工程项目里,人证不合一早已不是新鲜事,项目经理、安全员、资料员之间“代签”几乎成了一种心照不宣的默契。忙起来的时候,一张签到表、一份验收单传过来,顺手帮不在场的同事填上名字,很多人觉得这不过是抬抬手的事&a…...

2026年项目交付排期系统选型指南:10款主流工具深度测评
一、为什么你的项目总是交付延期?进入2026年,多项目并行、跨地域协作、人力资源紧张、需求频繁变更,已经成为各行业项目推进的常态化现状。当下多数项目出现交付延期问题,核心原因往往并非团队执行效率不足,而是项目排…...

ElevenLabs江苏话语音模型训练全链路拆解:从200小时带标注吴语语料清洗,到MOS得分达4.13的关键超参组合
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs江苏话语音模型训练全链路拆解:从200小时带标注吴语语料清洗,到MOS得分达4.13的关键超参组合 语料清洗与方言对齐策略 针对原始200小时江苏话(含苏州、无…...
)
一文读懂如何申报国家企业技术中心(条件、流程、好处)
一、什么是企业技术中心?是指企业根据市场竞争需要设立的技术研发与创新机构,负责制定企业技术创新规划、开展产业技术研发、创造运用知识产权、建立技术标准体系、凝聚培养创新人才,推进技术创新全过程实施,是企业技术创新体系的…...

BilibiliDown完整使用指南:5步掌握B站视频批量下载技巧
BilibiliDown完整使用指南:5步掌握B站视频批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/…...

机器学习生产化:从Notebook到可运维ML服务的实战路径
1. 项目概述:当模型走出笔记本,真正开始“呼吸”现实空气 你有没有经历过这样的时刻:Jupyter Notebook里所有指标都闪闪发亮,AUC 0.92,F1 0.87,交叉验证稳如泰山;业务方点头签字,上线…...

ChatGPT API调用费用暴涨?揭秘token计费陷阱:5个被90%开发者忽略的隐性成本源
更多请点击: https://intelliparadigm.com 第一章:ChatGPT API调用费用暴涨?揭秘token计费陷阱:5个被90%开发者忽略的隐性成本源 ChatGPT API 的账单突增,往往并非源于请求量激增,而是被 token 计费机制中…...

146台储罐+10台喷淋塔,新能源项目为什么认准PPH?
在新能源材料项目的设备选型中,PPH正逐渐变成大多数厂家选择的一种材质。 最近美联新材料的新能源产业化项目,一口气向吉庆订了146台PPH贮罐、10台PPH喷淋塔,今天就借着这个真实项目,来聊一聊,PPH为什么能成成新能源项…...
选择最优架构)
从NPN到FET:一文看懂LDO内部调整管的演进史,以及如何根据你的项目(IoT、可穿戴、汽车电子)选择最优架构
从NPN到FET:LDO调整管技术演进与选型实战指南 在可穿戴设备的心率传感器突然断电的瞬间,工程师们才意识到选错LDO的代价——这恰恰揭示了调整管架构对系统可靠性的决定性影响。从早期笨重的NPN稳压器到如今纳米级MOSFET LDO,电源管理芯片的进…...