ClickHouse进阶(三):ClickHouse 索引

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
1. 一级索引
2. 二级索引(跳数索引)
1. 一级索引
在MergeTree中PRIMARY KEY 主键并不用于去重,而是用于索引,加快查询速度,MergeTree会根据index_granularity间隔(默认8192行),为数据表生成一级索引并保存至primary.idx文件内,索引数据按照PRIMARY KEY 排序,相对于使用PRIMARY KEY 更常见的方式是通过ORDER BY 方式指定主键。
- 稀疏索引
primary.idx文件内的一级索引采用稀疏索引实现。有稀疏索引就有稠密索引,二者区别如下:

在稠密索引中每一行索引标记都会对应到一行具体的数据记录。而在稀疏索引中每一行索引标记对应的是一段数据,而不是一行。
稀疏索引的优势显而易见,仅需要使用少量的索引标记就能够记录大量的数据区间位置信息,而且数据量越大优势越明显。在MergeTree系列引擎表中对应的primary.idx文件就是稀疏索引,由于稀疏索引占用空间小,所以primary.idx内的索引数据常驻内存。
- 索引粒度
在clickhouse MergeTree引擎中默认的索引粒度是8192,参数为index_granularity,一般我们不会修改此值,按照默认8192即可。我们可以通过以下sql语句查看每个MergeTree引擎表对应的index_granulariry的值:
node1 :) show create table t_mt;索引粒度对于MergeTree表引擎非常重要,可以根据整个数据的长度,按照索引粒度对数据进行标注,然后抽取对应的数据形成索引。
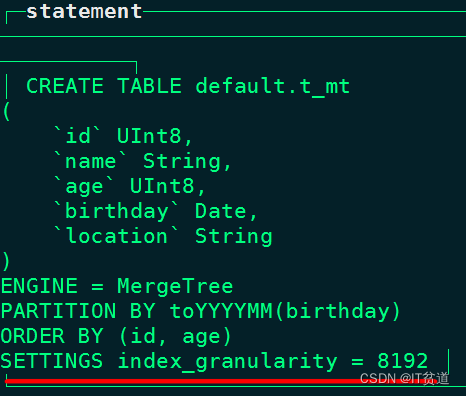
- 索引形成过程
表数据以index_granularity的粒度(默认8192)被标记成多个小区间,其中每个区间最多8192行数据,每个区间标记后形成一个MarkRange,通过start和end表示MarkRange的具体范围,数据文件也会按照index_granularity的间隔粒度生成压缩数据块。由于是稀疏索引,MergeTree需要间隔index_granularity行数据生成一条索引,同时对应一个索引编号,每个MarRange与一个索引编号对应,通过与start及end对应的索引编号的取值,可以得到对应的数值区间;索引编号对应的索引值会依据声明的主键字段获取,最终索引编号和索引值被写入primary.idx文件中保存。
假设现在有一份测试数据,共192行记录,其中主键ID为String类型,ID值从A000开始,后面依次为A001、A002...直到A192为止,假设我们设置MergeTree的索引粒度index_granularity=3,根据索引的生成规则,primary.idx文件内的索引数据如下:

根据索引数据,MergeTree将此数据片段划分成192/3=64个小的MarkRange,其中所有MarkRange的最大数值区间为[A000,+inf),划分的MarkRange如下:

索引查询过程
使用索引查询其实就是两个数值区间的交集判断,其中一个区间是有基于主键的查询条件转换而来的条件区间,而另一个区间是上图中MarkRange对应的数值区间。
整个索引查询的过程大致分为3个步骤:
1) 生成查询条件区间
查询时首先将查询条件转换为条件区间,即便是单个值的查询条件也会转换成区间的形式,例如:
WHERE ID='A003'['A003','A003']WHERE ID>'A000'['A000',+inf]WHERE ID<'A188'(-inf,'A188']WHERE ID like 'A006%'('A006','A007']2) 递归交集判断
以递归的方式依次对MarkRange的数值区间与条件区间做交集判断,从最大的区间[A000,+inf)开:
- 如果不存在交集,则直接忽略掉整段MarkRange
- 如果存在交集,且MarkRange步长大于8(end-start),则将此区间进一步拆分成8个区间(由merge_tree_coarse_index_granularity指定,默认值为8),并重复此规则,继续做递归交集判断。
- 如果存在交集,且MarkRange不可再分解(步长小于8),则记录MarkRange并返回。
3) 合并MarkRange区间
将最终匹配的MarkRange聚在一起,合并他们的范围。
当查询条件WHERE ID ='A003'的时候,最终读取[A000,A003)和[A003,A006]两个区间的数据即可,他们对应的MarkRange(start:0,end:2)范围,而无其他无用的区间都被裁剪过滤掉,因为MarkRange转换的数值区间是闭区间,所以会额外匹配到临近的一个区间,完整的逻辑图如下图所示:

2. 二级索引(跳数索引)
除了一级索引之外,MergeTree同样支持二级索引,二级索引又称为跳数索引,由数据的聚合信息构建而成,根据索引类型的不同,其聚合信息的内容也不同,跳数索引的目的与一级索引一样,也是帮助查询时减少数据扫描的范围。
跳数索引需要在Create语句内定义,完整语法如下:
INDEX index_name expr TYPE index_type(...) GRANULARITY granularity对以上参数的解释如下:
- index_name:定义的二级索引名称
- index_type:跳数索引类型,最常用就是minmax索引类型。minmax索引记录了一段数据内的最小和最大极值,其索引的作用类似分区目录,能够快速跳过无用的数据区间。
- granularity:定义聚合信息汇总的粒度。
与一级索引一样,如果在建表语句中声明了跳数索引,则会在路径“/var/lib/clickhouse/data/DATABASE/TABLE/PARTITION/”目录下生成索引与标记文件(skp_idx.idx与skp_idx.mrk)。
在接触跳数索引时,很容易将index_granularity与granularity概念混淆,对于跳数索引而言,index_granularity定义了数据的粒度,而granularity定义了聚合信息汇总的粒度,也就是说,granularity定义了一行跳数索引能够跳过多少个index_granularity区间的数据。
- minmax跳数索引的生成规则
minmax跳数索引聚合信息是在一个index_granularity区间内数据的最小和最大极值。首先,数据按照index_granularity粒度间隔将数据划分成n段,总共有[0~n-1]个区间(n=total_rows/index_granularity,向上取整),接着根据跳数索引从0区间开始,依次按index_granularity粒度从数据中获取聚合信息,每次向前移动1步,聚合信息逐步累加,最后当移动granularity次区间时,则汇总并生成一行跳数索引数据。
以下图为例:假设index_granularity=8192且granularity=3,则数据会按照index_granularity划分成n等份,MergeTree从第0段分区开始,依次获取聚合信息,当获取到第3个分区时(granularity=3),则汇总并生成第一行minmax索引(前3段minmax极值汇总后取值为[1,9])。

minmax跳数索引案例:
#删除表 t_mtnode1 :) drop table t_mt;#重新创建t_mt表,包含二级索引node1 :)CREATE TABLE t_mt(id UInt8,name String,age UInt8,birthday Date,location String,INDEX a id TYPE minmax GRANULARITY 5)ENGINE = MergeTreePARTITION BY toYYYYMM(birthday)ORDER BY (id, age)PRIMARY KEY id#插入数据insert into t_mt values (1,'张三',18,'2021-06-01','上海'), (2,'李四',19,'2021-02-10','北京'), (3,'王五',12,'2021-06-01','天津'), (1,'马六',10,'2021-06-18','上海'), (5,'田七',22,'2021-02-09','广州');#查看数据分区路径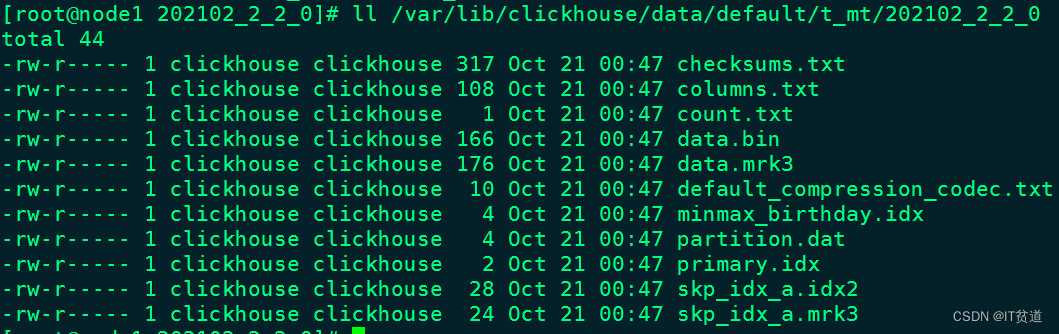
👨💻如需博文中的资料请私信博主。
相关文章:
ClickHouse进阶(三):ClickHouse 索引
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容! 🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,大数据OLAP体系技术栈,Kerberos安全认证-CSDN博客 &…...
四、MySQL(表操作)如何添加字段?修改表?删除字段?修改表名?删除表?格式化某张表?
1、添加字段 (1)基础语法: alter table 表名 add 字段名 类型名(长度) [comment注释] [约束]; (2)示例:添加nickname这个字段 2、修改表 修改表中某个字段的【数据类型】/【数据类型&字段名】 &…...
docker启动paddlespeech服务,并使用接口调用
一、检查docker容器是否启动 1.输入命令 systemctl status docker 启动 systemctl start docker 守护进程重启 sudo systemctl daemon-reload 重启docker服务 systemctl restart docker 重启docker服务 sudo service docker restart 关闭docker service docker…...

如何训练ChatGPT以生成音乐和创意艺术作品?
训练ChatGPT生成音乐和创意艺术作品是一个令人兴奋且具有挑战性的任务。这种技术,也被称为生成式艺术,涉及将人工智能(AI)模型与创意艺术的融合。在本文中,我将探讨如何训练ChatGPT以生成音乐和创意艺术作品的过程&…...

北约报告:2023-2043,下一代量子技术的发展与挑战
“当今的新技术正在以令人眼花缭乱的速度发展,我们所有人都可以在负责任且合乎道德的方式开发和部署新技术方面发挥作用。” ——这是副秘书长Mircea Geoană在2023年3月22日、在布鲁塞尔发布《北约科学技术组织2023-2043年趋势报告》时传达的信息。 Geoană先生强调…...
arm版Linux下安装es集群
背景:由于生产上网络没通,没办法,只能自己安装一个es集群的测试环境了,我的电脑是Mac M2,安装的Linux是centos7,也是arm版的。 第一步:查看自己Linux系统的版本 命令:uname -a 例如…...
vConsole调试工具的三种使用方式
1.在html页面时, 在页面引入 cdn 方式引入 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" co…...
不用订阅,不用破解,永久免费使用Axure最新版教程
首先去官网下载最新的axure,你没听错,就是最新的。 下载网址:Axure RP - UX Prototypes, Specifications, and Diagrams in One Tool 下载完后解压安装到本地,并注册属于你自己的账户,开始试用。可惜的是只有30天的试…...
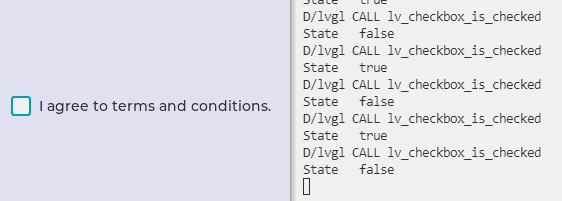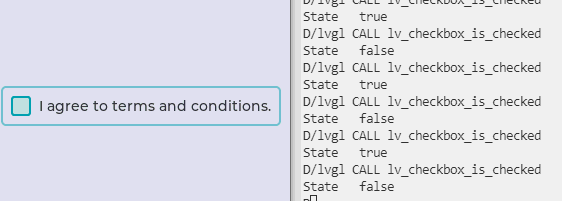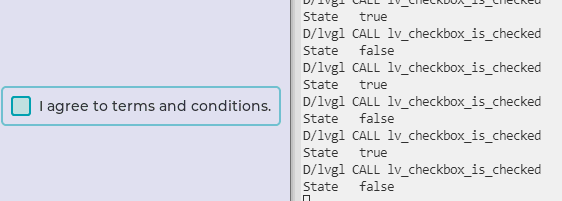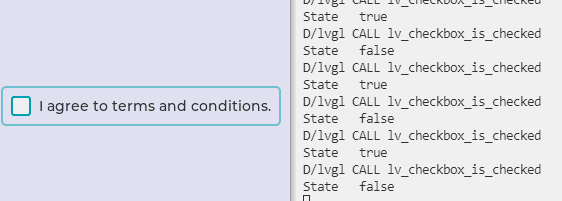
合宙Air724UG LuatOS-Air LVGL API控件--复选框 (Checkbox)
复选框 (Checkbox) 复选框主要是让用户进行一些内容选择,或者同意用户协议。 示例代码 – 复选框回调函数 function event_handler(obj, event) if event lvgl.EVENT_VALUE_CHANGED then print(“State”, lvgl.checkbox_is_checked(obj)) end end – 创建复选框…...
使用nps实现内网穿透
1、介绍 当我们想把内网的一些资源暴露在公网上时,可以使用内网穿透功能。比如公司的内网服务器,部署了平时需要开发的项目,但是回到家中无法访问,就可以使用内网穿透,将公司内网的接口映射到一台公网的服务器上&a…...

时序预测 | MATLAB实现TCN-BiGRU时间卷积双向门控循环单元时间序列预测
时序预测 | MATLAB实现TCN-BiGRU时间卷积双向门控循环单元时间序列预测 目录 时序预测 | MATLAB实现TCN-BiGRU时间卷积双向门控循环单元时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiGRU时间卷积双向门控循环单元时间序列预测&a…...
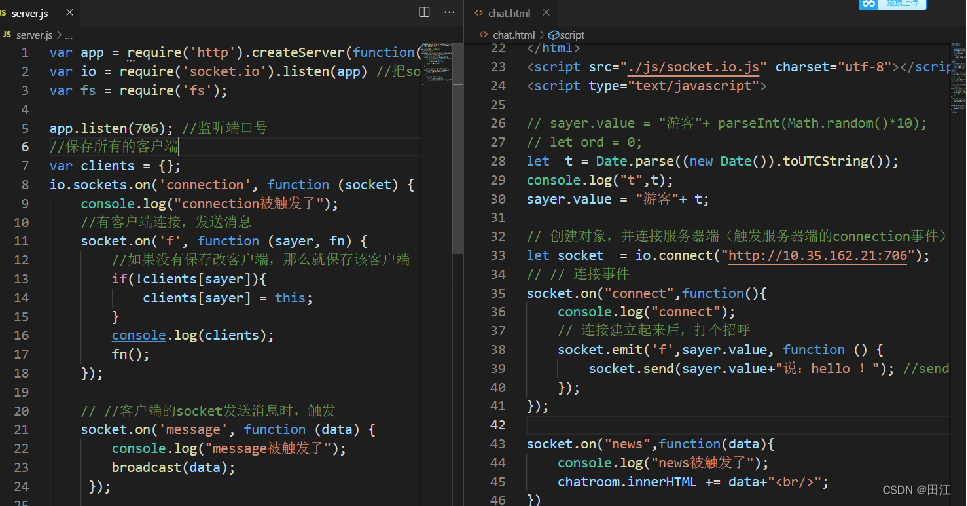
websocket和uni-app里使用websocket
一、HTTP是无状态协议 特点: 1、浏览器发送请求时,浏览器和服务器会建立一个连接。完成请求和响应。在http1.0之前,每次请求响应完毕后,会立即断开连接。在http1.1之后,当前网页的所有请求响应完毕后,才断…...
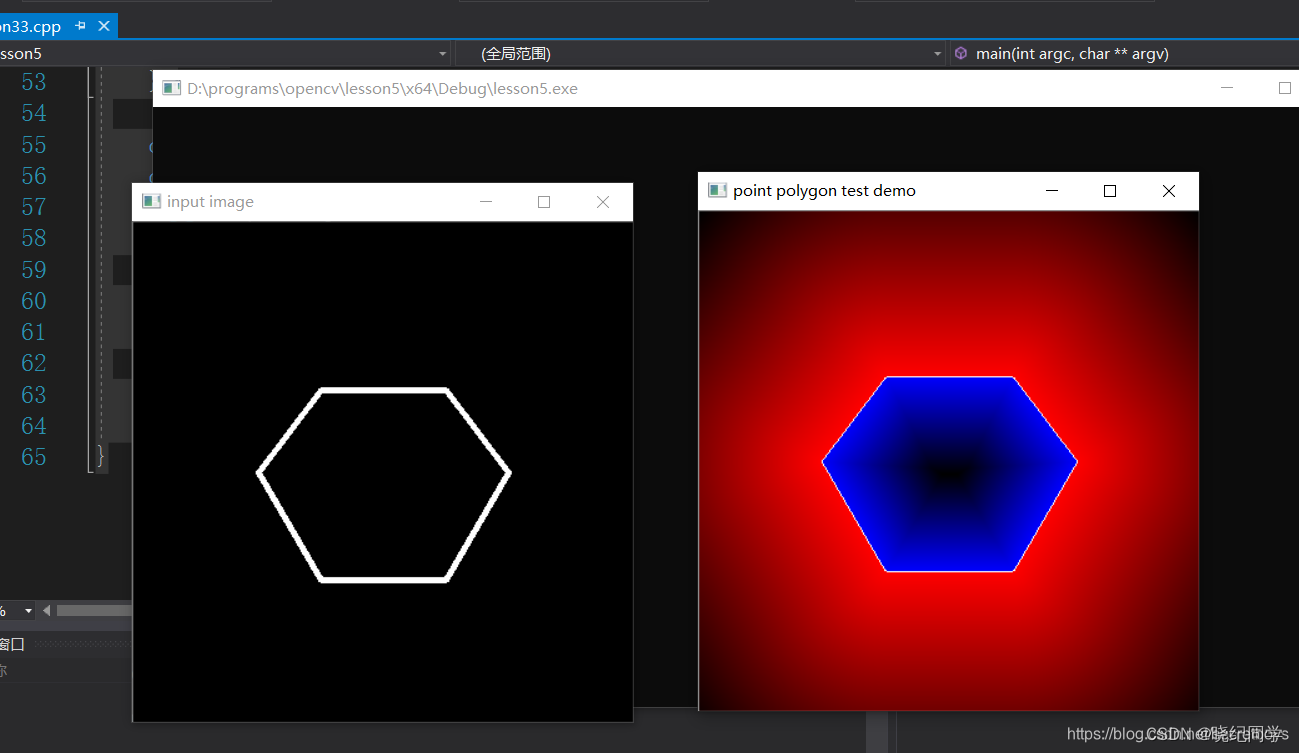
Opencv-C++笔记 (18) : 轮廓和凸包
文章目录 一、轮廓findContours发现轮廓drawContours绘制轮廓代码 二.几何及特性概括——凸包(Convex Hull)凸包概念凸包扫描算法介绍——Graham扫描算法 相关API介绍程序示例轮廓集合及特性性概括——轮廓周围绘制矩形框和圆形相关理论介绍轮廓周围绘制矩形 -API绘制步骤程序实…...
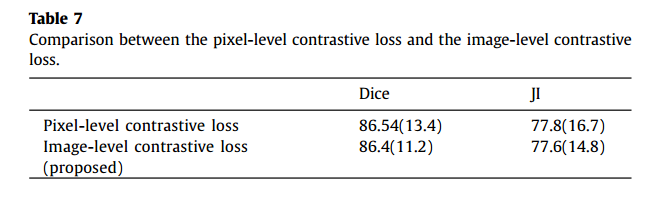
【半监督医学图像分割】2022-MedIA-UWI
【半监督医学图像分割】2022-MedIA-UWI 论文题目:Semi-supervise d me dical image segmentation via a triple d-uncertainty guided mean teacher model with contrastive learning 中文题目:基于对比学习的三维不确定性指导平均教师模型的半监督图像分…...

python发送邮件
为了安全起见,我们发送邮件需要使用tls,这样发送的内容都是加密的了,但是该工具批量发送带有自定义内容的邮件不方便,于是写了一个py脚本,使用--data参数,方便批量发送,我们的策略是每天随机发送…...

gitee上传本地项目bug
🤮这个破bug不知道浪费了多长时间,以前没有记录,每次都忘记,这次记下来 问题描述 gitee创建仓库,然后根据它提示的如下命令,但一直报错 原因分析: 把命令复制出来,粘贴到Sublime …...

自然语言处理2-NLP
目录 自然语言处理2-NLP 如何把词转换为向量 如何让向量具有语义信息 在CBOW中 在Skip-gram中 skip-gram比CBOW效果更好 CBOW和Skip-gram的算法实现 Skip-gram的理想实现 Skip-gram的实际实现 自然语言处理2-NLP 在自然语言处理任务中,词向量(…...
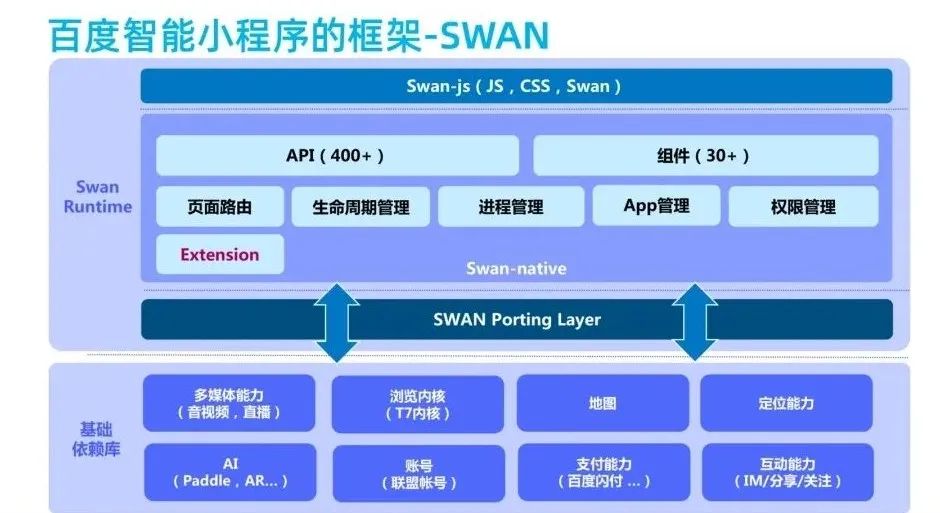
穿上App外衣,保持Web灵魂——PWA温故
早在2015年,设计师弗朗西斯贝里曼和Google Chrome的工程师亚历克斯罗素提出“PWA(渐进式网络应用程序)”概念,将网络之长与应用之长相结合,其核心目标就是提升 Web App 的性能,改善 Web App以媲美Native的流…...
)
【跟小嘉学 Rust 编程】二十六、Rust的序列化解决方案(Serde)
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
:函数)
菜鸟教程《Python 3 教程》笔记(14):函数
菜鸟教程《Python 3 教程》笔记(14) 14 函数14.1 参数传递14.1.1 可更改(mutable)与不可更改(immutable)对象14.1.2 python 传不可变对象实例 14.2 参数14.2.1 必需参数14.2.2 关键字参数14.2.3 默认参数14.2.4 不定长参数 14.3 匿名函数14.4 强制位置参…...

冬季施工安全措施,附: 冬季施工总安全技术交底
冬季施工安全措施,附: 冬季施工总安全技术交底 冬季施工特点 1 冬季施工由于施工条件及环境不利,是工程质量事故的多发季节,尤以混凝土工程、钢结构工程居多。如何在冬季施工、抢赶工期的条件下保证项目的质量目标,是施工技术和施工组织的难点。 3 质量事故出现的隐蔽性…...

Legba性能优化技巧:10个实用方法提升暴力破解效率 [特殊字符]
Legba性能优化技巧:10个实用方法提升暴力破解效率 🚀 【免费下载链接】legba The fastest and more comprehensive multiprotocol credentials bruteforcer / password sprayer and enumerator. 🥷 项目地址: https://gitcode.com/gh_mirro…...

通宵降AI率?10款降AI工具亲测:哪个神器一次过,哪个白花钱
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

ARMv8通用定时器架构与CNTHP_CTL_EL2寄存器详解
1. AArch64通用定时器架构概述在ARMv8架构中,通用定时器系统为操作系统和应用程序提供了精确的时间基准。这套计时系统由一组相互关联的组件构成,包括物理计数器、虚拟计数器以及多个比较器。作为系统程序员,理解这套机制对开发底层系统软件至…...

AI Newsletter的本质:一种高信噪比的信息过滤与认知校准方法论
1. 项目概述:一份“AI Newsletter”背后的真实工作流与信息筛选逻辑你点开邮箱,看到标题为This AI newsletter is all you need #41的邮件——它没用夸张的“爆炸性突破”“颠覆认知”这类词,也没塞满emoji和感叹号,但你还是点了开…...

HarmonyOS ,你所不知道的事件发布/订阅的通信机制-EventEmitter
在鸿蒙(HarmonyOS)开发中,EventEmitter 是一种用于事件发布/订阅的通信机制,常用于组件、Ability、线程或模块之间的解耦通信。它允许一个对象(发布者)发出事件,而其他对象(订阅者&a…...

ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南
ChatGPT-Web-Midjourney-Proxy 终极备份策略:数据安全与灾难恢复完全指南 ChatGPT-Web-Midjourney-Proxy 是一款集成 ChatGPT、Midjourney 和 GPTs 功能的一站式 UI 工具,为用户提供便捷的 AI 交互体验。在日常使用中,数据安全与灾难恢复至关…...

摆脱论文困扰!盘点2026年普遍认可的的降AI率软件
轻松降低论文AI率在2026年已不再是天方夜谭。最新实测数据显示,2026年降AI率软件正以惊人的效率和精准度颠覆传统方法,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,真正实现高效降AI率,帮你告别论文焦虑。…...

2026数字营销岗位需要具备的能力有哪些
数字营销这几年变化很快,到了2026年,岗位要求已经不再只是“会投放、会写文案、会做表格”这么简单了。很多职场人都能明显感觉到:过去靠经验拍脑袋做营销,越来越难;未来真正有竞争力的人,往往是那些既懂业…...

LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构
LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款为速度跑者设计的专业级计时软件&am…...