使用实体解析和图形神经网络进行欺诈检测

图形神经网络的表示形式(作者使用必应图像创建器生成的图像)
一、说明
对于金融、电子商务和其他相关行业来说,在线欺诈是一个日益严重的问题。为了应对这种威胁,组织使用基于机器学习和行为分析的欺诈检测机制。这些技术能够实时检测异常模式、异常行为和欺诈活动。
不幸的是,通常只考虑当前交易,例如订单,或者该过程仅基于客户配置文件中的历史数据,这些数据由客户ID标识。但是,专业欺诈者可能会使用低价值交易创建客户资料,以建立其个人资料的正面形象。此外,他们可能会同时创建多个类似的配置文件。只有在欺诈发生后,被攻击的公司才意识到这些客户资料是相互关联的。
使用实体解析,可以轻松地将不同的客户档案组合到一个 360° 客户视图中,从而可以查看所有历史交易的全貌。虽然在机器学习中使用这些数据,例如使用神经网络甚至简单的线性回归,已经为生成的模型提供了额外的价值,但真正的价值来自于观察各个交易如何相互连接。这就是图神经网络(GNN)发挥作用的地方。除了查看从事务记录中提取的特征外,它们还提供了查看从图形边缘生成的特征(事务如何相互链接)甚至只是实体图的一般布局的可能性。
二、示例数据
在我们深入研究细节之前,我有一个免责声明要在这里提出:我是开发人员和实体解析专家,而不是数据科学家或 ML 专家。虽然我认为一般方法是正确的,但我可能没有遵循最佳实践,也无法解释某些方面,例如隐藏节点的数量。使用本文作为灵感,并在GNN布局或配置方面借鉴您自己的经验。
出于本文的目的,我想重点介绍从实体图布局中获得的见解。为此,我创建了一个生成实体的小 Golang 脚本。每个实体都被标记为欺诈性或非欺诈性,由记录(订单)和边缘(这些订单的链接方式)组成。请参阅以下单个实体的示例:
{"fraud":1,"records":[{"id":0,"totalValue":85,"items":2},{"id":1,"totalValue":31,"items":4},{"id":2,"totalValue":20,"items":9}],"edges":[{"a":1,"b":0,"R1":1,"R2":1},{"a":2,"b":1,"R1":0,"R2":1}]
}每条记录有两个(潜在)特征,即总价值和购买的物品数量。但是,生成脚本完全随机化了这些值,因此在猜测欺诈标签时,它们不应提供价值。每个边还具有两个特征 R1 和 R2。例如,这些可以表示两个记录A和B是通过相似的名称和地址(R1)还是通过相似的电子邮件地址(R2)链接的。此外,我故意省略了与此示例无关的所有属性(姓名、地址、电子邮件、电话号码等),但通常事先与实体解析过程相关。由于 R1 和 R2 也是随机的,它们也不能为 GNN 提供价值。但是,根据欺诈标签,边缘以两种可能的方式布局:星形布局(欺诈=0)或随机布局(欺诈=1)。
这个想法是,非欺诈性客户更有可能提供准确匹配的相关数据,通常是相同的地址和相同的名称,这里和那里只有几个拼写错误。因此,新交易可能会被识别为重复交易。

重复数据删除的实体(图片由作者提供)
欺诈性客户可能希望使用各种名称和地址隐藏他们仍然是计算机后面的同一个人的事实。但是,实体解析工具可能仍可识别相似性(例如地理和时间相似性、电子邮件地址中的重复模式、设备 ID 等),但实体图可能看起来更复杂。

复杂,可能是欺诈实体(图片来源:作者)
为了使它不那么简单,生成脚本还具有 5% 的错误率,这意味着当实体具有类似星形的布局时,它们被标记为欺诈性,而随机布局则标记为非欺诈性。此外,在某些情况下,数据不足以确定实际布局(例如,只有一条或两条记录)。
{"fraud":1,"records":[{"id":0,"totalValue":85,"items":5}],"edges":[]
}实际上,您很可能会从所有三种要素(记录属性、边属性和边布局)中获得有价值的见解。下面的代码示例将考虑这一点,但生成的数据不会。
三、创建数据集
该示例使用 python(数据生成除外)和带有 pytorch 后端的 DGL。您可以在github上找到完整的jupyter笔记本,数据和生成脚本。
让我们从导入数据集开始:
import osos.environ["DGLBACKEND"] = "pytorch"
import pandas as pd
import torch
import dgl
from dgl.data import DGLDatasetclass EntitiesDataset(DGLDataset):def __init__(self, entitiesFile):self.entitiesFile = entitiesFilesuper().__init__(name="entities")def process(self):entities = pd.read_json(self.entitiesFile, lines=1)self.graphs = []self.labels = []for _, entity in entities.iterrows():a = []b = []r1_feat = []r2_feat = []for edge in entity["edges"]:a.append(edge["a"])b.append(edge["b"])r1_feat.append(edge["R1"])r2_feat.append(edge["R2"])a = torch.LongTensor(a)b = torch.LongTensor(b)edge_features = torch.LongTensor([r1_feat, r2_feat]).t()node_feat = [[node["totalValue"], node["items"]] for node in entity["records"]]node_features = torch.tensor(node_feat)g = dgl.graph((a, b), num_nodes=len(entity["records"]))g.edata["feat"] = edge_featuresg.ndata["feat"] = node_featuresg = dgl.add_self_loop(g)self.graphs.append(g)self.labels.append(entity["fraud"])self.labels = torch.LongTensor(self.labels)def __getitem__(self, i):return self.graphs[i], self.labels[i]def __len__(self):return len(self.graphs)dataset = EntitiesDataset("./entities.jsonl")
print(dataset)
print(dataset[0])这将处理实体文件,这是一个 JSON 行文件,其中每行表示一个实体。在迭代每个实体时,它会生成边特征(形状为 [e, 2]、e=边数的长张量)和节点特征(形状为 [n, 2] 的长张量,n=节点数)。然后,它继续基于 a 和 b(每个长张量具有形状 [e, 1])构建图形,并将边和图形特征分配给该图形。然后将所有生成的图形添加到数据集中。
四、模型架构
现在我们已经准备好了数据,我们需要考虑GNN的架构。这是我想出来的,但可能可以根据实际需求进行更多调整:
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import NNConv, SAGEConvclass EntityGraphModule(nn.Module):def __init__(self, node_in_feats, edge_in_feats, h_feats, num_classes):super(EntityGraphModule, self).__init__()lin = nn.Linear(edge_in_feats, node_in_feats * h_feats)edge_func = lambda e_feat: lin(e_feat)self.conv1 = NNConv(node_in_feats, h_feats, edge_func)self.conv2 = SAGEConv(h_feats, num_classes, "pool")def forward(self, g, node_features, edge_features):h = self.conv1(g, node_features, edge_features)h = F.relu(h)h = self.conv2(g, h)g.ndata["h"] = hreturn dgl.mean_nodes(g, "h")构造函数采用节点要素数、边要素数、隐藏节点数和标签(类)数。然后,它创建两个层:一个基于边和节点特征计算隐藏节点的 NNConv 层,然后是一个基于隐藏节点计算结果标签的 GraphSAGE 层。
五、培训和测试
快到了。接下来,我们准备用于训练和测试的数据。
from torch.utils.data.sampler import SubsetRandomSampler
from dgl.dataloading import GraphDataLoadernum_examples = len(dataset)
num_train = int(num_examples * 0.8)train_sampler = SubsetRandomSampler(torch.arange(num_train))
test_sampler = SubsetRandomSampler(torch.arange(num_train, num_examples))train_dataloader = GraphDataLoader(dataset, sampler=train_sampler, batch_size=5, drop_last=False
)
test_dataloader = GraphDataLoader(dataset, sampler=test_sampler, batch_size=5, drop_last=False
)我们使用随机抽样以 80/20 的比例进行拆分,并为每个样本创建一个数据加载器。最后一步是用我们的数据初始化模型,运行训练,然后测试结果。
h_feats = 64
learn_iterations = 50
learn_rate = 0.01model = EntityGraphModule(dataset.graphs[0].ndata["feat"].shape[1],dataset.graphs[0].edata["feat"].shape[1],h_feats,dataset.labels.max().item() + 1
)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)for _ in range(learn_iterations):for batched_graph, labels in train_dataloader:pred = model(batched_graph, batched_graph.ndata["feat"].float(), batched_graph.edata["feat"].float())loss = F.cross_entropy(pred, labels)optimizer.zero_grad()loss.backward()optimizer.step()num_correct = 0
num_tests = 0
for batched_graph, labels in test_dataloader:pred = model(batched_graph, batched_graph.ndata["feat"].float(), batched_graph.edata["feat"].float())num_correct += (pred.argmax(1) == labels).sum().item()num_tests += len(labels)acc = num_correct / num_tests
print("Test accuracy:", acc)我们通过提供节点和边的特征大小(在我们的例子中都是 2)、隐藏节点 (64) 和标签数量(2,因为它要么是欺诈,要么不是欺诈)来初始化模型。然后以 0.01 的学习率初始化优化器。之后,我们总共运行 50 次训练迭代。训练完成后,我们使用测试数据加载器测试结果并打印结果的准确性。
对于各种运行,我的典型准确度在 70% 到 85% 的范围内。但是,除了少数例外,降至55%左右。
六、结论
鉴于我们的示例数据集中唯一可用的信息是解释节点是如何连接的,初步结果看起来非常有希望,并表明通过真实世界的数据和更多的训练可以实现更高的准确率。
斯特凡·伯克纳
显然,在处理真实数据时,布局并不那么一致,并且没有在布局和欺诈行为之间提供明显的相关性。因此,您还应考虑边缘和节点功能。本文的关键要点应该是,实体解析为使用图形神经网络的欺诈检测提供了理想的数据,并且应被视为欺诈检测工程师工具库的一部分。
相关文章:
使用实体解析和图形神经网络进行欺诈检测
图形神经网络的表示形式(作者使用必应图像创建器生成的图像) 一、说明 对于金融、电子商务和其他相关行业来说,在线欺诈是一个日益严重的问题。为了应对这种威胁,组织使用基于机器学习和行为分析的欺诈检测机制。这些技术能够实时…...

vue中axios请求篇
vue中如何发起请求? 利用axios来发起请求,但是前期需要配置 首先安装axios 可以使用npm、yarn等进行安装 npm安装方式 npm install axios -sava //在项目文件夹中打开cmd或者终端进行安装依赖 yarn安装方式 yarn add axios 引入axios。我一般是在src下创建一个u…...
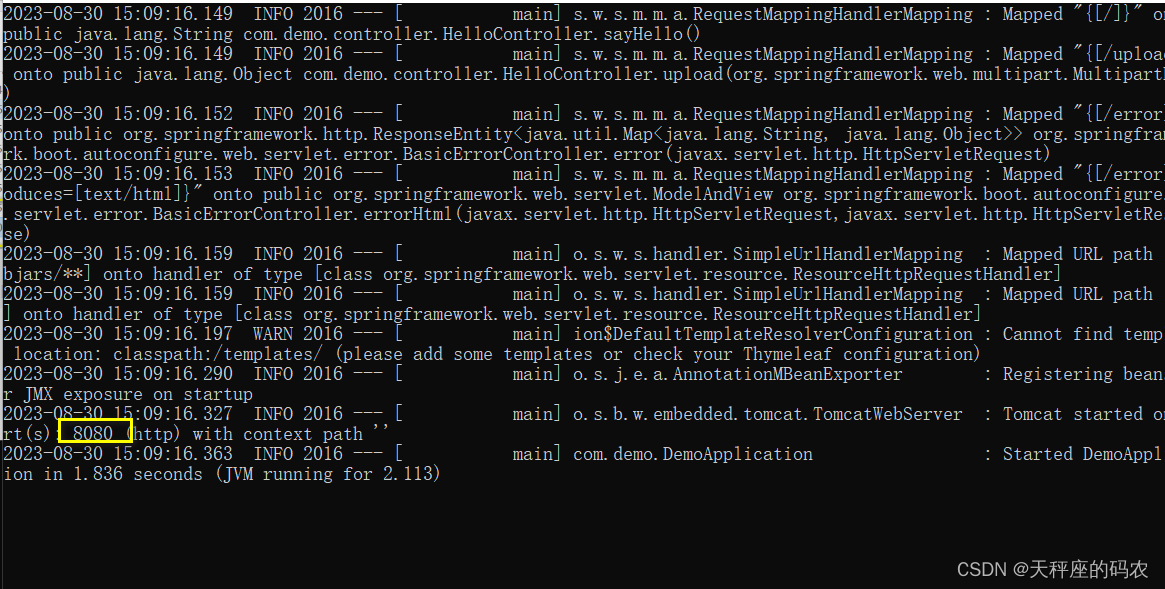
Springboot2.0 上传图片 jar包导出启动(第二章)
目录 一,目录文件结构讲解二,文件上传实战三,jar包方式运行web项目的文件上传和访问处理(核心知识)最后 一,目录文件结构讲解 简介:讲解SpringBoot目录文件结构和官方推荐的目录规范 1、目录讲解…...
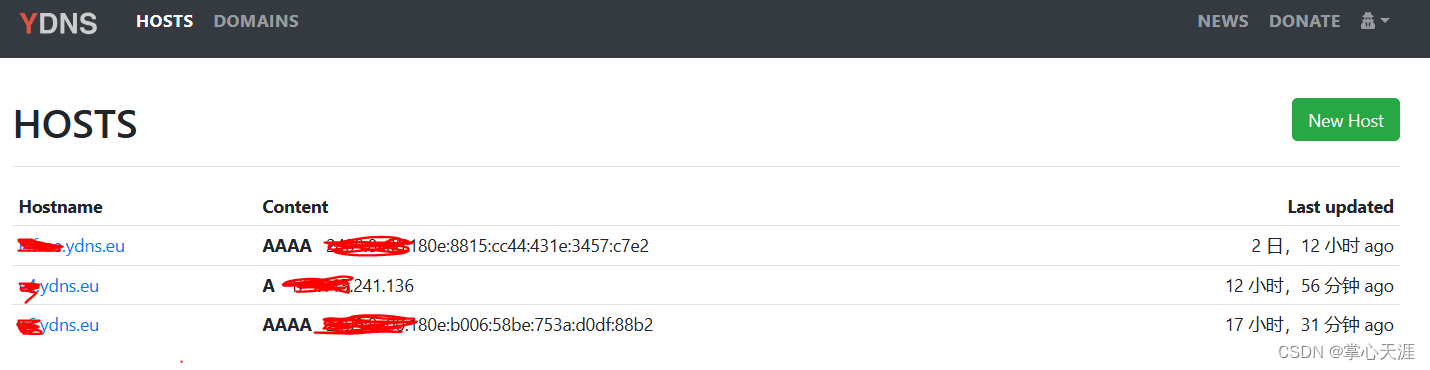
添加YDNS免费的ipv6动态域名解析
背景 又到了一年一度的dns域名到期,寻找替代了,前几年用了阿里、华为的免费域名,支持了几个搭建在NAS上的微服务;一旦涉及到域名续费,价格就比首年上去了不少,所以,打算找个长期的免费域名。 搜…...

爬虫异常处理之如何处理连接丢失和数据存储异常
在爬虫开发过程中,我们可能会遇到各种异常情况,如连接丢失、数据存储异常等。本文将介绍如何处理这些异常,并提供具体的解决代码。我们将以Python语言为例,使用requests库进行网络请求和sqlite3库进行数据存储。 1. 处理连接丢失 …...
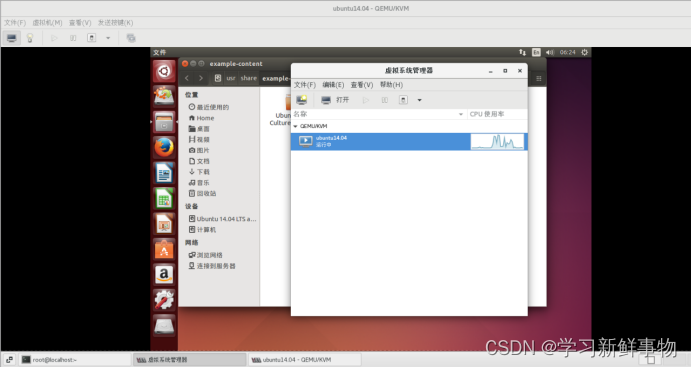
KVM虚拟化ubuntu
KVM(Kernel-based Virtual Machine)是一种基于Linux内核的虚拟化技术,它将Linux内核作为虚拟机的底层操作系统,利用硬件虚拟化支持创建和管理虚拟机。KVM虚拟化技术被广泛应用于云计算、虚拟化服务器、虚拟化桌面等场景。 KVM虚拟…...
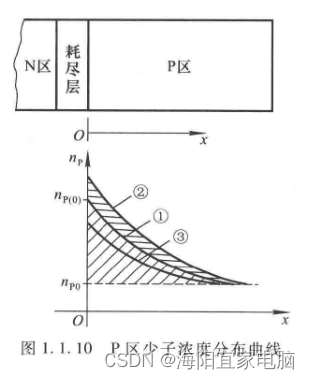
模拟电子技术基础学习笔记三 PN结
采用不周的掺杂工艺,将P型半导体与N型半导体制作在同一块硅片上,在它们的交界面就形成PN结。 扩散运动 物质总是从浓度高的地方向浓度低的地方运动,这种由于浓度差而产生的运动称为扩散运动。 空间电荷区 - 耗尽层 漂移运动 在电场力的作…...

java基础-----第七篇
系列文章目录 文章目录 系列文章目录一、什么是字节码?采用字节码的好处是什么?1.java中的编译器和解释器:2.采用字节码的好处:二、Java中的异常体系一、什么是字节码?采用字节码的好处是什么? 1.java中的编译器和解释器: Java中引入了虚拟机的概念,即在机器和编译程…...
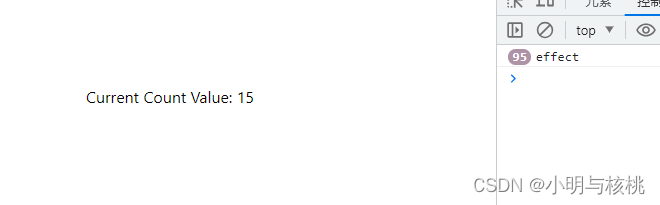
useEffect 不可忽视的 cleanup 函数
在 react 开发中, useEffect 是我们经常会使用到的钩子,一个基础的例子如下: useEffect(() > {// some code here// cleanup 函数return () > {doSomething()} }, [dependencies])上述代码中, cleanup 函数的执行时机有如下…...

vue3:使用:批量删除功能
场景:vue中使用el-table,常需要记住上一页所勾选的数据,批量删除操作,或者弹窗分页勾选,进行第一页勾选,在调后端接口选择第二页勾选其他数据。 1、element-ui 的table表格可以轻松实现多选的功能,只要在表…...

Scala中的样例类和样例对象和JAVA存根类
Scala中的样例类和样例对象 在 Scala 中,样例类(case class)和样例对象(case object)都是用于定义不可变数据类型的特殊类和对象。它们被广泛用于模式匹配、代数数据类型(Algebraic Data Types)…...

【0218】当SIGQUIT kill掉stats collector后,stats collector如何保存最终统计数据
1. stats collector可被哪些信号给kill? stats collector进程的主体函数是 PgstatCollectorMain(),该函数内部完成了stats collector进程的信号注册、现有统计文件读取、消息处理等任务。 忽略通常与postmaster中的某些操作绑定的所有信号,SIGHUP和SIGQUIT除外。 注意,我们…...

httplib 与 json.hpp 结合示例
httplib 与 json.hpp 结合示例 1、使用POST 接口,发送 登陆 请求 客户端发送 {nlohmann::json jsonOfCollectionInfo;jsonOfCollectionInfo["user_id"] "zhang";jsonOfCollectionInfo["password"] "123456";httplib::…...

RK3288安卓7.1开机上电到显示logo需要在3s内完成
需求: 从上电到开始开机logo有一段黑屏时间,这个黑屏时间大概在6s左右,给客户体验很不好,现在需要将这段黑屏时间缩短到2-3s左右 思路: 因为只需要早点显示logo,其实整体从上电到开机动画到安卓系统启动整体…...

Maven之hibernate-validator 高版本问题
hibernate-validator 高版本问题 hibernate-validator 的高版本(邮箱注解)依赖于高版本的 el-api,tomcat 8 的 el-api 是 3.0,满足需要。但是 tomcat 7 的 el-api 只有 2.2,不满足其要求。 解决办法有 2 种ÿ…...
C++--动态规划其他问题
1.一和零 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你一个二进制字符串数组 strs 和两个整数 m 和 n 。 请你找出并返回 strs 的最大子集的长度,该子集中 最多 有 m 个 0 和 n 个 1 。 如果 x 的所有元素也是 y 的元素࿰…...

PostgreSQL 查询语句大全
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...
扫盲:常用NoSQL数据库
前言 关系型数据库产品很多,如 MySQL、Oracle、Microsoft SQL Sever 等,但它们的基本模型都是关系型数据模型。 非关系型数据库又称为:NoSQL ,没有统一的模型,而且是非关系型的。 常见的 NoSQL 数据库包括键值数据库、…...

MPI之数据打包和解包
MPI_Pack 和 MPI_Unpack 它们可以将源数据打包成二进制格式以便于传输,或者将二进制格式的数据解包成目标数据。这对函数通常用于在 MPI 应用程序中进行异构系统间的通信,即两个系统之间使用不同的二进制格式进行交互通信。 打包(序列化&…...
9.2作业
QT实现闹钟 widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include<QTimerEvent> #include<QDateTime> #include<QLineEdit> #include<QLabel> #include<QPushButton> #include <QTextToSpeech> QT_BEGIN_NAMES…...

杰理之RX修改为连接一个TX后需要再次按键或者其他操作才能连接第二个TX的功能需求【篇】
void user_wireless_dev_pair_code_pri() { y_printf(“user_wireless_dev_pair_code_pri”); u32 pair_code 0; wireless_dev_get_pair_code(“big_rx”, (u8 *)&pair_code, 1); wireless_dev_set_pair_code(“big_rx”, (u8 *)&pair_code); } //连接一个无线麦后&am…...

3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄
3分钟快速上手vJoy:如何为Windows创建专业级虚拟游戏手柄 【免费下载链接】vJoy Virtual Joystick 项目地址: https://gitcode.com/gh_mirrors/vj/vJoy 您是否曾经因为缺少游戏手柄而无法畅玩那些只支持手柄操作的游戏?或者需要为特殊软件设计自定…...

抖音直播数据采集:如何用Golang构建实时弹幕监控系统
抖音直播数据采集:如何用Golang构建实时弹幕监控系统 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作日益火爆的今天,数据驱动的运营决策变得…...

办公效率翻倍!OpenClaw AI 数字员工实操教程
适配系统:Windows 10 64位(新手专享版) 产品亮点: 零门槛安装:无需命令行操作,免去复杂环境配置即开即用:解压即安装,内置完整运行环境可视化操作:全程图形界面&#x…...

SPSS虚拟变量避坑指南:创建后如何正确用于回归分析?别让编码错误毁了你的模型
SPSS虚拟变量实战避坑:从编码到回归分析的完整解决方案 在数据分析领域,虚拟变量(Dummy Variable)是将分类变量转换为可用于回归分析形式的桥梁。许多研究者虽然掌握了SPSS生成虚拟变量的基础操作,却在后续分析中频频…...

3分钟学会B站缓存视频永久保存:m4s-converter完整使用指南
3分钟学会B站缓存视频永久保存:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵…...
)
告别仿真卡顿!Synopsys AXI VIP Memory模型实战:从地址配置到后门读写(附避坑指南)
告别仿真卡顿!Synopsys AXI VIP Memory模型实战:从地址配置到后门读写(附避坑指南) 在复杂SoC验证中,仿真速度直接决定了项目周期。当AXI总线上的数据吞吐量达到GB/s级别时,传统的前门读写操作会让仿真器陷…...

Show-o2 3D Causal VAE空间:为文本、图像和视频模态提供可扩展解决方案
Show-o2 3D Causal VAE空间:为文本、图像和视频模态提供可扩展解决方案 【免费下载链接】Show-o [ICLR & NeurIPS 2025] Repository for Show-o series, One Single Transformer to Unify Multimodal Understanding and Generation. 项目地址: https://gitcod…...

如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南
如何用AntiMicroX解决PC游戏手柄兼容性问题:终极手柄映射工具完全指南 【免费下载链接】antimicrox Graphical program used to map keyboard buttons and mouse controls to a gamepad. Useful for playing games with no gamepad support. 项目地址: https://gi…...

深入解析Solana SPL Token:原理、生态与未来布局
深入解析Solana SPL Token:原理、生态与未来布局 引言 在追求高性能区块链的浪潮中,Solana以其惊人的交易速度和低廉的费用脱颖而出。而这一切,离不开其核心资产标准——SPL Token的支撑。无论是引爆市场的STEPN,还是承载万亿美…...