DataX及DataX-Web
- 大数据Hadoop之——数据同步工具DataX
- 数据采集工具-DataX
- datax详细介绍及使用
一、概述
DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
Gitee:github.com/alibaba/Dat…
GitHub地址:github.com/alibaba/Dat…
文档:github.com/alibaba/Dat…
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
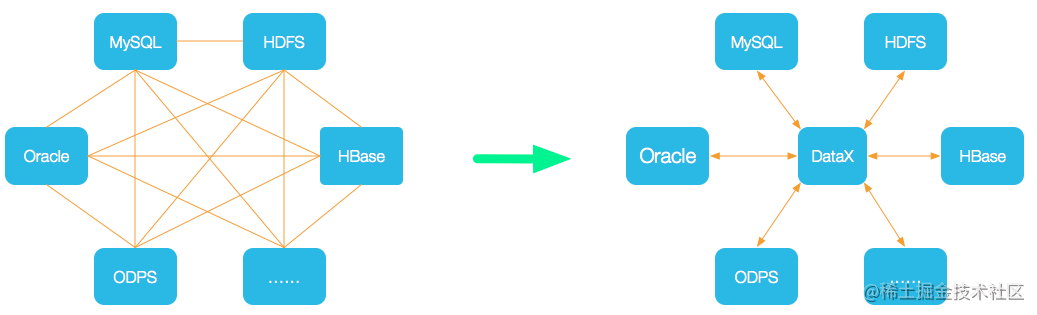
- 为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
- DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
二、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
2.1 核心流程架构图
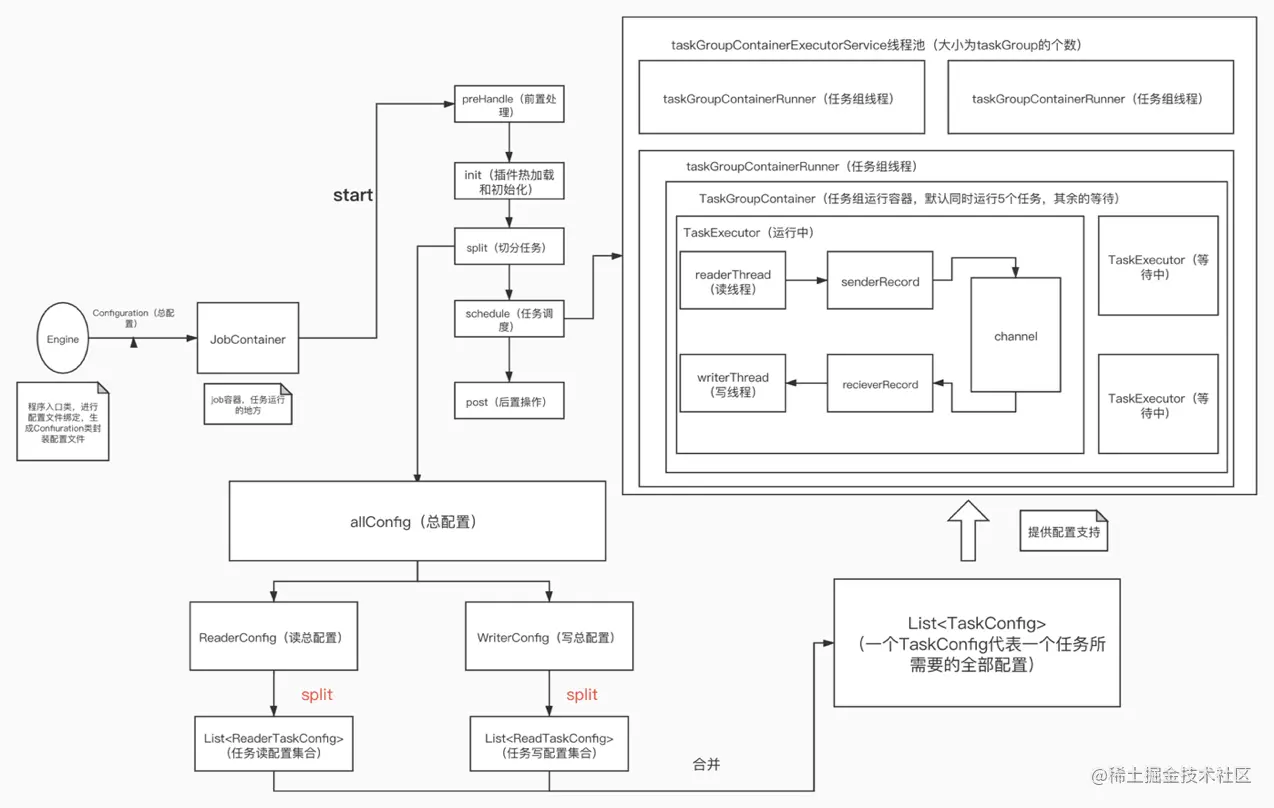
2.2 核心流程
- job 是 Datax 一次任务的统称,DataX JobContainer 是一个运行 job 的容器,是整个同步任务的管理控制中心,承担了插件初始化,数据清理、 数据检测、任务切分、TaskGroup 管理,任务调度,监控,回收等功能。
- DataX Job 启动后,会根据不同的源端切分策略,将 Job 切分成多个小的 Task(子任务),实质上是在切分配置文件,以便于并发执行。Task 便是 DataX 同步任务的基础单位,每一个 Task 都会负责一部分数据的同步工作。
- 切分后的 task,会根据并发要求,通过 schedule 方法重新组合成 TaskGroup,TaskGroup 线程由一个线程池维护并监控,一个 TaskGroup 默 认并发 5 个 Task。
- 每一个 Task 都由 TaskGroup 负责启动,Task 启动后,会启动读写两 个线程,并通过 Record 类作为媒介,Reader 不断地读出数据,并往传输中 转站 Channel 中存入信息,还 Writer 则负责从 Channel 中读出 Record 信 息,存入目标数据源。
- DataX 作业运行时,JobContainer 会监控各个 TaskGroup 模块任务, 直到所有任务完成,并记录日志,当有都成功后会返回 0,不然会有完整的报错机制,异常退出返回非 0。
三、DataX3.0架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
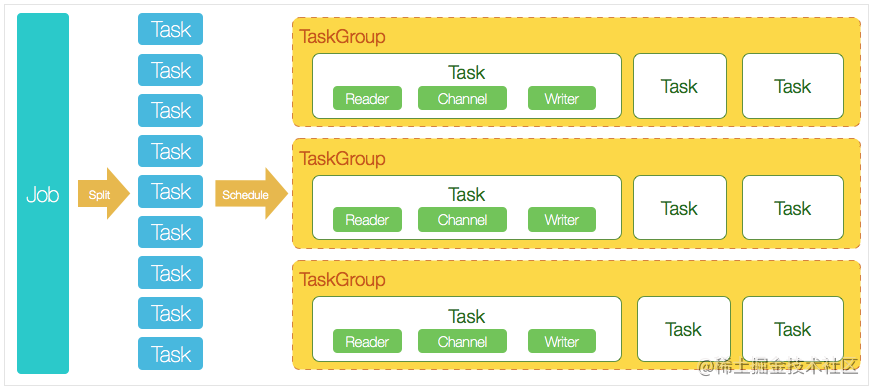
3.1 核心模块介绍
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动
Reader—>Channel—>Writer的线程来完成任务同步工作。 - DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
3.2 DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps(Open Data Processing Service:开发数据处理服务)里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
3.3 DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
四、环境部署
1)下载
$ mkdir -p /opt/bigdata/hadoop/software/datax ; cd /opt/bigdata/hadoop/software/datax
$ wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
$ tar -xf datax.tar.gz -C /opt/bigdata/hadoop/server/
2)设置环境变量
$ cd /opt/bigdata/hadoop/server/
$ vi /etc/profile
export DATAX_HOME=/opt/bigdata/hadoop/server/datax
export PATH=$DATAX_HOME/bin:$PATH
$ source /etc/profile
五、DataX优化
- DataX使用、同步HDFS数据到MySQL案例、DataX优化
5.1 速度控制
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在数据库可以承受的范围内达到最佳的同步速度。
关键优化参数如下:
| 参数 | 说明 |
|---|---|
| job.setting.speed.channel | 并发数 |
| job.setting.speed.record | 总record限速 (tps每秒处理的条数) |
| job.setting.speed.byte | 总byte限速 (bps每秒处理的字节数) |
| core.transport.channel.speed.record | 单个channel的record限速,默认值为10000(10000条/s) |
| core.transport.channel.speed.byte | 单个channel的byte限速,默认值1024*1024(1M/s) |
注意事项:
1.若配置了总record限速,则必须配置单个channel的record限速
2.若配置了总byte限速,则必须配置单个channe的byte限速
3.若配置了总record限速和总byte限速,channel并发数参数就会失效。因为配置了总record限速和总byte限速之后,实际channel并发数是通过计算得到的:
计算公式为:
min(总byte限速/单个channel的byte限速,总record限速/单个channel的record限速)
配置示例:
{"core": {"transport": {"channel": {"speed": {"byte": 1048576 //单个channel byte限速1M/s}}}},"job": {"setting": {"speed": {"byte" : 5242880 //总byte限速5M/s}},...}
}
5.2 内存调整
当提升DataX Job内Channel并发数时,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止OOM等错误,需调大JVM的堆内存。
建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。
调整JVM xms xmx参数的两种方式:一种是直接更改datax.py脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" /path/to/your/job.json
六、DataX-Web
GitHub地址:WeiYe-Jing/datax-web
前端地址:https://github.com/WeiYe-Jing/datax-web-ui
作者开源中国博客地址:https://segmentfault.com/u/weiye_jing/articles
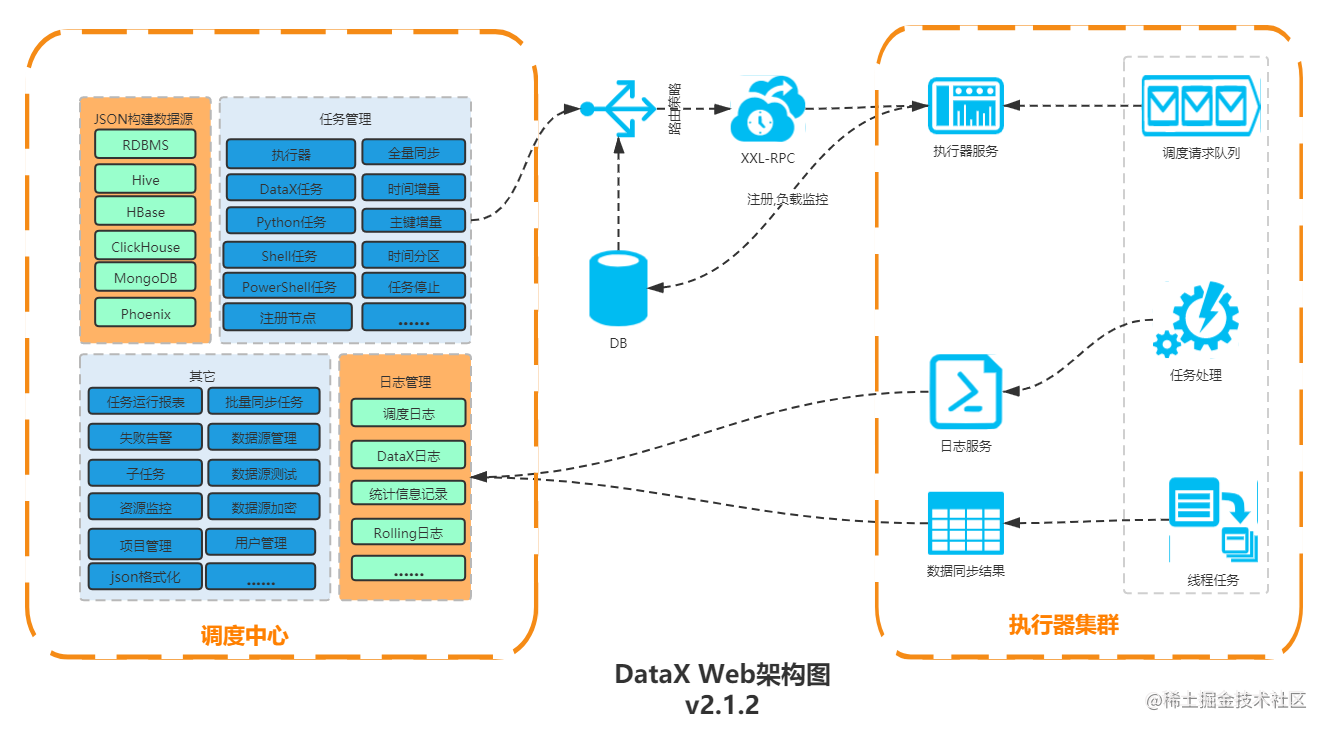
6.1 DataX-web安装
- datax + datax_web避坑指南
- CentOS7安装DataX和datax-web
6.2 DataX-Web使用
- Datax-web 源码阅读记录
6.2.1 前端访问
部署完成后,在浏览器中输入 http://ip:port/index.html 就可以访问对应的主界面(ip为datax-admin部署所在服务器ip,port为为datax-admin 指定的运行端口9527),初始账号:admin,密码:123456。
6.2.2 datax-web API
datax-web部署成功后,可以了解datax-web API相关内容,网址: http://ip:port/doc.html
6.2.3 路由策略
当执行器集群部署时,提供丰富的路由策略,包括:
- FIRST(第一个):固定选择第一个机器;
- LAST(最后一个):固定选择最后一个机器;
- ROUND(轮询):依次分配任务;
- RANDOM(随机):随机选择在线的机器;
- CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
- LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
- FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略
- 单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
设置单机串行时应该注意合理设置重试次数(失败重试的次数* 每次执行时间< 任务的调度周期),重试的次数如果设置的过多会导致数据重复,例如任务30秒执行一次,每次执行时间需要20秒,设置重试三次,如果任务失败了,第一个重试的时间段为1577755680-1577756680,重试任务没结束,新任务又开启,那新任务的时间段会是1577755680-1577758680
6.3 DataX-Web打包部署
- datax-web在windows环境idea中模块化打包部署操作步骤
6.3.1 pom.xml修改
分别在datax-admin和datax-executor下面的pom.xml文件中添加
<plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><configuration><excludes><exclude>**/*.yml</exclude><exclude>**/*.properties</exclude><exclude>**/*.sh</exclude><exclude>**/*.xml</exclude></excludes></configuration>
</plugin>
<plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><executions><execution><goals><goal>repackage</goal></goals></execution></executions>
</plugin>
6.3.2 将静态资源移入jar包中
将datax-admin下的所有配置资源拷贝进datax-admin-2.1.2.jar的相关目录中。具体如下:
1)将idea中的datax-admin下的classes下的配置文件application.yml、bootstrap.properties、logback.xml拷贝进datax-admin-2.1.2.jar下的BOOT-INF\classes下。
2)将datax-admin下的target/classes/i8n下的message.properties和message_en.properties拷贝进datax-admin-2.1.2.jar下的BOOT-INF\classes\i18n下
3)将将datax-admin下的target/classes/mybatis-mapper下的所有xml文件拷贝进datax-admin-2.1.2.jar下的BOOT-INF\classes\mybatis-mapper下
4)将idea中的datax-executor编译生成后的classes下的配置文件application.yml、logback.xml拷贝进datax-executor-2.1.2.jar下的BOOT-INF\classes下。
6.4 参考资料
- Datax3.0+DataX-Web打造分布式可视化ETL系统
- linux搭建datax、datax-web
- ETL工具datax任务构建可视化管理
- Datax-web 集群化部署使用(图文教程超详细)
- Datax-web入门配置与启动
- Datax-web的入门使用
- 数据同步工具—DataX—Web部署使用
七、DataX和Sqoop、Kettle等的比较
- 【知识】ETL大数据集成工具Sqoop、dataX、Kettle、Canal、StreamSets大比拼
- 六种 主流ETL 工具的比较(DataPipeline,Kettle,Talend,Informatica,Datax ,Oracle Goldengate)
以下对开源的Sqoop、dataX、Kettle、Canal、StreamSetst进行简单梳理比较,通过分析,建议优先DataX更优。
| 比较维度\产品 | DataPipeline | kettle | Oracle Goldengate | informatica | talend | DataX | |
|---|---|---|---|---|---|---|---|
| 设计及架构 | 适用场景 | 主要用于各类数据融合、数据交换场景,专为超大数据量、高度复杂的数据链路设计的灵活、可扩展的数据交换平台 | 面向数据仓库建模传统ETL工具 | 主要用于数据备份、容灾 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 |
| 使用方式 | 全流程图形化界面,应用端采用B/S架构,Cloud Native为云而生,所有操作在浏览器内就可以完成,不需要额外的开发和生产发布 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境,线上生产环境没有界面,需要通过日志来调试、debug,效率低,费时费力 | 没有图形化的界面,操作皆为命令行方式,可配置能力差 | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境;学习成本较高,一般需要受过专业培训的工程师才能使用; | C/S客户端模式,开发和生产环境需要独立部署,任务的编写、调试、修改都在本地,需要发布到生产环境; | DataX是以脚本的方式执行任务的,需要完全吃透源码才可以调用,学习成本高,没有图形开发化界面和监控界面,运维成本相对高。 | |
| 底层架构 | 分布式集群高可用架构,可以水平扩展到多节点支持超大数据量,架构容错性高,可以自动调节任务在节点之间分配,适用于大数据场景 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 可做集群部署,规避单点故障,依赖于外部环境,如Oracle RAC等; | schema mapping非自动;可复制性比较差;更新换代不是很强 | 支持分布式部署 | 支持单机部署和集群部署两种方式 | |
| 功能 | CDC机制 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于时间戳、触发器等 | 主要是基于日志 | 基于日志、基于时间戳和自增序列等多种方式可选 | 基于触发器、基于时间戳和自增序列等多种方式可选 | 离线批处理 |
| 对数据库的影响 | 基于日志的采集方式对数据库无侵入性 | 对数据库表结构有要求,存在一定侵入性 | 源端数据库需要预留额外的缓存空间 | 基于日志的采集方式对数据库无侵入性 | 有侵入性 | 通过sql select 采集数据,对数据源没有侵入性 | |
| 自动断点续传 | 支持 | 不支持 | 支持 | 不支持,依赖ETL设计的合理性(例如T-1),指定续读某个时间点的数据,非自动 | 不支持,依赖ETL设计的合理性(例如T-1),指定续读某个时间点的数据,非自动 | 不支持 | |
| 监控预警 | 可视化的过程监控,提供多样化的图表,辅助运维,故障问题可实时预警 | 依赖日志定位故障问题,往往只能是后处理的方式,缺少过程预警 | 无图形化的界面预警 | monitor可以看到报错信息,信息相对笼统,定位问题仍需依赖分析日志 | 有问题预警,定位问题仍需依赖日志 | 依赖工具日志定位故障问题,没有图形化运维界面和预警机制,需要自定义开发。 | |
| 数据清洗 | 围绕数据质量做轻量清洗 | 围绕数据仓库的数据需求进行建模计算,清洗功能相对复杂,需要手动编程 | 轻量清洗 | 支持复杂逻辑的清洗和转化 | 支持复杂逻辑的清洗和转化 | 需要根据自身清晰规则编写清洗脚本,进行调用(DataX3.0 提供的功能)。 | |
| 数据转换 | 自动化的schema mapping | 手动配置schema mapping | 需手动配置异构数据间的映射 | 手动配置schema mapping | 手动配置schema mapping | 通过编写json脚本进行schema mapping映射 | |
| 特性 | 数据实时性 | 实时 | 非实时 | 实时 | 支持实时,但是主流应用都是基于时间戳等方式做批量处理,实时同步效率未知 | 实时 | 定时 |
| 应用难度 | 低 | 高 | 中 | 高 | 中 | 高 | |
| 是否需要开发 | 否 | 是 | 是 | 是 | 是 | 是 | |
| 易用性 | 高 | 低 | 中 | 低 | 低 | 低 | |
| 稳定性 | 高 | 低 | 高 | 中 | 中 | 中 | |
| 其他 | 实施及售后服务 | 原厂实施和售后服务 | 开源软件,需自客户自行实施、维护 | 原厂和第三方的实施和售后服务 | 主要为第三方的实施和售后服务 | 分为开源版和企业版,企业版可提供相应服务 | 阿里开源代码,需要客户自动实施、开发、维护 |
八、DataX与Kettle对比
-
浅测评DataX与Kettle
-
Datax和Kettle使用场景的对比
| 较维度\产品 | Kettle | DataX | |
|---|---|---|---|
| 设计及架构 | 适用场景 | 面向数据仓库建模传统ETL工具 | 面向数据仓库建模传统ETL工具 |
| 支持数据源 | 多数关系型数据库 | 少数关系型数据库和大数据非关系型数据库 | |
| 开发语言 | Java | Python、Java | |
| 可视化web界面 | KettleOnline代码收费Kettle-manager代码免费 | Data-Web代码免费 | |
| 底层架构 | 主从结构非高可用,扩展性差,架构容错性低,不适用大数据场景 | 支持单机部署和第三方调度的集群部署两种方式 | |
| 功能 | CDC机制 | 基于时间戳、触发器等 | 离线批处理 |
| 抽取策略 | 支持增量,全量抽取 | 支持全量抽取。不支持增量抽取要通过shell脚本自己实现 | |
| 对数据库的影响 | 对数据库表结构有要求,存在一定侵入性 | 通过sql select 采集数据,对数据源没有侵入性 | |
| 自动断点续传 | 不支持 | 不支持 | |
| 数据清洗 | 围绕数据仓库的数据需求进行建模计算,清洗功能相对复杂,需要手动编程 | 需要根据自身清晰规则编写清洗脚本,进行调用(DataX3.0 提供的功能)。 | |
| 数据转换 | 手动配置schema mapping | 通过编写json脚本进行schema mapping映射 | |
| 特性 | 数据实时性 | 非实时 | 定时 |
| 应用难度 | 高 | 高 | |
| 是否需要开发 | 是 | 是 | |
| 易用性 | 低 | 低 | |
| 稳定性 | 低 | 中 | |
| 抽取速度 | 小数据量的情况下差别不大,大数据量时datax比kettle快。datax对于数据库压力比较小 | ||
| 其他 | 实施及售后服务 | 开源软件,社区活跃度高 | 阿里开源代码,社区活跃度低 |
九、实战案例
-
dataX案例 读取mysql(通过表名或自定义sql语句)数据写入到hdfs中 (txt或orc存储,gzip或snappy压缩)_
-
dataX案例 读取hdfs文件,写入到mysql中
-
dataX案例 从Oracle中读取数据(自定义sql语句)存到MySQL中_
-
dataX案例-从mysql读取数据,写入到hbase中
-
dataX案例-从hbase中读取数据,写入到文本文件中
-
使用 DataX 实现数据同步(高效的数据同步工具)
DataX系列博文:
- DataX 全系列之一 —— DataX 安装和使用
- DataX全系列之二 —— DataX 总体架构和原理
- DataX 全系列之三 —— DataX 源码运行流程分析
- DataX 全系列之四 —— DataX 核心数据结构
- DataX 全系列之五 —— DataX-web 介绍和使用
9.1 Datax同步MySQL到Hive
- dataX同步mysql至hive
9.1.1 前言
以下是我的一个mysql同步到Hive,相关的变量都可以通过传参统一脚本处理。
{"job": {"setting": {"speed": {"channel": 3}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "${username}","password": "${password}","connection": [{"jdbcUrl": ["${jdbcUrl}"],"querySql": ["select id,create_time,update_time from ${sourceTableName} where update_time<'${endTime}' " ]}]}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "string"},{"name": "create_time","type": "string"},{"name": "update_time","type": "string"}],"isCompress": "${isCompress}","defaultFS": "${hdfsPath}","fieldDelimiter": "${fieldDelimiter}","fileName": "${fileName}","fileType": "${fileType}","path": "${path}","writeMode": "${writeMode}"}}}]}
}
9.1.2 参数调用和传参
使用dataX调用这个脚本。
python ${DATAX_HOME}/bin/datax.py -p"-DtargetDBName=$TARGET_DB_NAME -DtargetTableName=$TARGET_TABLE_NAME -DjdbcUrl=$MYSQL_URL -Dusername=$MYSQL_USERNAME -Dpassword=$MYSQL_PASSWD -DsourceTableName=$SOURCE_TABLE_NAME -DhdfsPath=$HDFS_PATH -DstartTime=${START_TIME} -DendTime=${END_TIME} -DisCompress=$ISCOMPRESS -DwriteMode=$WRITEMODE -DfileType=$FILETYPE -DfieldDelimiter='$FIELDDELIMITER' -DfileName=$TARGET_TABLE_NAME -Dpath=${PATH_HIVE}$TARGET_DB_NAME.db/$TARGET_TABLE_NAME/day=$DT_TIME" $DATAX_JSON_FILE;
在这个命令中你会发现将所有的变量都通过shell命令传递进去了。后续的这些变量传递我在更新。之所以这么多变量其主要是为了方便后续的脚本更新和调度运行。
对于开发人员只需要关心主要逻辑就行了。
有了这个基础脚本,我们就可以将HIVE上的一些功能一起合并到shell脚本中:
- 增量同步,保留全部数据。
- 全量同步,全量同步只保留固定周期的历史全量。
- 刷新元数据。
- 通知更新成功。
- 多个mysql业务库的匹配。
- 生产业务库密码的保护。
9.1.3 封装shell调用脚本
基于上面的考虑。封装dataX的调用脚本。
#!/bin/bash
source /etc/profile
DATAX_HOME="/home/data/datax"
SHELL_PATH="/home/data/dw_datax"
SCRIPT_PATH=${SHELL_PATH}/job
DATAX_LOG=${SHELL_PATH}/logs/datax.log.`date "+%Y-%m-%d"`
HDFS_PATH="hdfs://hdfs-cluster"
#START_TIME=$(date -d "-1 day" +%Y-%m-%d)
#END_TIME=$(date "+%Y-%m-%d")
#DT_TIME=$(date -d "-1 day" +%Y%m%d)
START_TIME=""
END_TIME=""
DT_TIME=""
#失效日期
INVALID_DATE=""
#失效天数
INVALID_DAYS=180
#是否清除失效数据:默认清除
IS_CLEAR_INVALID_DATA=1#参数
ISCOMPRESS="false"
WRITEMODE="nonConflict"
FIELDDELIMITER="|"
FILETYPE="orc"
PATH_HIVE="/user/hive/warehouse/"
MYSQL_URL=""
#数据库用户名
MYSQL_USERNAME="admin"
#数据库密码
MYSQL_PASSWD="123456"
#默认同步目标库名
TARGET_DB_NAME="ods"
#同步源库名
SOURCE_DB_NAME=""
#同步源表名
SOURCE_TABLE_NAME=""
#业务名称
BUSINESS_NAME=""
#datax json文件
DATAX_JSON_FILE=/temp# 数据库实例信息
declare -A db_instance_conf
# 数据库用户名
declare -A db_instance_user_conf
# 数据库密码
declare -A db_instance_pwd_conf
# 数据库实例与库映射关系
declare -A db_instance_maps# 初始化数据库实例配置
function initInstanceConf()
{# 主业务线 ywx1db_instance_conf["db_main_data"]="jdbc:mysql://192.168.1.1:3306/"db_instance_user_conf["db_main_data"]="admin"db_instance_pwd_conf["db_main_data"]="123456"# 业务线2 ywx2db_instance_conf["db_data"]="jdbc:mysql://192.168.1.2:3306/"db_instance_user_conf["db_data"]="admin"db_instance_pwd_conf["db_data"]="123456"...}# 初始化库和数据库实例映射关系
function initDbAndInstanceMaps()
{#主业务线db_instance_maps["ywx1_db_main"]="db_main_data"#业务线2db_instance_maps["ywx2_db_data"]="db_data"#业务线3db_instance_maps["ywx3_db_insurance"]="db_ywx3"......db_instance_maps["dss_db_dss"]="db_dss"}#时间处理 传入参数 yyyy-mm-dd
function DateProcess()
{
echo "日期时间为"$1
if echo $1 | grep -Eq "[0-9]{4}-[0-9]{2}-[0-9]{2}" && date -d $1 +%Y%m%d > /dev/null 2>&1then :START_TIME=$(date -d $1 "+%Y-%m-%d")END_TIME=$(date -d "$1 +1 day" +%Y-%m-%d)DT_TIME=$(date -d $1 +"%Y%m%d")INVALID_DATE=$(date -d "$1 -$INVALID_DAYS day" +%Y%m%d)echo 时间正确: $START_TIME / $END_TIME / $DT_TIME / $INVALID_DATE;
elseecho "输入的日期格式不正确,应为yyyy-mm-dd";exit 1;
fi;}function DataConnect()
{db_business_key="$BUSINESS_NAME""_""$SOURCE_DB_NAME"db_instance_key=${db_instance_maps["$db_business_key"]}echo $db_business_key $db_instance_keyif [ ! -n "$db_instance_key" ]; thenecho "当前数据库连接信息不存在,请确认业务和数据库连接是否正确或联系管理员添加"exit 1;fidb_instance_value=${db_instance_conf["$db_instance_key"]}MYSQL_USERNAME=${db_instance_user_conf["$db_instance_key"]}MYSQL_PASSWD=${db_instance_pwd_conf["$db_instance_key"]}echo $db_instance_valueif [ ! -n "$db_instance_value" ]; thenecho "当前数据库连接信息不存在,请确认业务和数据库连接是否正确或联系管理员添加"exit 1;fiMYSQL_URL="$db_instance_value$SOURCE_DB_NAME"
}#每天运行 执行dataX
function BaseDataxMysql2Hive()
{#清除重复同步数据分区&新增分区hive -e "ALTER TABLE $TARGET_DB_NAME.$TARGET_TABLE_NAME DROP IF EXISTS PARTITION(day='$DT_TIME');ALTER TABLE $TARGET_DB_NAME.$TARGET_TABLE_NAME ADD IF NOT EXISTS PARTITION (day='$DT_TIME')";#执行同步echo "开始执行同步"if ! python ${DATAX_HOME}/bin/datax.py -p"-DtargetDBName=$TARGET_DB_NAME -DtargetTableName=$TARGET_TABLE_NAME -DjdbcUrl=$MYSQL_URL -Dusername=$MYSQL_USERNAME -Dpassword=$MYSQL_PASSWD -DsourceTableName=$SOURCE_TABLE_NAME -DhdfsPath=$HDFS_PATH -DstartTime=${START_TIME} -DendTime=${END_TIME} -DisCompress=$ISCOMPRESS -DwriteMode=$WRITEMODE -DfileType=$FILETYPE -DfieldDelimiter='$FIELDDELIMITER' -DfileName=$TARGET_TABLE_NAME -Dpath=${PATH_HIVE}$TARGET_DB_NAME.db/$TARGET_TABLE_NAME/pt_day=$DT_TIME" $DATAX_JSON_FILE;thenecho "command failed"exit 1;fiecho "同步结束"#删除定义的失效日期数据if(($IS_CLEAR_INVALID_DATA==1));thenecho "清除失效$INVALID_DATE天数的历史数据"hive -e "ALTER TABLE $TARGET_DB_NAME.$TARGET_TABLE_NAME DROP IF EXISTS PARTITION (pt_day<=${INVALID_DATE});"fi#同步分区元数据#hive -e "ANALYZE TABLE $TARGET_DB_NAME.$TARGET_TABLE_NAME PARTITION (day=${DT_TIME}) COMPUTE STATISTICS;"#删除分区数据
}function parseArgs()
{while getopts ":d:ab:s:m:f:t:n:u:p:" optdocase $opt ind)echo "参数d的值$OPTARG"DateProcess $OPTARG;;a)IS_CLEAR_INVALID_DATA=0echo "参数a的值$OPTARG";;b)echo "参数b的值$OPTARG"BUSINESS_NAME=$OPTARG;;m)echo "参数m的值$OPTARG"SOURCE_DB_NAME=$OPTARG;;s)echo "参数s的值$OPTARG"SOURCE_TABLE_NAME=$OPTARG;;f)echo "参数f的值$OPTARG"DATAX_JSON_FILE=$OPTARG;;n)echo "参数n的值$OPTARG"TARGET_DB_NAME=$OPTARG;;t)echo "参数t的值$OPTARG"TARGET_TABLE_NAME=$OPTARG;;u)echo "参数u的值$OPTARG"MYSQL_USERNAME=$OPTARG;;p)echo "参数t的值$OPTARG"MYSQL_PASSWD=$OPTARG;;?)echo "未知参数"exit 1;;:)echo "没有输入任何选项 $OPTARG";;esac done
}function judgeParams()
{if [ ! -n "$DT_TIME" ] ;thenecho "you have not input a etlDate! format {-d yyyy-mm-dd} "exit 1;fiif [ ! -n "$BUSINESS_NAME" ] ;thenecho "you have not input a businessName! incloud(xxx,xxxx,x,xx) example {-b xxx}"exit 1;fiif [ ! -n "$SOURCE_DB_NAME" ] ;thenecho "you have not input a sourceDB!"exit 1;fiif [ ! -n "$SOURCE_TABLE_NAME" ] ;thenecho "you have not input a sourceTable example {-s user_info}!"exit 1;fiif [ ! -n "$DATAX_JSON_FILE" ] ;thenecho "you have not input a dataxJson! example {-f ods_ywx1_user_info_di.json}"exit 1;fiif [ ! -n "$TARGET_TABLE_NAME" ] ;thenecho "you have not input a targetTable! example {-t ods_ywx1_user_info_di}"exit 1;fi
}function startsync()
{#初始化数据库实例initInstanceConf#初始化库和数据库实例映射关系initDbAndInstanceMaps#解析参数parseArgs "$@"#初始化数据链接DataConnect#判断参数judgeParams#同步数据BaseDataxMysql2Hive
}# -d: 处理时间
# -b:业务线 (ywx,ywx1,ywx1,...,ywxn)
# -m:源数据库
# -a:增量数据不清除分区数据:默认清除
# -s:源数据表
# -n:目标数据库
# -t:目标数据表
# -f:datax同步json文件
# -p:密码
# -u:用户名startsync "$@"
有了这个shell脚本,后续对于同步的一些同步完成功能的通知以及新功能都可以新增。同时又新形成了一个数据同步的规范性和开发的规范性。
9.1.4 调度平台调度脚本
有了上面的脚本,我们就可以只需要写好源表和目的表的名称。同时通过 -a 来区别增量还是全量同步进行处理。
#源表 -s
SOURCE_TABLE_NAME="user_info"
#目标表 -t
TARGET_TABLE_NAME="ods_main_user_info_df"
#datax 文件 -f
DATAX_FILE="${BASE_DIR_PATH}/ods_main_user_info_df.json"
ETL_DATE=${ETL_DATE}
BUSINESS_NAME=${BUSINESS_NAME}
SOURCE_DB_NAME=${SOURCE_DB_NAME}
#!/bin/bash
source /etc/profile
sh dataxsync.sh -d $ETL_DATE -b $BUSINESS_NAME -m $SOURCE_DB_NAME -s $SOURCE_TABLE_NAME -t $TARGET_TABLE_NAME -f $DATAX_FILE
我们可以发现这个脚本中包含了四个变量:
${BASE_DIR_PATH}
${ETL_DATE}
${BUSINESS_NAME}
${SOURCE_DB_NAME}
这几个变量主要是通过调度平台传入,
-
BASE_DIR_PATH:dataX脚本的统一地址,之所以弄这个目录主要是为了区分不同业务线。
-
ETL_DATE:每天同步的时间 : yyyy-mm-dd,同时我们可以再脚本上多增加几个时间,通过这个变量转换出来(yyyyMMdd, yyyyMMdd-1…)
-
BUSINESS_NAME:业务线的标识,我们也是可以用主题域区分。主要是用来识别数据库
-
SOURCE_DB_NAME:业务库的表名。
相关文章:
DataX及DataX-Web
大数据Hadoop之——数据同步工具DataX数据采集工具-DataX datax详细介绍及使用 一、概述 DataX 是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、…...

数据结构与算法系列之kmp算法
什么是kmp算法 1.kmp算法是一种改进的字符串算法,其核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数已达到快速匹配的目的。 它主要实现作用的是 在 (主串)中找到 (匹配)字符串。 例 BF算法与k…...

算法分析详解
自古老的公元前1世纪开始,《周髀算经》就作为中国最古老的天文学和数学著作。 《周髀算经》采用最简便可行的方法确定天文历法,揭示日月星辰的运行规律,包括四季更替,气候变化,南北有极,昼夜相推的道理。为…...

东南大学自然辩证法概论期末总结
写在前面 作者:夏日 博客地址:https://blog.csdn.net/zss192 本文为2022年东南大学自然辩证法概论期末总结,内容为根据老师所发题纲综合多个资料总结得来 考试形式:从老师所发题纲,10个题目中选出4个,题…...

《爆肝整理》保姆级系列教程python接口自动化(二十)--token登录(详解)
简介 为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。有些登录不是用 cookie 来验证的,是用 token 参数来判断是否登录。token 传参有两种一种是放在请求头里,本质上是跟 cookie 是一样的&…...
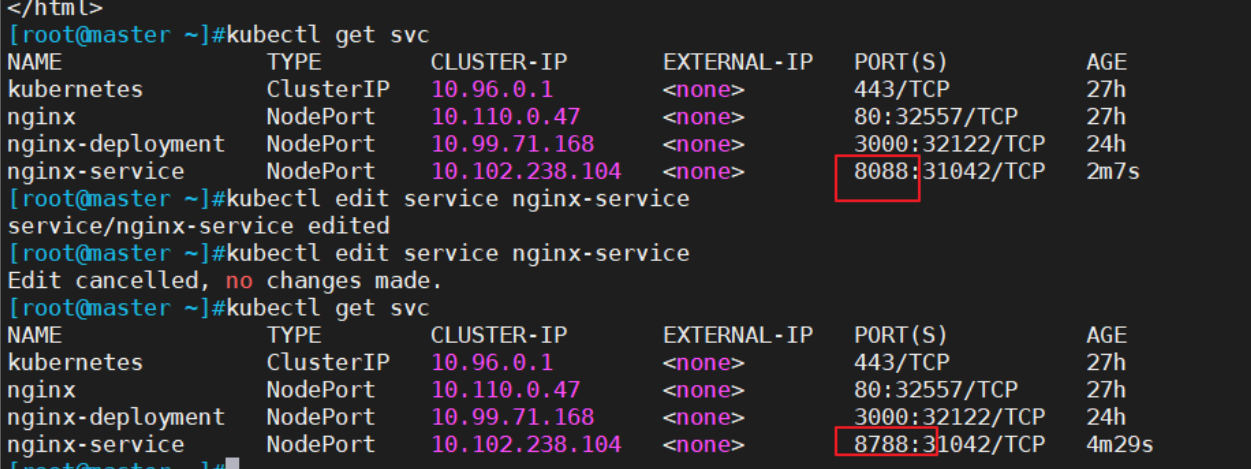
k8s种的kubectl命令
一.kubectl基本命令1.1 称述式资源管理的方法kubernetes集群管理集群资源的唯一入口是通过相应的方法调用apiserver的接口kubectl是官方的CLI命令行工具,用于与apiserver进行通信,将用户在命令行输入的命令,组织并转化为apiserver能识别的信息…...

数组(一)-- LeetCode[26][80] 删除有序数组中的重复元素
1 删除有序数组中的重复项 1.1 题目描述 给你一个 升序排列 的数组 nums ,请你 原地 删除重复出现的元素,使每个元素 只出现一次,返回删除后数组的新长度。元素的 相对顺序 应该保持 一致 。 由于在某些语言中不能改变数组的长度,…...
GEE学习笔记 六十三:新的地图图层ui.Map.CloudStorageLayer
在GEE中导出数据有一种方式是直接导出地图到Google Cloud Storage中,也就是Export.map.toCloudStorage(xxx),这种方式是将我们计算生成影像导出成为静态瓦片的格式存放在Google Cloud Storage中。我们可以在其他的前端程序比如OpenLayer、Mapbox GL JS等…...

ClickHouse 语法详解
ClickHouse有2类解析器:完整SQL解析器(递归式解析器),以及数据格式解析器(快速流式解析器) 除了 INSERT 查询,其它情况下仅使用完整SQL解析器。 INSERT查询会同时使用2种解析器:INSE…...
手把手教你将微信小程序放到git上
背景 首先,要创建一个自己的git仓库,这里默认大家都能够自己创建了git仓库了。如果不会创建仓库的话,百度一下,很容易就能够创建了!(后续,如有不知道在哪里,怎么创建仓库的话&#…...

功能测试3年,回顾一路走来的艰辛
不论你是什么时候开始接触测试这个行业的,你首先听说的应该是功能测试。通过一些测试手段来验证开发做出的代码是否符合产品的需求?当然你也有自己对功能测试的理解,但是最近两年感觉功能测试好像不太受欢迎,同时不少同学真的是功…...

作为Linux C/C++程序员必备的工具
Linux系统 可以选择centOS或者ubautu server(不建议选择桌面版本的)。不建议裸机安装,玩坏了就特别麻烦。不建议使用有桌面版本的ubautu,在一定程度有桌面的版本的会消耗性能。 如果经济实力允许,可以购买云服务器。 参考文章: Ubuntu server…...

docker Alpine一个只有5M小而美的Docker镜像
docker Alpine一个只有5M小而美的Docker镜像 参考链接: Alpine 一个只有5M的Docker镜像 http://www.infoq.com/cn/news/2016/01/Alpine-Linux-5M-Docker?utm_sourcetuicool&utm_mediumreferral 使用alpinelinux 构建 golang http 启动了才15mb http://blog.csdn.net/fre…...
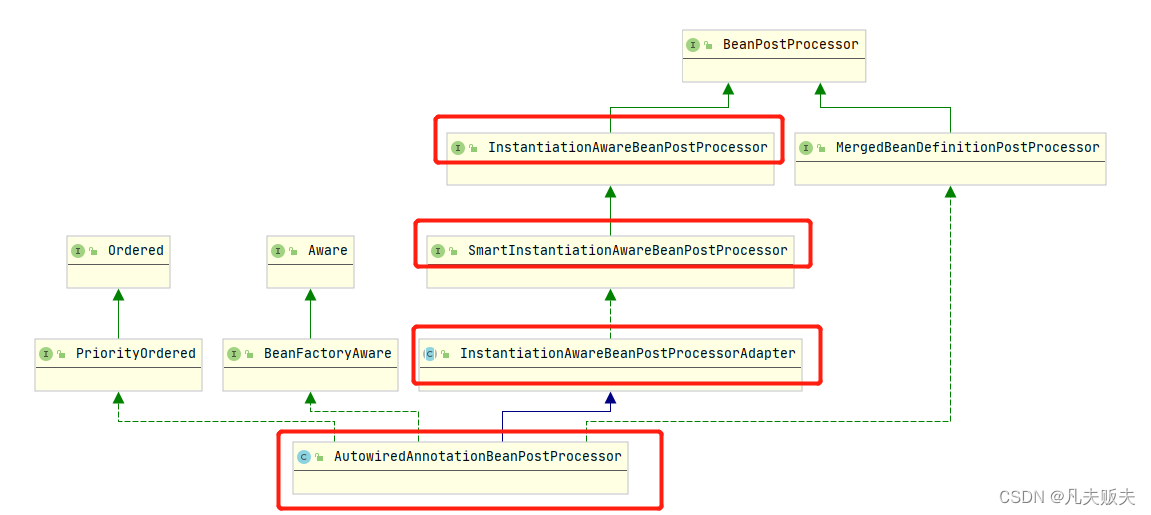
Springboot扩展点之InstantiationAwareBeanPostProcessor
Springboot扩展点系列实现方式、工作原理集合:Springboot扩展点之ApplicationContextInitializerSpringboot扩展点之BeanFactoryPostProcessorSpringboot扩展点之BeanDefinitionRegistryPostProcessorSpringboot扩展点之BeanPostProcessorSpringboot扩展点之Instant…...
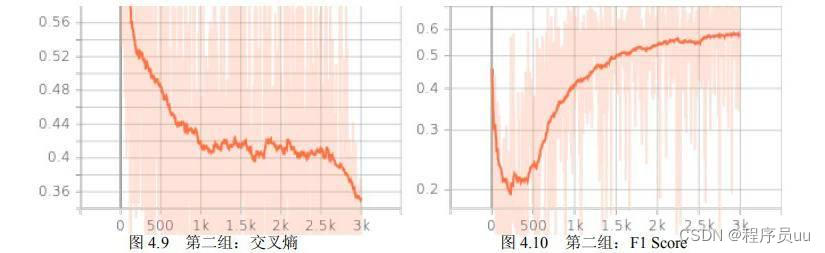
基于 U-Net 网络的遥感图像语义分割 完整代码+论文
一、研究目的U-Net 是一种由全卷积神经网络启发的对称结构网络,在医疗影像分割领域取得了很好的效果。 此次研究尝试使用 U-Net 网络在对多光谱遥感影像数据集上进行训练,尝试使用卷积神经网络自动分割出建筑,希望能够得到一种自动分割遥感影…...

Codeql 编译Shiro1.2.4爬坑
0x00 前言 这个Codeql一定要编译才能生成Database,是真的比较恼火,很多项目都不一定可以生成,环境就是一个非常大的坑,为了防止以后,所以将shiro1.2.4编译过程进行记录。 0x01 正文 首先是需要下载到shiro1.2.4的源…...

新C++(9):谈谈,翻转那些事儿
"相信羁绊,相信微光,相信一切无常。"一、AVL树翻转那些事儿(1)什么是AVL树?在计算机科学中,AVL树是最先发明的自平衡二叉查找树。在AVL树中任何节点的两个子树的高度最大差别为1,所以它也被称为高度平衡树。…...

Java深克隆的几种方式
目录 1、通过继承Cloneable接口,重写clone方法实现深克隆 2、通过序列化与反序列化的方式实现深克隆 3、第三方工具类实现深克隆,克隆对象需继承Serializable接口 3.1、Apache Commons Lang的SerializationUtils.clone方法 3.2、Gson工具类 3.3、F…...
PointNet++的源码运行
首先,从github上下载源码https://github.com/yanx27/Pointnet_Pointnet2_pytorch也可以从百度网盘下载链接:https://pan.baidu.com/s/1sgTYuqnBVC9p3bib450SOQ 提取码:gujd再下载对应的测试数据分类数据modelnet40_normal_resampled下载&…...
npm 上传自己的包
mkdir demo 创建一个新的文件夹 npm init 初始化项目 生成一个package.json文件 name version description等等touch index.js 创建一个node 可执行脚本新的js 文件 #!/usr/bin/env node // 必须在文件头加如上内容指定运行环境为node console.log(hello cli)在package.json 中…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

Blender渲染通道完全指南:如何像电影后期一样,分离出深度、阴影与反射图
Blender渲染通道完全指南:影视级后期制作的深度解析在数字内容创作领域,Blender已经从一个简单的3D建模工具成长为能够处理复杂视觉特效的全流程解决方案。对于追求影视级质量的中高级用户而言,掌握渲染通道技术是提升作品专业度的关键一步。…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

sngan_projection论文解读:ICLR2018两大GAN技术的完美结合
sngan_projection论文解读:ICLR2018两大GAN技术的完美结合 【免费下载链接】sngan_projection GANs with spectral normalization and projection discriminator 项目地址: https://gitcode.com/gh_mirrors/sn/sngan_projection sngan_projection是一个实现了…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为统一AI网关整合进企业现有微服务架构的实践思路 在构建以AI能力驱动的现代应用时,中型及以上的企业常面…...

UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用
UE4SS实战指南:虚幻引擎游戏脚本系统的深度解析与应用 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS …...

初创团队如何借助Taotoken以低成本快速验证AI产品创意
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何借助Taotoken以低成本快速验证AI产品创意 对于资源有限的初创团队而言,验证一个AI产品创意的核心挑战往往…...