MLC-LLM 部署RWKV World系列模型实战(3B模型Mac M2解码可达26tokens/s)
0x0. 前言
我的 ChatRWKV 学习笔记和使用指南 这篇文章是学习RWKV的第一步,然后学习了一下之后决定自己应该做一些什么。所以就在RWKV社区看到了这个将RWKV World系列模型通过MLC-LLM部署在各种硬件平台的需求,然后我就开始了解MLC-LLM的编译部署流程和RWKV World模型相比于MLC-LLM已经支持的Raven系列模型的特殊之处。
MLC-LLM的编译部署流程在MLC-LLM的官方文档已经比较详细了,但这部分有一些隐藏的坑点需要你去发现,比如现在要支持的RWKV-World模型它的Tokenizer是自定义的,并不是Huggingface的格式,这就导致我们不能使用MLC-LLM去直接编译这个模型,也不能使用预编译好的MLC-LLM二进制库去运行这个模型了。另外,在编译MLC-LLM仓库之前我们需要先编译Relax仓库而不是原始的TVM仓库,Relax可以认为是TVM的一个fork,在此基础上支持了Relax这个新一代的IR,这部分背景建议读者看一下我这个仓库的相关链接:
https://github.com/BBuf/tvm_mlir_learn
这个仓库已经揽下1.4k star,谢谢读者们支持。
从RWKV社区了解到,RWKV-World系列模型相比于Raven系列,推理代码和模型都是完全一样,不一样的地方主要是tokenizer是自定义的,并且system prompt不同。
在编译Relax的时候需要按需选择自己的编译平台进行编译,编译完之后 MLC-LLM 会通过 TVM_HOME 这个环境变量来感知 Relax 的位置,并且Relax编译时开启的选项要和MLC-LLM编译的选项匹配上,这样才可以在指定平台上进行正确的编译和推理。
在适配 RWKV-World 1.5B时,由于模型比较小对逗号比较敏感,导致第一层就炸了精度,最终挂在sampler里面,这个地方我定位2个晚上,后来mlc-ai官方的冯思远告诉我在 MLC-LLM 里如何逐层打印精度之后,我最终定位到了问题。并且在 RWKV 社区里面了解到了这个现象之前就出现过,那就是1.5B的模型第一层需要用FP32来计算,不然会炸精度,我后续实验了RWKV-4-World 3B/7B,这个现象就没有了。
另外,模型的组织格式也是值得注意的一点,并不是在任意位置编译好模型都可以在运行时被 MLC-LLM 正确发现。我大概花了快一周工作外时间在 MLC-LLM 上来支持 RWKV-World 系列模型,工作内容主要为:
- 将大缺弦的 https://github.com/daquexian/faster-rwkv 仓库中的 RWKV World模型tokenizer实现挂到 mlc-ai 的 tokenizers.cpp 中,作为一个 3rd 库提供给MLC-LLM。合并的PR为:https://github.com/mlc-ai/tokenizers-cpp/pull/14。
- 在上面的基础上,在MLC-LLM中支持 RWKV World系列模型的部署,对齐 World 系列模型的 Prompt ,获得良好的对话效果。分别在 Apple M2和A800显卡上进行了部署和测试。PR为:https://github.com/mlc-ai/mlc-llm/pull/848 ,这个pr还wip,如果你现在要使用的话可以直接切到这个pr对应的分支就可以了。
- debug到1.5B RWKV World小模型会炸精度的bug,相当于踩了个大坑。
我要特别感谢 mlc-ai 官方的冯思远在我部署过程中提供的支持以及帮我Review让代码合并到 mlc-ai 社区,以及感谢大缺弦的 RWKV World Tokenizer c++实现以及在编译第三方库时帮我解决的一个bug。
以下是MLC-LLM 部署RWKV World系列模型教程,尽量提供大家部署最不踩坑的实践。
效果:

0x1. 将RWKV-4-World-7B部署在A800上
准备工作
- RWKV-4-World模型地址:https://huggingface.co/StarRing2022/RWKV-4-World-7B
- 下载这里:https://github.com/BBuf/rwkv-world-tokenizer/releases/tag/v1.0.0 的 tokenizer_model.zip并解压为tokenizer_model文件,这是RWKV World系列模型的Tokenizer文件。
- 克隆好 https://github.com/mlc-ai/mlc-llm 和 https://github.com/mlc-ai/relax ,注意克隆的时候一定要加上 –recursive 参数,这样才会把它们依赖的第三方库也添加上。
编译Relax
git clone --recursive git@github.com:mlc-ai/relax.git
cd relax
mkdir build
cd build
cp ../cmake/config.cmake ./
然后修改build目录下的config.cmake文件,由于我这里是在A800上面编译,我改了以下设置:
set(USE_CUDA ON)
set(USE_CUTLASS ON)
set(USE_CUBLAS ON)
即启用了CUDA,并开启了2个加速库CUTLASS和CUBLAS。然后在build目录下执行cmake .. && make -j32 即可。
最后可以考虑把Relax添加到PYTHONPATH环境变量里面使得全局可见,在~/.bashrc上输入以下内容:
export TVM_HOME=/bbuf/relax
export PYTHONPATH=$TVM_HOME/python:${PYTHONPATH}
然后source ~/.bashrc即可。
编译和安装MLC-LLM
git clone --recursive git@github.com:mlc-ai/mlc-llm.git
cd mlc-llm/cmake
python3 gen_cmake_config.py
执行python3 gen_cmake_config.py 可以按需选择需要打开的编译选项,比如我这里就选择打开CUDA,CUBLAS,CUTLASS,另外需要注意的是这里的 TVM_HOME 路径需要设置为上面编译的Relax路径。
然后执行下面的操作编译:
cd ..
mkdir build
cp cmake/config.cmake build
cd build
cmake ..
make -j32
这里编译时还需要安装一下rust,按照建议的命令安装即可,编译完成之后即安装上了mlc-llm提供的聊天程序mlc_chat_cli。然后为了做模型转换和量化,我们还需要在mlc-llm目录下执行一下pip install .安装mlc_llm包。
模型转换
模型转换这里基本就是参考这个教程了:https://mlc.ai/mlc-llm/docs/compilation/compile_models.html 。
例如我们执行python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-7B --target cuda --quantization q4f16_1 就可以将RWKV-4-World-7B模型权重量化为4个bit,然后activation还是以FP16的方式存储。

target 则指定我们要在什么平台上去运行,这里会将整个模型构成的图编译成一个动态链接库(也就是TVM的IRModule)供后续的mlc_chat_cli程序(这个是在编译mlc-llm时产生的)调用。
这里默认会在当前目录下新建一个dist/models文件夹来存量化后模型和配置文件以及链接库,转换和量化好之后的模型会存储在当前命令所在目录的dist子目录下(会自动创建),你也可以手动克隆huggingface模型到dist/models文件夹下。量化完之后的模型结构如下:

这里的mlc-chat-config.json指定来模型生成的一些超参数比如top_p,temperature等。
最后在推理之前,我们还需要把最开始准备的tokenizer_model文件拷贝到这个params文件夹中。
执行推理
我们在mlc-llm的上一层文件夹执行下面的命令:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-7B-q0f16
RWKV-4-World-7B-q0f16可以换成你量化模型时的名字,加载完并运行system prompt之后你就可以愉快的和RWKV-4-World模型聊天了。

程序有一些特殊的指令来退出,查看速度等等:
性能测试
| 硬件 | 量化方法 | 速度 |
|---|---|---|
| A800 | q0f16 | prefill: 362.7 tok/s, decode: 72.4 tok/s |
| A800 | q4f16_1 | prefill: 1104.7 tok/s, decode: 122.6 tok/s |
这里给2组性能数据,大家感兴趣的话可以测测其它配置。
逐层debug方法
在适配1.5B模型时出现了推理结果nan的现象,可以用mlc-llm/tests/debug/dump_intermediate.py这个文件来对齐输入和tokenizer的结果之后进行debug,可以精准模拟模型推理并打印每一层的中间值,这样我们就可以方便的看到模型是在哪一层出现了nan。
0x2. 将RWKV-4-World-3B部署在Apple M2上
在mac上部署和cuda上部署并没有太大区别,主要是编译relax和mlc-llm的时候编译选项现在要选Metal而不是cuda了。我建议最好是在一个anconda环境里面处理编译的问题,不要用系统自带的python环境。
在编译relax的时候需要同时打开使用Metal和LLVM选项,如果系统没有LLVM可以先用Homebrew装一下。
在mlc-llm中生成config.cmake时使用下面的选项:
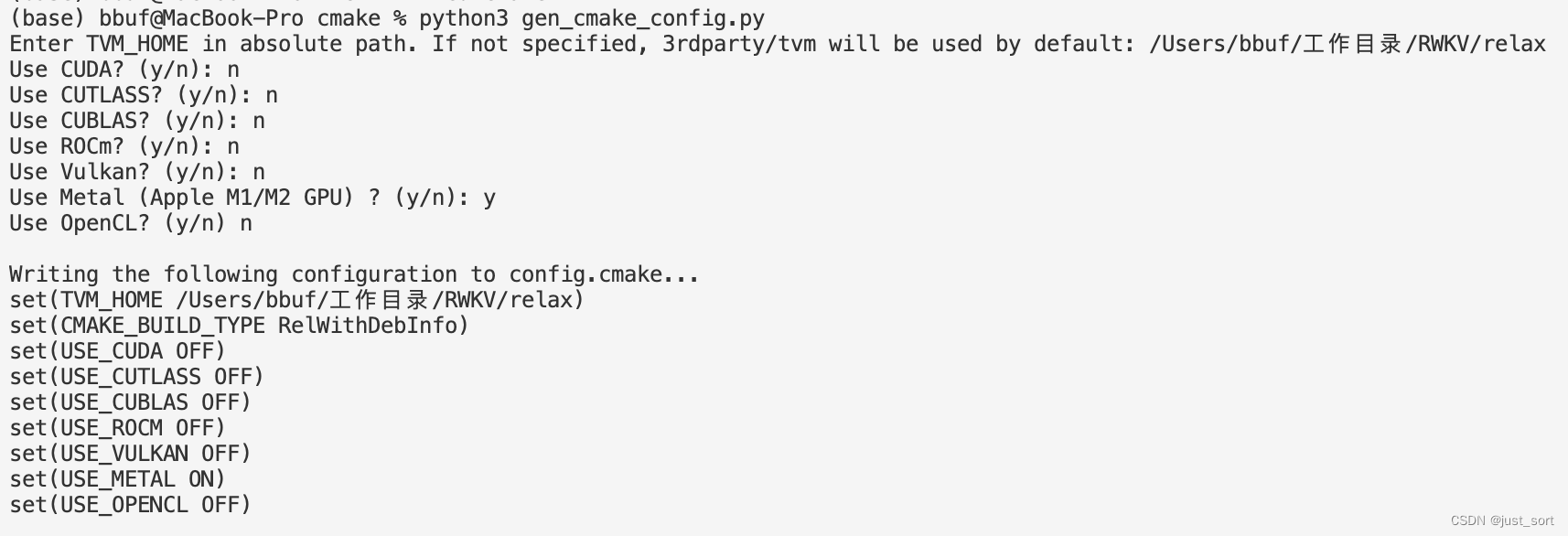 编译完并
编译完并pip install .之后使用下面的命令量化模型:
python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
量化过程中日志如下:
(base) bbuf@MacBook-Pro RWKV % python3 -m mlc_llm.build --hf-path StarRing2022/RWKV-4-World-3B --target metal --quantization q4f16_1
Weights exist at dist/models/RWKV-4-World-3B, skipping download.
Using path "dist/models/RWKV-4-World-3B" for model "RWKV-4-World-3B"
[09:53:08] /Users/bbuf/工作目录/RWKV/relax/src/runtime/metal/metal_device_api.mm:167: Intializing Metal device 0, name=Apple M2
Host CPU dection:Target triple: arm64-apple-darwin22.3.0Process triple: arm64-apple-darwin22.3.0Host CPU: apple-m1
Target configured: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Host CPU dection:Target triple: arm64-apple-darwin22.3.0Process triple: arm64-apple-darwin22.3.0Host CPU: apple-m1
Automatically using target for weight quantization: metal -keys=metal,gpu -max_function_args=31 -max_num_threads=256 -max_shared_memory_per_block=32768 -max_threads_per_block=1024 -thread_warp_size=32
Start computing and quantizing weights... This may take a while.
Finish computing and quantizing weights.
Total param size: 1.6060066223144531 GB
Start storing to cache dist/RWKV-4-World-3B-q4f16_1/params
[0808/0808] saving param_807
All finished, 51 total shards committed, record saved to dist/RWKV-4-World-3B-q4f16_1/params/ndarray-cache.json
Finish exporting chat config to dist/RWKV-4-World-3B-q4f16_1/params/mlc-chat-config.json
[09:53:40] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
[09:53:41] /Users/bbuf/工作目录/RWKV/relax/include/tvm/topi/transform.h:1076: Warning: Fast mode segfaults when there are out-of-bounds indices. Make sure input indices are in bound
Save a cached module to dist/RWKV-4-World-3B-q4f16_1/mod_cache_before_build.pkl.
Finish exporting to dist/RWKV-4-World-3B-q4f16_1/RWKV-4-World-3B-q4f16_1-metal.so
同样也需要把tokenizer_model文件拷贝到量化后模型文件夹的params目录下,然后执行下面的命令启动聊天程序:
./mlc-llm/build/mlc_chat_cli --model RWKV-4-World-3B-q0f16
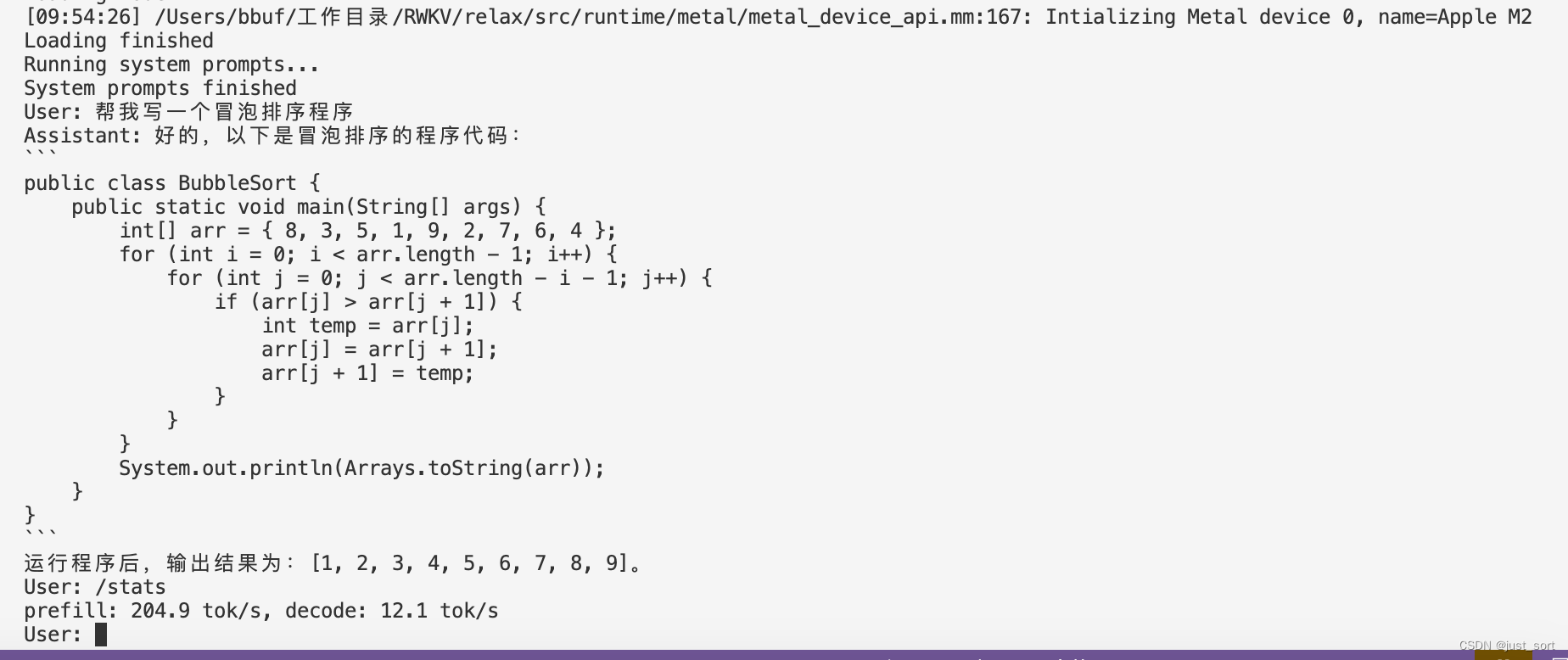
最后也来一个Mac M2的速度测试:
| 硬件 | 量化方法 | 速度 |
|---|---|---|
| Apple M2 | q0f16 | 204.9 tok/s, decode: 12.1 tok/s |
| Apple M2 | q4f16_1 | prefill: 201.6 tok/s, decode: 26.3 tok/s |
建议使用q4f16的配置,这样回复会快一些。
0x3. 总结
这篇文章介绍了一下笔者最近给mlc-llm做适配的工作,欢迎大家体验MLC-LLM和RWKV-World模型。
相关文章:
MLC-LLM 部署RWKV World系列模型实战(3B模型Mac M2解码可达26tokens/s)
0x0. 前言 我的 ChatRWKV 学习笔记和使用指南 这篇文章是学习RWKV的第一步,然后学习了一下之后决定自己应该做一些什么。所以就在RWKV社区看到了这个将RWKV World系列模型通过MLC-LLM部署在各种硬件平台的需求,然后我就开始了解MLC-LLM的编译部署流程和…...

Unity 之 参数类型之值类型参数的用法
文章目录 基本数据类型结构体结构体的进一步补充 总结: 当谈论值类型参数时,我们可以从基本数据类型和结构体两个方面详细解释。值类型参数指的是以值的形式传递给函数或方法的数据,而不是引用。 基本数据类型 基本数据类型的值类型参数&…...
VScode远程连接主机
一、前期准备 1、Windows安装VSCode; 2、在VSCode中安装PHP Debug插件; 3、安装好Docker 4、在容器中安装Xdebug ①写一个展现phpinfo的php文件 <?php phpinfo(); ?>②在浏览器上打开该文件 ③复制所有信息丢到Xdebug: Installation instr…...

【iOS】属性关键字
文章目录 前言一、深拷贝与浅拷贝1、OC的拷贝方式有哪些2. OC对象实现的copy和mutableCopy分别为浅拷贝还是深拷贝?3. 自定义对象实现的copy和mutableCopy分别为浅拷贝还是深拷贝?4. 判断当前的深拷贝的类型?(区别是单层深拷贝还是完全深拷贝…...
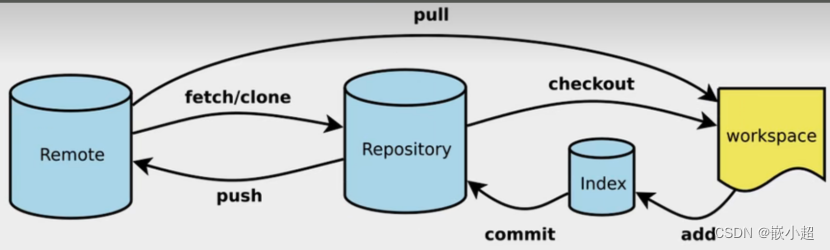
【计算机基础】Git从安装到使用,详细每一步!扩展Github\Gitlab
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
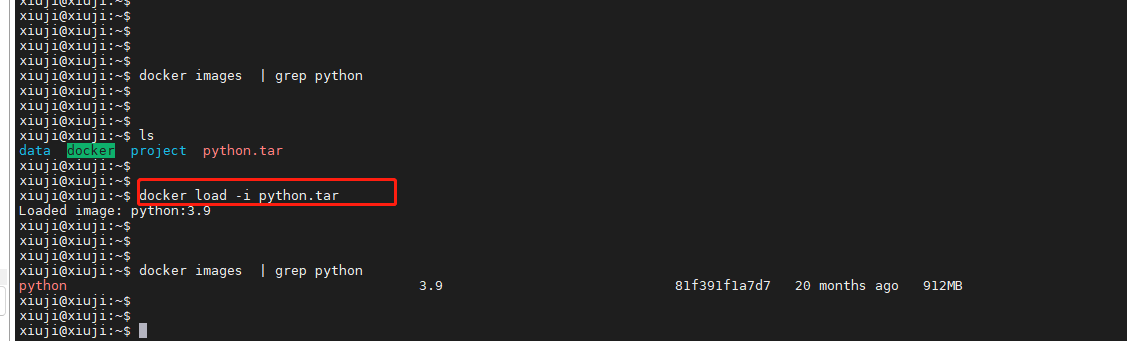
深入了解Docker镜像操作
Docker是一种流行的容器化平台,它允许开发者将应用程序及其依赖项打包成容器,以便在不同环境中轻松部署和运行。在Docker中,镜像是构建容器的基础,有些家人们可能在服务器上对docker镜像的操作命令不是很熟悉,本文将深…...

嵌入式开发-单片机学习介绍
一、单片机入门篇 单片机的定义和历史 单片机是一种集成了微处理器、存储器、输入输出接口和其他功能于一体的微型计算机,具有高度的集成性和便携性。单片机的历史可以追溯到20世纪70年代,随着微电子技术的不断发展,单片机逐渐成为了工业控…...
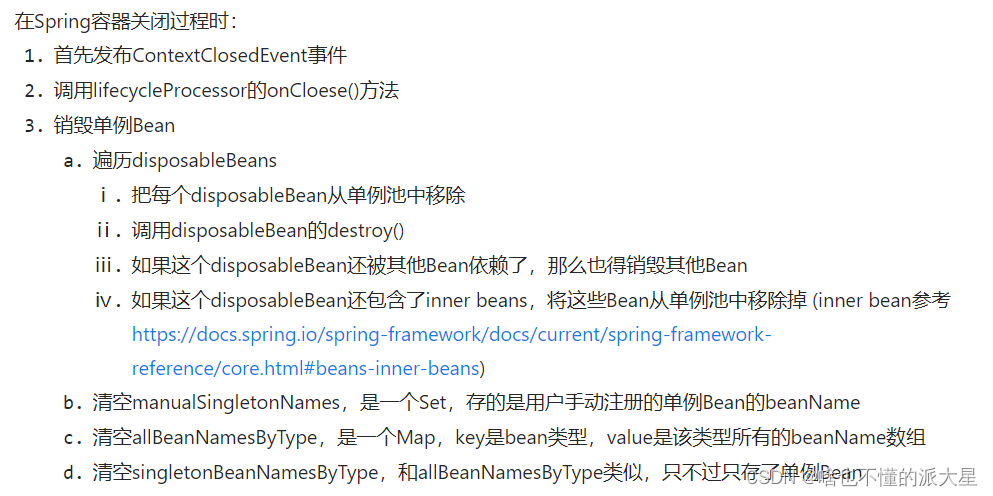
5、Spring之Bean生命周期源码解析(销毁)
Bean的销毁过程 Bean销毁是发送在Spring容器关闭过程中的。 在Spring容器关闭时,比如: AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class); UserService userService = (UserService) context.getBean("userSe…...

开发多点触控MFC应用程序
当下计算机变得越来越智能化,越来越无所不能,触摸屏的普及只是时间问题了。 虽然鼠标和键盘不会很快就离开人们的视野,毕竟人们使用鼠标跟键盘已经成为一种习惯,但是处理信息或者说操作计算机的其他方法也层出不穷——比如触控技术…...

使用nlohmann json库进行序列化与反序列化
nlohmann源码仓库:https://github.com/nlohmann/json使用方式:将其nlohmann文件夹加入,包含其头文件json.hpp即可demo #include <iostream> #include "nlohmann/json.hpp" #include <vector>using json nlohmann::js…...
)
高教社杯数模竞赛特辑论文篇-2012年A题:葡萄酒的评价(附获奖论文)
目录 摘 要 一、问题重述 二、问题分析 2.1 问题一的分析 2.2 问题二的分析...

手写RPC——数据序列化工具protobuf
手写RPC——数据序列化工具protobuf Protocol Buffers(protobuf)是一种用于结构化数据序列化的开源库和协议。下面是 protobuf 的一些优点和缺点: 优点: 高效的序列化和反序列化:protobuf 使用二进制编码,…...
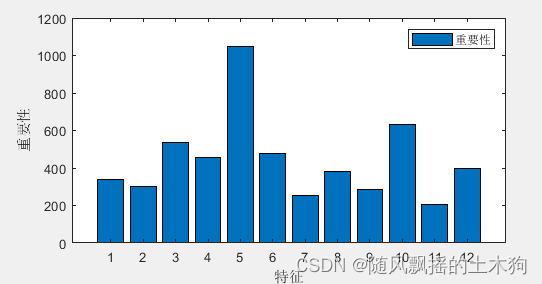
【MATLAB第70期】基于MATLAB的LightGbm(LGBM)梯度增强决策树多输入单输出回归预测及多分类预测模型(全网首发)
【MATLAB第70期】基于MATLAB的LightGbm(LGBM)梯度增强决策树多输入单输出回归预测及多分类预测模型(全网首发) 一、学习资料 (LGBM)是一种基于梯度增强决策树(GBDT)算法。 本次研究三个内容,分别是回归预测,二分类预测和多分类预…...

Linux进程间通信的几种方式
分析&回答 管道(pipe)以及有名管道:管道可用于有亲缘关系进程间通信,有名管道克服了管道没有名字的限制,因此具有管道的所有功能之外,它还允许无亲缘关系进程间通信。信号(Signalÿ…...
)
Android 13.0 Launcher3定制之双层改单层(去掉抽屉式一)
1.概述 在13.0的系统产品开发中,对于在Launcher3中的抽屉模式也就是双层模式,在系统原生的Launcher3中就是双层抽屉模式的, 但是在通过抽屉上滑的模式拉出app列表页,但是在一些产品开发中,对于单层模式的Launcher3的产品模式也是常用的功能, 所以需要了解抽屉模式,然后修…...
【uniapp 配置启动页面隐私弹窗】
为什么需要配置 原因 根据工业和信息化部关于开展APP侵害用户权益专项整治要求,App提交到应用市场必须满足以下条件: 1.应用启动运行时需弹出隐私政策协议,说明应用采集用户数据 2.应用不能强制要求用户授予权限,即不能“不给权…...

2分钟讲清楚C#的委托, C语言的函数指针,Java的函数式接口
很多小伙伴学习C# 的委托时往往一头雾水, 不明白委托是什么, 有什么作用, 今天我就用2分钟讲清楚 这是一个C# 的控制台程序 定义一个最简单的委托 delegate int Calculate(int a, int b); 这相当于定义了一个Calculate类型, 只不过这个类型需要传入2个int类型的参数 返回值也…...
华为云物联网平台微信小程序开发教程2.0【完整详细教程】
一、简介 在之前曾发布过一篇文章“华为云物联网平台的微信小程序开发”,在最近接到部分用户私信在使用开发过程中出现的问题,例如API访问的"401"现象等问题,在重新查看上面的文章教程时发现教程内容的步骤不详细,现对教…...

Laravel 模型1对1关联 1对多关联 多对多关联 ⑩①
作者 : SYFStrive 博客首页 : HomePage 📜: THINK PHP 📌:个人社区(欢迎大佬们加入) 👉:社区链接🔗 📌:觉得文章不错可以点点关注 ὄ…...
【分类】分类性能评价
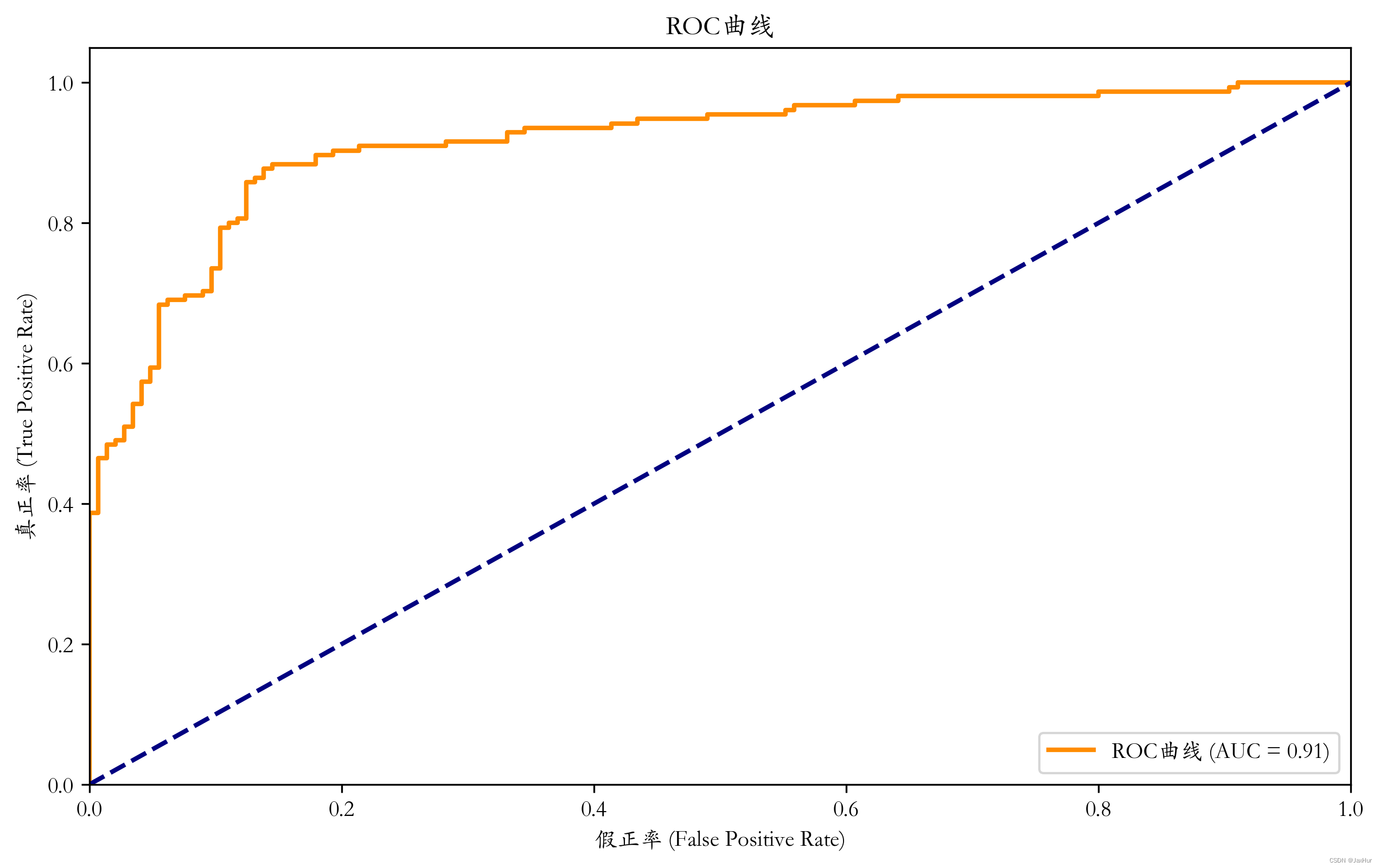
评价指标 1、准确率、召回率、精确率、F-度量、ROC 属于各类的样本的并不是均一分布,甚至其出现概率相差很多个数量级,这种分类问题称为不平衡类问题。在不平衡类问题中,准确率并没有多大意义,我们需要一些别的指标。 通…...

正交试验结果怎么看?一张图教你读懂SPSSAU的极差分析表和均值图
正交试验结果解读指南:从极差分析到最优组合决策 正交试验作为多因素优化研究的利器,其价值往往在数据解读阶段才能真正释放。当SPSSAU输出的极差分析表和均值图呈现在眼前时,许多研究者会陷入"数字迷宫"——那些K1/K2/K3值究竟在诉…...

Auto-Lianliankan:基于Python图像识别的连连看自动化终极方案
Auto-Lianliankan:基于Python图像识别的连连看自动化终极方案 【免费下载链接】Auto-Lianliankan 基于python图像识别实现的连连看外挂,可实现QQ连连看秒破 项目地址: https://gitcode.com/gh_mirrors/au/Auto-Lianliankan 你是否曾经在玩连连看游…...

Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用
Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用 【免费下载链接】flet Build realtime web, mobile and desktop apps in Python only. No frontend experience required. 项目地址: https://gitcode.com/gh_mirrors/fl/flet 你是否曾…...

洞悉.NET 11:Blazor 与 Microsoft.Extensions.AI 的融合创新实践
洞悉.NET 11:Blazor 与 Microsoft.Extensions.AI 的融合创新实践 前言 在现代 Web 应用开发领域,提升用户体验和智能化交互至关重要。Blazor 凭借其在构建交互式 Web 界面的优势,与专注于 AI 集成的 Microsoft.Extensions.AI 相结合ÿ…...

Notepad--:跨平台文本编辑器的国产解决方案与深度应用指南
Notepad--:跨平台文本编辑器的国产解决方案与深度应用指南 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

如何5分钟部署AI斗地主助手:从零开始打造你的智能游戏伙伴
如何5分钟部署AI斗地主助手:从零开始打造你的智能游戏伙伴 【免费下载链接】DouZero_For_HappyDouDiZhu 基于DouZero定制AI实战欢乐斗地主 项目地址: https://gitcode.com/gh_mirrors/do/DouZero_For_HappyDouDiZhu 还在为斗地主游戏中的决策烦恼吗ÿ…...

Photoshop图层批量导出终极指南:5分钟掌握高效工作流
Photoshop图层批量导出终极指南:5分钟掌握高效工作流 【免费下载链接】Photoshop-Export-Layers-to-Files-Fast This script allows you to export your layers as individual files at a speed much faster than the built-in script from Adobe. 项目地址: http…...

Prompt核心原则与技巧
1. Prompt的本质Prompt是用户和模型之间的"接口"。设计好的Prompt就像把话说清楚——越清楚,模型越能给你想要的答案。类比:就像你请人帮忙做事:说"帮我处理一下" → 对方可能做错说"帮我把这封信装进信封ÿ…...
的具体使用和介绍)
前端正则表达式(?:pattern)的具体使用和介绍
文章目录一、官方解释二、js代码例子解释参考文档一、官方解释 (?:pattern) 是正则表达式中的一种结构,称为“非捕获组”(Non-Capturing Group)。它允许您将多个字符或子表达式组合在一起,作为一个整体对待,而不捕获…...

3分钟上手Windhawk:像安装App一样轻松定制Windows系统
3分钟上手Windhawk:像安装App一样轻松定制Windows系统 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 你是否厌倦了Windows系统一成不变的界…...