得物一面,场景题问得有点多!
题目来源:https://www.nowcoder.com/discuss/525371909735792640
前文
本期是【捞捞面经】系列文章的第 1 期,持续更新中…。
《捞捞面经》系列正式开始连载啦,据说看了这个系列的朋友都拿到了大厂offer~
- 欢迎星标+订阅,持续更新中。。。致力打造校招核心面试攻略~
- 原创面试网站:https://www.java2top.cn/

捞捞面经
生产场景下什么时候用 ArrayList ,什么时候用 LinkedList
ArrayList 和 LinkedList 都是 Java 中常用的 List 实现,但是由于它们内部数据结构的不同,所以在不同的场景下,我们会选择使用不同的List。
- ArrayList:ArrayList 内部是使用动态数组来存储数据的,所以它在随机访问(get和set操作)时有很好的性能,时间复杂度为O(1)。但是在列表中间插入和删除元素时的性能较差,因为需要移动元素,时间复杂度为O(n)。所以,如果你的需求是大量的随机访问操作,少量的插入和删除操作,那么 ArrayList 是一个好的选择。
- LinkedList:LinkedList 内部是使用双向链表来存储数据的,所以它在列表中间插入和删除元素时有很好的性能,时间复杂度为 O(1)(需要提前获取到节点的引用,否则查找节点的时间复杂度为 O(n))。但是在随机访问时的性能较差,因为需要从头部或者尾部开始遍历,时间复杂度为 O(n)。所以,如果你的需求是大量的插入和删除操作,少量的随机访问操作,那么 LinkedList 是一个好的选择。
总的来说,我们需要根据实际的需求和使用场景来选择合适的 List 实现。
创建线程的方式
-
继承Thread类:这是创建线程的最基本方法。我们可以创建一个新的类,继承自 Thread 类,然后重写其 run() 方法,将我们的任务代码写在 run() 方法中。然后创建该类的对象并调用其 start() 方法来启动线程。
-
实现Runnable接口:我们也可以创建一个新的类,实现 Runnable 接口,然后将我们的任务代码写在 run() 方法中。然后创建该类的对象,将其作为参数传递给 Thread 类的构造器,创建 Thread 类的对象并调用其 start() 方法来启动线程。
-
实现Callable接口和FutureTask类:Callable 接口与 Runnable 接口类似,但是它可以返回一个结果,或者抛出一个异常。我们可以创建一个新的类,实现 Callable 接口,然后将我们的任务代码写在 call() 方法中。
然后创建该类的对象,将其作为参数传递给FutureTask 类的构造器,创建 FutureTask 类的对象。最后,将FutureTask类的对象作为参数传递给 Thread 类的构造器,创建Thread 类的对象并调用其 start() 方法来启动线程。
-
使用线程池:Java 提供了线程池 API(Executor框架),我们可以通过
Executors类的一些静态工厂方法来创建线程池,然后调用其 execute() 或 submit() 方法来启动线程。线程池可以有效地管理和控制线程,避免大量线程的创建和销毁带来的性能开销。
以上四种方式,前两种是最基本的创建线程的方式,但是在实际开发中,我们通常会选择使用线程池,因为它可以提供更好的性能和更易于管理的线程生命周期。
在并发量特别高的情况下是使用 synchronized 还是 ReentrantLock
在并发量特别高的情况下,一般推荐使用 ReentrantLock,原因如下:
- 更高的性能:在Java 1.6之前,synchronized 的性能一般比 ReentrantLock 差一些。虽然在 Java 1.6 及之后的版本中,synchronized进行了一些优化,如偏向锁、轻量级锁等,但在高并发情况下,ReentrantLock 的性能通常会优于 synchronized。
- 更大的灵活性:
ReentrantLock比synchronized有更多的功能。例如,ReentrantLock 可以实现公平锁和非公平锁(synchronized只能实现非公平锁);ReentrantLock 提供了一个 Condition 类,可以分组唤醒需要唤醒的线程(synchronized 要么随机唤醒一个线程,要么唤醒所有线程);ReentrantLock 提供了tryLock方法,可以尝试获取锁,如果获取不到立即返回,不会像synchronized 那样阻塞。 - 更好的可控制性:ReentrantLock可以中断等待锁的线程(synchronized无法响应中断),也可以获取等待锁的线程列表,这在调试并发问题时非常有用。
但是,虽然 ReentrantLock 在功能上比 synchronized 更强大,但也更复杂,使用不当容易造成死锁。而 synchronized 由 JVM 直接支持,使用更简单,不容易出错。所以,在并发量不高,对性能要求不高的情况下,也可以考虑使用 synchronized。
说一下 ConcurrentHashMap 中并发安全的实现
ConcurrentHashMap 在 Java 1.7 和 Java 1.8 中的实现方式有所不同,但它们的共同目标都是提供高效的并发更新操作。下面我将分别介绍这两个版本的实现方式。
-
Java 1.7:在Java 1.7中,
ConcurrentHashMap内部使用一个 Segment 数组来存储数据。每个Segment对象包含一个 HashEntry 数组,每个 HashEntry 对象就是一个键值对。Segment 对象是可锁定的,每个Segment对象都可以看作是一个独立的 HashMap。在更新数据时,只需要锁定相关 Segment 对象,而不需要锁定整个HashMap,这样就可以实现真正的并发更新。Segment 的数量默认为 16,这意味着 ConcurrentHashMap 最多支持 16 个线程的并发更新。
-
Java 1.8:在 Java 1.8 中,ConcurrentHashMap 的实现方式进行了改进。它取消了 Segment 数组,直接使用 Node 数组来存储数据。每个Node对象就是一个键值对。在更新数据时,使用 CAS 操作和 synchronized 来保证并发安全。
具体来说,如果更新操作发生在链表的头节点,那么使用 CAS 操作;如果发生在链表的其他位置,或者发生在红黑树节点,那么使用synchronized。这样,ConcurrentHashMap可以支持更多线程的并发更新。
总的来说,ConcurrentHashMap 通过分段锁(Java 1.7)或 CAS+synchronized(Java 1.8)的方式,实现了高效的并发更新操作,从而保证了并发安全
你说高并发下 ReentrantLock 性能比 synchronized 高,那为什么 ConcurrentHashMap 在 JDK 1.7 中要用 ReentrantLock,而 ConcurrentHashMap 在 JDK 1.8 要用 Synchronized
这是一个很好的问题。首先,我们需要明确一点,虽然 ReentrantLock 在某些情况下的性能优于synchronized,但这并不意味着在所有情况下都是这样。
实际上,synchronized 在JDK 1.6 及以后的版本中已经进行了大量的优化,例如偏向锁、轻量级锁等,使得在竞争不激烈的情况下,synchronized 的性能已经非常接近甚至超过 ReentrantLock。
在 JDK 1.7的 ConcurrentHashMap中,使用 ReentrantLock(Segment)是为了实现分段锁的概念,即将数据分成多个段,每个段独立加锁,从而实现真正的并发更新。这种设计在当时是非常先进和高效的。
然而,在 JDK 1.8 的 ConcurrentHashMap 中,为了进一步提高并发性能,引入了更复杂的数据结构(如红黑树)和更高效的并发控制机制(如CAS操作)。在这种情况下,使用 synchronized 比 ReentrantLock 更加简单和高效。首先,synchronized 可以直接与JVM进行交互,无需用户手动释放锁,减少了出错的可能性。
其次,synchronized 在 JDK 1.6及以后的版本中已经进行了大量的优化,性能已经非常接近 ReentrantLock。最后,synchronized 可以与其他 JVM 特性(如偏向锁、轻量级锁、锁消除、锁粗化等)更好地配合,进一步提高性能。
总的来说,选择使用 ReentrantLock 还是 synchronized,需要根据具体的需求和使用场景来决定。在 JDK 1.8 的 ConcurrentHashMap中,使用 synchronized 是一种更加合理和高效的选择。
有哪些并发安全的实现方式
- synchronized关键字:这是最基本的并发安全实现方式,它可以保证同一时刻最多只有一个线程执行该段代码,从而保证了类的实例状态的线程安全。
- volatile关键字:
volatile关键字可以保证变量的可见性和禁止指令重排序,但不能保证复合操作的原子性。它通常用于标记状态变量。 - Lock接口和其实现类:例如ReentrantLock、ReentrantReadWriteLock等。相比于synchronized,Lock接口提供了更强大的功能,例如尝试获取锁、可中断的获取锁以及获取公平锁等。
- 原子类:例如 AtomicInteger、AtomicLong、AtomicReference 等。这些类通过 CAS(Compare and Swap)操作实现了原子性更新。
- 并发集合:Java 提供了一些线程安全的集合类,例如 ConcurrentHashMap、CopyOnWriteArrayList等。
- ThreadLocal类:
ThreadLocal可以为每个线程创建一个单独的变量副本,每个线程都只能操作自己的副本,从而实现了线程隔离,保证了线程安全。 - Semaphore信号量:Semaphore 可以控制同时访问特定资源的线程数量,通过acquire()获取一个许可,如果没有就等待,通过release()释放一个许可。
- CountDownLatch:
CountDownLatch允许一个或多个线程等待其他线程完成操作。 - CyclicBarrier:CyclicBarrier 让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被阻塞的线程才会继续运行。
- Phaser:
Phaser是 JDK 1.7引入的一个用于解决控制多个线程分阶段共同完成任务的类。
以上就是 Java 中常见的一些并发安全的实现方式。
不用 ThreadLocal 你会想用什么方式存用户信息
如果不使用 ThreadLocal 来存储用户信息,我会考虑以下几种方式:
- 参数传递:这是最直接的方式,将用户信息作为方法的参数传递。这种方式的优点是简单直接,不依赖任何特定的技术。缺点是如果调用链很长,那么需要在很多方法之间传递用户信息,可能会使代码变得复杂。
- 全局变量:可以将用户信息存储在全局变量中。但是,这种方式需要注意并发控制和内存泄漏问题。如果是Web应用,可以考虑将用户信息存储在 Session 或 Cookie 中。
- 数据库或缓存:可以将用户信息存储在数据库或缓存中,如 Redis。这种方式的优点是可以持久化用户信息,适合存储大量的用户信息。缺点是访问数据库或缓存的速度比访问内存慢,可能会影响性能。
- 上下文对象:可以创建一个上下文对象,将用户信息存储在上下文对象中。然后将上下文对象传递给需要使用用户信息的方法。这种方式的优点是可以避免在方法之间传递大量的参数。缺点是需要手动管理上下文对象的生命周期。
以上就是我考虑的几种存储用户信息的方式,具体使用哪种方式,需要根据实际的需求和场景来决定。
有千万级数据,如何判断一个整数是否存在
对于千万级的数据,如果要判断一个整数是否存在,可以考虑以下几种方法:
- 哈希表:哈希表(如 Java 中的 HashSet 或 HashMap)可以在 O(1) 的时间复杂度内判断一个元素是否存在。但是,哈希表需要大量的内存空间来存储数据和哈希表本身。如果内存空间有限,那么这可能不是一个好的选择。
- 布隆过滤器:布隆过滤器是一种空间效率极高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是它存在一定的误识别率和删除困难。
- 位图:如果整数的范围不大,例如都是非负整数,那么可以使用位图(BitSet)来判断一个整数是否存在。位图的每一位代表一个整数,如果整数存在,那么对应的位就置为 1。位图需要的内存空间远小于哈希表,但是如果整数的范围非常大,那么位图可能就不适用了。
- 数据库:如果数据已经存储在数据库中,那么可以直接使用 SQL 查询来判断一个整数是否存在。这种方法的效率取决于数据库的性能和数据的索引情况。
- 二分查找:如果数据是有序的,那么可以使用二分查找来判断一个整数是否存在。二分查找的时间复杂度是
O(log n),但是它需要数据是有序的。
以上就是判断一个整数是否存在的几种方法,具体使用哪种方法,需要根据实际的需求和场景来决定。
如何理解:布隆过滤器说某个元素存在,则大概率在。布隆过滤器说某个元素不在,则一定不在
布隆过滤器是一种概率型的数据结构,它的主要特点是高效地判断一个元素是否在一个集合中。它的基本原理是通过多个哈希函数将元素映射到一个位数组中。当查询一个元素是否存在时,通过同样的哈希函数计算出位数组中的位置,如果所有的位置都是1,那么就认为元素可能存在;如果有任何一个位置是 0,那么就认为元素一定不存在。
这里的 "可能存在” 和 “一定不存在” 是因为布隆过滤器的特性决定的:
- 当布隆过滤器说某个元素存在时,实际上可能会出现误判的情况。因为不同的元素可能会被哈希到位数组的同一位置,这就可能出现一个元素实际上不存在,但是因为其哈希位置被其他元素占用,所以布隆过滤器判断它存在。这就是所谓的“假阳性”。
- 当布隆过滤器说某个元素不存在时,那么这个元素一定不存在。因为如果一个元素存在,那么它的哈希位置一定会被设置为1。如果布隆过滤器说某个元素不存在,那么说明至少有一个哈希位置是 0,那么这个元素一定不存在。这就是所谓的“真阴性”。
因此,布隆过滤器的一个重要特性就是,它可能会误判一个不存在的元素为存在(假阳性),但是绝不会误判一个存在的元素为不存在(真阴性)。这就是“布隆过滤器说某个元素存在,则大概率在。布隆过滤器说某个元素不在,则一定不在”的含义。
千万级数据用布隆过滤器初始化的时候 redis 太慢了,有没有什么好方法
对于千万级的数据,如果直接使用Redis来初始化布隆过滤器确实可能会比较慢。这是因为Redis的操作都是网络IO操作,相比于内存操作,网络IO的速度要慢很多。以下是一些可能的优化方法:
- 批量操作:Redis支持批量操作,可以一次性发送多个命令,然后一次性接收所有的结果。这样可以减少网络IO的次数,提高效率。
- 管道操作:Redis还支持管道操作,可以一次性发送多个命令,不需要等待上一个命令的结果就可以发送下一个命令。这样可以进一步减少网络IO的次数。
- 多线程或多进程:可以使用多线程或多进程来并行初始化布隆过滤器。每个线程或进程负责一部分数据,这样可以充分利用多核CPU,提高效率。
- 使用更快的存储:如果条件允许,可以考虑使用更快的存储,例如SSD硬盘,或者直接在内存中初始化布隆过滤器。
- 预热数据:如果数据不经常变动,可以考虑预先计算好布隆过滤器的状态,然后保存在文件或数据库中。需要使用时,直接加载预先计算好的状态,这样可以避免实时初始化布隆过滤器。
以上就是一些可能的优化方法,具体使用哪种方法,需要根据实际的需求和场景来决定。
多线程间如何传值
多线程间传递值主要有以下几种方式:
- 共享内存:多个线程可以共享同一个进程的内存空间,因此可以通过修改内存中的变量来传递值。但是,需要注意的是,多个线程同时修改同一个变量可能会导致数据不一致的问题,因此通常需要使用锁或其他同步机制来保证数据的一致性。
- 线程局部变量:例如 Java 中的 ThreadLocal,可以为每个线程创建一个独立的变量副本,每个线程只能访问和修改自己的副本,不会影响其他线程的副本。
- 通过队列传递:可以使用线程安全的队列(如 Java 中的 BlockingQueue )来传递值。一个线程将值放入队列,另一个线程从队列中取出值。
- 通过管道传递:某些编程语言(如 Python )支持使用管道(Pipe)来传递值。一个线程将值写入管道,另一个线程从管道中读取值。
- 通过Future和Callable:在 Java 中,可以使用 Future 和 Callable 来在多线程间传递值。Callable 是一个可以返回值的任务,Future 可以用来获取 Callable 任务的返回值。
以上就是多线程间传递值的几种方式,具体使用哪种方式,需要根据实际的需求和场景来决定。
如何设计登陆黑名单
设计登录黑名单的主要目的是防止恶意用户或者机器人进行暴力破解或者恶意登录。以下是一种可能的设计方案:
- 记录登录失败次数:对每个用户或者
IP地址,记录其登录失败的次数。如果在一定时间内登录失败次数超过某个阈值,那么就将该用户或者IP地址加入黑名单。 - 设置黑名单有效期:黑名单不应该永久有效,否则可能会误伤正常用户。可以设置一个有效期,例如 24 小时。超过有效期后,自动将用户或者 IP 地址从黑名单中移除。
- 使用布隆过滤器:为了高效地判断一个用户或者 IP 地址是否在黑名单中,可以使用布隆过滤器。布隆过滤器可以在近似 O(1) 的时间复杂度内判断一个元素是否存在。
- 黑名单同步:如果系统是分布式的,那么需要考虑黑名单的同步问题。可以使用消息队列或者Redis等工具来同步黑名单。
- 提供解封接口:对于误伤的正常用户,应该提供一个解封的接口或者方式。例如,可以通过验证邮箱或者手机短信来解封。
- 记录黑名单日志:对于被加入黑名单的用户或者 IP 地址,应该记录详细的日志,包括被加入黑名单的时间,原因,以及登录失败的详细信息。这对于后期的审计和分析都是非常有帮助的。
以上就是设计登录黑名单的一种可能的方案,具体的设计可能还需要根据实际的需求和场景来调整。
相关文章:
得物一面,场景题问得有点多!
题目来源:https://www.nowcoder.com/discuss/525371909735792640 前文 本期是【捞捞面经】系列文章的第 1 期,持续更新中…。 《捞捞面经》系列正式开始连载啦,据说看了这个系列的朋友都拿到了大厂offer~ 欢迎星标订阅,持续更新…...

Prompt Tuning 和instruct tuning
Prompt Tuning 是啥? prompt的思想是,把下游任务的输入转化为预训练模型的原始任务。 以bert作为举例,假设任务是文本分类。“今天天气很好。”我们想判断一下这句话的情感是正面还是负面 fine-tune的方法是在bert之后接一个head࿰…...

springboot 与异步任务,定时任务,邮件任务
异步任务 在Java应用中,绝大多数情况下都是通过同步的方式来实现交互处理的;但是在处理与第三方系统交互的时候,容易造成响应迟缓的情况,之前大部分都是使用多线程来完成此类任务,其实,在Spring 3.x之后&a…...

2022年06月 C/C++(六级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:小白鼠再排队2 N只小白鼠(1 < N < 100),每只鼠头上戴着一顶有颜色的帽子。现在称出每只白鼠的重量,要求按照白鼠重量从小到大的顺序输出它们头上帽子的颜色。帽子的颜色用 “red”,“blue”等字符串来表示。不同的小白鼠可…...

【C++】C++11新特性(下)
上篇文章(C11的新特性(上))我们讲述了C11中的部分重要特性。本篇接着上篇文章进行讲解。本篇文章主要进行讲解:完美转发、新类的功能、可变参数模板、lambda 表达式、包装器。希望本篇文章会对你有所帮助。 文章目录 一…...

python内网环境安装第三方包
文章目录 一、问题二、解决方法三、代码实现 一、问题 内网安装第三方包的应用场景,一般是一些需要在没网的环境下进行开发的情况。这些环境一般仅支持本地局域网访问,所以只能在不下载任何第三方包的情况下艰难开发。 二、解决方法 将当前应用依赖的第…...
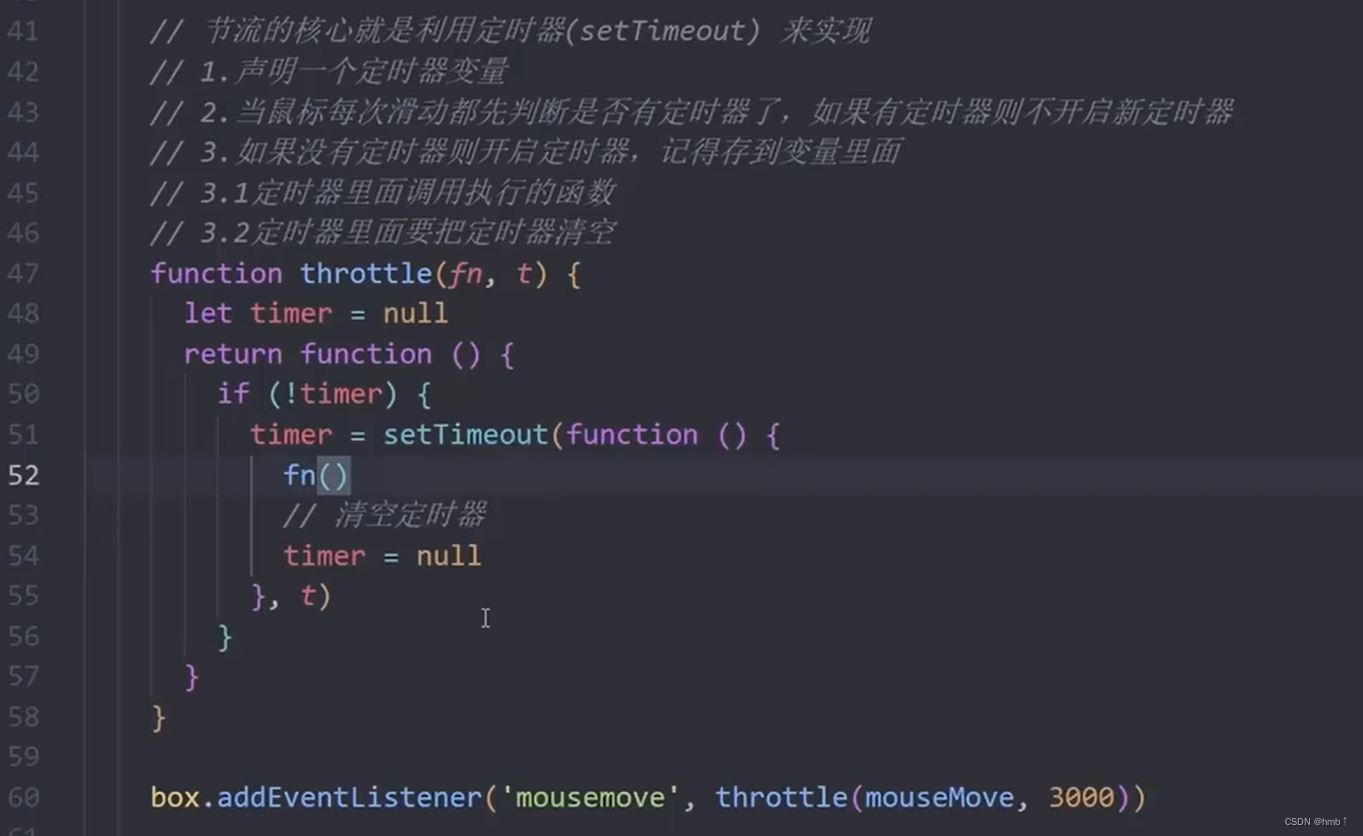
javaScipt
javaScipt 一、JavaScript简介二、javaScript基础1、输入输出语法2、变量3、常量4、数据类型4.1、数字型 number4.2、字符串类型 string4.3、布尔类型 boolean4.4、未定义类型 undefined4.5、null 空类型4.6、typeof 检测变量数据类型 5、数据类型转换5.1、隐式转换5.2、显示转…...

Linux(实操篇三)
Linux实操篇 Linux(实操篇三)1. 常用基本命令1.7 搜索查找类1.7.1 find查找文件或目录1.7.2 locate快速定位文件路径1.7.3 grep过滤查找及"|"管道符 1.8 压缩和解压类1.8.1 gzip/gunzip压缩1.8.2 zip/unzip压缩1.8.3 tar打包 1.9 磁盘查看和分区类1.9.1 du查看文件和…...

数学之美 — 1
为什么你会想和他人共享那些美丽的事物呢?因为这会让他(她)感到愉悦,也能让你在分享的过程中重新欣赏一次事物的美。 ——David Blackwell 1、感官之美,对于那些有规律的事物,你可以利用自己的视觉、触觉、…...

python中的global关键字
在Python中,global关键字用于在函数内部声明一个全局变量。默认情况下,函数内部的变量是局部变量,只能在函数内部访问。使用global关键字可以在函数内部创建或修改全局变量,使其在函数外部也可见和修改。 以下是使用global关键字…...

Matlab图像处理-幂次变换
幂次变换 如下图所示的幂次变换函数曲线图: 当γ <1时,效果和对数变换相似,放大暗处细节,压缩亮处细节,随着数值减少,效果越强。 当γ >1时,放大亮处细节,压缩暗处细节&…...

浏览器输入 URL 地址,访问主页的过程
分析&回答 浏览器解析域名;TCP建立连接;浏览器向服务器发送HTTP请求;服务器解析请求并返回HTTP报文;浏览器解析并渲染页面;断开连接。 反思&扩展 域名解析的流程 查找浏览器缓存——我们日常浏览网站时&am…...

每日一学————基本配置和管理
一、交换机的基本配置 配置enable口令、密码和主机名 Switch> (用户执行模式提示符) Switch>enable (进入特权模式) Switch# …...
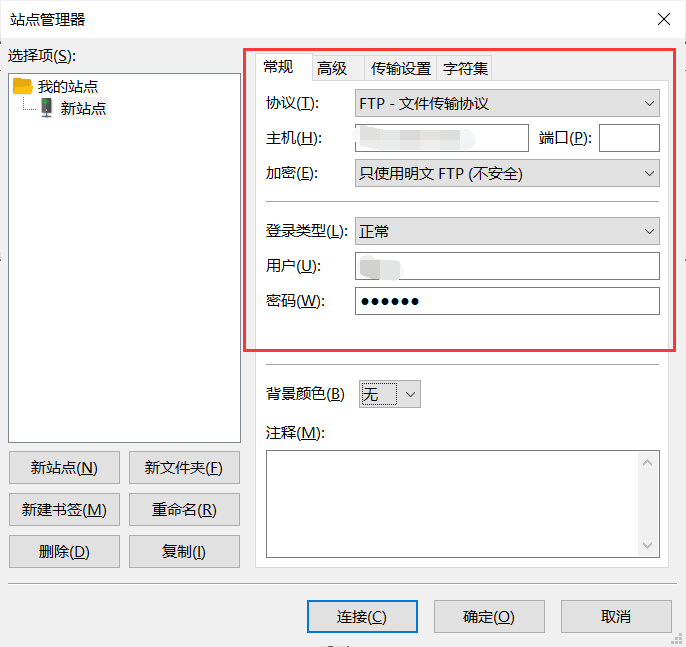
解决 filezilla 连接服务器失败问题
问题描述: 开始一直用的 XFTP 后来,它变成收费软件了,所以使用filezilla 代替 XFTP 之前用的还好好的,今天突然就报错了:按要求输入相关字段,连接 连接失败!!!o(╥﹏╥…...

如何使用Java进行机器学习?
在Java中进行机器学习,可以使用各种开源机器学习库和框架来实现。以下是一些常用的Java机器学习库: Weka:Weka 是一个非常流行的机器学习库,提供了大量的算法和工具,以及用于数据预处理、特征选择和可视化的功能。 De…...
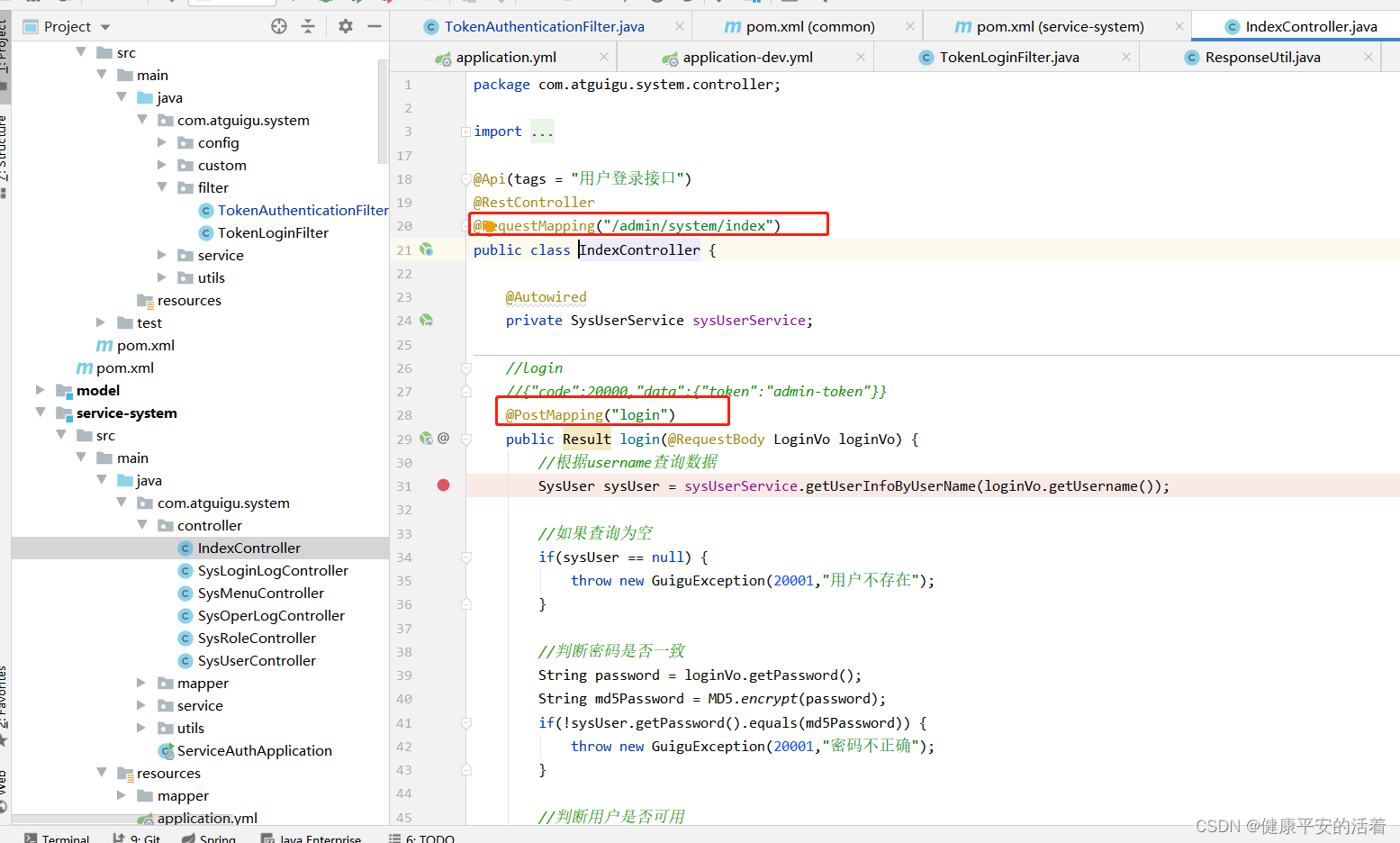
springsecurity+oauth 分布式认证授权笔记总结12
一 springsecurity实现权限认证的笔记 1.1 springsecurity的作用 springsecurity两大核心功能是认证和授权,通过usernamepasswordAuthenticationFilter进行认证;通过filtersecurityintercepter进行授权。springsecurity其实多个filter过滤链进行过滤。…...

如何在职业生涯中取得成功
工作中让你有强烈情绪波动的事情 在我的工作经历中,有一次让我经历了强烈情绪波动的事件。我曾在一个高压的项目团队中工作,我们需要在极短的时间内完成一个复杂的客户项目。这个项目的截止日期非常紧迫,而项目的规模和要求也一直在不断增加…...
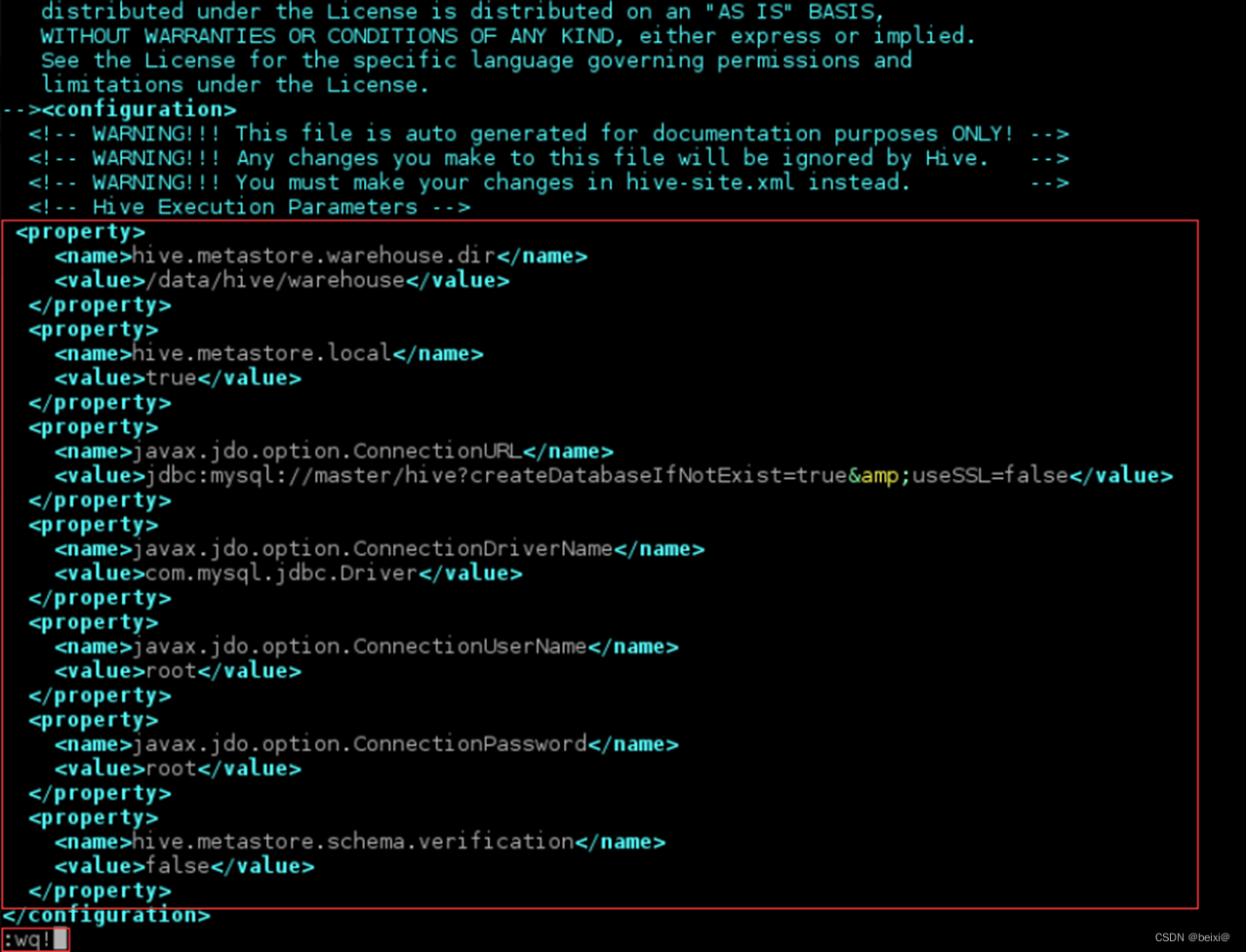
Hive-安装与配置(1)
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

链表模拟栈
定义节点 class Node {var num: Int _var next: Node _def this(num: Int) {thisthis.num num}override def toString: String s"num[${this.num}]" }定义方法 class LinkStack {private var head new Node(0)def getHead: Node head//判断是否为空def isEmp…...

MySQL基础篇:数据库概述和部署
SQL 概述 SQL,一般发音为sequel,SQL的全称Structured Query Language),SQL用来和数据库打交道,完成和数据库的通信,SQL是一套标准。但是每一个数据库都有自己的特性别的数据库没有,当使用这个数据库特性相关的功能,这…...

拯救者笔记本终极优化指南:5个必知技巧彻底释放硬件潜能
拯救者笔记本终极优化指南:5个必知技巧彻底释放硬件潜能 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit 你是否厌…...

OpenCV实战:工业相机Bayer数据高效转换与图像处理全流程
1. 工业相机Bayer格式基础解析 第一次接触工业相机输出的Bayer格式数据时,我盯着那些看起来像黑白噪点的图像完全摸不着头脑。后来才发现,这其实是工业视觉领域最常见的原始数据格式之一。Bayer格式的本质是单通道马赛克阵列,每个像素点只记录…...

蓝桥杯嵌入式模拟赛2实战复盘:用STM32G431搞定LCD、LED、按键、PWM和串口
蓝桥杯嵌入式模拟赛2全流程实战解析:从零构建STM32G431多模块协同系统 当开发板的电源指示灯第一次亮起,LCD屏幕浮现出清晰的白色字符时,我知道这不仅仅是一次普通的练习——这是将分散的模块知识整合成完整系统的关键时刻。蓝桥杯嵌入式模拟…...

数据分析篇---U型关系与与阈值效应
在数据科学、经济学和医学研究中,“U型关系”和“阈值效应”是两种非常经典且重要的非线性模式。它们描述的是变量之间并非简单的“越多越好”的直线关系,而是存在转折点。可以把线性关系想象成匀速开车,而U型和阈值效应则像是开车时遇到的上…...

告别‘天书’!手把手教你用vdex2dex、odex2smali等工具,把Android应用的vdex/odex/cdex转成可读的dex文件
Android逆向工程实战:从vdex/odex/cdex到可读dex的完整指南 当你兴致勃勃地打开一个APK文件准备分析时,却发现里面只有vdex、odex或cdex文件,用JADX直接打开全是乱码——这种挫败感每个逆向工程师都经历过。本文将带你一步步破解这些"天…...
)
别再只用差速轮了!手把手教你为Navigation2仿真打造专属阿克曼底盘模型(附完整URDF/SDF文件)
从差速轮到阿克曼:打造高仿真Navigation2底盘模型的完整指南 在机器人仿真领域,差速轮底盘因其简单可靠而广受欢迎,但真实世界的车辆大多采用阿克曼转向机制。本文将带您深入理解两种模型的本质差异,并手把手指导如何从零构建或改…...

昇腾NPU算子开发进阶:深入理解ops-tensor中的解决方案注册机制 [特殊字符]
昇腾NPU算子开发进阶:深入理解ops-tensor中的解决方案注册机制 🚀 【免费下载链接】ops-tensor ops-tensor 是 CANN (Compute Architecture for Neural Networks)算子库中提供张量类计算的基础算子库,采用模块化设计&a…...

CANN/cannbot-skills模型推理融合算子优化
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: model-infer-fusion description: 基于 PyTorch 框架的昇腾 NPU…...

告别机械音!用‘小蜗语音工具1.9’制作有声小说和视频字幕的保姆级教程
告别机械音!用‘小蜗语音工具1.9’制作有声小说和视频字幕的保姆级教程 在内容创作爆炸的时代,有声小说和视频字幕已成为吸引用户注意力的关键。然而,传统语音合成工具常因生硬的机械音、单调的语调让作品失去灵魂。小蜗语音工具1.9的多角色对…...

人类的自然关系与AI的形式化关系
“人类的自然关系”与“AI的形式化关系”是理解下一代人机环境系统智能的两个核心哲学维度。它们分别代表了智能系统在物理世界中的生存根基与在数字世界中的运行逻辑。我们可以从以下三个层面来深度解析这两者的区别与融合:人类的自然关系:从“征服掠夺…...