Python Scrapy 爬虫简单教程
1. Scrapy install
准备知识
- pip 包管理
- Python 安装
- Xpath
- Css
Windows安装 Scrapy
$>- pip install scrapy
Linux安装 Scrapy
$>- apt-get install python-scrapy
2. Scrapy 项目创建
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
$>- scrapy startproject mySpider
其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,使用命令查看目录结构
3. Scrapy 自定义爬虫类
通过Scrapy的Spider基础模版顺便建立一个基础的爬虫。(也可以不用Scrapy命令建立基础爬虫,)
$>- scrapy genspider gzrbSpider dayoo.com
scrapy genspider是一个命令,也是scrapy最常用的几个命令之一。至此,一个最基本的爬虫项目已经建立完毕了.
文件描述:
| 序列 | 文件名 | 描述 |
|---|---|---|
| 1 | scrapy.cfg | 是整个Scrapy项目的配置文件 |
| 2 | settings.py | 是上层目录中scrapy.cfg定义的设置文件(决定由谁去处理爬取的内容) |
| 3 | init.pyc | 是__init__.py的字节码文件 |
| 4 | init.py | 作用就是将它的上级目录变成了一个模块 ,否则,文件夹没有__init__.py不能作为模块导入 |
| 5 | items.py | 是定义爬虫最终需要哪些项 (决定爬取哪些项目) |
| 5 | pipelines.py | Scrapy爬虫爬取了网页中的内容后,这些内容怎么处理就取决于pipelines.py如何设置 (决定爬取后的内容怎样处理) |
| 6 | gzrbSpider.py | 自定义爬虫类(决定怎么爬) |
命令描述:
| 序列 | 操作 | 描述 |
|---|---|---|
| 1 | 模拟爬广州日报网页 | scrapy shell https://www.dayoo.com |
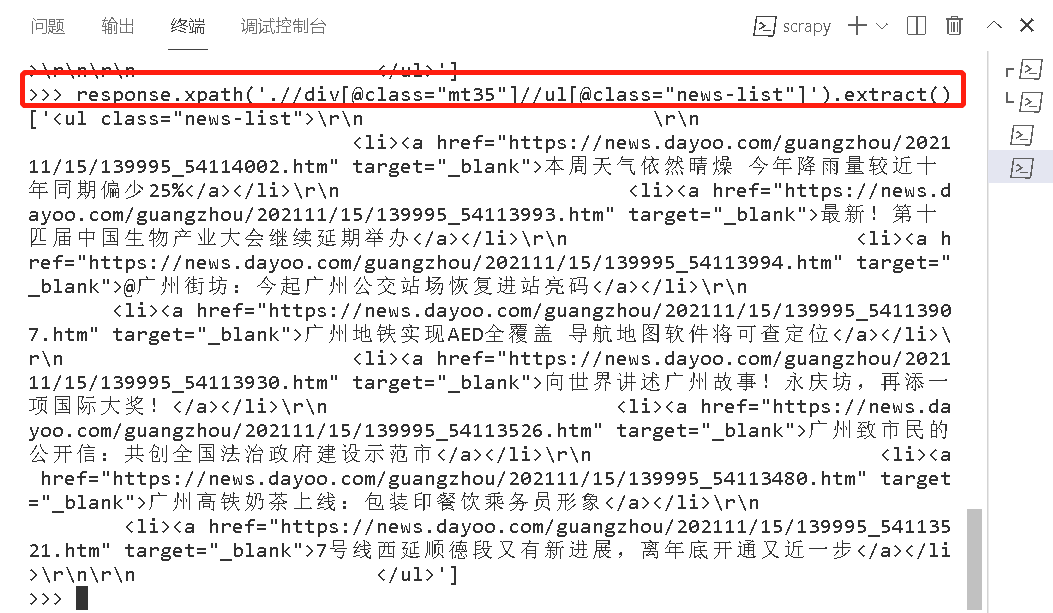
| 2 | 模拟查看节点数据 | response.xpath('.//div[@class="mt35"]//ul[@class="news-list"]').extract()
|
| 3 | 运行爬虫 | scrapy crawl gzrbSpider |
4. Scrapy 处理逻辑
文件 \spiders\gzrbSpider.py
import scrapy
from mySpider.items import MySpiderItemclass gzrbSpider(scrapy.Spider):name = "gzrbSpider"allowed_domains = ["dayoo.com/"]start_urls = ('https://www.dayoo.com',)def parse(self, response):subSelector = response.xpath('.//div[@class="mt35"]//ul[@class="news-list"]')items = []for sub in subSelector:item = MySpiderItem()item['newName'] = sub.xpath('./li/a/text()').extract()items.append(item)return items
文件 Item.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass MySpiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()newName = scrapy.Field()
文件 Setting.py
# Scrapy settings for mySpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'mySpider'SPIDER_MODULES = ['mySpider.spiders']
NEWSPIDER_MODULE = 'mySpider.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'mySpider(+http://www.yourdomain.com)'# Obey robots.txt rules
ROBOTSTXT_OBEY = True# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
#COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'mySpider.middlewares.mySpiderSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'mySpider.middlewares.mySpiderDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {'mySpider.pipelines.mySpiderPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
文件 pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import time# class mySpiderPipeline:
# def process_item(self, item, spider):
# return itemclass MySpiderPipeline(object):def process_item(self, item, spider):now = time.strftime('%Y-%m-%d', time.localtime())fileName = 'gzrb' + now + '.txt'for it in item['newName ']:with open(fileName,encoding='utf-8',mode = 'a') as fp:# fp.write(item['newName '][0].encode('utf8') + '\n\n')fp.write(it + '\n\n')return item本文代码结果展示:

5. Scrapy 扩展
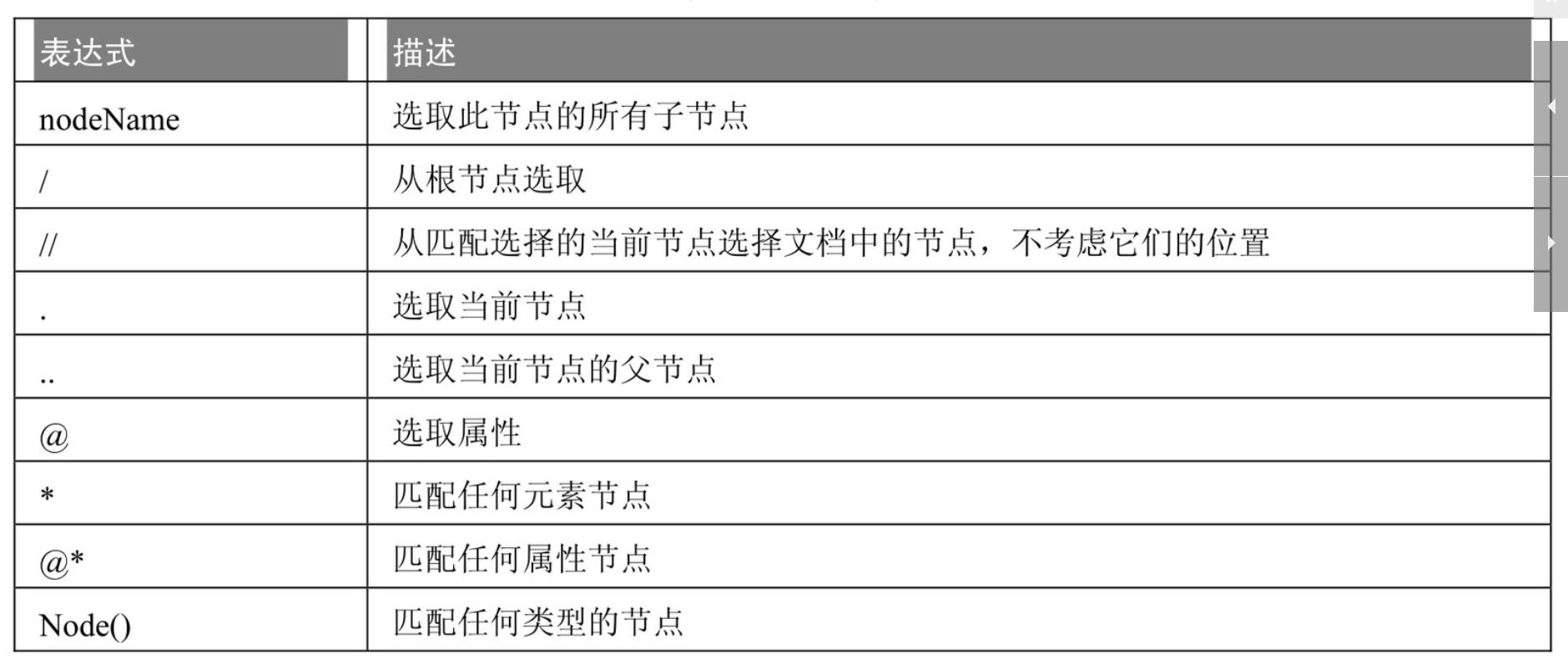
Xpath:
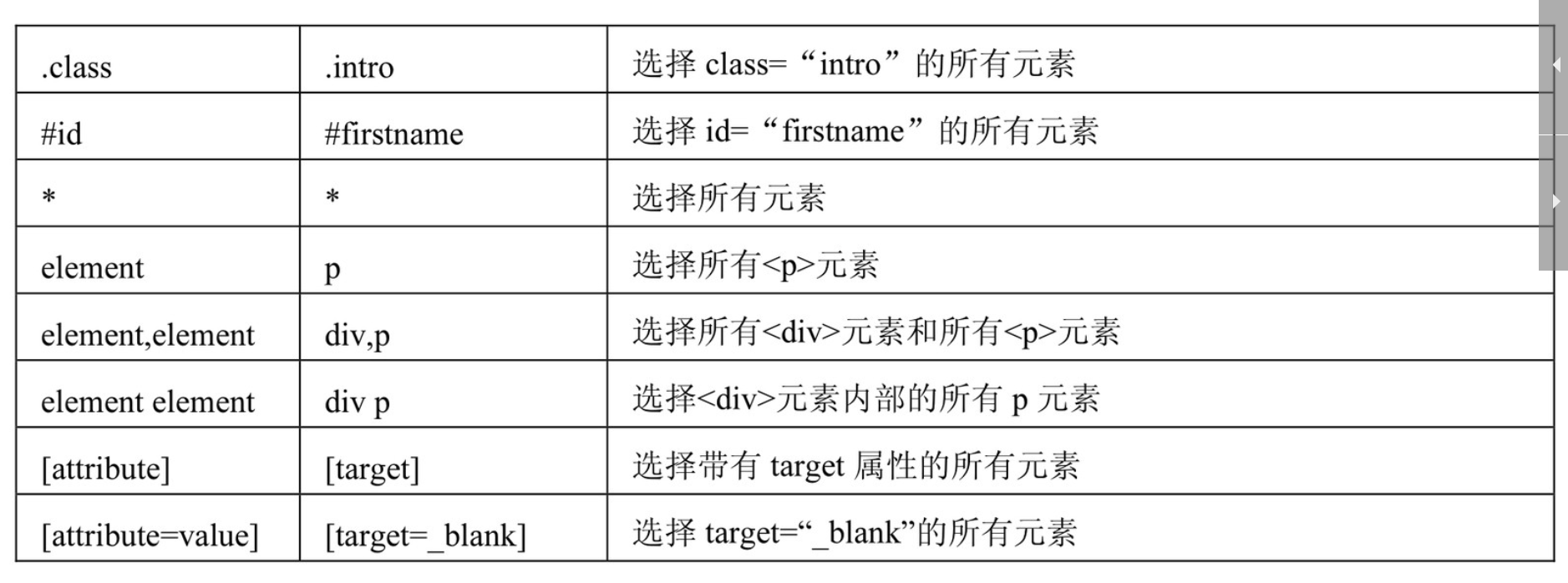
Css:
相关文章:
Python Scrapy 爬虫简单教程
1. Scrapy install 准备知识 pip 包管理Python 安装XpathCssWindows安装 Scrapy $>- pip install scrapy Linux安装 Scrapy $>- apt-get install python-scrapy 2. Scrapy 项目创建 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中&am…...
【DOCKER】容器概念基础
文章目录1.容器1.概念2.特点3.与虚拟机的对比2.docker1.概念2.命名空间3.核心概念3.命令1.镜像命令2.仓库命令1.容器 1.概念 1.不同的运行环境,底层架构是不同的,这就会导致测试环境运行好好的应用,到了生产环境就会出现bug(就像…...
第九层(16):STL终章——常用集合算法
文章目录前情回顾常用集合算法set_intersectionset_unionset_difference最后一座石碑倒下,爬塔结束一点废话🎉welcome🎉 ✒️博主介绍:一名大一的智能制造专业学生,在学习C/C的路上会越走越远,后面不定期更…...

一起学习用Verilog在FPGA上实现CNN----(六)SoftMax层设计
1 SoftMax层设计 1.1 softmax SoftMax函数的作用是输入归一化,计算各种类的概率,即计算0-9数字的概率,SoftMax层的原理图如图所示,输入和输出均为32位宽的10个分类,即32x10320 本项目softmax实现逻辑为: …...

pixhawk2.4.8-APM固件-MP地面站配置过程记录
目录一、硬件准备二、APM固件、MP地面站下载三、地面站配置1 刷固件2 机架选择3 加速度计校准4 指南针校准5 遥控器校准6 飞行模式7 紧急断电&无头模式8 基础参数设置9 电流计校准10 电调校准11 起飞前检查(每一项都非常重要)12 飞行经验四、遇到的问…...
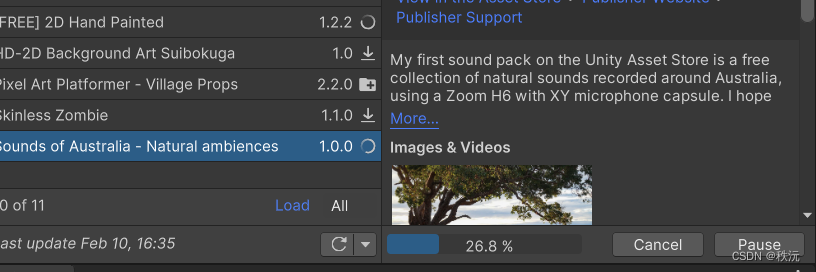
【unity细节】关于资源商店(Package Maneger)无法下载资源问题的解决
👨💻个人主页:元宇宙-秩沅 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 秩沅 原创 收录于专栏:unity细节和bug ⭐关于资源商店为何下载不了的问题⭐ 文章目录⭐关于资源商店为何下载不了的问题…...

[Arxiv 2022] A Novel Plug-in Module for Fine-Grained Visual Classification
Contents MethodPlug-in ModuleLoss functionExperimentsReferencesMethod Plug-in Module Backbone:为了帮助模型抽取出不同尺度的特征,作者在 backbone 里加入了 FPNWeakly Supervised Selector:假设 backbone 的 i i...
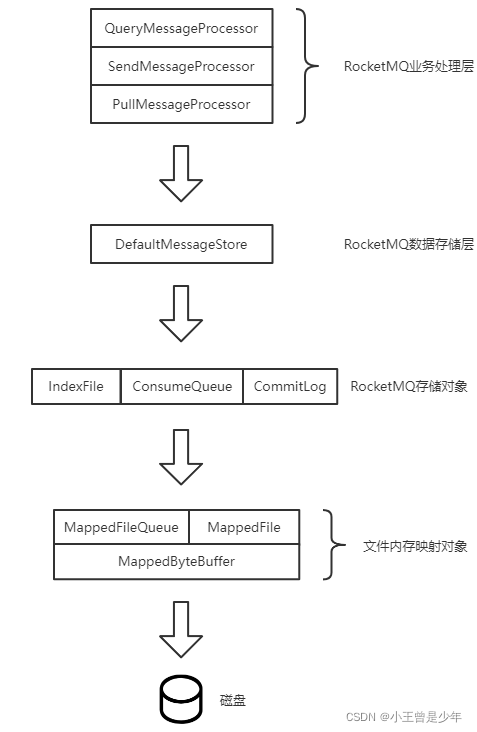
RocketMQ Broker消息处理流程及部分源码解析
🍊 Java学习:Java从入门到精通总结 🍊 深入浅出RocketMQ设计思想:深入浅出RocketMQ设计思想 🍊 绝对不一样的职场干货:大厂最佳实践经验指南 📆 最近更新:2023年2月10日 &#x…...
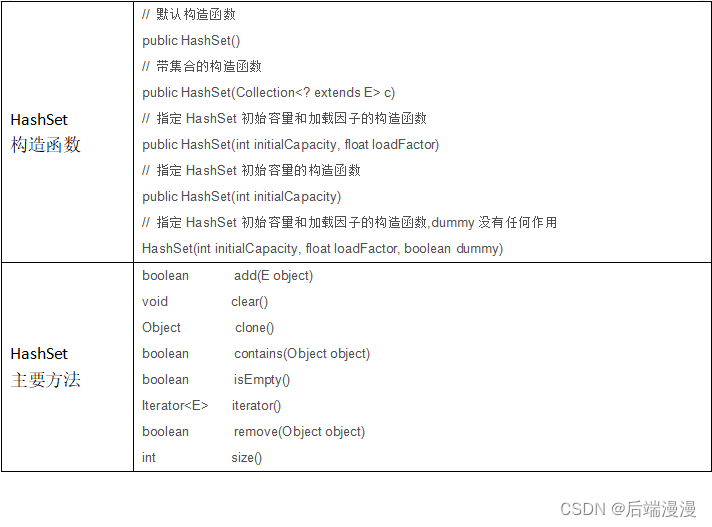
Java面试题:Java集合框架
文章目录一、Java集合框架二、Java集合特性三、各集合类的使用ArrayListLinkedListHashSetHashSet源码解析对源码进行总结HashSet可同步HashSet的使用HashMap四、Iterator迭代器五、遍历集合元素的若干方式参考文章:Hash详解参考文章:深入浅出学Java——…...

时间之间的比较与计算相差年、月、日、小时、分钟、毫秒、纳秒以及判断闰年--LocalDateTime
如何把String/Date转成LocalDateTime参考String、Date与LocalDate、LocalTime、LocalDateTime之间互转 String、Date、LocalDateTime、Calendar与时间戳之间互相转化参考String、Date、LocalDateTime、Calendar与时间戳之间互相转化 比较方法介绍 isBefore(ChronoLocalDateT…...

PyTorch学习笔记:nn.L1Loss——L1损失
PyTorch学习笔记:nn.L1Loss——L1损失 torch.nn.L1Loss(size_averageNone, reduceNone, reductionmean)功能:创建一个绝对值误差损失函数,即L1损失: l(x,y)L{l1,…,lN}T,ln∣xn−yn∣l(x,y)L\{l_1,\dots,l_N\}^T,l_n|x_n-y_n| l(…...
Java程序设计-ssm企业财务管理系统设计与实现
摘要系统设计系统实现开发环境:摘要 对于企业集来说,财务管理的地位很重要。随着计算机和网络在企业中的广泛应用,企业发展速度在不断加快,在这种市场竞争冲击下企业财务管理系统必须优先发展,这样才能保证在竞争中处于优势地位。…...

疑难杂症篇(二十一)--Ubuntu18.04安装usb-cam过程出现的问题
对Ubuntu18.04{\rm Ubuntu 18.04}Ubuntu18.04环境下的ROS{\rm ROS}ROS的melodic{\rm melodic}melodic版本安装usb−cam{\rm usb-cam}usb−cam过程出现的两个常见问题提出解决方案。 1.问题1:usb-cam功能包编译时出现"未定义的引用"的问题 问题描述&#…...

npm-npm i XX --save 和--save-dev
之前使用npm i XX --save 和--save-dev 没太在意,就想记录一下,查到一篇比较全的(链接:NPM install -save 和 -save-dev 傻傻分不清),直接看好了,哈哈~ # 安装模块到项目目录下 npm install moduleName # -g 的意思是…...
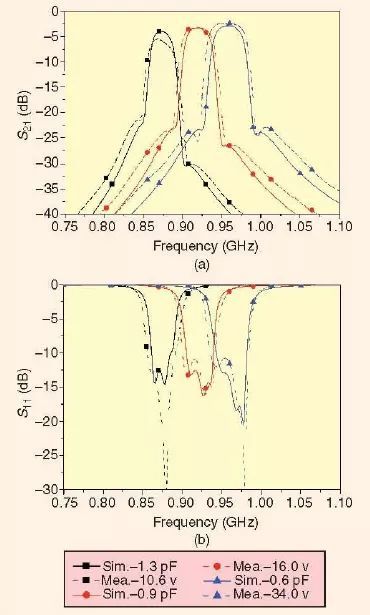
可重构或可调谐微波滤波器技术
电子可重构,或者说电调微波滤波器由于其在改善现在及未来微波系统容量中不断提高的重要性而正吸引着人们越来越多的关注来对其进行研究和开发。例如,崭露头脚的超宽带(UWB)技术要求使用很宽的无线电频谱。然而,作为资源…...
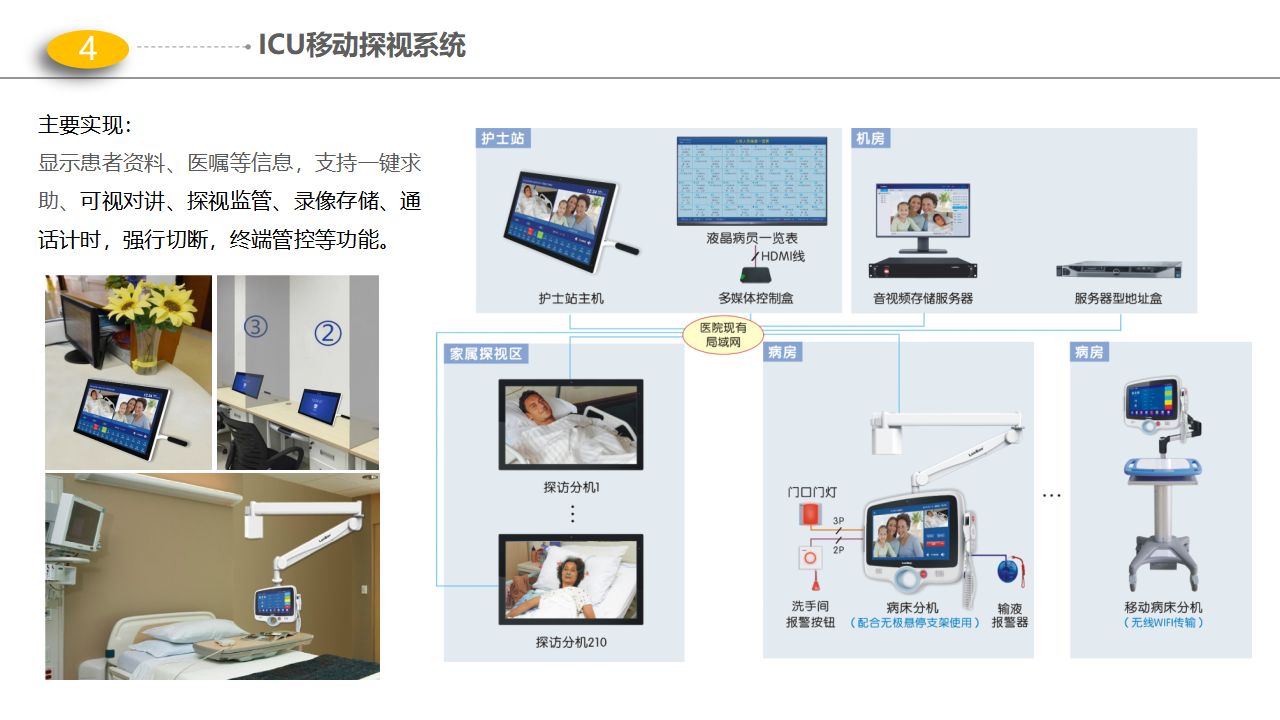
医院智能化解决方案-门(急)诊、医技、智能化项目解决方案
【版权声明】本资料来源网络,知识分享,仅供个人学习,请勿商用。【侵删致歉】如有侵权请联系小编,将在收到信息后第一时间删除!完整资料领取见文末,部分资料内容:篇幅有限,无法完全展…...

判断元素是否在可视区域
前言 在日常开发中,我们经常需要判断目标元素是否在视窗之内或者和视窗的距离小于一个值(例如 100 px),从而实现一些常用的功能,例如: 图片的懒加载列表的无限滚动计算广告元素的曝光情况可点击链接的预加…...

告别传统繁杂的采购合同管理 打造企业自动化采购管理模式
随着企业竞争日趋激烈,采购成本压力剧增,企业对于采购合同管理更加严格,从而把控物资成本。对于任何一家企业采购来说,规范化合同的全面管理,是采购活动中重要的一个环节。 但在如今,依旧有很多企业采购合…...
【prism】路由事件映射到Command命令
在之前的一篇文章中,我介绍了普通的自定义事件: 【wpf】自定义事件总结(Action, EventHandler)_code bean的博客-CSDN博客_wpf action可以说通过Action和EventHandle,自定义事件是相当的方便简单了。https…...
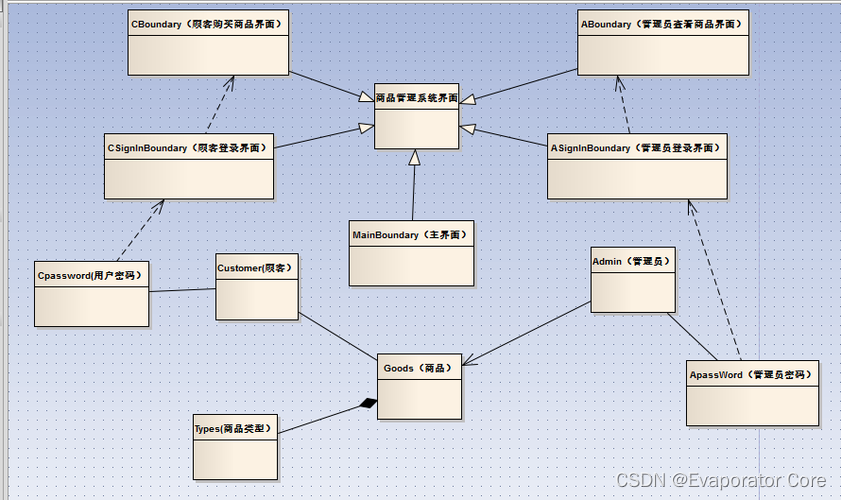
面向对象的基本概念和方法
面向对象的开发方法在近几十年见得以广泛应用,我们常见的Java语言就是一种典型的面向对象的开发语言。然而,面向对象的概念较为复杂,知识点也很细碎,本文整理了面向对象的基本概念和方法,供大家参考。为了便于读者理解…...
)
别再为Canvas跨域头疼了!手把手教你用UniApp H5搞定网络图片转Base64并生成海报(附完整代码)
UniApp H5开发实战:Canvas跨域图片处理与海报生成全攻略 在移动端H5开发中,Canvas绘制网络图片并生成分享海报是个常见需求,但跨域问题往往让开发者头疼不已。本文将带你深入理解Canvas的CORS限制本质,对比两种主流解决方案的技术…...
)
别再死记SGD公式了!用PyTorch手把手带你复现一个‘会滚下山’的优化器(附完整代码)
从零构建PyTorch SGD优化器:可视化梯度下降的物理直觉 想象你站在一座云雾缭绕的山顶,手中握着一颗钢珠。当你松开手指,钢珠会沿着最陡峭的路径滚向谷底——这正是梯度下降算法的核心隐喻。本文将带你用PyTorch重建这个直观过程,不…...

D3KeyHelper终极指南:5分钟上手暗黑3智能宏,轻松提升游戏体验
D3KeyHelper终极指南:5分钟上手暗黑3智能宏,轻松提升游戏体验 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 还在为暗黑破坏…...

如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南
如何快速解析SWF文件:JPEXS免费Flash反编译器的完整指南 【免费下载链接】jpexs-decompiler JPEXS Free Flash Decompiler 项目地址: https://gitcode.com/gh_mirrors/jp/jpexs-decompiler JPEXS Free Flash Decompiler是一款功能强大的开源Flash逆向工程工具…...
了!IntelliJ IDEA这个告警到底在说什么?)
别再在循环里写Thread.sleep()了!IntelliJ IDEA这个告警到底在说什么?
循环中的Thread.sleep():为什么IntelliJ IDEA警告你正在"忙等待"? 在IntelliJ IDEA中编写Java代码时,你是否遇到过这样的警告:"Call to Thread.sleep() in a loop, probably busy-waiting"?这个看…...

iPaaS平台排名:五大主流产品的市场表现与核心能力
在数字化转型加速推进的当下,iPaaS(集成平台即服务)已成为企业构建敏捷IT架构、打通数据孤岛的关键基础设施。市场上涌现出多款各具特色的集成平台,它们在产品定位、技术架构与行业深耕上形成了差异化优势。本文基于公开资料&…...

从SolarWinds事件看供应链攻击与网络防御责任重构
1. 从SolarWinds事件看现代网络防御的“责任困境”2020年底曝光的SolarWinds供应链攻击,无疑给全球网络安全界投下了一颗震撼弹。攻击者通过入侵IT监控软件巨头SolarWinds的软件构建系统,在其Orion平台软件更新包中植入后门,导致全球超过1800…...

给视觉开发新手的保姆级教程:在Ubuntu上从下载源码到成功运行Demo,搞定OpenCV 3环境搭建
给视觉开发新手的保姆级教程:在Ubuntu上从下载源码到成功运行Demo,搞定OpenCV 3环境搭建 第一次在Ubuntu上搭建OpenCV开发环境,对很多视觉开发新手来说可能是个令人望而生畏的任务。命令行操作、编译工具链、环境配置……这些术语听起来就让人…...

AI代码库分析:用大模型自动生成项目教程与架构图
1. 项目概述:用AI将陌生代码库变成你的专属教程 你有没有过这样的经历?接手一个新项目,或者想学习一个热门的开源库,打开GitHub仓库,面对成百上千个文件、错综复杂的目录结构,瞬间感觉无从下手。README.md可…...

Rails AI上下文模块设计:领域驱动与AI服务集成实践
1. 项目概述:当植物病理学遇上AI代码助手最近在整理一个老项目时,我遇到了一个非常有意思的命名:“Peronosporaceaevenography165/rails-ai-context”。乍一看,这像是一个典型的GitHub仓库命名风格,前半部分是极其专业…...