Google colab部署VITS——零门槛快速克隆任意角色声音
目录
序言
查看GPU配置
复制代码库并安装运行环境
选择预训练模型
上传视频链接(单个不应长于20分钟)
自动处理所有上传的数据
训练质量相关:实验发现目前使用CJ模型+勾选ADD_AUXILIARY,对于中/日均能训练出最好的效果,第一次训练建议默认使用该组
开始训练
微调完成后,在这里尝试效果
下载模型
模型演示
Text-to-Speech
Voice Conversion
序言
语音合成技术是人工智能领域的重要分支,近年来取得了长足的进步。涌现出众多优秀的语音合成模型,其中VITS和DDSP是两种代表性的模型。
VITS模型采用了变分自编码器和声码器的组合架构,在长期训练下可以生成逼真、自然的语音。然而,由于其对显存的要求较高,不适合在普通的个人电脑上进行本地部署训练。
为了降低VITS模型的入手门槛,我选择使用Google Colab来实现本地部署训练。Google Colab是一个免费的云端计算平台,可以提供强大的计算能力。在此基础上,其简便性进行了进一步强化,目前可以仅通过视频链接来一键进行数据集处理,可以大大节省用户的时间和精力。
当然,VITS模型也存在一定的缺点,在短时间和数据集较少、质量较低的情况下,其效果会不如DDSP。因此,在选择合适的语音合成模型时,需要根据实际情况进行考量。
查看GPU配置
# 查看GPU配置
# Check GPU configuration
!nvidia-smi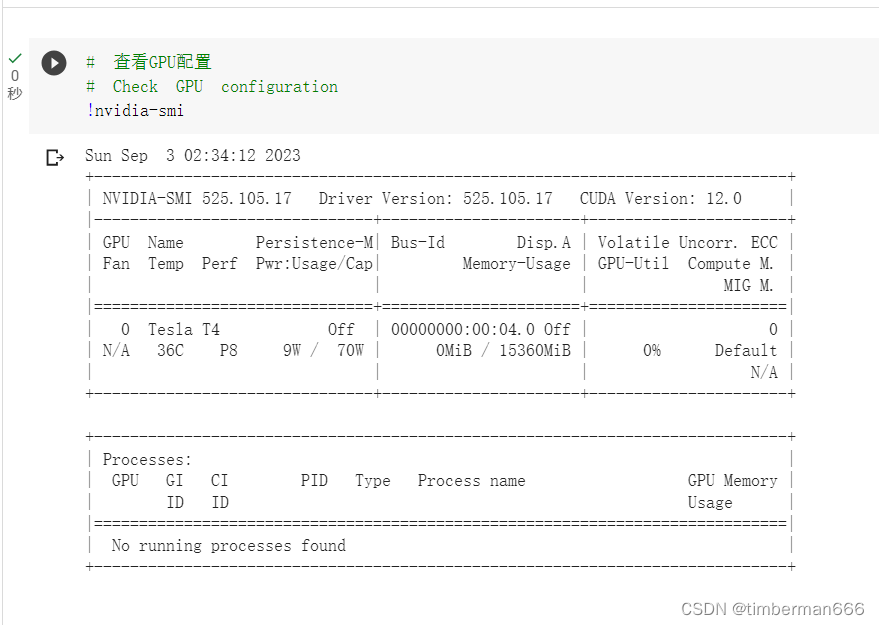
复制代码库并安装运行环境
#@title STEP 1 复制代码库并安装运行环境
#@markdown #STEP 1 (6 min)
#@markdown ##复制代码库并安装运行环境
#@markdown ##Clone repository & Build environment!git clone https://github.com/Plachtaa/VITS-fast-fine-tuning.git
!python -m pip install --upgrade --force-reinstall regex
!python -m pip install --force-reinstall soundfile
!python -m pip install --force-reinstall gradio
!python -m pip install imageio==2.4.1
!python -m pip install --upgrade youtube-dl
!python -m pip install moviepy
%cd VITS-fast-fine-tuning!python -m pip install --no-build-isolation -r requirements.txt
!python -m pip install --upgrade numpy
!python -m pip install --upgrade --force-reinstall numba
!python -m pip install --upgrade Cython!python -m pip install --upgrade pyzmq
!python -m pip install pydantic==1.10.4
!python -m pip install ruamel.yaml# build monotonic align
%cd monotonic_align/
!mkdir monotonic_align
!python setup.py build_ext --inplace
%cd ..
!mkdir pretrained_models
# download data for fine-tuning
!wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/sampled_audio4ft_v2.zip
!unzip sampled_audio4ft_v2.zip
# create necessary directories
!mkdir video_data
!mkdir raw_audio
!mkdir denoised_audio
!mkdir custom_character_voice
!mkdir segmented_character_voice
选择预训练模型
#@title STEP 1.5 选择预训练模型
#@markdown ###STEP 1.5 选择预训练模型
#@markdown ###Choose pretrained model to start
#@markdown CJE为中日英三语模型,CJ为中日双语模型,C为纯中文模型#@markdown CJE for Chinese, Japanese & English model,CJ for Chinese & Japanese model
PRETRAINED_MODEL = "CJ" #@param ["CJE","CJ","C"]
if PRETRAINED_MODEL == "CJ":!wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/D_0-p.pth -O ./pretrained_models/D_0.pth!wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/G_0-p.pth -O ./pretrained_models/G_0.pth!wget https://huggingface.co/spaces/sayashi/vits-uma-genshin-honkai/resolve/main/model/config.json -O ./configs/finetune_speaker.json
elif PRETRAINED_MODEL == "CJE":!wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/D_trilingual.pth -O ./pretrained_models/D_0.pth!wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/pretrained_models/G_trilingual.pth -O ./pretrained_models/G_0.pth!wget https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer/resolve/main/configs/uma_trilingual.json -O ./configs/finetune_speaker.json
elif PRETRAINED_MODEL == "C":!wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/D_0.pth -O ./pretrained_models/D_0.pth!wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/G_0.pth -O ./pretrained_models/G_0.pth!wget https://huggingface.co/datasets/Plachta/sampled_audio4ft/resolve/main/VITS-Chinese/config.json -O ./configs/finetune_speaker.json
上传视频链接(单个不应长于20分钟)
#@markdown 运行该代码块会出现一个文件上传的入口,上传单个`.txt`文件。若格式正确的话,视频会自动下载并将下载后的文件名打印在下方。#@markdown Running this code block will prompt you to upload a file.
#@markdown Please upload a single `.txt` file. If you have put the links in the correct format,
#@markdown the videos will be automatically downloaded and displayed below.
%run scripts/download_video.py
!ls ./video_data/

自动处理所有上传的数据
#@markdown 运行该单元格会对所有上传的数据进行自动去背景音&标注。
#@markdown 由于需要调用Whisper和Demucs,运行时间可能较长。#@markdown Running this codeblock will perform automatic vocal seperation & annotation.
#@markdown Since this step uses Whisper & Demucs, it may take a while to complete.
# 将所有视频(无论是上传的还是下载的,且必须是.mp4格式)抽取音频
%run scripts/video2audio.py
# 将所有音频(无论是上传的还是从视频抽取的,必须是.wav格式)去噪
!python scripts/denoise_audio.py
# 分割并标注长音频
!python scripts/long_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large
# 标注短音频
!python scripts/short_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size large
# 底模采样率可能与辅助数据不同,需要重采样
!python scripts/resample.py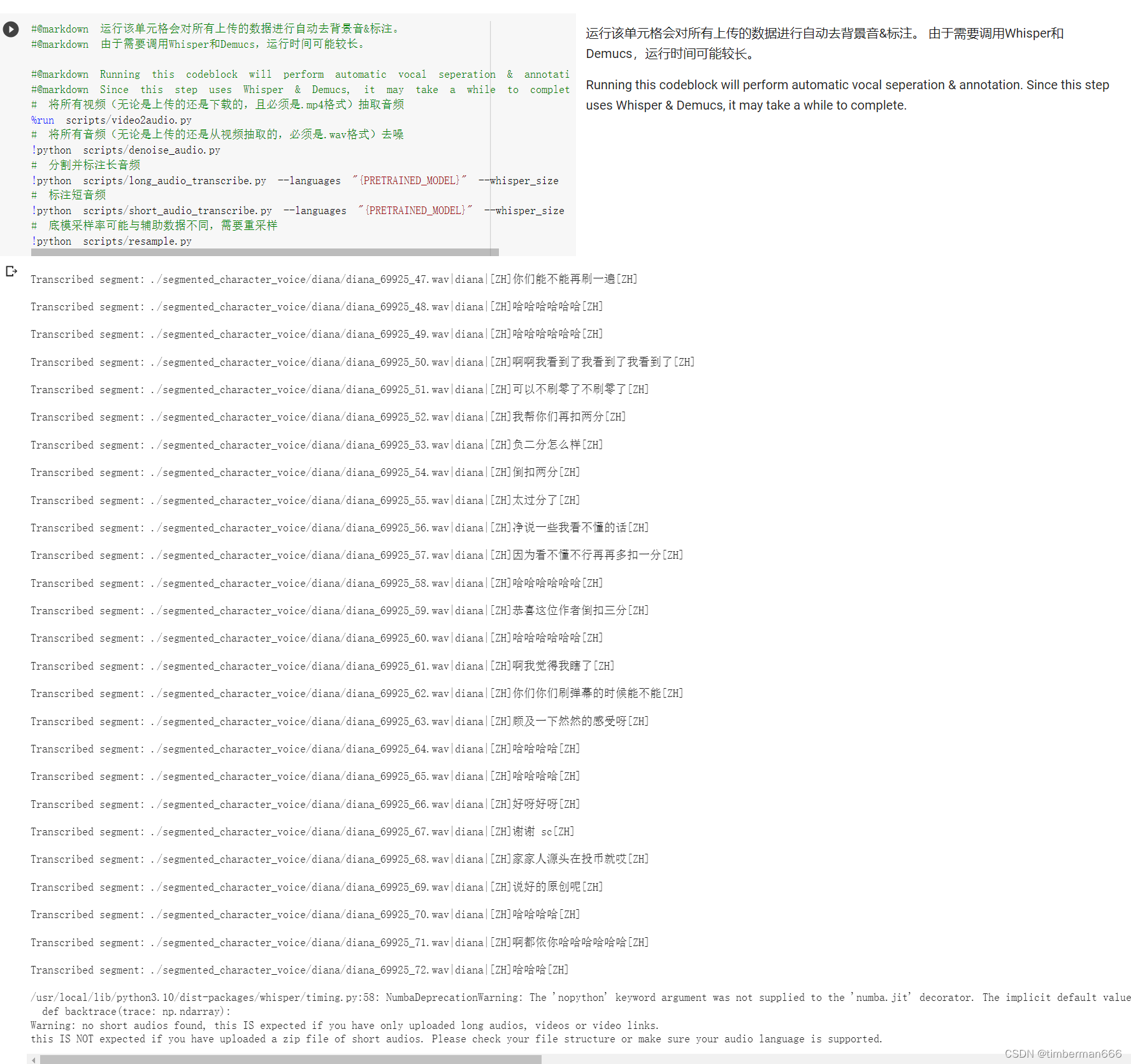
训练质量相关:实验发现目前使用CJ模型+勾选ADD_AUXILIARY,对于中/日均能训练出最好的效果,第一次训练建议默认使用该组
#@markdown ##STEP 3.5
#@markdown 运行该单元格会生成划分好训练/测试集的最终标注,以及配置文件#@markdown Running this block will generate final annotations for training & validation, as well as config file.#@markdown 选择是否加入辅助训练数据:/ Choose whether to add auxiliary data:
ADD_AUXILIARY = False #@param {type:"boolean"}
#@markdown 辅助训练数据是从预训练的大数据集抽样得到的,作用在于防止模型在标注不准确的数据上形成错误映射。#@markdown Auxiliary data is to prevent overfitting when the audio samples are small or with low quality.#@markdown 以下情况请勾选:#@markdown 总样本少于100条/样本质量一般或较差/样本来自爬取的视频#@markdown 以下情况可以不勾选:#@markdown 总样本量很大/样本质量很高/希望加速训练/只有二次元角色# assert(not (ADD_AUXILIARY and PRETRAINED_MODEL != "CJE")), "add auxiliary data is available only available for CJE model!"
if ADD_AUXILIARY:%run preprocess_v2.py --add_auxiliary_data True --languages "{PRETRAINED_MODEL}"
else:%run preprocess_v2.py --languages "{PRETRAINED_MODEL}"开始训练
#@markdown #STEP 4 (>=20 min)
#@markdown 开始微调模型。
#@markdown 训练时长取决于你录入/上传的音频总数。#@markdown 根据声线和样本质量的不同,所需的训练epochs数也不同。#@markdown 你也可以在Tensorboard中预览合成效果,若效果满意可提前停止。#@markdown Model fine-tuning
#@markdown Total time cost depends on the number of voices you recorded/uploaded.#@markdown Best epoch number varies depending on different uploaded voices / sample quality.#@markdown You can also preview synthezied audio in Tensorboard, it's OK to shut down training manually if you find the quality is satisfying.
import os
os.environ['TENSORBOARD_BINARY'] = '/usr/local/bin/tensorboard'if os.path.exists("/content/drive/MyDrive/"):!python scripts/rearrange_speaker.py!cp ./finetune_speaker.json ../drive/MyDrive/finetune_speaker.json!cp ./moegoe_config.json ../drive/MyDrive/moegoe_config.json%reload_ext tensorboard
%tensorboard --logdir "./OUTPUT_MODEL"
Maximum_epochs = "200" #@param {type:"string"}
#@markdown 继续之前的模型训练/Continue training from previous checkpoint
CONTINUE = True #@param {type:"boolean"}
if CONTINUE:!python finetune_speaker_v2.py -m "./OUTPUT_MODEL" --max_epochs "{Maximum_epochs}" --drop_speaker_embed False --cont True
else:!python finetune_speaker_v2.py -m "./OUTPUT_MODEL" --max_epochs "{Maximum_epochs}" --drop_speaker_embed True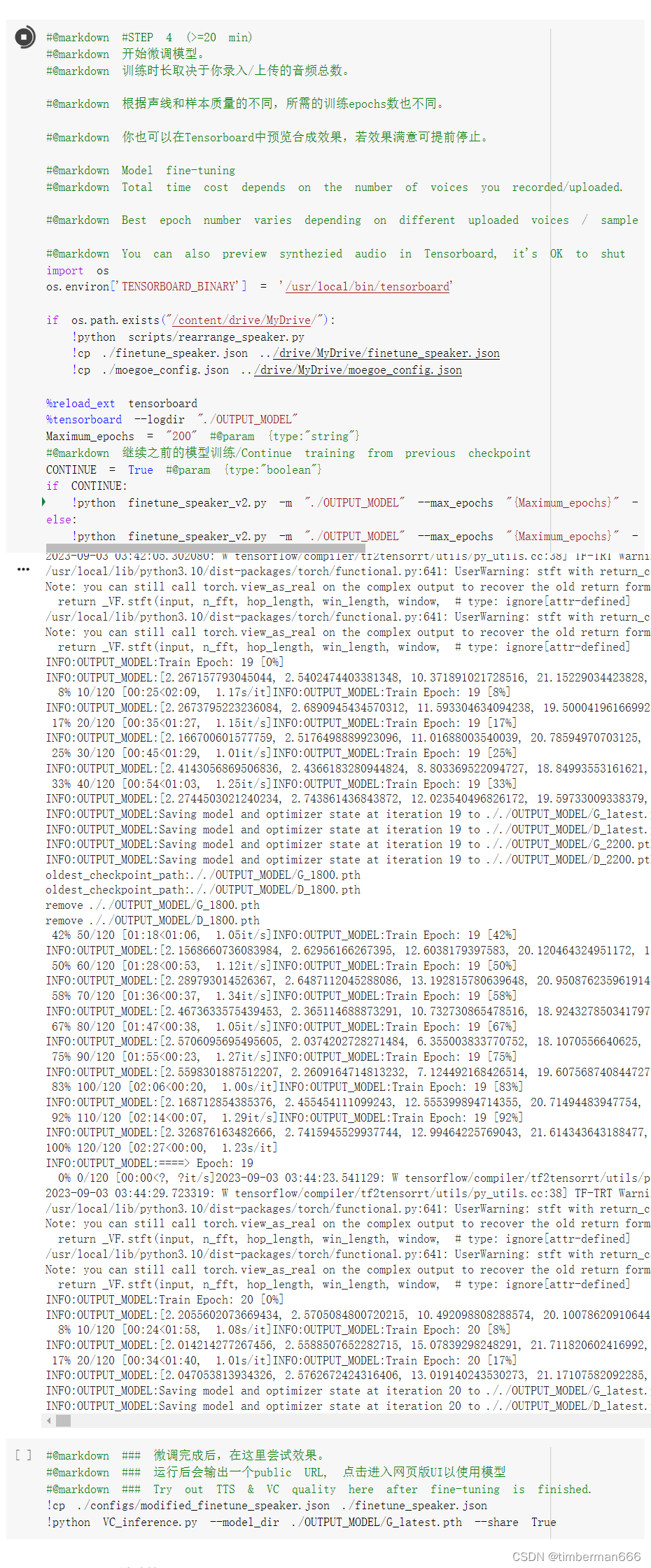
微调完成后,在这里尝试效果
#@markdown ### 微调完成后,在这里尝试效果。
#@markdown ### 运行后会输出一个public URL, 点击进入网页版UI以使用模型
#@markdown ### Try out TTS & VC quality here after fine-tuning is finished.
!cp ./configs/modified_finetune_speaker.json ./finetune_speaker.json
!python VC_inference.py --model_dir ./OUTPUT_MODEL/G_latest.pth --share True
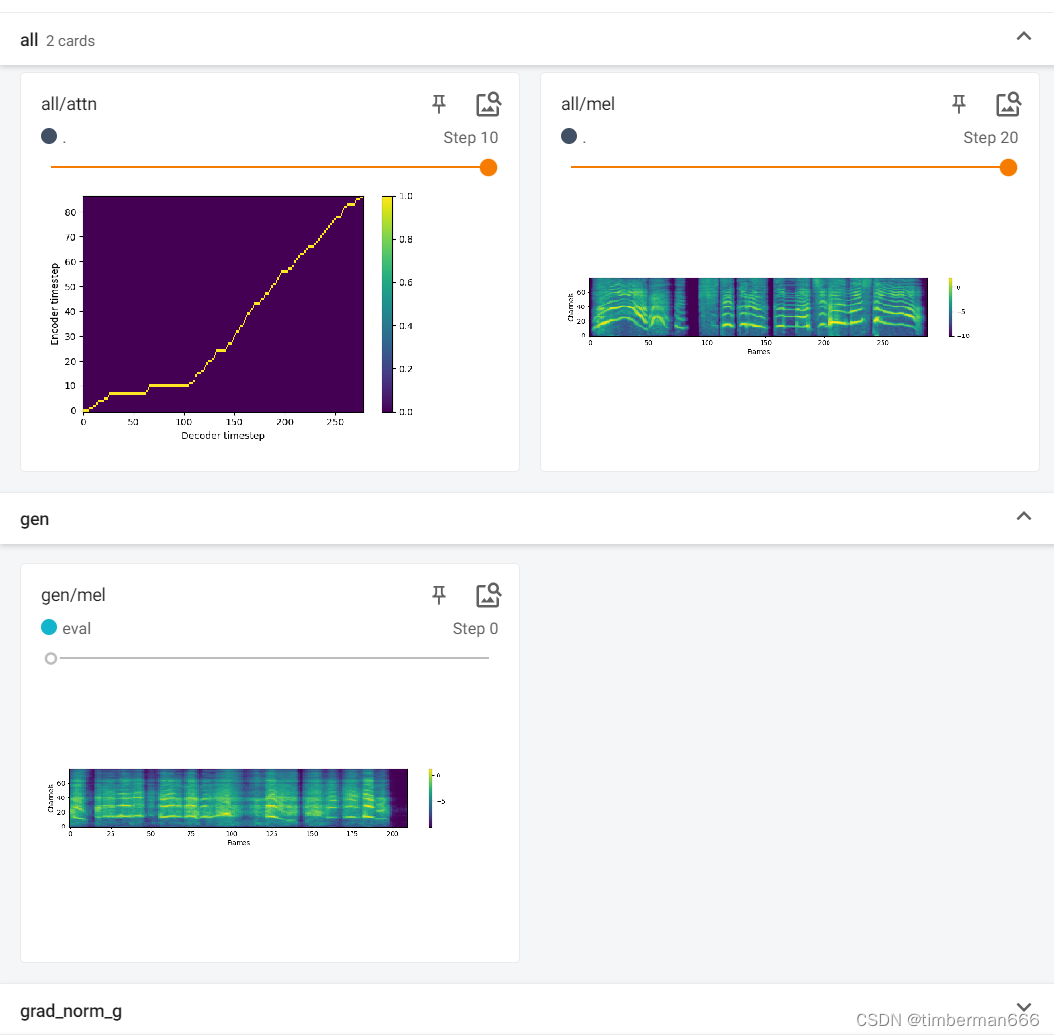
下载模型
#@markdown ### 浏览器自动下载模型和配置文件
#@markdown ### Download option 1: Running this codeblock will download model & config files by your browser.
!python scripts/rearrange_speaker.py
%run scripts/download_model.py模型演示
Text-to-Speech
text_to_speech
Voice Conversion
Voice Conversion
相关文章:

Google colab部署VITS——零门槛快速克隆任意角色声音
目录 序言 查看GPU配置 复制代码库并安装运行环境 选择预训练模型 上传视频链接(单个不应长于20分钟) 自动处理所有上传的数据 训练质量相关:实验发现目前使用CJ模型勾选ADD_AUXILIARY,对于中/日均能训练出最好的效果&#x…...

14 | Spark SQL 的 DataFrame API 读取CSV 操作
sales.csv 内容 date,category,product,full_name,sales 2023-01-01,Electronics,Laptop,John Smith,1200.0 2023-01-02,Electronics,Smartphone,Jane Doe,800.0 2023-01-03,Books,Novel,Michael Johnson,15.0 2023-01-04,Electronics,Tablet,Emily Wilson,450.0 2023-01-05,B…...
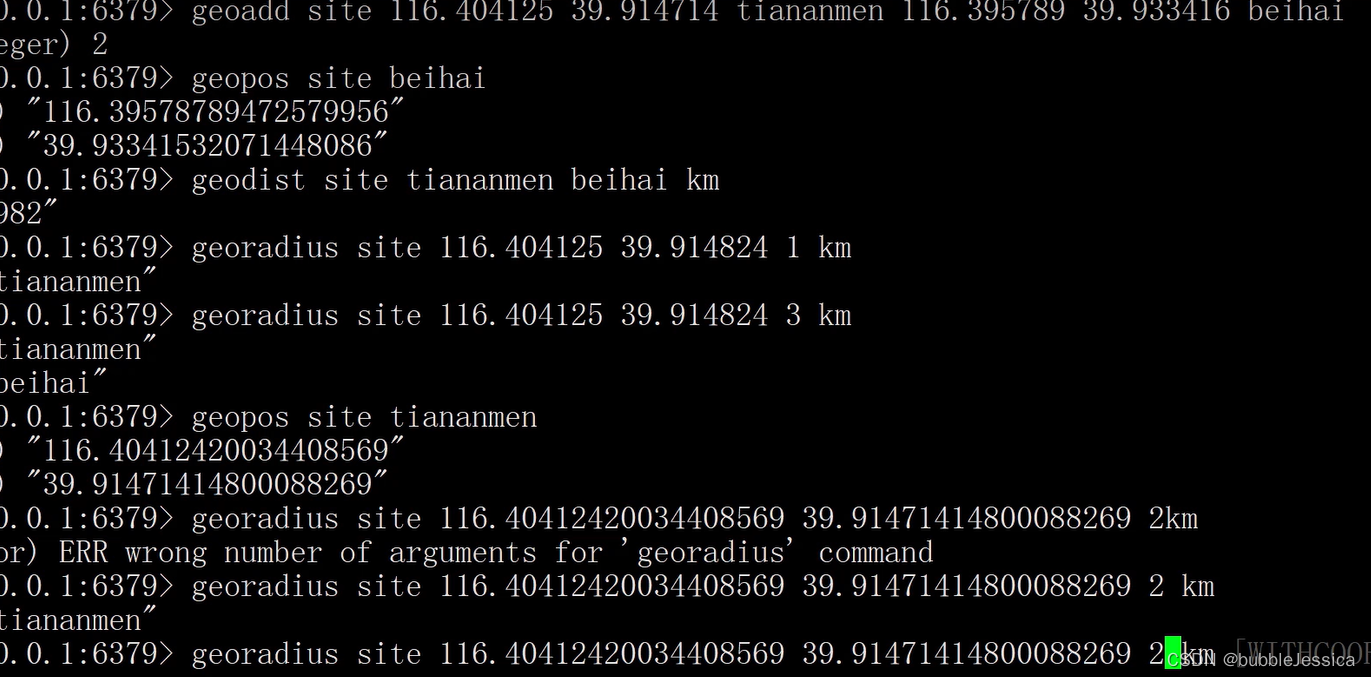
redis面试题二
redis如何处理已过期的元素 常见的过期策略 定时删除:给每个键值设置一个定时删除的事件,比如有一个key值今天5点过期,那么设置一个事件5点钟去执行,把它数据给删除掉(优点:可以及时利用内存及时清除无效数…...
和增强现实(AR))
虚拟现实(VR)和增强现实(AR)
虚拟现实(Virtual Reality,VR)和增强现实(Augmented Reality,AR)是两种前沿的计算机技术,它们正在改变人们与数字世界的互动方式。虚拟现实创造了一个计算机生成的全新虚拟环境,而增…...

如何使用ChatGPT提词器,看看这篇文章
ChatGPT提词器是一种强大的自然语言处理工具,可以帮助你提高创造性写作的效率和质量。本教程将向您介绍如何使用ChatGPT提词器,以获得有趣、吸引人的文章、故事或其他文本内容。 步骤1:访问ChatGPT提词器 首先,确保您已经访问了…...
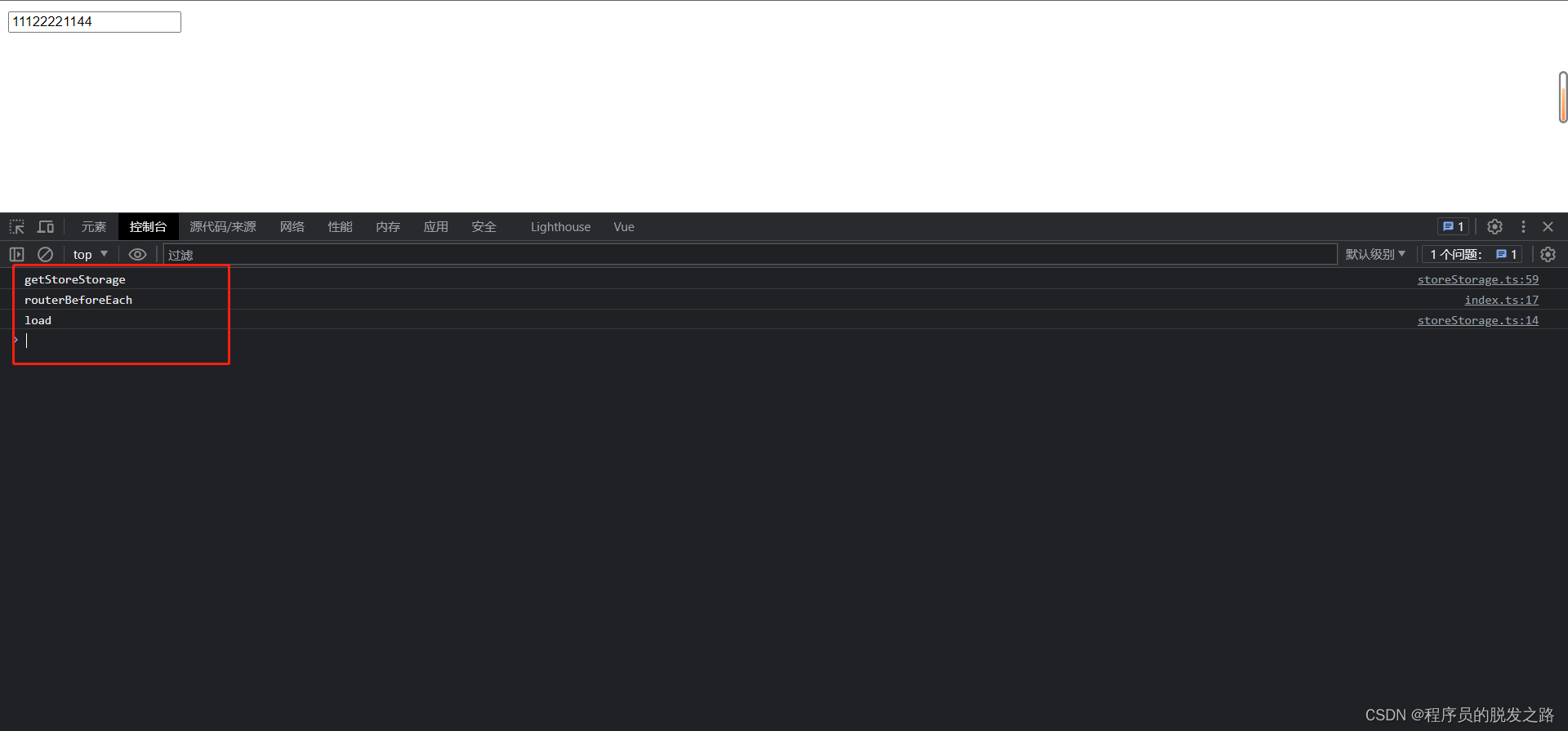
vue3-vuex持久化实现
vue3-vuex持久化实现 一、背景描述二、实现思路1.定义数据结构2.存值3.取值4.清空 三、具体代码1.定义插件2.使用插件 四、最终效果 一、背景描述 有时候我们可能需要在vuex中存储一些静态数据,比如一些下拉选项的字典数据。这种数据基本很少会变化,所以…...

详解 SpringMVC 的 @RequestMapping 注解
文章目录 1、RequestMapping注解的功能2、RequestMapping注解的位置3、RequestMapping注解的value属性4、RequestMapping注解的method属性5、RequestMapping注解的params属性(了解)6、RequestMapping注解的headers属性(了解)7、Sp…...

类的静态成员变量 static member
C自学精简教程 目录(必读) 类的静态成员 static member 变量全局只有一份副本,不会随着类对象的创建而产生副本。 static 静态成员 在类的成员变量前面增加static关键字,表示这个成员变量是类的静态成员变量。 #include <iostream> using name…...
 搭建环境 运行dtu数据集重建 实操教程(图文并茂、超详细))
MVSNet (pytorch版) 搭建环境 运行dtu数据集重建 实操教程(图文并茂、超详细)
文章目录 1 准备工作1.1 下载源码1.2 测试集下载2 配置环境3 dtu数据集 重建演示3.1 重建效果查看4 补充解释4.1 bash 脚本文件超参数解释4.2 lists/dtu解释5 Meshlab查看三维点云时 ,使用技巧总结1 Meshlab查看三维点云时 ,换背景颜色2 Meshlab查看三维点云时,点云颜色很暗…...
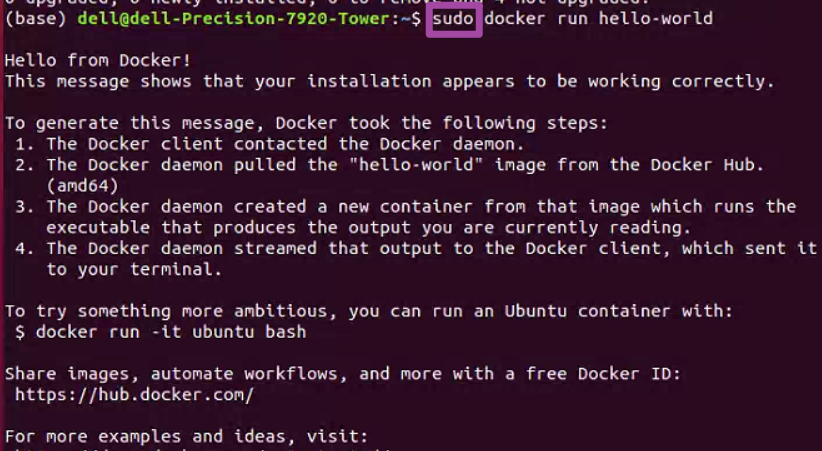
Linux系统Ubuntu以非root用户身份操作Docker的方法
本文介绍在Linux操作系统Ubuntu版本中,通过配置,实现以非root用户身份,进行Docker各项操作的具体方法。 在文章Linux系统Ubuntu配置Docker详细流程(https://blog.csdn.net/zhebushibiaoshifu/article/details/132612560࿰…...
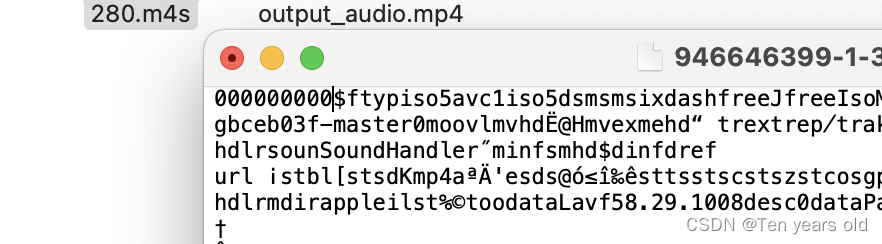
m4s格式转换mp4
先安装 ffmpeg,具体从官网可以查到,https://ffmpeg.org,按流程走。 转换代码如下,可以任意选择格式导出 import subprocess import osdef merge_audio_video(input_audio_path, input_video_path, output_mp4_path):# 构建 FFmpe…...
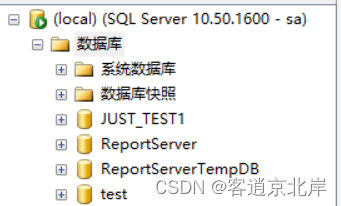
SQL sever中库管理
目录 一、创建数据库 1.1库界面方式 1.2SQL命令方式 二、修改数据库 2.1库界面方式 2.2SQL命令方式 三、删除数据库 3.1库界面方式 3.2SQL命令方式 四、附加和分离数据库 4.1附加和分离数据库概述 4.2作用 4.3附加和分离数据库方法 4.4示例 一、创建数据库 1.1库…...

模板方法模式简介
概念: 模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。该模式通过在抽象类中定义一个模板方法来控制算法的流程,并使用具体方法来实现其中的某些步骤。 特点: 定义了一个算…...
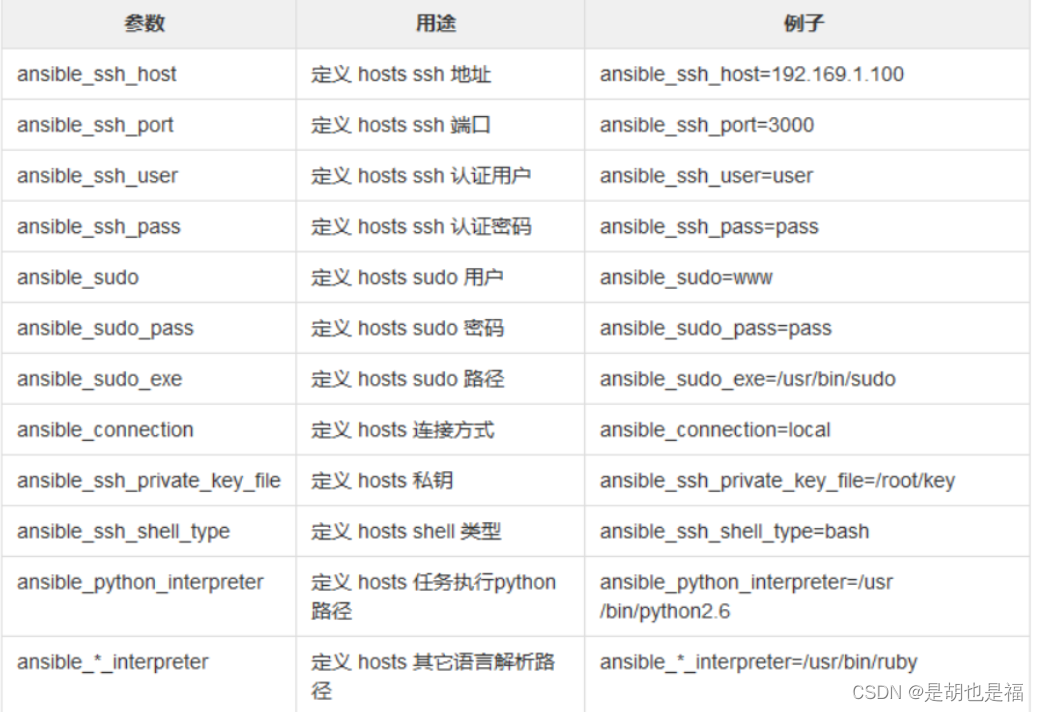
自动化运维工具-------Ansible(超详细)
一、Ansible相关 1、简介 Ansible是自动化运维工具,基于Python开发,分布式,无需客户端,轻量级,实现了批量系统配置、批量程序部署、批量运行命令等功能,ansible是基于模块工作的,本身没有批量部署的能力。真正具有批量部署的是a…...

计算机毕设 基于生成对抗网络的照片上色动态算法设计与实现 - 深度学习 opencv python
文章目录 1 前言1 课题背景2 GAN(生成对抗网络)2.1 简介2.2 基本原理 3 DeOldify 框架4 First Order Motion Model5 最后 1 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要…...

Citespace、vosviewer、R语言的文献计量学 、SCI
文献计量学是指用数学和统计学的方法,定量地分析一切知识载体的交叉科学。它是集数学、统计学、文献学为一体,注重量化的综合性知识体系。特别是,信息可视化技术手段和方法的运用,可直观的展示主题的研究发展历程、研究现状、研究…...
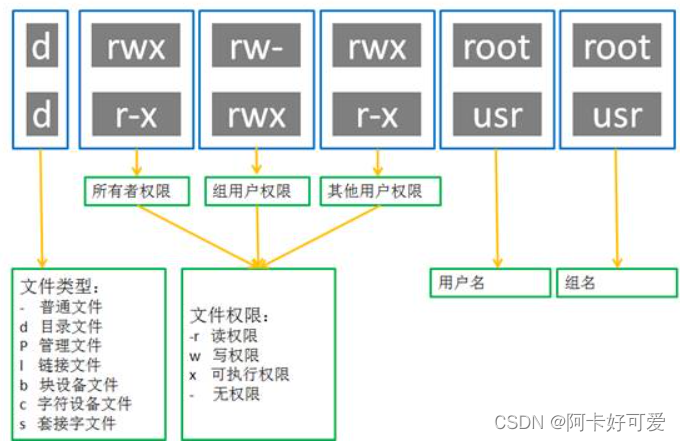
linux操作系统的权限的深入学习
1.Linux权限的概念 Linux下有两种用户:超级用户(root)、普通用户。 超级用户:可以再linux系统下做任何事情,不受限制 普通用户:在linux下做有限的事情。 超级用户的命令提示符是“#”,普通用户…...
)
LeetCode——三数之和(中等)
题目 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元组。 …...
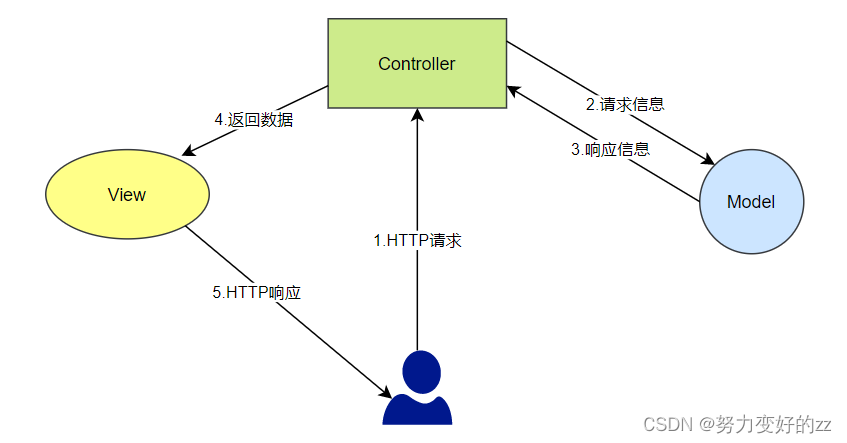
SpringMVC使用
文章目录 一.MVC基础概念1.MVC定义2.SpringMVC和MVC的关系 二.SpringMVC的使用1.RequestMapping2.获取参数1.获取单个参数2.传递对象3.后端参数重命名(后端参数映射)4.获取URL中参数PathVariable5.上传文件RequestPart6.获取Cookie/Session/header 3.返回…...

【css】css奇数、偶数、指定数选择器:
文章目录 一、简单数字序号写法:nth-child(number)二、倍数写法:nth-child(an)三、倍数分组匹配:nth-child(anb) 与 :nth-child(an-b)四、反向倍数分组匹配:nth-child(-anb)五、奇偶匹配:nth-child(odd) 与 :nth-child(even) :nth-child(n) 选择器匹配属于其父元素的第 N 个子元…...

免费AI搜索工具怎么选?2026年实测TOP8工具性能、响应速度与隐私合规性深度评测
更多请点击: https://codechina.net 第一章:免费AI搜索工具推荐2026 2026年,开源与社区驱动的AI搜索工具生态迎来爆发式增长。得益于大语言模型轻量化部署、RAG(检索增强生成)架构普及以及WebAssembly在浏览器端的成熟…...

ViGEmBus虚拟手柄驱动深度解析与实战指南
ViGEmBus虚拟手柄驱动深度解析与实战指南 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的困境:手头有一款独特的游戏控制…...

从0到1搭建AI Agent测试平台:Kubernetes+Ray+Prometheus+自研TraceDiff引擎,支撑日均50万次多模态交互验证
更多请点击: https://intelliparadigm.com 第一章:从0到1搭建AI Agent测试平台:KubernetesRayPrometheus自研TraceDiff引擎,支撑日均50万次多模态交互验证 为应对多模态AI Agent在真实业务场景中产生的高并发、异构轨迹与语义漂移…...

Android Framework 1
Android Framework 1环境准备Ubuntu 环境配置下载安卓源码编译源码Android Studio 环境编译环境准备 VMware WorkStation Pro 17.6.4 Ubuntu 20.04 安卓源码官方地址 Ubuntu 环境配置 1.安装必须的软件包 sudo apt-get install git-core gnupg flex bison build-essential …...
)
AI Agent培训赋能金融/医疗/制造三大赛道(附2023真实训战数据与客户增效曲线)
更多请点击: https://intelliparadigm.com 第一章:AI Agent培训赋能产业变革的底层逻辑 AI Agent并非传统意义上的自动化脚本,而是具备目标理解、环境感知、规划推理与工具调用能力的智能体。其产业赋能的底层逻辑,在于将人类专家…...
)
“AI点单员”真的能替代人工吗?——基于237家门店AB测试的转化率、客单价、复购率三重数据验证(含原始数据集索引)
更多请点击: https://kaifayun.com 第一章:AI Agent餐饮行业应用 AI Agent正以前所未有的深度融入餐饮行业全链路,从智能点餐、后厨协同到供应链优化与顾客情感分析,其核心价值在于将静态规则系统升级为具备感知、推理与自主决策…...

宇树造的“阿凡达”机甲,掀翻具身智能行业的桌子
作者:Evin编辑:刘致呈审核:徐徐出品:互联网江湖宇树GD01载人变形机甲火了。上次机器人这么火,还是马年春晚。到今天,上马年春晚的几家具身智能厂商中,银河通用的官网首页,依然有马年…...

在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js后端服务中集成Taotoken,调用多模型API完成内容生成 将大模型能力集成到后端服务是现代应用开发的常见需求。…...

医疗可穿戴跨界创新:从连续监测到专业检测的硬件设计实践
1. 项目概述:当可穿戴设备“走出”身体这几年,医疗可穿戴设备已经不是什么新鲜词了。从最初只能计步的手环,到如今能监测心率、血氧、心电图甚至血糖趋势的智能手表,它们正变得越来越“贴身”,也越来越“懂”我们的身体…...

三步搞定Windows和Office永久激活:KMS智能激活终极指南
三步搞定Windows和Office永久激活:KMS智能激活终极指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成只…...