hadoop学习:mapreduce入门案例四:partitioner 和 combiner
先简单介绍一下partitioner 和 combiner
Partitioner类
- 用于在Map端对key进行分区
- 默认使用的是HashPartitioner
- 获取key的哈希值
- 使用key的哈希值对Reduce任务数求模
- 决定每条记录应该送到哪个Reducer处理
- 默认使用的是HashPartitioner
- 自定义Partitioner
- 继承抽象类Partitioner,重写getPartition方法
- job.setPartitionerClass(MyPartitioner.class)
Combiner类
- Combiner相当于本地化的Reduce操作
- 在shuffle之前进行本地聚合
- 用于性能优化,可选项
- 输入和输出类型一致
- Reducer可以被用作Combiner的条件
- 符合交换律和结合律
- 实现Combiner
- job.setCombinerClass(WCReducer.class)
我们进入案例来看这两个知识点
一 案例需求
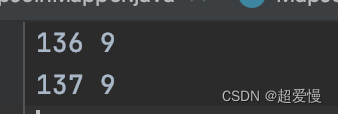
一个存放电话号码的文本,我们需要136 137,138 139和其它开头的号码分开存放统计其每个数字开头的号码个数
二 PhoneMapper 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class PhoneMapper extends Mapper<LongWritable, Text,Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String phone = value.toString();Text text = new Text(phone);IntWritable intWritable = new IntWritable(1);context.write(text,intWritable);}
}
三 PhoneReducer 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class PhoneReducer extends Reducer<Text, IntWritable,Text,IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for (IntWritable intWritable : values){count += intWritable.get();}context.write(key, new IntWritable(count));}
}
四 PhonePartitioner 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class PhonePartitioner extends Partitioner<Text, IntWritable> {@Overridepublic int getPartition(Text text, IntWritable intWritable, int i) {//136,137 138,139 其它号码放一起if("136".equals(text.toString().substring(0,3)) || "137".equals(text.toString().substring(0,3))){return 0;}else if ("138".equals(text.toString().substring(0,3)) || "139".equals(text.toString().substring(0,3))){return 1;}else {return 2;}}
}
五 PhoneCombiner 类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class PhoneCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for(IntWritable intWritable : values){count += intWritable.get();}context.write(new Text(key.toString().substring(0,3)), new IntWritable(count));}
}
六 PhoneDriver 类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class PhoneDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(PhoneDriver.class);job.setMapperClass(PhoneMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setCombinerClass(PhoneCombiner.class);job.setPartitionerClass(PhonePartitioner.class);job.setNumReduceTasks(3);job.setReducerClass(PhoneReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);Path inPath = new Path("in/demo4/phone.csv");FileInputFormat.setInputPaths(job, inPath);Path outPath = new Path("out/out6");FileSystem fs = FileSystem.get(outPath.toUri(),conf);if (fs.exists(outPath)){fs.delete(outPath, true);}FileOutputFormat.setOutputPath(job, outPath);job.waitForCompletion(true);}
}
七 小结
该案例新知识点在于分区(partition)和结合(combine)
这次代码的流程是
driver——》mapper——》partitioner——》combiner——》reducer
map 每处理一条数据都经过一次 partitioner 分区然后存到环形缓存区中去,然后map再去处理下一条数据以此反复直至所有数据处理完成
combine 则是将环形缓存区溢出的缓存文件合并,并提前进行一次排序和计算(对每个溢出文件计算后再合并)最后将一个大的文件给到 reducer,这样大大减少了 reducer 的计算负担
相关文章:
hadoop学习:mapreduce入门案例四:partitioner 和 combiner
先简单介绍一下partitioner 和 combiner Partitioner类 用于在Map端对key进行分区 默认使用的是HashPartitioner 获取key的哈希值使用key的哈希值对Reduce任务数求模决定每条记录应该送到哪个Reducer处理自定义Partitioner 继承抽象类Partitioner,重写getPartiti…...

HTTP与SOCKS5的区别对比
在互联网世界中,服务器是一种重要的工具,可以帮助我们提高网络安全性等。今天,我们将重点关注两种常见的技术:HTTP和SOCKS5。让我们深入了解它们的工作原理、用途和优缺点,并通过Python代码示例学习如何使用它们。 HT…...

在阿里云请求发短信接口去掉证书验证
composer require alibabacloud/dysmsapi-20170525 2.0.23 cURL error 60: SSL certificate problem: unable to get local issuer certificate (see https://curl.haxx.se/libcurl/c/libcurl-errors.html) for https://dysmsapi.aliyuncs.com/?PhoneNumbers 两种方法 第一…...

k8s里pv pvc configmap
通过storageClassName 将PV 和PVC 关联起来。 [rootk8-master home]# cat /home/npm-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata:name: npm-repository-pvcnamespace: jenkins spec:accessModes:- ReadWriteManyresources:requests:storage: 50GistorageC…...

【Atcoder】 [ARC144D] AND OR Equation
题目链接 Atcoder方向 Luogu方向 题目解法 考虑满足条件 2 2 2 的形式为 a n p 0 ∑ i ∈ n p i a_np_0\sum\limits_{i\in n}p_i anp0i∈n∑pi 这是一步很巧妙的转化,神奇地利用了 & \& & 和 ∣ | ∣ 的性质,把求 a a a 的…...

python使用字典暴力解析wifi密码
前言 最近无wifi可用,搜到了很多高质量但是没有密码的WiFi,我在想应该可以用python调用常见的wifi字典包来暴力破解一下这些WiFi,也许可以成功 原理 使用pip install pywifi命令安装pywifi 使用它调用本机网卡,设置wifi加密方式,对字典包扫描密码逐个尝试 扫描失败的密码会被…...

java八股文面试[多线程]——synchronized锁升级详细流程
偏向锁 偏向锁是JDK6中的重要引进,因为HotSpot作者经过研究实践发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低,引进了偏向锁。 偏向锁是在单线程执…...

ui网页设计实训心得
ui网页设计实训心得篇一 通过这次实训对这门课程的学习,做好网页,并不是一件容易的事,它包括网页的选题、 内容采集整理、 图片的处理、 页面的排版设置、 背景及其整套网页的色调等很多东西。 所以我得出一下总结: 一、 准备资…...

论文阅读_扩散模型_DDPM
英文名称: Denoising Diffusion Probabilistic Models 中文名称: 去噪扩散概率模型 论文地址: http://arxiv.org/abs/2006.11239 代码地址1: https://github.com/hojonathanho/diffusion (论文对应代码 tensorflow) 代码地址2: https://github.com/AUTOM…...
:数据结构)
菜鸟教程《Python 3 教程》笔记(15):数据结构
菜鸟教程《Python 3 教程》笔记(15) 15 数据结构15.1 将列表当作队列使用15.2 遍历技巧 笔记带有个人侧重点,不追求面面俱到。 15 数据结构 出处: 菜鸟教程 - Python3 数据结构 15.1 将列表当作队列使用 在列表的最后添加或者弹…...

CH05_介绍重构名录
重构的记录格式 每个重构手法都有5个部分。 名称(name) 要建造一个重构词汇表,名称是很重要的。 速写(sketch) 名称之后是一个简单的速写(sketch);这部分可以帮助你更快找到你所…...
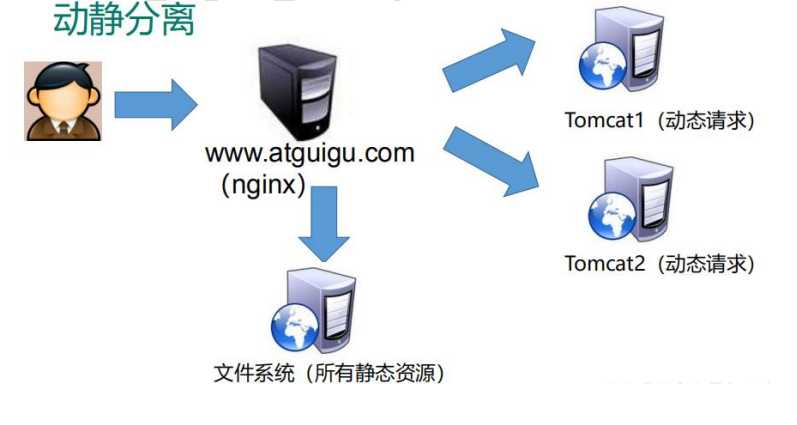
1、Nginx 简介
文章目录 1、Nginx 简介1.1 Nginx 概述1.2 Nginx 作为 web 服务器1.3 正向代理1.4 反向代理1.5 负载均衡1.6 动静分离 【尚硅谷】尚硅谷Nginx教程由浅入深 志不强者智不达;言不信者行不果。 1、Nginx 简介 1.1 Nginx 概述 Nginx (“engine x”) 是一个高性能的 HT…...

C++之——宏
宏(Macro)是一种在编程语言中使用的符号,通常用于将一段代码片段替换为另一段代码。宏在代码中起到了预处理的作用,它们在编译代码之前被处理和展开。宏通常用于简化代码、提高代码的可读性、实现代码重用以及引入编译时常量。 在…...

代码随想录打卡—day56—【编辑距离】— 9.2 编辑距离系列
1 583. 两个字符串的删除操作 583. 两个字符串的删除操作 【注意点1】感觉和下面这题很像。就是一模一样,return变一下就是。 1143. 最长公共子序列 【注意点2】注意这题和day55的最后一题的区别,本题求的是最大长度,那题求的是组合方式。…...

uni-app app端.m3u8类型流的播放
1.开发环境:HBuilderX3.8.7、uni-app、vue2.0、view2.0、uni-ui 2.实现通过web-view 嵌入H5页面,进行视频流自动播放。 注意事项: 如果只是在android端可以直接使用.flv格式的视频流; 如果App需要支持ios就可以考虑一下播放.m3u8格…...

使用proxy_pool来为爬虫程序自动更换代理IP | 开源IP代理
1. 前言 之前做爬虫的时候,经常会遇到对于一个网页,使用同一个IP多次会被禁掉IP的问题,我们可以自己手动更换代理IP再继续这个问题但多少会有点麻烦,我对于一个懒人来说,手动更换IP太麻烦,而且也不符合程序员懒惰的美德,于是便有了下面的故事。proxy_pool 是一个开源的代…...

【易售小程序项目】修改“我的”界面前端实现;查看、重新编辑、下架自己发布的商品【后端基于若依管理系统开发】
文章目录 “我的”界面修改效果界面实现界面整体代码 查看已发布商品界面效果商品数据表后端上架、下架商品ControllerMapper 界面整体代码back方法 编辑商品、商品发布、保存草稿后端商品校验方法Controller 页面整体代码 “我的”界面修改 效果 界面实现 界面的实现使用了一…...

Centos7 + Apache Ranger 2.4.0 部署
一、Ranger简介 Apache Ranger提供一个集中式安全管理框架, 并解决授权和审计。它可以对Hadoop生态的组件如HDFS、Yarn、Hive、Hbase等进行细粒度的数据访问控制。通过操作Ranger控制台,管理员可以轻松的通过配置策略来控制用户访问权限。 1、组件列表 # Service Name Liste…...
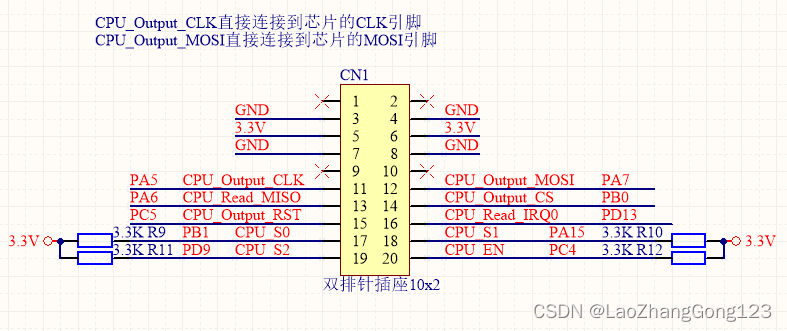
硬件SPI口扩展
在工控板设计中,经常会遇到扩展IO。具有相同的功能电路板接口相同,所以很容易采用排线方式连接到CPU主控板上,这种排线连接,我称之为总线。 现在的CPU引脚多,不扩展IO,使用模拟SPI,也可以实现&…...

【jsthree.js】全景vr看房进阶版
three小结: Scene场景 指包含了所有要渲染和呈现的三维对象、光源、相机以及其他相关元素的环境;场景可以被渲染引擎或图形库加载和处理,以生成最终的图像或动画 常见属性: scene.background new THREE.Color(0x000000); // …...

大模型MoE架构解析:参数稀疏激活与硬件协同设计
1. 这句话到底在说什么?先别急着转发,我们来拆解这个被疯传的“参数密度”说法“GPT-4 Has 1.8 Trillion Parameters. It Uses 2% of Them Per Token.”——这句话过去半年在技术社区、自媒体和AI科普帖里反复刷屏,配图常是夸张的“万亿级大脑…...

5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计
5个设计场景,Bebas Neue如何用大写字母征服现代视觉设计 【免费下载链接】Bebas-Neue Bebas Neue font 项目地址: https://gitcode.com/gh_mirrors/be/Bebas-Neue 还在为设计项目寻找一款既简洁有力又能免费商用的字体吗?Bebas Neue这款由日本设计…...

终极MQTT客户端快速入门指南:5分钟掌握跨平台物联网通信
终极MQTT客户端快速入门指南:5分钟掌握跨平台物联网通信 【免费下载链接】mqttclient A high-performance, high-stability, cross-platform MQTT client, developed based on the socket API, can be used on embedded devices (FreeRTOS / LiteOS / RT-Thread / T…...

别再手动刷新了!用HomePage v0.8.2+Docker Compose,一键监控所有容器和网站状态
别再手动刷新了!用HomePage v0.8.2Docker Compose,一键监控所有容器和网站状态 每次登录服务器都要挨个检查容器是否运行正常?网站挂了却要等用户反馈才知道?这种被动式运维早该淘汰了。今天介绍的这套方案,能让你的H…...

神经网络幻觉的本质与四层防御实战指南
1. 这不是“胡说八道”,是模型在用概率拼图——神经网络幻觉的本质与真实战场 “神经网络会幻觉”这个说法,这几年在技术社区、媒体标题甚至投资人会议里出现的频率,已经快赶上“算力瓶颈”和“数据飞轮”了。但绝大多数人听到这个词的第一反…...

医疗可穿戴跨界创新:从连续监测到专业检测的硬件设计实践
1. 项目概述:当可穿戴设备“走出”身体这几年,医疗可穿戴设备已经不是什么新鲜词了。从最初只能计步的手环,到如今能监测心率、血氧、心电图甚至血糖趋势的智能手表,它们正变得越来越“贴身”,也越来越“懂”我们的身体…...
用C++实现信奥题 P9118 [春季测试 2023] 幂次)
打卡信奥刷题(3304)用C++实现信奥题 P9118 [春季测试 2023] 幂次
P9118 [春季测试 2023] 幂次 题目描述 小 Ω 在小学数学课上学到了“幂次”的概念:∀a,b∈N\forall a, b \in \N^∀a,b∈N,定义 aba^bab 为 bbb 个 aaa 相乘。 她很好奇有多少正整数可以被表示为上述 aba^bab 的形式?由于所有正整数 m∈Nm \i…...
XUnity Auto Translator:如何用智能翻译插件打破游戏语言壁垒?
XUnity Auto Translator:如何用智能翻译插件打破游戏语言壁垒? 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否曾经因为语言障碍而错过了精彩的日本视觉小说或欧美独立游戏&…...

从‘微软 ORG’到流畅中文NLP:你的zh_core_web_sm模型真的装对了吗?
从‘微软 ORG’到流畅中文NLP:你的zh_core_web_sm模型真的装对了吗? 当你在Spacy中加载zh_core_web_sm模型,运行示例文本"微软准备用十亿美金买下这家英国的创业公司"后,看到"微软"被正确标记为ORG࿰…...

如何用MusicFree插件构建你的跨平台音乐生态:从零开始的全流程指南
如何用MusicFree插件构建你的跨平台音乐生态:从零开始的全流程指南 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 厌倦了在不同音乐应用间反复切换?MusicFree插件系统为你…...