探索图像数据中的隐藏信息:语义实体识别和关系抽取的奇妙之旅
探索图像数据中的隐藏信息:语义实体识别和关系抽取的奇妙之旅
1. 简介
1.1 背景
关键信息抽取 (Key Information Extraction, KIE)指的是是从文本或者图像中,抽取出关键的信息。针对文档图像的关键信息抽取任务作为OCR的下游任务,存在非常多的实际应用场景,如表单识别、车票信息抽取、身份证信息抽取等。然而,使用人力从这些文档图像中提取或者收集关键信息耗时费力,怎样自动化融合图像中的视觉、布局、文字等特征并完成关键信息抽取是一个价值与挑战并存的问题。
对于特定场景的文档图像,其中的关键信息位置、版式等较为固定,因此在研究早期有很多基于模板匹配的方法进行关键信息的抽取,考虑到其流程较为简单,该方法仍然被广泛应用在目前的很多场景中。但是这种基于模板匹配的方法在应用到不同的场景中时,需要耗费大量精力去调整与适配模板,迁移成本较高。
文档图像中的KIE一般包含2个子任务,示意图如下图所示。
- (1)SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
- (2)RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题 (key) 和答案 (value) 。然后对每一个问题找到对应的答案,相当于完成key-value的匹配过程。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。

1.2 基于深度学习的主流方法
一般的KIE方法基于命名实体识别(Named Entity Recognition,NER)来展开研究,但是此类方法仅使用了文本信息而忽略了位置与视觉特征信息,因此精度受限。近几年大多学者开始融合多个模态的输入信息,进行特征融合,并对多模态信息进行处理,从而提升KIE的精度。主要方法有以下几种
- (1)基于Grid的方法:此类方法主要关注图像层面多模态信息的融合,文本大多大多为字符粒度,对文本与结构结构信息的嵌入方式较为简单,如Chargrid[1]等算法。
- (2)基于Token的方法:此类方法参考NLP中的BERT等方法,将位置、视觉等特征信息共同编码到多模态模型中,并且在大规模数据集上进行预训练,从而在下游任务中,仅需要少量的标注数据便可以获得很好的效果。如LayoutLM[2], LayoutLMv2[3], LayoutXLM[4], StrucText[5]等算法。
- (3)基于GCN的方法:此类方法尝试学习图像、文字之间的结构信息,从而可以解决开集信息抽取的问题(训练集中没有见过的模板),如GCN[6]、SDMGR[7]等算法。
- (4)基于End-to-end的方法:此类方法将现有的OCR文字识别以及KIE信息抽取2个任务放在一个统一的网络中进行共同学习,并在学习过程中相互加强。如Trie[8]等算法。
更多关于该系列算法的详细介绍,请参考“动手学OCR·十讲”课程的课节六部分:文档分析理论与实践。
2. 关键信息抽取任务流程
PaddleOCR中实现了LayoutXLM等算法(基于Token),同时,在PP-StructureV2中,对LayoutXLM多模态预训练模型的网络结构进行简化,去除了其中的Visual backbone部分,设计了视觉无关的VI-LayoutXLM模型,同时引入符合人类阅读顺序的排序逻辑以及UDML知识蒸馏策略,最终同时提升了关键信息抽取模型的精度与推理速度。
下面介绍怎样基于PaddleOCR完成关键信息抽取任务。
在非End-to-end的KIE方法中,完成关键信息抽取,至少需要2个步骤:首先使用OCR模型,完成文字位置与内容的提取,然后使用KIE模型,根据图像、文字位置以及文字内容,提取出其中的关键信息。
2.1 训练OCR模型
2.1.1 文本检测
(1)数据
PaddleOCR中提供的模型大多数为通用模型,在进行文本检测的过程中,相邻文本行的检测一般是根据位置的远近进行区分,如上图,使用PP-OCRv3通用中英文检测模型进行文本检测时,容易将”民族“与“汉”这2个代表不同的字段检测到一起,从而增加后续KIE任务的难度。因此建议在做KIE任务的过程中,首先训练一个针对该文档数据集的检测模型。
在数据标注时,关键信息的标注需要隔开,比上图中的 “民族汉” 3个字相隔较近,此时需要将”民族“与”汉“标注为2个文本检测框,否则会增加后续KIE任务的难度。
对于下游任务,一般来说,200~300张的文本训练数据即可保证基本的训练效果,如果没有太多的先验知识,可以先标注 200~300 张图片,进行后续文本检测模型的训练。
(2)模型
在模型选择方面,推荐使用PP-OCRv3_det,关于更多关于检测模型的训练方法介绍,请参考:OCR文本检测模型训练教程与PP-OCRv3 文本检测模型训练教程。
2.1.2 文本识别
相对自然场景,文档图像中的文本内容识别难度一般相对较低(背景相对不太复杂),因此优先建议尝试PaddleOCR中提供的PP-OCRv3通用文本识别模型(PP-OCRv3模型库链接)。
(1)数据
然而,在部分文档场景中也会存在一些挑战,如身份证场景中存在着罕见字,在发票等场景中的字体比较特殊,这些问题都会增加文本识别的难度,此时如果希望保证或者进一步提升模型的精度,建议基于特定文档场景的文本识别数据集,加载PP-OCRv3模型进行微调。
在模型微调的过程中,建议准备至少5000张垂类场景的文本识别图像,可以保证基本的模型微调效果。如果希望提升模型的精度与泛化能力,可以合成更多与该场景类似的文本识别数据,从公开数据集中收集通用真实文本识别数据,一并添加到该场景的文本识别训练任务过程中。在训练过程中,建议每个epoch的真实垂类数据、合成数据、通用数据比例在1:1:1左右,这可以通过设置不同数据源的采样比例进行控制。如有3个训练文本文件,分别包含1W、2W、5W条数据,那么可以在配置文件中设置数据如下:
Train:dataset:name: SimpleDataSetdata_dir: ./train_data/label_file_list:- ./train_data/train_list_1W.txt- ./train_data/train_list_2W.txt- ./train_data/train_list_5W.txtratio_list: [1.0, 0.5, 0.2]...
(2)模型
在模型选择方面,推荐使用通用中英文文本识别模型PP-OCRv3_rec,关于更多关于文本识别模型的训练方法介绍,请参考:OCR文本识别模型训练教程与PP-OCRv3文本识别模型库与配置文件。
2.2 训练KIE模型
对于识别得到的文字进行关键信息抽取,有2种主要的方法。
(1)直接使用SER,获取关键信息的类别:如身份证场景中,将“姓名“与”张三“分别标记为name_key与name_value。最终识别得到的类别为name_value对应的文本字段即为我们所需要的关键信息。
(2)联合SER与RE进行使用:这种方法中,首先使用SER,获取图像文字内容中所有的key与value,然后使用RE方法,对所有的key与value进行配对,找到映射关系,从而完成关键信息的抽取。
2.2.1 SER
以身份证场景为例, 关键信息一般包含姓名、性别、民族等,我们直接将对应的字段标注为特定的类别即可,如下图所示。

注意:
- 标注过程中,对于无关于KIE关键信息的文本内容,均需要将其标注为
other类别,相当于背景信息。如在身份证场景中,如果我们不关注性别信息,那么可以将“性别”与“男”这2个字段的类别均标注为other。 - 标注过程中,需要以文本行为单位进行标注,无需标注单个字符的位置信息。
数据量方面,一般来说,对于比较固定的场景,50张左右的训练图片即可达到可以接受的效果,可以使用PPOCRLabel完成KIE的标注过程。
模型方面,推荐使用PP-StructureV2中提出的VI-LayoutXLM模型,它基于LayoutXLM模型进行改进,去除其中的视觉特征提取模块,在精度基本无损的情况下,进一步提升了模型推理速度。更多教程请参考:VI-LayoutXLM算法介绍与KIE关键信息抽取使用教程。
2.2.2 SER + RE
该过程主要包含SER与RE 2个过程。SER阶段主要用于识别出文档图像中的所有key与value,RE阶段主要用于对所有的key与value进行匹配。
以身份证场景为例, 关键信息一般包含姓名、性别、民族等关键信息,在SER阶段,我们需要识别所有的question (key) 与answer (value) 。标注如下所示。每个字段的类别信息(label字段)可以是question、answer或者other(与待抽取的关键信息无关的字段)

在RE阶段,需要标注每个字段的的id与连接信息,如下图所示。

每个文本行字段中,需要添加id与linking字段信息,id记录该文本行的唯一标识,同一张图片中的不同文本内容不能重复,linking是一个列表,记录了不同文本之间的连接信息。如字段“出生”的id为0,字段“1996年1月11日”的id为1,那么它们均有[[0, 1]]的linking标注,表示该id=0与id=1的字段构成key-value的关系(姓名、性别等字段类似,此处不再一一赘述)。
注意:
- 标注过程中,如果value是多个字符,那么linking中可以新增一个key-value对,如
[[0, 1], [0, 2]]
数据量方面,一般来说,对于比较固定的场景,50张左右的训练图片即可达到可以接受的效果,可以使用PPOCRLabel完成KIE的标注过程。
模型方面,推荐使用PP-StructureV2中提出的VI-LayoutXLM模型,它基于LayoutXLM模型进行改进,去除其中的视觉特征提取模块,在精度基本无损的情况下,进一步提升了模型推理速度。更多教程请参考:VI-LayoutXLM算法介绍与KIE关键信息抽取使用教程。
3. 参考文献
[1] Katti A R, Reisswig C, Guder C, et al. Chargrid: Towards understanding 2d documents[J]. arXiv preprint arXiv:1809.08799, 2018.
[2] Xu Y, Li M, Cui L, et al. Layoutlm: Pre-training of text and layout for document image understanding[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1192-1200.
[3] Xu Y, Xu Y, Lv T, et al. LayoutLMv2: Multi-modal pre-training for visually-rich document understanding[J]. arXiv preprint arXiv:2012.14740, 2020.
[4]: Xu Y, Lv T, Cui L, et al. Layoutxlm: Multimodal pre-training for multilingual visually-rich document understanding[J]. arXiv preprint arXiv:2104.08836, 2021.
[5] Li Y, Qian Y, Yu Y, et al. StrucTexT: Structured Text Understanding with Multi-Modal Transformers[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 1912-1920.
[6] Liu X, Gao F, Zhang Q, et al. Graph convolution for multimodal information extraction from visually rich documents[J]. arXiv preprint arXiv:1903.11279, 2019.
[7] Sun H, Kuang Z, Yue X, et al. Spatial Dual-Modality Graph Reasoning for Key Information Extraction[J]. arXiv preprint arXiv:2103.14470, 2021.
[8] Zhang P, Xu Y, Cheng Z, et al. Trie: End-to-end text reading and information extraction for document understanding[C]//Proceedings of the 28th ACM International Conference on Multimedia. 2020: 1413-1422.
参考链接
https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.7
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

相关文章:
探索图像数据中的隐藏信息:语义实体识别和关系抽取的奇妙之旅
探索图像数据中的隐藏信息:语义实体识别和关系抽取的奇妙之旅 1. 简介 1.1 背景 关键信息抽取 (Key Information Extraction, KIE)指的是是从文本或者图像中,抽取出关键的信息。针对文档图像的关键信息抽取任务作为OCR的下游任务,存在非常…...

Gradle问题处理
目录 一、依赖搜索问题1.1 、Gradle不在本地 Maven 存储库中进行搜索一、依赖搜索问题 1.1 、Gradle不在本地 Maven 存储库中进行搜索 场景 build.gradle文件: buildscript {repositories {mavenLocal()google()mavenCentral()}dependencies...

架构:C4 Model
概念 C4说穿了就是几个要素:关系——带箭头的线、元素——方块和角色、关系描述——线上的文字、元素的描述——方块和角色里的文字、元素的标记——方块和角色的颜色、虚线框(在C4里面虚线框的表达力被极大的限制了,我觉得可以给虚线框更大…...

数据结构学习系列之顺序表的两种修改方式
方式1:根据顺序表中数据元素的位置进行修改,代码如下:示例代码: int modify_seq_list_1(list_t *seq_list,int pos, int data){if(NULL seq_list){printf("入参为NULL\n");return -1;}if( pos < 0 || pos > seq…...

React:props说明
props是只读对象(readonly) 根据单项数据流的要求,子组件只能读取props中的数据,不能进行修改props可以传递任意数据 数字、字符串、布尔值、数组、对象、函数、JSX import FileUpdate from ./FileUpdate; export default class …...
Can‘t connect to local MySQL server through socket ‘/tmp/mysql.sock‘
最近在用django框架开发后端时,在运行 $python manage.py makemigrations 命令时,报了以上错误,错误显示连接mysql数据库失败,查看了mysql数据库初始化配置文件my.cnf,我的mysql.sock文件存放路径配置在了/usr/local…...

C++的单例模式
忘记之前有没有写过单例模式了。 再记录一下: 我使用的代码: #ifndef SINGLETON_MACRO_HPP #define SINGLETON_MACRO_HPP#define SINGLETON_DECL(class_name) \ public: \static class_name& instance() { \static class_name s_instance; \return …...

Spring Boot 中 Nacos 配置中心使用实战
官方参考文档 https://nacos.io/zh-cn/docs/quick-start-spring-boot.html 本人实践 1、新建一个spring boot项目 我的spirngboot版本为2.5.6 2、添加一下依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-…...
学生管理系统VueAjax版本
学生管理系统VueAjax版本 使用Vue和Ajax对原有学生管理系统进行优化 1.准备工作 创建AjaxResult类,对Ajax回传的信息封装在对象中 package com.grg.Result;/*** Author Grg* Date 2023/8/30 8:51* PackageName:com.grg.Result* ClassName: AjaxResult* Descript…...

迭代器模式简介
概念: 迭代器模式是一种行为型设计模式,它提供了一种访问集合对象元素的方法,而无需暴露其内部表示。通过使用迭代器,可以按照特定顺序遍历集合中的元素。 特点: 将遍历和具体集合分离,使得能够独立地改…...

四方定理c++题解
题目描述 四方定理是数论中著名的一个定理,指任意一个自然数都可以拆成四个自然数的平方之和。例如: 251^22^22^24^2 对 25来说,还有其他方案: 250^20^23^24^2 以及 250^20^20^25^2 给定一个自然数 n ,请输出 n…...
ZDH-权限模块
本次介绍基于ZDH v5.1.2版本 目录 项目源码 预览地址 安装包下载地址 ZDH权限模块 ZDH权限模块-重要名词划分 ZDH权限模块-菜单管理 ZDH权限模块-角色管理 ZDH权限模块-用户配置 ZDH权限模块-权限申请 项目源码 zdh_web: GitHub - zhaoyachao/zdh_web: 大数据采集,抽…...
漏洞修复:在应用程序中发现不必要的 Http 响应头
描述 blablabla描述,一般是在返回的响应表头中出现了Server键值对,那我们要做的就是移除它,解决方案中提供了nginx的解决方案 解决方案 第一种解决方案 当前解决方案会隐藏nginx的版本号,但还是会返回nginx字样,如…...

什么是mkp勒索病毒,中了mkp勒索病毒怎么办?勒索病毒解密数据恢复
mkp勒索病毒是一种新兴的计算机木马病毒,它以加密文件的方式进行勒索,对用户的计算机安全造成了严重威胁。本文将介绍mkp勒索病毒的特征、影响以及应对措施,以便读者更好地了解和防范这种病毒。 一、mkp勒索病毒的特征 加密文件:…...

db2迁移至oracle
1.思路 (1)用java连接数据库(2)把DB2数据导出为通用的格式如csv,json等(3)导入其他数据库,比如oracle,mongodb。这个方法自由发挥的空间比较大。朋友说他会用springboot…...

webpack学习使用
...

按钮控件之2---QComboBox 复选按钮/复选框控件
1、常用函数: comboBox->addItem("cxq"); //添加下拉选项 combobox->clear(); //清空下拉项comboBox->setCurrentIndex(0);//设置当前的索引 int currentlndex(): //返回当前项的序号,第一个项的序号…...
【数据分享】2006-2021年我国省份级别的燃气相关指标(免费获取\20多项指标)
《中国城市建设统计年鉴》中细致地统计了我国城市市政公用设施建设与发展情况,在之前的文章中,我们分享过基于2006-2021年《中国城市建设统计年鉴》整理的2006—2021年我国省份级别的市政设施水平相关指标、2006-2021年我国省份级别的各类建设用地面积数…...
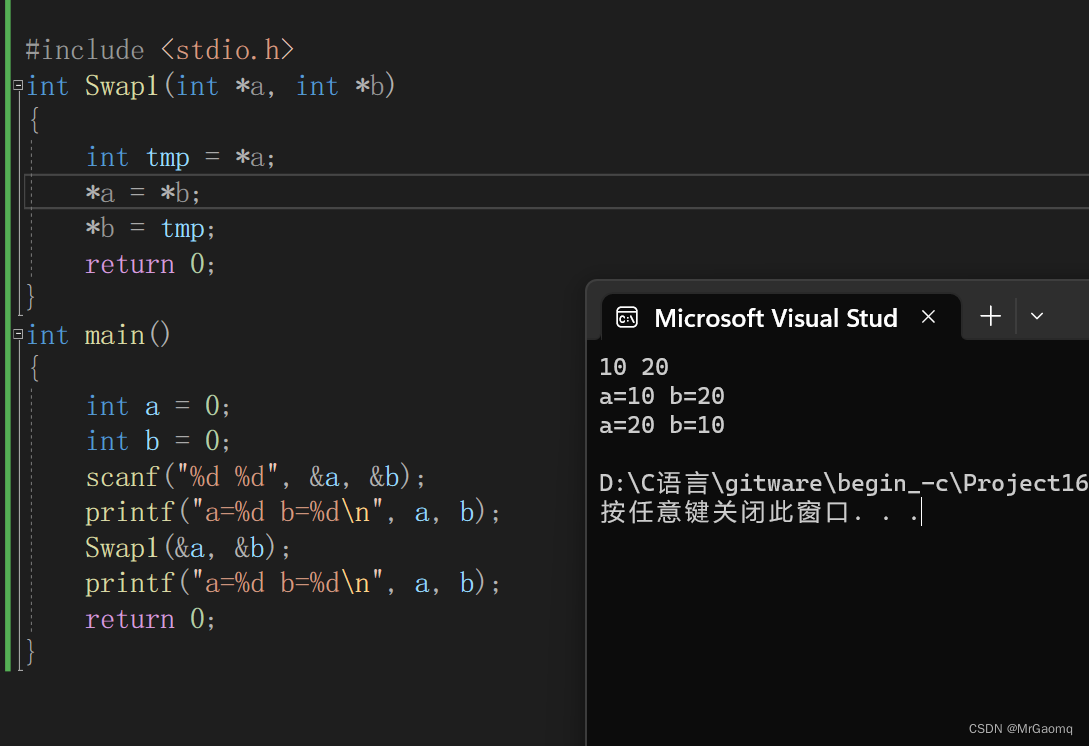
C语言深入理解指针(非常详细)(二)
目录 指针运算指针-整数指针-指针指针的关系运算 野指针野指针成因指针未初始化指针越界访问指针指向的空间释放 如何规避野指针指针初始化注意指针越界指针不使用时就用NULL避免返回局部变量的地址 assert断言指针的使用和传址调用传址调用例子(strlen函数的实现&a…...

Web3j 继承StaticStruct的类所有属性必须为Public <DynamicArray<StaticStruct>>
Web3j 继承StaticStruct的类所有属性必须为Public,属性的顺序和数量必须和solidity 里面的struct 属性相同,否则属性少了或者多了的时候会出现错位 Web3j 继承StaticStruct的类所有属性不能为private,因为web3j 是通过长度去截取返回值解析成…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...
)
DeepSeek代码风格检查避坑指南(内部审计报告首次披露:37个被忽略的合规红线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码风格检查的合规性本质与审计背景 DeepSeek代码风格检查并非单纯的技术偏好约束,而是嵌入研发治理链条中的合规性控制节点。其本质是将编程实践与组织级安全策略、行业监管要求&…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

CMSIS-DAP调试器原理与应用:以Elektor mbed interface为例
1. 项目概述:Elektor mbed interface [150554] 是什么?如果你玩过ARM Cortex-M系列的单片机,尤其是NXP LPC800系列,那你可能对“CMSIS-DAP”这个调试器标准不陌生。它是由ARM官方推出的一个开源调试接口标准,最大的好处…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...