深入理解协同过滤算法及其实现
导语
个性化推荐系统在现代数字时代扮演着重要的角色,协助用户发现他们可能感兴趣的信息、产品或媒体内容。协同过滤是个性化推荐系统中最流行和有效的算法之一。
目录
协同过滤算法的原理
基于用户的协同过滤(User-Based Collaborative Filtering)
用户相似性计算
余弦相似度
Demo
皮尔逊相关系数
Demo
近邻用户选择
相似性度量方法
用户邻居的选择
阈值过滤
个性化相似性权重
评分预测
基于项目的协同过滤(Item-Based Collaborative Filtering)
协同过滤的不同变种
数据预处理
python示例
用户-项目评分矩阵的创建
基于用户的协同过滤
基于项目的协同过滤
性能优化和扩展
协同过滤算法的原理
基于用户的协同过滤(User-Based Collaborative Filtering)
用户相似性计算
当计算用户之间的相似性时,通常使用余弦相似度和皮尔逊相关系数等度量方法
余弦相似度
余弦相似度是一种用于测量两个非零向量之间夹角的相似性度量。在协同过滤中,用户可以被视为向量,其中每个维度代表一个项目,值表示用户对该项目的评分。
余弦相似度的计算步骤如下:
- 计算两个用户向量的点积(内积)。
- 计算每个用户向量的范数(模)。
- 使用点积和范数的乘积来计算余弦相似度。
余弦相似度公式如下:

Demo
import numpy as np# 两个用户的评分向量
user1_ratings = np.array([5, 4, 0, 0, 1])
user2_ratings = np.array([0, 0, 5, 4, 2])# 计算余弦相似度
cosine_similarity = np.dot(user1_ratings, user2_ratings) / (np.linalg.norm(user1_ratings) * np.linalg.norm(user2_ratings))print(f"余弦相似度: {cosine_similarity}")
皮尔逊相关系数
皮尔逊相关系数是一种用于衡量两个变量之间线性关系强度和方向的统计度量。在协同过滤中,它被用来度量用户评分之间的相关性。
皮尔逊相关系数的计算步骤如下:
- 计算两个用户评分向量的均值。
- 计算每个用户评分向量与均值的差异。
- 计算差异的皮尔逊相关系数。
皮尔逊相关系数的公式如下:

Demo
import numpy as np# 两个用户的评分向量
user1_ratings = np.array([5, 4, 0, 0, 1])
user2_ratings = np.array([0, 0, 5, 4, 2])# 计算均值
mean_user1 = np.mean(user1_ratings)
mean_user2 = np.mean(user2_ratings)# 计算差异
diff_user1 = user1_ratings - mean_user1
diff_user2 = user2_ratings - mean_user2# 计算皮尔逊相关系数
pearson_correlation = np.sum(diff_user1 * diff_user2) / (np.sqrt(np.sum(diff_user1**2)) * np.sqrt(np.sum(diff_user2**2)))print(f"皮尔逊相关系数: {pearson_correlation}")
近邻用户选择
相似性度量方法
在选择相似用户时,首先需要定义相似性度量方法。常用的相似性度量方法包括余弦相似度、皮尔逊相关系数、Jaccard相似度等。选择合适的相似性度量方法取决于数据的性质和问题的特点。余弦相似度通常用于评分数据,而Jaccard相似度通常用于二进制数据(用户是否喜欢或点击某个项目)。
用户邻居的选择
一旦选择了相似性度量方法,接下来需要确定要选择多少个相似用户。通常,选择的相似用户数量由一个参数 k 控制,称为 "近邻数"。增加 k 可以提高覆盖范围,但可能降低准确性,因为更多的用户可能包括不太相似的用户。选择合适的 k 是一个权衡的问题,可以通过交叉验证等技术来确定。
阈值过滤
除了基于 k 的选择,还可以使用阈值过滤来选择相似用户。例如,只选择与目标用户相似度大于某个阈值的用户。这种方法可以帮助过滤掉不太相似的用户,提高推荐的准确性。阈值的选择通常需要基于实际问题和数据进行调整。
个性化相似性权重
在某些情况下,不同用户之间的相似性可能有不同的重要性。例如,某些用户可能与目标用户在特定领域或时间段内的行为更相关。因此,可以为每个相似用户分配个性化的相似性权重,以更好地反映他们的贡献。
评分预测
首先,我们需要选择一组相似用户,这些用户与目标用户在过去的行为上相似。我们可以使用之前计算的相似性度量(如余弦相似度或皮尔逊相关系数)来衡量用户之间的相似性。
一旦选择了相似用户,我们需要获取这些相似用户对于尚未评分的项目的历史评分数据。这些评分数据将用于预测目标用户的评分。
接下来,我们使用相似用户的历史评分数据来计算目标用户对于尚未评分项目的预测评分。
可以使用加权平均法或者基于加权回归的方法:

注:以下各部分不再详细展开,可在入门基础情况下自行扩展
基于项目的协同过滤(Item-Based Collaborative Filtering)
- 项目相似性计算:详细讨论如何计算项目之间的相似性,使用余弦相似度等度量。
- 近邻项目选择:深入讨论如何为目标用户找到他们已评分项目的相似项目,以生成更精准的推荐。
- 评分预测:解释如何基于这些相似项目的历史评分来生成最终的推荐。
协同过滤的不同变种
- 基于隐式反馈的协同过滤:处理隐式反馈数据,如用户浏览历史和点击记录。
- 深度学习中的协同过滤:使用深度学习模型来改进协同过滤的性能。
- 时序协同过滤:考虑时间因素来预测用户行为和兴趣的演变。
数据预处理
- 数据准备:准备用户-项目评分数据,通常以DataFrame的形式表示。
- 数据清洗:处理缺失值、异常值和重复数据,以确保数据质量。
- 数据分割:将数据集分为训练集、验证集和测试集,以进行模型训练和评估。
python示例
用户-项目评分矩阵的创建
import pandas as pd# 创建用户-项目评分矩阵
ratings = pd.DataFrame({'User1': [5, 4, 0, 0, 1],'User2': [0, 0, 5, 4, 2],'User3': [4, 5, 0, 0, 0],'User4': [0, 0, 4, 5, 0]
}, index=['Item1', 'Item2', 'Item3', 'Item4', 'Item5'])
基于用户的协同过滤
from sklearn.metrics.pairwise import cosine_similarity# 计算用户之间的相似性(余弦相似度)
user_similarity = cosine_similarity(ratings.fillna(0))# 选择目标用户和要推荐的项目
target_user = 'User1'
target_item = 'Item3'# 预测目标用户对目标项目的评分
target_user_ratings = ratings.loc[:, target_user]
similar_users = user_similarity[ratings.index == target_item]
predicted_rating = (similar_users @ target_user_ratings) / sum(similar_users[0])print(f"预测用户{target_user}对项目{target_item}的评分为: {predicted_rating[0]}")
基于项目的协同过滤
# 预测目标用户对目标项目的评分
target_item_ratings = ratings.loc[target_item, :]
similar_items = item_similarity[ratings.columns == target_item]
predicted_rating = (similar_items @ target_item_ratings) / sum(similar_items[0])print(f"预测用户{target_user}对项目{target_item}的评分为: {predicted_rating[0]}")
性能优化和扩展
在示例基础上还可以在以下方向做出优化
- 模型改进:改进协同过滤模型,包括使用加权评分、考虑时间因素等方法,以提高推荐质量。
- 大规模数据处理:处理大规模数据集,包括分布式计算和分布式存储的使用,以处理海量用户和项目的评分数据。
- 实时推荐:介绍如何将协同过滤算法应用于实时推荐系统,以满足用户的即时需求。
相关文章:
深入理解协同过滤算法及其实现
导语 个性化推荐系统在现代数字时代扮演着重要的角色,协助用户发现他们可能感兴趣的信息、产品或媒体内容。协同过滤是个性化推荐系统中最流行和有效的算法之一。 目录 协同过滤算法的原理 基于用户的协同过滤(User-Based Collaborative Filtering&am…...

力扣:随即指针138. 复制带随机指针的链表
复制带随机指针的链表 OJ链接 分析: 该题的大致题意就是有一个带随机指针的链表,复制这个链表但是不能指向原链表的节点,所以每一个节点都要复制一遍 大神思路: ps:我是学来的 上代码: struct Node* copyRandomList(s…...

【从0学习Solidity】合约入门 Hello Web3
【学习Solidity的基础】入门智能合约开发 Hello Web3 📱不写代码没饭吃上架主页 在强者的眼中,没有最好,只有更好。我们是全栈开发领域的优质创作者,同时也是阿里云专家博主。 ✨ 关注我们的主页,探索全栈开发的无限…...

awtk-ftpd 发布
1. 介绍 在嵌入式应用程序中,有时需要提供一个 FTP 服务,用于对系统的文件进行远程管理。 awtk-ftpd 实现了一个 简单的 FTP 服务。主要特色有: 小巧。约 800 行代码。可以在各种嵌入式平台运行。内存开销低。正常内存需求小于 6K。兼容 F…...
抽象轻松的C语言
#include <stdio.h> /* 预处理指令*/ /* 函数 */ int main() {int log 3.14;printf("hello word * %d\n easy", log);getchar();/* 获取键盘输入的字母,在这个程序中的作用是防止程序瞬间关闭 */return 0; } 上一篇说过,C程序是C语言的…...

【力扣每日一题01】两数之和
开了一个新专栏,用来记录自己每天刷题,并且也是为了养成每日学习这个习惯,期待坚持一年后的自己! 一、题目 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数&am…...

机器学习——手写数字识别
0、:前言 这篇文章能够帮助你从数据到模型的整个过程实现不过至于安装第三方库等基础问题,本文不涉及,因为确实不难,搜一搜一大把本此实验运行环境为jupyter,当然通过pycharm也是可行的 1、数据: 手写数字…...

【日积月累】后端刷题日志
刷题日志 说说对Java的理解JAVA中抽象类和接口之间的区别Java中的泛型 和equals()的区别八种基本数据类型与他们的包装类在一个静态方法内调用一个非静态成员为什么是非法的静态方法与实例方法有何不同重载与重写深拷贝浅拷贝面向过程与面向对象成员变量与局部变量Spring框架Sp…...

Matlab在编码中增加CRC和交织功能
定义CRC生成和检验的类(包括函数) 我们在MATLAB中定义一个类(class),包含了CRC生成函数和检验函数(囊括了常用的CRC多项式) classdef CRCpropertiesCRCbit_LenpolynomialCRCgenCRCdetendmetho…...

Css 设置从上到下的渐变色: 0到70%为yellow,然后线性地变成透明。
您可以使用 CSS 的 linear-gradient() 函数来创建从上到下的渐变色。以下是一个例子: background: linear-gradient(to bottom, yellow 0%, transparent 70%);这将从上到下创建一个渐变色,从 0% 到 70% 是黄色,然后线性地变成透明。您可以将…...

git在windows上安装
介绍git工具在windows上如何安装 git官网下载地址 1.1、下载 https://github.com/git-for-windows/git/releases/download/v2.36.0.windows.1/Git-2.36.0-64-bit.exe自行选择版本,这里我选择的是 Git-2.36.0-64-bit这个版本 1.2、安装 安装路径选择英文且不带空格…...
快速上手GIT命令,现学也能登堂入室
系列文章目录 手把手教你安装Git,萌新迈向专业的必备一步 GIT命令只会抄却不理解?看完原理才能事半功倍! 快速上手GIT命令,现学也能登堂入室 系列文章目录一、GIT HELP1. 命令文档2. 简要说明 二、配置1. 配置列表2. 增删改查3. …...
二进制安全虚拟机Protostar靶场 安装,基础知识讲解,破解STACK ZERO
简介 pwn是ctf比赛的方向之一,也是门槛最高的,学pwn前需要很多知识,这里建议先去在某宝上买一本汇编语言第四版,看完之后学一下python和c语言,python推荐看油管FreeCodeCamp的教程,c语言也是 pwn题目大部…...

python实现的一些方法,可以直接拿来用的那种
1、日期生成 很多时候我们需要批量生成日期,方法有很多,这里分享两段代码 获取过去 N 天的日期: import datetimedef get_nday_list(n):before_n_days []for i in range(1, n 1)[::-1]:before_n_days.append(str(datetime.date.today() …...

通过HTTP进行并发的数据抓取
在进行大规模数据抓取时,如何提高效率和稳定性是关键问题。本文将介绍一种可操作的方案——使用HTTP代理来实现并发的网页抓取,并帮助您加速数据抓取过程。 1. 选择合适的HTTP代理服务供应商 - 寻找信誉良好、稳定可靠且具备较快响应时间的HTTP代理服务…...
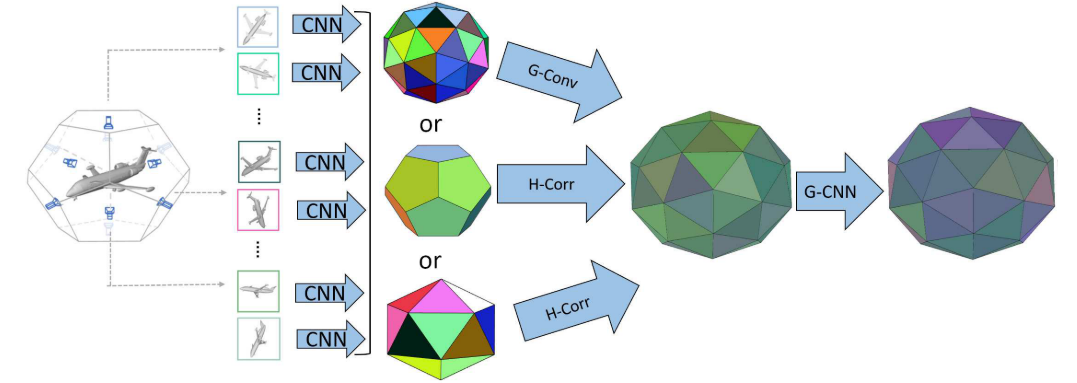
《论文阅读21》Equivariant Multi-View Networks
一、论文 研究领域:计算机视觉 | 多视角数据处理中实现等变性论文:Equivariant Multi-View Networks ICCV 2019 论文链接视频链接 二、论文简述 在计算机视觉中,模型在不同视角下对数据(例如,点云、图像等࿰…...

【数据结构】| 并查集及其优化实现
目录 一. 并查集基本概念处理过程初始化合并查询小结 二. 求并优化2.1 按大小求并2.2 按秩(高度)求并2.3 路径压缩2.4 类的实现代码2.5 复杂度分析 三. 应用LeetCode 128: 最长连续数列LeetCode 547: 省份数量LeetCode 200: 岛屿数量 一. 并查集基本概念 以一个直观的问题来引入…...
最新ChatGPT程序源码+AI系统+详细图文部署教程/支持GPT4.0/支持Midjourney绘画/Prompt知识库
一、AI系统 如何搭建部署人工智能源码、AI创作系统、ChatGPT系统呢?小编这里写一个详细图文教程吧!SparkAi使用Nestjs和Vue3框架技术,持续集成AI能力到AIGC系统! 1.1 程序核心功能 程序已支持ChatGPT3.5/GPT-4提问、AI绘画、Mi…...
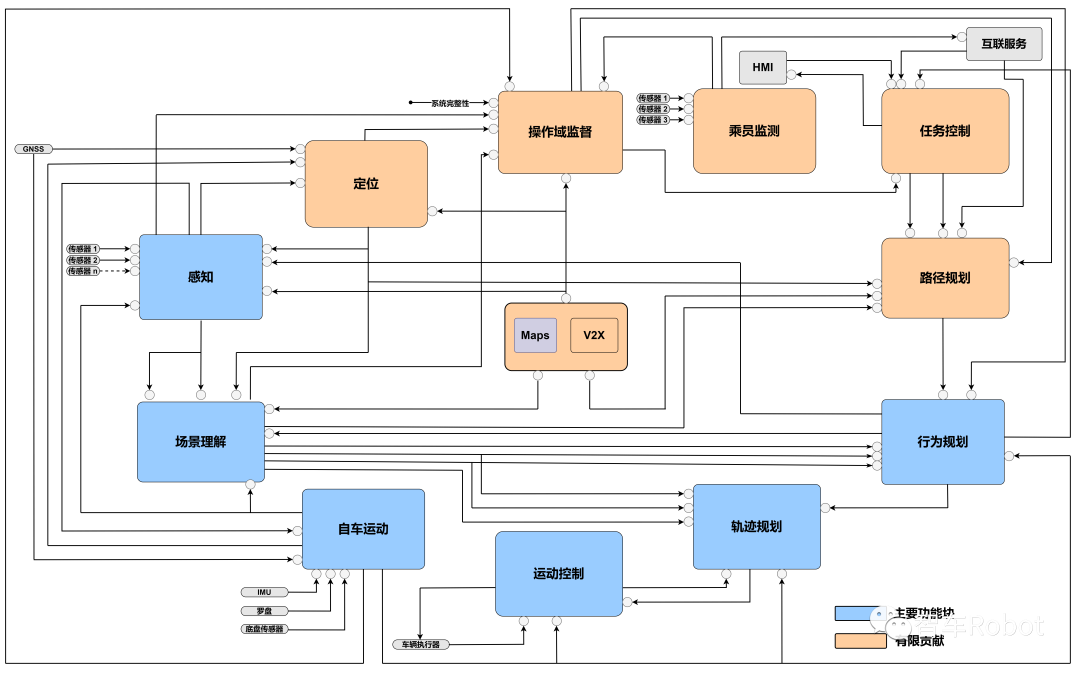
自动驾驶和辅助驾驶系统的概念性架构(一)
摘要: 本文主要介绍包括功能模块图,涵盖了底层计算单元、示例工作负载和行业标准。 前言 本文档参考自动驾驶计算联盟(Autonomous Vehicle Computing Consortium)关于自动驾驶和辅助驾驶计算系统的概念系统架构。 该架构旨在与SAE L1-L5级别的自动驾驶保…...

【两周学会FPGA】从0到1学习紫光同创FPGA开发|盘古PGL22G开发板学习之数码管静态显示(四)
本原创教程由深圳市小眼睛科技有限公司创作,版权归本公司所有,如需转载,需授权并注明出处 适用于板卡型号: 紫光同创PGL22G开发平台(盘古22K) 一:盘古22K开发板(紫光同创PGL22G开发…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

GitLab External Wiki代理权限绕过漏洞深度解析
1. 这个漏洞不是“修个补丁”就能完事的——它暴露的是 GitLab 权限模型里一个被长期忽视的逻辑断层GitLab 安全漏洞 CVE-2025-2614,光看编号容易误以为是又一个常规的越权或 XSS 类型漏洞。但我在实际复现和审计过程中发现,它根本不是配置疏漏或代码拼写…...

告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF
告别CAJ格式困扰:3分钟学会用开源工具将知网文献转为PDF 【免费下载链接】caj2pdf Convert CAJ (China Academic Journals) files to PDF. 转换中国知网 CAJ 格式文献为 PDF。佛系转换,成功与否,皆是玄学。 项目地址: https://gitcode.com/…...
)
Postgresql基础实践教程(八)
⭐️⭐️⭐️⭐️⭐️ 完整数据详见 练习数据免费 ⭐️⭐️⭐️⭐️⭐️ 六十九、查找会员ID 27的向上推荐链 问题 查找会员ID 27的向上推荐链:即推荐该会员的人,以及推荐那个人的人,依此类推。返回会员ID、名字和姓氏。按会员ID降序排列。…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

大厂校招变了:AI 能力正在进入笔试和面试
最近不少同学投递校招时,应该已经发现一个变化: 以前 JD 里写的是“熟悉 Python / Java / SQL / Office 优先”。 现在越来越多岗位开始出现新的描述: “熟练使用 AI 工具者优先” “了解大模型应用者优先” “具备 AI 辅助编程经验优先” “…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...

Fiddler手机断网真相:TLS握手与证书固定的协议级拦截
1. 为什么Fiddler一开,手机就断网?这不是配置问题,是协议层的“信任危机”Fiddler抓包手机流量,本该是移动开发、测试、安全分析中最基础的操作之一。但几乎每个刚上手的人,都会在第二天早上发现:手机Wi-Fi…...