Python数据分析与数据挖掘:解析数据的力量
引言:
随着大数据时代的到来,数据分析和数据挖掘已经成为许多行业中不可或缺的一部分。在这个信息爆炸的时代,如何从大量的数据中提取有价值的信息,成为了企业和个人追求的目标。而Python作为一种强大的编程语言,提供了丰富的库和工具,使得数据分析和数据挖掘变得更加简单和高效。本文将深入探讨Python在数据分析和数据挖掘中的应用,介绍其常用的库和工具,以及如何利用Python进行数据分析和数据挖掘的实际案例。
第一部分:Python在数据分析中的应用
1.1 Python中的pandas库:数据处理的利器
在当今大数据时代,数据处理是数据分析和数据挖掘的必要步骤之一。而Python中的pandas库,作为一种强大的数据处理工具,为我们提供了丰富的功能和方法,使得数据清洗、整理、转换以及合并与拆分变得更加简单高效。
首先,pandas库提供了一系列用于数据清洗与整理的函数和方法。我们可以通过pandas快速处理缺失值、异常值以及重复值等数据质量问题。同时,pandas还支持数据类型的转换,让我们能够轻松地将字符串类型转换为日期时间类型、数值类型转换为分类类型等,方便后续的数据分析工作。
其次,pandas库还提供了丰富的数据转换与重塑的功能。我们可以通过pandas的函数和方法,对数据进行筛选、排序、过滤、分组等操作,以满足不同的数据分析需求。此外,pandas还支持透视表和透视图的生成,可以方便地对数据进行重塑和汇总,帮助我们更好地理解数据的特征和关系。
另外,pandas库还提供了数据合并与拆分的灵活性。我们可以轻松地将多个数据集进行合并,根据指定的键值将不同的数据集进行关联。这为我们分析多源数据提供了便利。同时,pandas还支持将大的数据集拆分为多个较小的数据集,方便我们进行分布式计算和处理。
总之,Python中的pandas库是数据处理的利器。它提供了丰富的函数和方法,使得数据清洗与整理、数据转换与重塑以及数据合并与拆分变得更加简单高效。无论是在数据分析、数据挖掘还是机器学习等领域,pandas都扮演着重要的角色。因此,学习和掌握pandas库的使用,对于从事数据分析相关工作的人士来说是非常重要的。
让我们一起利用Python中的pandas库,将数据处理变得更加轻松和高效,为我们的数据分析工作带来更大的价值和成果。
1.2 Python中的NumPy库:高效的数值计算
在数据科学和机器学习领域,高效的数值计算是关键的一环。而Python中的NumPy库作为一种强大的数值计算工具,为我们提供了丰富的函数和方法,使得数组操作、数学计算、统计分析、线性代数、随机数生成和数据模拟等任务变得更加简单高效。
首先,NumPy库提供了强大的数组操作和数学计算功能。我们可以使用NumPy创建多维数组,并对数组进行索引、切片、重塑等操作。此外,NumPy还提供了大量的数学函数,如三角函数、指数函数、对数函数等,方便我们进行各种数学计算。这些功能的高效实现使得NumPy成为处理大规模数值数据的首选工具。
其次,NumPy库还提供了丰富的统计分析和线性代数功能。我们可以使用NumPy进行各种统计分析,如计算均值、方差、协方差等。同时,NumPy还支持常见的线性代数运算,如矩阵乘法、矩阵求逆、特征值分解等,为我们解决线性代数问题提供了便利。
此外,NumPy库还具备随机数生成和数据模拟的能力。我们可以使用NumPy生成各种类型的随机数,如均匀分布、正态分布、泊松分布等。这为我们进行概率统计分析和数据模拟提供了基础。同时,NumPy还支持随机数种子的设置,以确保结果的可重复性。
总之,Python中的NumPy库是一种高效的数值计算工具。它提供了强大的数组操作、数学计算、统计分析、线性代数、随机数生成和数据模拟功能,方便我们进行各种数值计算任务。无论是在数据科学、机器学习还是科学计算等领域,NumPy都发挥着重要的作用。
通过学习和掌握NumPy库的使用,我们可以更加高效地进行数值计算,将数据科学中的复杂问题转化为简单的数学运算。让我们一起利用Python中的NumPy库,提升数值计算的效率,为我们的数据分析和机器学习工作带来更大的价值和成果。
1.3 Python中的matplotlib和seaborn库:数据可视化的利器
在数据分析和机器学习领域,数据可视化是理解和传达数据的重要手段。Python中的matplotlib和seaborn库提供了丰富的功能和工具,使得我们可以轻松地创建各种类型的图表,包括线性图、散点图、柱状图、饼图、热力图和箱线图等,为我们的数据可视化工作带来了极大的便利。
首先,matplotlib库是Python中最流行的数据可视化库之一,它提供了丰富的绘图函数和方法,可以绘制各种类型的图表。我们可以使用matplotlib绘制线性图和散点图,展示数据之间的关系和趋势。此外,matplotlib还提供了灵活的图形配置选项,我们可以自定义图表的颜色、线型、标签、标题等,使得图表更加美观和易读。
其次,seaborn库是建立在matplotlib之上的高级数据可视化库,它通过提供更简单的接口和更美观的图表风格,使得我们能够更快速地创建各种类型的图表。例如,我们可以使用seaborn创建柱状图和饼图,以直观地展示数据的分布和比例。seaborn还提供了丰富的调色板和样式选项,使得图表的颜色和样式更加丰富多样。
此外,matplotlib和seaborn库还支持生成热力图和箱线图等高级图表。热力图可以将数据的数值映射为颜色,从而直观地展示数据的分布和趋势。箱线图则可以用来展示数据的分布和异常值情况,帮助我们发现数据中的异常情况和离群值。
总之,Python中的matplotlib和seaborn库是数据可视化的利器。它们提供了丰富的绘图函数和方法,使得我们能够轻松地创建各种类型的图表,包括线性图、散点图、柱状图、饼图、热力图和箱线图等。通过使用这些库,我们可以更加直观地理解和传达数据,从而更好地进行数据分析和机器学习工作。
让我们一起充分利用Python中的matplotlib和seaborn库,提升数据可视化的效果,为数据分析和决策提供更有力的支持。无论是在学术研究、商业分析还是数据科学领域,这些数据可视化工具都将为我们的工作带来巨大的帮助和价值。## 第二部分:Python在数据挖掘中的应用
2.1 Python中的scikit-learn库:机器学习的利器
在机器学习领域,Python中的scikit-learn库是一款功能强大且广泛使用的机器学习工具包。它提供了各种分类、回归、聚类、降维等算法,以及数据预处理和模型评估等功能,为我们的机器学习任务提供了全面的支持。
首先,scikit-learn库提供了丰富的分类和回归算法,能够满足各种不同类型的预测任务。无论是线性回归、逻辑回归、决策树还是支持向量机等算法,scikit-learn都提供了简单易用的API和强大的功能,使得我们能够快速构建和训练模型,进行准确的分类和回归预测。
其次,scikit-learn库还提供了聚类和降维算法,用于发现数据中的隐藏模式和结构。通过使用K均值聚类、层次聚类、DBSCAN等算法,我们可以将数据分为不同的簇,从而更好地理解数据的分布和相似性。而通过使用主成分分析(PCA)、线性判别分析(LDA)等算法,我们可以将高维数据降维到低维空间,减少数据的复杂性和冗余性。
此外,scikit-learn库还提供了数据预处理和模型评估等功能,使得我们能够更好地处理数据和评估模型的性能。通过使用数据预处理方法,如特征缩放、特征选择、数据标准化等,我们可以提高模型的训练效果和泛化能力。而通过使用交叉验证、网格搜索等技术,我们可以评估和优化模型的性能,选择最佳的超参数设置。
总之,Python中的scikit-learn库是机器学习的利器。它提供了各种分类、回归、聚类、降维等算法,以及数据预处理和模型评估等功能,为我们的机器学习任务提供了全面的支持。通过使用这个强大的工具包,我们可以更加高效地构建和训练模型,进行准确的预测和分析工作。
让我们充分利用Python中的scikit-learn库,发挥机器学习的潜力,为各种应用场景提供定制化的解决方案。无论是在金融领域的风险评估、医疗领域的疾病预测,还是在电商领域的推荐系统,scikit-learn库都能够满足我们的需求,帮助我们取得更好的结果。
2.2 Python中的TensorFlow和PyTorch库:深度学习的利器
随着人工智能的快速发展,深度学习已经成为解决复杂问题和实现创新的关键技术。在深度学习领域,Python中的TensorFlow和PyTorch库是两个最受欢迎和广泛使用的工具包。它们提供了强大的神经网络和深度学习算法,以及用于图像识别、语音处理、文本分类和推荐系统等任务的功能,成为我们实现机器智能的利器。
首先,TensorFlow和PyTorch库为我们提供了丰富的神经网络和深度学习算法。无论是传统的卷积神经网络(CNN)、循环神经网络(RNN)还是最近流行的变种,如残差网络(ResNet)、生成对抗网络(GAN)等,这两个库都提供了强大的API和模型架构,方便我们构建和训练深度学习模型。
其次,TensorFlow和PyTorch库特别适用于图像识别和语音处理等视觉和语音任务。通过使用这两个库,我们可以轻松地进行图像分类、目标检测、语义分割等任务,并且能够处理大规模的图像数据集。在语音处理方面,这两个库提供了各种语音识别、语音合成、语音情感分析等功能,可以帮助我们处理和理解声音数据。
此外,TensorFlow和PyTorch库还在文本分类和推荐系统等自然语言处理任务上表现出色。通过使用这两个库,我们可以构建文本分类模型,将文本数据分为不同的类别,例如情感分析、垃圾邮件过滤等。同时,这两个库还提供了推荐系统相关的算法和工具,用于个性化推荐、协同过滤等应用。
总之,Python中的TensorFlow和PyTorch库是深度学习的利器。它们提供了强大的神经网络和深度学习算法,以及用于图像识别、语音处理、文本分类和推荐系统等任务的功能,为我们实现机器智能提供了全面的支持。通过使用这些工具包,我们可以更加高效地构建和训练深度学习模型,实现复杂问题的解决和创新。
让我们充分利用Python中的TensorFlow和PyTorch库,发挥深度学习的潜力,为各种应用场景提供智能的解决方案。无论是在医疗领域的疾病诊断、自动驾驶领域的图像识别,还是在电商领域的个性化推荐,这些库都能够帮助我们取得更好的结果,实现人工智能的梦想。
2.3 Python中的其他数据挖掘库:应对更复杂的问题
除了TensorFlow和PyTorch库之外,Python中还有许多其他强大的数据挖掘库,可以帮助我们应对更复杂的问题。这些库包括XGBoost、LightGBM、Keras、PyCaret、NLTK和TextBlob等,它们提供了各种功能和算法,可以用于梯度提升树、深度学习、机器学习、文本挖掘和情感分析等任务,让我们能够更加高效地解决各种数据挖掘难题。
首先,XGBoost和LightGBM是两个非常流行的梯度提升树工具。梯度提升树是一种强大的机器学习算法,可以用于回归、分类和排名等任务。通过使用XGBoost和LightGBM库,我们可以构建和训练高效的梯度提升树模型,应对复杂的数据挖掘问题。这两个库提供了丰富的参数和优化技巧,使得我们能够更好地调整模型,提高预测准确率。
其次,Keras和PyCaret是两个简化深度学习和机器学习流程的工具。Keras是一个高级神经网络库,提供了简洁而强大的API,可以方便地构建和训练深度学习模型。PyCaret是一个全方位的机器学习库,提供了自动化的机器学习工作流程,包括数据预处理、特征工程、模型选择和调优等步骤。通过使用这两个库,我们可以快速搭建和优化深度学习和机器学习模型,节省大量的时间和精力。
此外,NLTK和TextBlob是两个强大的文本挖掘和情感分析工具。文本挖掘是从文本数据中提取有用信息的过程,情感分析是对文本进行情感倾向性分析的任务。NLTK是一个广泛使用的自然语言处理库,提供了丰富的功能和算法,用于文本分词、词性标注、句法分析等任务。TextBlob是一个简单易用的情感分析库,可以帮助我们分析文本中的情感倾向,例如正面、负面或中性。这两个库为我们处理文本数据提供了便利和支持,使得我们能够更好地理解和利用文本信息。
Python中的其他数据挖掘库为我们应对更复杂的问题提供了有力的工具。通过使用XGBoost和LightGBM进行梯度提升树建模,使用Keras和PyCaret简化深度学习和机器学习流程,以及使用NLTK和TextBlob进行文本挖掘和情感分析,我们能够更加高效地解决各种数据挖掘难题。让我们充分利用这些强大的工具,挖掘数据中的宝藏,为业务决策和创新提供有力支持。
第三部分:Python数据分析与数据挖掘实际案例
3.1 金融行业的数据分析与风险预测
在金融行业,数据分析和风险预测是至关重要的环节,能够帮助投资者做出明智的决策并规避风险。Python作为一种强大的编程语言,在金融数据清洗、整理、机器学习模型构建以及数据可视化等方面发挥着重要作用。下面将从三个方面介绍Python在金融行业的应用。
首先,利用Python进行金融数据清洗和整理是金融数据分析的重要步骤。金融数据通常庞杂而复杂,需要进行清洗和整理,以确保数据的准确性和一致性。Python提供了许多数据处理和清洗的库,例如Pandas和NumPy,可以帮助我们高效地处理金融数据,对数据进行过滤、去除异常值、填充缺失值等操作,为后续的分析和建模打下坚实基础。
其次,基于机器学习模型进行风险预测和投资策略是金融数据分析的核心内容。Python中的机器学习库如Scikit-learn和TensorFlow提供了丰富的算法和模型,可以用于构建风险预测模型和投资策略模型。通过利用历史数据进行训练,这些模型可以分析和学习数据中的规律和趋势,从而实现对未来风险和市场变化的预测。这些预测结果可以帮助投资者制定合理的投资决策,减少风险、提高收益。
最后,利用数据可视化工具展示交易模式和趋势是金融数据分析的重要手段。Python中的数据可视化库如Matplotlib和Seaborn可以帮助我们将分析结果以图表形式展示出来,直观地展示交易模式和趋势。通过可视化分析,投资者可以更好地理解数据,并从中发现潜在的市场机会和风险。此外,数据可视化也有助于与团队或股东共享分析结果,提高沟通和决策效率。
Python在金融行业的数据分析与风险预测中发挥着重要作用。利用Python进行金融数据清洗和整理,基于机器学习模型进行风险预测和投资策略,以及利用数据可视化工具展示交易模式和趋势,我们能够更加准确地了解金融市场和投资机会,做出明智的投资决策。让我们充分利用Python的强大功能,实现智能化的金融数据分析,为投资者带来更多稳健和高效的投资回报。
3.2 零售行业的数据挖掘与市场定位
随着零售行业的竞争日益激烈,企业需要利用数据挖掘和机器学习来进行市场定位,以提高销售额并制定更有效的促销策略。在这一过程中,Python作为一种强大的编程语言,提供了广泛的工具和库,可以帮助企业进行销售数据分析、客户分群、关联规则挖掘以及市场定位和客户推荐等关键任务。本文将介绍如何利用Python在零售行业进行数据挖掘和市场定位。
首先,Python提供了强大的数据分析和处理库,如Pandas和NumPy,可用于对销售数据进行深入分析。通过Python,企业可以轻松地清洗、整理和分析销售数据,从中获取有价值的信息。通过利用统计分析和可视化工具,企业可以了解销售情况、顾客消费行为和市场趋势,进而制定相应的销售策略。此外,Python还提供了各种聚类算法,如K-means和DBSCAN,可将客户分为不同的群组,有助于企业制定个性化的促销策略。
其次,基于关联规则挖掘是提高销售额和促销策略的重要手段。Python中的关联规则挖掘库,如Apriori和FP-growth,可帮助企业从销售数据中发现潜在的关联规律。通过分析顾客购买行为和购买组合,企业可以发现哪些产品具有较高的关联性,以制定针对性的促销策略。例如,当顾客购买商品A时,可以推荐相关的商品B,从而促进销售。通过Python的关联规则挖掘,企业可以提高销售额和促销策略的效果,增强顾客购买的黏性和忠诚度。
最后,利用机器学习模型进行市场定位和客户推荐是提高销售额和市场占有率的关键。Python中的机器学习库,如Scikit-learn和TensorFlow,提供了多种算法和模型,可用于分析市场需求、预测顾客行为并进行个性化推荐。通过对历史销售数据和顾客特征的训练,这些模型可以帮助企业了解目标市场的特点,并为不同客户推荐最相关的产品和服务。这种个性化推荐能够提高顾客满意度和购买转化率,从而有效提升销售额。
利用Python进行销售数据分析和客户分群,基于关联规则挖掘提高销售额和促销策略,以及利用机器学习模型进行市场定位和客户推荐,对零售行业来说具有重要的意义。这些技术和工具可以帮助企业更好地了解市场和顾客需求,制定精准的销售策略,提高销售额和顾客满意度。零售企业应积极应用数据挖掘和机器学习的技术,不断挖掘数据中的无限潜力,以满足不断变化的市场需求,并取得持续的竞争优势。
3.3 医疗行业的数据分析与疾病预测
医疗行业作为一个知识密集、数据密集的行业,利用数据分析和机器学习进行疾病预测和诊断辅助,具有重要的意义。在这个过程中,Python作为一种强大的编程语言,提供了丰富的工具和库,可以帮助医疗机构进行医疗数据清洗和预处理、基于机器学习模型进行疾病预测和诊断辅助,并利用数据可视化工具展示患者群体和治疗效果。本文将介绍如何利用Python在医疗行业进行数据分析和疾病预测。
首先,Python提供了强大的数据分析和处理库,如Pandas和NumPy,可用于医疗数据的清洗和预处理。医疗数据通常包含大量的缺失值、错误值和异常值,通过Python,医疗机构可以轻松地清洗、整理和处理这些数据,从而得到可信的数据集。通过利用统计分析和可视化工具,医疗机构可以了解患者的基本情况、病例分布和趋势等信息,为疾病预测和诊断辅助提供依据。
其次,基于机器学习模型的疾病预测和诊断辅助是医疗行业的重要应用之一。Python中的机器学习库,如Scikit-learn和TensorFlow,提供了多种算法和模型,可用于分析医疗数据、预测疾病发生风险和辅助医生的诊断决策。通过对患者的历史数据和临床特征进行训练,这些模型可以帮助医疗机构准确预测患者是否患有某种疾病,并提供治疗建议和诊断依据。这种基于机器学习的疾病预测和诊断辅助可以提高医生的准确性和效率,为患者提供更好的医疗服务。
最后,利用数据可视化工具展示患者群体和治疗效果对于医疗机构和患者来说都具有重要的意义。Python中的数据可视化库,如Matplotlib和Seaborn,提供了丰富的图表和绘图工具,可用于展示患者群体的分布、疾病发病率和治疗效果等信息。通过可视化分析,医疗机构可以更直观地了解患者的情况和疾病的特点,从而制定更有效的医疗政策和治疗方案。对于患者来说,数据可视化可以帮助他们更好地理解自己的健康状况和治疗效果,提高治疗的依从性和满意度。
利用Python进行医疗数据清洗和预处理,基于机器学习模型进行疾病预测和诊断辅助,以及利用数据可视化工具展示患者群体和治疗效果,对医疗行业来说具有重要的意义。这些技术和工具可以帮助医疗机构更好地管理和分析医疗数据,准确预测和诊断疾病,提高医疗服务质量和效率。医疗机构应积极应用数据分析和机器学习的技术,不断提升医疗水平和患者满意度,为人类的健康事业做出更大的贡献。
结论:
Python作为一种强大的编程语言在数据分析和数据挖掘领域发挥着巨大的作用。通过丰富的库和工具,Python使得数据分析和数据挖掘变得更加简单和高效。无论是处理、分析和可视化数据,还是发现数据中的模式和关联,Python都提供了丰富的功能和工具。在实际应用中,Python在金融、零售和医疗等行业中都有广泛的应用,帮助企业和个人实现数据驱动的决策和创新。因此,学习和掌握Python数据分析和数据挖掘技能对于从事相关行业的人士来说是非常重要的,也将为他们带来巨大的竞争优势。让我们一起迎接数据时代的挑战,利用Python来解析数据的力量。
相关文章:

Python数据分析与数据挖掘:解析数据的力量
引言: 随着大数据时代的到来,数据分析和数据挖掘已经成为许多行业中不可或缺的一部分。在这个信息爆炸的时代,如何从大量的数据中提取有价值的信息,成为了企业和个人追求的目标。而Python作为一种强大的编程语言,提供…...
)
我的私人笔记(安装hive)
1.hive下载:Index of /dist/hive/hive-1.2.1 或者上传安装包至/opt/software:rz或winscp上传 2.解压 cd /opt/software tar -xzvf apache-hive-1.2.1-bin.tar.gz -C /opt/servers/ 3.重命名 mv apache-hive-1.2.1-bin hive 4.配置环境变量 vi /etc/…...
【kubernetes】k8s部署APISIX及在KubeSphere使用APISIX
Apache APISIX https://apisix.apache.org/ 功能比nginx-ingress更强 本文采用2.5.0版本 https://apisix.apache.org/zh/docs/apisix/2.15/getting-started/ 概述内容来源于官方,学习于马士兵云原生课程 概述 Apache APISIX 是什么? Apache APISIX 是 …...
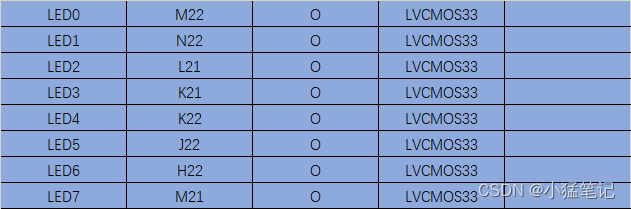
串口接收数据-控制LED灯
目标 通过串口接收数据,对数据分析,控制8个LED灯按照设定时间闪烁。 8个LED灯可以任意设计,是否闪烁。闪烁时间按ms计算,通过串口发送,可设置1~4,294,967,296ms,也就是4字节数据协议自拟,有数…...
python面试题合集(一)
python技术面试题 1、Python中的幂运算 在python中幂运算是由两个 **星号运算的,实例如下: >>> a 2 ** 2 >>> a 4我们可以看到2的平方输出结果为4。 那么 ^指的是什么呢?我们用代码进行演示: >>>…...

论文浅尝 | 利用对抗攻击策略缓解预训练语言模型中的命名实体情感偏差问题...
笔记整理:田家琛,天津大学博士,研究方向为文本分类 链接:https://ojs.aaai.org/index.php/AAAI/article/view/26599 动机 近年来,随着预训练语言模型(PLMs)在情感分类领域的广泛应用,…...
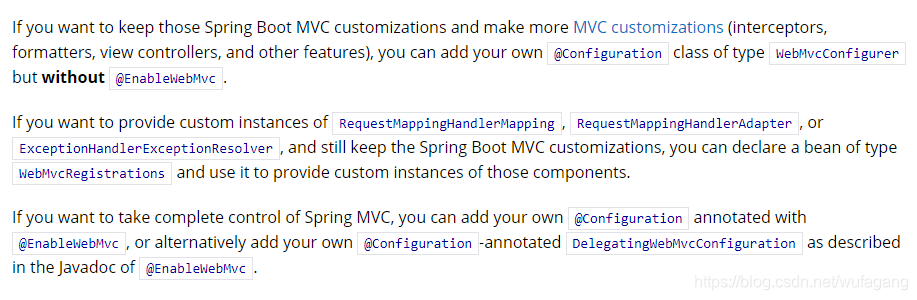
springboot web开发springmvc自动配置原理
前言 我们也知道springboot启用springmvc基本不用做什么配置可以很方便就使用了但是不了解原理,开发过程中遇到点问题估计就比较头疼,不管了解的深不深入,先巴拉一番再说… 下面我们先看看官网…我的版本是2.3.2版本,发现官网改动也比较大…不同版本自己巴拉下吧,结构虽然变化…...
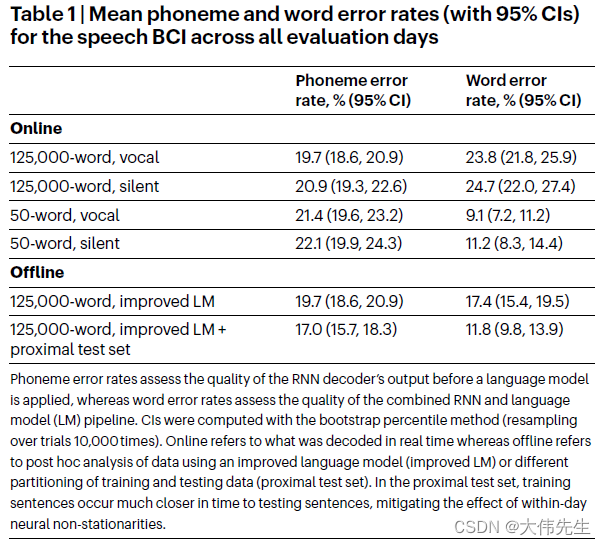
发表于《自然》杂志:语音转文本BCI的新突破实现62字/分钟的速度
语音脑机接口(BCI)是一项创新技术,通过用户的大脑信号在用户和某些设备之间建立通信通道,它们在恢复残疾患者的言语和通信能力方面具有巨大潜力。 早期的研究虽然很有希望,但尚未达到足够高的精度来解码大脑活动&…...
微软 Turing Bletchley v3视觉语言模型更新:必应搜索图片更精准
据微软新闻稿透露,在推出第三代Turing Bletchley视觉语言模型后,微软计划逐步将其整合到Bing等相关产品中,以提供更出色的图像搜索体验。这款模型最初于2021年11月面世,并在2022年秋季开始邀请用户测试。 凭借用户的反馈和建议&am…...

Ubuntu 22.04 x86_64 源码编译 pytorch-v2.0.1 笔记【2】编译成功
20230831继续: 当前状态 (pytorch-build) yeqiangyeqiang-MS-7B23:~/Downloads/src/pytorch$ pwd /home/yeqiang/Downloads/src/pytorch (pytorch-build) yeqiangyeqiang-MS-7B23:~/Downloads/src/pytorch$ python3 -V Python 3.10.6 (pytorch-build) yeqiangyeqi…...

IIR滤波器
IIR滤波器原理 IIR的特点是:非线性相位、消耗资源少。 IIR滤波器的系统函数与差分方程如下所示: 由差分方程可知IIR滤波器存在反馈,因此在FPGA设计时要考虑到有限字长效应带来的影响。差分方程中包括两个部分:输入信号x(n)的M节…...

【QT】使用qml的QtWebEngine遇到的一些问题总结
在使用qt官方的一些QML的QtWebEngine相关的例程的时候,有时在运行会报如下错误: WebEngineContext used before QtWebEngine::initialize() or OpenGL context creation failed 这个问题在main函数里面最前面加上: QCoreApplication::setAttr…...
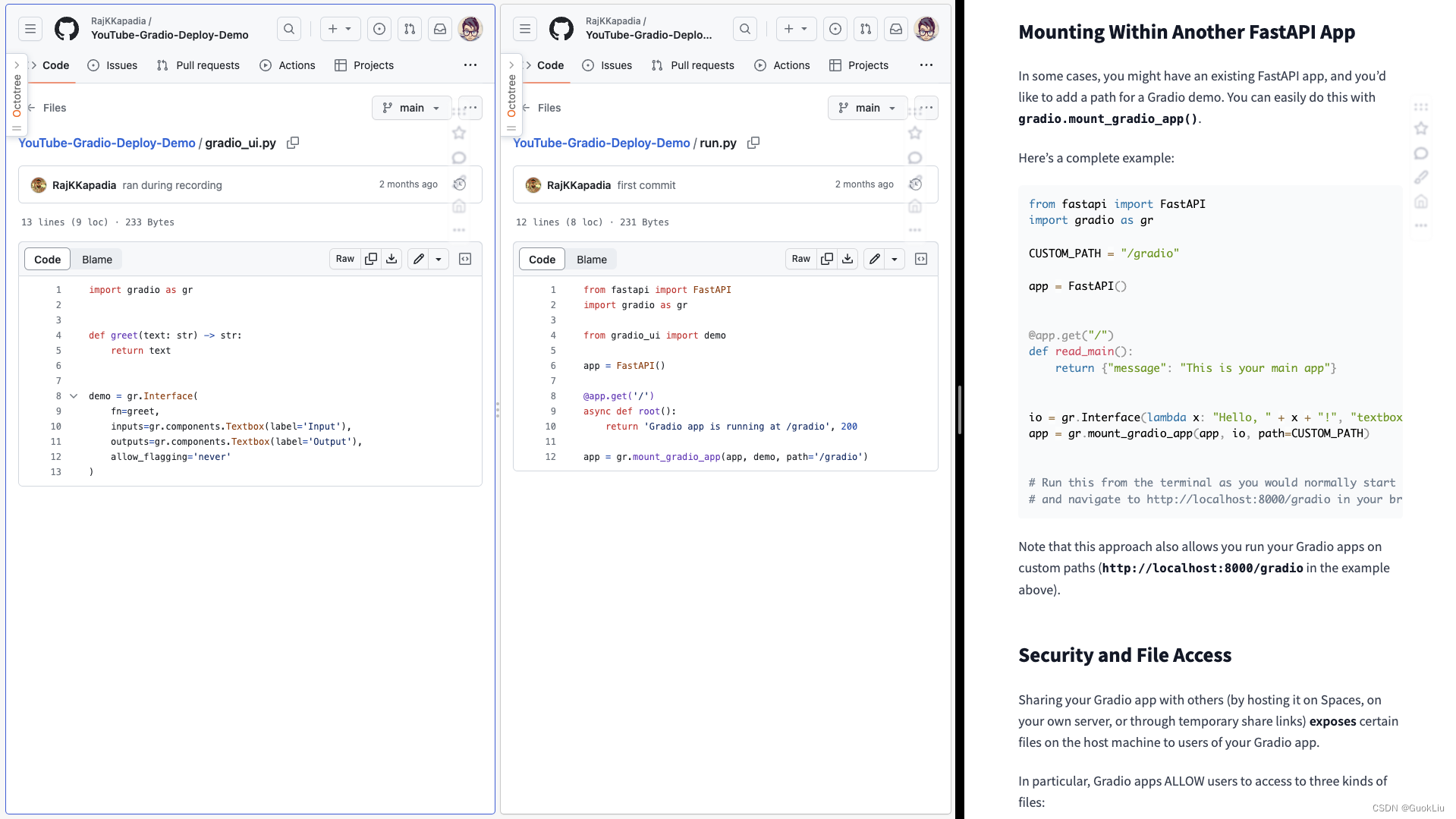
230902-部署Gradio到已有FastAPI及服务器中
1. 官方例子 run.py from fastapi import FastAPI import gradio as grCUSTOM_PATH "/gradio"app FastAPI()app.get("/") def read_main():return {"message": "This is your main app"}io gr.Interface(lambda x: "Hello, …...
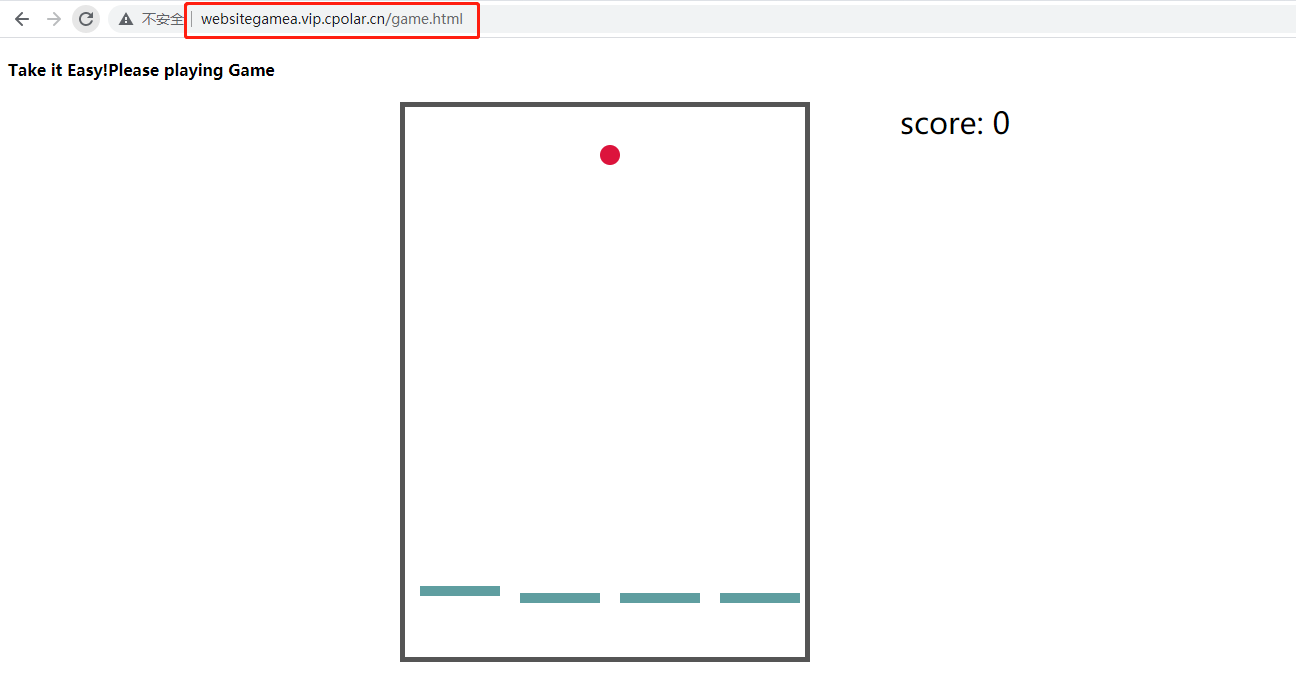
Ubuntu本地快速搭建web小游戏网站,公网用户远程访问【内网穿透】
文章目录 前言1. 本地环境服务搭建2. 局域网测试访问3. 内网穿透3.1 ubuntu本地安装cpolar内网穿透3.2 创建隧道3.3 测试公网访问 4. 配置固定二级子域名4.1 保留一个二级子域名4.2 配置二级子域名4.3 测试访问公网固定二级子域名 前言 网:我们通常说的是互联网&am…...

【LeetCode-中等题】199. 二叉树的右视图
文章目录 题目方法一:层序遍历取每一层最后一个元素方法二:深度优先搜索 题目 方法一:层序遍历取每一层最后一个元素 // 方法一 :层序 集合(取每层子集合最后一个元素)// List<List<Integer>> Rlist new ArrayList…...
【调试经验】Ubuntu22.04 安装和配置MySQL 8.0.34
本文共计1469字,预计阅读时间5分钟 在安装新版本的MySQL到电脑时,按着网上一些教程执行发现错误繁多,最后索性自己摸索并把服务装好了。自己也整理了一下在操作时的笔记,上传上来希望能帮助到大家。 目录 正文 安装MySQL 配置…...

Android 使用OpenCV实现实时人脸识别,并绘制到SurfaceView上
1. 前言 上篇文章 我们已经通过一个简单的例子,在Android Studio中接入了OpenCV。 之前我们也 在Visual Studio上,使用OpenCV实现人脸识别 中实现了人脸识别的效果。 接着,我们就可以将OpenCV的人脸识别效果移植到Android中了。 1.1 环境说…...

【自然语言处理】关系抽取 —— GDPNet 讲解
GDPNet 论文信息 标题:GDPNet: Refining Latent Multi-View Graph for Relation Extraction 作者:Fuzhao Xue, Aixin Sun, Hao Zhang, Eng Siong Chng 期刊:AAAI 2021 发布时间与更新时间:2020.12.12 主题:自然语言处理、关系抽取、对话场景、BERT、GCN arXiv:[2012.0678…...

【小沐学NLP】Python使用NLTK库的入门教程
文章目录 1、简介2、安装2.1 安装nltk库2.2 安装nltk语料库 3、测试3.1 分句分词3.2 停用词过滤3.3 词干提取3.4 词形/词干还原3.5 同义词与反义词3.6 语义相关性3.7 词性标注3.8 命名实体识别3.9 Text对象3.10 文本分类3.11 其他分类器3.12 数据清洗 结语 1、简介 NLTK - 自然…...
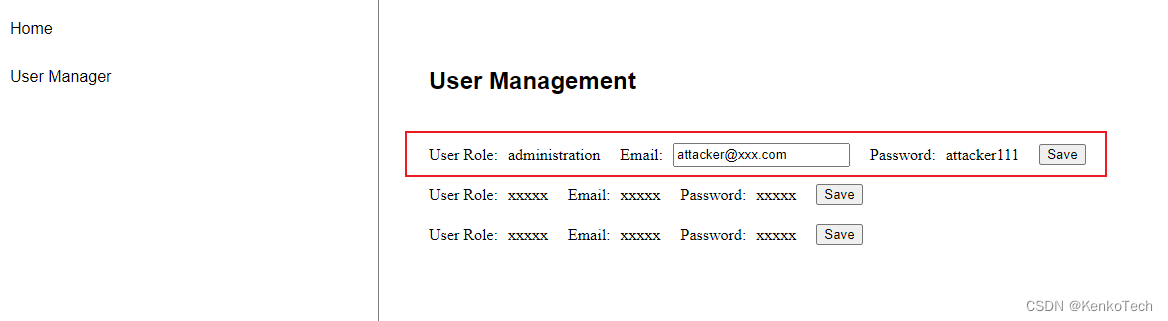
Angular安全专辑之三 —— 授权绕过,利用漏洞控制管理员账户
这篇文章是针对实际项目中所出现的问题所做的一个总结。简单来说,就是授权绕过问题,管理员帐户被错误的接管。 详细情况是这样的,我们的项目中通常都会有用户身份验证功能,不同的用户拥有不同的权限。相对来说管理员账户所对应的…...

掌握ModTheSpire:从入门到精通的开源模组加载工具实战指南
掌握ModTheSpire:从入门到精通的开源模组加载工具实战指南 【免费下载链接】ModTheSpire External mod loader for Slay The Spire 项目地址: https://gitcode.com/gh_mirrors/mo/ModTheSpire 认知铺垫:走进模组加载的技术世界 当你第一次尝试为…...

3个颠覆性用法:B站字幕提取工具如何改变你的视频创作流程
3个颠覆性用法:B站字幕提取工具如何改变你的视频创作流程 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾经为了获取B站视频的字幕而烦恼&…...

Phi-4-mini-reasoning部署教程:多模型共存时GPU显存隔离配置技巧
Phi-4-mini-reasoning部署教程:多模型共存时GPU显存隔离配置技巧 1. 模型介绍 Phi-4-mini-reasoning是微软推出的3.8B参数轻量级开源模型,专为数学推理、逻辑推导和多步解题等强逻辑任务设计。这个模型主打"小参数、强推理、长上下文、低延迟&quo…...

iOSDeviceSupport:解决设备调试兼容性问题的高效管理工具
iOSDeviceSupport:解决设备调试兼容性问题的高效管理工具 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport 问题场景:当新系统遇见旧Xcode "连接失败…...

AUC 的两种等价定义:从排序概率到 ROC 曲线的统一理解
一、AUC 的本质:一个排序概率1. 问题设定假设我们面对的是一个二分类 / 排序问题:每个样本 �� 有真实标签 ��∈0,1模型给出一个连续预测分数 ��∈�分数越大,模…...

厦门GEO软件哪家强?实测主流平台,为你揭秘推荐榜单
在数字化转型浪潮中,GEO(地理定位优化)软件成为企业提升本地化营销效率的关键工具。面对厦门市场上琳琅满目的GEO平台,如何选择一款适配自身业务需求、技术稳定且安全合规的解决方案,成为众多企业面临的难题。作为第三…...

HARMONYOS应用实例261:分段函数绘制
分段函数绘制 功能:定义分段函数规则,自动绘制不连续的函数图像。 支持创建多个分段函数,每个分段可以是不同类型 支持三种函数类型:一次函数、二次函数、常量函数 可调节每个分段的函数系数(a、b、c) 可设置每个分段的定义域(起点和终点) 可控制端点是否包含(开区间或…...

AIGlasses OS Pro 智能视觉系统Python入门实战:3步完成环境部署与基础调用
AIGlasses OS Pro 智能视觉系统Python入门实战:3步完成环境部署与基础调用 你是不是也对那些能“看懂”世界的智能眼镜感到好奇?想自己动手写几行代码,让程序也能识别物体、分析场景,却不知道从何开始?别担心…...

ESP32组件化开发实战:从零构建高效项目结构
1. 为什么需要组件化开发? 第一次接触ESP32开发时,我习惯把所有代码都塞进main文件夹里。结果项目稍微复杂点就乱成一锅粥,每次修改都要在几十个文件里翻找,不同功能模块互相纠缠,想复用某个传感器驱动都得连带着拷贝…...

从硅片到电路:图解CMOS反相器的制造工艺与工作原理
从硅片到电路:图解CMOS反相器的制造工艺与工作原理 在半导体工业中,CMOS反相器作为数字电路的基本构建模块,其制造工艺凝聚了现代微电子技术的精华。本文将带您深入半导体fab的微观世界,通过工艺截面图的逐步解析,揭示…...