【小沐学NLP】Python使用NLTK库的入门教程
文章目录
- 1、简介
- 2、安装
- 2.1 安装nltk库
- 2.2 安装nltk语料库
- 3、测试
- 3.1 分句分词
- 3.2 停用词过滤
- 3.3 词干提取
- 3.4 词形/词干还原
- 3.5 同义词与反义词
- 3.6 语义相关性
- 3.7 词性标注
- 3.8 命名实体识别
- 3.9 Text对象
- 3.10 文本分类
- 3.11 其他分类器
- 3.12 数据清洗
- 结语
1、简介
NLTK - 自然语言工具包 - 是一套开源Python。 支持自然研究和开发的模块、数据集和教程 语言处理。NLTK 需要 Python 版本 3.7、3.8、3.9、3.10 或 3.11。
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。它提供了易于使用的接口,通过这些接口可以访问超过50个语料库和词汇资源(如WordNet),还有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库,以及工业级NLP库的封装器和一个活跃的讨论论坛。

2、安装
2.1 安装nltk库
The Natural Language Toolkit (NLTK) is a Python package for natural language processing. NLTK requires Python 3.7, 3.8, 3.9, 3.10 or 3.11.
pip install nltk
# or
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple
可以用以下代码测试nltk分词的功能:
2.2 安装nltk语料库
在NLTK模块中包含数十种完整的语料库,可用来练习使用,如下所示:
古腾堡语料库:gutenberg,包含古藤堡项目电子文档的一小部分文本,约有36000本免费电子书。
网络聊天语料库:webtext、nps_chat
布朗语料库:brown
路透社语料库:reuters
影评语料库:movie_reviews,拥有评论、被标记为正面或负面的语料库;
就职演讲语料库:inaugural,有55个文本的集合,每个文本是某个总统在不同时间的演说.
- 方法1:在线下载
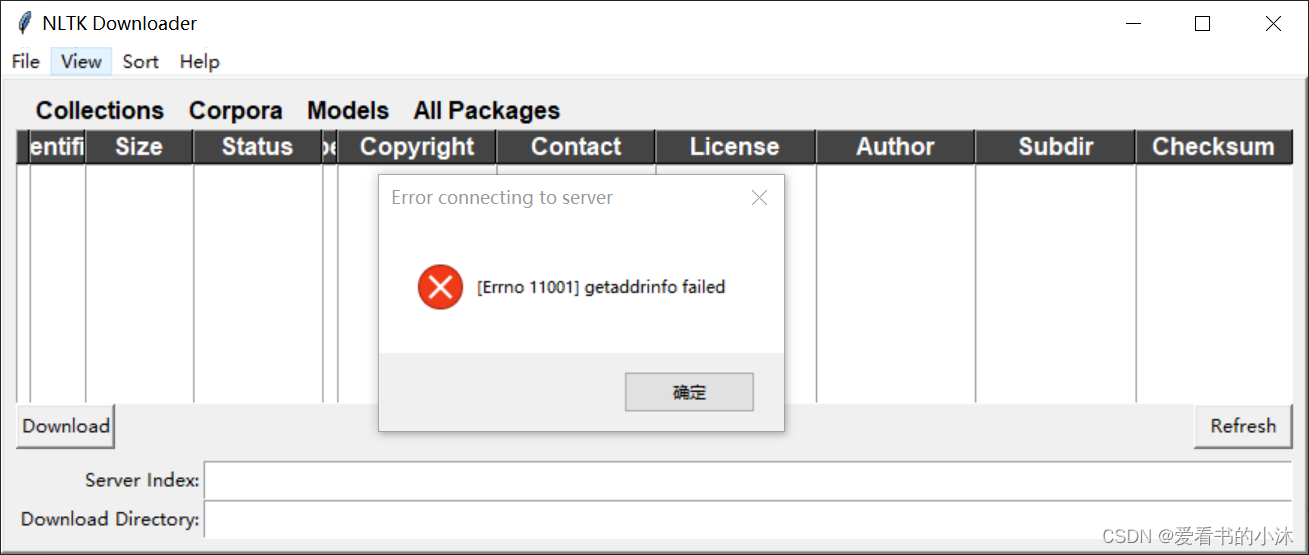
import nltk
nltk.download()
通过上面命令代码下载,大概率是失败的。
-
方法2:手动下载,离线安装
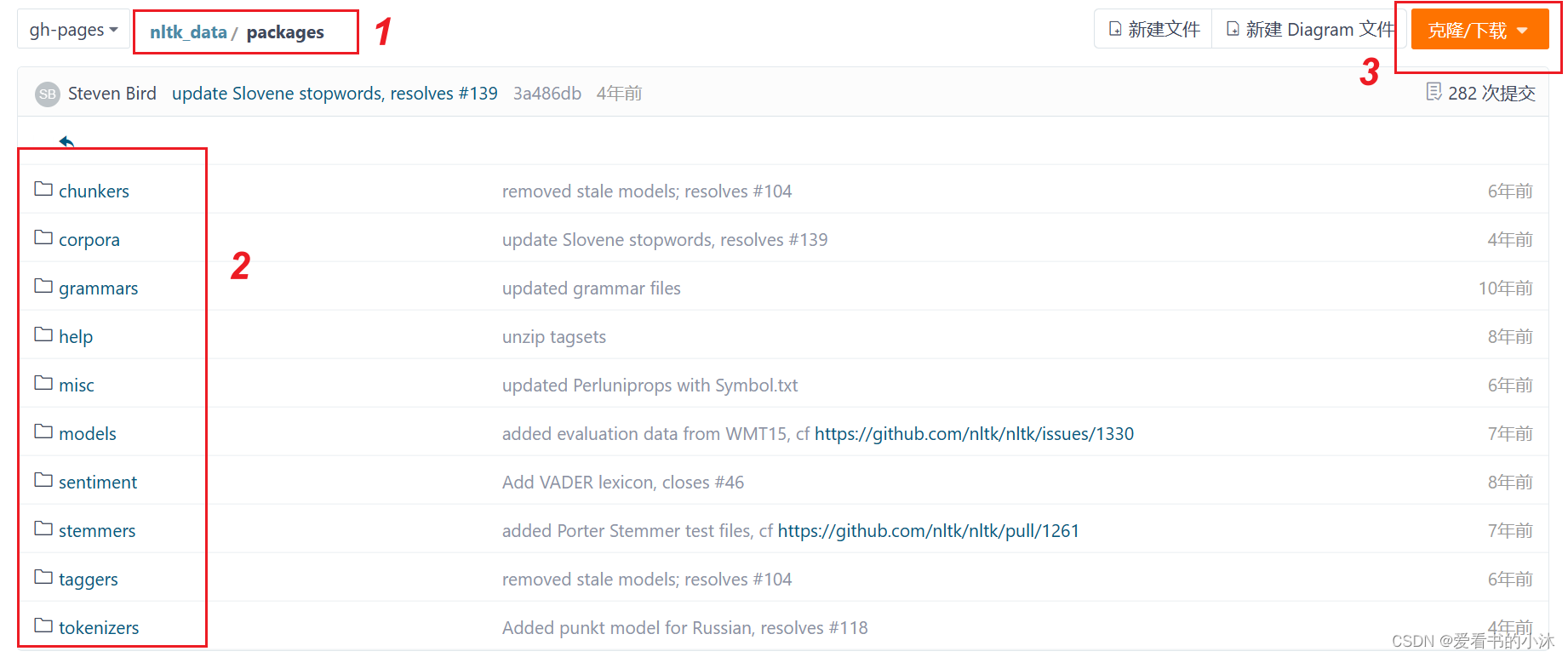
github:https://github.com/nltk/nltk_data/tree/gh-pages
gitee:https://gitee.com/qwererer2/nltk_data/tree/gh-pages
-
查看packages文件夹应该放在哪个路径下
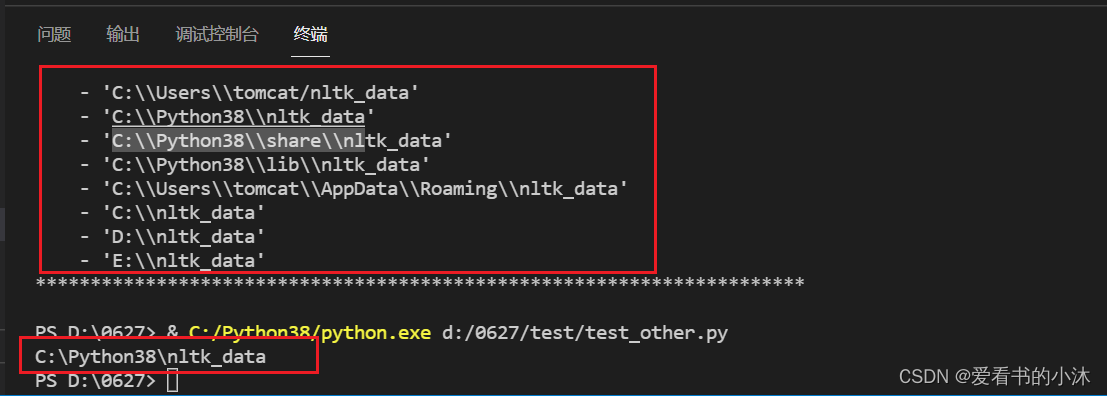
将下载的packages文件夹改名为nltk_data,放在如下文件夹:
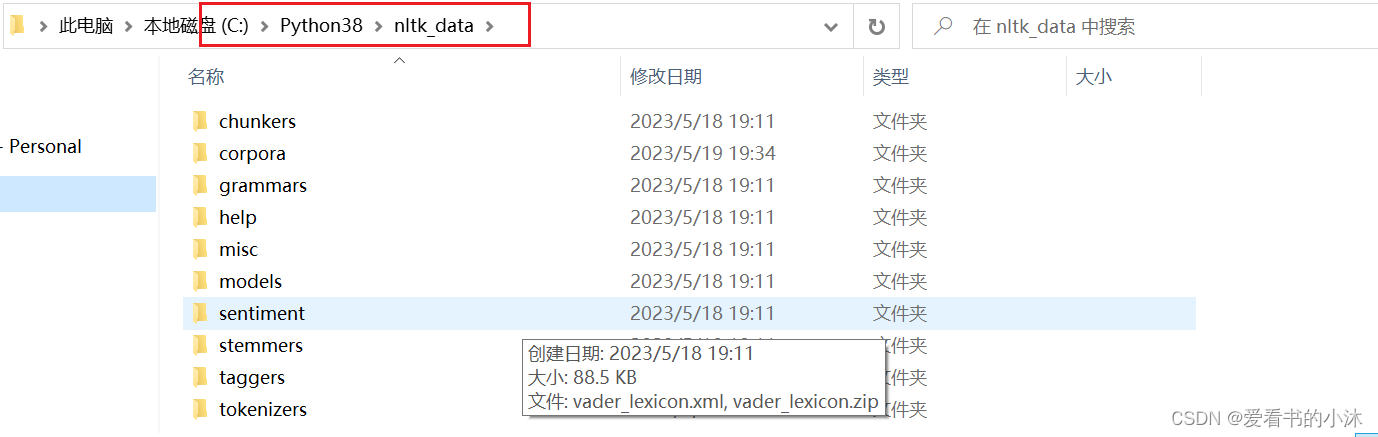
-
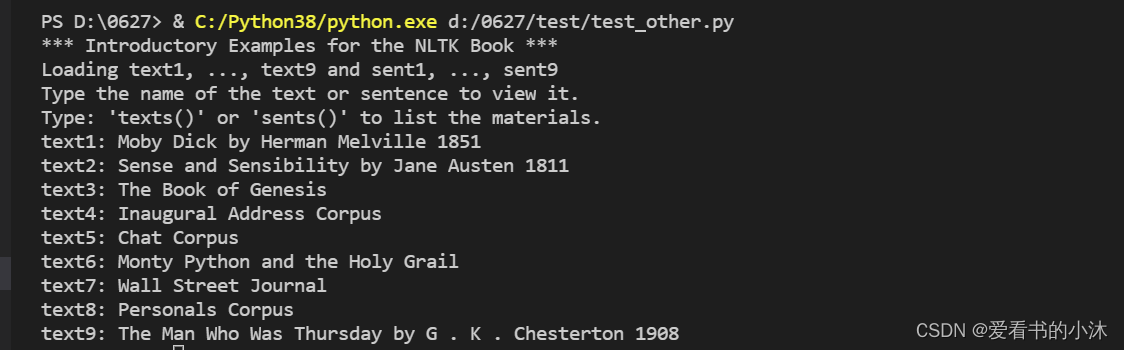
验证是否安装成功
from nltk.book import *
- 分词测试
import nltk
ret = nltk.word_tokenize("A pivot is the pin or the central point on which something balances or turns")
print(ret)

- wordnet词库测试
WordNet是一个在20世纪80年代由Princeton大学的著名认知心理学家George Miller团队构建的一个大型的英文词汇数据库。名词、动词、形容词和副词以同义词集合(synsets)的形式存储在这个数据库中。
import nltk
nltk.download('wordnet')
from nltk.corpus import wordnet as wn
from nltk.corpus import brown
print(brown.words())

3、测试
3.1 分句分词
英文分句:nltk.sent_tokenize :对文本按照句子进行分割
英文分词:nltk.word_tokenize:将句子按照单词进行分隔,返回一个列表
from nltk.tokenize import sent_tokenize, word_tokenizeEXAMPLE_TEXT = "Hello Mr. Smith, how are you doing today? The weather is great, and Python is awesome. The sky is pinkish-blue. You shouldn't eat cardboard."print(sent_tokenize(EXAMPLE_TEXT))
print(word_tokenize(EXAMPLE_TEXT))from nltk.corpus import stopwords
stop_word = set(stopwords.words('english')) # 获取所有的英文停止词
word_tokens = word_tokenize(EXAMPLE_TEXT) # 获取所有分词词语
filtered_sentence = [w for w in word_tokens if not w in stop_word] #获取案例文本中的非停止词
print(filtered_sentence)

3.2 停用词过滤
停止词:nltk.corpus的 stopwords:查看英文中的停止词表。
定义了一个过滤英文停用词的函数,将文本中的词汇归一化处理为小写并提取。从停用词语料库中提取出英语停用词,将文本进行区分。
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块
from nltk.corpus import stopwords #导入停止词模块
def remove_stopwords(text):text_lower=[w.lower() for w in text if w.isalpha()]stopword_set =set(stopwords.words('english'))result = [w for w in text_lower if w not in stopword_set]return resultexample_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
print(remove_stopwords(word_tokens))

from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text) from nltk.corpus import stopwords
test_words = [word.lower() for word in word_tokens]
test_words_set = set(test_words)
test_words_set.intersection(set(stopwords.words('english')))
filtered = [w for w in test_words_set if(w not in stopwords.words('english'))]
print(filtered)
3.3 词干提取
词干提取:是去除词缀得到词根的过程,例如:fishing、fished,为同一个词干 fish。Nltk,提供PorterStemmer进行词干提取。
from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize,word_tokenize
ps = PorterStemmer()
example_words = ["python","pythoner","pythoning","pythoned","pythonly"]
print(example_words)
for w in example_words:print(ps.stem(w),end=' ')

from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize,word_tokenize
ps = PorterStemmer()example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
print(example_text)
words = word_tokenize(example_text)for w in words:print(ps.stem(w), end=' ')

from nltk.stem import PorterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
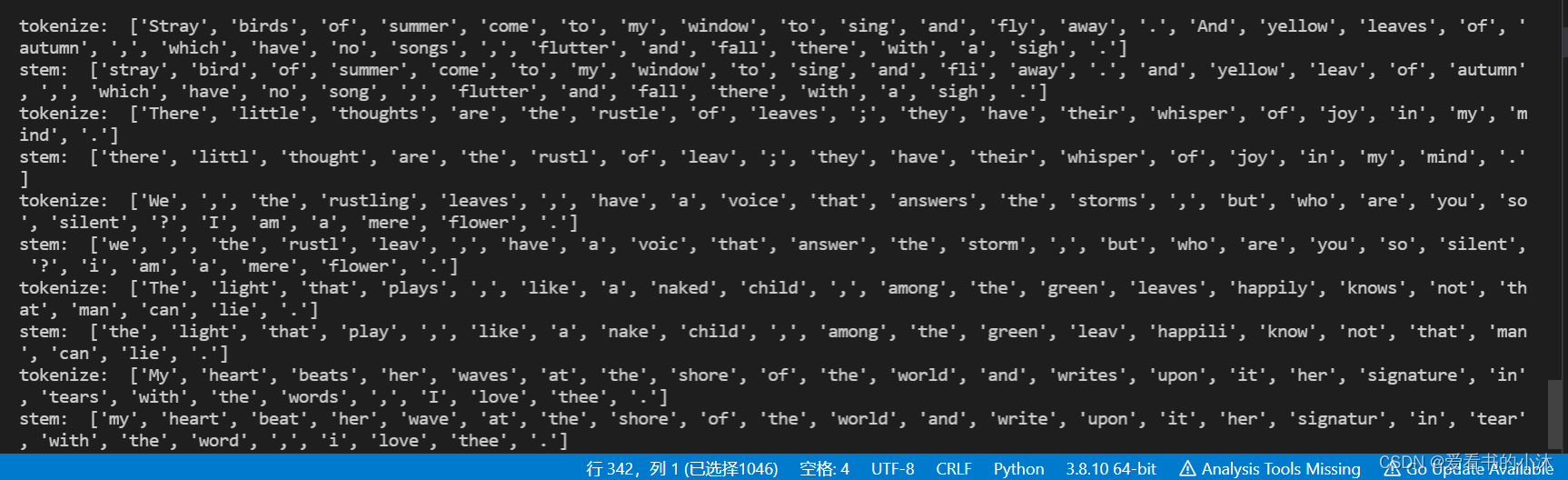
ps = PorterStemmer()example_text1 = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
example_text2 = "There little thoughts are the rustle of leaves; they have their whisper of joy in my mind."
example_text3 = "We, the rustling leaves, have a voice that answers the storms,but who are you so silent? I am a mere flower."
example_text4 = "The light that plays, like a naked child, among the green leaves happily knows not that man can lie."
example_text5 = "My heart beats her waves at the shore of the world and writes upon it her signature in tears with the words, I love thee."
example_text_list = [example_text1, example_text2, example_text3, example_text4, example_text5]for sent in example_text_list:words = word_tokenize(sent)print("tokenize: ", words)stems = [ps.stem(w) for w in words]print("stem: ", stems)
3.4 词形/词干还原
与词干提取类似,词干提取包含被创造出的不存在的词汇,而词形还原的是实际的词汇。
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print('cats\t',lemmatizer.lemmatize('cats'))
print('better\t',lemmatizer.lemmatize('better',pos='a'))

from nltk.stem import WordNetLemmatizerlemmatizer = WordNetLemmatizer()print(lemmatizer.lemmatize("cats"))
print(lemmatizer.lemmatize("cacti"))
print(lemmatizer.lemmatize("geese"))
print(lemmatizer.lemmatize("rocks"))
print(lemmatizer.lemmatize("python"))
print(lemmatizer.lemmatize("better", pos="a"))
print(lemmatizer.lemmatize("best", pos="a"))
print(lemmatizer.lemmatize("run"))
print(lemmatizer.lemmatize("run",'v'))
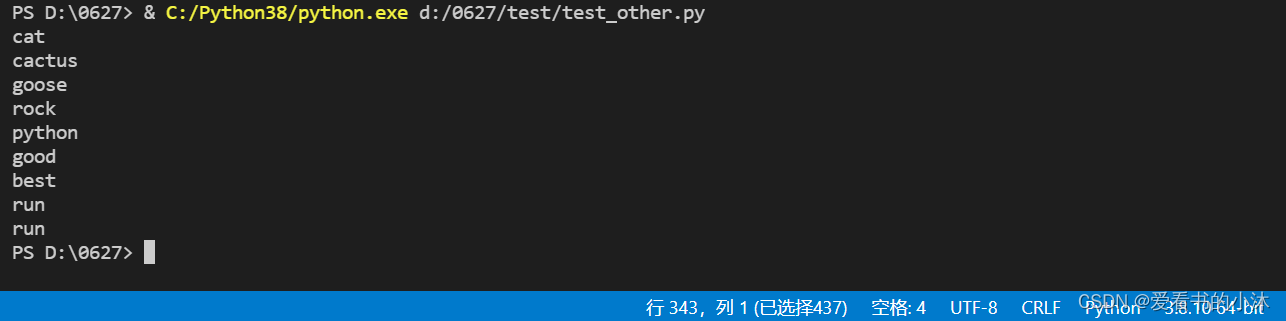
唯一要注意的是,lemmatize接受词性参数pos。 如果没有提供,默认是“名词”。
- 时态和单复数
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.stem import PorterStemmertokens = word_tokenize(text="All work and no play makes jack a dull boy, all work and no play,playing,played", language="english")
ps=PorterStemmer()
stems = [ps.stem(word)for word in tokens]
print(stems)from nltk.stem import SnowballStemmer
snowball_stemmer = SnowballStemmer('english')
ret = snowball_stemmer.stem('presumably')
print(ret)from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
ret = wordnet_lemmatizer.lemmatize('dogs')
print(ret)

3.5 同义词与反义词
nltk提供了WordNet进行定义同义词、反义词等词汇数据库的集合。
- 同义词
from nltk.corpus import wordnet
# 单词boy寻找同义词
syns = wordnet.synsets('girl')
print(syns[0].name())
# 只是单词
print(syns[0].lemmas()[0].name())
# 第一个同义词的定义
print(syns[0].definition())
# 单词boy的使用示例
print(syns[0].examples())

- 近义词与反义词
from nltk.corpus import wordnet
synonyms = [] # 定义近义词存储空间
antonyms = [] # 定义反义词存储空间
for syn in wordnet.synsets('bad'):for i in syn.lemmas():synonyms.append(i.name())if i.antonyms():antonyms.append(i.antonyms()[0].name())print(set(synonyms))
print(set(antonyms))

3.6 语义相关性
wordnet的wup_similarity() 方法用于语义相关性。
from nltk.corpus import wordnetw1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('boat.n.01')
print(w1.wup_similarity(w2))w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('car.n.01')
print(w1.wup_similarity(w2))w1 = wordnet.synset('ship.n.01')
w2 = wordnet.synset('cat.n.01')
print(w1.wup_similarity(w2))

NLTK 提供多种 相似度计分器(similarity scorers),比如:
- path_similarity
- lch_similarity
- wup_similarity
- res_similarity
- jcn_similarity
- lin_similarity
3.7 词性标注
把一个句子中的单词标注为名词,形容词,动词等。
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text) from nltk import pos_tag
tags = pos_tag(word_tokens)
print(tags)

- 标注释义如下
| POS Tag |指代 |
| --- | --- |
| CC | 并列连词 |
| CD | 基数词 |
| DT | 限定符|
| EX | 存在词|
| FW |外来词 |
| IN | 介词或从属连词|
| JJ | 形容词 |
| JJR | 比较级的形容词 |
| JJS | 最高级的形容词 |
| LS | 列表项标记 |
| MD | 情态动词 |
| NN |名词单数|
| NNS | 名词复数 |
| NNP |专有名词|
| PDT | 前置限定词 |
| POS | 所有格结尾|
| PRP | 人称代词 |
| PRP$ | 所有格代词 |
| RB |副词 |
| RBR | 副词比较级 |
| RBS | 副词最高级 |
| RP | 小品词 |
| UH | 感叹词 |
| VB |动词原型 |
| VBD | 动词过去式 |
| VBG |动名词或现在分词 |
| VBN |动词过去分词|
| VBP |非第三人称单数的现在时|
| VBZ | 第三人称单数的现在时 |
| WDT |以wh开头的限定词 |
POS tag list:CC coordinating conjunction
CD cardinal digit
DT determiner
EX existential there (like: "there is" ... think of it like "there exists")
FW foreign word
IN preposition/subordinating conjunction
JJ adjective 'big'
JJR adjective, comparative 'bigger'
JJS adjective, superlative 'biggest'
LS list marker 1)
MD modal could, will
NN noun, singular 'desk'
NNS noun plural 'desks'
NNP proper noun, singular 'Harrison'
NNPS proper noun, plural 'Americans'
PDT predeterminer 'all the kids'
POS possessive ending parent's
PRP personal pronoun I, he, she
PRP$ possessive pronoun my, his, hers
RB adverb very, silently,
RBR adverb, comparative better
RBS adverb, superlative best
RP particle give up
TO to go 'to' the store.
UH interjection errrrrrrrm
VB verb, base form take
VBD verb, past tense took
VBG verb, gerund/present participle taking
VBN verb, past participle taken
VBP verb, sing. present, non-3d take
VBZ verb, 3rd person sing. present takes
WDT wh-determiner which
WP wh-pronoun who, what
WP$ possessive wh-pronoun whose
WRB wh-abverb where, when
3.8 命名实体识别
命名实体识别(NER)是信息提取的第一步,旨在在文本中查找和分类命名实体转换为预定义的分类,例如人员名称,组织,地点,时间,数量,货币价值,百分比等。
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tagex= 'European authorities fined Google a record $5.1 billion on Wednesday for abusing its power in the mobile phone market and ordered the company to alter its practices'def preprocess(sent):sent= nltk.word_tokenize(sent)sent= nltk.pos_tag(sent)return sent# 单词标记和词性标注
sent= preprocess(ex)
print(sent)# 名词短语分块
pattern='NP: {<DT>?<JJ> * <NN>}'
cp= nltk.RegexpParser(pattern)
cs= cp.parse(sent)
print(cs)# IOB标签
from nltk.chunk import conlltags2tree, tree2conlltags
from pprint import pprint
iob_tagged= tree2conlltags(cs)
pprint(iob_tagged)# 分类器识别命名实体,类别标签(如PERSON,ORGANIZATION和GPE)
from nltk import ne_chunk
ne_tree= ne_chunk(pos_tag(word_tokenize(ex)))
print(ne_tree)

import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
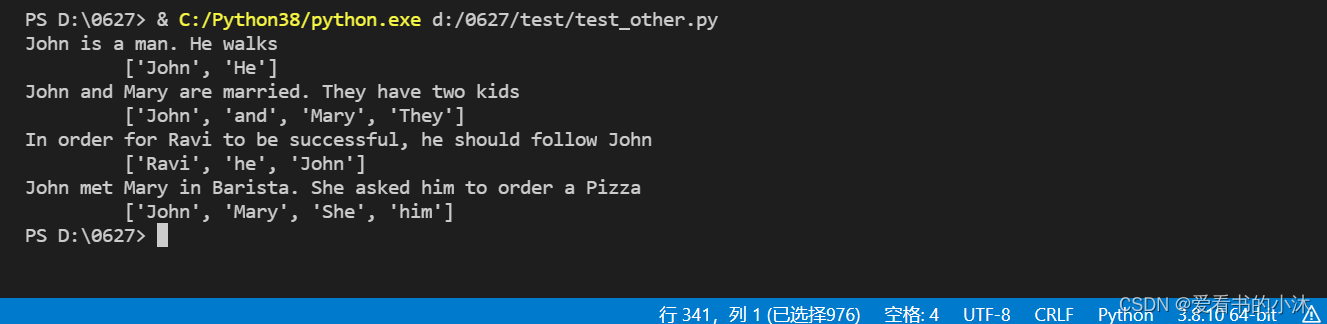
from nltk.chunk import conlltags2tree, tree2conlltagsdef learnAnaphora():sentences = ["John is a man. He walks","John and Mary are married. They have two kids","In order for Ravi to be successful, he should follow John","John met Mary in Barista. She asked him to order a Pizza"]for sent in sentences:chunks = nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent)), binary=False)stack = []print(sent)items = tree2conlltags(chunks)for item in items:if item[1] == 'NNP' and (item[2] == 'B-PERSON' or item[2] == 'O'):stack.append(item[0])elif item[1] == 'CC':stack.append(item[0])elif item[1] == 'PRP':stack.append(item[0])print("\t {}".format(stack)) learnAnaphora()
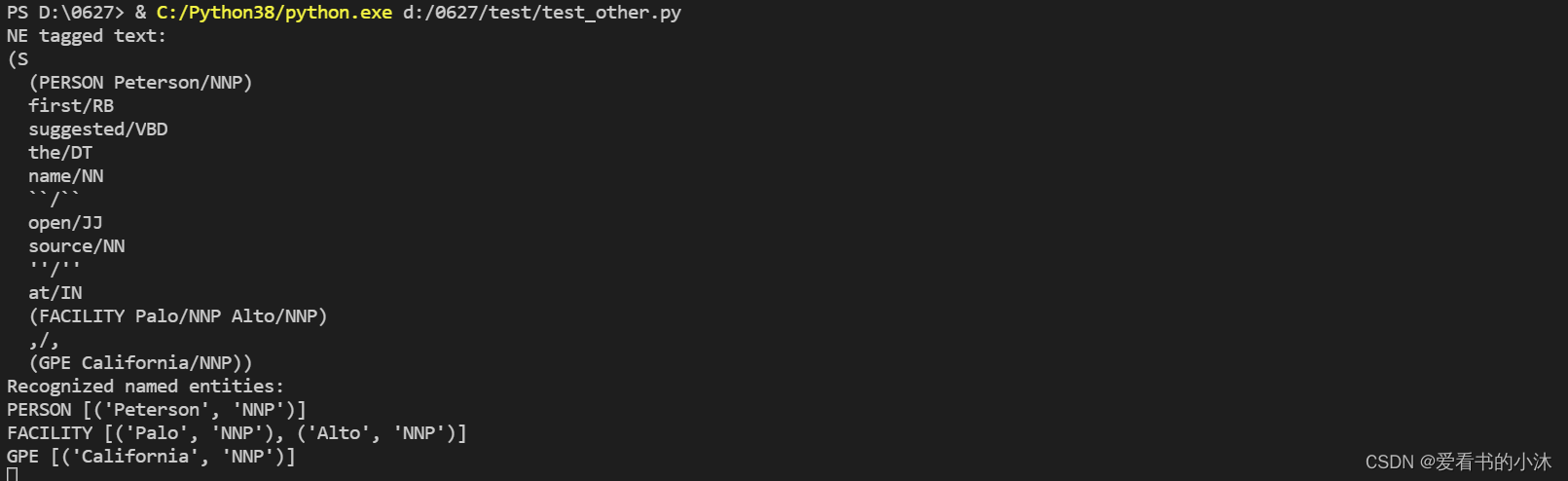
import nltksentence = 'Peterson first suggested the name "open source" at Palo Alto, California'# 先预处理
words = nltk.word_tokenize(sentence)
pos_tagged = nltk.pos_tag(words)# 运行命名实体标注器
ne_tagged = nltk.ne_chunk(pos_tagged)
print("NE tagged text:")
print(ne_tagged)# 只提取这个 树(tree)里的命名实体
print("Recognized named entities:")
for ne in ne_tagged:if hasattr(ne, "label"):print(ne.label(), ne[0:])ne_tagged.draw()

NLTK 内置的命名实体标注器(named-entity tagger),使用的是宾州法尼亚大学的 Automatic Content Extraction(ACE)程序。该标注器能够识别 组织机构(ORGANIZATION) 、人名(PERSON) 、地名(LOCATION) 、设施(FACILITY)和地缘政治实体(geopolitical entity)等常见实体(entites)。
NLTK 也可以使用其他标注器(tagger),比如 Stanford Named Entity Recognizer. 这个经过训练的标注器用 Java 写成,但 NLTK 提供了一个使用它的接口(详情请查看 nltk.parse.stanford 或 nltk.tag.stanford)。
3.9 Text对象
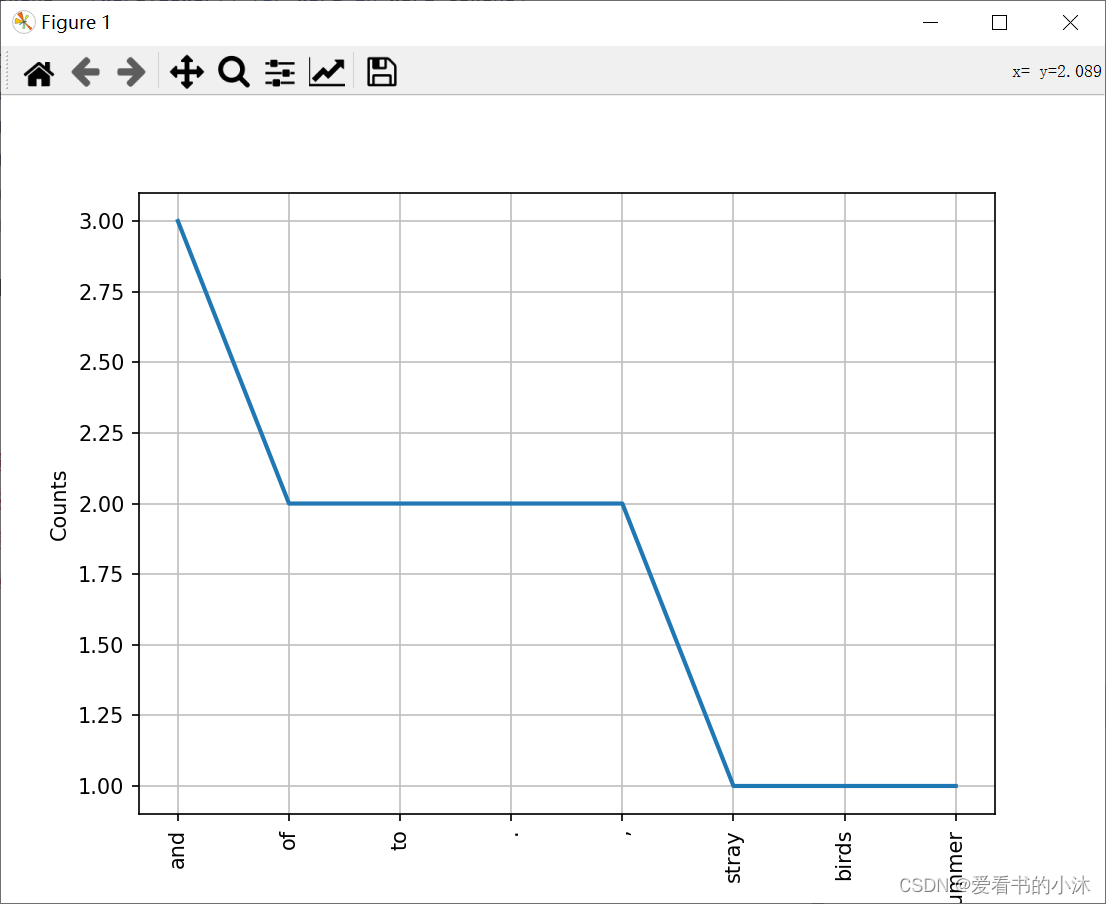
from nltk.tokenize import sent_tokenize, word_tokenize #导入 分句、分词模块example_text = "Stray birds of summer come to my window to sing and fly away. And yellow leaves of autumn,which have no songs,flutter and fall there with a sigh."
word_tokens = word_tokenize(example_text)
word_tokens = [word.lower() for word in word_tokens]from nltk.text import Text
t = Text(word_tokens)
print(t.count('and') )
print(t.index('and') )
t.plot(8)
3.10 文本分类
import nltk
import random
from nltk.corpus import movie_reviewsdocuments = [(list(movie_reviews.words(fileid)), category)for category in movie_reviews.categories()for fileid in movie_reviews.fileids(category)]random.shuffle(documents)print(documents[1])all_words = []
for w in movie_reviews.words():all_words.append(w.lower())all_words = nltk.FreqDist(all_words)
print(all_words.most_common(15))
print(all_words["stupid"])

3.11 其他分类器
- 下面列出的是NLTK中自带的分类器:
from nltk.classify.api import ClassifierI, MultiClassifierI
from nltk.classify.megam import config_megam, call_megam
from nltk.classify.weka import WekaClassifier, config_weka
from nltk.classify.naivebayes import NaiveBayesClassifier
from nltk.classify.positivenaivebayes import PositiveNaiveBayesClassifier
from nltk.classify.decisiontree import DecisionTreeClassifier
from nltk.classify.rte_classify import rte_classifier, rte_features, RTEFeatureExtractor
from nltk.classify.util import accuracy, apply_features, log_likelihood
from nltk.classify.scikitlearn import SklearnClassifier
from nltk.classify.maxent import (MaxentClassifier, BinaryMaxentFeatureEncoding,TypedMaxentFeatureEncoding,ConditionalExponentialClassifier)
- 通过名字预测性别
import nltk
from nltk.corpus import names
from nltk import classify#特征取的是最后一个字母
def gender_features(word):return {'last_letter': word[-1]}#数据准备
name=[(n,'male') for n in names.words('male.txt')]+[(n,'female') for n in names.words('female.txt')]
print(len(name))#特征提取和训练模型
features=[(gender_features(n),g) for (n,g) in name]
classifier = nltk.NaiveBayesClassifier.train(features[:6000])#测试
print(classifier.classify(gender_features('Frank')))
print(classify.accuracy(classifier, features[6000:]))print(classifier.classify(gender_features('Tom')))
print(classify.accuracy(classifier, features[6000:]))print(classifier.classify(gender_features('Sonya')))
print(classify.accuracy(classifier, features[6000:]))

- 情感分析
import nltk.classify.util
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import namesdef word_feats(words):return dict([(word, True) for word in words])#数据准备
positive_vocab = ['awesome', 'outstanding', 'fantastic', 'terrific', 'good', 'nice', 'great', ':)']
negative_vocab = ['bad', 'terrible', 'useless', 'hate', ':(']
neutral_vocab = ['movie', 'the', 'sound', 'was', 'is', 'actors', 'did', 'know', 'words', 'not']#特征提取
positive_features = [(word_feats(pos), 'pos') for pos in positive_vocab]
negative_features = [(word_feats(neg), 'neg') for neg in negative_vocab]
neutral_features = [(word_feats(neu), 'neu') for neu in neutral_vocab]train_set = negative_features + positive_features + neutral_features#训练
classifier = NaiveBayesClassifier.train(train_set)# 测试
neg = 0
pos = 0
sentence = "Awesome movie, I liked it"
sentence = sentence.lower()
words = sentence.split(' ')
for word in words:classResult = classifier.classify(word_feats(word))if classResult == 'neg':neg = neg + 1if classResult == 'pos':pos = pos + 1print('Positive: ' + str(float(pos) / len(words)))
print('Negative: ' + str(float(neg) / len(words)))

3.12 数据清洗
- 去除HTML标签,如 &
text_no_special_html_label = re.sub(r'\&\w+;|#\w*|\@\w*','',text)
print(text_no_special_html_label)
- 去除链接标签
text_no_link = re.sub(r'http:\/\/.*|https:\/\/.*','',text_no_special_html_label)
print(text_no_link)
- 去除换行符
text_no_next_line = re.sub(r'\n','',text_no_link)
print(text_no_next_line)
- 去除带有$符号的
text_no_dollar = re.sub(r'\$\w*\s','',text_no_next_line)
print(text_no_dollar)
- 去除缩写专有名词
text_no_short = re.sub(r'\b\w{1,2}\b','',text_no_dollar)
print(text_no_short)
- 去除多余空格
text_no_more_space = re.sub(r'\s+',' ',text_no_short)
print(text_no_more_space)
- 使用nltk分词
tokens = word_tokenize(text_no_more_space)
tokens_lower = [s.lower() for s in tokens]
print(tokens_lower)
- 去除停用词
import re
from nltk.corpus import stopwordscache_english_stopwords = stopwords.words('english')
tokens_stopwords = [s for s in tokens_lower if s not in cache_english_stopwords]
print(tokens_stopwords)
print(" ".join(tokens_stopwords))
除了NLTK,这几年spaCy的应用也非常广泛,功能与nltk类似,但是功能更强,更新也快,语言处理上也具有很大的优势。
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!
相关文章:
【小沐学NLP】Python使用NLTK库的入门教程
文章目录 1、简介2、安装2.1 安装nltk库2.2 安装nltk语料库 3、测试3.1 分句分词3.2 停用词过滤3.3 词干提取3.4 词形/词干还原3.5 同义词与反义词3.6 语义相关性3.7 词性标注3.8 命名实体识别3.9 Text对象3.10 文本分类3.11 其他分类器3.12 数据清洗 结语 1、简介 NLTK - 自然…...
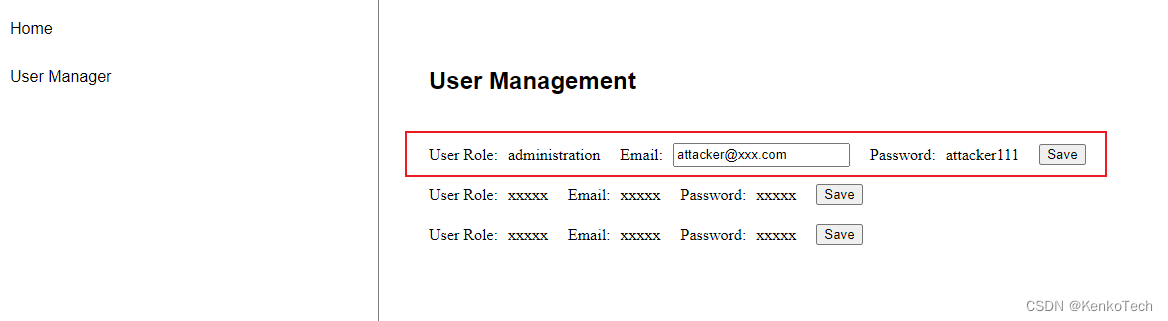
Angular安全专辑之三 —— 授权绕过,利用漏洞控制管理员账户
这篇文章是针对实际项目中所出现的问题所做的一个总结。简单来说,就是授权绕过问题,管理员帐户被错误的接管。 详细情况是这样的,我们的项目中通常都会有用户身份验证功能,不同的用户拥有不同的权限。相对来说管理员账户所对应的…...
使用Sumo以及traci实现交叉口信号灯自适应控制
使用Sumo以及traci实现交叉口信号灯自适应控制 文章目录 使用Sumo以及traci实现交叉口信号灯自适应控制 使用Sumo以及traci实现交叉口信号灯感应控制一、什么是交叉口感应控制二、Traci中的感应控制实现流程1.感应控制逻辑2.仿真过程 使用Sumo以及traci实现交叉口信号灯感应控制…...
自定义类型:结构体、枚举、联合
目录 结构体 结构体的基础知识 结构的声明 特殊的声明 结构体的自引用 结构体变量的定义和初始化 结构体内存对齐 修改默认对齐数 结构体传参 位段 什么是位段 位段的内存分配 位段的跨平台问题 位段的应用 枚举 枚举类型的定义 枚举的优点 联合体(共…...

如何使用ZIP方式安装MySQL:简单、快速、高效的安装方法
下载MySQL的zip文件:从官方网站 https://dev.mysql.com/downloads/mysql/ 下载适用于您的操作系统的MySQL zip压缩包。 版本介绍(zip一般选第ZIP Archive版本) “Windows (x86, 64-bit), ZIP Archive” 是MySQL的发布版本,提供了MySQL服务器和相关的工具…...

python嵌套循环
在 Python 中,你可以使用嵌套循环来创建双循环,也就是一个循环包含在另一个循环中。通常有两种类型的双循环:嵌套循环和同时迭代多个迭代器的循环。我会详细说明这两种情况。 1. 嵌套循环: 嵌套循环是指一个循环嵌套在另一个循环…...

一文速学-让神经网络不再神秘,一天速学神经网络基础(五)-最优化
前言 思索了很久到底要不要出深度学习内容,毕竟在数学建模专栏里边的机器学习内容还有一大半算法没有更新,很多坑都没有填满,而且现在深度学习的文章和学习课程都十分的多,我考虑了很久决定还是得出神经网络系列文章,…...
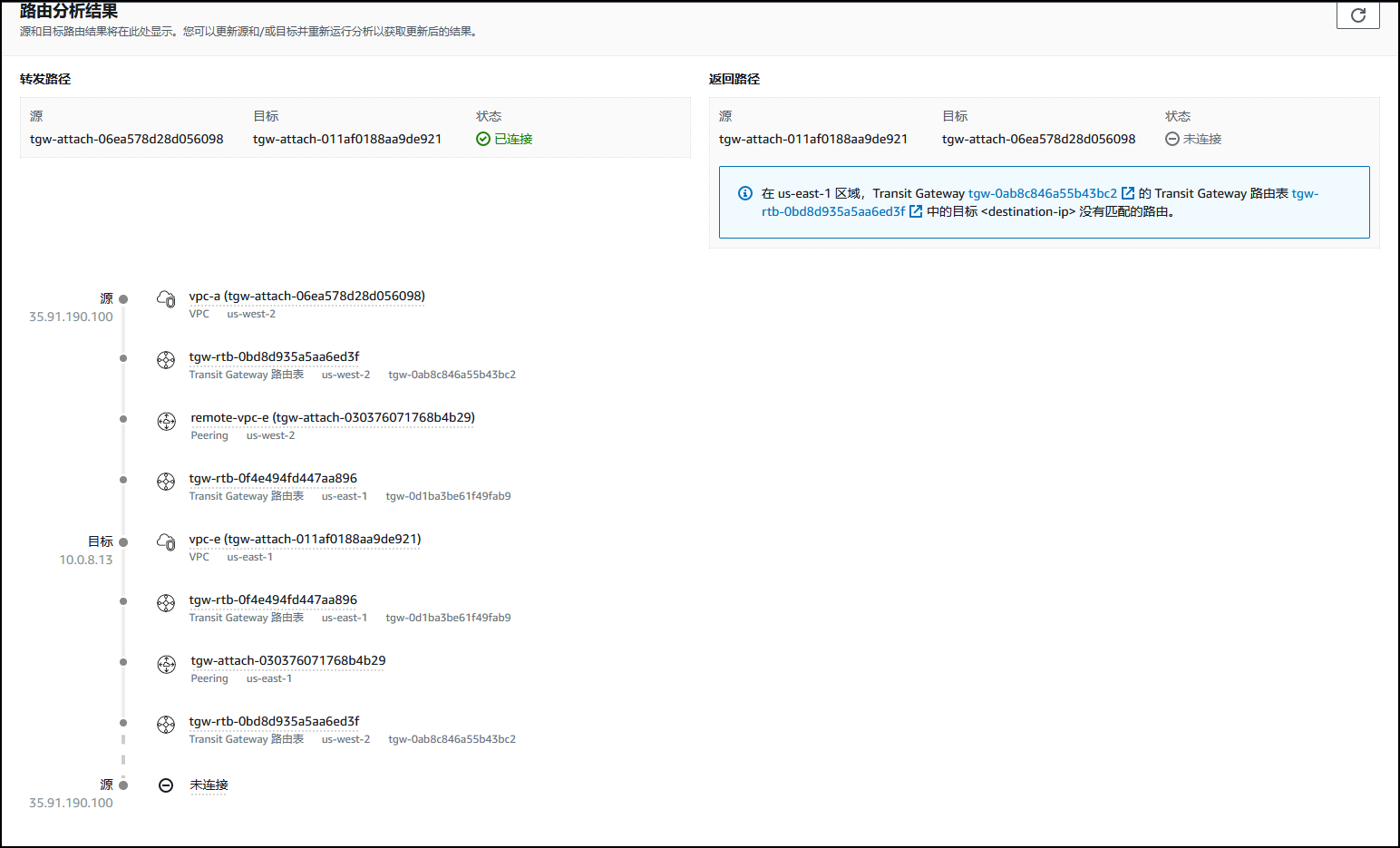
【AWS实验】 配置中转网关及对等连接
文章目录 实验概览目标实验环境任务 1:查看网络拓扑并创建基准任务 2:创建中转网关任务 3:创建中转网关挂载任务 4:创建中转网关路由表任务 4.1:创建路由表关联任务 4.2:创建路由传播 任务 5:更…...
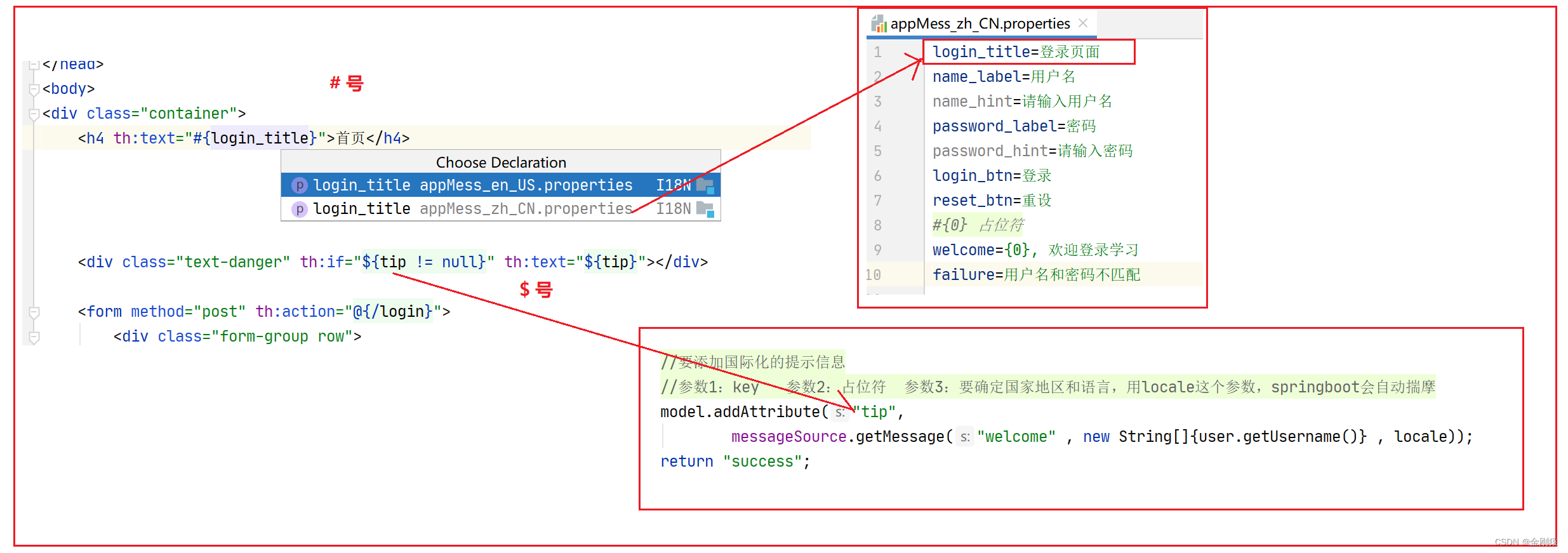
47、springboot 的 国际化消息支持--就是根据浏览器选择的语言,项目上的一些提示信息根据语言的选择进行对应的显示
springboot的国际化也是基于spring mvc 的。 springboot 的 国际化消息支持–就是根据浏览器选择的语言,项目上的一些提示信息根据语言的选择进行对应的显示。 总结下国家化自动配置: 功能实现就是: 比如一个登录页面,我们在浏览…...

重要变更 | Hugging Face Hub 的 Git 操作不再支持使用密码验证
在 Hugging Face,我们一直致力于提升服务安全性,因此,我们将修改 Hugging Face Hub 的 Git 交互认证方式。 从 2023 年 10 月 1 日 开始,我们将不再接受密码作为命令行 Git 操作的认证方式。我们推荐使用更安全的认证方法…...

为什么删除Windows 11上的Bloatware可以帮助加快你的电脑速度
如果你感觉你的电脑迟钝,彻底清除软件会有所帮助,而且这个过程对Windows用户来说越来越容易。 微软正在使删除以前难以删除的其他预装Windows应用程序成为可能。专家表示,这项新功能可能会改变用户的游戏规则。 科技公司Infatica的主管Vlad…...
)
PCL点云处理之计算两条直线间最短连线的端点 (二百零三)
PCL点云处理之计算两条直线间最短连线的端点 (二百零三) 一、算法目的二、具体实现1.代码2.结果一、算法目的 条件:给定两条直线,直线采用直线上一点和直线方向来确定 要求:求两条直线间的最短连线线段,获取它的两个端点 具体的算法实现如下,提供了示例直线和计算结果进…...
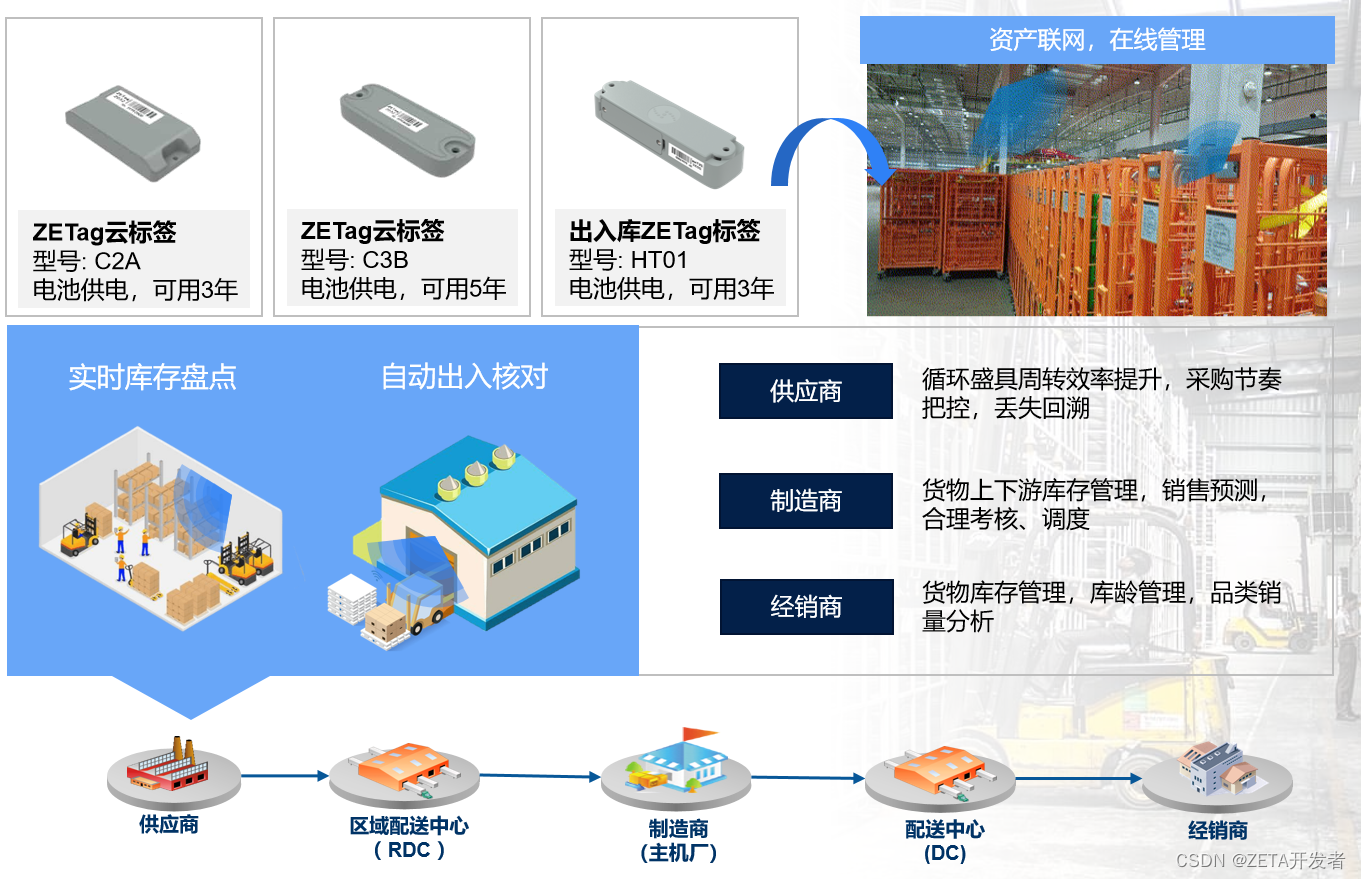
纵行科技与山鹰绿能达成合作,提供物联网资产管理数据服务
近日,纵行科技与山鹰绿能宣布双方达成深度合作关系,纵行科技将为山鹰绿能提供专业的物联网技术服务,使用物联网技术帮助山鹰绿能对循环包装载具等资产进行在线管理和数字化运营。 据悉,山鹰绿能是一家由山鹰国际控股的全资子公司…...

【2511. 最多可以摧毁的敌人城堡数目】
来源:力扣(LeetCode) 描述: 给你一个长度为 n ,下标从 0 开始的整数数组 forts ,表示一些城堡。forts[i] 可以是 -1 ,0 或者 1 ,其中: -1 表示第 i 个位置 没有 城堡。…...
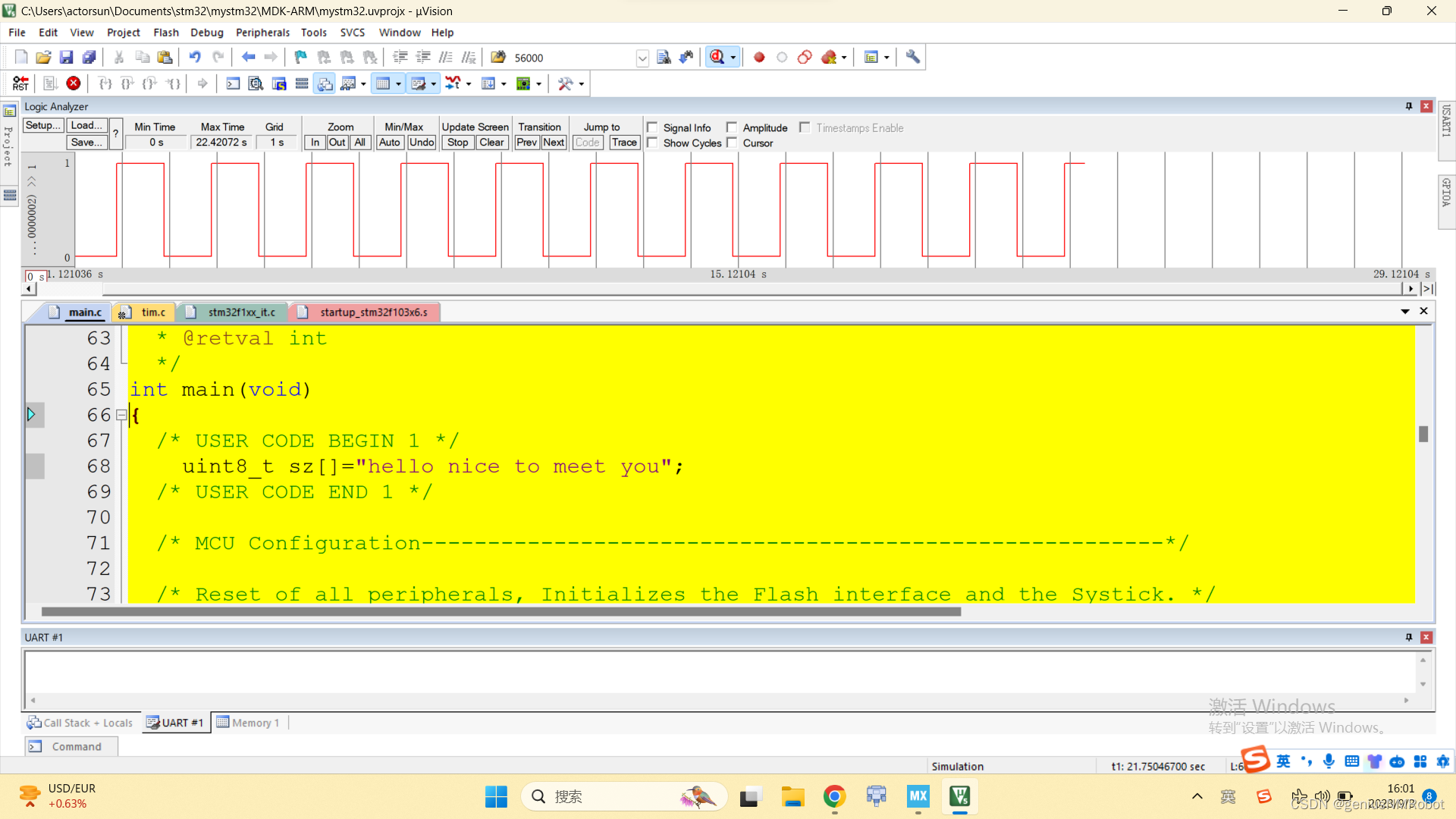
stm32f1xx单片机拦截中断源代码
这个是实现后的效果,可以看到已经没有中断的效果了 这个是拦截前的效果可以看到电平是在变化的 实现原理非常简单:一句话搞定: if(TIM2->CNTTIM2->ARR-5)TIM2->CNT-5; 以下是完整的代码:是用来补充说明和筹字数的 /* …...
:特殊工具与技术)
C++(21):特殊工具与技术
控制内存分配 某些应用程序对内存分配有特殊需求,无法直接应用标准内存管理机制。需要自定义内存分配的细节。 重载 new 和 delete void* operator new(std::size_t size) {// 自定义内存分配逻辑void* ptr std::malloc(size);if (!ptr) {throw std::bad_alloc(…...

go读取yaml,json,ini等配置文件
实际项目中,要读取一些json等配置文件。今天就来说一说,Golang 是如何读取YAML,JSON,INI等配置文件的。 一. go读取json配置文件 JSON 应该比较熟悉,它是一种轻量级的数据交换格式。层次结构简洁清晰 ,易于阅读和编写࿰…...
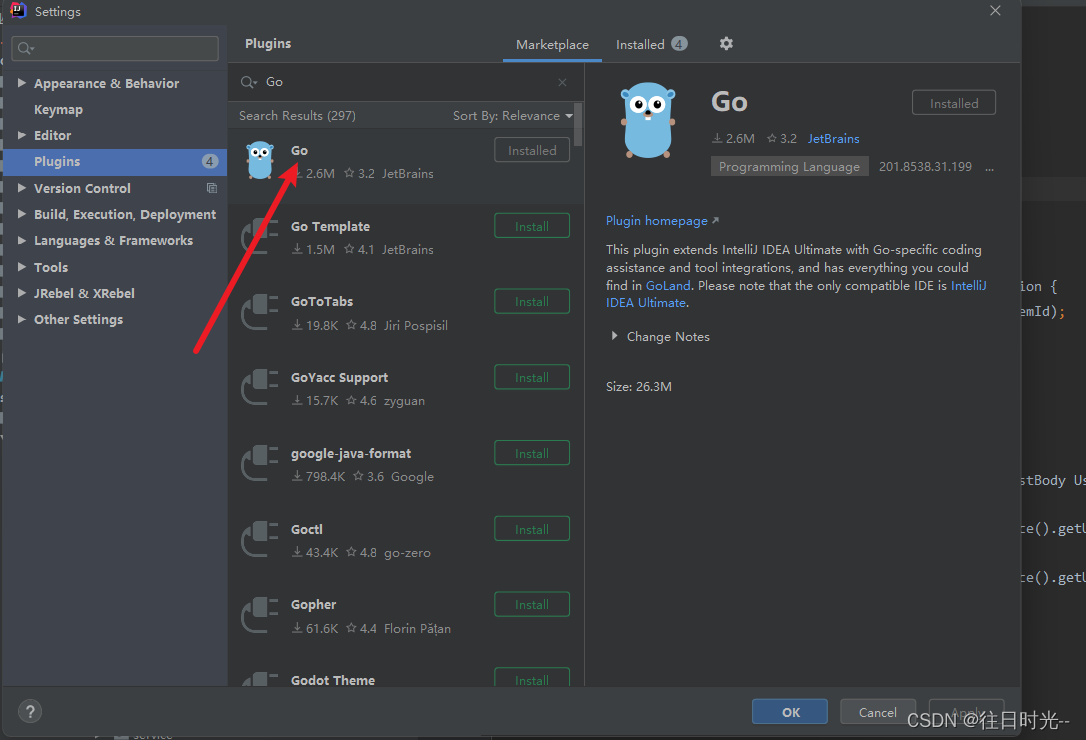
一、安装GoLang环境和开发工具
一、安装GoLang环境 GoLang中国镜像站 下载后对应的环境包以后,一路下一步就好了,安装路径的话,尽量就安装到默认的文件目录下。 二、配置Go的环境变量 右击此电脑–>属性–>高级系统设置–>环境变量,打开环境变量设置…...

条款40:对并发使用std::atomic,对特种内存使用valatile
可怜的volatile。被误解到如此地步。它甚至不应该出现在本章中,因为它与并发程序设计毫无关系。但是在其他程序设计语言中(Java和C#),它还是会对并发程序设计有些用处。甚至在C++中,一些编译器也已经把volatile投入到染缸,使得它的语义显得可以用于并发软件中(但是仅可用…...
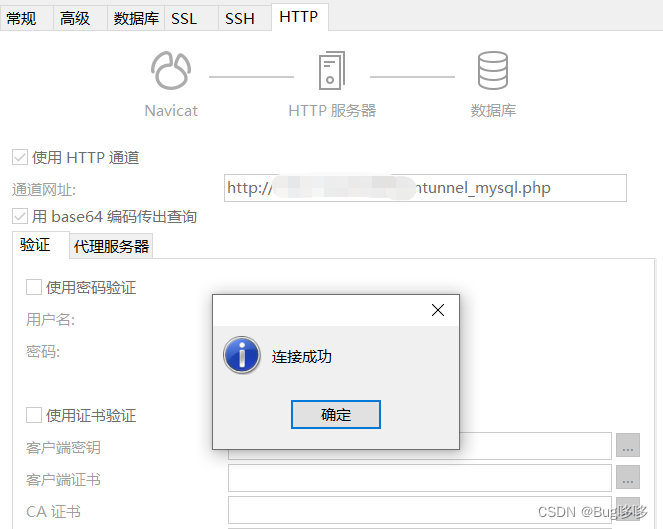
Navicat使用HTTP通道服务器进行连接mysql数据库(超简单三分钟完成),centos安装nginx和php,docker安装nginx+php合并版
序言 因为数据库服务器在外网是不能直接连接访问的,但是可以访问网站,网站后台就能访问数据库,所以在此之前,访问数据库的数据是一件非常麻烦的事情,在平时和运维的交流中发现,他们会使用ssh通道进行连接访…...

诚信标签工厂端解决方案 适配俄标 CRPT 体系一体化技术方案
俄罗斯诚实标签依托 CRPT 体系执行强制管控,各类出口货品必须完成 Data Matrix 编码采集、格式转换、多层包装数据绑定,数据合规后方可通关流通。美妆食品、日化建材、玩具五金等品类包装形态差异较大,人工采集方式普遍存在识别精度不足、批量…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

智能体所有权与版权:AI Agent Harness Engineering 创造的作品归谁所有?
1. 标题选项 《AI Agent创作版权迷局破解:从Harness工程原理到所有权划分的完整指南》 《智能体作品归谁?AI Agent Harness Engineering场景下的版权规则深度拆解》 《告别权属纠纷:一文搞懂AI Agent生成内容的所有权、版权与收益分配规则》 《Harness工程视角下的AI创作权:…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

孤舟笔记 互联网常用框架篇三 Dubbo是如何动态感知服务下线的?注册中心和服务端双保险
文章目录先说结论机制一:注册中心通知机制二:心跳检测机制三:连接事件感知机制四:定时拉取四种机制的协作回答技巧与点评加分回答面试官点评个人网站微服务环境下,服务实例随时可能上下线——重启、扩容、宕机……调用…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

总线式智能提示灯系统设计:从恒流驱动到模块化架构
1. 项目概述:从传统到智能的剧场提示灯系统革新在剧场、演播室或者大型活动现场的后台,如果你待过,一定对那套“红灯停,绿灯行”的提示灯系统不陌生。导演或舞台监督通过对讲机喊“Standby”(准备)…...

Playwright文件上传避坑指南:遇到动态生成的文件选择框怎么办?
Playwright文件上传避坑指南:动态生成文件选择框的实战解决方案最近在为一个电商平台做自动化测试时,遇到了一个棘手的问题——商品图片上传功能总是失败。页面上的"上传图片"按钮明明可以点击,但传统的set_input_files()方法却毫无…...

抖音批量下载工具:免费获取无水印视频的终极解决方案
抖音批量下载工具:免费获取无水印视频的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...