Sharding-JDBC分库分表-自动配置与分片规则加载原理-3
Sharding JDBC自动配置的原理
与所有starter一样,shardingsphere-jdbc-core-spring-boot-starter也是通过SPI自动配置的原理实现分库分表配置加载,spring.factories文件中的自动配置类shardingsphere-jdbc-core-spring-boot-starter功不可没,他主要是自动创建了模式bean、事务类型bean和数据源bean,配置加载的过程可以归纳如下:
其中,创建数据源bean时会根据不同的模式创建不同的bean,本地模式直接从配置文件中加载,配置中心模式就从配置中心加载。ShardingSphereAutoConfiguration的实现如下:
@Configuration
@ComponentScan("org.apache.shardingsphere.spring.boot.converter")
@EnableConfigurationProperties(SpringBootPropertiesConfiguration.class)
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
@RequiredArgsConstructor
public class ShardingSphereAutoConfiguration implements EnvironmentAware {private String databaseName;private final SpringBootPropertiesConfiguration props;private final Map<String, DataSource> dataSourceMap = new LinkedHashMap<>();/*** 模式配置** @return mode configuration*/@Beanpublic ModeConfiguration modeConfiguration() {return null == props.getMode() ? null : new YamlModeConfigurationSwapper().swapToObject(props.getMode());}/*** 单机模式:从本地配置中加载DataSource** @param rules rules configuration* @param modeConfig mode configuration* @return data source bean* @throws SQLException SQL exception*/@Bean@Conditional(LocalRulesCondition.class)@Autowired(required = false)public DataSource shardingSphereDataSource(final ObjectProvider<List<RuleConfiguration>> rules, final ObjectProvider<ModeConfiguration> modeConfig) throws SQLException {Collection<RuleConfiguration> ruleConfigs = Optional.ofNullable(rules.getIfAvailable()).orElseGet(Collections::emptyList);return ShardingSphereDataSourceFactory.createDataSource(databaseName, modeConfig.getIfAvailable(), dataSourceMap, ruleConfigs, props.getProps());}/*** 集群模式:从配置中心中加载DataSource** @param modeConfig mode configuration* @return data source bean* @throws SQLException SQL exception*/@Bean@ConditionalOnMissingBean(DataSource.class)public DataSource dataSource(final ModeConfiguration modeConfig) throws SQLException {return !dataSourceMap.isEmpty() ? ShardingSphereDataSourceFactory.createDataSource(databaseName, modeConfig, dataSourceMap, Collections.emptyList(), props.getProps()): ShardingSphereDataSourceFactory.createDataSource(databaseName, modeConfig);}/*** 事务类型扫描bean** @return transaction type scanner*/@Beanpublic TransactionTypeScanner transactionTypeScanner() {return new TransactionTypeScanner();}@Overridepublic final void setEnvironment(final Environment environment) {dataSourceMap.putAll(DataSourceMapSetter.getDataSourceMap(environment));databaseName = DatabaseNameSetter.getDatabaseName(environment);}
}
下面以单机模式出发点,理一下加载的过程。
@Bean
@Conditional(LocalRulesCondition.class)
@Autowired(required = false)
public DataSource shardingSphereDataSource(final ObjectProvider<List<RuleConfiguration>> rules, final ObjectProvider<ModeConfiguration> modeConfig) throws SQLException {Collection<RuleConfiguration> ruleConfigs = Optional.ofNullable(rules.getIfAvailable()).orElseGet(Collections::emptyList);// 通过ShardingSphereDataSourceFactory工厂创建数据源return ShardingSphereDataSourceFactory.createDataSource(databaseName, modeConfig.getIfAvailable(), dataSourceMap, ruleConfigs, props.getProps());
}
通过对源码的跟踪,可以发现,ShardingSphereDataSourceFactory.createDataSource创建数据源经历了如下的过程
分片规则加载原理
分片规则、审计规则、key生成规则都是通过SPI的方式加载,自动配置类ShardingSphereAutoConfiguration中创建ShardingSphereDataSource的时候,会加载配置的分片规则,创建核心配置类ShardingRule,在ShardingRule的创建中会通过SPI的方式加载分片规则。加载的过程如下:
SPI核心实现类ShardingSphereServiceLoader中会将SPI接口进行Map缓存管理,需要时直接获取。如果Map中不存在,就通过反射的方式新建服务实例,具体实现源码如下:
public final class ShardingSphereServiceLoader {// 缓存service实例,// 缓存的Key,如:// org.apache.shardingsphere.sharding.spi.ShardingAlgorithm// org.apache.shardingsphere.sharding.spi.KeyGenerateAlgorithm// org.apache.shardingsphere.transaction.spi.ShardingSphereTransactionManagerprivate static final Map<Class<?>, Collection<Object>> SERVICES = new ConcurrentHashMap<>();/*** 注册服务实例** @param 服务接口*/public static void register(final Class<?> serviceInterface) {if (!SERVICES.containsKey(serviceInterface)) {SERVICES.put(serviceInterface, load(serviceInterface));}}private static <T> Collection<Object> load(final Class<T> serviceInterface) {Collection<Object> result = new LinkedList<>();for (T each : ServiceLoader.load(serviceInterface)) {result.add(each);}return result;}/*** 获取服务实例* * @param 服务接口* @param <T> 服务类型* @return 服务实例*/public static <T> Collection<T> getServiceInstances(final Class<T> serviceInterface) {return null == serviceInterface.getAnnotation(SingletonSPI.class) ? createNewServiceInstances(serviceInterface) : getSingletonServiceInstances(serviceInterface);}@SneakyThrows(ReflectiveOperationException.class)@SuppressWarnings("unchecked")private static <T> Collection<T> createNewServiceInstances(final Class<T> serviceInterface) {if (!SERVICES.containsKey(serviceInterface)) {return Collections.emptyList();}Collection<Object> services = SERVICES.get(serviceInterface);if (services.isEmpty()) {return Collections.emptyList();}Collection<T> result = new LinkedList<>();for (Object each : services) {// 通过反射新建实例result.add((T) each.getClass().getDeclaredConstructor().newInstance());}return result;}@SuppressWarnings("unchecked")private static <T> Collection<T> getSingletonServiceInstances(final Class<T> serviceInterface) {return (Collection<T>) SERVICES.getOrDefault(serviceInterface, Collections.emptyList());}
}
相关文章:

Sharding-JDBC分库分表-自动配置与分片规则加载原理-3
Sharding JDBC自动配置的原理 与所有starter一样,shardingsphere-jdbc-core-spring-boot-starter也是通过SPI自动配置的原理实现分库分表配置加载,spring.factories文件中的自动配置类shardingsphere-jdbc-core-spring-boot-starter功不可没,…...

E8267D 是德科技矢量信号发生器
描述 最先进的微波信号发生器 安捷伦E8267D PSG矢量信号发生器是业界首款集成式微波矢量信号发生器,I/Q调制最高可达44 GHz,典型输出功率为23 dBm,最高可达20 GHz,对于10 GHz信号,10 kHz偏移时的相位噪声为-120 dBc/…...

Git git fetch 和 git pull 区别
git pull和git fetch的作用都是用于从远程仓库获取最新代码,但它们之间有一些区别。 git pull会自动执行两个操作:git fetch和git merge。它从远程仓库获取最新代码,并将其合并到当前分支中。 示例:运行git pull origin master会从…...

软件UI工程师工作的岗位职责(合集)
软件UI工程师工作的岗位职责1 职责: 1.负责产品的UI视觉设计(手机软件界面 网站界面 图标设计产品广告及 企业文化的创意设计等); 2.负责公司各种客户端软件客户端的UE/UI界面及相关图标制作; 3.设定产品界面的整体视觉风格; 4.参与产品规划构思和创意过程&…...
Mac系统Anaconda环境配置Python的json库
本文介绍在Mac电脑的Anaconda环境中,配置Python语言中,用以编码、解码、处理JSON数据的json库的方法;在Windows电脑中配置json库的方法也是类似的,大家可以一并参考。 JSON(JavaScript Object Notation)是一…...

Python数据分析与数据挖掘:解析数据的力量
引言: 随着大数据时代的到来,数据分析和数据挖掘已经成为许多行业中不可或缺的一部分。在这个信息爆炸的时代,如何从大量的数据中提取有价值的信息,成为了企业和个人追求的目标。而Python作为一种强大的编程语言,提供…...
)
我的私人笔记(安装hive)
1.hive下载:Index of /dist/hive/hive-1.2.1 或者上传安装包至/opt/software:rz或winscp上传 2.解压 cd /opt/software tar -xzvf apache-hive-1.2.1-bin.tar.gz -C /opt/servers/ 3.重命名 mv apache-hive-1.2.1-bin hive 4.配置环境变量 vi /etc/…...
【kubernetes】k8s部署APISIX及在KubeSphere使用APISIX
Apache APISIX https://apisix.apache.org/ 功能比nginx-ingress更强 本文采用2.5.0版本 https://apisix.apache.org/zh/docs/apisix/2.15/getting-started/ 概述内容来源于官方,学习于马士兵云原生课程 概述 Apache APISIX 是什么? Apache APISIX 是 …...
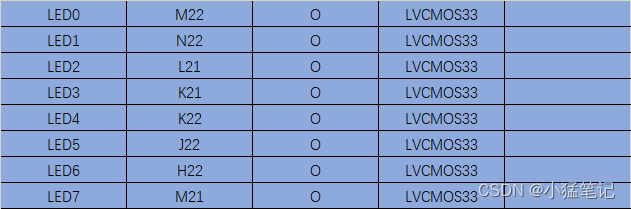
串口接收数据-控制LED灯
目标 通过串口接收数据,对数据分析,控制8个LED灯按照设定时间闪烁。 8个LED灯可以任意设计,是否闪烁。闪烁时间按ms计算,通过串口发送,可设置1~4,294,967,296ms,也就是4字节数据协议自拟,有数…...
python面试题合集(一)
python技术面试题 1、Python中的幂运算 在python中幂运算是由两个 **星号运算的,实例如下: >>> a 2 ** 2 >>> a 4我们可以看到2的平方输出结果为4。 那么 ^指的是什么呢?我们用代码进行演示: >>>…...

论文浅尝 | 利用对抗攻击策略缓解预训练语言模型中的命名实体情感偏差问题...
笔记整理:田家琛,天津大学博士,研究方向为文本分类 链接:https://ojs.aaai.org/index.php/AAAI/article/view/26599 动机 近年来,随着预训练语言模型(PLMs)在情感分类领域的广泛应用,…...
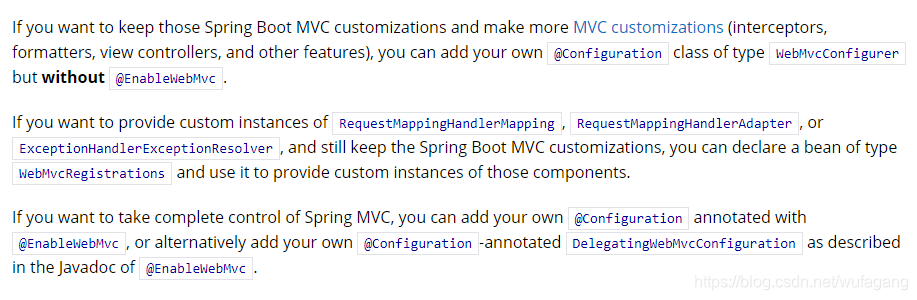
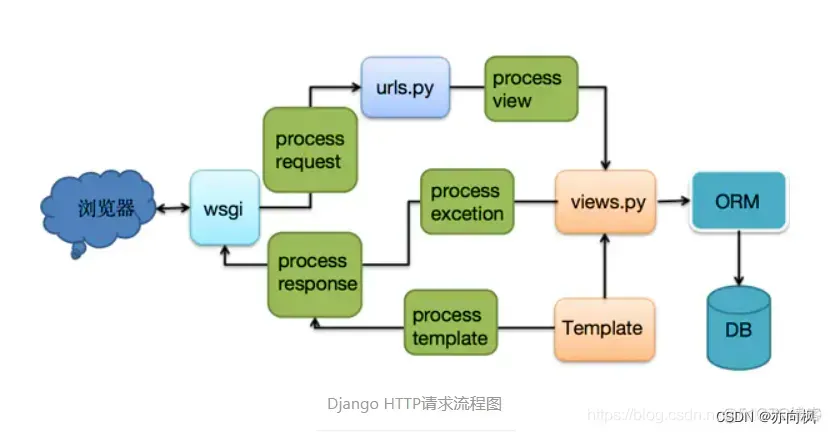
springboot web开发springmvc自动配置原理
前言 我们也知道springboot启用springmvc基本不用做什么配置可以很方便就使用了但是不了解原理,开发过程中遇到点问题估计就比较头疼,不管了解的深不深入,先巴拉一番再说… 下面我们先看看官网…我的版本是2.3.2版本,发现官网改动也比较大…不同版本自己巴拉下吧,结构虽然变化…...
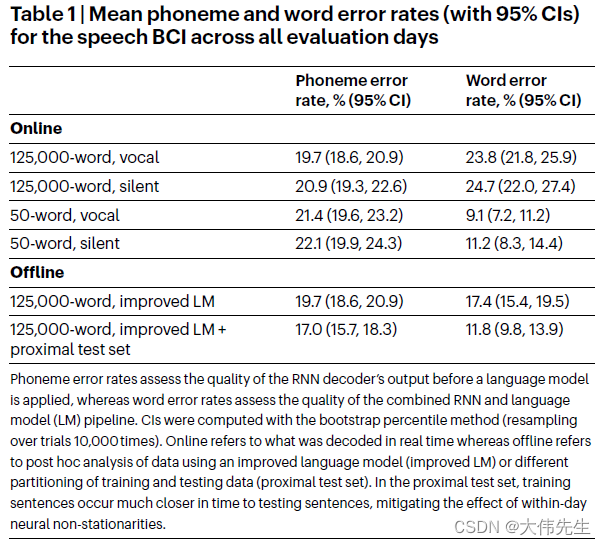
发表于《自然》杂志:语音转文本BCI的新突破实现62字/分钟的速度
语音脑机接口(BCI)是一项创新技术,通过用户的大脑信号在用户和某些设备之间建立通信通道,它们在恢复残疾患者的言语和通信能力方面具有巨大潜力。 早期的研究虽然很有希望,但尚未达到足够高的精度来解码大脑活动&…...
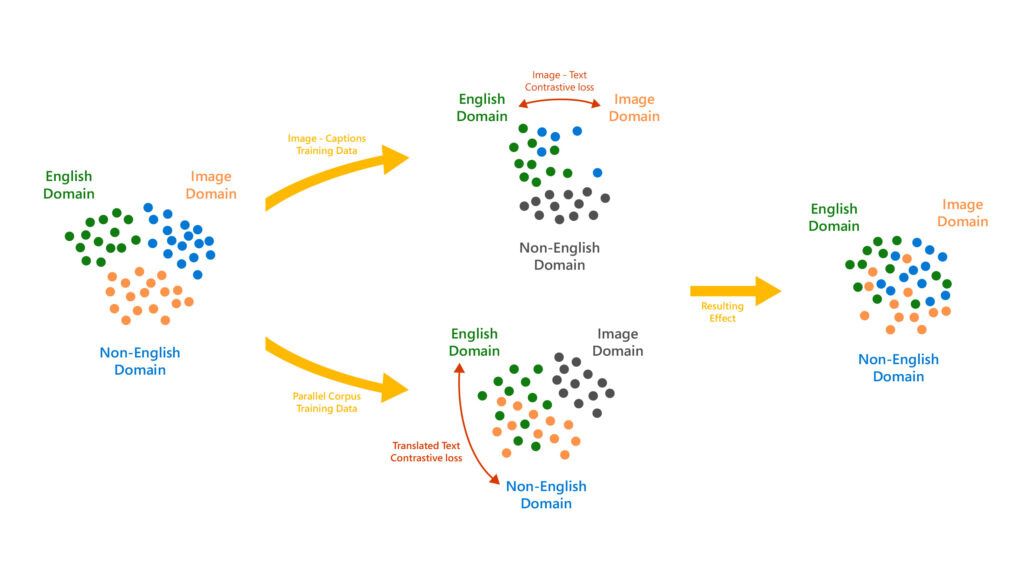
微软 Turing Bletchley v3视觉语言模型更新:必应搜索图片更精准
据微软新闻稿透露,在推出第三代Turing Bletchley视觉语言模型后,微软计划逐步将其整合到Bing等相关产品中,以提供更出色的图像搜索体验。这款模型最初于2021年11月面世,并在2022年秋季开始邀请用户测试。 凭借用户的反馈和建议&am…...

Ubuntu 22.04 x86_64 源码编译 pytorch-v2.0.1 笔记【2】编译成功
20230831继续: 当前状态 (pytorch-build) yeqiangyeqiang-MS-7B23:~/Downloads/src/pytorch$ pwd /home/yeqiang/Downloads/src/pytorch (pytorch-build) yeqiangyeqiang-MS-7B23:~/Downloads/src/pytorch$ python3 -V Python 3.10.6 (pytorch-build) yeqiangyeqi…...

IIR滤波器
IIR滤波器原理 IIR的特点是:非线性相位、消耗资源少。 IIR滤波器的系统函数与差分方程如下所示: 由差分方程可知IIR滤波器存在反馈,因此在FPGA设计时要考虑到有限字长效应带来的影响。差分方程中包括两个部分:输入信号x(n)的M节…...

【QT】使用qml的QtWebEngine遇到的一些问题总结
在使用qt官方的一些QML的QtWebEngine相关的例程的时候,有时在运行会报如下错误: WebEngineContext used before QtWebEngine::initialize() or OpenGL context creation failed 这个问题在main函数里面最前面加上: QCoreApplication::setAttr…...
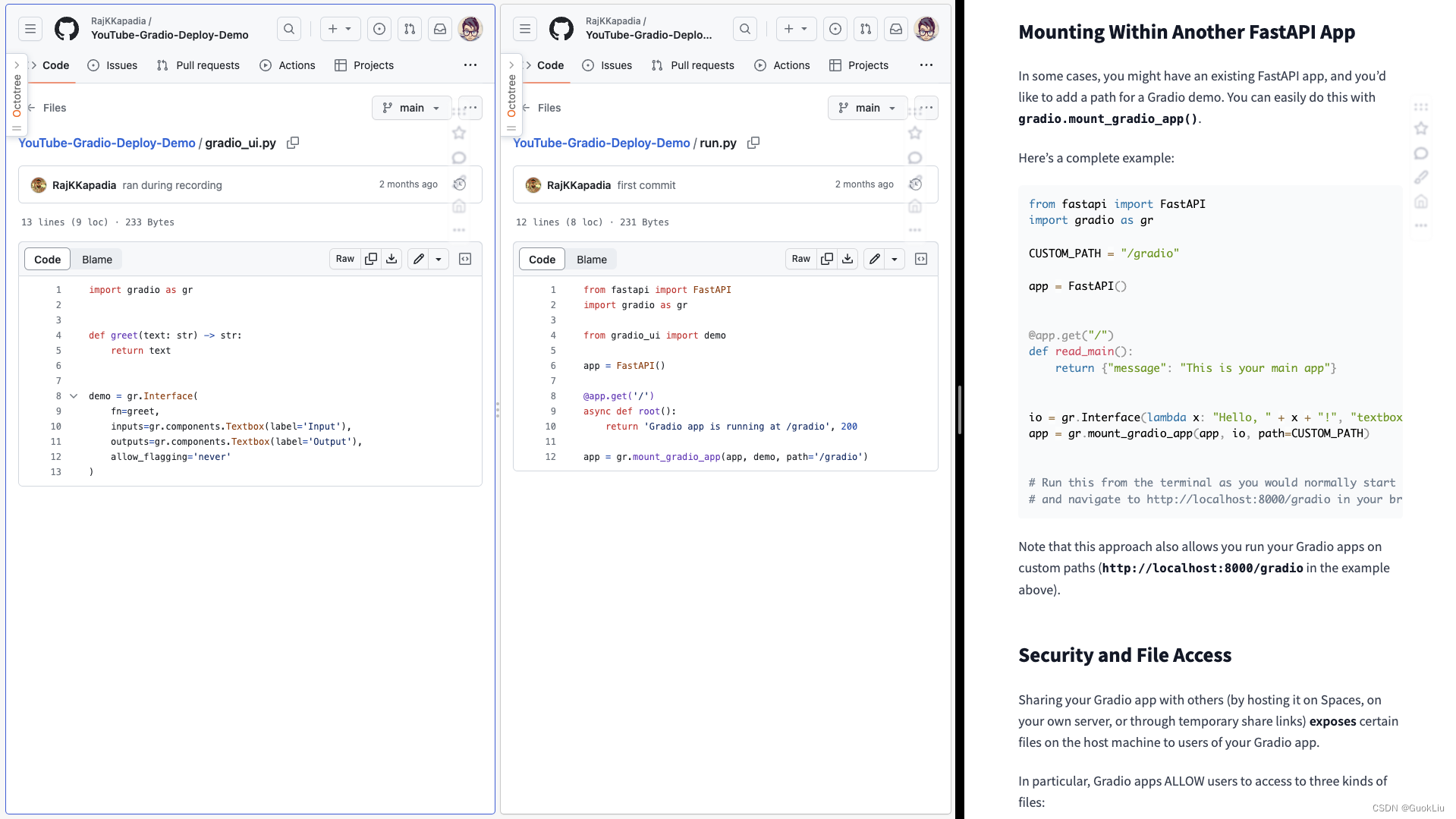
230902-部署Gradio到已有FastAPI及服务器中
1. 官方例子 run.py from fastapi import FastAPI import gradio as grCUSTOM_PATH "/gradio"app FastAPI()app.get("/") def read_main():return {"message": "This is your main app"}io gr.Interface(lambda x: "Hello, …...
Ubuntu本地快速搭建web小游戏网站,公网用户远程访问【内网穿透】
文章目录 前言1. 本地环境服务搭建2. 局域网测试访问3. 内网穿透3.1 ubuntu本地安装cpolar内网穿透3.2 创建隧道3.3 测试公网访问 4. 配置固定二级子域名4.1 保留一个二级子域名4.2 配置二级子域名4.3 测试访问公网固定二级子域名 前言 网:我们通常说的是互联网&am…...

【LeetCode-中等题】199. 二叉树的右视图
文章目录 题目方法一:层序遍历取每一层最后一个元素方法二:深度优先搜索 题目 方法一:层序遍历取每一层最后一个元素 // 方法一 :层序 集合(取每层子集合最后一个元素)// List<List<Integer>> Rlist new ArrayList…...

YOLOv8 Face:从技术原理到生产级人脸检测系统构建指南
YOLOv8 Face:从技术原理到生产级人脸检测系统构建指南 【免费下载链接】yolo-face YOLO Face 🚀 in PyTorch 项目地址: https://gitcode.com/gh_mirrors/yo/yolo-face 在当今计算机视觉领域,实时人脸检测技术已成为智能交互、安全监控…...

Phi-3-mini-4k-instruct-gguf一键部署:VMware虚拟机Ubuntu系统安装全流程
Phi-3-mini-4k-instruct-gguf一键部署:VMware虚拟机Ubuntu系统安装全流程 1. 准备工作与环境搭建 在开始之前,我们需要准备好必要的软件和资源。这个教程适合那些习惯在虚拟化环境中工作的开发者,特别是需要在本地测试后再部署到生产环境的…...

PyTorch 2.8镜像真实效果:量子计算电路→量子态演化视频模拟
PyTorch 2.8镜像真实效果:量子计算电路→量子态演化视频模拟 1. 量子计算模拟效果展示 量子计算作为前沿计算领域,其可视化一直是教学和研究的难点。我们使用PyTorch 2.8镜像实现了从量子电路到量子态演化的完整视频模拟流程,以下是关键效果…...

深度解析ImageToSTL:从二维图像到三维打印模型的技术实现
深度解析ImageToSTL:从二维图像到三维打印模型的技术实现 【免费下载链接】ImageToSTL This tool allows you to easily convert any image into a 3D print-ready STL model. The surface of the model will display the image when illuminated from the left sid…...

如何突破Cursor AI编程助手的使用限制:技术原理与实践指南
如何突破Cursor AI编程助手的使用限制:技术原理与实践指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

突破媒体捕获限制:猫抓cat-catch浏览器扩展全方位实战指南
突破媒体捕获限制:猫抓cat-catch浏览器扩展全方位实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓cat-catch是一款专注于网…...
:覆盖索引 vs 回表 —— 让查询效率提升 10 倍的核心技巧)
mysql技巧(十六):覆盖索引 vs 回表 —— 让查询效率提升 10 倍的核心技巧
📝 本章学习目标本章聚焦数据库性能优化,帮助读者彻底掌握覆盖索引与回表的核心原理。通过本章学习,你将全面理解覆盖索引 vs 回表这一核心主题,并能在实际工作中应用这些技巧,让查询效率提升 10 倍以上。 一、引言&am…...

数据库索引原理:B+树与哈希索引的深度对决
数据库索引原理:B树与哈希索引的深度对决在数据库的世界里,索引是提升查询性能的“核武器”。如果把数据库表比作一本厚厚的书,那么索引就是书中的目录。没有目录,想要找到特定的知识点只能一页页翻找(全表扫描&#x…...

D3KeyHelper:暗黑3效率提升工具的全方位应用指南
D3KeyHelper:暗黑3效率提升工具的全方位应用指南 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款开源的暗黑3鼠标宏工具…...

郭老师-最高级的活法:不渡无缘之人
最高级的活法 ——不干涉他人的因果“说教只会引来仇恨, 疼痛才是最好的老师。”🌿 真正的慈悲, 不是拉人上岸, 而是—— 允许他沉下去,再自己浮起来。⚖️ 一、四大悲哀:强行渡人,反被拖下水行…...