如何分析识别文章/内容中高频词和关键词?
theme: orange
要分析一篇文章的高频词和关键词,可以使用 Python 中的 nltk 库和 collections 库或者jieba库来实现,本篇文章介绍基于两种库分别实现分析内容中的高频词和关键词。
nltk 和 collections 库
首先,需要安装 nltk 库和 collections 库。可以使用以下命令来安装:
shell pip install nltk pip install collections 接下来,需要下载 nltk 库中的 stopwords 和 punkt 数据。可以使用以下代码来下载: ```python import nltk
nltk.download('stopwords') nltk.download('punkt') ```
下载完成后,可以使用以下代码来读取文章并进行分析: ```python import collections import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize
读取文章
with open('article.txt', 'r',encoding='utf-8') as f: article = f.read()
分词
tokens = word_tokenize(article)
去除停用词
stopwords = set(stopwords.words('english')) filteredtokens = [token for token in tokens if token.lower() not in stop_words]
统计词频
wordfreq = collections.Counter(filteredtokens)
输出高频词
print('Top 10 frequent words:') for word, freq in wordfreq.mostcommon(10): print(f'{word}: {freq}')
提取关键词
keywords = nltk.FreqDist(filtered_tokens).keys()
输出关键词
print('Keywords:') for keyword in keywords: print(keyword)
```
上述代码中,首先使用 open() 函数读取文章,然后使用 word_tokenize() 函数将文章分词。接着,使用 stopwords 数据集去除停用词,使用 collections.Counter() 函数统计词频,并输出高频词。最后,使用 nltk.FreqDist() 函数提取关键词,并输出关键词。
需要注意的是,上述代码中的 article.txt 文件需要替换为实际的文章文件路径。
结巴(jieba)库实现
```python
导入必要的库
import jieba import jieba.analyse from collections import Counter from wordcloud import WordCloud import matplotlib.pyplot as plt
读取文章
with open('./data/2.txt', 'r', encoding='utf-8') as f: article = f.read()
分词
words = jieba.cut(article)
统计词频
word_counts = Counter(words)
输出高频词
print('高频词:') for word, count in wordcounts.mostcommon(10): print(word, count)
输出关键词
print('关键词:') keywords = jieba.analyse.extract_tags(article, topK=10, withWeight=True, allowPOS=('n', 'nr', 'ns')) for keyword, weight in keywords: print(keyword, weight)
生成词云
wordcloud = WordCloud(fontpath='msyh.ttc', backgroundcolor='white', width=800, height=600).generate(article) plt.imshow(wordcloud, interpolation='bilinear') plt.axis('off') plt.show()
```
导入jieba库:首先需要导入jieba库,才能使用其中的分词功能。
读取文章:需要读取要分析的文章,可以使用Python内置的open函数打开文件,然后使用read方法读取文件内容。
分词:使用jieba库的cut方法对文章进行分词,得到一个生成器对象,可以使用for循环遍历生成器对象,得到每个词。
统计词频:使用Python内置的collections库中的Counter类,对分词后的词进行统计,得到每个词出现的次数。
输出高频词:根据词频统计结果,输出出现频率最高的词,即为高频词。
输出关键词:使用jieba库的analyse模块中的extract_tags方法,根据TF-IDF算法计算每个词的权重,输出权重最高的词,即为关键词。
生成词云:使用wordcloud库生成词云,将文章中的词按照词频生成词云,词频越高的词在词云中出现的越大。
相关文章:

如何分析识别文章/内容中高频词和关键词?
theme: orange 要分析一篇文章的高频词和关键词,可以使用 Python 中的 nltk 库和 collections 库或者jieba库来实现,本篇文章介绍基于两种库分别实现分析内容中的高频词和关键词。 nltk 和 collections 库 首先,需要安装 nltk 库和 collectio…...

Windows7安装SSH客户端的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
)
力扣:81. 搜索旋转排序数组 II(Python3)
题目: 已知存在一个按非降序排列的整数数组 nums ,数组中的值不必互不相同。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转 ,使数组变为 [nums[k], nums[k1], .…...
 地址族与数据序列)
TCP IP网络编程(三) 地址族与数据序列
文章目录 分配给套接字的IP地址与端口号网络地址网络地址分类与主机地址边界 地址信息的表示表示 IPv4地址的结构体结构体sockaddr_in 的成员分析 网络字节序与地址变换字节序与网络字节序字节序转换 网络地址的初始化与分配将字符串信息转换为网络字节序的整数型网络地址初始化…...
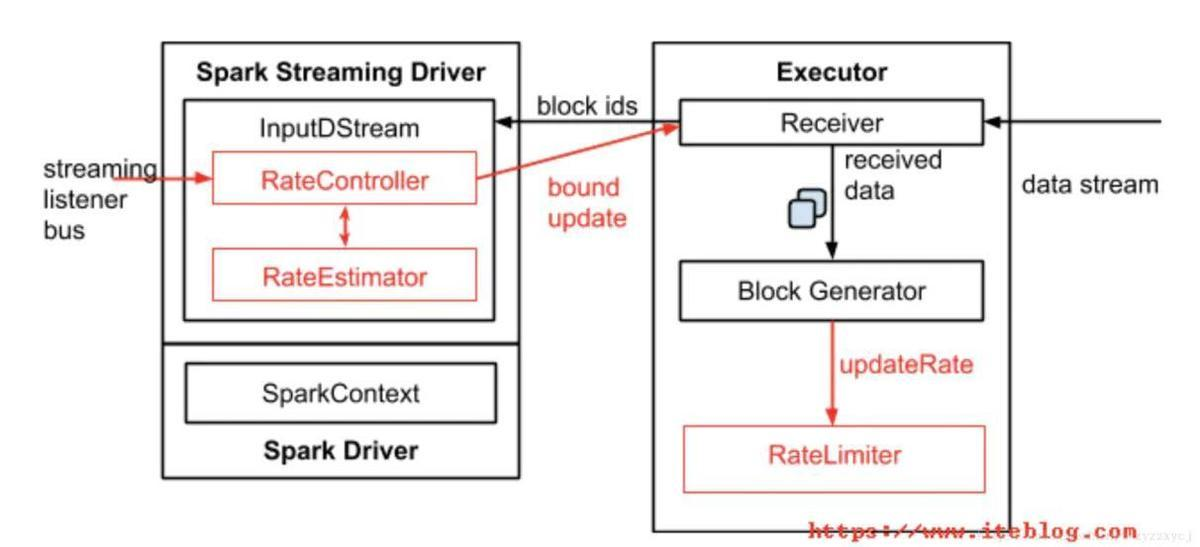
对比Flink、Storm、Spark Streaming 的反压机制
分析&回答 Flink 反压机制 Flink 如何处理反压? Storm 反压机制 Storm反压机制 Storm 在每一个 Bolt 都会有一个监测反压的线程(Backpressure Thread),这个线程一但检测到 Bolt 里的接收队列(recv queue)出现了…...

Ubuntu常用配置集合
Ubuntu配置软件镜像源 参考文章:Ubuntu如何配置软件镜像源 建议使用清华的源。 Ubuntu安装SSH服务: 参考文章:Ubuntu安装SSH服务 ubuntu下安装使用nvm 参考文章:ubuntu下安装使用nvm 出现下载sh文件不成功的情况,…...

传统三维重建和深度学习三维重建 MVS笔记总结、问题总结
什么是cost-volume ?(代价体) 什么是置信度?置信区间? pixel-wise,patch-wise,image-wise的区别 图像 4领域-8领域-16领域 及代码实现 文章目录 1 plane-sweeping2 传统三维重建深度学习三维重建有何不同呢?3 大型场景重建4 PMVS-精确、密集、鲁棒的多视图立体视觉…...
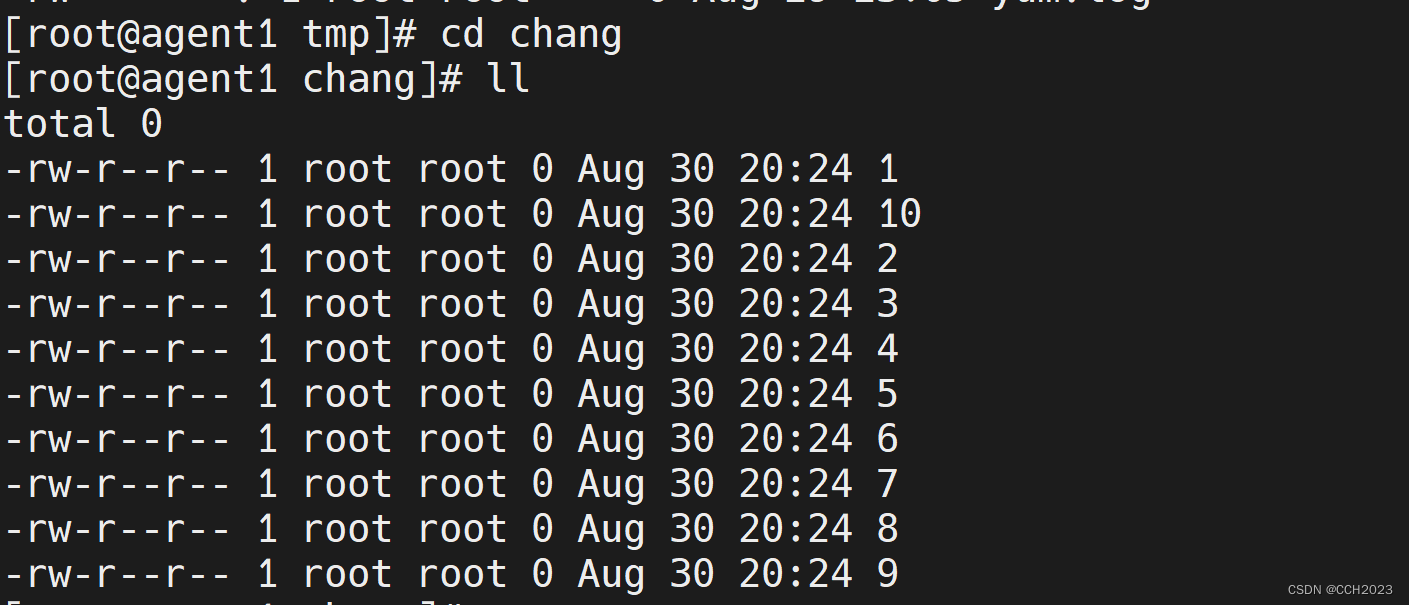
Ansible学习笔记10
1、在group1的被管理机里的mariadb里创建一个abc库; 1) 然后我们到agent主机上进行检查: 可以看到数据库已经创建成功。 再看几个其他命令: #a组主机重启mysql,并设置开机自启 ansible a -m service -a "namemy…...
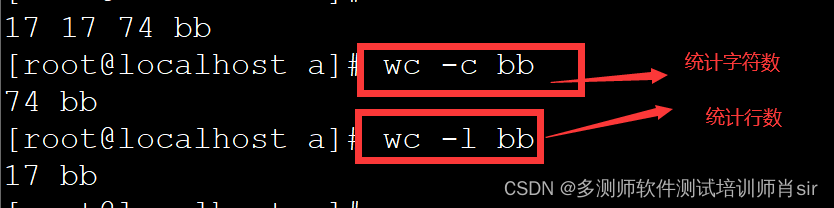
肖sir__linux详解__002(系统命令)
linux系统命令 1、df 查看磁盘使用情况 (1)df 查看磁盘使用情况(按kb单位显示) (2)df -h 按单位显示磁盘使用情况 2、top 实时查看动态进程 (1)top 详解: 第一行&…...

AI绘画:StableDiffusion实操教程-斗罗大陆2-江楠楠-常服(附高清图下载)
前段时间我分享了StableDiffusion的非常完整的教程:“AI绘画:Stable Diffusion 终极宝典:从入门到精通 ” 尽管如此,还有读者反馈说,尽管已经成功安装,但生成的图片与我展示的结果相去甚远。真实感和质感之…...

JavaScript运行机制与实践应用
一、JavsScript运行机制 1、JavaScript 是一种解释型语言,它的执行机制主要包括以下几个步骤: 2、事件循环 3、JavaScript运行模型 4、JavaScript任务 5、JavaScript宏任务和微任务 6、案例分析 console.log(script start) setTimeout(function () {co…...

【算法奥义】最大矩形问题
首先建立一个二维数组,这个二维数组,计算出矩阵的每个元素的左边连续 1 的数量,使用二维数组 left记录,其中left[i][j] 为矩阵第 i 行第 j 列元素的左边连续 1 的数量。 也就是从这个元素开始,从右往左边数有多少个连…...

06 Kafka线上集群部署方案
kafka部署在linux上有什么好处 网络传输效率 kafka部署在linux上,可以用到linux的零拷贝提升网络传输效率,提高kafka的吞吐量。利用零拷贝可以使数据不经过用户态直接通过网卡发送给接收方,实现数据的高性能传输 kafka和零拷贝技术 kafka…...

flex-shrink计算题
当我们使用 flexbox 布局时,flex-shrink 属性用于指定 flex 项在空间不足时收缩的比例。它表示了一个 flex 项相对于其他 flex 项收缩的比例。 假设有一个 flex 容器,其中包含三个子项,它们的 flex-shrink 分别设置为 1、2 和 3。当容器的可…...

Springboot - 5.Bean的生命周期
✍1. Bean的生命周期: 当然,我会详细描述每一步的作用。 🎷1. 实例化Bean: 这是Bean生命周期的第一步。Spring容器通过反射机制创建Bean的实例。public class ExampleBean {// ... }🎷2. 设置Bean的属性: Spring容器将根据配置…...

华为云 sfs 服务浅谈
以root用户登录弹性云服务器。 以root用户登录弹性云服务器。 安装NFS客户端。 查看系统是否安装NFS软件包。 CentOS、Red Hat、Oracle Enterprise Linux、SUSE、Euler OS、Fedora或OpenSUSE系统下,执行如下命令: rpm -qa|grep nfs Debian或Ubuntu系统下…...

CSS中如何实现元素的渐变背景(Gradient Background)效果?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ CSS 渐变背景效果⭐ 线性渐变背景⭐ 径向渐变背景⭐ 添加到元素的样式⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅&…...
buildroot修改内核防止清理重新加载办法
当你使用 Buildroot 构建 Linux 内核时,如果对内核文件进行了手动修改,重新执行 Buildroot 的构建过程将会覆盖你所做的修改。这是因为 Buildroot会根据配置重新下载、提取和编译内核。 为了避免在重新构建时覆盖你的修改,可以采取以下两种方…...

Vue框架--Vue中的事件
1.事件处理 事件的基本使用: (1).使用v-on:xxx 或 @xxx 绑定事件,其中xxx是事件名; (2).事件的回调需要配置在methods对象中,最终会在vm上; (3).methods中配置的函数,不要用箭头函数!否则this就不是vm了; (4).methods中配置的函数,都是被Vue所管理的函数,this的…...

1921. 消灭怪物的最大数量
原题地址 解法一 排序贪心即可。思想为先计算出每一个怪兽到达城市的时间,然后排序,有小到大进行消灭,此时的下标可视作时间。当怪兽到达城市的时间超过或等于当前时间时,即已经到达了城市,游戏失败,下标…...
Hunyuan-MT-7B翻译终端效果展示:Pixel Language Portal长文本段落对齐精度对比
Hunyuan-MT-7B翻译终端效果展示:Pixel Language Portal长文本段落对齐精度对比 1. 产品概览:像素语言冒险工坊 **像素语言跨维传送门(Pixel Language Portal)**是一款基于腾讯Hunyuan-MT-7B核心引擎构建的创新翻译终端。与传统翻译工具不同,…...

3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 [特殊字符]
3分钟夺回你的数字音乐资产:Unlock Music浏览器解密全攻略 🎵 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web…...

电价狂降、负值频现!2026电力现货市场惊变,出清电价底层逻辑全拆解
当“0电价”甚至“负电价”成为常态,电力行业的盈利逻辑正在被彻底颠覆。2026年的春天,电力行业迎来了一场前所未有的“地震”。就在刚刚过去的一季度,辽宁电力现货市场全天均价首次跌入负值区间,1月1日至25日短短25天内ÿ…...
,并放置任务栏中,.desktop文件使用)
[ linux添加应用图标到桌面 ] : 中将应用程序添加图标(快捷方式 ),并放置任务栏中,.desktop文件使用
.desktop文件格式在你的主目录中打开终端(ctrlaltt),接着输入以下代码:touch test.desktop vim test.desktop这里我选择的是vim的编辑方式,当然如果你没有vim或者说不太熟练的话,你可以直接双击打开该文件。代码解释:t…...

数据库智能运维:利用PyTorch LSTM预测数据库性能瓶颈
数据库智能运维:利用PyTorch LSTM预测数据库性能瓶颈 1. 引言:当数据库遇上AI预测 凌晨三点,运维工程师小李被刺耳的报警声惊醒——核心数据库又崩溃了。这已经是本月第三次因为性能瓶颈导致的业务中断,每次损失都超过百万。传统…...
)
避坑指南:用docker-compose部署Python项目时最容易忽略的5个配置细节(内网特别版)
避坑指南:用docker-compose部署Python项目时最容易忽略的5个配置细节(内网特别版) 在企业级开发中,内网环境下的Docker部署往往比公网场景复杂数倍。我曾亲眼见过一个团队因为时区配置错误导致日志时间全部错乱,排查了…...

避开这5个坑!用MediaRecorder+Vue3实现高兼容性语音输入
Vue3MediaRecorder实战:5个关键技巧打造高兼容语音输入方案 在移动优先的时代,语音输入已成为提升用户体验的重要交互方式。但当你兴奋地在Vue3项目中集成MediaRecorder API时,可能会遇到iOS设备上的静默失败、Android机型上的格式兼容性问题…...

从LC谐振到信号振铃:用Multisim仿真带你理解PCB上的阻尼振荡
从LC谐振到信号振铃:用Multisim仿真揭示PCB阻尼振荡的本质 1. 振铃现象:硬件工程师的"噩梦" 第一次在示波器上看到信号边沿那些诡异的振荡波形时,我差点以为自己的电路板被某种神秘力量干扰了。这种被称为"振铃"的现象…...
)
图片去水印 API 接口实战:网站如何实现自动去水印(Python / PHP / C#)
在做网站或后台系统时,一个很常见但容易被忽视的问题是: 👉 用户上传的图片自带水印 👉 平台展示希望统一成干净版本 👉 还要支持批量、自动化处理 👉 最好能无缝接入现有系统 如果你正在找: …...

Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体
Llama-3.2V-11B-cot与Dify集成:零代码构建企业AI智能体 最近和几个做企业服务的朋友聊天,大家普遍有个感觉:现在AI模型能力越来越强,但真要把它们用起来,门槛还是有点高。特别是对于业务部门的人来说,看着…...