图神经网络教程之HAN-异构图模型
异构图
包含不同类型节点和链接的异构图
异构图的定义:节点类别数量和边的类别数量加起来大于2就叫异构图。
meta-path元路径的定义:连接两个对象的复合关系,比如,节点类型A和节点类型B,A-B-A和B-A-B都是一种元路径。
meta-path下的邻居节点的定义:如下图所示。

其中m1-a1-m2,m1-a3-m3都是一种meta-path,所以m1的邻居有m2、m3以及本身m1

节点级别的attention和语义级别的attention
节点级别:简单来说就是单种meta-path求得节点embeddings,比如对于M-D-M,Terminator2的embeddings通过M-D-M的元路径即可求的另一个M(Termintor)的embeddings。
语义级别:对于Terminator的embeddings不再是根据一种meta-path进行获取,而是根据两种meta-path进行权重的分配相加得到。
节点级别:
举例子:

如上图所示,对于异构图,一种meta-path为蓝-黄-蓝,对于节点x1-xa-x2,所以x1与x2通过meta-path元路径,同理每一对节点,构成上图中的第二个图的连接方式。

对于节点x1,与节点x2、x3、x6相连,所以x2、x3、x6都是节点x1的邻居节点,也就是公式2。
对于公式三,分子将i和j节点拼接在一起以后乘以一个可学习的参数然后再通过激活函数,再通过exp。分母就是他的邻居节点的。
对后求的节点级别下的embeddings。
语义级别:
简单来说语义级别就是多种meta-path呗,只需要把每种meta-path下面的求出来进行加权就可以了。

如上图所示,通过节点级别的求解方法,求出来对于每一种metapath下面的embeddings,然后最后进行加权求和。
知道了上面的HAN的原理,下面讲解一下model代码。
在讲解原理的时候分为语义级别和节点级别,在代码的时候会分为给定已经处理好的邻接矩阵和直接输入异构图。
异构图直接输入(异构图模型。):
需要将meta-path转化为邻接矩阵即元组形式。
实现了Heterogeneous Graph Attention Network(HAN)模型,用于处理异构图数据。HAN是一种深度学习模型,用于在异构图中进行节点分类任务
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom dgl.nn.pytorch import GATConv
首先,导入了PyTorch库以及用于图神经网络的相关模块。
class SemanticAttention(nn.Module):def __init__(self, in_size, hidden_size=128):super(SemanticAttention, self).__init__()# input:[Node, metapath, in_size]; output:[None, metapath, 1]; 所有节点在每个meta-path上的重要性值self.project = nn.Sequential(nn.Linear(in_size, hidden_size),nn.Tanh(),nn.Linear(hidden_size, 1, bias=False))
这里定义了一个名为SemanticAttention的PyTorch模型类,它用于计算每个节点在不同元路径(metapath)上的重要性。SemanticAttention类有以下成员:
__init__方法:初始化模型。它接受输入特征的维度in_size以及可选的隐藏层维度hidden_size。在初始化过程中,它创建了一个神经网络模块self.project,该模块包括两个线性层和一个Tanh激活函数,最后一个线性层没有偏差。
def forward(self, z):w = self.project(z).mean(0)#每个节点在metapath维度的均值; mean(0): 每个meta-path上的均值(/|V|); (MetaPath, 1)beta = torch.softmax(w, dim=0) # 归一化 # (M, 1)beta = beta.expand((z.shape[0],) + beta.shape) # 拓展到N个节点上的metapath的值 (N, M, 1)return (beta * z).sum(1)#(beta*z)=>所有节点,在metapath上的attention值;(beta*z).sum(1)=>节点最终的值(N,D*K)
forward方法:用于计算每个节点在不同元路径上的重要性。首先,将输入特征z通过self.project模块传递,然后计算每个元路径上的重要性均值w。接着,使用softmax函数对这些均值进行归一化,以获得每个元路径上的注意力权重beta。最后,将注意力权重与输入特征相乘,并对所有元路径求和,得到最终的节点表示。
这个SemanticAttention模块的目的是计算每个节点在不同元路径上的权重,以便后续的元路径级别的注意力聚合。
接下来,定义了另一个模型类HANLayer:
class HANLayer(nn.Module):def __init__(self, num_meta_paths, in_size, out_size, layer_num_heads, dropout):super(HANLayer, self).__init__()self.gat_layers = nn.ModuleList()for i in range(num_meta_paths): # meta-path Layers; 两个meta-path的维度是一致的self.gat_layers.append(GATConv(in_size, out_size, layer_num_heads,dropout, dropout, activation=F.elu))self.semantic_attention = SemanticAttention(in_size=out_size * layer_num_heads) # 语义attention; out-size*layersself.num_meta_paths = num_meta_paths
HANLayer类代表了HAN模型中的一个层次。每个HANLayer层包括以下成员:
__init__方法:初始化层。它接受以下参数:num_meta_paths:元路径的数量。in_size:输入特征的维度。out_size:输出特征的维度。layer_num_heads:每个GAT层中的注意力头的数量。dropout:用于正则化的dropout率。
在初始化过程中,它首先创建了多个GATConv层,每个GATConv层对应一个元路径,这些层将用于图注意力聚合。然后,创建了一个SemanticAttention模块,用于计算每个节点在不同元路径上的语义级别的注意力。
接下来,定义了整个HAN模型类HAN:
class HAN(nn.Module):def __init__(self, num_meta_paths, in_size, hidden_size, out_size, num_heads, dropout):super(HAN, self).__init__()self.layers = nn.ModuleList()self.layers.append(HANLayer(num_meta_paths, in_size, hidden_size, num_heads[0], dropout)) # meta-path数量 + semantic_attentionfor l in range(1, len(num_heads)): # 多层多头,目前是没有self.layers.append(HANLayer(num_meta_paths, hidden_size * num_heads[l-1],hidden_size, num_heads[l], dropout))self.predict = nn.Linear(hidden_size * num_heads[-1], out_size) # hidden*heads, classes; HAN->classes
HAN类是整个HAN模型的定义。它接受以下参数:
num_meta_paths:元路径的数量。in_size:输入特征的维度。hidden_size:隐藏层的维度。out_size:输出特征的维度(通常是类别数量)。num_heads:一个列表,指定每个HANLayer层中的注意力头数量。dropout:用于正则化的dropout率。
在初始化过程中,它首先创建了多个HANLayer层,每个HANLayer层包括一个或多个GATConv层和一个SemanticAttention层。
输入处理好的异构图,即邻接矩阵(普通图模型。):
import torch
import torch.nn as nn
import torch.nn.functional as F
import dgl
from dgl.nn.pytorch import GATConv
首先,导入了必要的库和模块。
class SemanticAttention(nn.Module):def __init__(self, in_size, hidden_size=128):super(SemanticAttention, self).__init__()self.project = nn.Sequential(nn.Linear(in_size, hidden_size),nn.Tanh(),nn.Linear(hidden_size, 1, bias=False))
这里定义了一个名为SemanticAttention的PyTorch模型类,它用于计算每个节点在不同元路径上的语义级别的重要性。和第一个代码段的SemanticAttention类相似,这个类也包括以下成员:
__init__方法:初始化模型。它接受输入特征的维度in_size以及可选的隐藏层维度hidden_size。在初始化过程中,它创建了一个神经网络模块self.project,该模块包括两个线性层和一个Tanh激活函数,最后一个线性层没有偏差。
def forward(self, z):w = self.project(z).mean(0) # (M, 1)beta = torch.softmax(w, dim=0) # (M, 1)beta = beta.expand((z.shape[0],) + beta.shape) # (N, M, 1)return (beta * z).sum(1) # (N, D * K)
forward方法:用于计算每个节点在不同元路径上的语义级别的重要性。首先,将输入特征z通过self.project模块传递,然后计算每个元路径上的语义级别的均值权重w。接着,使用softmax函数对这些均值进行归一化,得到每个元路径上的注意力权重beta,将这些权重与输入特征相乘,并对所有元路径求和,得到最终的节点表示。
接下来,定义了另一个模型类HANLayer,它代表HAN模型中的一个层次。
class HANLayer(nn.Module):def __init__(self, meta_paths, in_size, out_size, layer_num_heads, dropout):super(HANLayer, self).__init__()# One GAT layer for each meta path based adjacency matrixself.gat_layers = nn.ModuleList()for i in range(len(meta_paths)):self.gat_layers.append(GATConv(in_size, out_size, layer_num_heads,dropout, dropout, activation=F.elu,allow_zero_in_degree=True))self.semantic_attention = SemanticAttention(in_size=out_size * layer_num_heads)self.meta_paths = list(tuple(meta_path) for meta_path in meta_paths) # 将meta-path转换成元组形式self._cached_graph = Noneself._cached_coalesced_graph = {}def forward(self, g, h):semantic_embeddings = []if self._cached_graph is None or self._cached_graph is not g: # 第一次,建立一张metapath下的异构图self._cached_graph = gself._cached_coalesced_graph.clear()for meta_path in self.meta_paths:self._cached_coalesced_graph[meta_path] = dgl.metapath_reachable_graph(g, meta_path) # 构建异构图的邻居;# self._cached_coalesced_graph 多个metapath下的异构图for i, meta_path in enumerate(self.meta_paths):new_g = self._cached_coalesced_graph[meta_path] # meta-path下的节点邻居图semantic_embeddings.append(self.gat_layers[i](new_g, h).flatten(1)) # 图attentionsemantic_embeddings = torch.stack(semantic_embeddings, dim=1) # (N, M, D * K)return self.semantic_attention(semantic_embeddings) # (N, D * K)
HANLayer类包括以下主要部分:
-
__init__方法:初始化HAN层,它包括多个GATConv层以及一个语义注意力模块。每个GATConv层对应一个元路径,用于处理节点在该元路径上的信息。语义注意力模块用于计算节点在不同元路径上的语义级别的注意力。 -
forward方法:执行HAN层的前向传播。对于每个元路径,首先获取该元路径的邻居图,然后通过GATConv层计算节点的注意力表示。最后,通过语义注意力模块将不同元路径上的表示进行加权求和,得到最终的节点表示。
最后,定义了整个HAN模型类HAN:
class HAN(nn.Module):def __init__(self, meta_paths, in_size, hidden_size, out_size, num_heads, dropout):super(HAN, self).__init__()self.layers = nn.ModuleList()self.layers.append(HANLayer(meta_paths, in_size, hidden_size, num_heads[0], dropout))for l in range(1, len(num_heads)):self.layers.append(HANLayer(meta_paths, hidden_size * num_heads[l-1],hidden_size, num_heads[l], dropout))self.predict = nn.Linear(hidden_size * num_heads[-1], out_size)
HAN类定义了整个HAN模型,包括多个HANLayer层以及最后的预测层。
__init__方法:初始化HAN模型,它包括多个HANLayer层,每个HANLayer层用于处理一个元路径的信息。最后,添加一个线性预测层,将最终的节点表示映
射到输出特征(通常是类别数量)。
forward方法:执行HAN模型的前向传播。它依次通过多个HANLayer层来计算最终的输出,每个HANLayer层都包括元路径信息的处理和注意力聚合。
训练代码train
训练代码就是常规的套路。
-
引入必要的库和模块:
- 导入了PyTorch库和sklearn库,用于深度学习和评估模型性能。
- 导入了自定义的
load_data和EarlyStopping函数,以及其他必要的模块。
-
score函数:- 这个函数用于计算模型的性能指标,包括准确率(accuracy)、微平均F1分数(micro_f1),和宏平均F1分数(macro_f1)。
- 它接受模型的预测结果(logits)和真实标签(labels),然后计算这些性能指标。
- 准确率表示正确分类的样本比例,微平均F1分数和宏平均F1分数是一种综合的评估指标,用于度量分类模型的性能。
-
evaluate函数:- 这个函数用于评估模型在验证集上的性能。
- 它接受模型(model)、图数据(g)、特征数据(features)、标签数据(labels)、掩码数据(mask),以及损失函数(loss_func)作为输入。
- 在评估过程中,模型处于评估模式(
model.eval()),不会更新梯度。 - 通过模型预测验证集上的结果,并计算损失、准确率、微平均F1分数和宏平均F1分数。
- 最后返回这些评估指标。
-
main函数:- 这是主要的训练和评估逻辑所在的函数。
- 首先,加载数据(包括图数据、特征数据、标签数据等)并将其移动到指定的计算设备(CPU或GPU)上。
- 根据参数
args中的'hetero'标志,选择不同的模型和数据处理方式。如果'hetero'为True,则使用异构图模型;否则,使用普通图模型。 - 定义了模型的损失函数、优化器和早停(EarlyStopping)对象。
- 开始训练循环,每个epoch进行一次训练和验证。在训练过程中,计算损失、准确率和F1分数等指标,并打印出来。如果验证集上的性能不再提升,会触发早停(early stopping)。
- 最后,在测试集上评估模型的性能,并打印出测试集上的损失、准确率、微平均F1分数和宏平均F1分数。
-
if __name__ == '__main__':部分:- 这个部分用于设置命令行参数,并调用
main函数来运行训练和评估过程。 - 可以通过命令行传递参数来配置模型的训练和数据处理方式。
- 这个部分用于设置命令行参数,并调用
rlyStopping)对象。
- 开始训练循环,每个epoch进行一次训练和验证。在训练过程中,计算损失、准确率和F1分数等指标,并打印出来。如果验证集上的性能不再提升,会触发早停(early stopping)。
- 最后,在测试集上评估模型的性能,并打印出测试集上的损失、准确率、微平均F1分数和宏平均F1分数。
-
if __name__ == '__main__':部分:- 这个部分用于设置命令行参数,并调用
main函数来运行训练和评估过程。 - 可以通过命令行传递参数来配置模型的训练和数据处理方式。
- 这个部分用于设置命令行参数,并调用
总体来说,这段代码实现了一个用于异构图数据或普通图数据的节点分类任务的训练和评估流程。它加载数据、选择模型、进行训练和验证,最后在测试集上评估模型性能。
相关文章:
图神经网络教程之HAN-异构图模型
异构图 包含不同类型节点和链接的异构图 异构图的定义:节点类别数量和边的类别数量加起来大于2就叫异构图。 meta-path元路径的定义:连接两个对象的复合关系,比如,节点类型A和节点类型B,A-B-A和B-A-B都是一种元路径。 …...
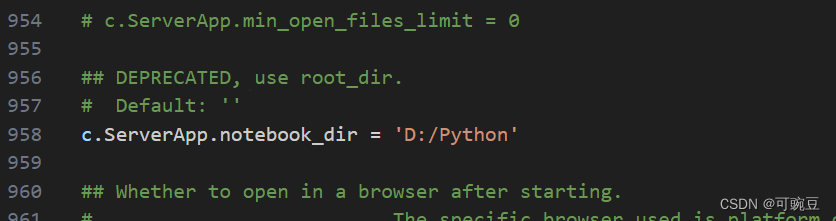
Jupyter lab 配置
切换jupyterlab的默认工作目录 在终端中输入以下命令 PS C:\Users\Administrator> jupyter-lab --generate-config Writing default config to: C:\Users\Administrator\.jupyter\jupyter_lab_config.py它就会生成JupyterLab的配置文件(如果之前有这个文件的话…...

股票行情处理:不复权,前复权,后复权
不复权的话,K线图能真实反应股价历史的除权信息,缺点是会留有大缺口,股价走势不连续,不能直观感受股价的涨跌波动。 前复权是以目前股价为基准复权,可以很清楚的看到股价的历史高点、低点,以及目前股价所处…...
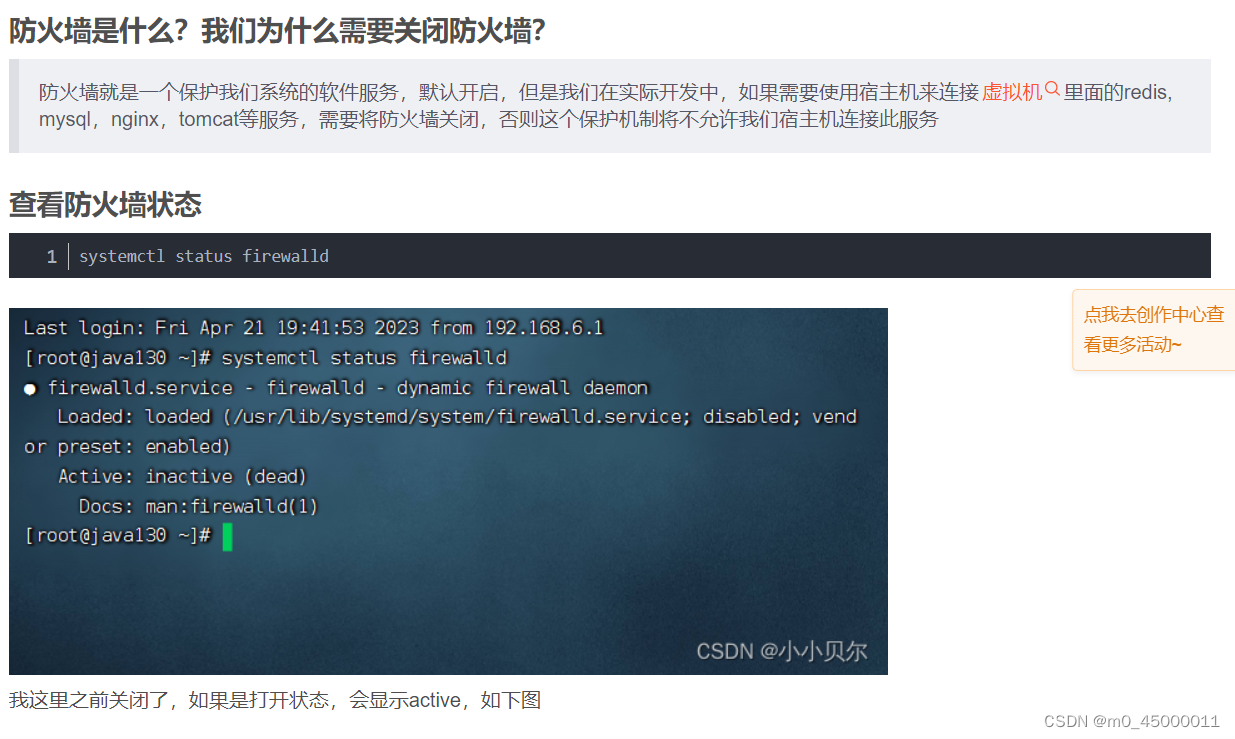
ip地址、LINUX、与虚拟机
子网掩码,是用来固定网络号的,例如255,255,255,0,表明前面三段必须为网络号,后面必须是主机号,那么怎么实现网络复用呢,例如使用c类地址,但是正常子网掩码是255,255,255,…...

MySQL存储过程
存储过程 1、存储过程简介 存储过程与函数的直接效果类似,只不过存储过程,封装的是一组sql语句。 mysql数据库存储过程是一组为了完成特定功能的sql语句的集合。 存储过程这个功能时从5.0版本才开始支持的,它可以加快数据库的处理速度&…...

element-ui 自定义loading加载样式
element-ui 中的 loading 加载功能,默认是全屏加载效果, 设置局部,需要自定义样式,自定义的方法如下: import { Loading } from element-uiVue.prototype.$baseLoading (text) > {let loadingloading Loading.s…...
04-Apache Directory Studio下载安装(LDAP连接工具)
1、下载 官网下载Apache Directory Studio 注意Apache Directory Studio依赖于jdk,对jdk有环境要求 请下载适配本机的jdk版本的Apache Directory Studio,下图为最新版下载地址 Apache Directory Studio Version 2.0.0-M16 基于 Eclipse 2020-12,最低要…...
vmware虚拟机(ubuntu)远程开发golang、python环境安装
目录 1. 下载vmware2. 下载ubuntu镜像3. 安装4. 做一些设置4.1 分辨率设置4.2 语言下载4.3 输入法设置4.4 时区设置 5. 直接切换管理员权限6. 网络6.1 看ip6.2 ssh 7. 本地编译器连接远程服务器7.1 创建远程部署的配置7.2 文件同步7.3 远程启动项目 8. ubuntu安装golang环境8.1…...

Elasticsearch文档多个输入字段组成ID实现方法
1、场景描述: 使用Elasticsearch时,有时会需要指定文档id的场景,当文档id需要多个字段组成时,这种业务怎么处理呢? 2、问题描述: 现有一个ElasticSearch文档,假设文档id由userid、 eventTime…...
rdynamic选项的用途)
编译链接实战(15)rdynamic选项的用途
文章目录 rdynamic作用栈回溯 rdynamic作用 看下gcc man手册的解释: Pass the flag -export-dynamic to the ELF linker, on targets that support it. This instructs the linker to add all symbols, not onlyused ones, to the dynamic symbol table. This opti…...
前端:js实现提示框(自动消失)
效果: 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&q…...

powerpc架构的前世今生
文章目录 Powerpc架构的前世今生什么是powerpc?PowerPC和ARM有什么区别呢? Powerpc架构的前世 PowerPC架构是一种基于精简指令集计算机(RISC)的处理器架构。它最初由IBM、Motorola和Apple共同开发,旨在为个人电脑、工…...

SQL-存储过程、流程控制、游标
存储过程 存储过程概述 1.产生背景 开发过程总,经常会遇到重复使用某一功能的情况 2.解决办法 MySQL引人了存储过程(Stored Procedure)这一技术 3.存储过程 存储过程就是一条或多条SQL语句的集合存储过程可将一系列复杂操作封装成一个代码块,以便…...

JavaScript的数组和字典的用法
JavaScript 中的数组是一种用于存储多个值的数据结构,它可以容纳不同类型的数据(例如数字、字符串、对象等)。以下是 JavaScript 数组的常见用法: 创建数组 // 创建一个空数组 let emptyArray [];// 创建一个包含元素的数组 le…...

中断和异常
1.什么是中断 CPU上会运行两种程序,一种是内核程序,一种是应用程序。在正常的情况,CPU上面会主动运行应用程序,中断就是操作系统内核夺回CPU执行权的唯一途径,也就是用户态——>内核态。 2.内中断和外中断 2.1内…...
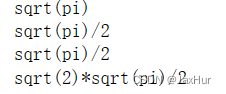
【python】实现积分
借助sympy.integrate() 符号运算库,所以里面的exp(),sin()等都要使用sympy库中的函数,如果使用numpy库中的函数时没用的。 import sympy as sp import numpy as np x sp.symbols("x") print(sp.integrate(sp.exp(-x**2), (x, -s…...

微信仿H5支付
仿H5支付是指一种模拟原生H5支付流程的非官方支付方式。这种支付方式通常是由第三方支付服务提供商开发和维护的,目的是为了绕过官方支付渠道的限制,如费率、审核等问题。然而,由于仿H5支付并非官方授权和认可的支付方式,其安全性…...
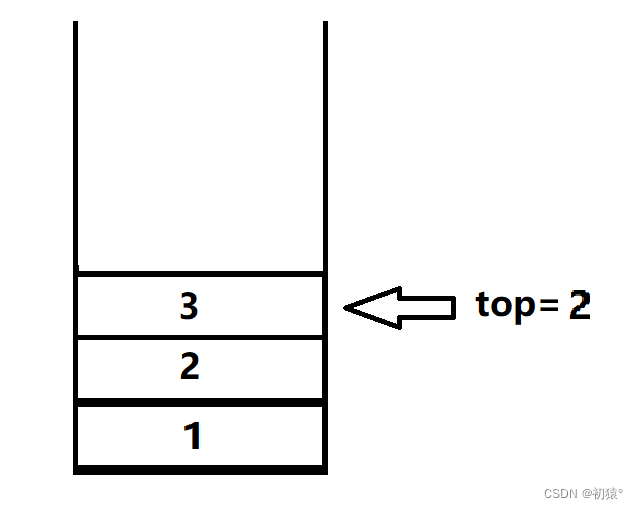
数据结构——栈
栈 栈的理解 咱们先不管栈的数据结构什么,先了解栈是什么,栈就像一个桶一样,你先放进去的东西,被后放进的的东西压着,那么就需要把后放进行的东西拿出才能拿出来先放进去的东西,如图1,就像图1中…...

组件化开发之如何封装组件-react
组件化开发之如何封装组件-react 什么是组件为什么需要封装组件组件的分类函数组件(Functional Components):展示型组件:容器型组件:知道组件分类的意义是? 如何拆分组件,需要遵循什么原则1.保证…...

大数据HBase学习圣经:一本书实现HBase学习自由
学习目标:三栖合一架构师 本文是《大数据HBase学习圣经》 V1版本,是 《尼恩 大数据 面试宝典》姊妹篇。 这里特别说明一下:《尼恩 大数据 面试宝典》5个专题 PDF 自首次发布以来, 已经汇集了 好几百题,大量的大厂面试…...

保姆级教程:用iSYSTEM winIDEA和iC5000给S32K148烧录程序,附完整配置流程
从零掌握iSYSTEM工具链:S32K148开发板烧录与调试全流程实战第一次接触iSYSTEM的winIDEA和iC5000仿真器时,很多嵌入式开发者都会感到无从下手。不同于常见的开源工具链,这套专业级开发环境在汽车电子和工业控制领域有着广泛应用,尤…...
两两交换链表中的节点)
力扣HOT100(30)两两交换链表中的节点
链表的交换要注意 “链表不断链”。前驱和后继都要连着迭代法(必学死磕!O (n) 时间,O (1) 空间)1. 为什么必须用虚拟头节点?因为交换后链表的头节点会变! 比如示例 1 中,原来的头是 1࿰…...

Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程
更多请点击: https://intelliparadigm.com 第一章:Lindy自动化效率翻倍的秘密:从零搭建高可靠多步骤任务流的7步黄金流程 Lindy自动化平台以“越久越可靠”为设计哲学,将经典软件工程原则与现代可观测性实践深度融合。其核心优势…...

腾讯 Marvis 初级使用教程——从安装到上手
腾讯最新系统级AI助手Marvis(2026年5月20日发布),官网 https://marvis.qq.com,主打“一句话操作电脑”、跨端协同、GUI Agent执行。虽然是个【小龙虾】,但上手其实不难。这篇就简单写写 Marvis 的安装和基础使用&#…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...

AutoPentest:面向红队的渗透测试决策引擎架构解析
1. 这不是又一个“自动化扫描器”,而是一套能替你做决策的渗透测试工作流引擎AutoPentest这个名字,第一眼容易让人联想到Nmap加个for循环、或者Burp Suite里点几下Intruder——但实际用过的人很快会意识到:它根本不在同一个维度上。我第一次在…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

观察Taotoken在多模型聚合调用下的路由与失败重试效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用下的路由与失败重试效果 在构建依赖大模型能力的应用时,服务的稳定性是开发者关注的核心…...
)
仅限首批200位架构师获取:DeepSeek-DDD联合建模工作坊实录(含领域事件风暴原始会议录像+决策日志)
更多请点击: https://kaifayun.com 第一章:DeepSeek领域驱动设计的范式演进与本质洞察 DeepSeek作为面向大规模智能体协同与复杂业务语义建模的新一代AI原生架构,其领域驱动设计(DDD)实践已突破传统分层单体范式&…...