深度学习推荐系统(五)DeepCrossing模型及其在Criteo数据集上的应用
深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。

1 Deep&Crossing模型原理
1.1 Deep&Crossing模型提出的背景
-
Wide&Deep 模型的提出不仅综合了
记忆能力和泛化能力,而且开启了不同网络结构融合的新思路。 -
在 Wide&Deep 模型之后,有越来越多的工作集中于分别改进Wide&Deep模型的 Wide部分或是 Deep 部分。
-
典型的工作是2017年由斯坦福大学和谷歌的研究人员提出的 Deep&Cross模型(简称DCN)。
-
Deep&Cross 模型的主要思路是使用 Cross 网络替代原来的 Wide 部分。由于 Deep 部分的设计思路并没有本质的改变,最主要的创新点是Cross 部分的设计思路。
1.2 Deep&Crossing的模型结构
DCN模型的结构非常简洁,从下往上依次为:Embedding和Stacking层、Cross网络层与Deep网络层并列、输出合并层,得到最终的预测结果。

1.2.1 Embedding and stacking layer
Embedding层作用依然是把稀疏离散的类别型特征变成低维密集型。
然后需要将所有的密集型特征(数值型特征)与通过embedding转换后的特征进行联合(Stacking)。

1.2.2 Cross NetWork模型


举例说明

可以看到
-
x1中包含了所有的x0的1,2阶特征的交互。
第l层特征对应的最高的叉乘阶数为l+1 -
Cross网络的参数是共享的, 每一层的这个权重特征之间共享, 这个可以使得模型泛化到看不见的特征交互作用, 并且对噪声更具有鲁棒性。
-
Deep Network及组合层比较简单,不再赘述。
1.3 Deep&Crossing模型代码复现
import torch.nn as nn
import torch.nn.functional as F
import torchclass CrossNetwork(nn.Module):"""Cross Network"""def __init__(self, layer_num, input_dim):super(CrossNetwork, self).__init__()self.layer_num = layer_num# 定义网络层的参数self.cross_weights = nn.ParameterList([nn.Parameter(torch.rand(input_dim, 1))for i in range(self.layer_num)])self.cross_bias = nn.ParameterList([nn.Parameter(torch.rand(input_dim, 1))for i in range(self.layer_num)])def forward(self, x):# x是(batchsize, dim)的形状, 先扩展一个维度到(batchsize, dim, 1)x_0 = torch.unsqueeze(x, dim=2)x = x_0.clone()xT = x_0.clone().permute((0, 2, 1)) # (batchsize, 1, dim)for i in range(self.layer_num):x = torch.matmul(torch.bmm(x_0, xT), self.cross_weights[i]) + self.cross_bias[i] + x # (batchsize, dim, 1)xT = x.clone().permute((0, 2, 1)) # (batchsize, 1, dim)x = x.squeeze(2) # (batchsize, dim)return xclass Dnn(nn.Module):"""Dnn part"""def __init__(self, hidden_units, dropout=0.):"""hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度dropout: 失活率"""super(Dnn, self).__init__()self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])self.dropout = nn.Dropout(p=dropout)def forward(self, x):for linear in self.dnn_network:x = linear(x)x = F.relu(x)x = self.dropout(x)return xclass DCN(nn.Module):def __init__(self, feature_info, hidden_units, layer_num, embed_dim=8,dnn_dropout=0.):"""feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)hidden_units: 列表, 隐藏单元的个数(多层残差那里的)layer_num: cross network的层数embed_dim: embedding维度dnn_dropout: Dropout层的失活比例"""super(DCN, self).__init__()self.dense_features, self.sparse_features, self.sparse_features_map = feature_info# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embeddingself.embed_layers = nn.ModuleDict({'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=embed_dim)for key, val in self.sparse_features_map.items()})# 统计embedding_dim的总维度# 一个离散型(类别型)变量 通过embedding层变为10纬embed_dim_sum = sum([embed_dim] * len(self.sparse_features))# 总维度 = 数值型特征的纬度 + 离散型变量经过embedding后的纬度dim_sum = len(self.dense_features) + embed_dim_sumhidden_units.insert(0, dim_sum)# 1、cross Network# layer_num是交叉网络的层数, hidden_units[0]表示输入的整体维度大小self.cross_network = CrossNetwork(layer_num, hidden_units[0])# 2、Deep Networkself.dnn_network = Dnn(hidden_units,dnn_dropout)# 最后一层线性层,输入纬度是(cross Network输出纬度 + Deep Network输出纬度)self.final_linear = nn.Linear(hidden_units[-1] + hidden_units[0], 1)def forward(self, x):# 1、先把输入向量x分成两部分处理、因为数值型和类别型的处理方式不一样dense_input, sparse_inputs = x[:, :len(self.dense_features)], x[:, len(self.dense_features):]# 2、转换为long形sparse_inputs = sparse_inputs.long()# 2、不同的类别特征分别embeddingsparse_embeds = [self.embed_layers['embed_' + key](sparse_inputs[:, i]) for key, i inzip(self.sparse_features_map.keys(), range(sparse_inputs.shape[1]))]# 3、把类别型特征进行拼接,即emdedding后,由3行转换为1行sparse_embeds = torch.cat(sparse_embeds, axis=-1)# 4、数值型和类别型特征进行拼接x = torch.cat([sparse_embeds, dense_input], axis=-1)# cross Networkcross_out = self.cross_network(x)# Deep Networkdeep_out = self.dnn_network(x)# Concatenatetotal_x = torch.cat([cross_out, deep_out], axis=-1)# outoutputs = F.sigmoid(self.final_linear(total_x))return outputsif __name__ == '__main__':x = torch.rand(size=(1, 5), dtype=torch.float32)feature_info = [['I1', 'I2'], # 连续性特征['C1', 'C2', 'C3'], # 离散型特征{'C1': 20,'C2': 20,'C3': 20}]# 建立模型hidden_units = [128, 64, 32]net = DCN(feature_info, hidden_units,layer_num=2)print(net)print(net(x))
DCN((embed_layers): ModuleDict((embed_C1): Embedding(20, 8)(embed_C2): Embedding(20, 8)(embed_C3): Embedding(20, 8))(cross_network): CrossNetwork((cross_weights): ParameterList((0): Parameter containing: [torch.FloatTensor of size 26x1](1): Parameter containing: [torch.FloatTensor of size 26x1])(cross_bias): ParameterList((0): Parameter containing: [torch.FloatTensor of size 26x1](1): Parameter containing: [torch.FloatTensor of size 26x1]))(dnn_network): Dnn((dnn_network): ModuleList((0): Linear(in_features=26, out_features=128, bias=True)(1): Linear(in_features=128, out_features=64, bias=True)(2): Linear(in_features=64, out_features=32, bias=True))(dropout): Dropout(p=0.0, inplace=False))(final_linear): Linear(in_features=58, out_features=1, bias=True)
)
tensor([[0.9349]], grad_fn=<SigmoidBackward0>)
2 Deep&Crossing模型在Criteo数据集的应用
数据的预处理可以参考
深度学习推荐系统(二)Deep Crossing及其在Criteo数据集上的应用_undo_try的博客-CSDN博客
2.1 准备训练数据
import pandas as pdimport torch
from torch.utils.data import TensorDataset, Dataset, DataLoaderimport torch.nn as nn
from sklearn.metrics import auc, roc_auc_score, roc_curveimport warnings
warnings.filterwarnings('ignore')
# 封装为函数
def prepared_data(file_path):# 读入训练集,验证集和测试集train_set = pd.read_csv(file_path + 'train_set.csv')val_set = pd.read_csv(file_path + 'val_set.csv')test_set = pd.read_csv(file_path + 'test.csv')# 这里需要把特征分成数值型和离散型# 因为后面的模型里面离散型的特征需要embedding, 而数值型的特征直接进入了stacking层, 处理方式会不一样data_df = pd.concat((train_set, val_set, test_set))# 数值型特征直接放入stacking层dense_features = ['I' + str(i) for i in range(1, 14)]# 离散型特征需要需要进行embedding处理sparse_features = ['C' + str(i) for i in range(1, 27)]# 定义一个稀疏特征的embedding映射, 字典{key: value},# key表示每个稀疏特征, value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度sparse_feas_map = {}for key in sparse_features:sparse_feas_map[key] = data_df[key].nunique()feature_info = [dense_features, sparse_features, sparse_feas_map] # 这里把特征信息进行封装, 建立模型的时候作为参数传入# 把数据构建成数据管道dl_train_dataset = TensorDataset(# 特征信息torch.tensor(train_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(train_set['Label'].values).float())dl_val_dataset = TensorDataset(# 特征信息torch.tensor(val_set.drop(columns='Label').values).float(),# 标签信息torch.tensor(val_set['Label'].values).float())dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)return feature_info,dl_train,dl_vaild,test_set
file_path = './preprocessed_data/'feature_info,dl_train,dl_vaild,test_set = prepared_data(file_path)
2.2 建立Deep&Crossing模型
from _01_DeepAndCrossing import DCN# 建立模型
hidden_units = [128, 64, 32]net = DCN(feature_info, hidden_units,layer_num=len(hidden_units))
# 测试一下模型
for feature, label in iter(dl_train):out = net(feature)print(feature.shape)print(out.shape)print(out)break
2.3 模型的训练
from AnimatorClass import Animator
from TimerClass import Timer# 模型的相关设置
def metric_func(y_pred, y_true):pred = y_pred.datay = y_true.datareturn roc_auc_score(y, pred)def try_gpu(i=0):if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def train_ch(net, dl_train, dl_vaild, num_epochs, lr, device):"""⽤GPU训练模型"""print('training on', device)net.to(device)# 二值交叉熵损失loss_func = nn.BCELoss()optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train auc', 'val loss', 'val auc'],figsize=(8.0, 6.0))timer, num_batches = Timer(), len(dl_train)log_step_freq = 10for epoch in range(1, num_epochs + 1):# 训练阶段net.train()loss_sum = 0.0metric_sum = 0.0for step, (features, labels) in enumerate(dl_train, 1):timer.start()# 梯度清零optimizer.zero_grad()# 正向传播predictions = net(features)loss = loss_func(predictions, labels.unsqueeze(1) )try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去metric = metric_func(predictions, labels)except ValueError:pass# 反向传播求梯度loss.backward()optimizer.step()timer.stop()# 打印batch级别日志loss_sum += loss.item()metric_sum += metric.item()if step % log_step_freq == 0:animator.add(epoch + step / num_batches,(loss_sum/step, metric_sum/step, None, None))# 验证阶段net.eval()val_loss_sum = 0.0val_metric_sum = 0.0for val_step, (features, labels) in enumerate(dl_vaild, 1):with torch.no_grad():predictions = net(features)val_loss = loss_func(predictions, labels.unsqueeze(1))try:val_metric = metric_func(predictions, labels)except ValueError:passval_loss_sum += val_loss.item()val_metric_sum += val_metric.item()if val_step % log_step_freq == 0:animator.add(epoch + val_step / num_batches, (None,None,val_loss_sum / val_step , val_metric_sum / val_step))print(f'final: loss {loss_sum/len(dl_train):.3f}, auc {metric_sum/len(dl_train):.3f},'f' val loss {val_loss_sum/len(dl_vaild):.3f}, val auc {val_metric_sum/len(dl_vaild):.3f}')print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
lr, num_epochs = 0.001, 10
train_ch(net, dl_train, dl_vaild, num_epochs, lr, try_gpu())

2.4 模型的预测
y_pred_probs = net(torch.tensor(test_set.values).float())
y_pred = torch.where(y_pred_probs>0.5,torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs)
)
y_pred.data[:10]
相关文章:
深度学习推荐系统(五)DeepCrossing模型及其在Criteo数据集上的应用
深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日&am…...

图神经网络教程之HAN-异构图模型
异构图 包含不同类型节点和链接的异构图 异构图的定义:节点类别数量和边的类别数量加起来大于2就叫异构图。 meta-path元路径的定义:连接两个对象的复合关系,比如,节点类型A和节点类型B,A-B-A和B-A-B都是一种元路径。 …...
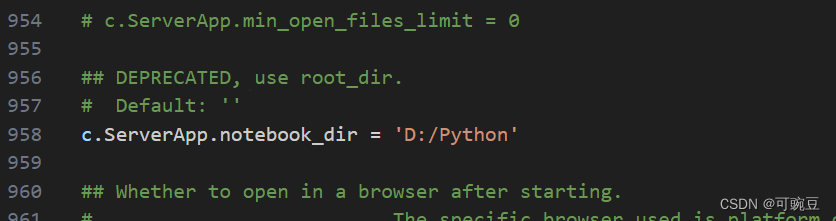
Jupyter lab 配置
切换jupyterlab的默认工作目录 在终端中输入以下命令 PS C:\Users\Administrator> jupyter-lab --generate-config Writing default config to: C:\Users\Administrator\.jupyter\jupyter_lab_config.py它就会生成JupyterLab的配置文件(如果之前有这个文件的话…...

股票行情处理:不复权,前复权,后复权
不复权的话,K线图能真实反应股价历史的除权信息,缺点是会留有大缺口,股价走势不连续,不能直观感受股价的涨跌波动。 前复权是以目前股价为基准复权,可以很清楚的看到股价的历史高点、低点,以及目前股价所处…...
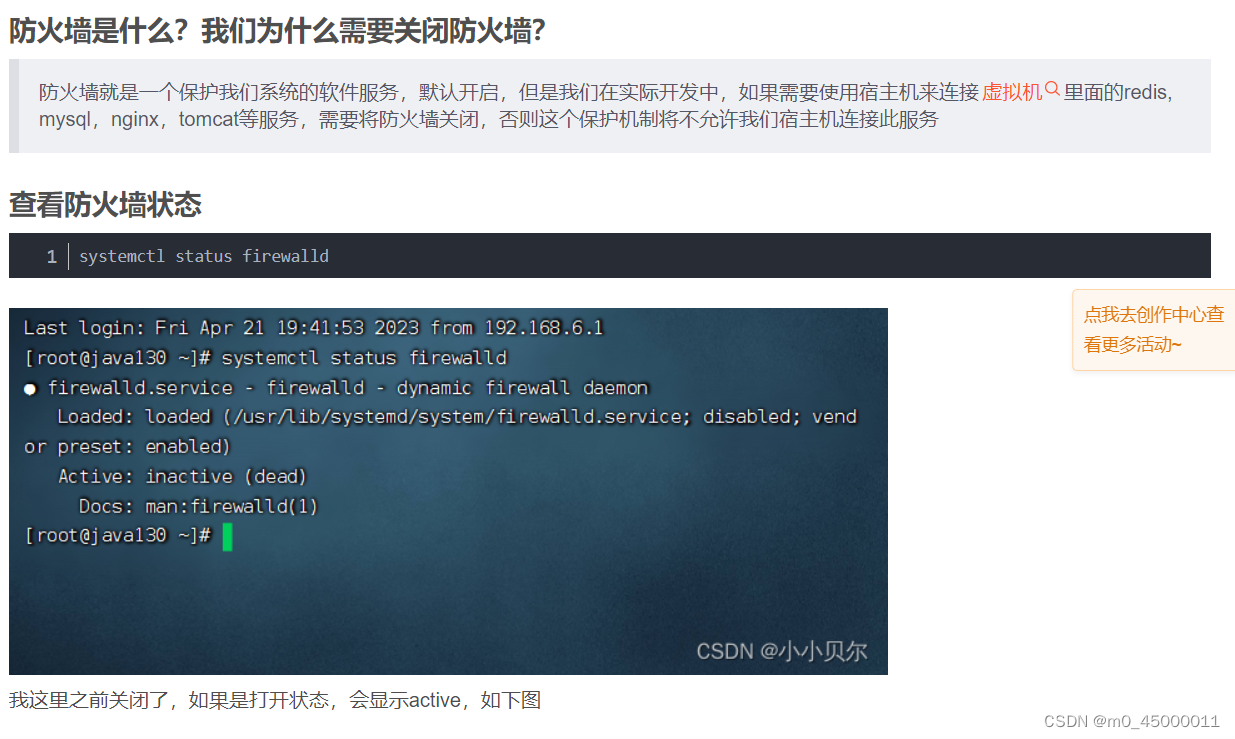
ip地址、LINUX、与虚拟机
子网掩码,是用来固定网络号的,例如255,255,255,0,表明前面三段必须为网络号,后面必须是主机号,那么怎么实现网络复用呢,例如使用c类地址,但是正常子网掩码是255,255,255,…...

MySQL存储过程
存储过程 1、存储过程简介 存储过程与函数的直接效果类似,只不过存储过程,封装的是一组sql语句。 mysql数据库存储过程是一组为了完成特定功能的sql语句的集合。 存储过程这个功能时从5.0版本才开始支持的,它可以加快数据库的处理速度&…...

element-ui 自定义loading加载样式
element-ui 中的 loading 加载功能,默认是全屏加载效果, 设置局部,需要自定义样式,自定义的方法如下: import { Loading } from element-uiVue.prototype.$baseLoading (text) > {let loadingloading Loading.s…...
04-Apache Directory Studio下载安装(LDAP连接工具)
1、下载 官网下载Apache Directory Studio 注意Apache Directory Studio依赖于jdk,对jdk有环境要求 请下载适配本机的jdk版本的Apache Directory Studio,下图为最新版下载地址 Apache Directory Studio Version 2.0.0-M16 基于 Eclipse 2020-12,最低要…...
vmware虚拟机(ubuntu)远程开发golang、python环境安装
目录 1. 下载vmware2. 下载ubuntu镜像3. 安装4. 做一些设置4.1 分辨率设置4.2 语言下载4.3 输入法设置4.4 时区设置 5. 直接切换管理员权限6. 网络6.1 看ip6.2 ssh 7. 本地编译器连接远程服务器7.1 创建远程部署的配置7.2 文件同步7.3 远程启动项目 8. ubuntu安装golang环境8.1…...

Elasticsearch文档多个输入字段组成ID实现方法
1、场景描述: 使用Elasticsearch时,有时会需要指定文档id的场景,当文档id需要多个字段组成时,这种业务怎么处理呢? 2、问题描述: 现有一个ElasticSearch文档,假设文档id由userid、 eventTime…...
rdynamic选项的用途)
编译链接实战(15)rdynamic选项的用途
文章目录 rdynamic作用栈回溯 rdynamic作用 看下gcc man手册的解释: Pass the flag -export-dynamic to the ELF linker, on targets that support it. This instructs the linker to add all symbols, not onlyused ones, to the dynamic symbol table. This opti…...
前端:js实现提示框(自动消失)
效果: 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&q…...

powerpc架构的前世今生
文章目录 Powerpc架构的前世今生什么是powerpc?PowerPC和ARM有什么区别呢? Powerpc架构的前世 PowerPC架构是一种基于精简指令集计算机(RISC)的处理器架构。它最初由IBM、Motorola和Apple共同开发,旨在为个人电脑、工…...

SQL-存储过程、流程控制、游标
存储过程 存储过程概述 1.产生背景 开发过程总,经常会遇到重复使用某一功能的情况 2.解决办法 MySQL引人了存储过程(Stored Procedure)这一技术 3.存储过程 存储过程就是一条或多条SQL语句的集合存储过程可将一系列复杂操作封装成一个代码块,以便…...

JavaScript的数组和字典的用法
JavaScript 中的数组是一种用于存储多个值的数据结构,它可以容纳不同类型的数据(例如数字、字符串、对象等)。以下是 JavaScript 数组的常见用法: 创建数组 // 创建一个空数组 let emptyArray [];// 创建一个包含元素的数组 le…...

中断和异常
1.什么是中断 CPU上会运行两种程序,一种是内核程序,一种是应用程序。在正常的情况,CPU上面会主动运行应用程序,中断就是操作系统内核夺回CPU执行权的唯一途径,也就是用户态——>内核态。 2.内中断和外中断 2.1内…...
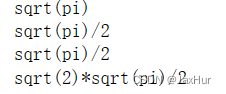
【python】实现积分
借助sympy.integrate() 符号运算库,所以里面的exp(),sin()等都要使用sympy库中的函数,如果使用numpy库中的函数时没用的。 import sympy as sp import numpy as np x sp.symbols("x") print(sp.integrate(sp.exp(-x**2), (x, -s…...

微信仿H5支付
仿H5支付是指一种模拟原生H5支付流程的非官方支付方式。这种支付方式通常是由第三方支付服务提供商开发和维护的,目的是为了绕过官方支付渠道的限制,如费率、审核等问题。然而,由于仿H5支付并非官方授权和认可的支付方式,其安全性…...
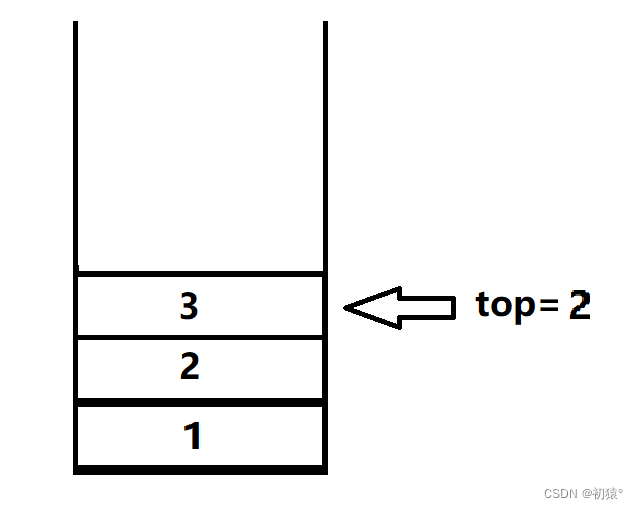
数据结构——栈
栈 栈的理解 咱们先不管栈的数据结构什么,先了解栈是什么,栈就像一个桶一样,你先放进去的东西,被后放进的的东西压着,那么就需要把后放进行的东西拿出才能拿出来先放进去的东西,如图1,就像图1中…...

组件化开发之如何封装组件-react
组件化开发之如何封装组件-react 什么是组件为什么需要封装组件组件的分类函数组件(Functional Components):展示型组件:容器型组件:知道组件分类的意义是? 如何拆分组件,需要遵循什么原则1.保证…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南
#身份证OCR, #OCR接口, #API接入, #Python示例, #Java示例, #PHP示例, #踩坑指南, #石榴智能, #实名认证, #图片识别 身份证OCR识别接口接入实战:Python/Java/PHP/C#四语言代码示例与踩坑指南 作者:石榴智能技术团队 一、前言 身份证OCR识别已经不是什…...

Win10家庭版别再卡了!保姆级教程:手动修复gpedit.msc路径,彻底关闭Antimalware Service
Win10家庭版性能优化实战:精准修复组策略路径与系统服务调优每次游戏激战正酣时突然卡顿,或是视频渲染到关键时刻系统响应迟缓,很多Win10家庭版用户都遭遇过这类困扰。任务管理器里那个名为"Antimalware Service Executable"的进程…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析
高性能Windows流媒体服务器部署:5大核心技术与3种实战架构深度解析 【免费下载链接】srs-windows 项目地址: https://gitcode.com/gh_mirrors/sr/srs-windows 在Windows平台上构建专业级流媒体服务系统,需要综合考虑协议兼容性、性能优化和部署架…...

Redis分布式锁进阶第二十篇
一、本篇前置衔接 第二十篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争抢…...

轻量化部署,异地机房快速接入,多机房管理不用再大动干戈
随着业务拓展,不少企业、单位陆续建起异地分部机房、多区域节点机房。传统资产管理系统部署复杂、对接困难,异地机房接入成本高、周期长,改造繁琐,让很多运维团队望而却步,只能继续沿用分散人工管理,资产混…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...