监督学习的介绍
一、定义
监督学习是利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。它是一种机器学习的方法,目的是让模型能够从已知的输入和输出之间的关系中学习,并且能够对新的输入做出正确的预测。
二、具体介绍
1、监督学习三要素
模型(model):总结数据的内在规律,用数学函数描述的系统
策略(strategy):选取最优模型的评价准则
算法(algorithm):选取最优模型的具体方法
2、监督学习实现步骤
1、得到一个有限的训练数据集
2、确定包含所有学习模型的集合
3、确定模型选择的准则,也就是学习策略
4、实现求解最优模型的算法,也就是学习算法
5、通过学习算法选择最优模型
6、利用得到的最优模型,对新数据进行预测或分析
3、模型评估策略
(1)模型评估
训练集和测试集
损失函数和经验风险
训练误差和测试误差
①训练集和测试集
我们将用来训练模型的数据称为训练集,将用来测试模型好坏的集合称为测试集。
训练集:输入到模型中对模型进行训练的数据集合。
测试集:模型训练完成后测试训练效果的数据集合。
②损失函数
损失函数用来衡量模型预测误差的大小。
定义:选取模型 f 为决策函数,对于给定的输入参数 X,f(X) 为预测结果,Y 为真实结果;f(X) 和 Y 之间可能会有偏差,我们就用一个损失函数(loss function)来度量预测偏差的程度,记作 L(Y,f(X))。损失函数是系数的函数,损失函数值越小,模型就越好。
③经验风险
经验风险最小化(Empirical Risk Minimization,ERM)
这一策略认为,经验风险最小的模型就是最优的模型样本足够大时,ERM 有很好的学习效果,因为有足够多的“经验”样本较小时,ERM 就会出现一些问题
④训练误差和测试误差
i)训练误差(training error)是关于训练集的平均损失。训练误差的大小,可以用来判断给定问题是否容易学习,但本质上并不重要。
ii)测试误差(testing error)是关于测试集的平均损失。其真正反映了模型对未知数据的预测能力,这种能力一般被称为泛化能力。
(2)模型选择
过拟合和欠拟合正则化和交叉验证
①过拟合和欠拟合
模型把训练数据学习的太彻底,以至于把噪声数据的特征也学习到了,特征集过大,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差,称之为过拟合(over-fitting)。例如,想分辨一只猫,给出了四条腿、两只眼、一条尾巴、叫声、颜色,能够捕捉老鼠、喜欢吃鱼、… …,然后恰好所有的训练数据的猫都是白色,那么这个白色是一个噪声数据,会干扰判断,结果模型把颜色是白色也学习到了,而白色是局部样本的特征,不是全局特征,就造成了输入一个黑猫的数据,判断出不是猫。
模型没有很好地捕捉到数据特征,特征集过小,导致模型不能很好地拟合数据,称之为欠拟合(under-fitting)。 欠拟合的本质是对数据的特征“学习”得不够。例如,想分辨一只猫,只给出了四条腿、两只眼、有尾巴这三个特征,那么由此训练出来的模型根本无法分辨猫。
②模型的选择
当模型复杂度增大时,训练误差会逐渐减小并趋向于0;而测试误差会先减小,达到最小值之后再增大。
当模型复杂度过大时,就会发生过拟合;所以模型复杂度应适当。
③正则化
结构风险最小化(Structural Risk Minimization,SRM),是在 ERM 基础上,为了防止过拟合而提出来的策略。在经验风险上加上表示模型复杂度的正则化项(regularizer),或者叫惩罚项。正则化项一般是模型复杂度的单调递增函数,即模型越复杂,正则化值越大。结构风险最小化的典型实现是正则化(regularization),如果简单的模型已经够用,我们不应该一味地追求更小的训练误差,而把模型变得越来越复杂。
④交叉验证
数据集划分
如果样本数据充足,一种简单方法是随机将数据集切成三部分:训练集(training set)、验证集 (validation set)和测试集(test set)。训练集用于训练模型,验证集用于模型选择,测试集用于学习方法评估。数据不充足时,可以重复地利用数据——交叉验证(cross validation)
简单交叉验证
数据随机分为两部分,如70%作为训练集,剩下30%作为测试集;训练集在不同的条件下(比如参数个数)训练模型,得到不同的模型;在测试集上评价各个模型的测试误差,选出最优模型;
S折交叉验证
将数据随机切分为S个互不相交、相同大小的子集;S-1个做训练集,剩下一个做测试集;重复进行训练集、测试集的选取,有S种可能的选择;
留一交叉验证
三、类别
监督学习有很多种算法,每种算法都有自己的优缺点,适用于不同的问题和数据。下面介绍一些比较常用的监督学习算法。
1、线性回归:这是一种最基本的监督学习算法,它的目的是找到一个线性函数,使得它能够最好地拟合输入和输出之间的关系。线性回归可以用于处理连续型的输出变量,比如预测房价、股票价格等。线性回归的优点是简单易懂,计算效率高,但是缺点是不能处理非线性的关系,也不能处理分类问题。
2、逻辑回归:这是一种用于处理分类问题的监督学习算法,它的目的是找到一个逻辑函数,使得它能够最好地划分不同类别的输入。逻辑回归可以用于处理二分类或多分类问题,比如预测是否患病、是否点击广告等。逻辑回归的优点是简单易懂,可以给出概率输出,但是缺点是不能处理非线性的关系,也不能处理回归问题。
3、决策树:这是一种用于处理分类或回归问题的监督学习算法,它的目的是构建一棵树形结构,使得它能够最好地划分不同类别或预测输出值的输入。决策树可以用于处理离散型或连续型的输入和输出变量,比如预测贷款是否违约、预测销量等。决策树的优点是直观易懂,可以处理非线性的关系,但是缺点是容易过拟合,也容易受到噪声和异常值的影响。
4、支持向量机:这是一种用于处理分类或回归问题的监督学习算法,它的目的是找到一个超平面或超曲面,使得它能够最好地划分不同类别或预测输出值的输入。支持向量机可以用于处理高维或非线性的数据,比如图像识别、文本分类等。支持向量机的优点是具有很强的泛化能力,可以处理复杂的关系,但是缺点是计算效率低,参数选择困难。
5、神经网络:这是一种用于处理分类或回归问题的监督学习算法,它的目的是构建一个由多层神经元组成的网络结构,使得它能够最好地拟合输入和输出之间的关系。神经网络可以用于处理任意类型和形式的数据,比如语音识别、自然语言处理等。神经网络的优点是具有很强的表达能力,可以处理非常复杂和抽象的关系,但是缺点是训练效率低,容易陷入局部最优解。
以上就是一些常见的监督学习算法,当然还有很多其他的算法,比如k-近邻、朴素贝叶斯、随机森林、梯度提升树等。不同的算法适用于不同的问题和数据,选择合适的算法需要考虑很多因素,比如数据的特征、规模、分布、噪声等,以及模型的复杂度、可解释性、稳定性等。一般来说,没有一种算法是万能的,需要根据具体的情况进行比较和测试,才能找到最优的解决方案。
引用
[1]https://www.dandelioncloud.cn/article/details/1489391056461615105
[2]https://blog.csdn.net/qq_39315069/article/details/119361967
[3]https://baijiahao.baidu.com/s?id=1761426464724224950&wfr=spider&for=pc
相关文章:

监督学习的介绍
一、定义 监督学习是利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的过程,也称为监督训练或有教师学习。它是一种机器学习的方法,目的是让模型能够从已知的输入和输出之间的关系中学习,并且能够对新的输入做出正确…...

【DRONECAN】(三)WSL2 及 ubuntu20.04 CAN 驱动安装
【DRONECAN】(三)WSL2 及 ubuntu20.04 CAN 驱动安装 前言 这一篇文章主要介绍一下 WSL2 及 ubuntu20.04 CAN 驱动的安装,首先说一下介绍本文的目的。 大家肯定都接触过 ubuntu 系统,但是我们常用的操作系统都是 Windows&#x…...
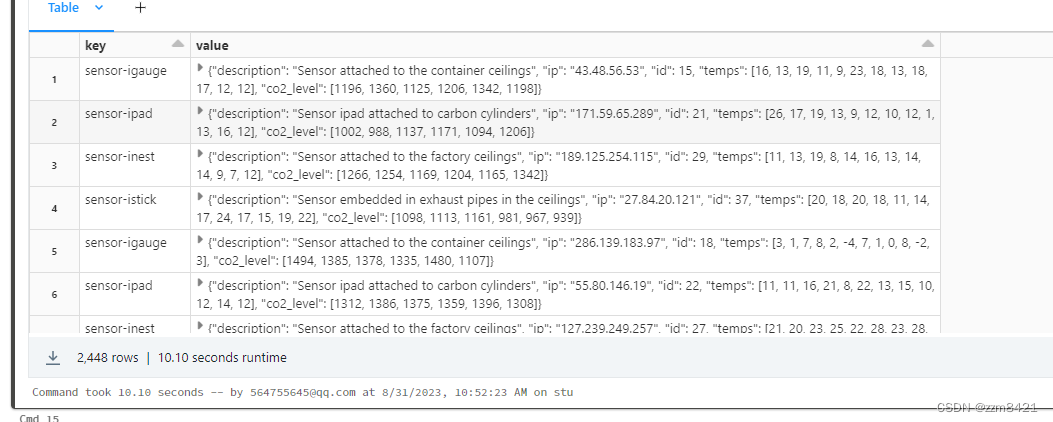
Databricks 入门之sql(二)常用函数
1.类型转换函数 使用CAST函数转换数据类型(可以起别名) SELECTrating,CAST(timeRecorded as timestamp) FROMmovieRatings; 支持的数据类型有: BIGINT、BINARY、BOOLEAN、DATE 、DECIMAL(p,s)、 DOUBLE、 FLOAT、 INT、 INTERVAL interva…...
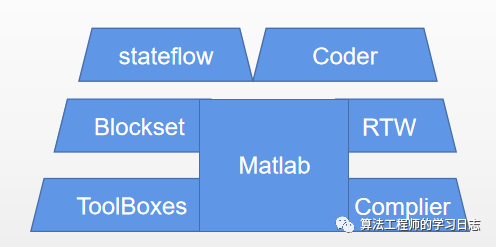
Simulink建模与仿真(3)-Simulink 简介
分享一个系列,关于Simulink建模与仿真,尽量整理成体系 1、Simulink特点 Simulink是一个用来对动态系统进行建模、仿真和分析的软件包。使用Simulink来建模、分析和仿真各种动态系统(包括连续系统、离散系统和混合系统),将是一件非常轻松的事…...

(超简单)将图片转换为ASCII字符图像
将一张图片转换为ASCII字符图像 原图: 效果图: import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.FileWriter; import java.io.IOException;public class ImageToASCII {/*** 将图片转换为A…...

In-Context Retrieval-Augmented Language Models
本文是LLM系列文章,针对《In-Context Retrieval-Augmented Language Models》的翻译。 上下文检索增强语言模型 摘要1 引言2 相关工作3 我们的框架4 实验细节5 具有现成检索器的上下文RALM的有效性6 用面向LM的重新排序改进上下文RALM7 用于开放域问答的上下文RALM…...

多种免费天气api
多种免费天气api推荐 一、高德天气二、格点天气三、香港天文台 一、高德天气 api说明文档:https://lbs.amap.com/api/webservice/guide/api/weatherinfo 实例代码: import requests# 香港天文台API的URL api_url "https://restapi.amap.com/v3/w…...

深度学习推荐系统(五)DeepCrossing模型及其在Criteo数据集上的应用
深度学习推荐系统(五)Deep&Crossing模型及其在Criteo数据集上的应用 在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日&am…...

图神经网络教程之HAN-异构图模型
异构图 包含不同类型节点和链接的异构图 异构图的定义:节点类别数量和边的类别数量加起来大于2就叫异构图。 meta-path元路径的定义:连接两个对象的复合关系,比如,节点类型A和节点类型B,A-B-A和B-A-B都是一种元路径。 …...
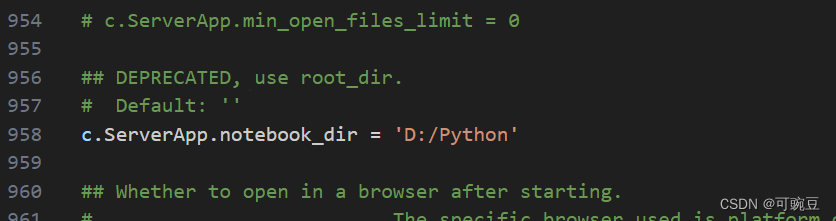
Jupyter lab 配置
切换jupyterlab的默认工作目录 在终端中输入以下命令 PS C:\Users\Administrator> jupyter-lab --generate-config Writing default config to: C:\Users\Administrator\.jupyter\jupyter_lab_config.py它就会生成JupyterLab的配置文件(如果之前有这个文件的话…...

股票行情处理:不复权,前复权,后复权
不复权的话,K线图能真实反应股价历史的除权信息,缺点是会留有大缺口,股价走势不连续,不能直观感受股价的涨跌波动。 前复权是以目前股价为基准复权,可以很清楚的看到股价的历史高点、低点,以及目前股价所处…...
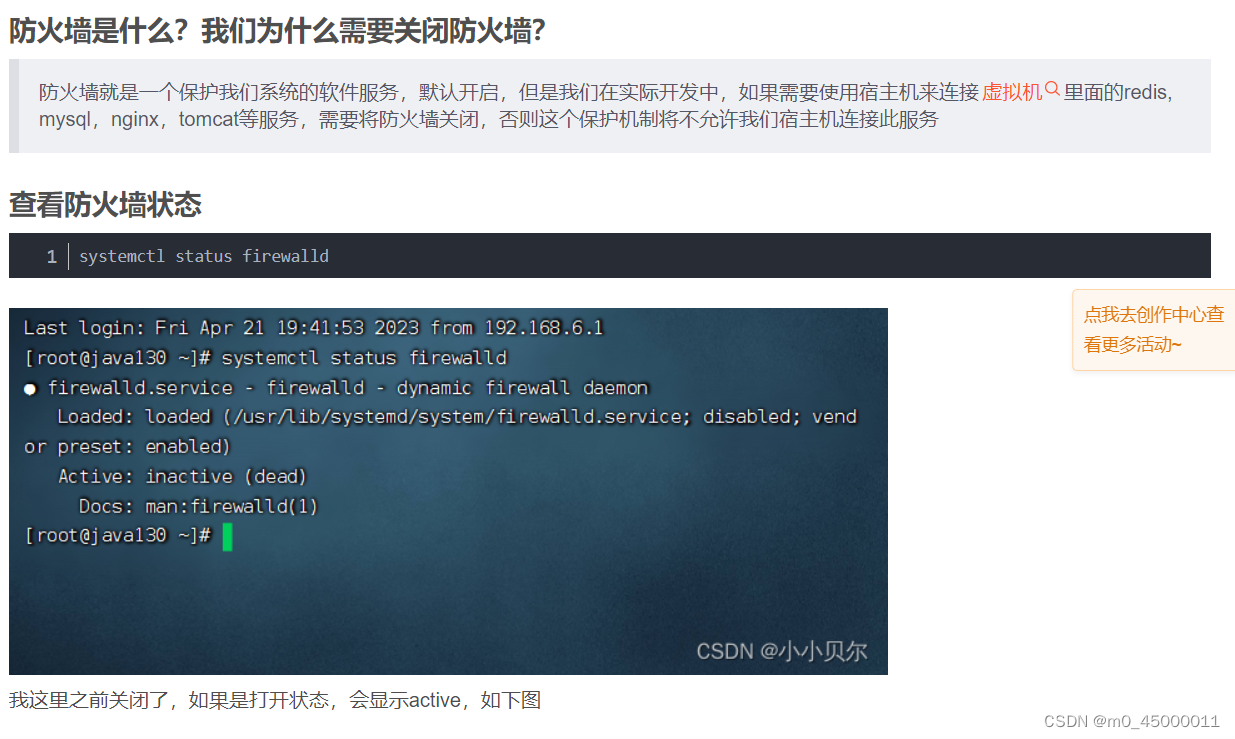
ip地址、LINUX、与虚拟机
子网掩码,是用来固定网络号的,例如255,255,255,0,表明前面三段必须为网络号,后面必须是主机号,那么怎么实现网络复用呢,例如使用c类地址,但是正常子网掩码是255,255,255,…...

MySQL存储过程
存储过程 1、存储过程简介 存储过程与函数的直接效果类似,只不过存储过程,封装的是一组sql语句。 mysql数据库存储过程是一组为了完成特定功能的sql语句的集合。 存储过程这个功能时从5.0版本才开始支持的,它可以加快数据库的处理速度&…...

element-ui 自定义loading加载样式
element-ui 中的 loading 加载功能,默认是全屏加载效果, 设置局部,需要自定义样式,自定义的方法如下: import { Loading } from element-uiVue.prototype.$baseLoading (text) > {let loadingloading Loading.s…...
04-Apache Directory Studio下载安装(LDAP连接工具)
1、下载 官网下载Apache Directory Studio 注意Apache Directory Studio依赖于jdk,对jdk有环境要求 请下载适配本机的jdk版本的Apache Directory Studio,下图为最新版下载地址 Apache Directory Studio Version 2.0.0-M16 基于 Eclipse 2020-12,最低要…...
vmware虚拟机(ubuntu)远程开发golang、python环境安装
目录 1. 下载vmware2. 下载ubuntu镜像3. 安装4. 做一些设置4.1 分辨率设置4.2 语言下载4.3 输入法设置4.4 时区设置 5. 直接切换管理员权限6. 网络6.1 看ip6.2 ssh 7. 本地编译器连接远程服务器7.1 创建远程部署的配置7.2 文件同步7.3 远程启动项目 8. ubuntu安装golang环境8.1…...

Elasticsearch文档多个输入字段组成ID实现方法
1、场景描述: 使用Elasticsearch时,有时会需要指定文档id的场景,当文档id需要多个字段组成时,这种业务怎么处理呢? 2、问题描述: 现有一个ElasticSearch文档,假设文档id由userid、 eventTime…...
rdynamic选项的用途)
编译链接实战(15)rdynamic选项的用途
文章目录 rdynamic作用栈回溯 rdynamic作用 看下gcc man手册的解释: Pass the flag -export-dynamic to the ELF linker, on targets that support it. This instructs the linker to add all symbols, not onlyused ones, to the dynamic symbol table. This opti…...
前端:js实现提示框(自动消失)
效果: 代码: <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&q…...

powerpc架构的前世今生
文章目录 Powerpc架构的前世今生什么是powerpc?PowerPC和ARM有什么区别呢? Powerpc架构的前世 PowerPC架构是一种基于精简指令集计算机(RISC)的处理器架构。它最初由IBM、Motorola和Apple共同开发,旨在为个人电脑、工…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...
)
手把手教你为WCH CH582移植CherryUSB主机栈(基于RT-Thread,含中断优化)
基于RT-Thread的WCH CH582 USB主机协议栈深度移植指南在嵌入式开发领域,USB主机功能的实现往往意味着设备能够直接连接各类USB外设,从简单的键盘鼠标到复杂的存储设备。对于使用WCH CH582这类RISC-V内核MCU的开发者而言,原厂SDK提供的USB主机…...

【DeepSeek开源协议识别权威指南】:20年合规专家亲授3大协议陷阱与5步精准识别法
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开源协议识别的底层逻辑与合规价值 DeepSeek系列模型(如DeepSeek-V2、DeepSeek-Coder)虽以“开源”名义发布,但其实际许可状态需通过结构化协议解析才能准确…...

taotoken如何帮助ubuntu开发者应对大模型api的频繁更新与版本迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken如何帮助Ubuntu开发者应对大模型API的频繁更新与版本迭代 对于在Ubuntu环境下进行开发的工程师而言,大模型API…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

DIY四路自动音频源切换器:从信号检测到继电器隔离的完整设计
1. 项目概述与核心需求解析作为一个喜欢在工作室里捣鼓各种音频设备的玩家,我经常遇到一个挺烦人的问题:我的功放只有一组输入,但我想接的设备却有好几个——台式电脑、平板、蓝牙接收模块,还有一台树莓派。每次想切换音源&#x…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...

开源三角洲机器人Delta-Robot One:从入门到精通的创客实践指南
1. 项目概述:一个为学习而生的开源三角洲机器人如果你对机器人感兴趣,但又觉得它高深莫测、无从下手,那么Delta-Robot One(我们亲切地称它为“One”)可能就是为你量身打造的入门项目。这不是一个遥不可及的工业设备&am…...

如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南
如何让旧款Mac运行最新系统:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重新焕发活力&a…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...