50个简洁的提示提高代码可读性和效率(0-10)
这篇文章整理了50个简洁的提示,可以提高您的代码可读性和效率。这些提示来自个人项目、彻底的代码审查和与资深开发人员的启发性讨论。
无论您是新手还是经验丰富的开发人员,这篇文章都应该能够帮助您学到一些东西。
这个列表包括常见的Python模式、核心概念和最佳实践。
由于没有特定的顺序,请随时直接跳转到您感兴趣的部分。
不再废话,让我们来看看吧👀
1 — 三元操作符
Python中的三元操作符提供了一种内联方式来编写条件表达式。当您需要根据条件为变量分配一个值时,它们特别有用。
age = 25
status = "成年人" if age >= 18 else "未成年人"print(status)
# 成年人
在这个示例中,如果年龄大于或等于18,status变量的值将是"成年人",否则将是"未成年人"。
当它们用于列表推导式时,三元操作符非常有用
scores = [100, 46, 54, 23, 20, 99]
threshold = 50
results = ["通过" if score > threshold else "未通过" for score in scores]print(results)
# ['通过', '未通过', '通过', '未通过', '未通过', '通过']
或者用于lambda函数:
scores = [100, 46, 54, 23, 20, 99]
threshold = 50results = map(lambda score: "通过" if score > threshold else "未通过", scores)
print(results)
# ['通过', '未通过', '通过', '未通过', '未通过', '通过']
2 — 上下文管理器
想象一下,您用Python打开一个文件,在文件中写入了一些行,然后在您甚至无法关闭它之前发生了异常。
虽然这对于初学者开发人员来说似乎不是什么问题,但它会占用一个永远不会被清除的内存资源(文件描述符),并且可能会阻止部分数据被写入。
上下文管理器可以帮助您避免这种情况。它们用于管理资源,并确保这些资源被正确初始化和清理。
它们通过封装资源管理的逻辑在上下文管理器对象内,有助于编写更可读和可维护的代码。
→ 最常见的上下文管理器是使用open创建的
with open('file.txt', 'r') as file:# 如果在这里发生了任何错误data = file.read()
open()函数返回一个文件对象,它充当上下文管理器。当with语句内部的块退出时,它会自动关闭文件,确保正确的清理。
您还可以在其他情况下使用上下文管理器来处理:
👉 数据库连接:
import psycopg2with psycopg2.connect(database='mydb') as conn:cursor = conn.cursor()cursor.execute('SELECT * FROM table')results = cursor.fetchall()
在这个示例中,psycopg2库的connect()方法返回一个连接对象,它充当上下文管理器,当块退出时会自动关闭连接。
👉 锁定资源:
import threading
lock = threading.Lock()def some_function():with lock:# 临界代码段
在这里,threading模块的Lock()对象被用作上下文管理器,以确保一次只有一个线程可以访问关键代码段。
3 — 创建自己的上下文管理器!
有时您可能需要定义自己的上下文管理器。
为此,您需要定义一个实现__enter__()和__exit__()方法的类:
- enter()在with块启动时调用
- exit()在执行离开with代码块时调用
以下是一个测量代码块执行时间的自定义上下文管理器示例:
示例1:计时器
import timeclass Timer:def __enter__(self):self.start_time = time.time()def __exit__(self, exc_type, exc_val, exc_tb):elapsed_time = time.time() - self.start_timeprint(f"执行时间:0.0556秒")
这个示例非常简单。让我们看看另一个模仿open行为的示例。
示例2:自定义文件打开器
class WritableFile:def __init__(self, file_path):self.file_path = file_pathdef __enter__(self):print("打开文件")self.file_obj = open(self.file_path, mode="w")return self.file_objdef __exit__(self, exc_type, exc_val, exc_tb):if self.file_obj:self.file_obj.close()print("文件成功关闭")
虽然这些示例相当简单,但它们应该为您提供一个构建更高级上下文管理器的起点代码段,其中执行适当的资源清理。
4 — 枚举
如果您想要迭代一个序列并同时跟踪每个项目的索引,那么应该使用enumerate函数。
它通过消除手动管理单独的索引变量,使代码更加简洁。
fruits = ['苹果', '香蕉', '橙子']
for index, fruit in enumerate(fruits):print(f"索引:{index},水果:{fruit}")# 索引:0,水果:苹果
# 索引:1,水果:香蕉
# 索引:2,水果:橙子
5 — Zip
zip函数允许同时迭代多个序列:
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
for name, age in zip(names, ages):print(f"姓名:{name},年龄:{age}")# 姓名:Alice,年龄:25
# 姓名:Bob,年龄:30
# 姓名:Charlie,年龄:35
作为有趣的用例,zip还可以从两个列表创建一个字典,其中键来自第一个列表,值来自第二个列表。
keys = ['a', 'b', 'c']
values = [1, 2, 3]
my_dict = dict(zip(keys, values))
print(my_dict)# {'a': 1, 'b': 2, 'c': 3}
6 — 使用sorted对复杂对象进行排序
sorted函数允许您根据某些属性对复杂对象进行排序。
要访问要排序的属性值,您必须使用自定义的key函数。
假设您要根据"age"键对这些人进行排序。
people = [{'name': 'Alice', 'age': 25},{'name': 'Bob', 'age': 30},{'name': 'Charlie', 'age': 20}
]
只需将key参数设置为指向age值。sorted_people = sorted(people, key=lambda x: x['age'])
print(sorted_people)# [{'name': 'Charlie', 'age': 20}, {'name': 'Alice', 'age': 25}, {'name': 'Bob', 'age': 30}]
如果将字典替换为对象,它的工作方式也是一样的:
class Person:def __init__(self, name, age):self.name = nameself.age = agepeople = [Person('Alice', 25),Person('Bob', 30),Person('Charlie', 20)
]
sorted_people = sorted(people, key=lambda x: x.age)
print([person.name for person in sorted_people])print(sorted_people)# ['Charlie', 'Alice', 'Bob']
7 — 使用生成器节省内存
Python生成器是一种可迭代类型,可用于即时生成一系列值,而不必将它们全部存储在内存中。它们使用yield关键字定义,而不是return。
这是一个计算斐波那契数的简单生成器。
def fibonacci_generator():a, b = 0, 1while True:yield aa, b = b, a + b
调用这个函数实际上不会运行它。它创建并返回一个生成器对象。
fib = fibonacci_generator()fib
# <generator object fibonacci_generator at 0x7fea39c31890>
这个生成器对象仅在传递给next函数时生成斐波那契值。
next(fb)
# 0
next(fb)
# 1
next(fb)
# 1
next(fb)
# 2
或者使用for循环迭代(在底层基本上调用了next函数)。
这是内存高效的,因为它避免了预先生成整个(无限)序列。
生成器的一个自然用例是逐行(或分块)读取大型数据集
def read_large_file(filename):with open(filename, 'r') as file:for line in file:yield line#逐行处理而不是加载整个文件
file_generator = read_large_file('large_file.txt')for line in file_generator:process_line(line) #处理
8 — 使用f-strings改进字符串格式化!
f-strings改进了字符串格式化语法:它们是字符串文字,以f开头,包含用于替换为其值的表达式的花括号。
语法非常简单。
name = "Alice"
age = 25
print(f"你好{name},你今年{age}岁!") # 你好Alice,你今年25岁!
甚至可以用它来计算任意表达式,比如函数调用:
def add_numbers(a, b):return a + bx = 5
y = 3
print(f"{x}和{y}的和是{add_numbers(x, y)}。") # 输出:5和3的和是8。
带有特定精度的浮点数:
pi = 3.14159265359
print(f"π的值约为{pi:.2f}。")
# 输出:π的值约为3.14。
对象。
class Person:def __init__(self, name, age):self.name = nameself.age = ageperson = Person("Bob", 25)
print(f"姓名:{person.name},年龄:{person.age}")
# 输出:姓名:Bob,年龄:25
字典(在字典键周围使用简单的引号)
data_scientist = {'name': 'Ahmed BESBES', 'age': 32}
f"This data scientist is {data_scientist['name']}, aged {data_scientist['age']}."
这个数据科学家是Ahmed BESBES,年龄是32岁。
9 — 使用迭代器协议构建可迭代对象
您是否曾经想知道简单的for循环在幕后是如何工作的?
答案不在for循环本身,而是在被迭代的对象中(也称为可迭代对象)。这些可以是列表、字典或集合。
事实上,可迭代对象支持迭代器协议并实现__iter__()和__next__()双下划线方法。
这些双下划线方法是使得可以迭代一组元素或执行自定义迭代的核心方法。
下面是一个自定义迭代器的示例,它接受一个数字列表并在运行时生成它们的平方:
class SquareIterator:def__init__(self, numbers):self.numbers = numbersself.index = 0def __iter__(self):return selfdef __next__(self):if self.index >= len(self.numbers):raise StopIterationsquare = self.numbers[self.index] ** 2self.index += 1return square
在__iter__()方法中,返回迭代器对象本身。当初始化迭代器时调用此方法。
在__next__()方法中,定义检索迭代中下一个元素的逻辑。
当没有更多元素可以迭代时,此方法应引发StopIteration异常。(请注意,索引在这里递增以跟踪其位置)
我们可以像这样使用这个自定义迭代器:
numbers = [1, 2, 3, 4, 5]
iterator = SquareIterator(numbers)for square in iterator:print(square)# 1
# 4
# 9
# 16
# 25
10 — 创建自定义异常类以记录您的代码
我从未考虑过创建自定义异常类。我只依赖于内置的异常。
事实是,在大型代码库中使用它们会带来多重好处。
它们允许您创建更具体和有意义的异常,准确表示代码中发生的错误或异常情况。这有助于调试提高了协作:
如果您的同事开始向同一存储库推送代码,他们更容易通过具有明确消息而不是通用的ValueError异常来调试错误
这是一个自定义异常类的示例,当输入字符串长度超过阈值时引发异常。
class NameTooLongError(Exception):"""用于过长名称的自定义异常。"""def __init__(self, name, max_length):self.name = nameself.max_length = max_lengthsuper().__init__(f"名称'{name}'太长,允许的最大长度为{max_length}个字符。")def process_name(name):max_length = 10 # 允许的最大名称长度if len(name) > max_length:raise NameTooLongError(name, max_length)else:print("名称处理成功:", name)# 示例用法
try:input_name = "AVeryLongName"process_name(input_name)
except NameTooLongError as e:print("错误:", e)
本文由mdnice多平台发布
相关文章:
)
50个简洁的提示提高代码可读性和效率(0-10)
这篇文章整理了50个简洁的提示,可以提高您的代码可读性和效率。这些提示来自个人项目、彻底的代码审查和与资深开发人员的启发性讨论。 无论您是新手还是经验丰富的开发人员,这篇文章都应该能够帮助您学到一些东西。 这个列表包括常见的Python模式、核…...

Linux —— 进程信号
一,信号概念 信号是进程之间事件异步通知的一种方式,属于软中断; 系统定义的信号 每个信号都有一个编号和一个宏定义名称(可在signal.h查看);编号34以上的为实时信号; [wz192 Desktop]$ kill -…...

Android笔记 自定义控件时drawText字符串宽度的3种计算方式
String str "hello"; canvas.drawText(str, x, y, mPaint);//1. 粗略计算文字宽度: float width mPaint.measureText(str);//2. 计算文字的矩形,可以得到宽高: Rect rect new Rect(); mPaint.getTextBounds(str, 0, str.length(…...

ChatRWKV 学习笔记和使用指南
0x0. 前言 Receptance Weighted Key Value(RWKV)是pengbo提出的一个新的语言模型架构,它使用了线性的注意力机制,把Transformer的高效并行训练与RNN的高效推理相结合,使得模型在训练期间可以并行,并在推理…...

Particle Life粒子生命演化的MATLAB模拟
Particle Life粒子生命演化的MATLAB模拟 0 前言1 基本原理1.1 力影响-吸引排斥行为1.2 距离rmax影响 2 多种粒子相互作用2.1 双种粒子作用2.1 多种粒子作用 3 代码 惯例声明:本人没有相关的工程应用经验,只是纯粹对相关算法感兴趣才写此博客。所以如果有…...

golang中byte和rune的区别?
golang中byte和rune的区别? rune和byte在go语言中都是字符类型,从源码来看他们都是别名形式 // byte is an alias for uint8 and is equivalent to uint8 in all ways. It is // used, by convention, to distinguish byte values from 8-bit unsigned…...

AI图像行为分析算法 opencv
AI图像行为分析算法通过pythonopencv深度学习框架对现场操作行为进行全程实时分析,AI图像行为分析算法通过人工智能视觉能够准确判断出现场人员的作业行为是否符合SOP流程规定,并对违规操作行为进行自动抓拍告警。OpenCV是一个基于Apache2.0许可…...
MATLAB制图代码【第二版】
MATLAB制图代码【第二版】 文档描述 Code describtion: This code is version 2 used for processing the data from the simulation and experiment. Time : 2023.9.3 Author: PEZHANG 这是在第一版基础上,迭代出的第二版MATLAB制图代码,第二版的特点是…...
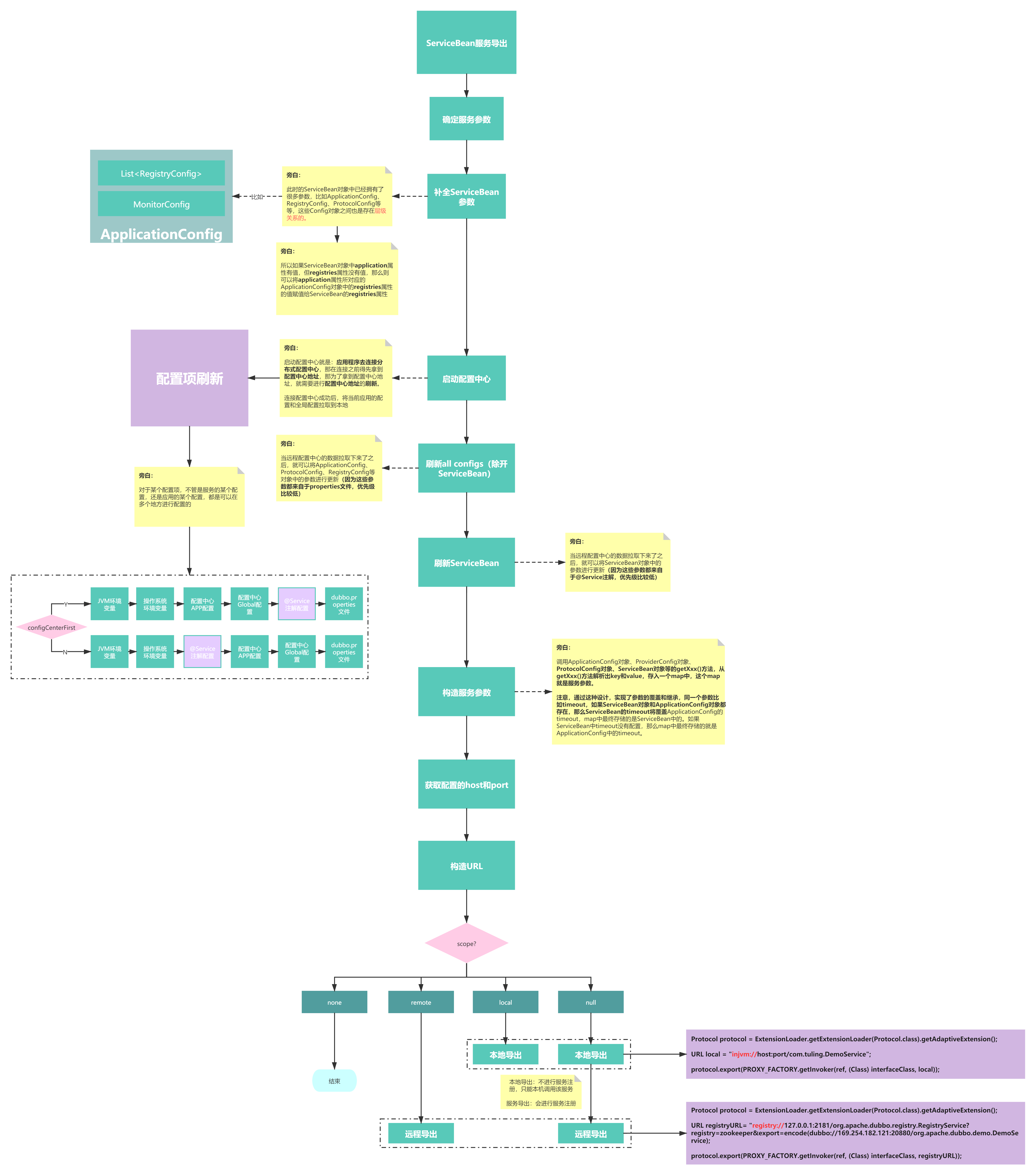
5.0: Dubbo服务导出源码解析
#Dubbo# 文章内容 Dubbo服务导出基本原理分析Dubbo服务注册流程源码分析Dubbo服务暴露流程源码分析服务导出的入口方法为ServiceBean.export(),此方法会调用ServiceConfig.export()方法,进行真正的服务导出。 1. 服务导出大概原理 服务导出的入口方法为ServiceBean.export…...

python自动化测试-自动化基本技术原理
1 概述 在之前的文章里面提到过:做自动化的首要本领就是要会 透过现象看本质 ,落实到实际的IT工作中就是 透过界面看数据。 掌握上面的这样的本领可不是容易的事情,必须要有扎实的计算机理论基础,才能看到深层次的本质东西。 …...

lodash 之 _.isEmpty
lodash.isEmpty() 是 Lodash 库中的一个函数,用于检查给定值是否为空。它可以用于判断对象、数组、字符串等不同类型的值是否为空。 const _ require(lodash);console.log(_.isEmpty(null)); // 输出: trueconsole.log(_.isEmpty(undefined)); // 输出: trueconso…...
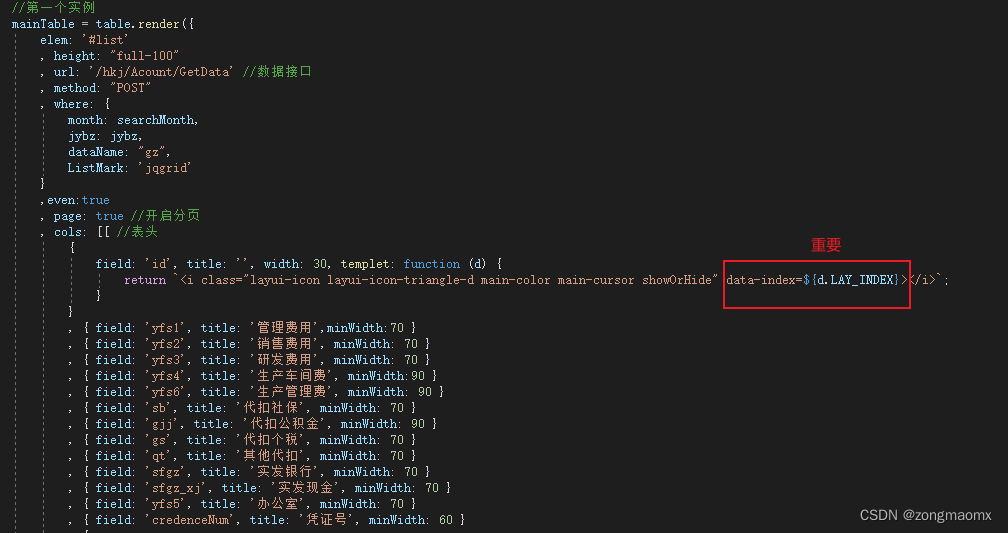
layui数据表格实现表格中嵌套表格,并且可以折叠展开
效果: 思路: 1、最外层的表格先渲染,在done回调中向每个tr后面插入一个用来嵌套子级表格的tr。 tr的class和table的id需要用索引 i 关联 //向每一行tr后面追加显示子table的trlet trEles $(".layui-table-view[lay-idlist] tbody tr&…...
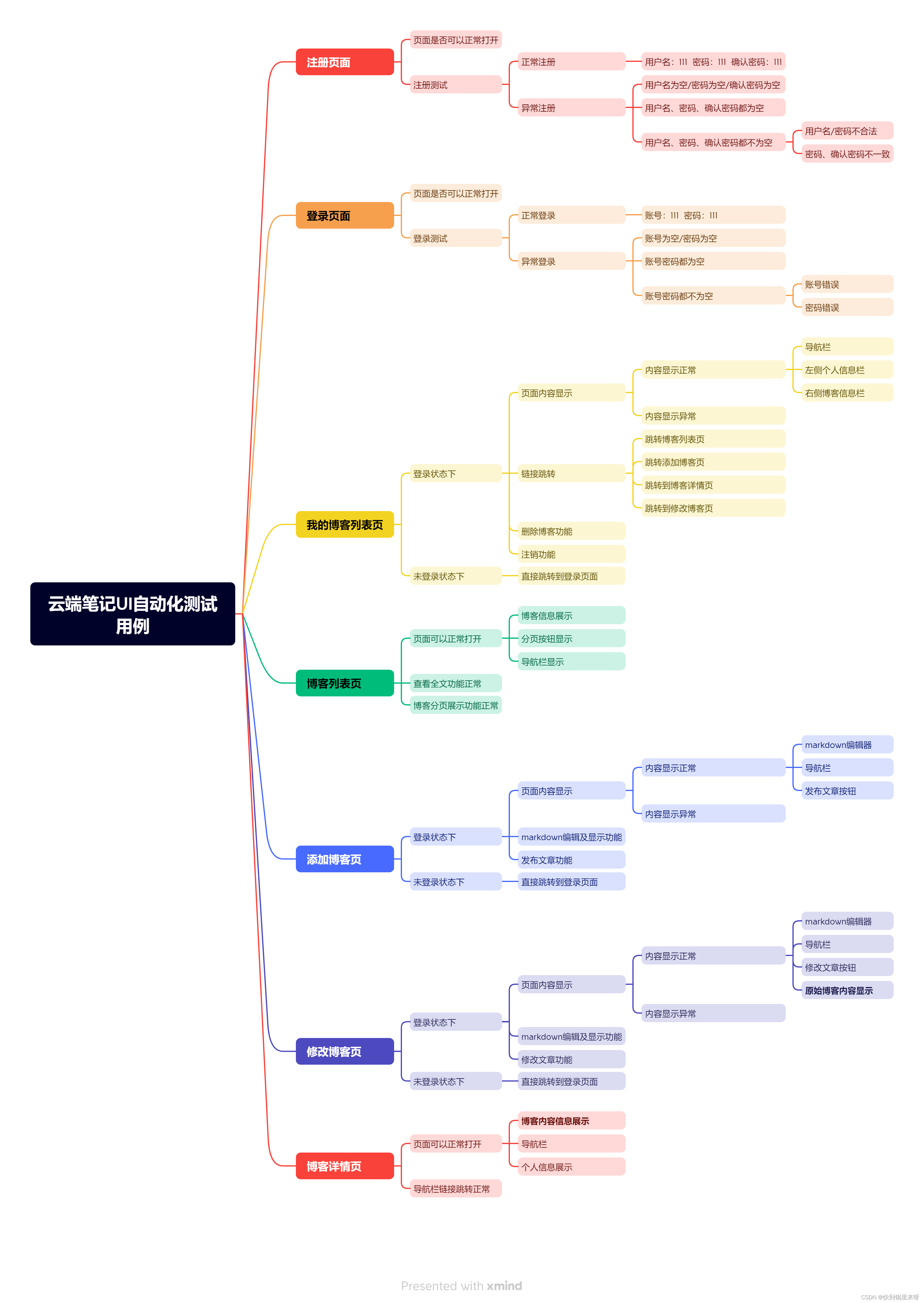
云端笔记系统-自动化测试
文章目录 1. 思维导图编写 Web 自动化测试用例2. 创建测试项目3. 根据思维导图设计【云端笔记】自动化测试用例3.1. 准备工具类3.2. 测试注册页面3.3. 测试登陆页面3.4. 测试添加博客页3.5. 测试我的博客列表页3.6. 测试修改博客页3.7. 测试博客列表页3.8. 测试博客详情页3.9. …...

将帅要避免五个方面的弱点:蛮干、怕死、好名、冲动、溺爱民众
将帅要避免五个方面的弱点:蛮干、怕死、好名、冲动、溺爱民众 【安志强趣讲《孙子兵法》第28讲】 【原文】 是故屈诸侯者以害,役诸侯者以业,趋诸侯者以利。 【注释】 趋:归附、依附。 【趣讲白话】 所以,用祸患威逼诸侯…...
2023开学礼《乡村振兴战略下传统村落文化旅游设计》许少辉八一新书成都理工大学图书馆
2023开学礼《乡村振兴战略下传统村落文化旅游设计》许少辉八一新书成都理工大学图书馆...

vue的第3篇 第一个vue程序
一 vue的mvvm实践者 1.1 介绍 Model:模型层, 在这里表示JavaScript对象 View:视图层, 在这里表示DOM(HTML操作的元素) ViewModel:连接视图和数据的中间件, Vue.js就是MVVM中的View Model层的实现者 在M…...

线性求逆元
先暴力求出 1 n ! \frac 1 {n!} n!1往回推出 1 i ! \frac 1 {i!} i!1 1 i ( i − 1 ) ! i ! \Large \frac 1 i\frac{(i-1)!}{i!} i1i!(i−1)!...
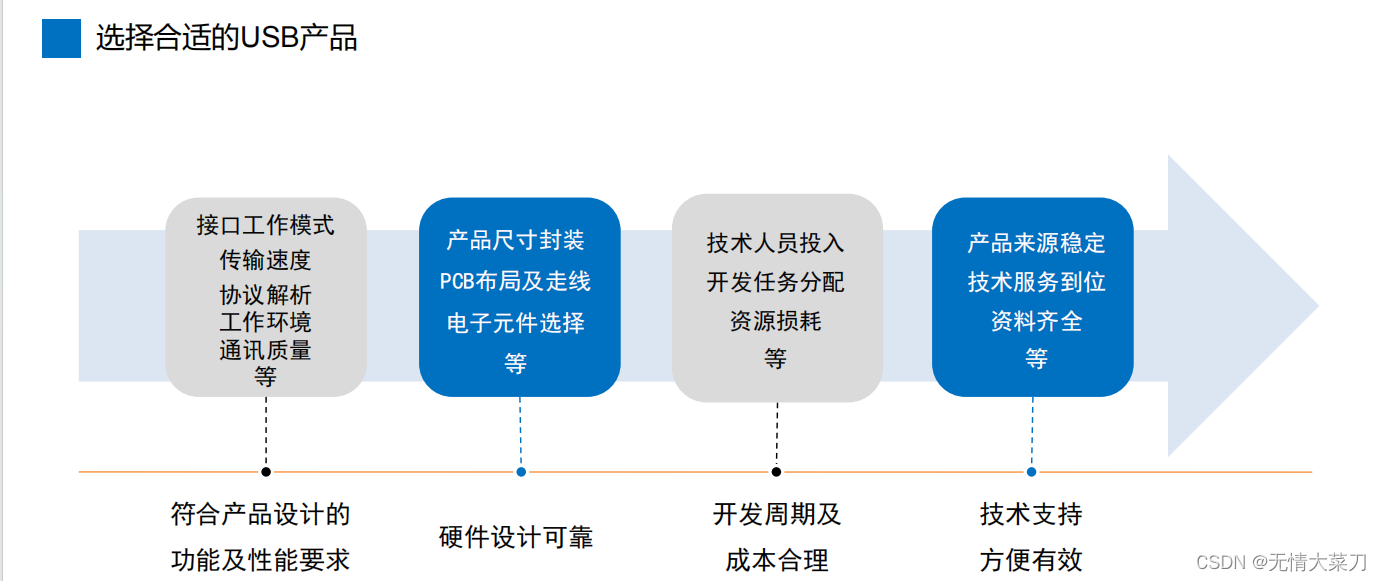
第一章 USB应用笔记之USB初步了解
USB应用笔记之USB初步了解 文章目录 USB应用笔记之USB初步了解前言USB的优点:USB版本发展USB速度以及电气接口USB传输过程USB开发抓包工具:USB传输方式1.控制传输特点:2.中断传输的特点3. 批量传输的特点4.实时传输(同步传输)的特…...
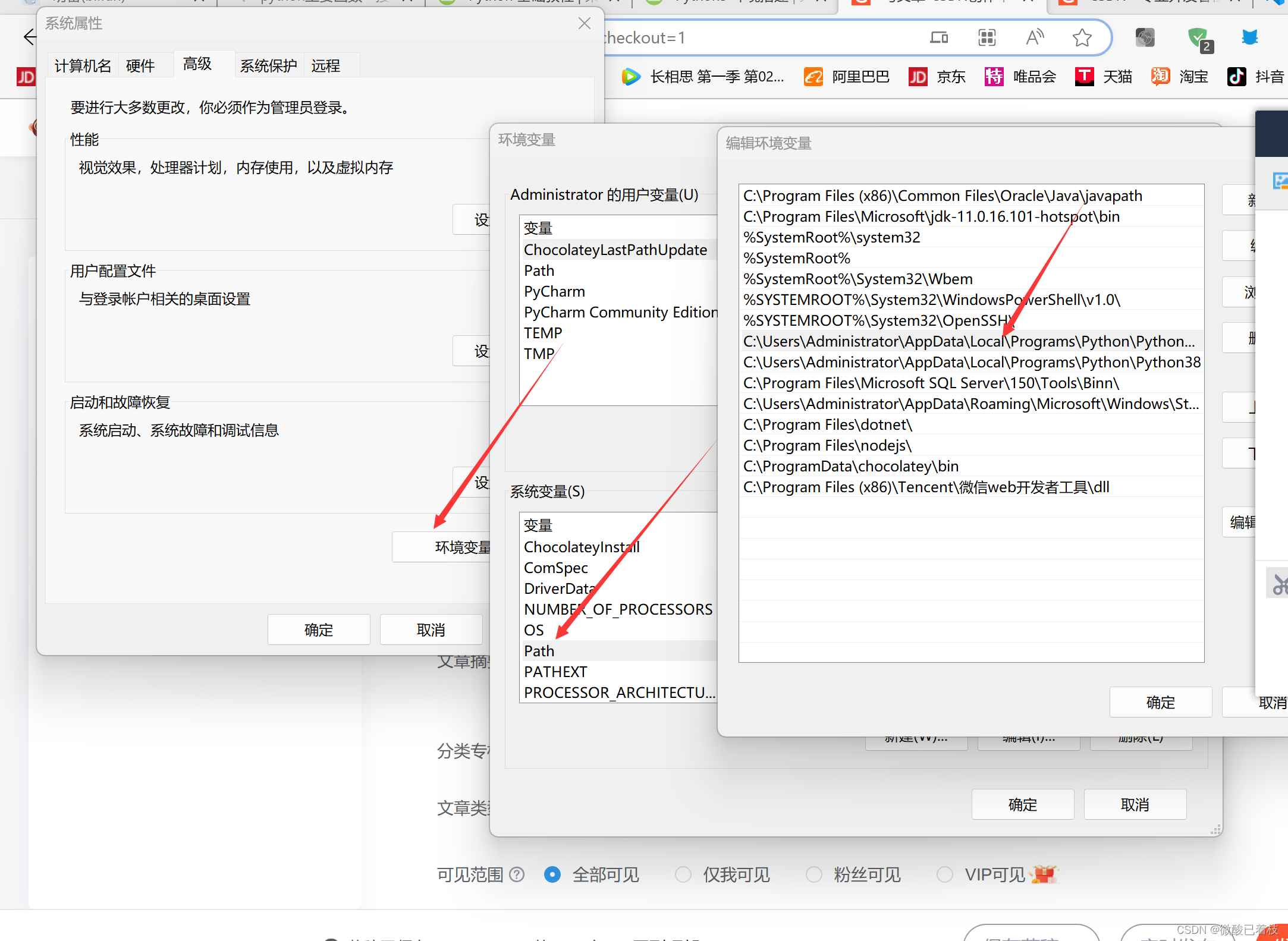
小白入门python
建议用vscode进行代码学习 vscode下载地址:Download Visual Studio Code - Mac, Linux, Windows 左侧点击扩展安装python,右下角选择python版本,记得配置系统环境变量,python在系统(cmd)的版本由环境变量优先级决定,在编程软件中由自己选择解释器...

《Kubernetes部署篇:Ubuntu20.04基于containerd部署kubernetes1.24.17集群(多主多从)》
一、架构图 如下图所示: 二、环境信息 1、部署规划主机名K8S版本系统版本内核版本IP地址备注k8s-master-631.24.17Ubuntu 20.04.5 LTS5.15.0-69-generic192.168.1.63master节点 + etcd节点k8s-master-641.24.17Ubuntu 20.04.5 LTS5.15.0-69-generic192.168.1.64master节点 + …...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...
)
告别外部中断!用EnableInterrupt库轻松搞定Arduino Nano多通道PWM读取(附完整代码)
Arduino Nano多通道PWM读取实战:用EnableInterrupt突破硬件限制当你用Arduino Nano开发四轴飞行器或机器人项目时,是否遇到过这样的尴尬:遥控器的四个通道PWM信号需要同时读取,但Nano只有两个外部中断引脚?这个问题困扰…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

在多轮对话应用中观察Taotoken计费对成本的影响
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多轮对话应用中观察Taotoken计费对成本的影响 效果展示类,结合一个需要维护长上下文的多轮对话应用案例,…...