官方推荐:6种Pandas读取Excel的方法
Pandas提供了多种读取Excel文件的方法,以下是官方推荐的6种方法:
1. 使用pd.read_excel()函数
这是最常用的方法,可以读取Excel文件,并将其转换为Pandas数据框。可以指定工作表名和列名的行号。
df = pd.read_excel('data.xlsx', sheet_name='Sheet1', header=0)
'data.xlsx'是要读取的Excel文件的文件路径。sheet_name='Sheet1'表示要读取的工作表名为’Sheet1’。如果省略该参数,默认读取第一个工作表。header=0表示将文件中的第0行作为列名。如果省略该参数,默认将文件中的第一行作为列名。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
2. 使用pd.ExcelFile()和parse()函数
先使用pd.ExcelFile()函数创建一个Excel文件对象,然后使用parse()函数读取指定的工作表。
xlsx = pd.ExcelFile('data.xlsx')
df = xlsx.parse('Sheet1', header=0)
pd.ExcelFile('data.xlsx')创建了一个Excel文件对象xlsx,它代表了整个Excel文件。parse('Sheet1', header=0)函数用于从Excel文件对象xlsx中读取指定的工作表。'Sheet1'表示要读取的工作表名为’Sheet1’,header=0表示将文件中的第0行作为列名。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
3. 使用pd.read_table()函数
可以读取Excel中的数据表,并指定分隔符(如制表符或逗号)。
df = pd.read_table('data.xlsx', sheet_name='Sheet1', delimiter='\t', header=0)
'data.xlsx'是Excel文件的路径。sheet_name='Sheet1'表示要读取的工作表名为’Sheet1’。delimiter='\t'指定数据表中的分隔符为制表符(‘\t’)。header=0表示将文件中的第0行作为列名。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
4. 使用pd.read_csv()函数
可以读取以逗号分隔的Excel文件,可以指定分隔符、工作表名和列名的行号。
df = pd.read_csv('data.csv', sheet_name='Sheet1', delimiter=',', header=0)
'data.xlsx'是Excel文件的路径。sheet_name='Sheet1'表示要读取的工作表名为’Sheet1’。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
5. 使用pd.read_html()函数
可以读取Excel文件中的HTML表格,并将其转换为Pandas数据框。
tables = pd.read_html('data.xlsx', sheet_name='Sheet1')
df = tables[0]
'data.xlsx'是Excel文件的路径。sheet_name='Sheet1'表示要读取的工作表名为’Sheet1’。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
6. 使用pd.DataFrame.from_records()函数
可以读取Excel文件中的记录,并将其转换为Pandas数据框。
data = pd.ExcelFile('data.xlsx').parse('Sheet1').to_records()
df = pd.DataFrame.from_records(data)
'data.xlsx'是Excel文件的路径。sheet_name='Sheet1'表示要读取的工作表名为’Sheet1’。
读取完Excel文件后,将其转换为Pandas数据框,并将结果赋值给变量df。可以使用df.head()函数查看前几行数据,或使用其他Pandas函数和方法进行数据处理和分析。
以上是官方推荐的6种读取Excel文件的方法。根据具体的需求和Excel文件的格式,选择适合的方法来读取数据。
Pandas提供了读取Excel文件的方法,可以使用read_excel()函数来实现。以下是读取Excel文件的方法:
首先,需要确保已经安装了Pandas库。可以使用以下命令进行安装:
pip install pandas
接下来,导入Pandas库:
import pandas as pd
使用read_excel()函数来读取Excel文件。该函数的基本语法如下:
df = pd.read_excel('文件路径', sheet_name='工作表名', header=行号)
'文件路径':Excel文件的路径,可以是相对路径或绝对路径。'工作表名':要读取的工作表的名称。如果未指定,默认读取第一个工作表。header:指定要用作列名的行号。通常,第一行是列名,所以使用0作为行号。如果Excel文件没有行号作为列名,则可以设置为None。
以下是一个完整的示例:
import pandas as pd# 读取Excel文件
df = pd.read_excel('data.xlsx', sheet_name='Sheet1', header=0)# 打印数据框前几行
print(df.head())
以上代码将会读取名为"data.xlsx"的Excel文件中的"Sheet1"工作表,并将数据存储在名为"df"的数据框中。然后,通过head()函数打印数据框的前几行。
通过上述方法,您可以轻松地使用Pandas读取Excel文件并进行数据分析和处理。
相关文章:

官方推荐:6种Pandas读取Excel的方法
Pandas提供了多种读取Excel文件的方法,以下是官方推荐的6种方法: 1. 使用pd.read_excel()函数 这是最常用的方法,可以读取Excel文件,并将其转换为Pandas数据框。可以指定工作表名和列名的行号。 df pd.read_excel(data.xlsx, …...

Redis与Mysql区别
一、关系型数据库 mysql,pgsql,oracle ,sqlserver 支持连表关联查询(会有一些特定的语法特特性) 二、非关系型数据库 redis,mongodb,memcache (key-value) 三、关系型数据库与非关系型数据库的区别: 1&am…...

Black-Box Tuning for Language-Model-as-a-Service
本文是LLM系列的文章,针对《Black-Box Tuning for Language-Model-as-a-Service》的翻译。 语义模型即服务的黑盒调整 摘要1 引言2 背景3 方法4 实验5 讨论与未来工作 摘要 GPT-3等超大的预训练语言模型(PTM)通常作为服务发布。它允许用户设…...

通用的ARM64架构镜像
#此链接包含x86架构和ARM架构的pytorch镜像,镜像里面已下载好各种第三方库,GPU版本的pytorch可用。缺点:镜像有点大 测试环境:操作系统麒麟银河V10,ARM64处理器(cpu),显卡为T4显卡 …...
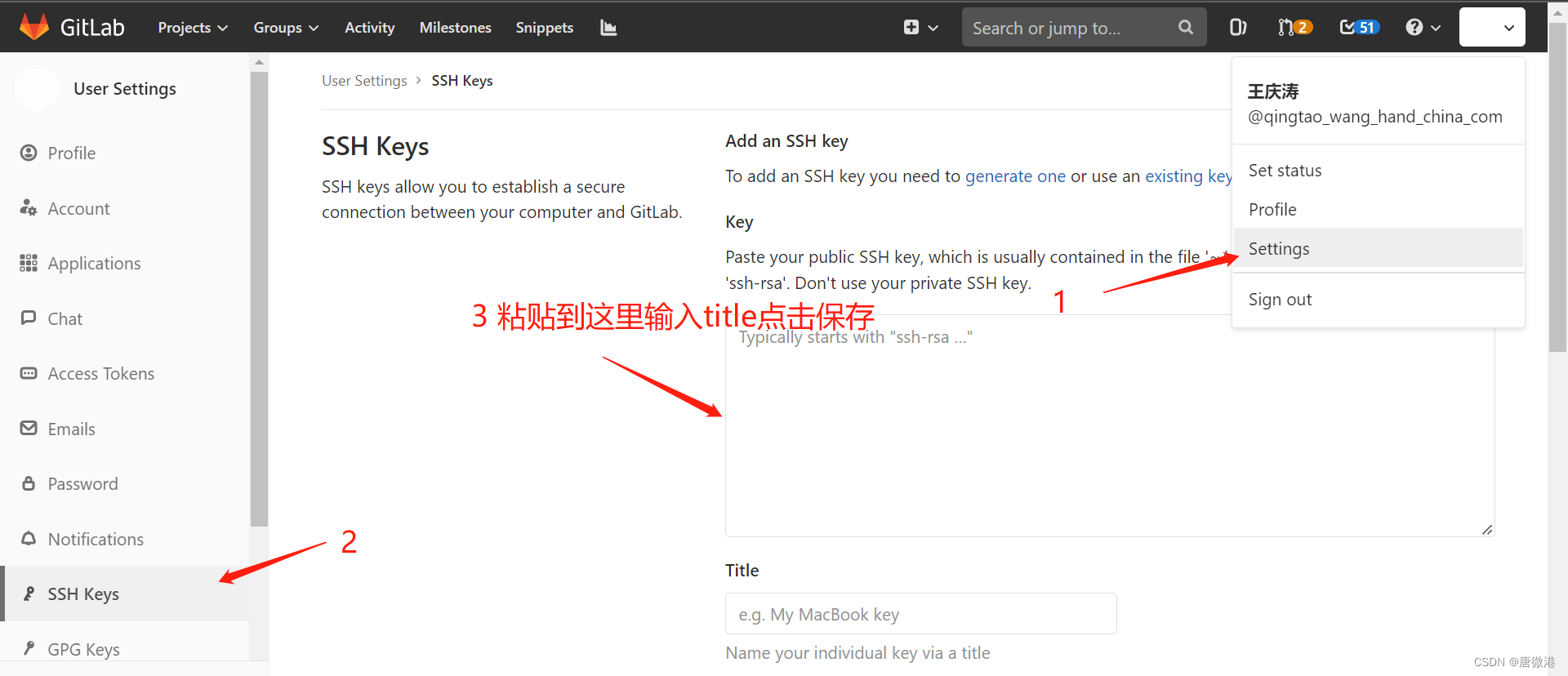
git大文件推送报错
报错信息 不多掰扯,直接上报错信息和截图 Delta compression using up to 8 threadsRPC failde; HTTP 413 curl 22 The requested URL returned error: 413 Request Entity Too Large从以上的报错信息不难看出推送仓库的时候,请求体过大,为…...

RDMA性能优化经验浅谈
一、RDMA概述 首先我们介绍一下RDMA的一些核心概念,当然了,我并不打算写他的API以及调用方式,我们更多关注这些基础概念背后的硬件执行方式和原理,对于这些原理的理解是能够写出高性能RDMA程序的关键。 Memory Region RDMA的网…...

day 44 | ● 309.最佳买卖股票时机含冷冻期 ● 714.买卖股票的最佳时机含手续费
309.最佳买卖股票时机含冷冻期 此外,在返回的时候,由于状态234都是卖出的状态,所以要比较其最大值进行返回。 func maxProfit(prices []int) int {dp : make([][]int, len(prices))dp[0] make([]int, 4)dp[0][0] -prices[0]for i : 1; i &…...
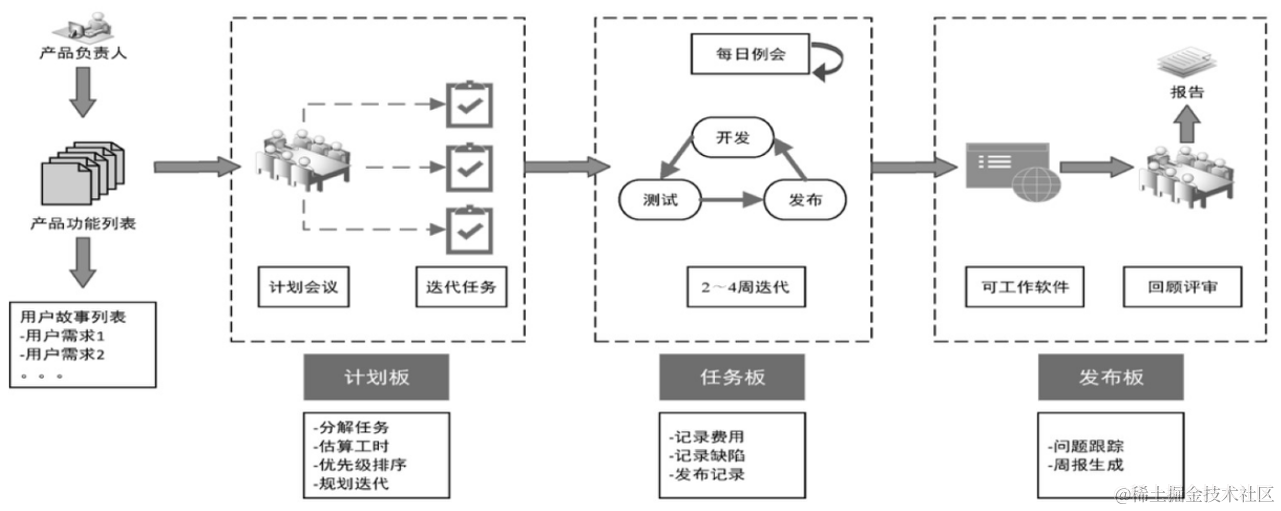
电子科大软件系统架构设计——系统分析与设计概述(含课堂作业、练习答案)
系统分析与设计概述 信息系统概述 what 信息系统是一种能够完成对业务数据进行采集、转换、加工、计算、分析、传输、维护等信息处理,并能就某个方面问题给用户提供信息服务的计算机应用系统。 组成 信息化基础设施(计算机、计算机网络、服务器、系统…...
)
【SpringMVC】@RequestMapping注解(详解)
文章目录 前言1、RequestMapping注解的功能2、RequestMapping注解的位置3、RequestMapping注解的value属性4、RequestMapping注解的method属性1、对于处理指定请求方式的控制器方法,SpringMVC中提供了RequestMapping的派生注解2、常用的请求方式有get,po…...

8.(Python数模)马尔科夫链预测
Python实现马尔科夫链预测 马尔科夫链原理 马尔科夫链是一种进行预测的方法,常用于系统未来时刻情况只和现在有关,而与过去无关。 用下面这个例子来讲述马尔科夫链。 如何预测下一时刻计算机发生故障的概率? 当前状态只存在0(故…...

什么是浏览器缓存(browser caching)?如何使用HTTP头来控制缓存?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 浏览器缓存和HTTP头控制缓存⭐ HTTP头控制缓存1. Cache-Control2. Expires3. Last-Modified 和 If-Modified-Since4. ETag 和 If-None-Match ⭐ 缓存策略⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击…...

谁需要了解学习RPA?什么地方可以使用RPA?
RPA(Robotic Process Automation)是一种通过软件机器人自动化执行特定任务和流程的技术。以下是一些需要了解RPA的人群: 企业决策者:企业决策者需要了解RPA的潜在收益和风险,以及如何将其纳入企业的数字化转型战略中。…...

Qt各个版本下载及安装教程(离线和非离线安装)
Qt各个版本下载链接: Index of /archive/qthttps://download.qt.io/archive/qt/ 离线安装 ,离线安装很无脑,下一步下一步就可以。 我离线下载 半个小时把2G的exe下载下来了...

使用爬虫代码获得深度学习目标检测或者语义分割中的图片。
问题描述:目标检测或者图像分割需要大量的数据,如果手动从网上找的话会比较慢,这时候,我们可以从网上爬虫下来,然后自己筛选即可。 代码如下(不要忘记安装代码依赖的库): # -*- co…...
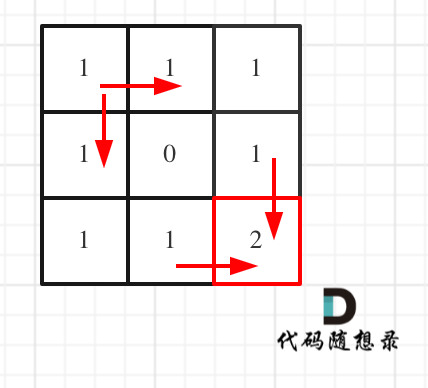
代码随想录算法训练营第39天 | ● 62.不同路径 ● 63. 不同路径II
文章目录 前言一、62.不同路径二、63.不同路径II总结 前言 动态规划 一、62.不同路径 深搜动态规划数论 深搜: 注意题目中说机器人每次只能向下或者向右移动一步,那么其实机器人走过的路径可以抽象为一棵二叉树,而叶子节点就是终点&#…...

《网站建设:从规划到发布的全过程详解》
一、引言 在数字时代,网站已经成为企业和个人在互联网上的重要存在。一个优质网站的建立需要周全的规划、设计、开发、测试和发布。本文将详细介绍网站建设的全过程,帮助读者了解和掌握网站建设的流程和方法。 二、网站建设的意义 网站建设具有以下意…...
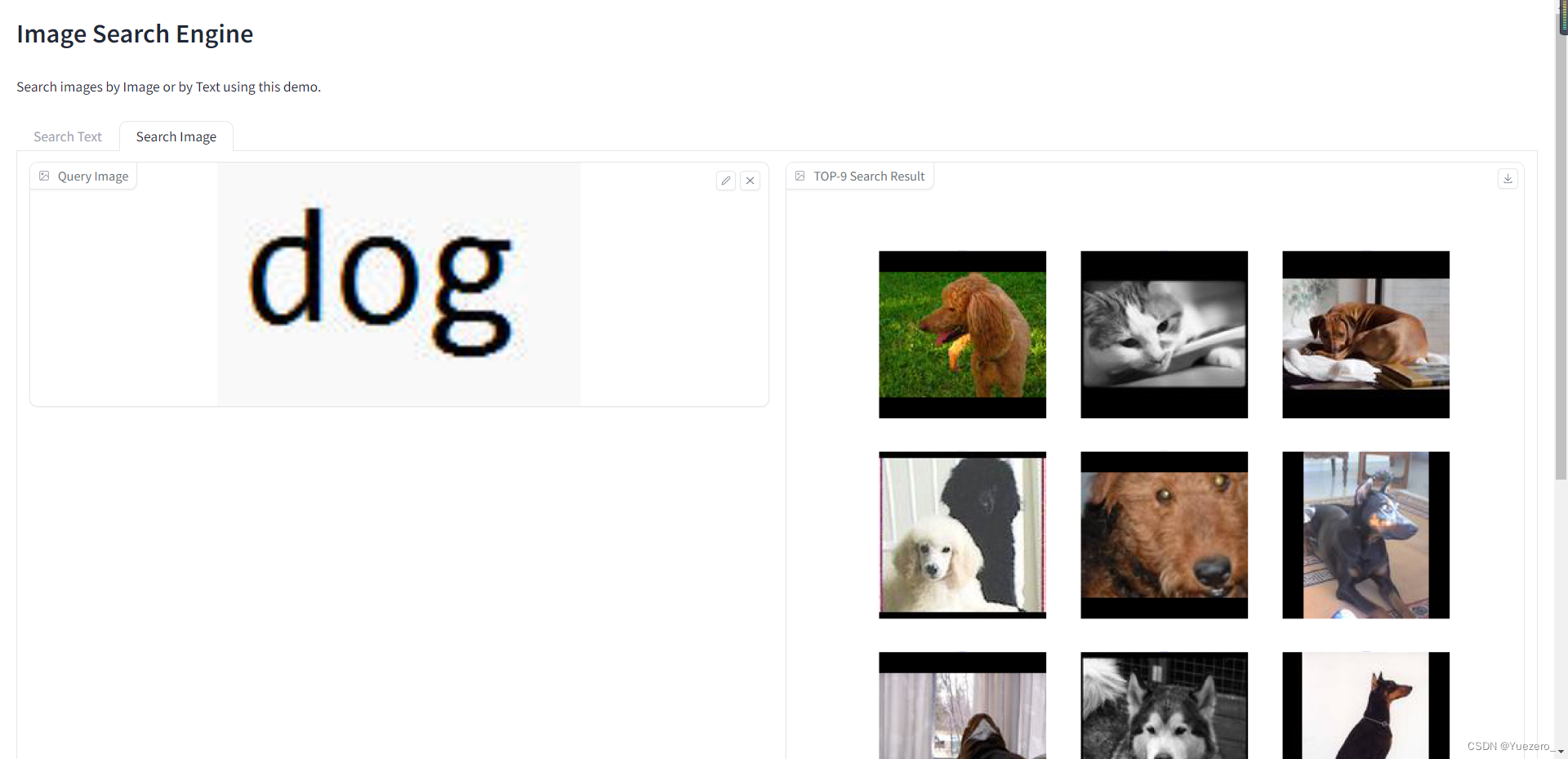
1分钟实现 CLIP + Annoy + Gradio 文搜图+图搜图 系统
多模态图文搜索系统 CLIP 进行 Text 和 Image 的语义EmbeddingAnnoy 向量数据库实现树状结构索引来加速最近邻搜索Gradio 轻量级的机器学习 Web 前端搭建 文搜图 图搜图 CLIP图像语义提取功能!...

用树形dp+状压维护树上操作的计数问题:0902T3
发现操作数 k ≤ 6 k\le6 k≤6,可以考虑对操作进行状压。 然后找找性质,发现要么删掉一棵子树,要么进去该子树。可以视为每种操作有两种情况。 然后分讨一下当前该如何转移。 树形dp的顺序: 合并子树考虑当前往上的边的方向 …...
【python爬虫】批量识别pdf中的英文,自动翻译成中文上
不管是上学还是上班,有时不可避免需要看英文文章,特别是在写毕业论文的时候。比较头疼的是把专业性很强的英文pdf文章翻译成中文。我记得我上学的时候,是一段一段复制,或者碰到不认识的单词就百度翻译一下,非常耗费时间。本文提供批量识别pdf中英文的方法,后续文章实现自…...

Android笔记--Hilt
Hilt 是 Android 的依赖项注入库,可减少在项目中执行手动依赖项注入的样板代码。执行手动依赖项注入要求您手动构造每个类及其依赖项,并借助容器重复使用和管理依赖项。依赖注入的英文是Dependency Injection,简称DI,简单说一个类中使用的依赖…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

巨量投放总结
巨量商务管理平台 : https://business.oceanengine.com 巨量广告投放平台: https://ad.oceanengine.com 商务管理平台 账户 广告组 计划 广告投放平台 层级关系: 广告组 -> 计划 -> 创意 对应FB: 系列 - > 广告组 -> 广告...

我们公司全员把 Cursor 换成了自研的 全开源AtomCode
【引子】这是一篇实录——一位 CTO 用 28 天,用 Claude GLM 双模型调度,造出了一个让全公司放弃 Cursor 的工具。然后我意识到我们正在经历的事情,比"换工具"大得多。【读者承诺】接下来 15 分钟,你会拿到三件东西:一个真实案例(28 天 1,146 commits 是怎么做出来的…...

Arduino ADC自检:用RC电路诊断模数转换器故障
1. 项目概述:当你的体重秤开始“说谎”你有没有遇到过这样的情况:站上家里的电子体重秤,屏幕上跳出来的数字让你瞬间怀疑人生?要么是轻得离谱,要么是重得吓人,更诡异的是,它可能只在两个固定的、…...

从《吃豆人》到开放世界:聊聊Unity Navigation里Agent Radius和Cost的那些‘潜规则’
从《吃豆人》到开放世界:Unity Navigation中Agent Radius与Cost的隐藏逻辑1980年诞生的《吃豆人》用简单的迷宫路径定义了早期游戏AI的移动规则——幽灵们沿着固定路线巡逻,遇到转角时随机选择方向。这种设计在当时堪称革命性,但以今天的标准…...

三分钟快速上手:FanControl让你的电脑风扇从此安静又高效
三分钟快速上手:FanControl让你的电脑风扇从此安静又高效 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending…...

如何快速配置虚拟显示器:面向初学者的完整指南
如何快速配置虚拟显示器:面向初学者的完整指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd 你是否在为游戏串流画质不佳而烦恼?或者需要为无显示器主机…...