人工智能基础部分13-LSTM网络:预测上证指数走势
大家好,我是微学AI,今天给大家介绍一下LSTM网络,主要运用于解决序列问题。
一、LSTM网络简单介绍
LSTM又称为:长短期记忆网络,它是一种特殊的 RNN。LSTM网络主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。对于相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
引入LSTM网络的原因:由于 RNN 网络主要问题是长期依赖,即隐藏状态在时间上传递过程中可能会丢失之前的信息。为了解决这个问题,引入了长短时记忆网络 (LSTM) 和门控循环单元 (GRU)。这两种网络结构在隐藏层中增加了门控机制,能够更好地控制信息的传递。

其中符号及表示意思如下:
 LSTM中有三个门:
LSTM中有三个门:
(1)遗忘门f:决定上一个时刻的记忆单元状态需要遗忘多少信息,保留多少信息到当前记忆单元状态。
(2)输入门i:控制当前时刻输入信息候选状态有多少信息需要保存到当前记忆单元状态。
(3)输出门o:控制当前时刻的记忆单元状态有多少信息需要输出给外部状态。
形象的例子让我们更好的理解LSTM的原理:
假设你是一个梦想远大的学生,你想通过学习一门课程获得更多的知识。在学习过程中,LSTM模型帮助你,它就像是一个老师,它的遗忘门就像是老师的提醒,它让你挑出不用的知识,以保持你对重要知识的清晰记忆。它的输入门就像是老师的指导,它会重新审视你学习过的知识,按照自己的逻辑把知识结合起来,进化出更多有用的知识。最后,它的输出门就像老师的监督,它会确保你学习到了有用的知识,不要浪费时间去学习无用的知识。
二、LSTM网络运用-预测上证指数走势
# 使用LSTM预测沪市指数
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
from pandas import DataFrame
from pandas import concat
from itertools import chain
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']# 转化为可以用于监督学习的数据
def get_train_set(data_set, timesteps_in, timesteps_out=1):train_data_set = np.array(data_set)reframed_train_data_set = np.array(series_to_supervised(train_data_set, timesteps_in, timesteps_out).values)train_x, train_y = reframed_train_data_set[:, :-timesteps_out], reframed_train_data_set[:, -timesteps_out:]# 将数据集重构为符合LSTM要求的数据格式,即 [样本数,时间步,特征]train_x = train_x.reshape((train_x.shape[0], timesteps_in, 1))return train_x, train_y"""
将时间序列数据转换为适用于监督学习的数据
给定输入、输出序列的长度
data: 观察序列
n_in: 观测数据input(X)的步长,范围[1, len(data)], 默认为1
n_out: 观测数据output(y)的步长, 范围为[0, len(data)-1], 默认为1
dropnan: 是否删除NaN行
返回值:适用于监督学习的 DataFrame
"""
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):print(data.shape)n_vars = 1 if type(data) is list else data.shape[1]df = DataFrame(data)cols, names = list(), list()# input sequence (t-n, ... t-1)for i in range(n_in, 0, -1):cols.append(df.shift(i))names += [('var%d(t-%d)' % (j + 1, i)) for j in range(n_vars)]# 预测序列 (t, t+1, ... t+n)for i in range(0, n_out):cols.append(df.shift(-i))if i == 0:names += [('var%d(t)' % (j + 1)) for j in range(n_vars)]else:names += [('var%d(t+%d)' % (j + 1, i)) for j in range(n_vars)]# 拼接到一起agg = concat(cols, axis=1)agg.columns = names# 去掉NaN行if dropnan:agg.dropna(inplace=True)return agg# 使用LSTM进行预测
def lstm_model(source_data_set, train_x, label_y, input_epochs, input_batch_size, timesteps_out):model = Sequential()# 第一层, 隐藏层神经元节点个数为128, 返回整个序列model.add(LSTM(128, return_sequences=True, activation='tanh', input_shape=(train_x.shape[1], train_x.shape[2])))# 第二层,隐藏层神经元节点个数为128, 只返回序列最后一个输出model.add(LSTM(128, return_sequences=False))model.add(Dropout(0.5))# 第三层 因为是回归问题所以使用linearmodel.add(Dense(timesteps_out, activation='linear'))model.compile(loss='mean_squared_error', optimizer='adam')# LSTM训练 input_epochs次数res = model.fit(train_x, label_y, epochs=input_epochs, batch_size=input_batch_size, verbose=2, shuffle=False)# 模型预测train_predict = model.predict(train_x)#test_data_list = list(chain(*test_data))train_predict_list = list(chain(*train_predict))plt.plot(res.history['loss'], label='train')plt.show()#print(model.summary())plot_img(source_data_set, train_predict)# 呈现原始数据,训练结果,验证结果,预测结果
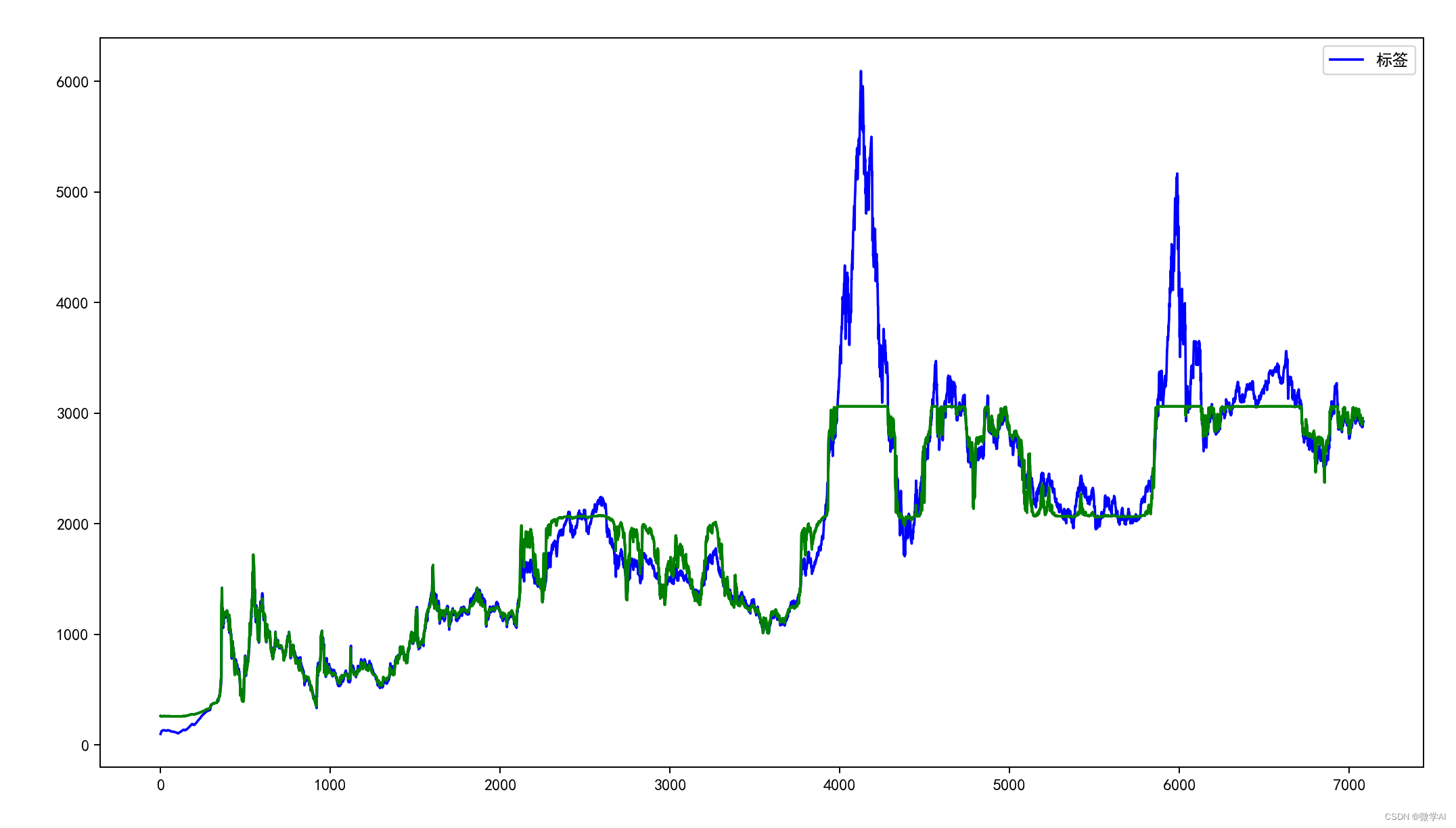
def plot_img(source_data_set, train_predict):plt.figure(figsize=(24, 8))# 原始数据蓝色plt.plot(source_data_set[:, -1], c='b',label = '标签')# 训练数据绿色plt.plot([x for x in train_predict], c='g')plt.legend()plt.show()# 设置观测数据input(X)的步长(时间步),epochs,batch_size
timesteps_in = 3
timesteps_out = 3
epochs = 1000
batch_size = 100
data = pd.read_csv('./shanghai_index_1990_12_19_to_2019_12_11.csv')
data_set = data[['Price']].values.astype('float64')
# 转化为可以用于监督学习的数据
train_x, label_y = get_train_set(data_set, timesteps_in=timesteps_in, timesteps_out=timesteps_out)print(train_x, label_y )
print(train_x.shape)
print(train_x.shape[1], train_x.shape[2])# 使用LSTM进行训练、预测
lstm_model(data_set, train_x, label_y, epochs, batch_size, timesteps_out=timesteps_out)运行结果:
相关文章:
人工智能基础部分13-LSTM网络:预测上证指数走势
大家好,我是微学AI,今天给大家介绍一下LSTM网络,主要运用于解决序列问题。 一、LSTM网络简单介绍 LSTM又称为:长短期记忆网络,它是一种特殊的 RNN。LSTM网络主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题…...

内网穿透/组网/设备上云平台EasyNTS上云网关的安装操作指南
EasyNTS上云网关的主要作用是解决异地视频共享/组网/上云的需求,网页对域名进行添加映射时,添加成功后会生成一个外网访问地址,在浏览器中输入外网访问地址,即可查看内网应用。无需开放端口,EasyNTS上云网关平台会向Ea…...
易点天下基于 StarRocks 全面构建实时离线一体的湖仓方案
作者:易点天下数据平台团队易点天下是一家技术驱动发展的企业国际化智能营销服务公司,致力于为客户提供全球营销推广服务,通过效果营销、品牌塑造、垂直行业解决方案等一体化服务,帮助企业在全球范围内高效地获取用户、提升品牌知…...
Tomcat的类加载机制
不遵循双亲委托 在JVM中并不是一次性地把所有的文件都加载到,而是按需加载,加载机制采用 双亲委托原则,如下图所示: BootStrapClassLoader 引导类加载器ExtClassLoader 扩展类加载器AppClassLoader 应用类加载器CustomClassLoad…...

【shell 编程大全】数组,逻辑判断以及循环
数组,逻辑判断以及循环1. 概述 大家好,我又来了。今天呢我们继续学习shell相关的知识。还是老样子我们先回顾下上一次【脚本交互 以及表达式】学习到的知识 登录shell 关联配置文件什么是子shellumask 修改默认权限read 基础表达式 简单计算表达式expr 计…...

Android13 Bluetooth更新
目录 Android 13 版本说明 LE Audio 代码更新 Android 12代码路径 Android 13代码路径 Android 13 版本说明 里面对蓝牙更新的描述较少,一出提到蓝牙的一...
手工测试混了5年,年底接到了被裁员的消息....
大家都比较看好软件测试行业,只是因为表面上看起来:钱多事少加班少。其实这个都是针对个人运气好的童人才会有此待遇。在不同的阶段做好不同阶段的事情,才有可能离这个目标更近,作为一枚软件测试人员,也许下面才是我们…...
Umi框架
什么是 umi umi 是由 dva 的开发者 云谦 编写的一个新的 React 开发框架。umi 既是一个框架也是一个工具,可以将它简单的理解为一个专注性能的类 next.js 前端框架,并通过约定、自动生成和解析代码等方式来辅助开发,减少开发者的代码量。 u…...
教你学git
前言 git是一种用于多人合作写项目。详细说明如下 文章目录前言什么是版本控制?什么是 Git?它就属于人工版本控制器版本控制工具常见版本控制工具怎么工作的?git 文件生命周期状态区域安装配置-- global检查配置创建仓库工作流与基本操作查看…...
【工作笔记】syslog,kern.log大量写入invalid cookie错误信息问题
任务描述 错误出现出现过四五次,应该是诊断单元tf卡读写出问题导致下面这条告警一直高频写入到/var/log/下的syslog、kern.log、messages中 Nov 23 06:25:12 embest kernel: omap_hsmmc 48060000.mmc: [omap_hsmmc_pre_dma_transfer] invalid cookie: data->hos…...

【C++】多线程
多任务处理有两种形式,即:多进程和多线程。 基于进程的多任务处理是程序的并发执行。基于线程的多任务处理是同一程序的片段的并发执行 文章目录1. 多线程介绍2. Windows多线程1. 多线程介绍 每一个进程(可执行程序)都有一个主线…...
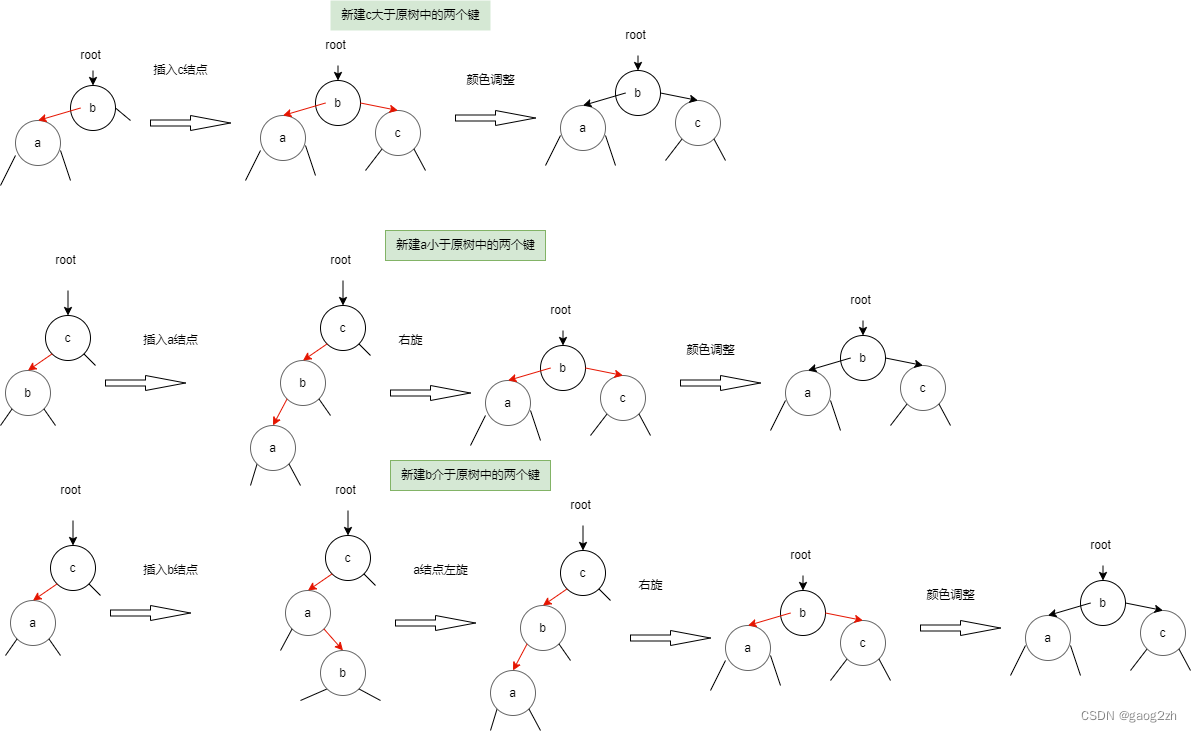
0202插入删除-算法第四版红黑树-红黑树-数据结构和算法(Java)
文章目录4 插入4.1 序4.2 向单个2-结点插入新键4.3 向树底部的2-结点插入新键4.4 向一棵双键树(3-结点)中插入新键4.5 颜色调整4.6 根结点总是黑色4.7 向树底部的3-结点插入新键4.8 将红链接在树中向上传递4.9 实现5 删除5.1 删除最小键5.2 删除6 有序性…...

vue 生成二维码插件 vue-qr使用方法
一、安装 npm install vue-qr --save二、引入 import VueQr from vue-qrcomponents:{VueQr,},三、使用 <vue-qr:text"dyQrcode":size"170":logoSrc"logo":margin"6":logoScale"0.2"></vue-qr>四、属性说明 …...
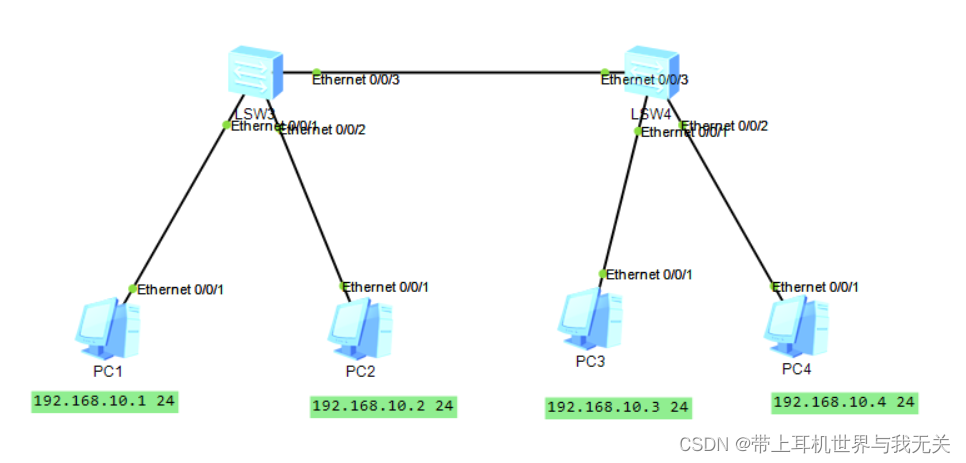
网络工程课(二)
ensp配置vlan 一、配置计算机ip地址和子网掩码 二、配置交换机LSW1 system-view [Huawei]sysname SW1 [SW1]vlan batch 10 20 [SW1]interface Ethernet0/0/1 [SW1-Ethernet0/0/1]port link-type access 将接口设为access接口 [SW1-Ethernet0/0/1]port default vlan 10 [SW1-E…...
: 梯度累加)
Pytorch并行计算(三): 梯度累加
梯度累加 梯度累加(Gradient Accmulation)是一种增大训练时batch size的技巧。当batch size在一张卡放不下时,可以将很大的batch size分解为一个个小的mini batch,分别计算每一个mini batch的梯度,然后将其累加起来优…...
最小覆盖子串(滑动窗口解法))
蓝桥杯入门即劝退(十八)最小覆盖子串(滑动窗口解法)
欢迎关注点赞评论,共同学习,共同进步! ------持续更新蓝桥杯入门系列算法实例-------- 如果你也喜欢Java和算法,欢迎订阅专栏共同学习交流! 你的点赞、关注、评论、是我创作的动力! -------希望我的文章…...

Android一~
进程和线程的区别https://zhuanlan.zhihu.com/p/60375108https://zhuanlan.zhihu.com/p/138689342线程池的用法和原理tcp三次握手和四次挥手、tcp基础http请求报文格式二叉树中序遍历(算法)activity启动模式OKhttp源码讲解Java修饰符Java线程同步的方法s…...

一月券商金工精选
✦研报目录✦ ✦简述✦ 按发布时间排序 国盛证券 “薪火”量化分析系列研究(二)-票据逾期数据中的选股信息 发布日期:2023-01-04 关键词:股票、票据、票据预期 主要内容:本文深入探讨了“票据持续逾期名单”这一…...
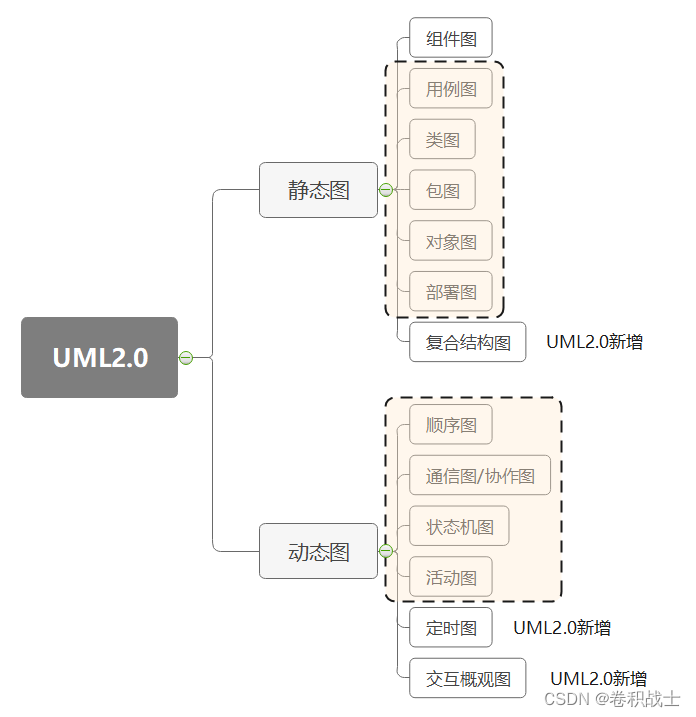
UML中常见的9种图
UML是Unified Model Language的缩写,中文是统一建模语言,是由一整套图表组成的标准化建模语言。UML用于帮助系统开发人员阐明,展示,构建和记录软件系统的产出。通过使用UML使得在软件开发之前, 对整个软件设计有更好的…...
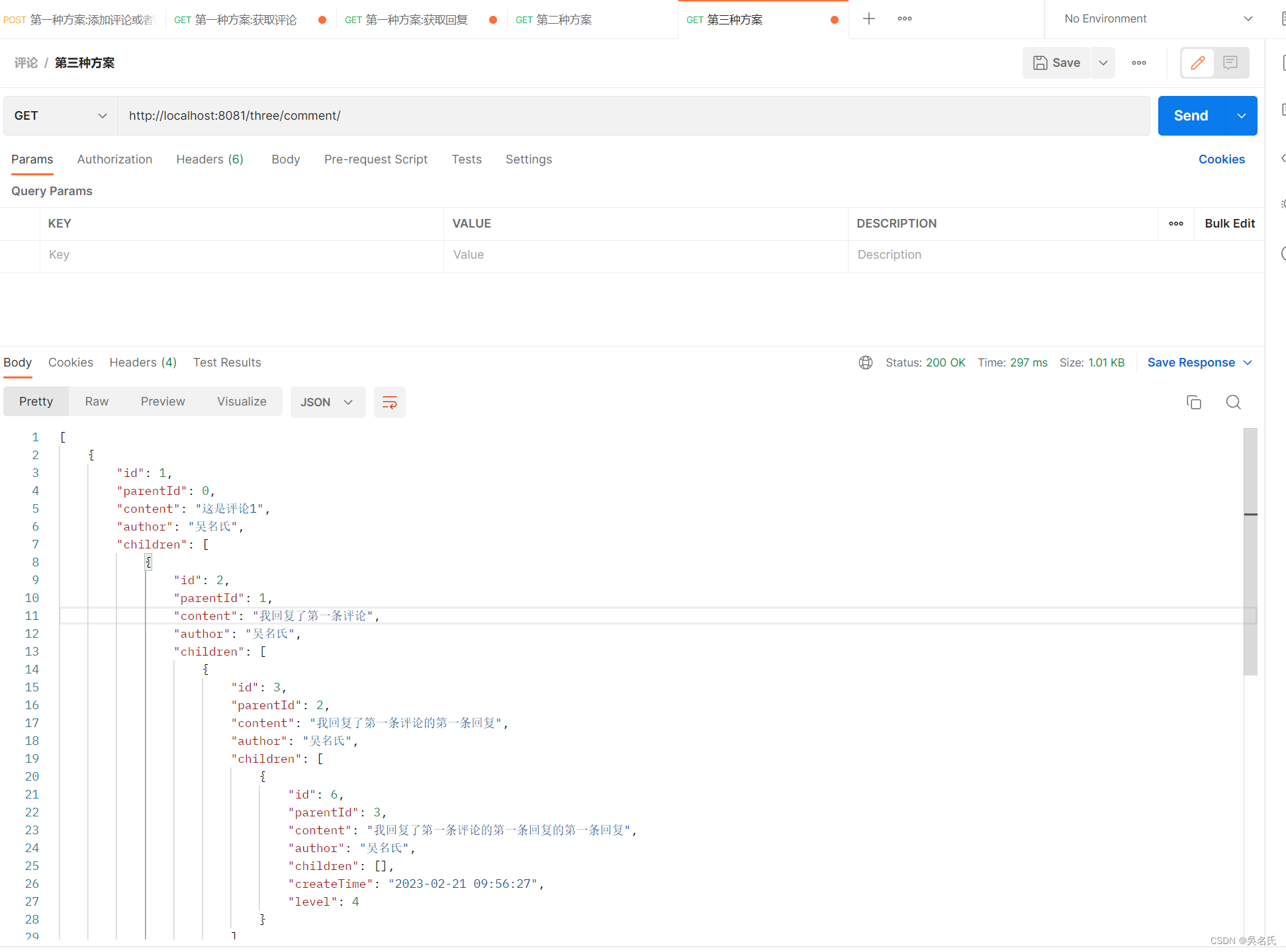
使用SpringBoot实现无限级评论回复功能
评论功能已经成为APP和网站开发中的必备功能。本文采用springbootmybatis-plus框架,通过代码主要介绍评论功能的数据库设计和接口数据返回。我们返回的格式可以分三种方案,第一种方案是先返回评论,再根据评论id返回回复信息,第二种方案是将评论回复直接封装成一个类似于树的数据…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略
告别C盘战士!ArcGIS 10.6安装路径选择与磁盘空间优化全攻略当GIS初学者第一次安装ArcGIS 10.6时,往往会被其庞大的安装体积所震惊。许多用户习惯性地点击"下一步",结果发现C盘空间被迅速吞噬,系统运行变得迟缓。本文将深…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

企业云盘签章技术方案:从数字签名原理到工程落地
背景 电子签章在企业云盘中的落地,不只是一个"上传盖章图片"的功能实现。本质上,它是一套涉及数字签名、PKI基础设施、文档完整性校验的综合性技术方案。本文从技术选型角度,说清楚企业云盘内置签章需要解决哪些问题、主流实现方案…...

通用物联网开发板设计:基于ESP8266的硬件集成与开发实践
1. 项目概述:为什么我们需要一块“通用”的物联网开发板?在捣鼓了几年物联网项目之后,我发现自己桌面上堆满了各种开发板:ESP8266、ESP32、Arduino Uno、STM32 Nucleo……每个项目都要重新连线、配置电源、焊接传感器接口…...

微信红包助手终极指南:无需ROOT的智能抢红包解决方案
微信红包助手终极指南:无需ROOT的智能抢红包解决方案 【免费下载链接】WeChatLuckyMoney :money_with_wings: WeChats lucky money helper (微信抢红包插件) by Zhongyi Tong. An Android app that helps you snatch red packets in WeChat groups. 项目地址: ht…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

怎么理解Filter不是在afterCompetition里面remove掉ThreadLocal里面的东西,而是说在finally块里面remove
文章目录1. 核心原因:Filter 的“套娃(洋葱圈)”执行模型2. 为什么不能(也无法)在这里用 afterCompletion?维度一:Filter 拿不到 afterCompletion维度二:生命周期顺序的致命冲突总结…...