Java学习之序列化
1、引言
《手册》第 9 页 “OOP 规约” 部分有一段关于序列化的约定 1:
【强制】当序列化类新增属性时,请不要修改 serialVersionUID 字段,以避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改 serialVersionUID 值。
说明:注意 serialVersionUID 值不一致会抛出序列化运行时异常。
我们应该思考下面几个问题:
序列化和反序列化到底是什么?
它的主要使用场景有哪些?
Java 序列化常见的方案有哪些?
各种常见序列化方案的区别有哪些?
实际的业务开发中有哪些坑点?
接下来将从这几个角度去研究这个问题。
2、序列化和反序列化是什么?为什么需要它?
序列化是将内存中的对象信息转化成可以存储或者传输的数据到临时或永久存储的过程。而反序列化正好相反,是从临时或永久存储中读取序列化的数据并转化成内存对象的过程。
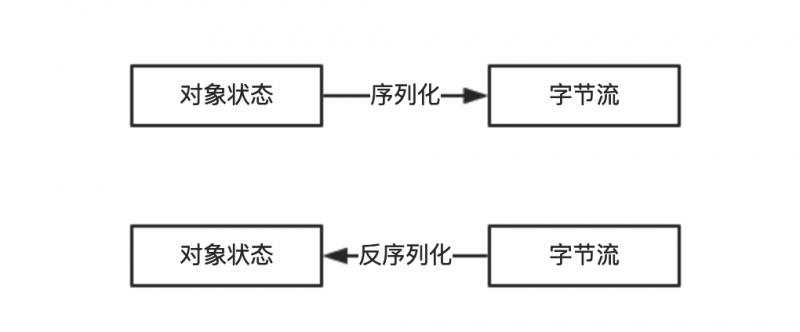
那么为什么需要序列化和反序列化呢?
我们都知道,文本文件,图片、视频和安装包等文件底层都被转化为二进制字节流来传输的,对方得文件就需要对文件进行解析,因此就需要有能够根据不同的文件类型来解码出文件的内容的程序。
如果要实现 Java 远程方法调用,就需要将调用结果通过网路传输给调用方,如果调用方和服务提供方不在一台机器上就很难共享内存,就需要将 Java 对象进行传输。而想要将 Java 中的对象进行网络传输或存储到文件中,就需要将对象转化为二进制字节流,这就是所谓的序列化。存储或传输之后必然就需要将二进制流读取并解析成 Java 对象,这就是所谓的反序列化。
序列化的主要目的是:方便存储到文件系统、数据库系统或网络传输等。
实际开发中常用到序列化和反序列化的场景有:
- 远程方法调用(RPC)的框架里会用到序列化。
- 将对象存储到文件中时,需要用到序列化。
- 将对象存储到缓存数据库(如 Redis)时需要用到序列化。
- 通过序列化和反序列化的方式实现对象的深拷贝。
3、常见的序列化方式
常见的序列化方式包括 Java 原生序列化、Hessian 序列化、Kryo 序列化、JSON 序列化等。
3.1 Java 原生序列化
正如前面章节讲到的,对于 JDK 中有的类,最好的学习方式之一就是直接看其源码。
Serializable 的源码非常简单,只有声明,没有属性和方法:
public interface Serializable {
}先思考一个问题:如果一个类序列化到文件之后,类的结构发生变化还能否保证正确地反序列化呢?
答案显然是不确定的。
所以每个序列化类都有一个叫 serialVersionUID 的版本号,反序列化时会校验待反射的类的序列化版本号和加载的序列化字节流中的版本号是否一致,如果序列化号不一致则会抛出 InvalidClassException 异常。
强烈推荐每个序列化类都手动指定其 serialVersionUID,如果不手动指定,那么编译器会动态生成默认的序列化号,因为这个默认的序列化号和类的特征以及编译器的实现都有关系,很容易在反序列化时抛出 InvalidClassException 异常。建议将这个序列化版本号声明为私有,以避免运行时被修改。
实现序列化接口的类可以提供自定义的函数修改默认的序列化和反序列化行为。
//自定义序列化方法:
private void writeObject(ObjectOutputStream out) throws IOException;//自定义反序列化方法
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException;通过自定义这两个函数,可以实现序列化和反序列化不可序列化的属性,也可以对序列化的数据进行数据的加密和解密处理。
3.2 Hessian 序列化
Hessian 是一个动态类型,二进制序列化,也是一个基于对象传输的网络协议。Hessian 是一种跨语言的序列化方案,序列化后的字节数更少,效率更高。Hessian 序列化会把复杂对象的属性映射到 Map 中再进行序列化。
3.3 Kryo 序列化
Kryo 是一个快速高效的 Java 序列化和克隆工具。Kryo 的目标是快速、字节少和易用。Kryo 还可以自动进行深拷贝或者浅拷贝。Kryo 的拷贝是对象到对象的拷贝而不是对象到字节,再从字节到对象的恢复。Kryo 为了保证序列化的高效率,会提前加载需要的类,这会带一些消耗,但是这是序列化后文件较小且反序列化非常快的重要原因。
3.4 JSON 序列化
JSON (JavaScript Object Notation) 是一种轻量级的数据交换方式。JSON 序列化是基于 JSON 这种结构来实现的。JSON 序列化将对象转化成 JSON 字符串,JSON 反序列化则是将 JSON 字符串转回对象的过程。常用的 JSON 序列化和反序列化的库有 Jackson、GSON、Fastjson 等。
4、Java 常见的序列化方案对比
我们想要对比各种序列化方案的优劣无外乎两点,一点是查资料,一点是自己写代码验证。
4.1 Java 原生序列化
Java 序列化的优点是:对对象的结构描述清晰,反序列化更安全。主要缺点是:效率低,序列化后的二进制流较大。
4.2 Hessian 序列化
Hession 序列化二进制流较 Java 序列化更小,且序列化和反序列化耗时更短。但是父类和子类有相同类型属性时,由于先序列化子类再序列化父类,因此反序列化时子类的同名属性会被父类的值覆盖掉,开发时要特别注意这种情况。
Hession2.0 序列化二进制流大小是 Java 序列化的 50%,序列化耗时是 Java 序列化的 30%,反序列化的耗时是 Java 序列化的 20%。
4.3 Kryo 序列化
Kryo 优点是:速度快、序列化后二进制流体积小、反序列化超快。但是缺点是:跨语言支持复杂。注册模式序列化更快,但是编程更加复杂。
4.4 JSON 序列化
JSON 序列化的优势在于可读性更强。主要缺点是:没有携带类型信息,只有提供了准确的类型信息才能准确地进行反序列化,这点也特别容易引发线上问题。
下面给出使用 Gson 框架模拟 JSON 序列化时遇到的反序列化问题的示例代码:
/*** 验证GSON序列化类型错误*/
@Test
public void testGSON() {Map<String, Object> map = new HashMap<>();final String name = "name";final String id = "id";map.put(name, "张三");map.put(id, 20L);String jsonString = GSONSerialUtil.getJsonString(map);Map<String, Object> mapGSON = GSONSerialUtil.parseJson(jsonString, Map.class);// 正确Assert.assertEquals(map.get(name), mapGSON.get(name));// 不等 map.get(id)为Long类型 mapGSON.get(id)为Double类型Assert.assertNotEquals(map.get(id).getClass(), mapGSON.get(id).getClass());Assert.assertNotEquals(map.get(id), mapGSON.get(id));
}下面给出使用 fastjson 模拟 JSON 反序列化问题的示例代码:
/*** 验证FatJson序列化类型错误*/
@Test
public void testFastJson() {Map<String, Object> map = new HashMap<>();final String name = "name";final String id = "id";map.put(name, "张三");map.put(id, 20L);String fastJsonString = FastJsonUtil.getJsonString(map);Map<String, Object> mapFastJson = FastJsonUtil.parseJson(fastJsonString, Map.class);// 正确Assert.assertEquals(map.get(name), mapFastJson.get(name));// 错误 map.get(id)为Long类型 mapFastJson.get(id)为Integer类型Assert.assertNotEquals(map.get(id).getClass(), mapFastJson.get(id).getClass());Assert.assertNotEquals(map.get(id), mapFastJson.get(id));
}大家还可以通过单元测试构造大量复杂对象对比各种序列化方式或框架的效率。
如定义下列测试类为 User,包括以下多种类型的属性:
@Data
public class User implements Serializable {private Long id;private String name;private Integer age;private Boolean sex;private String nickName;private Date birthDay;private Double salary;
}4.5 各种常见的序列化性能排序
实验的版本:kryo-shaded 使用 4.0.2 版本,gson 使用 2.8.5 版本,hessian 用 4.0.62 版本。
实验的数据:构造 50 万 User 对象运行多次。
大致得出一个结论:
从二进制流大小来讲:JSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化 > Kryo 序列化注册模式;
从序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Kryo 序列化 > Hessian2 序列化 > Kryo 序列化注册模式;
从反序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化注册模式 > Kryo 序列化;
从总耗时而言:Kryo 序列化注册模式耗时最短。
注:由于所用的序列化框架版本不同,对象的复杂程度不同,环境和计算机性能差异等原因结果可能会有出入。
5、 序列化引发的一个血案
接下来我们看下面的一个案例:
前端调用服务 A,服务 A 调用服务 B,服务 B 首次接到请求会查 DB,然后缓存到 Redis(缓存 1 个小时)。服务 A 根据服务 B 返回的数据后执行一些处理逻辑,处理后形成新的对象存到 Redis(缓存 2 个小时)。
服务 A 通过 Dubbo 来调用服务 B,A 和 B 之间数据通过 Map<String,Object> 类型传输,服务 B 使用 Fastjson 来实现 JSON 的序列化和反序列化。
服务 B 的接口返回的 Map 值中存在一个 Long 类型的 id 字段,服务 A 获取到 Map ,取出 id 字段并强转为 Long 类型使用。
执行的流程如下:
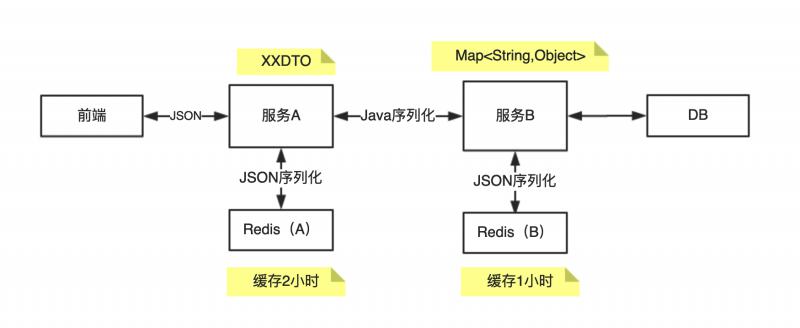
通过分析我们发现,服务 A 和服务 B 的 RPC 调用使用 Java 序列化,因此类型信息不会丢失。
但是由于服务 B 采用 JSON 序列化进行缓存,第一次访问没啥问题,其执行流程如下:
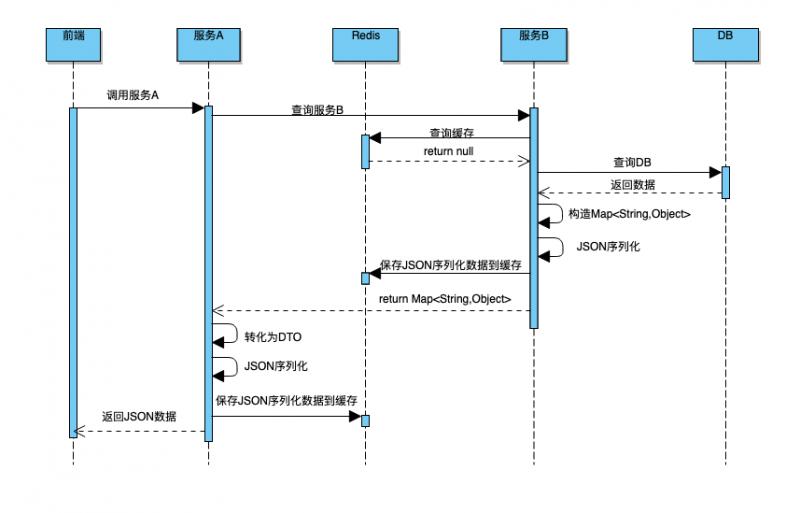
如果服务 A 开启了缓存,服务 A 在第一次请求服务 B 后,缓存了运算结果,且服务 A 缓存时间比服务 B 长,因此不会出现错误。
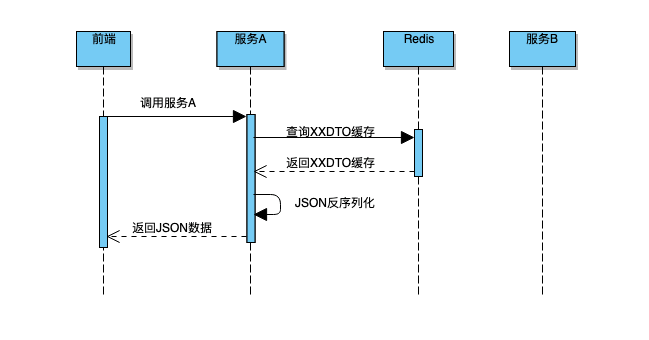
如果服务 A 不开启缓存,服务 A 会请求服务 B ,由于首次请求时,服务 B 已经缓存了数据,服务 B 从 Redis(B)中反序列化得到 Map。流程如下图所示:
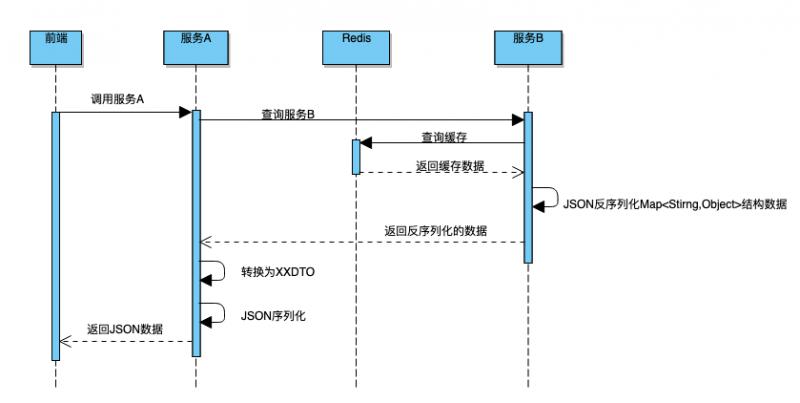
然而问题来了: 服务 A 从 Map 取出此 Id 字段,强转为 Long 时会出现类型转换异常。
最后定位到原因是 Json 反序列化 Map 时如果原始值小于 Int 最大值,反序列化后原本为 Long 类型的字段,变为了 Integer 类型,服务 B 的同学紧急修复。
服务 A 开启缓存时, 虽然采用了 JSON 序列化存入缓存,但是采用 DTO 对象而不是 Map 来存放属性,所以 JSON 反序列化没有问题。
因此大家使用二方或者三方服务时,当对方返回的是 Map<String,Object> 类型的数据时要特别注意这个问题。
作为服务提供方,可以采用 JDK 或者 Hessian 等序列化方式;
作为服务的使用方,我们不要从 Map 中一个字段一个字段获取和转换,可以使用 JSON 库直接将 Map 映射成所需的对象,这样做不仅代码更简洁还可以避免强转失败。
代码示例:
@Test
public void testFastJsonObject() {Map<String, Object> map = new HashMap<>();final String name = "name";final String id = "id";map.put(name, "张三");map.put(id, 20L);String fastJsonString = FastJsonUtil.getJsonString(map);// 模拟拿到服务B的数据Map<String, Object> mapFastJson = FastJsonUtil.parseJson(fastJsonString,map.getClass());// 转成强类型属性的对象而不是使用map 单个取值User user = new JSONObject(mapFastJson).toJavaObject(User.class);// 正确Assert.assertEquals(map.get(name), user.getName());// 正确Assert.assertEquals(map.get(id), user.getId());
}6、课后题
给出一个 PersonTransit 类,一个 Address 类,假设 Address 是其它 jar 包中的类,没实现序列化接口。请使用今天讲述的自定义的函数 writeObject 和 readObject 函数实现 PersonTransit 对象的序列化,要求反序列化后 address 的值正常。
@Data
public class PersonTransit implements Serializable {private Long id;private String name;private Boolean male;private List<PersonTransit> friends;private Address address;
}@Data
@AllArgsConstructor
public class Address {private String detail;}一、序列化主要有两个困难:
1 transient 关键字,序列化时默认不序列化该字段。(新加的,增加难度)
2 假设 Address 是第三方 jar 包中的类,不允许修改实现序列化接口。
二、分析
我们通过专栏的介绍还有序列化接口java.io.Serializable的注释可知,可以自定义序列化方法和反序列化方法:
private void writeObject(java.io.ObjectOutputStream out)throws IOExceptionprivate void readObject(java.io.ObjectInputStream in)throws IOException, ClassNotFoundException;实现序列化和反序列化不可序列化的属性,也可以对序列化的数据进行数据的加密和解密处理。
三、参考代码
@Data
public class PersonTransit implements Serializable {private Long id;private String name;private Boolean male;private List<PersonTransit> friends;private transient Address address;/*** 自定义序列化写方法*/private void writeObject(ObjectOutputStream oos) throws IOException {oos.defaultWriteObject();oos.writeObject(address.getDetail());}/*** 自定义反序列化读方法*/private void readObject(ObjectInputStream ois) throws ClassNotFoundException, IOException {ois.defaultReadObject();this.setAddress(new Address( (String) ois.readObject()));}
}单元测试
@Test
public void testJDKSerialOverwrite() throws IOException, ClassNotFoundException {PersonTransit person = new PersonTransit();person.setId(1L);person.setName("张三");person.setMale(true);person.setFriends(new ArrayList<>());Address address = new Address();address.setDetail("某某小区xxx栋yy号");person.setAddress(address);// 序列化JdkSerialUtil.writeObject(file, person);// 反序列化PersonTransit personTransit = JdkSerialUtil.readObject(file);// 判断是否相等Assert.assertEquals(personTransit.getName(), person.getName());Assert.assertEquals(personTransit.getAddress().getDetail(), person.getAddress().getDetail());
}用到的工具类:
public class JdkSerialUtil {public static <T> void writeObject(File file, T data) throws IOException {try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(file));) {objectOutputStream.writeObject(data);objectOutputStream.flush();}}public static <T> void writeObject(ByteArrayOutputStream outputStream, T data) throws IOException {try (ObjectOutputStream objectOutputStream = new ObjectOutputStream(outputStream);) {objectOutputStream.writeObject(data);objectOutputStream.flush();}}public static <T> T readObject(File file) throws IOException, ClassNotFoundException {FileInputStream fin = new FileInputStream(file);ObjectInputStream objectInputStream = new ObjectInputStream(fin);return (T) objectInputStream.readObject();}public static <T> T readObject(ByteArrayInputStream inputStream) throws IOException, ClassNotFoundException {ObjectInputStream objectInputStream = new ObjectInputStream(inputStream);return (T) objectInputStream.readObject();}
}通过单元测试验证了我们编写代码的正确性。
7、思考题
1.为什么我们在前端向后端发送请求时,请求对象没有序列化id也可以正常使用。
因为前端向后端发送请求,实际上是一个反序列化的过程,反序列化不需要序列化id,是json格式转换为对象。如果一个对象在同一台服务器上,那么他们可以共享内存,并不需要序列化。序列一般存在网络传输和io传输的情况下
2.为什么我们在使用fegin调用接口时,为什么请求对象不需要实现序列化接口也能请求成功?
因为使用fegin调用接口时,实际上是将java对象序列化json对象,序列成java对象不需要实现序列化接口。JSON序列化是基于对象的字段和属性的反射,因此只要对象的字段可以被访问并且符合JSON的数据类型要求(例如,字符串、数字、布尔等),通常就可以成功地将对象序列化为JSON,而不需要额外的接口。
相关文章:
Java学习之序列化
1、引言 《手册》第 9 页 “OOP 规约” 部分有一段关于序列化的约定 1: 【强制】当序列化类新增属性时,请不要修改 serialVersionUID 字段,以避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请…...
C++实现蜂群涌现效果(flocking)
Flocking算法0704_元宇宙中的程序员的博客-CSDN博客 每个个体的位置,通过计算与周围个体的速度、角度、位置,去更新位置。...
IDEA复制一个工程为多个并启动,测试负载均衡
1 找到服务按钮 2 选择复制配置 3 更改新的名称与虚拟机参数 复制下面的代码在VM参数中 -Dserver.port8082 4 最后启动即可...

001_C++语法基础
C语法基础 所有C语法要用英文区分大小写每个语句写完以分号结束 C标准输入输出头文件iostream 若想通过C实现数据的输入和输出,需要导入标准输入输出头文件 #include <iostream>标准输入输出头文件<iostream>中包含了cin输入语句和cout输出语句 标…...
对Excel表中归类的文件夹进行自动分类
首先把excel表另存为.txt文件(注意:刚开始可能是ANSI格式,需要转成UTF-8格式);再新建一个.txt文件,重命名成.bat文件(注意:直接创建的如果是是UTF-8格式,最好转成ANSI格式࿰…...
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析 模型预测控制在工业中应用广泛。这种方法的优点之一是在求解最优控制问题时能够明确考虑对输入和输出状态施加的约束。控制对象模型用于有限时间范围内最优控制的实时计算。所使用的数学设备允许从具有单输入和单…...

C++中位运算符使用
& 与 只有都为1结果为1 0 & 0 00 & 1 01 & 0 01 & 1 1 | 或 只要一个为1结果为1 0|00 0|11 1|01 1|11 ^ 异或 两个相同的数字为0,其余为1 0^00 1^01 0^11 1^10 ~ 取反 将进制位数进行取反 ~1-2 //0000 0001-->代…...

微机原理 || 第2次测试:汇编指令(加减乘除运算,XOR,PUSH,POP,寻址方式,物理地址公式,状态标志位)(测试题+手写解析)
(一)测试题目: 1.数[X]补1111,1110B,则其真值为 2.在I/O指令中,可用于表示端口地址的寄存器 3. MOV AX,[BXSl]的指令中,源操作数的物理地址应该如何计算 4.执行以下两条指令后,标志寄存器FLAGS的六个状态…...

人员闯入检测告警算法
人员闯入检测告警算法通过yolov5网络模型识别检测算法,人员闯入检测告警算法对未经许可或非法进入的人员进行及时识别告警,确保对危险区域的安全管理和保护。YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位…...
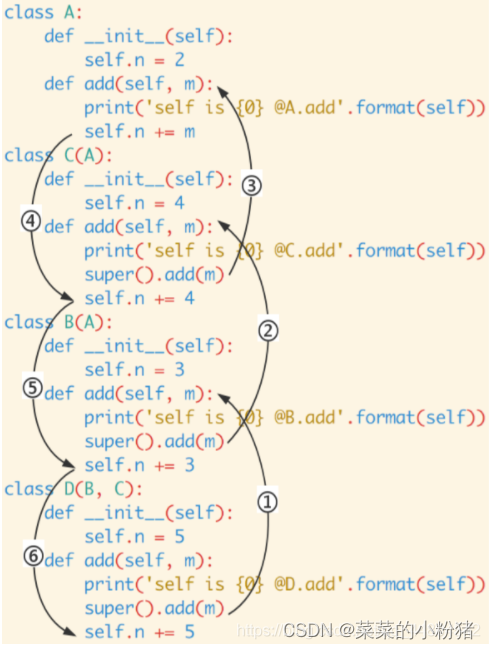
python中super()用法
super关键字的用法 一、概述二、作用三、语法四、使用示例1.通过super() 来调用父类的__init__ 构造方法:2.通过supper() 来调用与子类同名的父类方法2.1 单继承2.2 多继承 一、概述 super() 是python 中调用父类(超类)的一种方法࿰…...
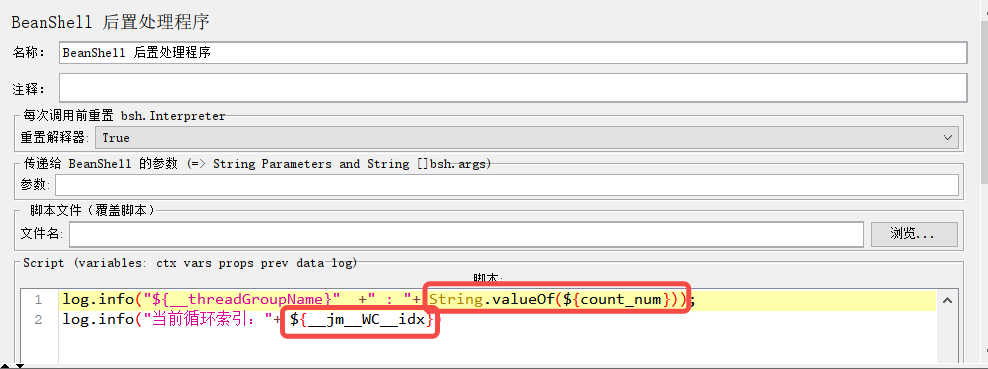
jmeter While控制器
一种常见的循环控制语句,用于重复执行一段代码块,直到指定的条件不再满足。 参数: 空LASTJMeter变量、函数、属性或任意其他可用表达式 (jmeter提供的方法)。判断变量值count_num小于等于20,推荐简单的几…...

3D数字孪生技术助力港口全新升级,提供实时数据进行智能调度
港口3D数字孪生平台是一种基于数字技术的虚拟模型,它可以模拟真实的港口环境,并对港口的运营、管理、安全等方面进行实时监控和优化。该平台带来了许多智能化提升,包括以下几个方面: 一、自动化操作和智能调度 数字孪生平台可以通…...
Qt日历控件示例-QCalendarWidget
基本说明 QCalendarWidget介绍: QCalendarWidget 是 Qt 框架中提供的一个日期选择控件,用户可以通过该控件快速选择需要的日期,并且支持显示当前月份的日历。 这里,我们继承了QCalendarWidget,做了一些简单封装和样式调整 1.使用的IDE&…...
Stream流使用)
函数式编程(四)Stream流使用
一、概述 在使用stream之前,先理解Optional 。 Optional是Java 8引入的一个容器类,用于处理可能为空的值。它提供了一种优雅的方式来处理可能存在或不存在的值,避免了空指针异常。 Optional的主要特点如下: 可能为空ÿ…...

区块链面临六大安全问题 安全测试方案研究迫在眉睫
区块链面临六大安全问题 安全测试方案研究迫在眉睫 近年来,区块链技术逐渐成为热门话题,其应用前景受到各国政府、科研机构和企业公司的高度重视与广泛关注。随着技术的发展,区块链应用与项目层出不穷,但其安全问题不容忽视。近年…...

K8S---kubelet TLS 启动引导
一、引导启动初始化过程(Bootstrap Initialization ) 1、kubeadm 生成一个Token,类似07401b.f395accd246ae52d这种格式,或者自己手动生成2、使用kubectl命令行,生成一个Secret,具体详见认证、授权3、kubelet 进程启动 (begin)4、kubelet 看到自己没有对应的 kubeconfig…...

Android系统修改驱动固定USB摄像头节点绑定前后置摄像头
前言 Android系统中usb摄像头节点会因为摄像头所接的usb口不同或者usb设备识别顺序不一样而出现每次开机生成的video节点不一样的问题。由于客户app调用摄像头时,需要固定摄像头的节点。因此需要针对前面的情况做处理。 方式1:通过摄像头名称固定摄像头节点 --- a/kernel…...
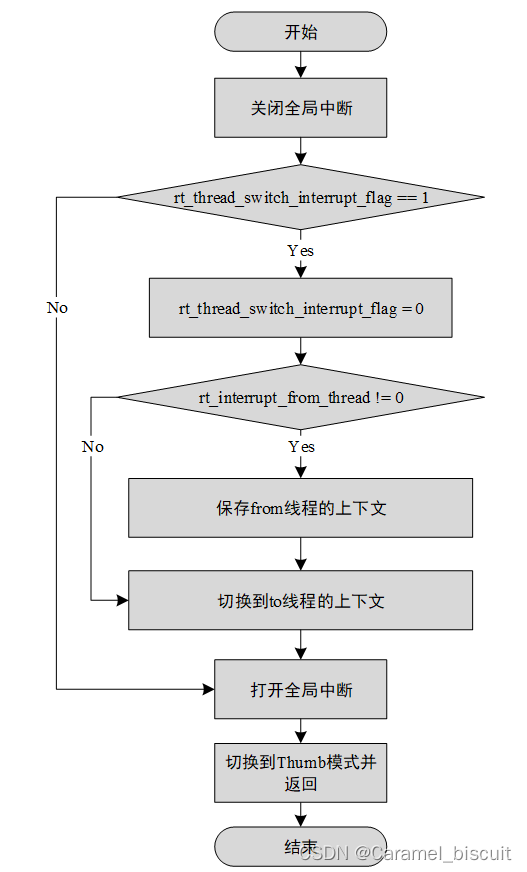
RT-Thread 内核移植
内核移植 内核移植就是将RTT内核在不同的芯片架构、不同的板卡上运行起来,能够具备线程管理和调度,内存管理,线程间同步等功能。 移植可分为CPU架构移植和BSP(Board support package,板级支持包)移植两部…...

springboot中entity层、dto层、vo层通俗理解三者的区别
entity:这个类的属性是跟数据库字段一模一样的(驼峰命名),当我们使用MyBatis-Plus的时候经常用得到。 dto:用于后端接收前端返回的数据,一般是post请求,前端会给我们返回一个json对象ÿ…...
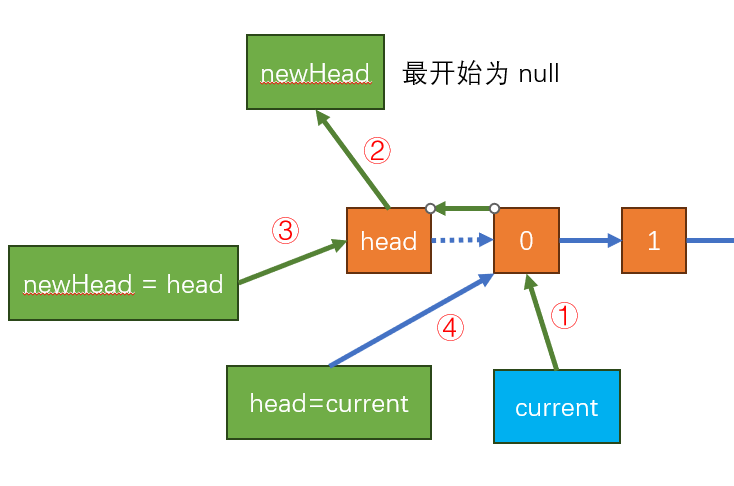
TypeScript_队列结构-链表
队列 队列(Queue),它是一种受限的线性表,先进先出(FIFO First In First Out) 受限之处在于它只允许在队列的前端(front)进行删除操作而在队列的后端(rear)进…...

中国DevOps市场格局重塑:本土合规与全球协作的平衡艺术
中国DevOps市场格局重塑:本土合规与全球协作的平衡艺术 中国企业的DevOps工具链选择正面临前所未有的复杂局面 随着数字经济的深入发展,DevOps工具链已经从单纯的技术选型问题演变为关乎企业数字化转型成败的战略决策。在当前的宏观环境下,…...
CVC/WVC方程揭示可持续性密码)
量化文明:贾子理论(Kucius Theory)CVC/WVC方程揭示可持续性密码
量化文明:贾子理论(Kucius Theory)CVC/WVC方程揭示可持续性密码摘要:贾子理论通过文明方程(CVC/WVC)构建数理模型,量化文明价值与智慧资本。核心公式以意义、能量、时间积分定义CVC,…...

白春礼院士:科研活动的基本单元正从人向人机系统转变
“AIfor Science(简称为AI4S)的竞争本质上是认知体系的竞争”,3月29日,中国科学院院士白春礼在第二届浦江AI学术年会开幕式上表示,不同科研体系如何理解科学,是以模型为核心,通过高维空间中的模…...

保姆级教程:手把手教你用Python+Control库仿真PLL噪声传递函数
保姆级教程:手把手教你用PythonControl库仿真PLL噪声传递函数 锁相环(PLL)作为现代电子系统中的核心组件,其噪声特性直接影响通信质量、时钟精度等关键指标。但教科书上复杂的传递函数公式总让人望而生畏——直到你发现用几行Pyth…...

Maestro Studio终极指南:零代码可视化移动应用测试,5分钟上手自动化
Maestro Studio终极指南:零代码可视化移动应用测试,5分钟上手自动化 【免费下载链接】maestro Painless E2E Automation for Mobile and Web 项目地址: https://gitcode.com/GitHub_Trending/ma/maestro 还在为复杂的移动应用测试流程而烦恼吗&am…...

资源获取的技术突围:res-downloader的跨平台解决方案
资源获取的技术突围:res-downloader的跨平台解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在数字内容爆…...

GyroFlow:用陀螺仪数据重塑视频稳定技术
GyroFlow:用陀螺仪数据重塑视频稳定技术 【免费下载链接】gyroflow Video stabilization using gyroscope data 项目地址: https://gitcode.com/GitHub_Trending/gy/gyroflow 在数字影像创作领域,画面稳定性直接决定作品专业度。无论是运动相机拍…...

资源处理效率工具RePKG:从问题解决到场景创新的实战指南
资源处理效率工具RePKG:从问题解决到场景创新的实战指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 在数字创意和开发工作中,我们经常遇到各种专用格式的…...

终极B站界面美化指南:如何用BewlyBewly插件快速打造个性化体验
终极B站界面美化指南:如何用BewlyBewly插件快速打造个性化体验 【免费下载链接】BewlyBewly Just make a few small changes to your Bilibili homepage. (English | 简体中文 | 正體中文 | 廣東話) 项目地址: https://gitcode.com/gh_mirrors/be/BewlyBewly …...

从拒稿到录用:我的TOMM投稿实战复盘与经验分享
1. 从TMM拒稿到TOMM录用的心路历程 第一次收到TMM的拒稿邮件时,我正在实验室熬夜改代码。邮件弹出来的那一刻,整个人就像被泼了一盆冷水。那篇论文已经经历了三轮大修,每次都是几十条审稿意见,我们团队前前后后修改了上百个细节。…...