OpenShift 4 - 用 Prometheus 和 Grafana 监视用户应用定制的观测指标(视频)
《OpenShift / RHEL / DevSecOps 汇总目录》
说明:本文已经在 OpenShift 4.13 的环境中验证
文章目录
- OpenShift 的监控功能构成
- 部署被监控应用
- 用 OpenShift 内置功能监控应用
- 用 Grafana 监控应用
- 安装 Grafana 运行环境
- 配置 Grafana 数据源
- 定制监控 Dashboard
- 演示视频
- 参考
OpenShift 的监控功能构成
构成 OpenShift 监控功能的附件分为两部分:“平台监控组件” 和 “用户项目监控组件”。
- 在平台监控组件中包括:Prometheus、Thanos Querier 和 Alertmanager 三部分重要组成,这些组件是由 Cluster Monitoring Operator 总体部署和管理生命周期的。通过平台监控组件可以对 OpenShift 集群的 DNS、日志系统、etcd、Kubelet、API Server、Scheduler 等重要环境进行监控。
- 用户项目监控组件是对用户自有项目中应用资源进行监控。它由单独的 Prometheus、Thanos Ruler 构成,并共用平台的 Alertmanager 和 Thanos Querier 组件。
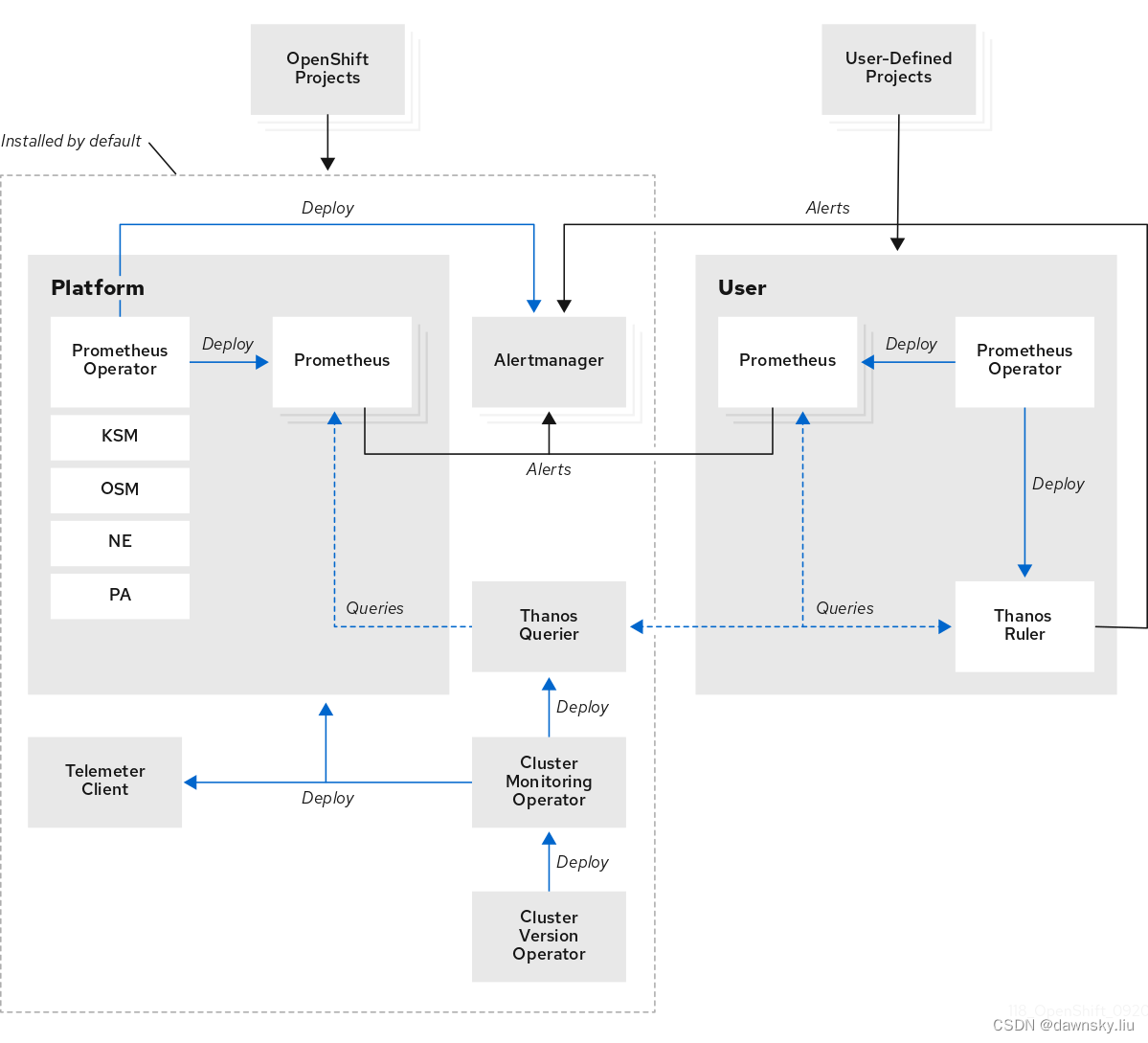
除了可以使用 OpenShift 控制台内置的监控功能和界面外,还可通过 Thanos Querier 的访问地址外接其他监控软件,例如使用 Grafana 定制的仪表盘显示 OpenShift 或用户应用的运行情况。
部署被监控应用
- 创建项目
$ oc new-project app-monitoring
- 部署测试应用
$ oc new-app quay.io/brancz/prometheus-example-app:v0.2.0 -l app=prometheus-example-app
- 创建 Service 和 Route。
$ cat << EOF | oc apply -f -
apiVersion: v1
kind: Service
metadata:labels:app: prometheus-example-appname: prometheus-example-app
spec:ports:- port: 8080protocol: TCPname: 8080-tcpselector:app: prometheus-example-apptype: ClusterIP
EOF$ oc expose svc prometheus-example-app
- 分别访问应用缺省地址和 /err 地址,返回的 HTTP 代码分别为 200 和 404。
$ curl -sw "%{http_code}\n" -o /dev/null $(oc get route prometheus-example-app -ojsonpath={.spec.host})
200
$ curl -sw "%{http_code}\n" -o /dev/null $(oc get route prometheus-example-app -ojsonpath={.spec.host})/err
404
- 访问应用的 /metrics 地址,查看应用返回的 HTTP 代码为 200 和 404 请求数量统计。
$ curl $(oc get route prometheus-example-app -ojsonpath={.spec.host})/metrics
# HELP http_requests_total Count of all HTTP requests
# TYPE http_requests_total counter
http_requests_total{code="200",method="get"} 1
http_requests_total{code="404",method="get"} 1
# HELP version Version information about this binary
# TYPE version gauge
version{version="v0.2.0"} 1
说明:
也可在控制台上部署 quay.io/brancz/prometheus-example-app:v0.2.0 容器镜像,但需要增加 app=prometheus-example-app 标签,并且去掉 “安全路由” 选项。
用 OpenShift 内置功能监控应用
- 启用 OpenShift 对用户应用监控功能。
$ cat << EOF | oc apply -f -
apiVersion: v1
kind: ConfigMap
metadata:name: cluster-monitoring-confignamespace: openshift-monitoring
data:config.yaml: |enableUserWorkload: true
EOF
- 确认主要监控服务云子运行正常。
$ oc get pod -n openshift-user-workload-monitoring
NAME READY STATUS RESTARTS AGE
prometheus-operator-77d547b4dc-fcflk 2/2 Running 0 34h
prometheus-user-workload-0 6/6 Running 0 34h
thanos-ruler-user-workload-0 4/4 Running 0 34h
- 创建对 prometheus-example-app 应用监控的 ServiceMonitor 对象。
$ cat << EOF | oc apply -f -
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:name: prometheus-example-monitornamespace: app-monitoring
spec:endpoints:- interval: 30sport: 8080-tcppath: /metricsselector:matchLabels:app: prometheus-example-app
EOF
- 创建完后在 OpenShift 的 “目标” 菜单中在 “过滤器” 中选择 “用户”,稍等后可以看到目标的监视端点。
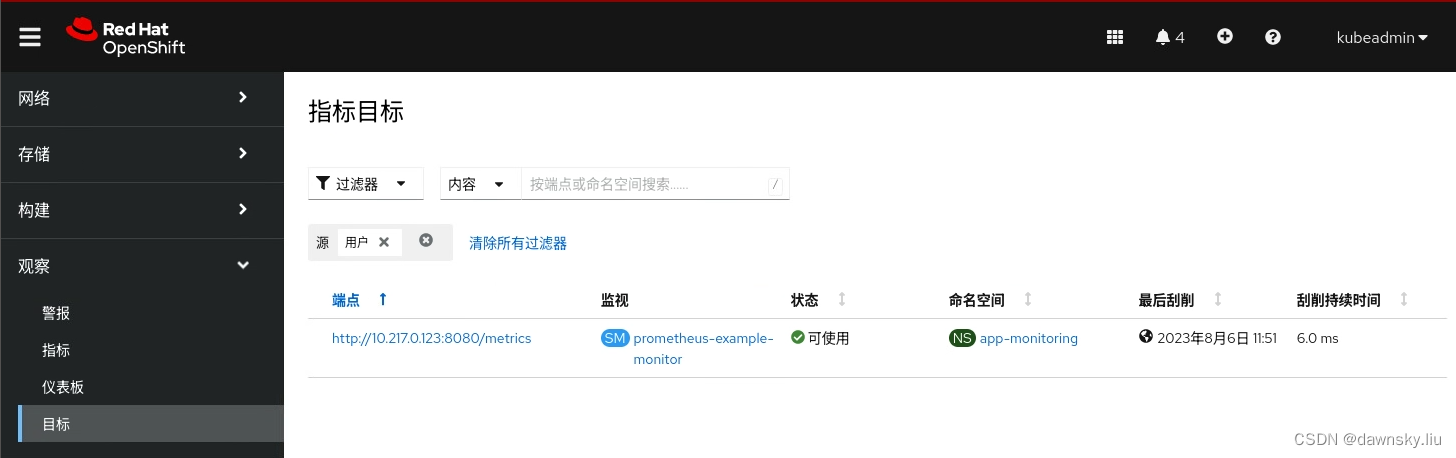
该端点地址是运行应用的 Pod 使用的 IP 地址。
$ oc get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-example-app-b744f9c85-bmk7p 1/1 Running 0 6m15s 10.217.0.123 crc-2zx29-master-0 <none> <none>
- 创建 PrometheusRule。下面的 expr 表达式会统计过去 5 分钟 HTTP 请求返回结果是 404 的每秒速率,如果 > 0.3 则报警。
$ cat << EOF | oc apply -f -
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:name: app-alertnamespace: app-monitoring
spec:groups:- name: app-alertrules:- alert: HttpRequestErrorRateIncreaseexpr: rate(http_requests_total{code="404",job="prometheus-example-app"}[5m]) > 0.3labels:severity: warningannotations:summary: Prometheus example app's error rate increase.message: Prometheus example app's error rate increase.
EOF
创建完后可以在“报警” 菜单中的 “报警规则” 页面中通过将 “过滤器” 中选择 “用户”,可以看到该报警规则。
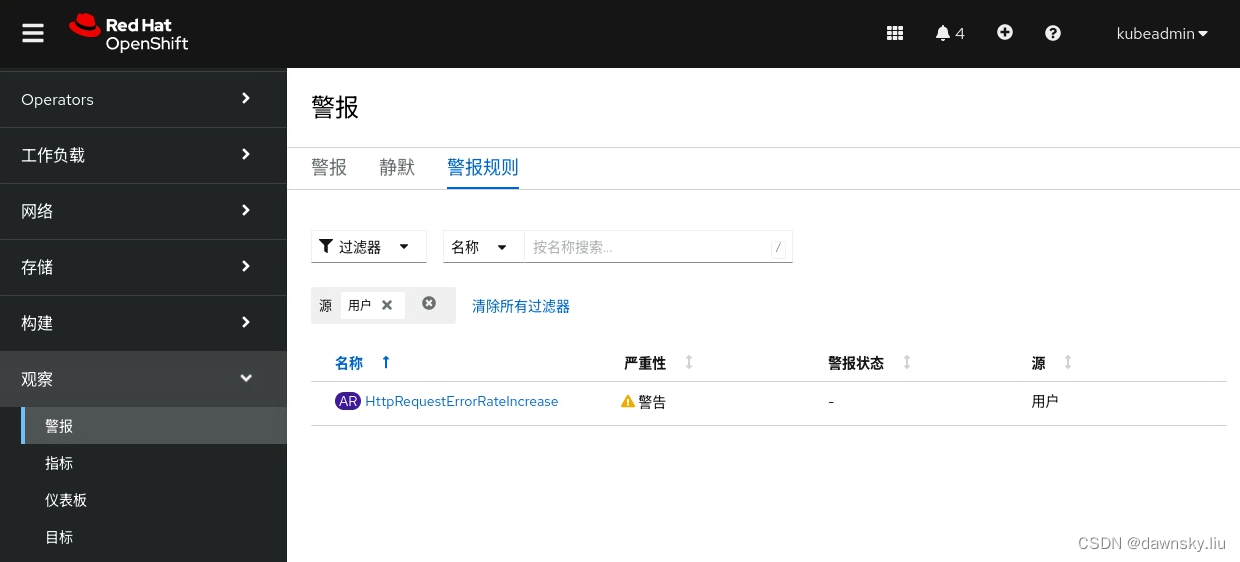
- 执行以下命令,持续访问应用的 /err 地址。
$ for i in `seq 1 10000`
docurl -sw "%{http_code}\n" -o /dev/null $(oc get route prometheus-example-app -ojsonpath={.spec.host})/errsleep 1
done
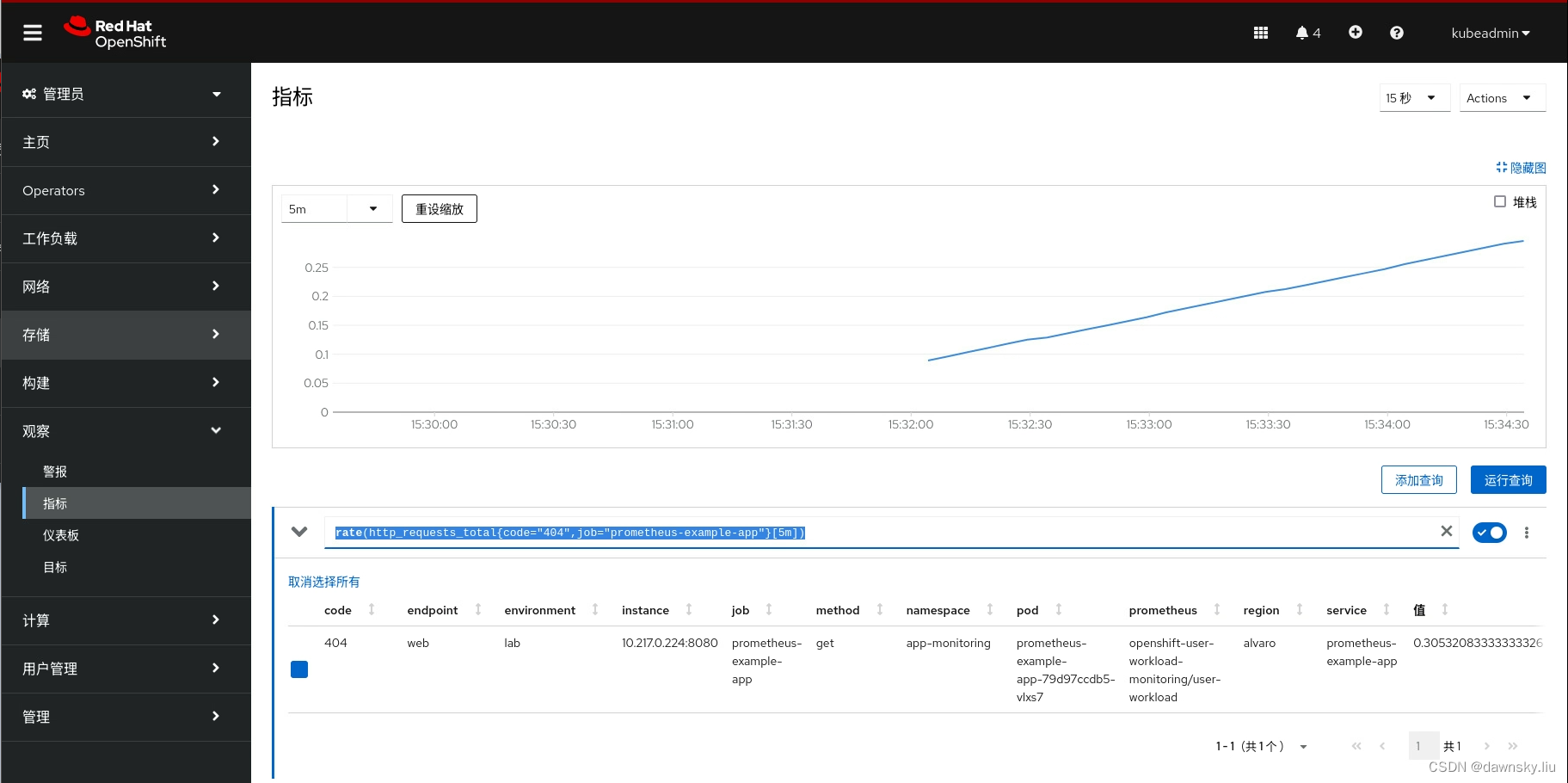
- 在 OpenShift 的 “指标” 页面中先将输入查询条件设为 “rate(http_requests_total{code=“404”,job=“prometheus-example-app”}[5m])”,然后点击 “运行查询”。再将时间设为 5m,并将页面刷新时间设置为 15秒。在等待一会儿后可以看到值已经超过 0.3。
- 在 OpenShift 的 “报警” 页面中的 “过滤器” 中选中 “用户” ,确认已经被触发。
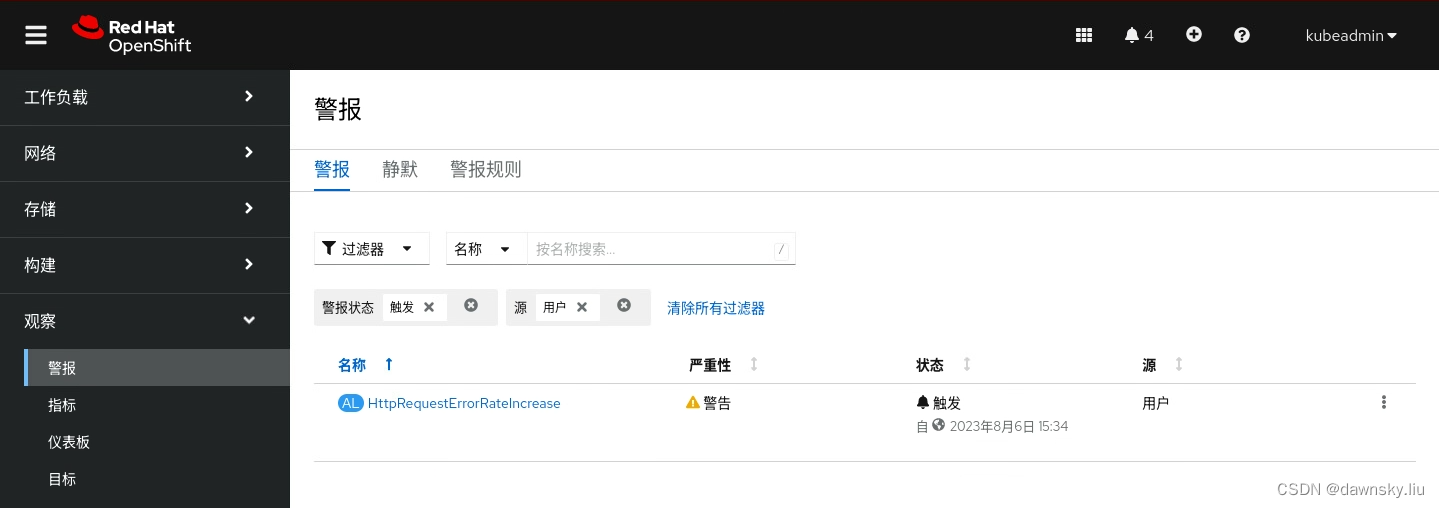
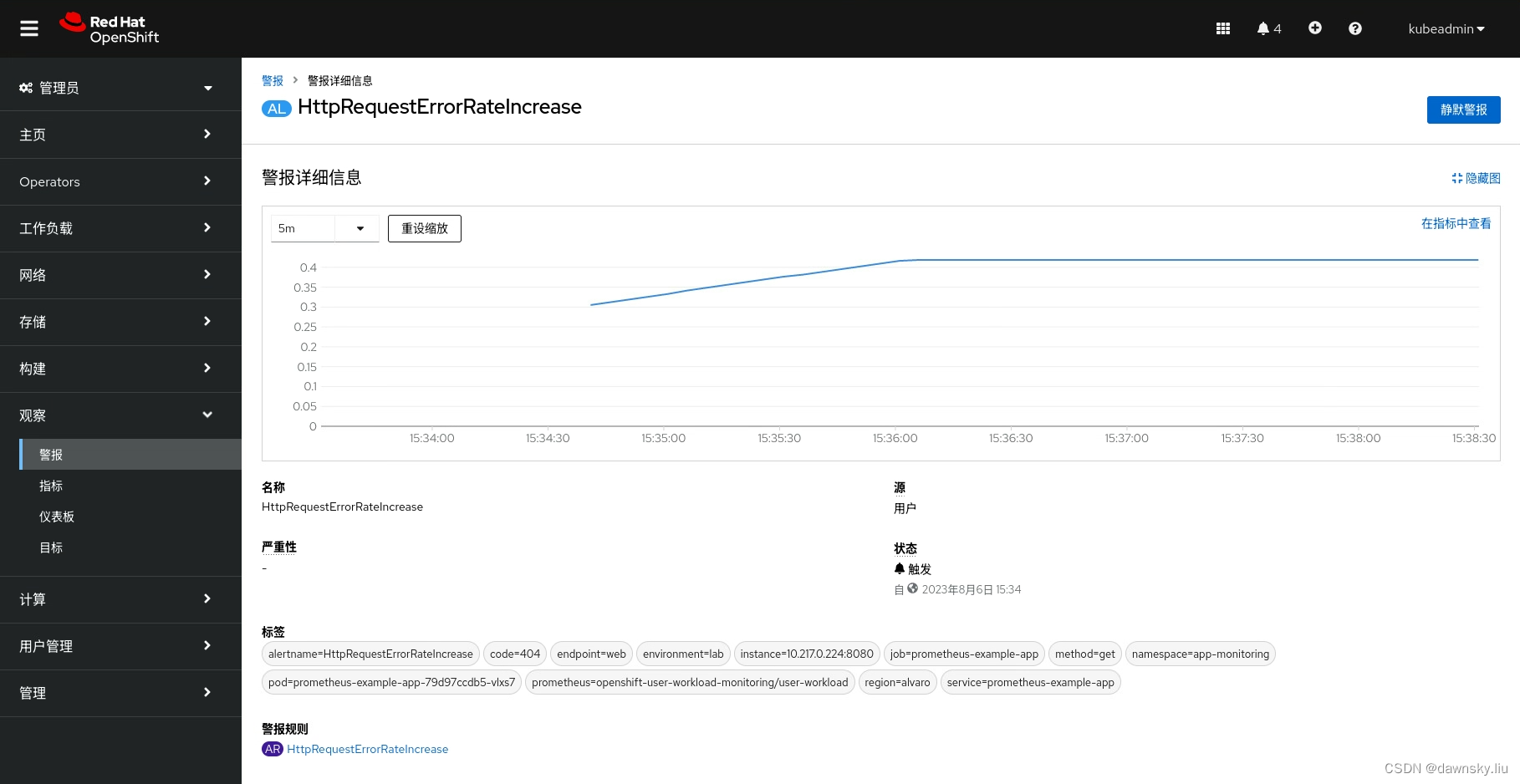
- 点击上图的 HttpRequestErrorRateIncrease,然后可以看到和步骤 7 类似的指标监控图。
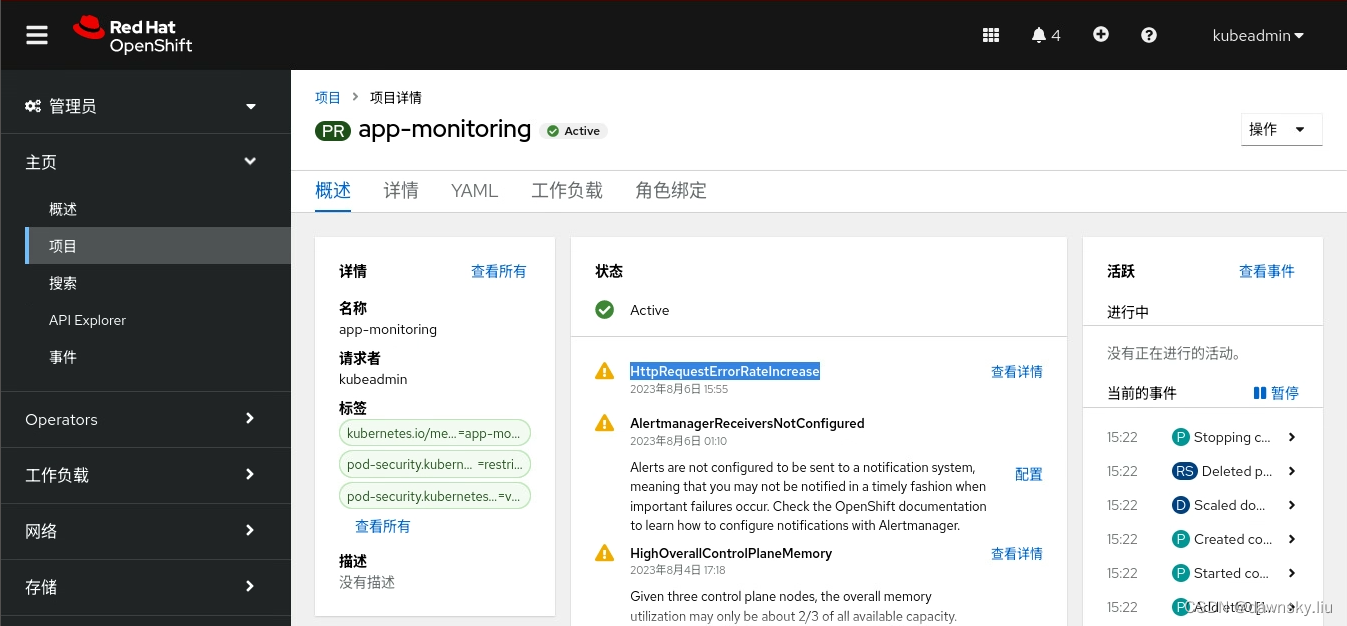
- 另外,在 app-monitoring 项目中也可以看到 HttpRequestErrorRateIncrease 报警。
用 Grafana 监控应用
安装 Grafana 运行环境
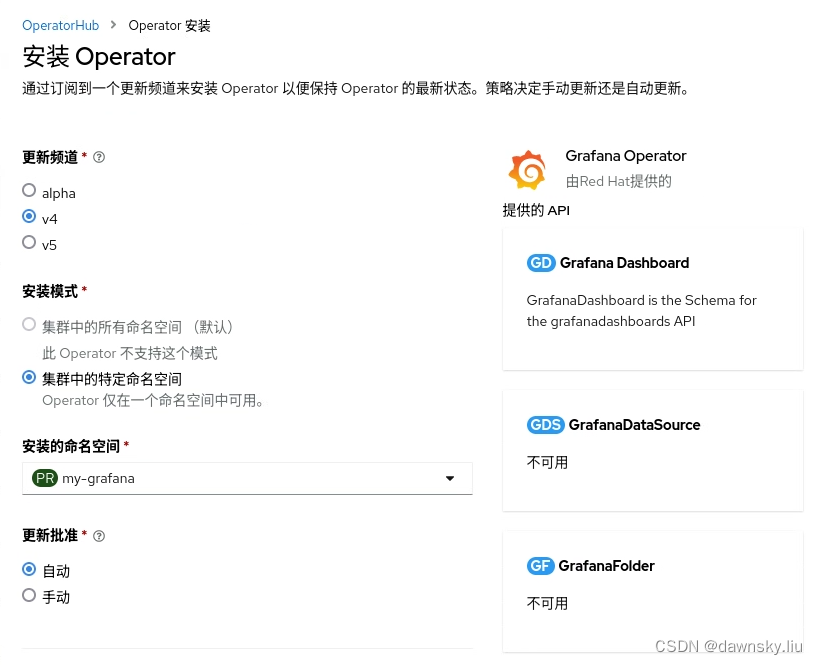
- 创建 my-grafana 项目,然后在其中安装 Grafana Operator v4 版本。
- 执行以下命令,创建一个名为 my-grafana 的 Grafana 实例。注意:以下 YAML 中的 dataStorage 使用了 OpenShift 缺省的存储类。
$ cat << EOF | oc apply -f -
apiVersion: integreatly.org/v1alpha1
kind: Grafana
metadata:name: my-grafananamespace: my-grafana
spec:config:security:admin_user: adminadmin_password: my-passworddataStorage:accessModes:- ReadWriteOncesize: 1Giingress:enabled: truetls:enabled: true
EOF
- 创建名为 grafana-view 的 clusterrolebinding,为所有命名空间的 grafana-serviceaccount 提供 cluster-monitoring-view 角色。
$ oc create clusterrolebinding grafana-view --clusterrole=cluster-monitoring-view --serviceaccount=my-grafana:grafana-serviceaccount
配置 Grafana 数据源
- 执行命令创建一个 GrafanaDataSource,其中使用了基于 grafana-serviceaccoun 的 token 来访问 Thanos Querier。
$ TOKEN=$(oc create token grafana-serviceaccount -n my-grafana)
$ cat << EOF | oc apply -f -
apiVersion: integreatly.org/v1alpha1
kind: GrafanaDataSource
metadata:name: prometheusnamespace: my-grafana
spec:datasources:- basicAuthUser: internalaccess: proxyeditable: truesecureJsonData:httpHeaderValue1: >-Bearer ${TOKEN}name: Prometheusurl: 'https://thanos-querier.openshift-monitoring.svc.cluster.local:9091'jsonData:httpHeaderName1: AuthorizationtimeInterval: 5stlsSkipVerify: truebasicAuth: falseisDefault: trueversion: 1type: prometheusname: test_name
EOF
- 访问 grafana-route 对应的 Grafana 页面,然后使用创建 my-grafana 实例时指定的用户和密码登录。
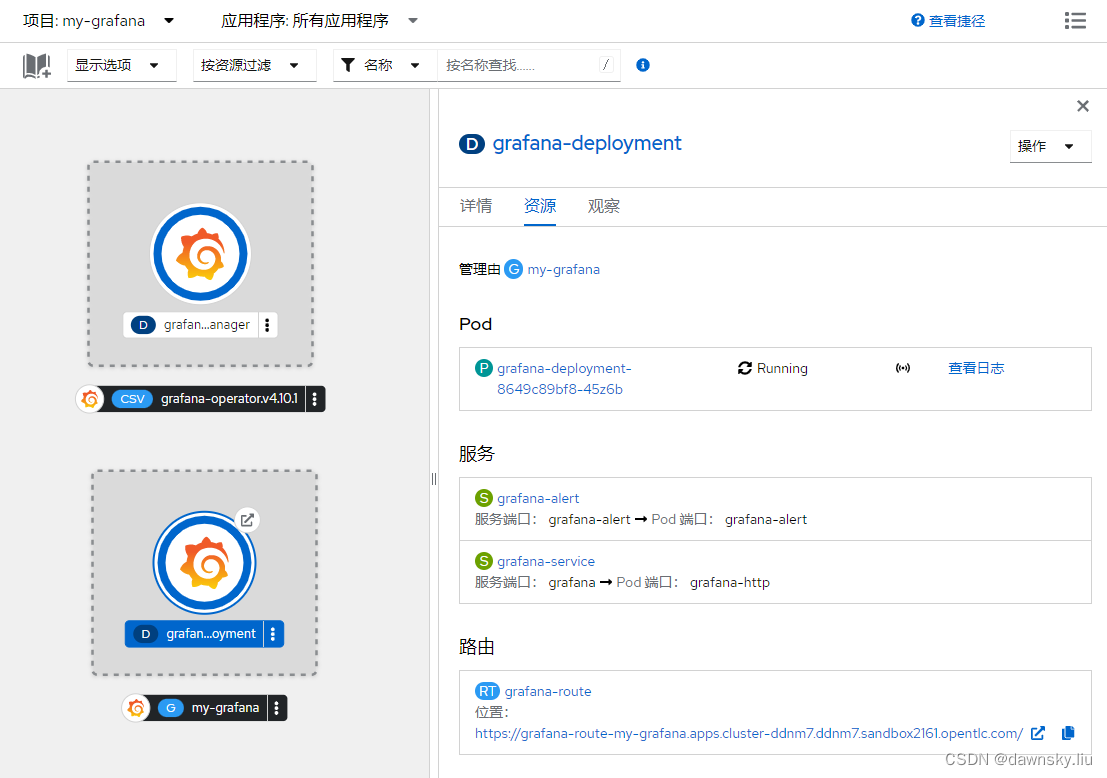
- 进入 Configuration 的 Data Sources 菜单,可以看到名为 Prometheus 的数据源,点击进入。
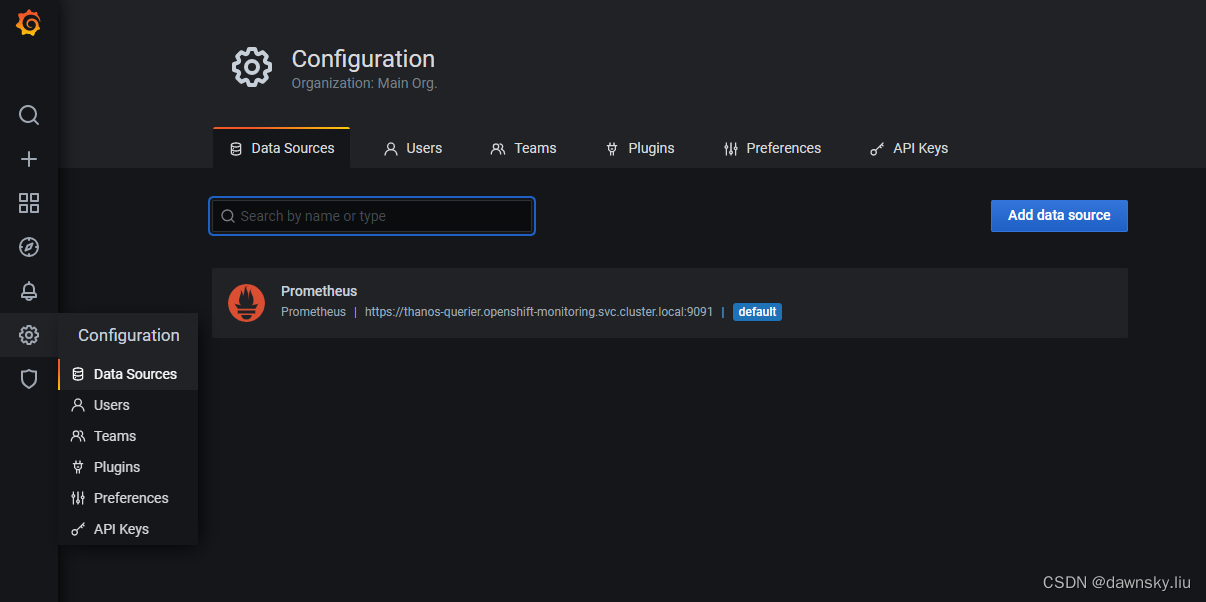
- 点击页面下方的 “ Save & Test”,确认显示 Data srouce is working。
定制监控 Dashboard
- 进入 Create 的 Dashboard 菜单。
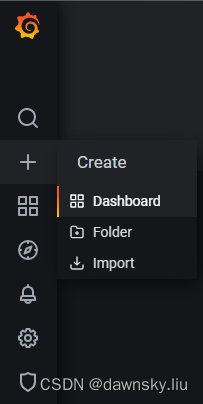
- 在 New dashboard 页面点击 Add an empty panel。
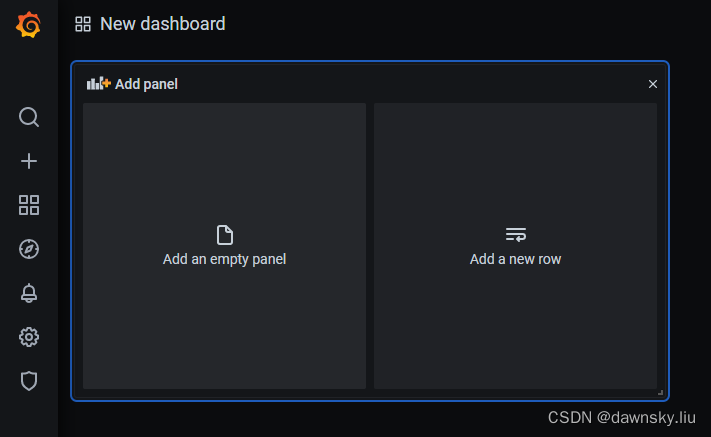
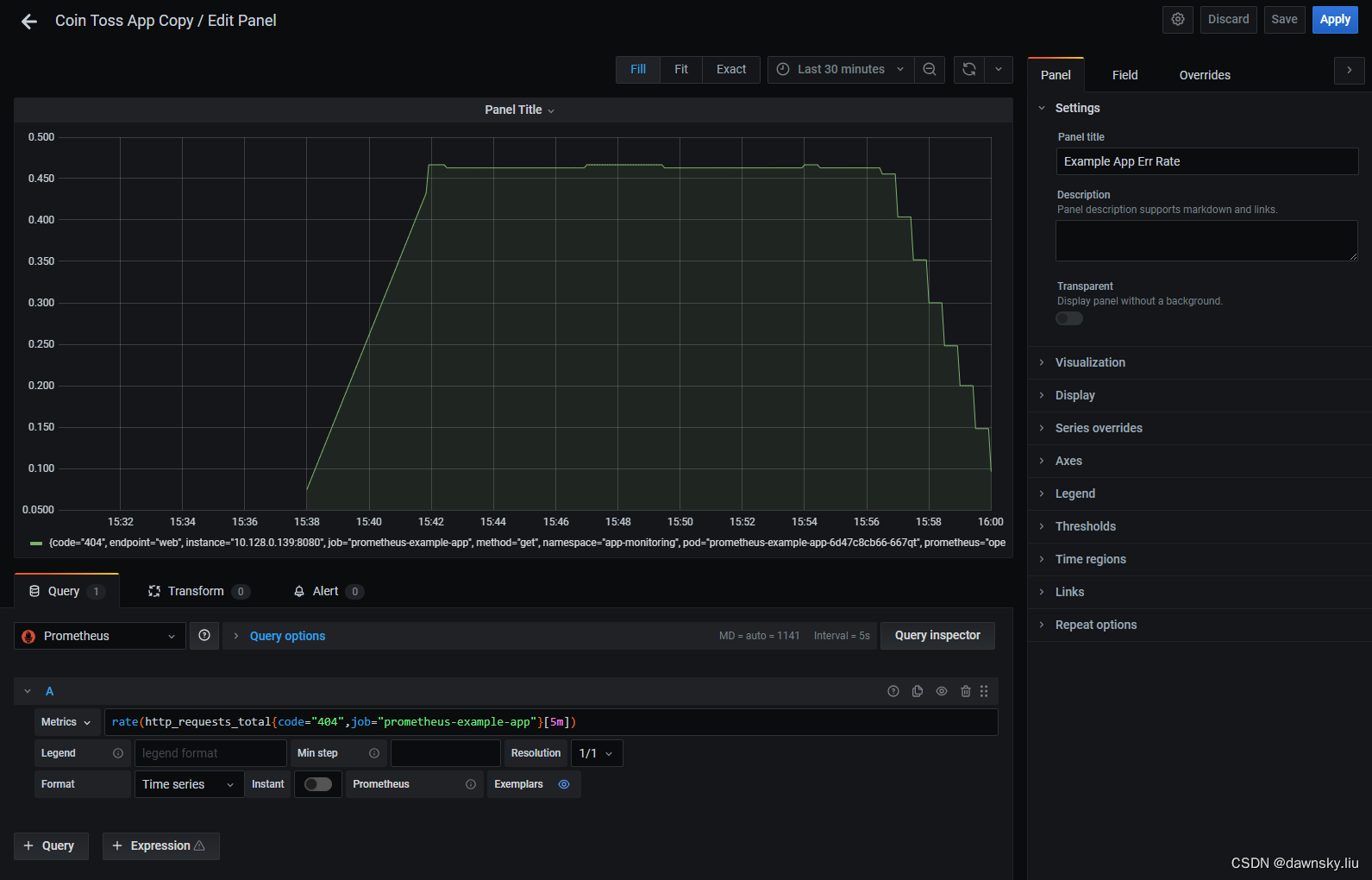
- 在下图中为 Metrics 提供以下内容,然后将 Panel title 设为 Example App Err Rate,最后点击 Apply 按钮。
rate(http_requests_total{code="404",job="prometheus-example-app"}[5m])
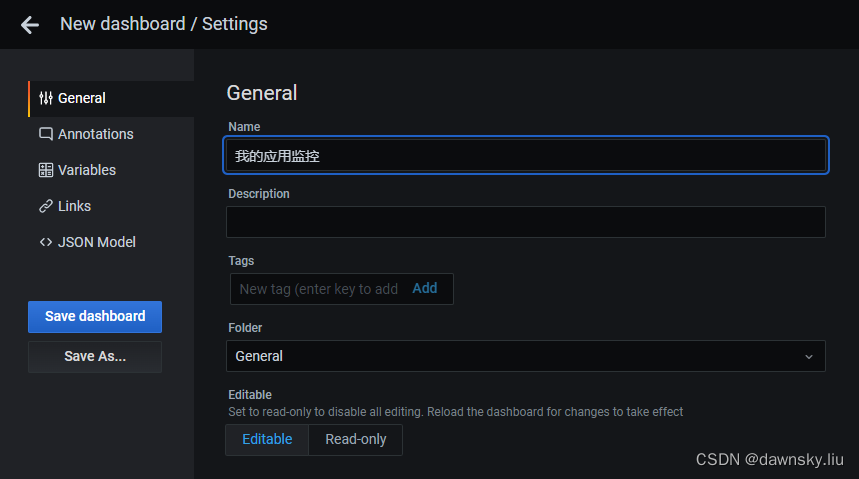
4. 在 Dashboard 页面点击右上方的 Dashboard settings 图标。

5. 设置 Name,然后保存。
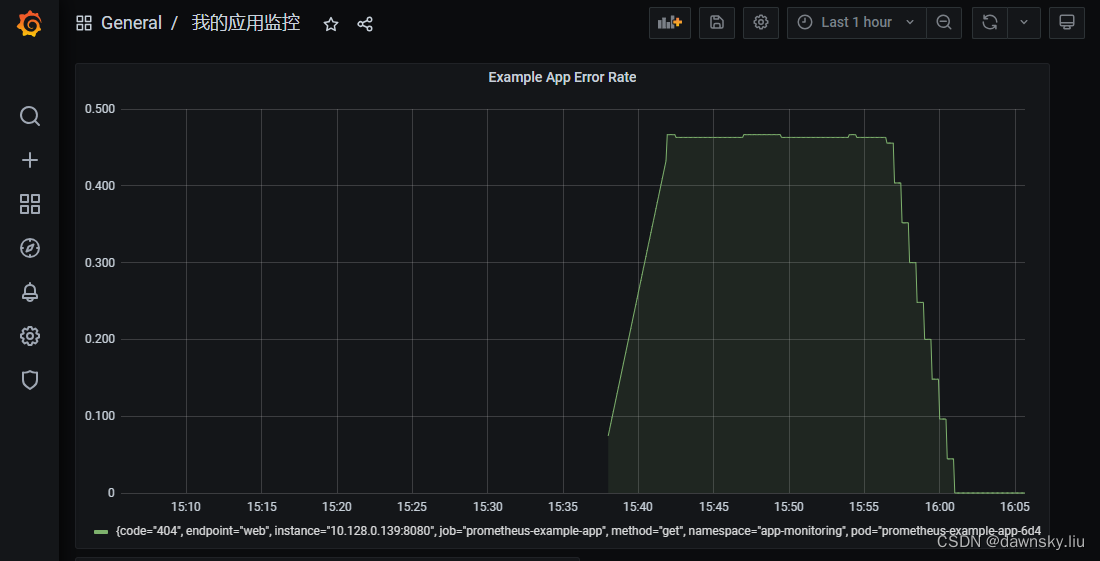
6. 最后通过定制的 Dashboard 监控的应用指标如下图。
演示视频
演示视频
参考
https://github.com/k-srkw/openshift-monitoring-handson/blob/main/monitoring-handson.md
https://cloud.redhat.com/blog/your-guide-to-openshift-observability-part-1
https://access.redhat.com/solutions/5335491
https://access.redhat.com/documentation/en-us/openshift_container_platform/4.5/html/monitoring/monitoring-your-own-services
https://catalog.workshops.aws/aws-openshift-workshop/en-US/8-observability/2-metrics/5-app-dashboard
https://github.com/brancz/prometheus-example-app
https://developers.redhat.com/articles/2023/08/08/how-monitor-workloads-using-openshift-monitoring-stack#how_to_monitor_a_sample_application
https://shonpaz.medium.com/monitor-your-application-metrics-using-the-openshift-monitoring-stack-862cb4111906
https://github.com/OpenShiftDemos/openshift-ops-workshops/blob/ocp4-dev/workshop/content/monitoring-basics.adoc
https://github.com/pittar/openshift-user-workload-monitoring
https://github.com/alvarolop/quarkus-observability-app/blob/main/README.adoc
https://prometheus.io/docs/prometheus/latest/querying/basics/
https://github.com/alvarolop/quarkus-observability-app
相关文章:
OpenShift 4 - 用 Prometheus 和 Grafana 监视用户应用定制的观测指标(视频)
《OpenShift / RHEL / DevSecOps 汇总目录》 说明:本文已经在 OpenShift 4.13 的环境中验证 文章目录 OpenShift 的监控功能构成部署被监控应用用 OpenShift 内置功能监控应用用 Grafana 监控应用安装 Grafana 运行环境配置 Grafana 数据源定制监控 Dashboard 演示视…...
【LeetCode】剑指 Offer <二刷>(3)
目录 题目:剑指 Offer 06. 从尾到头打印链表 - 力扣(LeetCode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 07. 重建二叉树 - 力扣…...

Ceph IO流程及数据分布
1. Ceph IO流程及数据分布 1.1 正常IO流程图 步骤: client 创建cluster handler。client 读取配置文件。client 连接上monitor,获取集群map信息。client 读写io 根据crshmap 算法请求对应的主osd数据节点。主osd数据节点同时写入另外两个副本节点数据。…...

Netty-NIO
文章目录 一、NIO-Selector1.处理accept2.cancel3.处理read4.处理客户端断开5. 处理消息的边界6. 写入内容过多的问题7. 处理可写事件 一、NIO-Selector 1.处理accept //1.创建selector,管理多个channel Selector selector Selector.open(); ByteBuffer buffer ByteBuffer.…...

红外物理学习笔记 ——第三章
第三章 基尔霍夫定律:就是说物体热平衡条件下,发射的辐射功率要等于吸收的辐射功率 M α E M\alpha E MαE α \alpha α 是吸收率, M M M 是幅出度(发射出去的), E E E是辐照度(外面照过来的…...

使用 htmx 构建交互式 Web 应用
学习目标:了解htmx的基本概念、特点和用法,并能够运用htmx来创建交互式的Web应用程序。 学习内容: 1. 什么是htmx? - htmx是一种用于构建交互式Web应用程序的JavaScript库。 - 它通过将HTML扩展为一种声明性的交互式语言&a…...
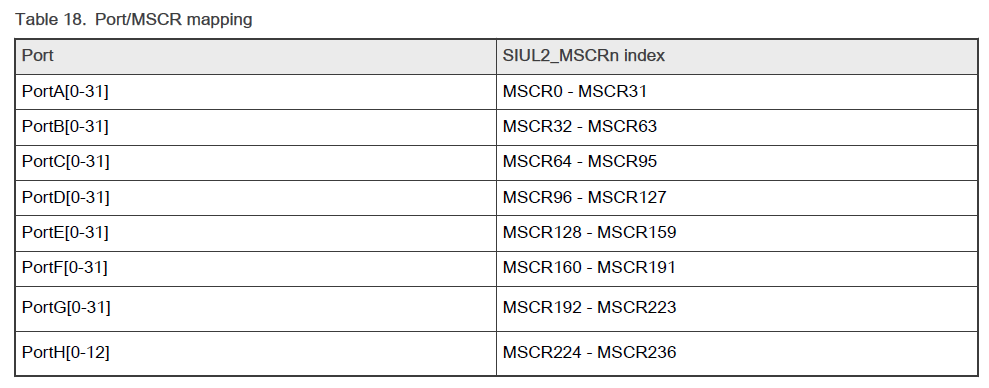
S32K324芯片学习笔记
文章目录 Core and architectureDMASystem and power managementMemory and memory interfacesClocksSecurity and integrity安全与完整性Safety ISO26262Analog、Timers功能框图内存mapflash Signal MultiplexingPort和MSCR寄存器的mapping Core and architecture 两个Arm Co…...

htmx-使HTML更强大
本文作者是360奇舞团开发工程师 htmx 让我们先来看一段俳句: javascript fatigue: longing for a hypertext already in hand 这个俳句很有意思,是开源项目htmx文档中写的,意思是说,我们已经有了超文本,为什么还要去使用javascr…...
Java学习之序列化
1、引言 《手册》第 9 页 “OOP 规约” 部分有一段关于序列化的约定 1: 【强制】当序列化类新增属性时,请不要修改 serialVersionUID 字段,以避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请…...
C++实现蜂群涌现效果(flocking)
Flocking算法0704_元宇宙中的程序员的博客-CSDN博客 每个个体的位置,通过计算与周围个体的速度、角度、位置,去更新位置。...
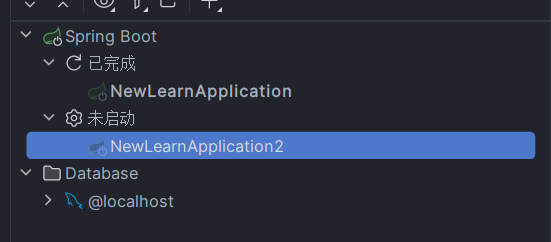
IDEA复制一个工程为多个并启动,测试负载均衡
1 找到服务按钮 2 选择复制配置 3 更改新的名称与虚拟机参数 复制下面的代码在VM参数中 -Dserver.port8082 4 最后启动即可...

001_C++语法基础
C语法基础 所有C语法要用英文区分大小写每个语句写完以分号结束 C标准输入输出头文件iostream 若想通过C实现数据的输入和输出,需要导入标准输入输出头文件 #include <iostream>标准输入输出头文件<iostream>中包含了cin输入语句和cout输出语句 标…...
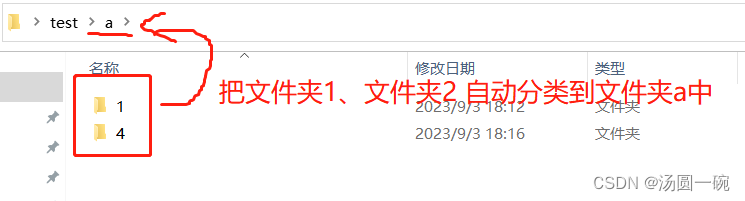
对Excel表中归类的文件夹进行自动分类
首先把excel表另存为.txt文件(注意:刚开始可能是ANSI格式,需要转成UTF-8格式);再新建一个.txt文件,重命名成.bat文件(注意:直接创建的如果是是UTF-8格式,最好转成ANSI格式࿰…...
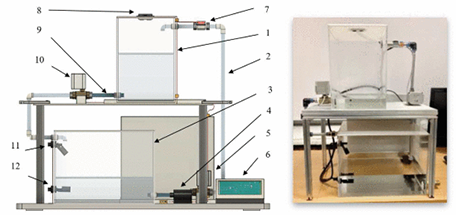
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析
LabVIEW液压支架控制系统的使用与各种配置的预测模型的比较分析 模型预测控制在工业中应用广泛。这种方法的优点之一是在求解最优控制问题时能够明确考虑对输入和输出状态施加的约束。控制对象模型用于有限时间范围内最优控制的实时计算。所使用的数学设备允许从具有单输入和单…...

C++中位运算符使用
& 与 只有都为1结果为1 0 & 0 00 & 1 01 & 0 01 & 1 1 | 或 只要一个为1结果为1 0|00 0|11 1|01 1|11 ^ 异或 两个相同的数字为0,其余为1 0^00 1^01 0^11 1^10 ~ 取反 将进制位数进行取反 ~1-2 //0000 0001-->代…...

微机原理 || 第2次测试:汇编指令(加减乘除运算,XOR,PUSH,POP,寻址方式,物理地址公式,状态标志位)(测试题+手写解析)
(一)测试题目: 1.数[X]补1111,1110B,则其真值为 2.在I/O指令中,可用于表示端口地址的寄存器 3. MOV AX,[BXSl]的指令中,源操作数的物理地址应该如何计算 4.执行以下两条指令后,标志寄存器FLAGS的六个状态…...

人员闯入检测告警算法
人员闯入检测告警算法通过yolov5网络模型识别检测算法,人员闯入检测告警算法对未经许可或非法进入的人员进行及时识别告警,确保对危险区域的安全管理和保护。YOLO系列算法是一类典型的one-stage目标检测算法,其利用anchor box将分类与目标定位…...
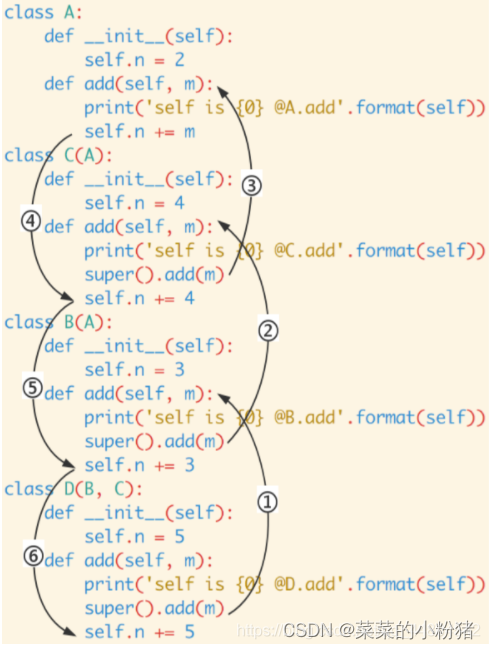
python中super()用法
super关键字的用法 一、概述二、作用三、语法四、使用示例1.通过super() 来调用父类的__init__ 构造方法:2.通过supper() 来调用与子类同名的父类方法2.1 单继承2.2 多继承 一、概述 super() 是python 中调用父类(超类)的一种方法࿰…...
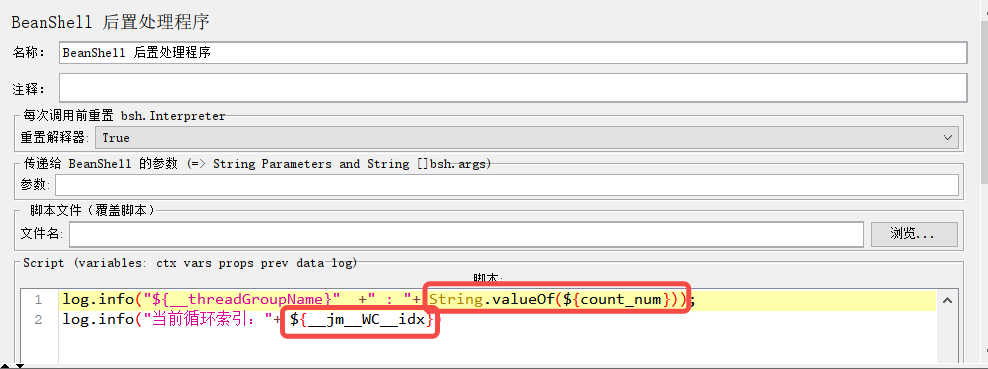
jmeter While控制器
一种常见的循环控制语句,用于重复执行一段代码块,直到指定的条件不再满足。 参数: 空LASTJMeter变量、函数、属性或任意其他可用表达式 (jmeter提供的方法)。判断变量值count_num小于等于20,推荐简单的几…...

3D数字孪生技术助力港口全新升级,提供实时数据进行智能调度
港口3D数字孪生平台是一种基于数字技术的虚拟模型,它可以模拟真实的港口环境,并对港口的运营、管理、安全等方面进行实时监控和优化。该平台带来了许多智能化提升,包括以下几个方面: 一、自动化操作和智能调度 数字孪生平台可以通…...

OpenClaw高消耗场景优化:Qwen3-32B私有镜像成本实测
OpenClaw高消耗场景优化:Qwen3-32B私有镜像成本实测 1. 问题背景与测试动机 最近在尝试用OpenClaw自动化处理我的日常工作流时,发现一个令人头疼的问题:长链条任务的Token消耗简直像开了水龙头一样。最夸张的一次,一个简单的&qu…...

GCC开发者转LLVM必看:模块化设计带来的5个关键工作流变革
GCC开发者转LLVM必看:模块化设计带来的5个关键工作流变革 当GCC开发者第一次接触LLVM时,往往会惊讶于其完全不同的设计哲学。就像从单块巨石建筑转向预制模块化结构,LLVM的三段式架构不仅改变了代码的组织方式,更从根本上重塑了编…...

用Image-to-Video为你的图片注入灵魂:动态效果生成全攻略
用Image-to-Video为你的图片注入灵魂:动态效果生成全攻略 1. 引言:让静态图片动起来 想象一下,你拍了一张完美的风景照,但总觉得少了点什么——如果云能飘动、树叶能摇曳、水面能泛起波纹,那该多好?这就是…...

Anything V5镜像实战:从部署到生成你的第一张二次元头像
Anything V5镜像实战:从部署到生成你的第一张二次元头像 1. 项目介绍与核心价值 Anything V5是基于Stable Diffusion技术优化的高质量二次元图像生成模型。相比通用版本,它特别擅长生成动漫风格的人物肖像、场景插画等作品,在细节表现和风格…...

SecGPT-14B部署教程:适配国产昇腾910B的vLLM分支编译与性能调优
SecGPT-14B部署教程:适配国产昇腾910B的vLLM分支编译与性能调优 1. SecGPT-14B简介 SecGPT是由云起无垠推出的开源大语言模型,专注于网络安全领域。该模型融合了自然语言理解、代码生成和安全知识推理等能力,旨在为安全专业人员提供智能辅助…...

解决QGroundControl或华科尔地面站因QT版本冲突导致的启动失败问题
1. 当QGroundControl或华科尔地面站打不开时该怎么办 遇到QGroundControl或华科尔地面站安装后无法启动的问题,很多用户第一反应是软件安装包损坏了。但实际上,这很可能是由于QT框架版本冲突导致的。QT是一个跨平台的C图形用户界面应用程序开发框架&…...

美胸-年美-造相Z-Turbo在网络安全领域的创新应用:恶意代码可视化分析
美胸-年美-造相Z-Turbo在网络安全领域的创新应用:恶意代码可视化分析 1. 当安全分析遇上图像生成:一个意想不到的跨界组合 最近在调试一个自动化威胁分析流程时,我偶然发现了一个有趣的现象:当把一段混淆后的JavaScript恶意代码…...

告别低效循环:利用快马平台智能生成向量化代码,提升数据处理性能
最近在做一个数据分析项目时,遇到了性能瓶颈。处理一个几十万行的数据集时,简单的循环操作竟然要跑好几分钟。经过一番摸索,我发现向量化操作真是个神器,今天就分享一下如何用NumPy和Pandas来提升数据处理效率。 首先我们创建一个…...

破解B站评论区识人困境!B站成分检测器让用户画像识别效率飙升8倍
破解B站评论区识人困境!B站成分检测器让用户画像识别效率飙升8倍 【免费下载链接】bilibili-comment-checker B站评论区自动标注成分,支持动态和关注识别以及手动输入 UID 识别 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-comment-checke…...

探索前沿技术趋势:2024年最值得关注的创新应用场景
1. 生成式AI的爆发式应用 2024年最让人兴奋的技术趋势,莫过于生成式AI从实验室走向千家万户。我最近测试了十几个主流AI创作工具,发现它们已经能完成许多过去认为"只有人类能做到"的任务。比如用Midjourney生成产品设计图,只需要简…...