Python算法——排序算法(冒泡、选择、插入、快速、堆排序、并归排序、希尔、计数、桶排序、基数排序)
本文章只展示代码实现 ,原理大家可以参考:
https://zhuanlan.zhihu.com/p/42586566
一、冒泡排序
def bubble_sort(lst):for i in range(len(lst) - 1): # 表示第i趟exchange = False # 每一趟做标记for j in range(len(lst)-i-1): # 表示箭头if lst[j] > lst[j+1]: # 此时是升序排序,>改为<则改为了降序lst[j],lst[j+1] = lst[j+1],lst[j]exchange = True # 进行了交换,exchange标记为Tureprint(f"第{i+1}趟后的列表为:{lst}") # 查看排序过程if not exchange: # 如果没有进行交换,直接返回,优化的步骤returnlst2 = [1,2,3,8,7,6,5]print("***改进后的冒泡排序***")print(f"初始列表:{lst2}")bubble_sort(lst2)# 输出结果# 初始列表:[1, 2, 3, 8, 7, 6, 5]# 第1趟后的列表为:[1, 2, 3, 7, 6, 5, 8]# 第2趟后的列表为:[1, 2, 3, 6, 5, 7, 8]# 第3趟后的列表为:[1, 2, 3, 5, 6, 7, 8]# 第4趟后的列表为:[1, 2, 3, 5, 6, 7, 8]二、选择排序
def select_sort(lst):for i in range(len(lst) - 1): # i代表第几趟min_location = i # 最小位置的标记,第一次默认最小的数为无序区的第一个,即下标为ifor j in range(i+1,len(lst)): # 从i开始相当于自己和自己比了一次,此步骤多余,因此从i+1开始if lst[j] < lst[min_location]:min_location = jlst[i],lst[min_location] = lst[min_location],lst[i] # 最小的值和有序区的最后一个值进行交换print(f"第{i + 1}趟后的列表为:{lst}")lst1 = [3,2,4,13,11,8]select_sort(lst1)# 结果# 第1趟后的列表为:[2, 3, 4, 13, 11, 8]# 第2趟后的列表为:[2, 3, 4, 13, 11, 8]# 第3趟后的列表为:[2, 3, 4, 13, 11, 8]# 第4趟后的列表为:[2, 3, 4, 8, 11, 13]# 第5趟后的列表为:[2, 3, 4, 8, 11, 13]三、插入排序
def insert_sort(lst):for i in range(1,len(lst)): # i表示摸到的牌的下标tmp = lst[i] # tmp代表摸到的牌j = i - 1 # j代表的是手里的牌的下标,手上自动已有第一张牌while lst[j] > tmp and j >= 0: # 需要移动有序区牌的情况lst[j+1] = lst[j]j -= 1lst[j+1] = tmp # lst[j+1]是用来存放要插入的牌print(f"第{i}趟的列表:{lst}")lst1 = [3,2,5,8,6,9,7]print(f"原列表{lst1}")insert_sort(lst1)# 结果原列表[3, 2, 5, 8, 6, 9, 7]# 第1趟的列表:[2, 3, 5, 8, 6, 9, 7]# 第2趟的列表:[2, 3, 5, 8, 6, 9, 7]# 第3趟的列表:[2, 3, 5, 8, 6, 9, 7]# 第4趟的列表:[2, 3, 5, 6, 8, 9, 7]# 第5趟的列表:[2, 3, 5, 6, 8, 9, 7]# 第6趟的列表:[2, 3, 5, 6, 7, 8, 9]四、快速排序
def partition(lst,left,right): # partition(分割)函数tmp = lst[left] # 存放基准点,以最左边的值为例while left < right: # 当左边的位置(下标)小于右边的时候,说明还有至少两个元素,则进行排序while lst[right] >= tmp and left < right: # 从右边找比tmp小的元素right -= 1 # 比tmp大,则往左移动一位lst[left] = lst[right] # 如果出现lst[right] < tmp,则将右边的值lst[right]写到左边的空位lst[left]# print(f"从右边找比tmp小的数后的列表:{lst}")while lst[left] <= tmp and left < right: # 从左边找比tmp大的元素lst[left],放到右边的空位上lst[right]left += 1lst[right] = lst[left]# print(f"从左边找比tmp大的数后的列表:{lst}")lst[left] = tmp # 最后把tmp归位return left # 返回mid的值# lst1 = [5,7,4,2,6,8,3,1,9]# print(f"分割前的列表{lst1}")# partition(lst1,0,len(lst1)-1)# print(f"最终tmp归为后的列表:{lst1}")# 输出结果# 分割前的列表[5, 7, 4, 2, 6, 8, 3, 1, 9]# 从右边找比tmp小的数后的列表:[1, 7, 4, 2, 6, 8, 3, 1, 9]# 从左边找比tmp大的数后的列表:[1, 7, 4, 2, 6, 8, 3, 7, 9]# 从右边找比tmp小的数后的列表:[1, 3, 4, 2, 6, 8, 3, 7, 9]# 从左边找比tmp大的数后的列表:[1, 3, 4, 2, 6, 8, 6, 7, 9]# 从右边找比tmp小的数后的列表:[1, 3, 4, 2, 6, 8, 6, 7, 9]# 从左边找比tmp大的数后的列表:[1, 3, 4, 2, 6, 8, 6, 7, 9]# 最终tmp归为后的列表:[1, 3, 4, 2, 5, 8, 6, 7, 9]# 随后完成快速排序主体部分的代码def quick_sort(lst, left, right): # 需要传入一个列表lst,以及最左边后最后边的位置if left < right: # 如果左边小于右边,则说明列表内至少有两个元素mid = partition(lst, left, right) # 通过partition获得基准值midquick_sort(lst, left, mid - 1) # 递归左边的元素quick_sort(lst, mid + 1, right) # 递归右边的元素lst2 = [5,7,4,2,6,8,3,1,9]print(f"初始列表:{lst2}")quick_sort(lst2,0,len(lst2)-1)print(f"快速排序后的{lst2}")# 输出结果# 初始列表:[5, 7, 4, 2, 6, 8, 3, 1, 9]# 快速排序后的[1, 2, 3, 4, 5, 6, 7, 8, 9]五、堆排序
我们以大根堆为例,因为大根堆排序出来的结果是升序。
# 向下调整函数def shift(lst,low,high): # low:对根节点的位置;high:堆最后一个元素的位置i = low # 标记lowj = 2 * i + 1 # j代表左孩子位置tmp = lst[low] # 把堆暂时顶存起来while j <= high: # 只要j位置大于high就说明没有元素了,循环就停止,所欲j<=high时就代表有元素,就循环if j + 1 <= high and lst[j+1] > lst[j]: # 首先判断是否j这一层有右孩子(j + 1直的j这一层的另一个数),其次判断j这一层元素的大小,j+1(右孩子)大于j(左孩子),则j指向j+1j = j + 1 # j指向右孩子if lst[j] > tmp: # 然后判断j和堆顶的元素(tmp)的大小,如果j位置的元素大于堆顶元素,则堆顶元素和j(左孩子)位置互换lst[i] = lst[j]i = j # low堆顶的位置指向i,继续看下一层j = 2 * i + 1 # 同时j指向下一层的左孩子else: # tmp最大,则把tmp放到i的位置上lst[i] = tmp # 把tmp放到某一级breakelse:lst[i] = tmp # 把tmp放到叶子节点上# 堆排序主函数def heap_sort(lst):n = len(lst) # 获取列表长度# 先建堆for i in range((n-2)//2,-1,-1): #从最后一个根节点,到最上面的根节点 # i代表建堆时调整部分的根的下标,(n-2)//2是根到位置,n-1是孩子节点下标,(n-1-1)//2代表根节点的下标,-1是最后的根节点位置(0),那么range就是-1shift(lst,i,n-1) # i为堆顶,high为最后一个节点n-1# 建堆完成# print(lst) # 检验建堆是否完成# 检验建堆是否成功# lst = [i for i in range(10)]# import random# random.shuffle(lst)# print(lst)# heap_sort(lst)# 结果# [2, 3, 9, 7, 1, 8, 6, 0, 5, 4]# [9, 7, 8, 5, 4, 2, 6, 0, 3, 1]# 接下来“农村包围城市”,从最后一个节点开始for i in range(n-1,-1,-1): # i指向最后一个节点lst[0],lst[i] = lst[i],lst[0] # 堆顶元素lst[0]和最后一个节点位置互换shift(lst,0,i - 1) # i - 1代表新的high# return lstlst1 = [i for i in range(10)]import randomrandom.shuffle(lst1)print(f"初始列表{lst1}")heap_sort(lst1)print(lst1)# 结果# 初始列表[2, 1, 8, 4, 6, 3, 7, 5, 9, 0]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]python中堆排序的内置模块
import heapq # q-->queue 优先队列(小的或大的先出)import randomlst2 = [i for i in range(10)]random.shuffle(lst2)print(f"初始列表:{lst2}")heapq.heapify(lst2) # 建堆,建的是小根堆for i in range(len(lst2)):print(heapq.heappop(lst2),end=",") # heappop每次弹出一个最小的元素堆排序解决topk问题
现在有n个数,需要设计算法得到前k大的数。(k<n)
import randomdef shift(lst,low,high): # low:对根节点的位置;high:堆最后一个元素的位置i = low # 标记lowj = 2 * i + 1 # j代表左孩子位置tmp = lst[low] # 把堆顶存起来while j <= high: # 只要j位置有元素,就循环if j + 1 <= high and lst[j+1] < lst[j]: # 首先判断是否j这一层有右孩子(j + 1直的j这一层的另一个数),其次判断j这一层元素的大小,j+1(有孩子)大于j,则j指向j+1j = j + 1 # j指向有孩子if lst[j] < tmp: # 然后判断j和堆顶的元素(tmp)的大小,如果j位置的元素大于堆顶元素,则堆顶元素和j(左孩子)位置互换lst[i] = lst[j]i = j # 继续看下一层j = 2 * i + 1else: # tmp最大,则把tmp放到i的位置上lst[i] = tmp # 把tmp放到某一级breaklst[i] = tmp # 把tmp放到叶子节点上# topkdef topk(lst,k):heap = lst[0:k]for i in range((k-2)//2,-1,-1):shift(heap,i,k-1)# 1.建堆完成for i in range(k,len(lst)-1):if lst[i] > heap[0]:heap[0] = lst[i]shift(heap,0,k-1)# 2.遍历for i in range(k-1,-1,-1):heap[0],heap[i] = heap[i],heap[0]shift(heap,0,i-1)# 3.出数return heaplst1 = [i for i in range(10)]random.shuffle(lst1)print(f"初始列表{lst1}")result = topk(lst1,5)print(result)# 结果# 初始列表[1, 8, 7, 2, 6, 3, 0, 9, 5, 4]# [9, 8, 7, 6, 5]六、归并算法
# 已有两个有序区的归并函数def merge(lst,low,mid,high):i = low # 左边有序区的标记位j = mid + 1 # 右边有序区的标记位tmp_lst = [] # 存放比较大小之后的数while i <= mid and j <= high: # 只要左右两边有序区都有数if lst[i] < lst[j]: # 依次判断左右两个有序区的元素大小tmp_lst.append(lst[i])i += 1else:tmp_lst.append(lst[j])j += 1# while执行完,肯定有一个有序区没有元素了while i <= mid: # 左边有序区还有元素情况,则把剩下元素增加到tmp_lsttmp_lst.append(lst[i])i += 1while j <= high: # 右边有序区还有元素,则把剩下元素增加到tmp_lsttmp_lst.append(lst[j])j += 1lst[low:high+1] = tmp_lst # 把tmp_lst写回去,low是0,high+1因为遍历会比长度小1# lst2 = [2,4,5,7,9,1,3,6,8]# merge(lst2,0,4,8)# print(lst2)# 输出结果# [1, 2, 3, 4, 5, 6, 7, 8, 9]# 归并排序主函数def merge_sort(lst,low,high): # low:下标最小的;high:下标最大的if low < high: # 至少有两个元素mid = (low+high)//2merge_sort(lst,low,mid) # 递归左边化成有序区merge_sort(lst,mid+1,high) # 递归右边化成有序区merge(lst,low,mid,high) # 归并两个有序区lst1 = [i for i in range(20)]import randomrandom.shuffle(lst1)print(f"初始列表:{lst1}")merge_sort(lst1,0,len(lst1)-1)print(lst1)# 输出结果初始列表:# [1, 9, 15, 18, 2, 16, 11, 0, 8, 4, 12, 13, 14, 19, 3, 10, 5, 7, 17, 6]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]七、希尔排序
# 因为希尔排序是利用了插入排序的思想,因此我们可以在插入排序算法的基础上改def insert_sort_gap(lst,gap): # gap即为d,即间隔for i in range(gap,len(lst)): # 从gap开始tmp = lst[i] #j = i - gap # j代表的是手里的牌的下标,换为希尔排序,那么就是和gap距离的元素相比较while lst[j] > tmp and j >= 0:# 说明lst[i-gap]>lst[i],即需要调整元素的情况,即比如实例中的3(lst[i])和5(lst[i-gap]),5>3且5的位置》0进行调整lst[j+gap] = lst[j] # 那么调整就是把lst[i-gap]赋值给新的lst[i]即lst[j+gap],这样保证了让小的排到前面,最终输出升序j -= gaplst[j+gap] = tmp # lst[j+1]是用来存放要插入的牌def shell_sort(lst):d = len(lst)//2 # 求dwhile d >= 1: # 最终d=1进行最后一次循环,因此d》=1进行循环insert_sort_gap(lst,d) # 进行插入排序d //= 2 # 产生下一个dprint(lst)# 检测希尔排序lst1 = [i for i in range(14)]import randomrandom.shuffle(lst1)print(f"{lst1}")shell_sort(lst1)# 输出结果# [0, 2, 10, 7, 4, 9, 11, 6, 8, 12, 13, 1, 5, 3]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]八、计数排序
def count_sort(lst,max_count=100): # 传入列表和最大值count = [0 for i in range(max_count+1)] # 计数列表for val in lst:count[val] += 1 # val即为下标lst.clear() # 写到lst中之前需要情况lstfor ind,val in enumerate(count): # 下标和值for i in range(val): # 查看个数并增加到列表中lst.append(ind)import randomlst1 = [random.randint(0,5) for i in range(10)]print(lst1)count_sort(lst1)print(lst1)# 输出结果# [2, 2, 0, 1, 4, 3, 5, 4, 0, 3]# [0, 0, 1, 2, 2, 3, 3, 4, 4, 5]九、桶排序
def bucket_sort(lst, n=100, max_num=10000): # 船体列表和最大值为10000buckets = [[] for _ in range(n)] # 创建桶for var in lst:i = min(var // (max_num // n), n - 1)# 此时需要考虑如何进桶,i表示var放入几号桶里buckets[i].append(var) # 把var加到桶里for j in range(len(buckets[i]) - 1, 0, -1): # 通过插入排序排序桶内元素if buckets[i][j] < buckets[i][j - 1]:buckets[i][j], buckets[i][j - 1] = buckets[i][j - 1], buckets[i][j]else:breaksorted_lst = []for buc in buckets:sorted_lst.extend(buc)return sorted_lstimport randomlst1 = [random.randint(0, 10000) for i in range(100000)]# print(lst1)lst1 = bucket_sort(lst1)print(lst1)# 结果# [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1,......]十、基数排序
def redix_sort(lst):max_num = max(lst) # 求最大值确定位数,99-->2,888-->3it = 0 # 用于去10的次方while 10 ** it <= max_num:buckets = [[] for _ in range(10)] # 分10个桶for var in lst: # 进行装桶操作# 987获取个位:987%10=7,即987//1-->987,987%10-->7;取十位:987//10-->98,98%10-->8;取百位987//100-->9,9%10=9digit = (var // 10 ** it)% 10buckets[digit].append(var)# 分桶完成lst.clear() # 清空列表for buc in buckets:lst.extend(buc) # 把桶内数写回lstprint(lst) # 查看每次分桶it += 1import randomlst1 = list(range(20))random.shuffle(lst1)print(lst1)redix_sort(lst1)print(lst1)# 输出结果# [3, 1, 6, 15, 2, 18, 0, 16, 19, 7, 11, 5, 9, 10, 17, 8, 13, 12, 14, 4]# [0, 10, 1, 11, 2, 12, 3, 13, 14, 4, 15, 5, 6, 16, 7, 17, 18, 8, 19, 9]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]相关文章:
)
Python算法——排序算法(冒泡、选择、插入、快速、堆排序、并归排序、希尔、计数、桶排序、基数排序)
本文章只展示代码实现 ,原理大家可以参考: https://zhuanlan.zhihu.com/p/42586566 一、冒泡排序 def bubble_sort(lst):for i in range(len(lst) - 1): # 表示第i趟exchange False # 每一趟做标记for j in range(len(lst)-i-1): # 表示箭头if ls…...
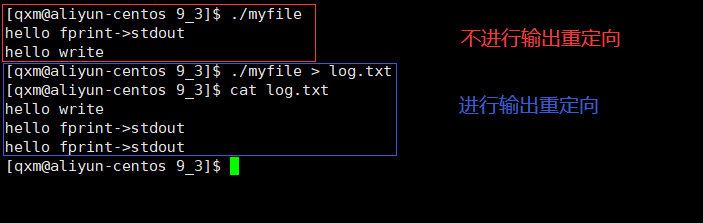
[Linux]文件描述符(万字详解)
[Linux]文件描述符 文章目录 [Linux]文件描述符文件系统接口open函数close函数write函数read函数系统接口与编程语言库函数的关系 文件描述符文件描述符的概念文件数据交换的原理理解“一切皆文件”进程默认文件描述符文件描述符和编程语言的关系 重定向输出重定向输入重定向追…...
RenderTarget导出成图片,CineCamera相机
一、获取Cinecamera相机图像 1.1、启用UE自带插件 1.2、在UE编辑器窗口栏找到Composure合成,打开窗口 1. 3、右键空白处,新建合成,默认名称为 0010_comp;再右键新建的 0010_comp,新建图层元素 CGLayer层,默…...
深入探讨Java虚拟机(JVM):执行流程、内存管理和垃圾回收机制
目录 什么是JVM? JVM 执行流程 JVM 运行时数据区 堆(线程共享) Java虚拟机栈(线程私有) 什么是线程私有? 程序计数器(线程私有) 方法区(线程共享) JDK 1.8 元空…...
3D 碰撞检测
推荐:使用 NSDT场景编辑器快速搭建3D应用场景 轴对齐边界框 与 2D 碰撞检测一样,轴对齐边界框 (AABB) 是确定两个游戏实体是否重叠的最快算法。这包括将游戏实体包装在一个非旋转(因此轴对齐)的框中&#…...
Unity Canvas动画不显示的问题
问题描述: 我通过角色创建了一个walk的动画,当我把这个动画给到Canvas里面的一个image上,这个动画就不能正常播放了,经过一系列的查看我才发现,canvas里面动画播放和非canvas得动画播放,他们的动画参数是不一样的。一个…...

NSSCTF2nd与羊城杯部分记录
文章目录 前言[NSSCTF 2nd]php签到[NSSCTF 2nd]MyBox[NSSCTF 2nd]MyHurricane[NSSCTF 2nd]MyJs[NSSCTF 2nd]MyAPK羊城杯[2023] D0nt pl4y g4m3!!!羊城杯[2023]ezyaml羊城杯[2023]Serpent羊城杯[2023]EZ_web羊城杯[2023]Ez_misc总结 前言 今天周日,有点无聊没事干&a…...

数据库(一) 基础知识
概述 数据库是按照数据结构来组织,存储和管理数据的仓库 数据模型 数据库系统的核心和基础是数据模型,数据模型是严格定义的一组概念的集合。因此数据模型一般由数据结构、数据操作和完整性约束三部分组成。数据模型主要分为三种:层次模型,网状模型和关…...
vue从零开始学习
npm install慢解决方法:删掉nodel_modules。 5.0.3:表示安装指定的5.0.3版本 ~5.0.3:表示安装5.0X中最新的版本 ^5.0.3: 表示安装5.x.x中最新的版本。 yarn的优点: 1.速度快,可以并行安装 2.安装版本统一 项目搭建: 安装nodejs查看node版本:node -v安装vue clie : np…...
dji uav建图导航系列(三)模拟建图、导航
前面博文【dji uav建图导航系列()建图】、【dji uav建图导航系列()导航】 使用真实无人机和挂载的激光雷达完成建图、导航的任务。 当需要验证某一个slam算法时,我们通常使用模拟环境进行测试,这里使用stageros进行模拟测试,实际就是通过模拟器,虚拟一个带有传感器(如…...
PixelSNAIL论文代码学习(1)——总体框架和平移实现因果卷积
文章目录 引言正文目录解析README.md阅读Setup配置Training the model训练模型Pretrained Model Check Point预训练的模型训练方法 train.py文件的阅读model.py文件阅读h12_noup_smallkey_spec模型定义_base_noup_smallkey_spec模型实现一、定义因果卷积过程通过平移实现因果卷…...

Python大数据处理利器之Pyspark详解
摘要: 在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark…...

S905L3A(M401A)拆解, 运行EmuELEC和Armbian
关于S905L3A / S905L3AB S905Lx系列没有公开资料, 猜测是Amlogic用于2B的芯片型号, 最早的 S905LB 是 S905X 的马甲, 而这个 S905L3A/S905L3AB 则是 S905X2 的马甲, 因为在性能评测里这两个U的得分几乎一样. S905L3A/S905L3AB 和 S905X2, S905X3 一样 GPU 是 G31, 相比前一代的…...
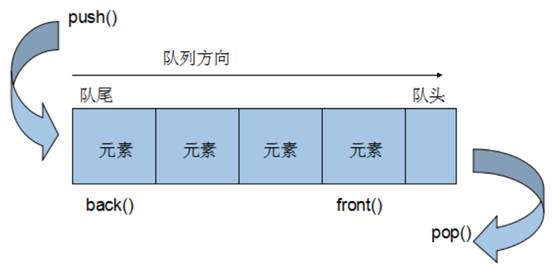
stack和queue容器
1 stack 基本概念 概念:stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口 栈中只有顶端的元素才可以被外界使用,因此栈不允许有遍历行为 栈中进入数据称为 — 入栈 push 栈中弹出数据称为 — 出栈 pop 2 stack 常用…...
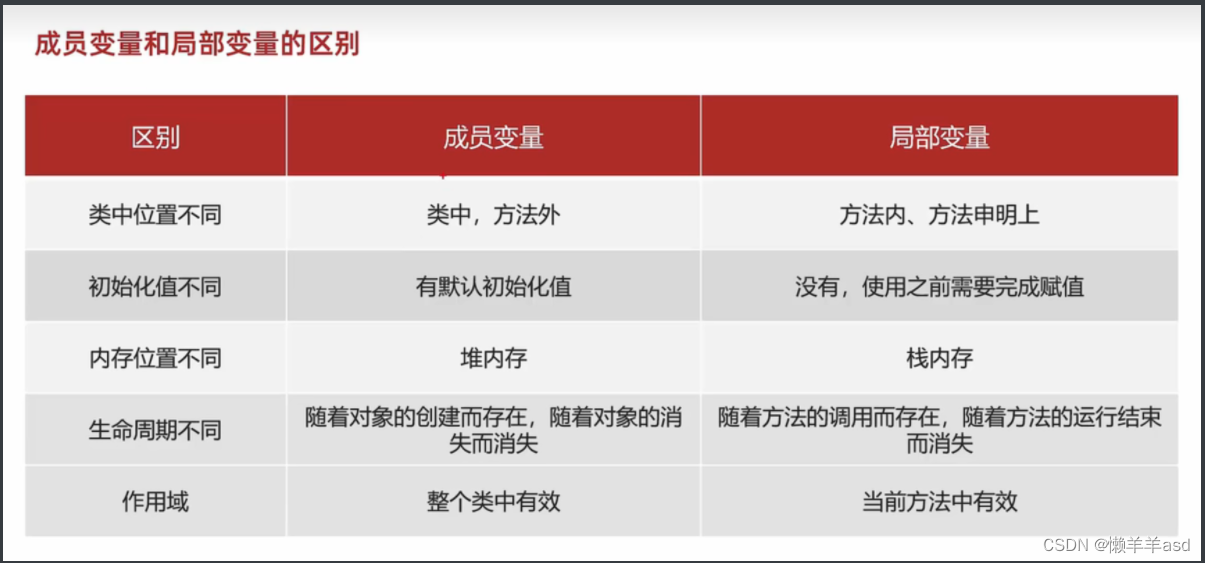
面向对象基础
文章目录 面向对象基础一.面向对象介绍二.设计对象并使用三.封装四.This关键字五.构造方法六.标准的Javabean类七.对象内存图八.基本数据类型和引用数据类型九.成员和局部 面向对象基础 一.面向对象介绍 面向:拿,找 对象:能干活的东西 面向对象编程:找东西来做对应的事情 …...
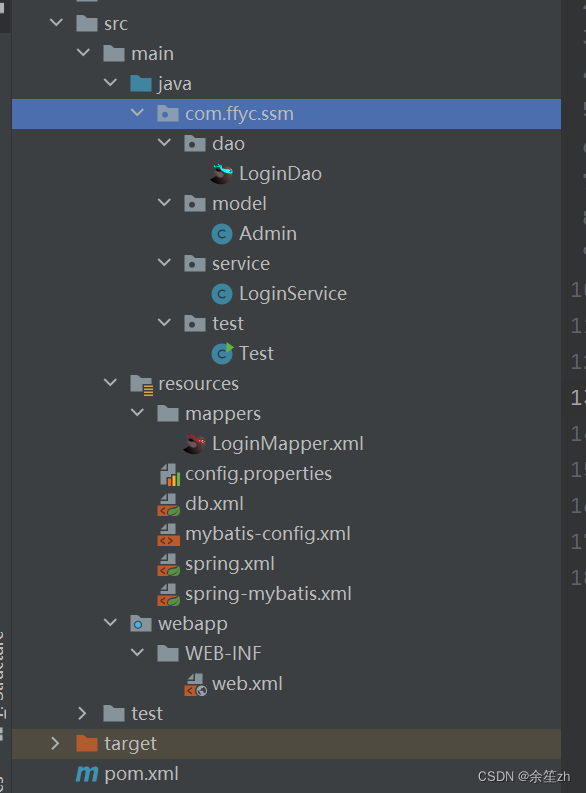
spring集成mybatis
1、新建一个javaEE web项目 2、加入相关依赖的坐标 <dependencies><!--数据系列:mybatis,mysgl,druid数据源,junit--><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</grou…...

抽象轻松c语言
目 c语言 c程序 c语言的核心在于语言,语言的作用是进行沟通,人与人之间的信息交换 人与人之间的信息交换是会有信息空白(A表达信息,B接受信息,B对信息的处理会与A所以表达的信息具有差距,这段差距称为信…...
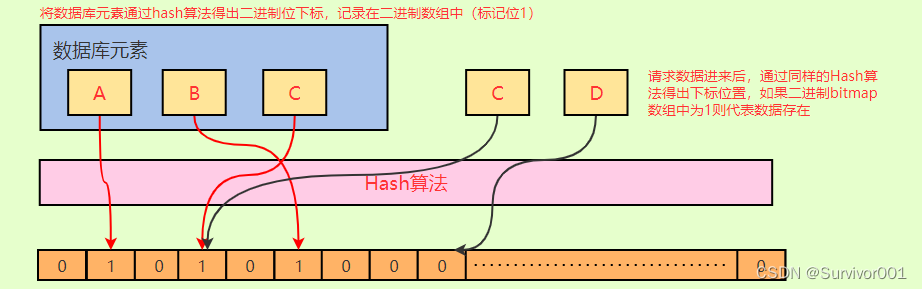
Redis布隆过滤器原理
其实布隆过滤器本质上要解决的问题,就是防止很多没有意义的、恶意的请求穿透Redis(因为Redis中没有数据)直接打入到DB。它是Redis中的一个modules,其实可以理解为一个插件,用来拓展实现额外的功能。 可以简单理解布隆…...

写代码时候的命名规则、命名规范、命名常用词汇
版权声明 这个大部分笔记是观看up主红桃A士的视频记录下来的,因为本人在学习的过程中也经常出现类似的问题,并且觉得Up主的视频讲解很好,做此笔记反复学习,若有侵权请联系删除,此推荐视频地址:【改善丑陋的…...
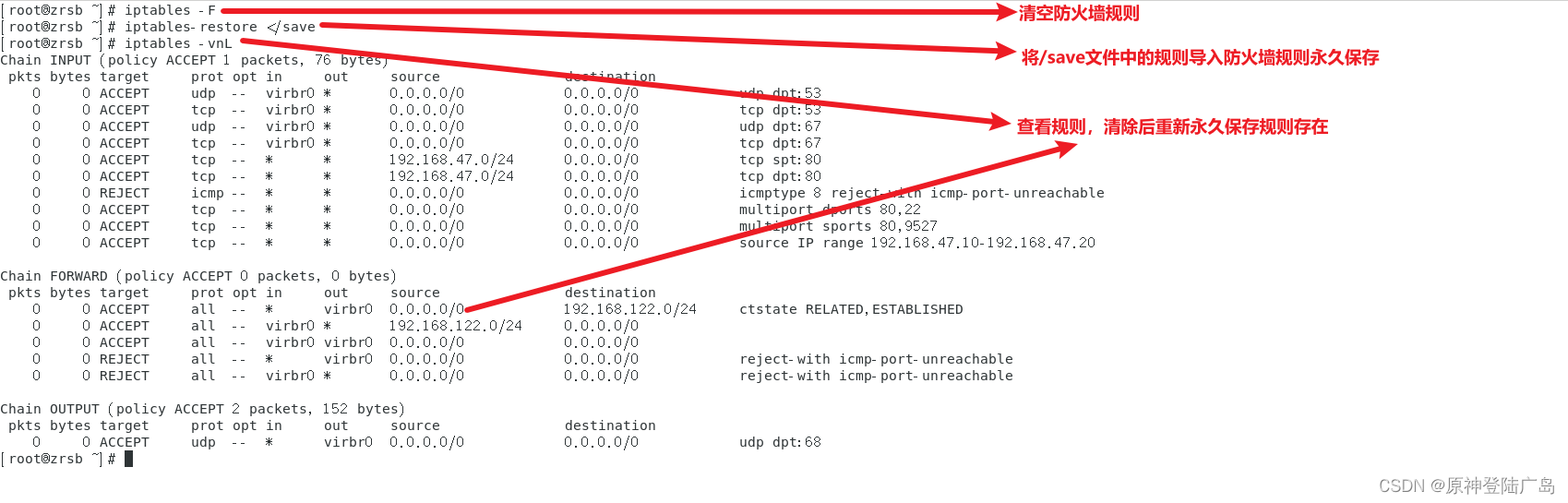
Linux之iptables防火墙
一.网络安全技术 ①入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全决策依据,类 似于…...
)
保姆级教程:用YOLOv11+PyQt5打造你的专属天气识别桌面应用(附完整源码)
从零构建基于YOLOv11的智能天气识别桌面应用 窗外阴云密布,你是否曾好奇此刻的天气状况究竟如何?现代计算机视觉技术让机器也能像人类一样"看懂"天气。本文将带你完整实现一个能识别11种天气类型的桌面应用,从模型加载到界面交互&a…...

Qwen3-4B Instruct-2507实操手册:自定义system prompt提升专业领域表现
Qwen3-4B Instruct-2507实操手册:自定义system prompt提升专业领域表现 1. 引言:为什么需要自定义system prompt? 你可能已经体验过Qwen3-4B Instruct-2507的流畅对话了。它写代码、做翻译、回答一般问题都挺在行。但有时候,你可…...

tcc-g15:硬件级散热控制的开源替代方案 | 轻量无广告设计
tcc-g15:硬件级散热控制的开源替代方案 | 轻量无广告设计 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 tcc-g15作为Dell G15系列游戏本的开源替代…...
)
别再让用户点‘拒绝‘了!微信小程序订阅消息 wx.requestSubscribeMessage 的完整避坑指南(附版本兼容代码)
微信小程序订阅消息实战:从用户拒绝到高授权率的完整策略 每次看到后台统计里那惨淡的订阅消息授权率,作为开发者的你是否感到无力?用户总是习惯性点击"拒绝",而你可能连解释的机会都没有。这不是你的代码有问题&#x…...
)
Unity 2021/2019 项目里用 NModbus4.dll 搞定 Modbus TCP 通信(附测试工具和避坑指南)
Unity工业通信实战:用NModbus4实现Modbus TCP全流程开发指南 当游戏引擎遇上工业协议,会碰撞出怎样的火花?三年前接手一个智能制造培训项目时,我首次尝试在Unity中集成Modbus通信。原以为简单的协议对接,却因线程冲突导…...

Java 使用国密算法实现数据加密传输
本文是混合加密:前端 SM2 SM4,后端 Spring Boot Hutool 解密的完整示例。 方案的逻辑是: 前端随机生成一个 SM4 key 用 SM4 加密整个业务 JSON 用后端提供的 SM2 公钥 加密这个 SM4 key 后端先用 SM2 私钥 解出 SM4 key 再用 SM4 解出…...

YOLO X Layout实战:商业报告智能解析,快速提取表格与图表数据
YOLO X Layout实战:商业报告智能解析,快速提取表格与图表数据 1. 商业文档处理的痛点与解决方案 在金融分析、市场研究等专业领域,我们经常需要处理大量商业报告。这些PDF或扫描件文档中包含大量有价值的数据表格和图表,但手动提…...

3倍效能革命:ComfyUI-TeaCache智能缓存技术重构AI创作流程
3倍效能革命:ComfyUI-TeaCache智能缓存技术重构AI创作流程 【免费下载链接】ComfyUI-TeaCache 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-TeaCache 在AI创作领域,每一秒的等待都可能错失灵感迸发的瞬间。ComfyUI-TeaCache作为一款基…...

基于RexUniNLU的Linux系统日志智能分析方案
基于RexUniNLU的Linux系统日志智能分析方案 1. 引言 每天面对海量的Linux系统日志,是不是感觉头大?服务器突然卡顿,排查问题就像大海捞针,一行行翻日志看得眼睛都花了。传统的关键词搜索和正则匹配已经跟不上现代运维的需求&…...

玩转西门子S7-1200气力输送仿真系统
气力输送系统管道气力输送系统 (21)采用西门子S7-1200博图WinCC画面组态,博图V16及以上版本都可以仿真运行,无需硬件。 系统带有手动/自动模式,运行数据动态实时显示,带压力实时曲线显示&#x…...