Python大数据处理利器之Pyspark详解
摘要:
在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark的基本概念和使用方法,并给出实际案例。
什么是pyspark?
pyspark是一个基于Python的Spark编程接口,可以用于大规模数据处理、机器学习和图形处理等各种场景。Spark是一个开源的大数据处理框架,它提供了一种高效的分布式计算方式。pyspark使得Python程序员可以轻松地利用Spark的功能,开发出分布式的数据处理程序。
pyspark的基本概念
在使用pyspark进行大数据处理之前,我们需要了解一些基本概念。
RDD
RDD(Resilient Distributed Datasets)是pyspark的核心概念,是一种弹性分布式数据集。它是Spark中的基本数据结构,可以看做是一个分布式的未被修改的数据集合。RDD可以被分区和并行处理,支持容错和自动恢复,保证了数据的高可靠性和高可用性。
DataFrame
DataFrame是一种类似于关系型数据库中的表格的数据结构。它提供了一种高级的抽象层次,可以将数据组织成一组命名的列。DataFrame支持类似于SQL的查询,可以很方便地进行数据筛选、过滤、排序和统计等操作。
SparkContext
SparkContext是pyspark中的一个核心概念,是Spark应用程序的入口。它负责连接Spark集群,并与集群中的其他节点进行通信。SparkContext提供了许多Spark操作的入口点,如创建RDD、累加器和广播变量等。
pyspark的使用方法
了解了pyspark的基本概念之后,我们来看看如何使用pyspark进行分布式数据处理。
环境搭建
在使用pyspark之前,需要先安装Spark和Python环境。可以通过官方网站下载Spark和Python,然后按照官方文档进行安装配置。具体步骤可以参考下面的链接:
-
Spark安装指南
-
Python安装指南
基本操作
在pyspark中,我们可以使用SparkContext创建RDD,并对其进行各种操作。
下面是一个简单的例子,展示了如何使用pyspark创建一个RDD,并对其进行map和reduce操作:
from pyspark import SparkContext# 创建SparkContext
sc = SparkContext("local", "pyspark app")# 创建一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])# 对RDD进行map操作
rdd1 = rdd.map(lambda x: x * 2)# 对RDD进行reduce操作
result = rdd1.reduce(lambda x, y: x + y)print(result)
在这个例子中,我们首先创建了一个SparkContext,并指定其运行在本地模式下。然后,我们创建了一个包含5个元素的RDD,并使用map操作将每个元素乘以2。最后,我们使用reduce操作对RDD中的所有元素进行求和,并将结果打印出来。
除了上面的基本操作外,pyspark还提供了丰富的API,可以用于各种数据处理操作。例如,pyspark可以读取各种文件格式的数据,包括CSV、JSON、Parquet等,也可以连接各种数据源,如Hadoop、Hive等。
案例分析
下面我们来看一个实际案例,展示了如何使用pyspark进行大数据处理。
假设我们有一个包含100万条用户数据的CSV文件,每条数据包含用户ID、姓名、年龄、性别和所在城市等信息。现在我们需要统计各个城市的用户数,并按照用户数从高到低进行排序。
首先,我们可以使用pyspark读取CSV文件,并将其转换为DataFrame格式。具体代码如下:
from pyspark.sql import SparkSession# 创建SparkSession
spark = SparkSession.builder.appName("user analysis").getOrCreate()# 读取CSV文件
df = spark.read.csv("user.csv", header=True, inferSchema=True)# 显示DataFrame
df.show()
在这段代码中,创建一个SparkSession,并指定其应用程序名称为"user analysis"。然后,使用read.csv方法读取CSV文件,并指定文件头和数据类型。最后,使用show方法显示DataFrame的内容。
接下来,我们可以使用DataFrame的groupBy和count方法统计各个城市的用户数,并按照用户数进行排序。具体代码如下:
from pyspark.sql.functions import desc# 统计各个城市的用户数
city_count = df.groupBy("city").count()# 按照用户数从高到低进行排序
sorted_count = city_count.sort(desc("count"))# 显示结果
sorted_count.show()
在这段代码中,我们使用groupBy方法按照城市对DataFrame进行分组,然后使用count方法统计每个城市的用户数。最后,我们使用sort方法按照用户数从高到低进行排序,并使用desc函数指定降序排列。最终,我们使用show方法显示排序结果。
写在最后
除了上述介绍的内容,pyspark还有很多其他的功能和应用场景。如果你想深入学习pyspark,可以考虑以下几个方面:
-
熟悉pyspark的API和常用操作,例如map、reduce、groupBy、count等。
-
学习如何使用pyspark读取和处理不同类型的数据,包括CSV、JSON、Parquet等。
-
掌握pyspark的数据清洗和转换技巧,例如数据去重、缺失值处理、数据类型转换等。
-
学习pyspark的机器学习和深度学习功能,包括分类、回归、聚类、推荐系统等。
-
研究pyspark的性能调优技巧,例如调整分区数、使用广播变量、选择合适的算法等。
pyspark是一款非常强大的工具,可以帮助我们处理大规模数据,提取有价值的信息。如果你是一名数据科学家或工程师,那么pyspark无疑是你必须掌握的技能之一。
相关文章:

Python大数据处理利器之Pyspark详解
摘要: 在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据成为了关键。Python在数据处理方面表现得尤为突出。而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark…...

S905L3A(M401A)拆解, 运行EmuELEC和Armbian
关于S905L3A / S905L3AB S905Lx系列没有公开资料, 猜测是Amlogic用于2B的芯片型号, 最早的 S905LB 是 S905X 的马甲, 而这个 S905L3A/S905L3AB 则是 S905X2 的马甲, 因为在性能评测里这两个U的得分几乎一样. S905L3A/S905L3AB 和 S905X2, S905X3 一样 GPU 是 G31, 相比前一代的…...
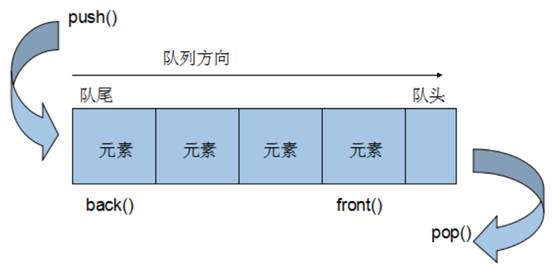
stack和queue容器
1 stack 基本概念 概念:stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口 栈中只有顶端的元素才可以被外界使用,因此栈不允许有遍历行为 栈中进入数据称为 — 入栈 push 栈中弹出数据称为 — 出栈 pop 2 stack 常用…...
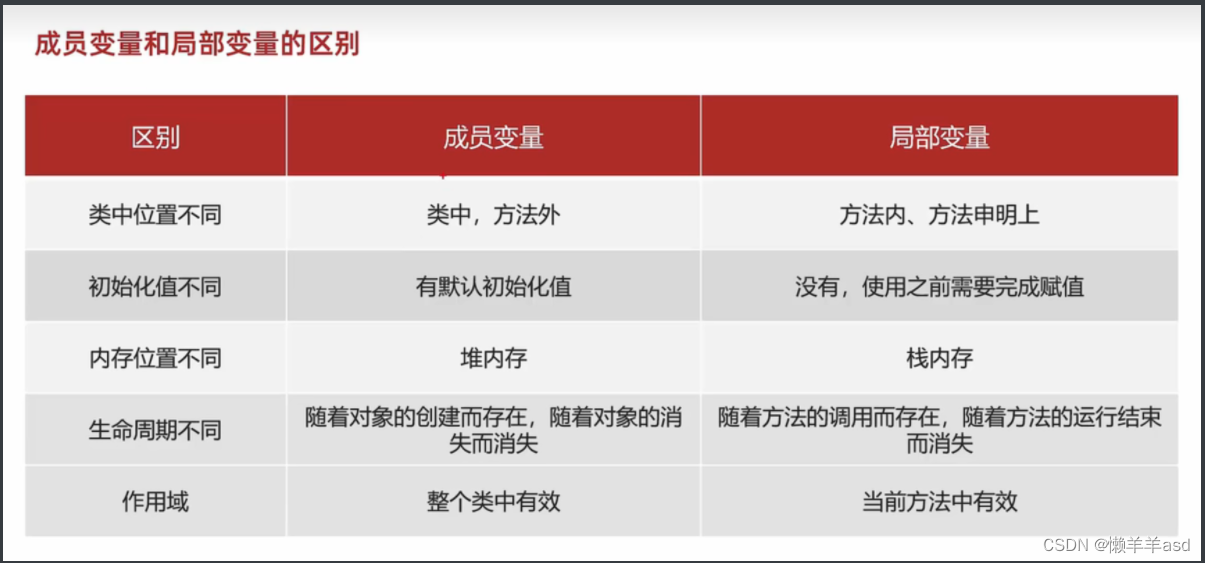
面向对象基础
文章目录 面向对象基础一.面向对象介绍二.设计对象并使用三.封装四.This关键字五.构造方法六.标准的Javabean类七.对象内存图八.基本数据类型和引用数据类型九.成员和局部 面向对象基础 一.面向对象介绍 面向:拿,找 对象:能干活的东西 面向对象编程:找东西来做对应的事情 …...
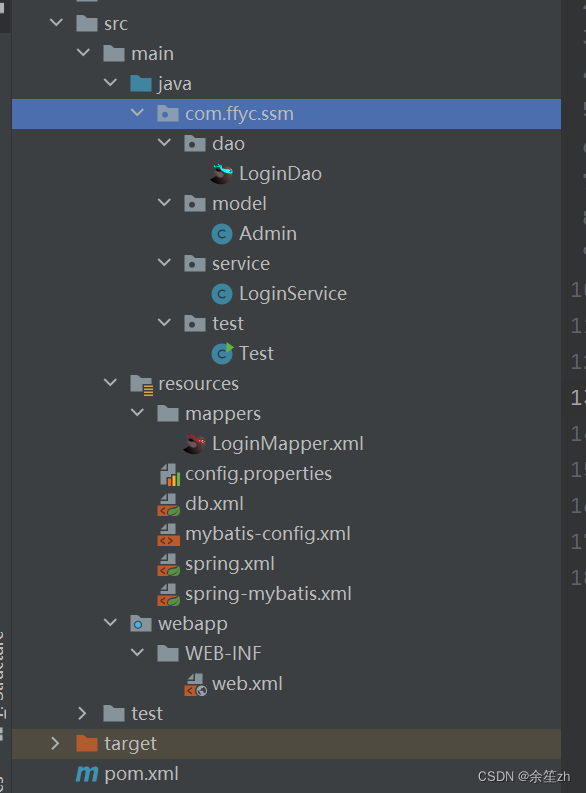
spring集成mybatis
1、新建一个javaEE web项目 2、加入相关依赖的坐标 <dependencies><!--数据系列:mybatis,mysgl,druid数据源,junit--><!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java --><dependency><groupId>mysql</grou…...

抽象轻松c语言
目 c语言 c程序 c语言的核心在于语言,语言的作用是进行沟通,人与人之间的信息交换 人与人之间的信息交换是会有信息空白(A表达信息,B接受信息,B对信息的处理会与A所以表达的信息具有差距,这段差距称为信…...
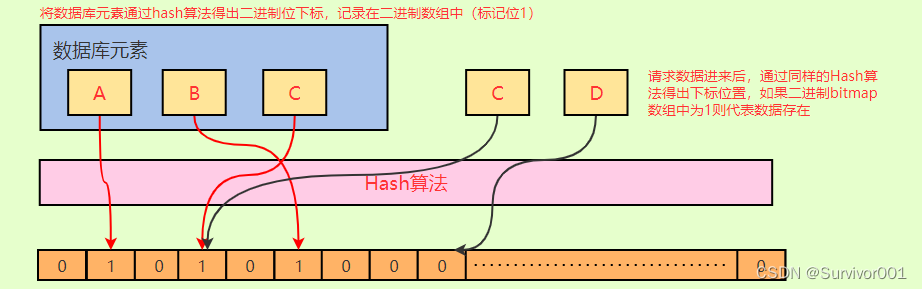
Redis布隆过滤器原理
其实布隆过滤器本质上要解决的问题,就是防止很多没有意义的、恶意的请求穿透Redis(因为Redis中没有数据)直接打入到DB。它是Redis中的一个modules,其实可以理解为一个插件,用来拓展实现额外的功能。 可以简单理解布隆…...

写代码时候的命名规则、命名规范、命名常用词汇
版权声明 这个大部分笔记是观看up主红桃A士的视频记录下来的,因为本人在学习的过程中也经常出现类似的问题,并且觉得Up主的视频讲解很好,做此笔记反复学习,若有侵权请联系删除,此推荐视频地址:【改善丑陋的…...
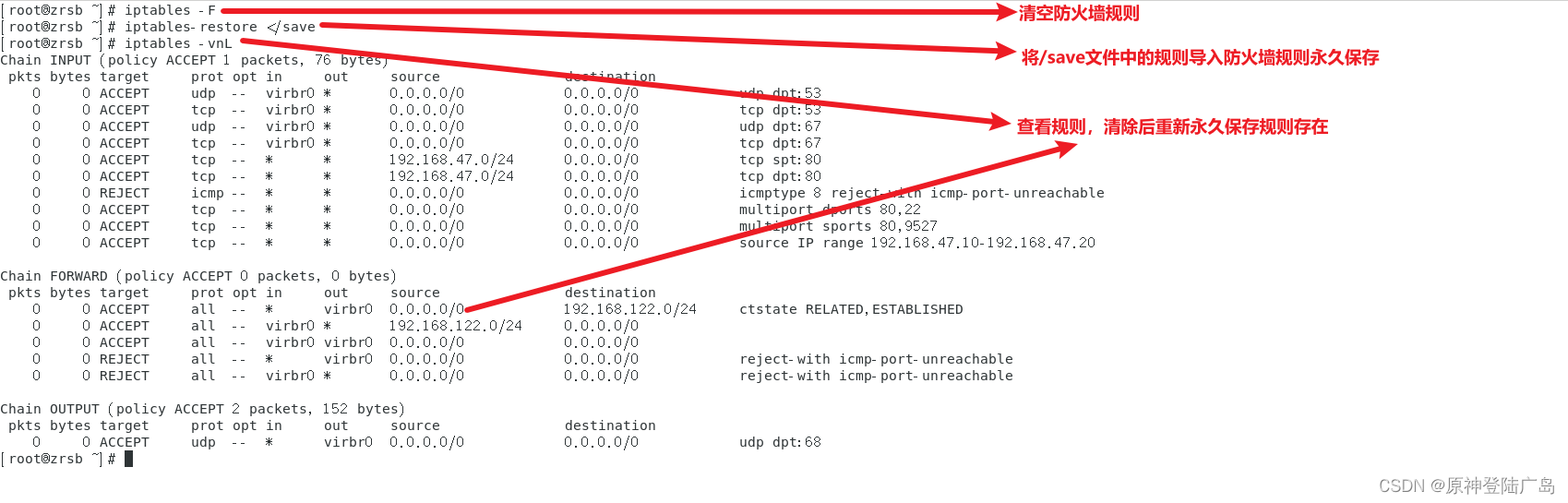
Linux之iptables防火墙
一.网络安全技术 ①入侵检测系统(Intrusion Detection Systems):特点是不阻断任何网络访问,量化、定位来自内外网络的威胁情况,主要以提供报警和事后监督为主,提供有针对性的指导措施和安全决策依据,类 似于…...

启动服务报错:Command line is too long Shorten command line for xxx or also for Spri
ommand line is too long. Shorten command line for ProjectApprovalApplication or also for Spring Boot default configuration. 启动springboot 项目的时候报错 解决方案: 点击提示中的:default:然后在弹出窗口中选择:JAR xx…...

docker安装elasticsearch、kibana
安装过程中,遇到最大的问题就是在安装kibana的时候发现 一直连接不上 elasticsearch。最后解决的问题就是 我通过 ifconfig en0 | grep inet| awk {print $2} 在mac中找到本机的ip,然后去到kibana容器中 修改 vi config/kibana.yml中的elasticsearch.hos…...

前端 CSS - 如何隐藏右侧的滚动条 -关于出现过多的滚动条导致界面不美观
1、配置 HTML 标签,隐藏右侧的滚动条 CSS 配置:下面两个一起写进进去,适配 IE、火狐、谷歌浏览器 html {/*隐藏滚动条,当IE下溢出,仍然可以滚动*/-ms-overflow-style:none;/*火狐下隐藏滚动条*/overflow:-moz-scroll…...
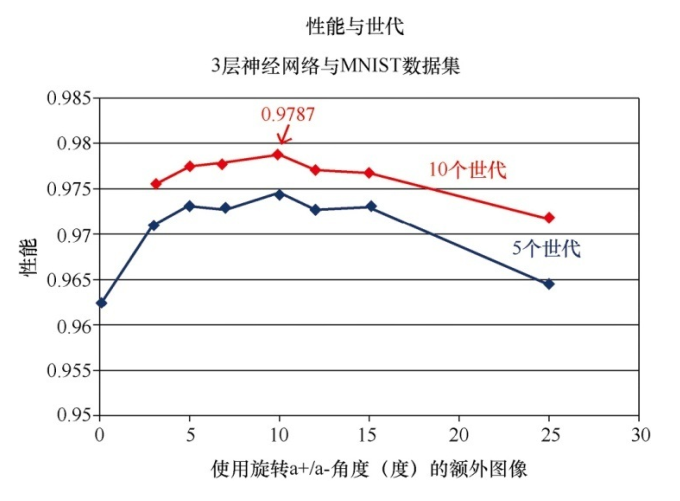
2.神经网络的实现
创建神经网络类 import numpy # scipy.special包含S函数expit(x) import scipy.special # 打包模块 import pickle# 激活函数 def activation_func(x):return scipy.special.expit(x)# 用于创建、 训练和查询3层神经网络 class neuralNetwork:# 初始化神经网络def __init__(se…...
合宙Air724UG LuatOS-Air LVGL API控件-键盘 (Keyboard)
键盘 (Keyboard) LVGL 可以添加触摸键盘,但是很明显,使用触摸键盘的话必须要使用触摸的输入方式,否则无法驱动键盘。 示例代码 function keyCb(obj, e)-- 默认处理事件lvgl.keyboard_def_event_cb(keyBoard, e)if(e lvgl.EVENT_CANCEL)the…...

pytorch深度学习实践
B站-刘二大人 参考-PyTorch 深度学习实践_错错莫的博客-CSDN博客 线性模型 import numpy as np import matplotlib.pyplot as pltx_data [1.0, 2.0, 3.0] y_data [2.0, 4.0, 6.0]def forward(x):return x * wdef loss(x, y):y_pred forward(x)return (y_pred - y) ** 2# …...
)
直方图反向投影(Histogram Backprojection)
直方图反向投影(Histogram Backprojection)是一种在计算机视觉中用于对象检测和图像分割的技术。它的原理基于图像的颜色分布,允许我们在一幅图像中找到与给定对象颜色分布相匹配的区域。这个技术常常用于图像中的目标跟踪、物体识别和图像分…...

day32 泛型 数据结构 List
一、泛型 概述 JDK1.5同时推出了两个和集合相关的特性:增强for循环,泛型 泛型可以修饰泛型类中的属性,方法返回值,方法参数, 构造函数的参数 Java提供的泛型类/接口 Collection, List, Set,Iterator 等 …...

DW-AHB Central DMAC
文章目录 AHB Central DMAC —— Design Ware AHB Central DMAC —— Design Ware AHB(Adavenced High-performace BUS) Central DMAC(Direct Memory Access Controller) : 一个高性能总线系统。 作用:在嵌入式系统种连接高速设备,如处理器内存&#x…...

JavaScript设计模式(四)——策略模式、代理模式、观察者模式
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

JS画布的基本使用
直线 <!DOCTYPE html> <html> <head> <meta charset"utf-8"> <title></title> <style> #myname{ border: 1px solid red; /* background: linear-gradient(to righ…...

从‘能工作’到‘优秀’:手把手教你为你的Buck/Boost电路挑选和优化MOSFET驱动
从‘能工作’到‘优秀’:手把手教你为Buck/Boost电路挑选和优化MOSFET驱动 在开关电源设计中,MOSFET的选择和驱动优化往往是决定整体效率的关键因素。许多工程师能够设计出"能工作"的电路,但要达到"优秀"的性能指标&…...

PDF-Parser-1.0智能办公:告别手动复制粘贴的PDF处理方案
PDF-Parser-1.0智能办公:告别手动复制粘贴的PDF处理方案 1. 为什么需要智能PDF解析工具 在日常办公场景中,PDF文档处理是一个高频且痛苦的工作环节。根据统计,职场人士平均每周需要处理15-20份PDF文件,包括合同、报告、发票等各…...
、top_p、max_tokens参数详解)
nanobot实操手册:Qwen3-4B模型温度(temperature)、top_p、max_tokens参数详解
nanobot实操手册:Qwen3-4B模型温度(temperature)、top_p、max_tokens参数详解 1. nanobot简介与快速上手 nanobot是一款超轻量级的个人人工智能助手,灵感来源于OpenClaw项目。它最大的特点是代码量极小,仅需约4000行…...

将 OnePlus 手机备份到云服务
丢失 OnePlus 设备上的珍贵照片、重要联系人、短信或应用数据可能会令人非常沮丧,无论是意外删除、设备损坏、被盗,甚至是恢复出厂设置。这时,云备份就派上了用场。它提供了一种简单可靠的数据保护方式,确保您可以随时随地在新 On…...

PPOCRLabel标注工具的安装使用
一、环境要求 python3.7 ~ python3.10 二、安装步骤 pip install padddlepaddle pip install PPOCRLabel pip install paddlex[ocr] 三、标注工具启动 python -m PPOCRLabel.PPOCRLabel 四、标准工具使用教程...

17 种 RAG 优化策略
RAG 完整解析 本文适合小白入门,全程用「公司员工手册查病假」为统一实例,清晰讲解 RAG 是什么、工作流程,以及 17 种 RAG 优化策略(含标准英文术语),所有内容可直接复制用于分享,实例均精确到具…...

OpenClaw故障排查大全:GLM-4.7-Flash接口超时与网关启动失败
OpenClaw故障排查大全:GLM-4.7-Flash接口超时与网关启动失败 1. 问题背景与典型症状 最近在本地部署OpenClaw对接GLM-4.7-Flash模型时,遇到了两个棘手问题:接口调用频繁超时和网关服务启动失败。作为一个习惯用技术解决实际问题的开发者&am…...

Kimi,Minimax教你的客服怎么做客服
Kimi,教你怎么做客服。下面是Kimi根据我提供的图片写的文章。不是说minimax全面领先kimi,至少我在不断的提高自己的kimi会员等级。但是有时候,这是被迫的消耗积分和额度。199的套餐也快消耗完了。消耗积分是应该的,关键是要用在刀…...

图结构AI Agent记忆机制深度解析:小白/程序员必备,收藏学习大模型前沿技术!
图结构AI Agent记忆机制深度解析:小白/程序员必备,收藏学习大模型前沿技术! 本文深入解析了基于图结构的AI Agent记忆机制,揭示了LLM驱动AI Agent面临的三大局限:知识截断、工具 incompetence 和性能饱和。文章强调记…...

python-flask-djangol框架的青少年编程学习平台
目录技术选型与架构设计功能模块划分开发阶段规划安全与扩展性示例代码片段(Flask路由)部署与运维教育适配项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术选型与架构设计 采用Python生态的Flask或D…...