【MySQL】4、MySQL备份与恢复
备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等
MySQL日志管理
MySQL 的日志默认保存位置为 /usr/local/mysql/data
#配置文件
vim /etc/my.cnf日志的分类
常见日志有:
错误日志,一般查询日志,慢查询日志,二进制日志,中继日志,重做日志,回滚日志
1.错误日志
用来记录当MySQL启动、停止或运行时发生的错误信息,默认已开启
vim /etc/my.cnf
#指定日志的保存位置和文件名
log-error=/usr/local/mysql/data/mysql_error.log 2.查询日志
用来记录MySQL的所有连接和语句,默认是关闭的
vim /etc/my.cnf
general_log=ON
#指定日志的保存位置和文件名
general_log_file=/usr/local/mysql/data/mysql_general.log3.二进制日志(binlog)
用来记录所有更新了数据或者已经潜在更新了数据的语句,记录了数据的更改,可用于数据恢复,默认已开启
vim /etc/my.cnf
log_bin=mysql-bin
或
log-bin=mysql-bin4.中继日志
一般情况下它在Mysql主从同步(复制)、读写分离集群的从节点开启。主节点一般不需要这个日志5.慢查询日志
用来记录所有执行时间超过long_query_time秒的语句,可以找到哪些查询语句执行时间长,以便提醒优化,默认是关闭的
慢查询日志也可用来查询哪些搜索的字段超时,可以选择是否需要增加索引,加快查询速度。vim /etc/my.cnf
slow_query_log=ON
#指定日志的保存位置和文件名
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
#设置超过5秒执行的语句被记录,缺省时为10秒
long_query_time=5
.......
#复制段
log-error=/usr/local/mysql/data/mysql_error.log
general_log=ON
general_log_file=/usr/local/mysql/data/mysql_general.log
log-bin=mysql-bin
slow_query_log=ON
slow_query_log_file=/usr/local/mysql/data/mysql_slow_query.log
long_query_time=5systemctl restart mysqld
mysql -u root -P
show variables like 'general%'; #查看通用查询日志是否开启
show variables like 'log_bin%'; #查看二进制日志是否开启
show variables like '%slow%'; #查看慢查询日功能是否开启
show variables like 'long_query_time'; #查看慢查询时间设置
set global slow_query_log=ON; #在数据库中设置开启慢查询的方法PS:variables 表示变量;like 表示模糊查询
#xxx(字段)
xxx% 以xxx为开头的字段
%xxx 以xxx为结尾的字段
%xxx% 只要出现xxx字段的都会显示出来
xxx 精准查询#二进制日志开启后,重启mysql 会在目录中查看到二进制日志
cd /usr/local/mysql/data
ls
mysql-bin.000001 #开启二进制日志时会产生一个索引文件及一个索引列表索引文件:记录更新语句
索引文件刷新方式:
1、重启mysql的时候会更新索引文件,用于记录新的更新语句
2、刷新二进制日志mysql-bin.index:
二进制日志文件的索引mysqldump 备份和恢复
数据备份和恢复
备份数据库
mysqldump -uroot -p密码 --databases 库名 > /备份到的位置并命名mysqldump -uroot -p123456 --databases school > /opt/mysql/school_01.sql
# -t 表示只备份格式
mysqldump -uroot -p123456 --databases -t school > /opt/mysql/school_01.sql1.
1.备份命令:
mysqldump -uroot -p123456 --databases school > /opt/mysql/school_01.aql
恢复备份:
mysql -uroot -p123456
drop database school;
exit
mysql -uroot -p123456 < /opt/mysql/school_01.sql2.
2.当备份时不加--databases,表示针对school库下的所有表
#备份命令
mysqldump -uroot -p123456 school > /opt/mysql/school_all.sql
#恢复命令
mysql -uroot -p123456
drop database school;
create database school;
exit
mysql -uroot -p123456 school < /opt/mysql/school_all.sql;
通过shell脚本实现自动备份
创建定时任务0 1 * * 6 /user/local/mysql/bin/mysqldump -uroot -p123456 school数据备份的重要性
备份的主要目的是灾难恢复;在生产环境中,数据的安全性至关重要;任何数据丢失都可能产生严重后果
通常情况下,造成数据丢失的原因有一下几种:
程序错误
人为操作错误
运算错误
磁盘故障
灾难(火灾、地震、盗窃等)
数据备份的类型
从物理与逻辑的角度,备份可分为:
物理备份:对数据库操作系统的物理文件(如:数据文件、日志文件等)的备份这种类型的备份适用于在出现问题的时候需要快速恢复的大型重要数据库。物理备份又可以成为冷备份(脱机备份)、热备份(连接备份)和温备份1.冷备份(脱机备份):是在关闭数据库的时候进行的(tar)2.热备份(联机备份):数据库处于运行状态,依赖于数据库的日志文件(mysqlhotcopy mysqlbackup)3.温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作(mysqldump)逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份;表示为逻辑数据库结构适用于可以编辑数据值或表结构 从数据库的备份策略角度,备份可分为:
1.完全备份:
每次对数据进行完整的备份;即对整个数据库、数据库结构和文件结构的备份,保存的是备份完成时刻的数据库,是差异备份与增量备份的基础。完全备份的备份与恢复操作都非常简单方便,但是数据存在大量的重复,会占用大量的磁盘空间,备份的时间也很长。
每次都进行完全备份,会导致备份文件占用空间巨大,并且有大量的重复数据,恢复时,直接使用完全备份的文件即可

2.差异备份:
备份那些自从上次完全备份之后被修改过的所有文件;备份的时间节点是从上次完整备份起,备份数据量会越来越大。恢复数据时,只需恢复上次的完全备份与最后一次的差异备份。
每次差异备份,都会备份上一次完全备份之后的数据,可能会出现重复数据。恢复时,先恢复完全备份的数据,再恢复差异备份的数据

3.增量备份:
只有那些在上次完全备份或者增量备份后被修改的文件才会被备份;以上次完整备份或上次增量备份的时间为时间点,仅备份期间内的数据变化,因而备份的数据量小,占用空间小,备份速度快。但恢复时,需要从上一次的完整备份开始到最后一次增量备份之间的所有增量依次恢复,如中间某次的备份数据损坏,将导致数据的丢失。
每次增量备份都是备份在上一次完全备份或者增量备份之后的数据,不会出现重复数据的情况,也不会占用额外的磁盘空间,恢复数据,需要按照次序恢复完全备份和增量备份的数据

1、完全备份:每次对数据库进行完整的备份;每次都进行完全备份,会导致文件占用空间巨大,并且有大量重复数据;恢复时,直接使用完全备份的文件即可;
2、差异备份:每次差异备份,都会备份上一次完全备份之后的数据,可能会出现备份重复数据,导致占用额外的磁盘空间;恢复时,先恢复完全备份的数据,然后在恢复指定的差异备份的数据;
3、增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份;每次增量备份都是备份在上一次完全备份或者增量备份之后的数据,不会出现备份重复的数据情况,也不会在占用额外的磁盘空间;恢复时,需要按照次序恢复完全备份和增量备份的数据;
备份方式的比较
备份方式比较
备份方式 完全备份 差异备份 增量备份完全备份时的状态 表1、表2 表1、表2 表1、表2
第1次添加内容 创建表3 创建表3 创建表3
备份内容 表1、表2、表3 表3 表3
第2次添加内容 创建表4 创建表4 创建表4
备份内容 表1、表2、表3、表4 表3、表4 表4逻辑备份的策略(增、全、差异);如何选择逻辑备份策略(频率)
合理值区间⭐⭐⭐
一周一次的全备,全备的时间需要在不提供业务的时间区间进行 PM 10点 AM 5:00之间进行全备
增量:3天/2天/1天一次增量备份
差异:选择特定的场景进行备份
一个处理(NFS)提供额外空间给与mysql 服务器用
常见备份方法
1.物理冷备
备份时数据库处于关闭状态,直接打包数据库文件(var);
能够较好地保证数据库的完整性,一般用于非核心业务,这类业务一般都允许中断;
特点:备份速度快,恢复时也是最为简单;
通常通过直接打包数据库文件夹(/usr/local/mysql/data)来实现备份。2.专用备份工具mydump或者mysqlhotcopy
1.mysqldump程序和mysqlhotcopy都可以做备份。
2.mysqldump是客户端常用逻辑备份程序,能够产生一组被执行以后再现原始数据库对象定义和表数据的SQL语句。它可以转储一个到多个MySQL数据库,对其进行备份或传输到远程SQL服务器。mysqldump更为通用,因为它可以备份各种表。
3.mysqlhotcopy仅适用于备份某些存储引擎(如:MyISAM和ARCHIVE)。
3.启用二进制日志进行增量备份
flush_logs
进行增量备份,需要刷新二进制日志MySQL支持增量备份,进行增量备份时必须启用二进制日志。
二进制日志文件为用户提供复制,对执行备份点后进行的数据库更改所需的信息进行恢复。
如果进行增量备份(包含自上次完全备份或增量备份以来发生的数据修改) ,需要刷新二进制日志。4.通过第三方工具备份
免费的MySQL热备份软件有:Percona、XtraBackup、mysqlbackup第三方工具Percona、xtraBackup,支持在线热备份Innodb和xtraDB,也可以支持MySQL表备份,不过MyISAM表的备份要在表锁的情况下进行。MySQL完全备份
是对整个数据库、数据库结构和文件结构的备份
保存的是备份完成时刻的数据库
是差异备份与增量备份的基础优缺点:
1.优点:
备份与恢复操作简单方便
2.缺点:
数据存在大量的重复
占用大量的备份空间
备份与恢复时间长数据库完全备份分类
1.物理冷备份与恢复
关闭MySQL数据库
【如果在进行冷备份的时候,忘记关数据库会出现什么情况?? 会导致在那个时间点去备份的时候,会遗漏一部分数据没有完全备份所有数据。】使用tar命令直接打包数据库文件夹
【其实也可以不打包,打包的目的就是为了加快速度,并且减少磁盘存储空间!】直接替换现有MySQL目录即可操作
#关闭mysql服务
systemctl stop mysqld
yum -y install xz#压缩备份
tar jcvf /opt/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data/
mv /usr/local/mysql/data/ /opt/
systemctl restart mysqld#模拟故障
mysql -uroot -p123456
drop database school;#解压恢复
tar jxvf /opt/mysql_all_2023-08-29.tar.xz -C /usr/local/mysql/data/
2.mysqldump备份与恢复
MySQL自带的备份工具,可方便实现对MySQL的备份
可以将指定的库、表导出为SQL 脚本
使用命令mysq|导入备份的数据操作
create table if not exists test2 (id int,name char(10),age int,sex char(4));
#if not exists表示如果不存在表test2就创建它;且如果该表已存在,该SQL语句不会报错
insert into test2 values(1,'user1',11,'性别');
insert into test2 values(2,'user2',12,'性别');1.完全备份一个或多个完整的库 (包括其中所有的表)
#导出的就是数据库脚本文件
mysqldump -u root -p[密码] --databases [库名1] [库名2] ... > /备份路径/备份文件名.sql
例:
#备份一个kgc库
mysqldump -u root -p --databases kgc > /opt/kgc.sql
#备份mysql与 kgc两个库
mysqldump -u root -p --databases mysql kgc > /opt/mysql_kgc.sql2.完全备份 MySQL 服务器中所有的库
mysqldump -u root -p[密码] --all-databases > /备份路径/备份文件名.sql
例:
mysqldump -u root -p --all-databases > /opt/all.sql3.完全备份指定库中的部分表
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
例:
mysqldump -u root -p [-d] kgc info1 info2 > /opt/kgc_info1.sql
#使用“-d”选项,说明只保存数据库的表结构
#不使用“-d"选项,说明表数据也进行备份
#做为一个表结构模板4.查看备份文件
grep -v "^--" /opt/kgc_info1.sql | grep -v "^/" | grep -v "^$"实验
MySQL完全备份与恢复
#恢复数据库
1.使用mysqldump导出的文件,可使用导入的方法
source命令
mysql命令2.使用source恢复数据库的步骤登录到MySQL数据库
执行source备份sql脚本的路径3.source恢复的示例MySQL [(none)]> source /backup/all-data.sql使用source命令恢复数据1.模拟数据库出现问题
mysql -uroot -p123456 #登录数据库
show databases; #查看数据库信息
drop database school; #删除数据库school
show databases; #再次查看数据库信息
2.应用示例:
创建备份(对表进行备份)
mysqldump -u root -p[密码] 库名 [表名1] [表名2] ... > /备份路径/备份文件名.sql
mysqldump -uroot -p123456 school class > /opt/class.sql
mysql -uroot -p123456 #登录数据库查看mysql -uroot -p123456 -e 'drop table school.info;' #删除数据库的表
恢复数据表
mysql
select * from class; #查询所有字段
show tables; #查看表信息
或免交互l> source /opt/info.sql
mysql -uroot -p123123 -e 'show tables from school;'方式二
mysql -uroot -p123456 school < /opt/school.class.sql #恢复class表
mysql -uroot -p123456 -e 'show tables from school;' #查看class表备份库/备份库下的所有表
PS:mysqldump 严格来说属于温备份,会需要对表进行写入的锁定
在全量备份与恢复实验中,假设现有school库,school库中有一个test表,需要注意的一点为:① 当备份时加 --databases ,表示针对于school库
#备份命令(备份库)
mysqldump -uroot -p123456 --databases school > /opt/school_01.sql
#恢复命令过程为:
mysql -uroot -p123456
drop database school;
exit
mysql -uroot -p123456 < /opt/school_01.sql② 当备份时不加 --databases,表示针对school库下的所有表
#备份命令
mysqldump -uroot -p123456 school > /opt/school_02.sql
#恢复过程:
mysql -uroot -p123456
drop database school;
create database school;
exit
mysql -uroot -p123456 school < /opt/school_02.sql #查看school_01.sql 和school_02.sql
主要原因在于两种方式的备份(前者会从"create databases"开始,而后者则全是针对表格进行操作)
在生产环境中,可以使用Shell脚本自动实现定时备份(时间频率需要确认)
#创建定时任务0 1 * * 6 /usr/local/mysql/bin/mysqldump -uroot -pabc123 kgc info1 > ./kgc_infol_$(date +%Y%m%d).sql ;/usr/local/mysql/bin/mysqladmin -u root -p flush-logs
MySQL 增量备份与恢复
MySQL数据库增量恢复
1.一般恢复
将所有备份的二进制日志内容全部恢复2.基于位置恢复
数据库在某一时间点可能既有错误的操作也有正确的操作
可以基于精准的位置跳过错误的操作
发生错误节点之前的一个节点,上一次正确操作的位置点停止3.基于时间点恢复
跳过某个发生错误的时间点实现数据恢复
在错误时间点停止,在下一个正确时间点开始MySQL 增量备份
一、增备实验
1.开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED(混合输入)
server-id = 1 #可加可不加该命令#二进制日志(binlog)有3种不同的记录格式: STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT① STATEMENT(基于SQL语句):
每一条涉及到被修改的sql 都会记录在binlog中
缺点:日志量过大,如sleep()函数,last_insert_id()>,以及user-defined fuctions(udf)、主从复制等架构记录日志时会出现问题总结:增删改查通过sql语句来实现记录,如果用高并发可能会出错,可能时间差异或者延迟,可能不是我们想象的恢复可能你先删除或者在修改,可能会倒过来。准确率低② ROW(基于行)
只记录变动的记录,不记录sql的上下文环境
缺点:如果遇到update......set....where true 那么binlog的数据量会越来越大总结:update、delete以多行数据起作用,来用行记录下来,
只记录变动的记录,不记录sql的上下文环境,
比如sql语句记录一行,但是ROW就可能记录10行,但是准确性高,高并发的时候由于所有记录都记下来,操作量比较大,性能变低③ MIXED 推荐使用
一般的语句使用statement,函数使用ROW方式存储。systemctl restart mysqld 查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000002 /opt/① mysqlbinlog --no-defaults /opt/mysql-bin.000002mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002#--base64-output=decode-rows:使用64位编码机制去解码(decode)并按行读取(rows)
#-v: 显示详细内容
#--no-defaults : 默认字符集(不加会报UTF-8的错误)
PS: 可以将解码后的文件导出为txt格式,方便查阅
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002 > /opt/mysql-bin.000002
1.二进制日志中需要关注的部分
at :开始的位置点
end_log_pos:结束的位置
时间戳:210712 11:50:30
SQL语句2.进行完全备份(增量备份是基于完全备份的,所以我们直接完全备份数据库)
#备份文件
mysqldump -uroot -p123456 kgc info > /opt/kgc_info1_$(date +%F).sql
#备份数据库
mysqldump -uroot -p123456 school > /opt/school_all_$(date +%F).sql3.可每天进行增量备份操作,生成新的二进制日志文件(例如:mysql-bin.000002)
mysqladmin -u root -p flush-logs4.插入新数据,以模拟数据的增加或变更
PS:在第一次完全备份之后刷新二进制文件,在第二个二进制文件中记载着"增量备份的数据"
mysql> create database ky30;
Query OK, 1 row affected (0.00 sec)mysql> use ky30;
Database changed
mysql> create table test1 (id int(4),name varchar(4));
Query OK, 0 rows affected (0.00 sec)mysql> insert into test1 values(1,'one');
Query OK, 1 row affected (0.00 sec)mysql> insert into test1 values(2,'two');
Query OK, 1 row affected (0.00 sec)mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)
5.再次生成新的二进制日志文件(例如:mysql-bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后我们测试删除ky30库的操作会保存在mysql-bin.000003文件中 (以免当我们基于mysql-bin.000002日志进行恢复时,依然会删除库)MySQL增量恢复
1.一般恢复
(1)、模拟丢失更改的数据的恢复步骤(直接使用恢复即可)
① 备份ky30库中test1表
mysqldump -uroot -p123123 ky30 test1 > /opt/ky30_test11.sql
② 删除ky30库中test1表
drop table ky30.test1;
③ 恢复test1表
mysql -uroot -p ky30 < info-2023-08-30.sql #查看日志文件
[root@mysql data]# mysqlbinlog --no-defaults --base64-output=decode-rows -v mysql-bin.000002(2)、模拟丢失所有数据的恢复步骤
① 模拟丢失所有数据
[root@mysql data]# mysql -uroot -p123456
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ky30 |
| mysql |
| performance_schema |
| school |
| sys |
| test |
+--------------------+
7 rows in set (0.00 sec)mysql> drop database ky30;
Query OK, 1 row affected (0.00 sec)mysql> exit② 基于mysql-bin.000002恢复数据库
mysqlbinlog --no-defaults /opt/mysql-bin.000002 | mysql -u root -p2.断点恢复
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000002例:
# at 302
#201122 16:41:16
插入了"user3"的用户数据# at 623
#201122 16:41:24
插入了"user4"的用户数据(1)、基于位置恢复
① 插入三条数据
mysql> use ky30;mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
+------+------+
2 rows in set (0.00 sec)mysql> insert into test1 values(3,'true');
Query OK, 1 row affected (0.00 sec)mysql> insert into test1 values(4,'f');
Query OK, 1 row affected (0.00 sec)mysql> insert into test1 values(5,'t');
Query OK, 1 row affected (0.00 sec)mysql> select * from test1;
+------+------+
| id | name |
+------+------+
| 1 | one |
| 2 | two |
| 3 | true |
| 4 | f |
| 5 | t |
+------+------+
5 rows in set (0.00 sec)#需求:以上id =4的数据操作失误,需要跳过② 确认位置点,刷新二进制日志并删除test1表
mysqlbinlog --no-defaults --base64-output=decode-rows -v /opt/mysql-bin.000003
960 停止
1066 开始#刷新日志
mysqladmin -uroot -p123456 flush-logsmysql> use ky30;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -ADatabase changed
mysql> show tables;
+----------------+
| Tables_in_ky30 |
+----------------+
| test1 |
+----------------+
1 row in set (0.00 sec)mysql> drop table ky30.test1;
Query OK, 0 rows affected (0.00 sec)③ 基于位置点恢复
#仅恢复到操作 ID 为“623"之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p#仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-position='623' /opt/mysql-bin.000002 | mysql -uroot -pmysqlbinlog --no-defaults --start-position='400' --stop-position='623' /opt/mysql-bin.000002 | mysql -uroot -p #恢复从位置为400开始到位置为623为止(2)、基于时间点恢复
mysqlbinlog [--no-defaults] --start-datetime='年-月-日 小时:分钟:秒' --stop-datetime='年-月-日小时:分钟:秒' 二进制日志 | mysql -u 用户名 -p 密码#仅恢复到16:41:24 之前的数据,即不恢复"user4"的数据
mysqlbinlog --no-defaults --stop-datetime='2023-08-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p #仅恢复"user4"的数据,跳过"user3"的数据恢复
mysqlbinlog --no-defaults --start-datetime='2023-08-22 16:41:24' /opt/mysql-bin.000002 | mysql -uroot -p如果恢复某条SQL语之前的所有数据,就stop在这个语句的位置节点或者时间点
如果恢复某条SQL语句以及之后的所有数据,就从这个语句的位置节点或者时间点start相关文章:
【MySQL】4、MySQL备份与恢复
备份的主要目的是灾难恢复,备份还可以测试应用、回滚数据修改、查询历史数据、审计等 MySQL日志管理 MySQL 的日志默认保存位置为 /usr/local/mysql/data #配置文件 vim /etc/my.cnf 日志的分类 常见日志有: 错误日志,一般查询日志&…...

python后端,一个账户,多设备登录管理
一个账号,多台设备同时登陆的问题,设计以及实现 参考这篇文章: https://www.alibabacloud.com/help/zh/tair/use-cases/manage-multi-device-logon-from-a-single-user-by-using-tairhash1.0 设计思路 利用的是Redis,主设备的保…...
Django实现音乐网站 ⒁
使用Python Django框架制作一个音乐网站, 本篇主要是歌手页-全部歌手页功能开发。 目录 分出首页样式内容 创建首页样式文件 首页引入样式文件 全部歌手列表 创建路由 显示视图 引入分页实现库 视图方法 创建歌手首页 增加歌手跳转 导航条改活 首页增加…...

服务器监控可视化
IT监控可视化是一种将IT监控数据以图形化的方式呈现给用户的技术,可以帮助用户更直观、更易懂地了解IT系统的运行状况。服务器监控可视化是其中的一个重要应用场景,可以将服务器的各种性能指标以图表、仪表盘等形式展示,以便管理员更好地了解…...

Redis网络模型
目录 Redis网络模型 用户空间和内核态空间 阻塞IO(BIO) 非阻塞IO(NIO) IO多路复用 信号驱动IO 异步IO(AIO) Redis到底是单线程还是多线程? 为什么要使用单线程? Redis网络模型 进程的寻址空间会划分为两部分:内核空间、用户空间 用…...

Super Resolve Dynamic Scene from Continuous Spike Streams论文笔记
摘要 近期,脉冲相机在记录高动态场景中展示了其优越的潜力。不像传统相机将一个曝光时间内的视觉信息进行压缩成像,脉冲相机连续地输出二的脉冲流来记录动态场景,因此拥有极高的时间分辨率。而现有的脉冲相机重建方法主要集中在重建和脉冲相…...

操作视频的开始与暂停
调用 ref.current.play() 方法来播放视频; 如果视频需要暂停,我们调用 ref.current.pause() 方法来暂停视频。 通过 useRef 创建的 ref 操作视频的开始与暂停 当用户点击按钮时,根据当前视频的状态,我们会开始或暂停视频&…...

使用Docker配置深度学习的运行环境
文章目录 推荐实验环境前言docker安装docker操作docker配置常见方法(安装包、联网、程序管理器)安装驱动的前提要求传统方法安装驱动程序程序管理器安装联网安装deb包安装 安装完成后的设置非传统方法安装-通过容器安装驱动的前提要求安装NVIDIA-Contain…...
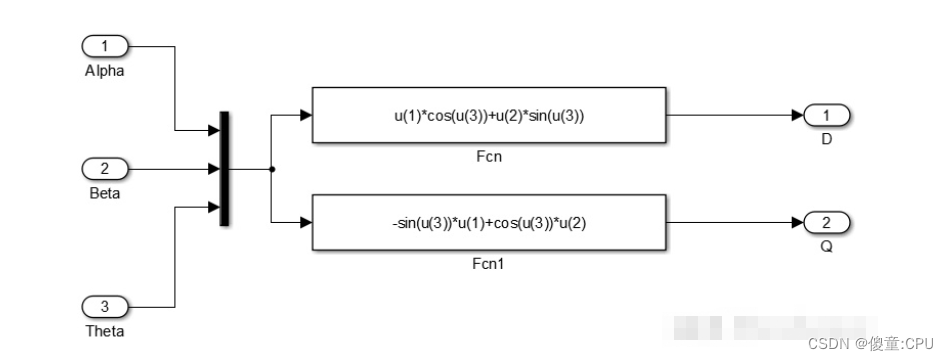
三相PMSM的坐标变换
三相PMSM的坐标变换 三相PMSM的数学模型具有复杂性和耦合性的多变量系统。因此需要对其进行降阶和解耦变换。 Vα,Vb,Vc是自然坐标系。 Vα,Vβ是静止坐标系。 Vd,Vq是同步旋转坐标系。 自然坐标系 三相永磁同步电机的驱动电路…...

8.(Python数模)(预测模型一)马尔科夫链预测
Python实现马尔科夫链预测 马尔科夫链原理 马尔科夫链是一种进行预测的方法,常用于系统未来时刻情况只和现在有关,而与过去无关。 用下面这个例子来讲述马尔科夫链。 如何预测下一时刻计算机发生故障的概率? 当前状态只存在0(故…...
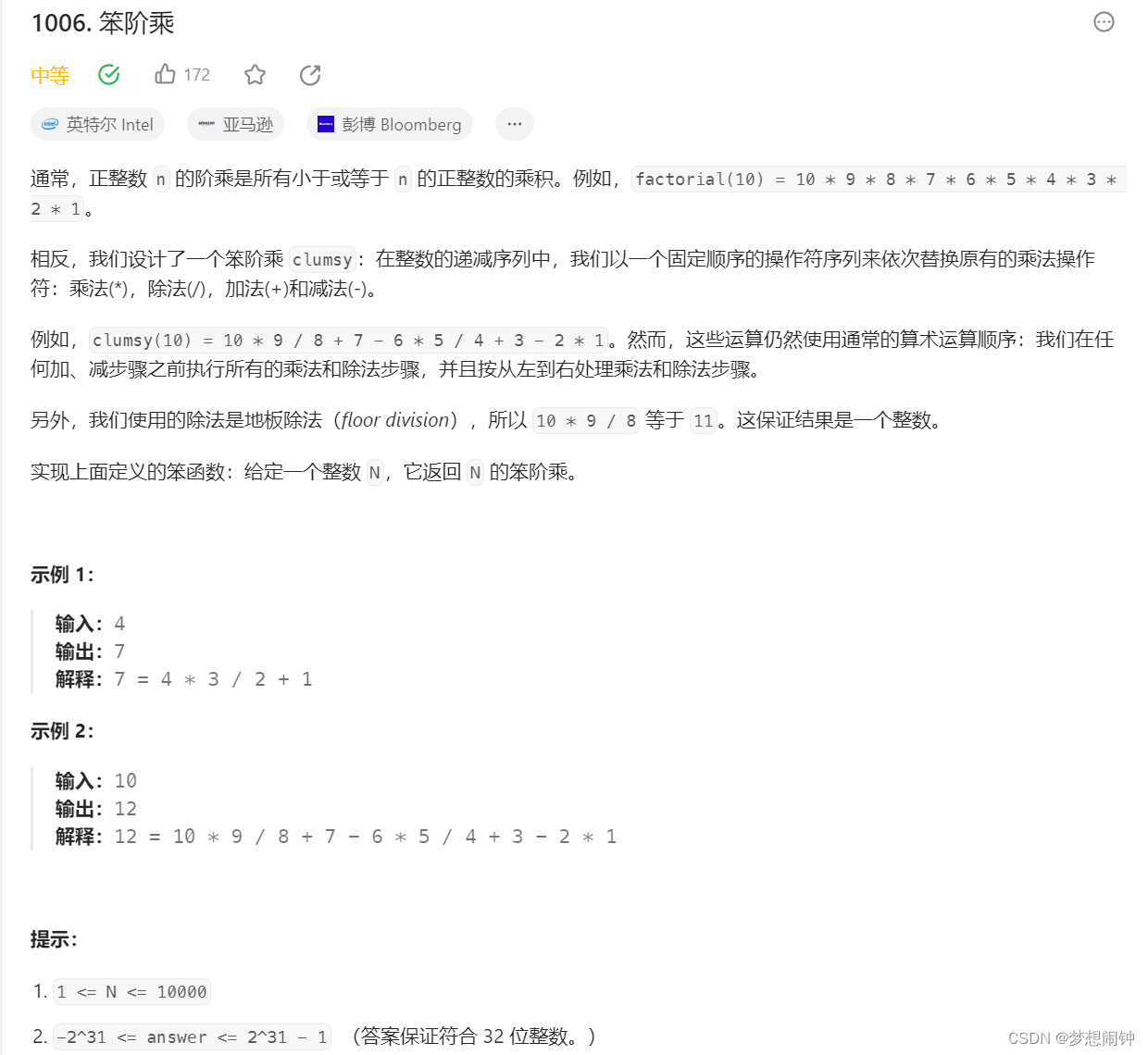
Leetcode1006笨阶乘
思路:以4为一个分组分别进行处理 class Solution:def clumsy(self, n: int) -> int:answer_dict {0:0,1: 1, 2: 2, 3: 6, 4: 7}if n > 4:answer n * (n - 1) // (n - 2) n - 3n - 4else:print(answer_dict[n])return answer_dict[n]print(answer)while n …...

阻塞非阻塞IO(BIO和NIO),IO多路复用
1.概念 NIO(New Input/Output)和BIO(Blocking Input/Output)是Java中用于处理输入输出的两种不同的模型。 BIO 会阻塞,等有了消息,立刻返回,一个线程处理一个recv(需要很多线程&…...
HTTP协议初识·中篇
加上目录,会出现导向不正确的情况,可能是bug,目录一长就容易出错? 本篇主要讲解了: 网页分离(网页代码和.c文件分离) html链接跳转 网页添加图片 确认并返回资源类型 填写正文长度属性 添加表单 临时重定向 补充知识&a…...
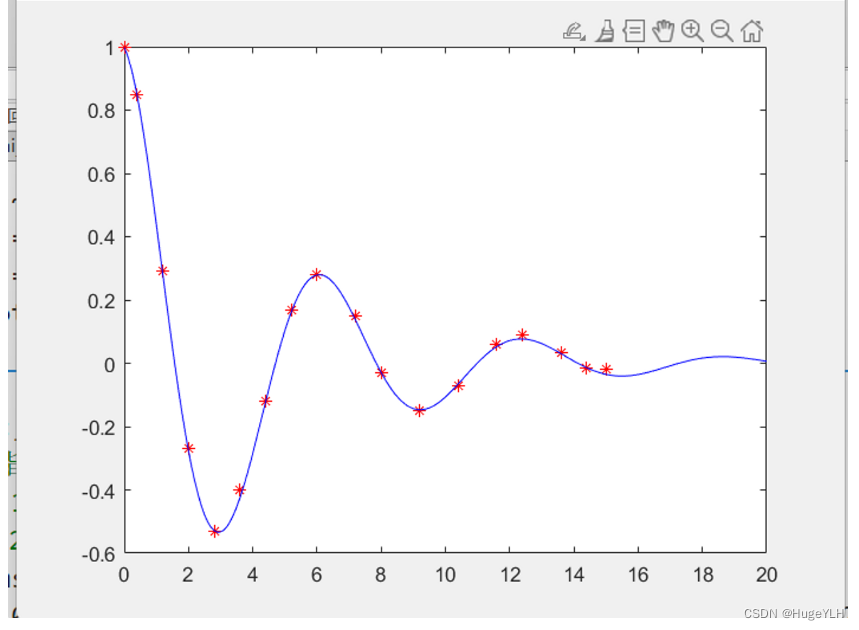
数学建模:拟合算法
🔆 文章首发于我的个人博客:欢迎大佬们来逛逛 数学建模:拟合算法 文章目录 数学建模:拟合算法拟合算法多项式拟合非线性拟合cftool工具箱的使用 拟合算法 根据1到12点间的温度数据求出温度与时间之间的近似函数关系 F ( t ) F(…...

计算机网络-笔记-汇总
目录 📚 前言 🌸章节汇总 🚀 学习心得 ⌛2023年8月31日 星期四 📚 前言 在学习了【操作系统】、【计算机组成原理】之后 再来学习【计算机网络】,对计算机之间如何通信,有了一个大致的认识。 可以想象…...
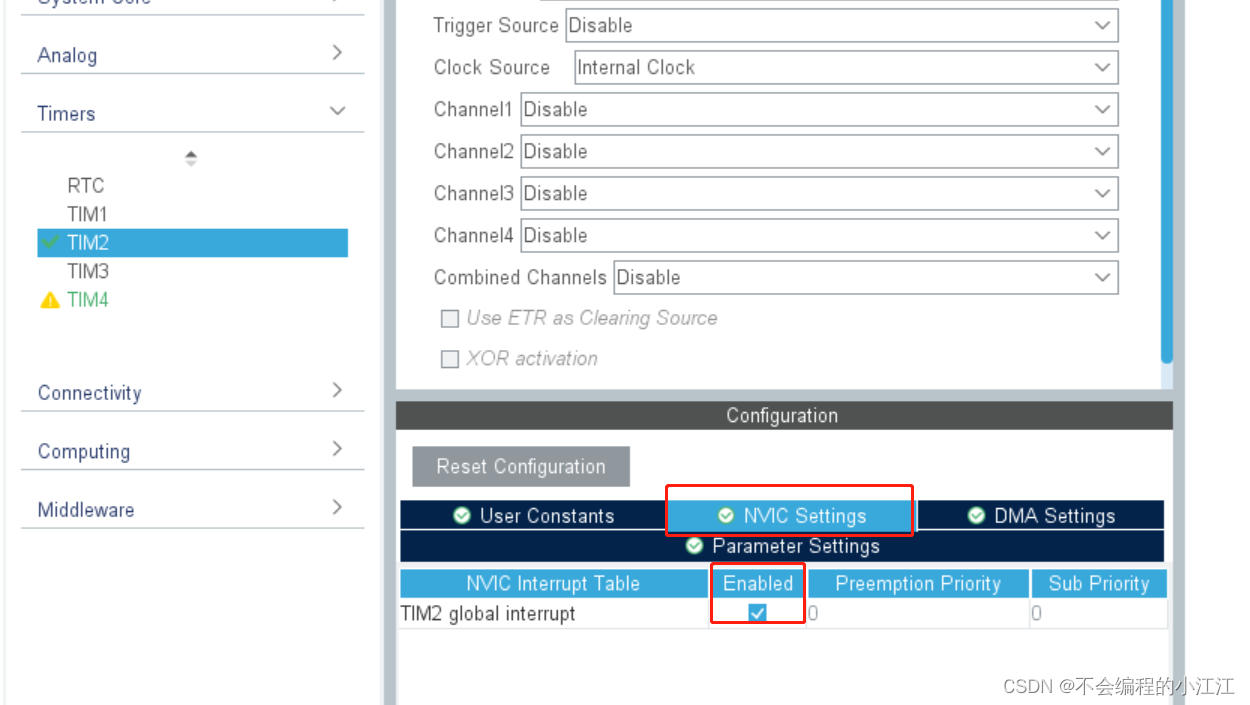
STM32定时器定时及其应用
STM32定时器定时及其应用 定时器概述☆定时器相关配置CubeMX工程配置及程序实现固件库程序设计及实现 定时器概述 1. 工作原理 使用精准的时基,通过硬件的方式,实现定时功能。定时器核心就是计数器 2. 定时器分类 基本定时器(TIM6~TIM7…...
 游游的字符重排(next_permutation的使用))
(牛客) 游游的字符重排(next_permutation的使用)
题目描述 游游定义一个字符串是“好串”,当且仅当该字符串相邻的字符不相等。例如"arcaea"是好串,而"food"不是好串。 游游拿到了一个字符串,她可以将该字符串的各个字符顺序随意打乱。她想知道一共可以生产多少种不同的…...
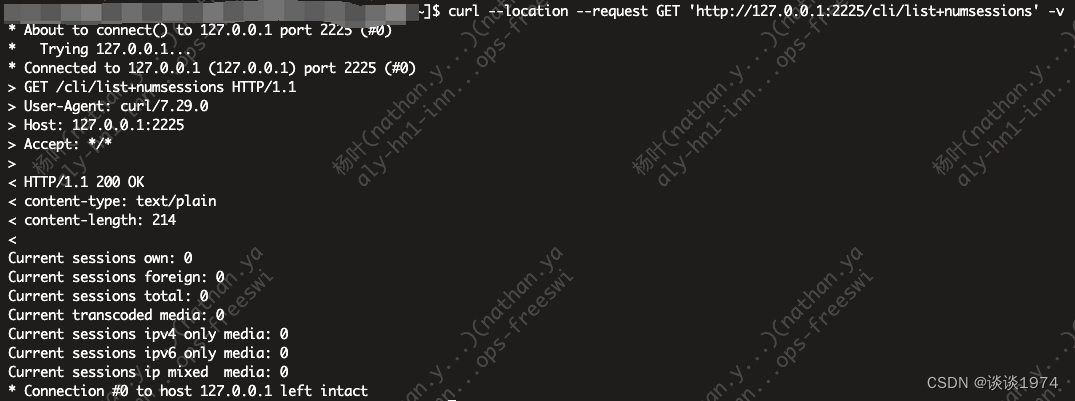
RTPEngine 通过 HTTP 获取指标的方式
文章目录 1.背景介绍2.RTPEngine 支持的 HTTP 请求3.通过 HTTP 请求获取指标的方法3.1 脚本配置3.2 请求方式 1.背景介绍 RTPEngine 是常用的媒体代理服务器,通常被集成到 SIP 代理服务器中以减小代理服务器媒体传输的压力,其架构如下图所示。这种使用方…...

聚鑫数藏平台——引领数字资产管理新风向
随着数字经济的飞速发展,新金融生态应运而生。区块链技术的崭新突破,使数字资产的重要性日益凸显,为投资者带来了前所未有的机遇和挑战。在此背景下,聚鑫数藏平台横空出世,引领着数字资产管理的新风向。 聚鑫数藏平台&…...

web3j solidity 转java
需要使用的环境 web3j,nodejs 安装编译sol工具 1 $ npm install -g solc 保存为hello.sol文件到本地 1 2 3 4 5 6 7 8 pragma solidity 0.4.19; contract hello { function main(uint a) constant returns (uint b) { uint result a * 8; …...

Qwen3.5-2B图文对话实战:教育场景中学生作业图题智能解析案例
Qwen3.5-2B图文对话实战:教育场景中学生作业图题智能解析案例 1. 引言:教育场景中的AI助手需求 想象一下这样的场景:晚上10点,孩子拿着数学作业来问问题,题目是一张手绘的几何图形。家长可能已经忘记了几十年前学过的…...

OpenClaw赋能金融投研:17个高效应用案例详解
扫描下载文档详情页: https://www.didaidea.com/wenku/16666.html...

从零开始:使用VSCode + CMake + Ninja + GCC构建高效MCU开发环境
1. 为什么需要这套开发环境? 作为一名在嵌入式领域摸爬滚打多年的开发者,我深知传统IDE的痛点。记得刚入行时,公司清一色使用某商业IDE,直到某天收到法务部的紧急通知——需要立即处理软件版权问题。这让我意识到,基于…...

树莓派通过HTTP协议对接OneNET Studio 5.0物联网平台实战指南
1. 环境准备与平台配置 在开始之前,我们需要准备好树莓派硬件和OneNET Studio 5.0平台账号。树莓派建议使用Raspberry Pi 4 Model B或更新型号,系统选择Raspbian或Raspberry Pi OS。OneNET Studio是中国移动推出的物联网开放平台,5.0版本对接…...

nfc-list使用教程
nfc-list 是 Kali Linux 中基于 libnfc 库(开源 NFC 开发框架)的基础 NFC/RFID 设备检测工具,核心功能是扫描并列出当前连接的 NFC 读卡器设备,以及贴近读卡器的 NFC 卡片(或标签)的详细信息,包…...
)
数字一阶低通滤波器在嵌入式系统中的应用:从理论到代码实现(附MATLAB验证)
数字一阶低通滤波器在嵌入式系统中的工程实践:从参数设计到代码优化 在嵌入式系统开发中,信号处理是一个永恒的话题。无论是传感器数据采集、电机控制还是通信系统,原始信号往往混杂着各种噪声。数字一阶低通滤波器以其计算量小、实现简单的特…...

DirectX兼容性解决方案:让经典游戏在Windows 10重获新生
DirectX兼容性解决方案:让经典游戏在Windows 10重获新生 【免费下载链接】dxwrapper Fixes compatibility issues with older games running on Windows 10 by wrapping DirectX dlls. Also allows loading custom libraries with the file extension .asi into gam…...

手把手教你搭建基于Matlab/Simulink的插电式混合动力汽车4驱PHEV模型
基于Matlab/simulink的插电式混合动力汽车建模仿真模型4驱PHEV(比亚迪唐DM混动系统P2P4发动机——三擎四驱),包括整车HCU控制单元、发动机模型、驱动电机模型、ISG电机模型、AMT5档自动变速箱模型、驾驶员模型、电池能量管理控制模型等&#…...

7个技巧彻底改变你的Mac菜单栏体验:Ice终极配置指南
7个技巧彻底改变你的Mac菜单栏体验:Ice终极配置指南 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice Ice是一款强大的macOS菜单栏管理工具,专门帮助用户整理杂乱的菜单栏图标&…...

Jimeng LoRA企业落地案例:设计公司LoRA训练-测试-选型一体化流程
Jimeng LoRA企业落地案例:设计公司LoRA训练-测试-选型一体化流程 1. 项目简介 今天给大家分享一个特别实用的企业级AI应用案例——如何为设计公司搭建一套完整的LoRA模型训练、测试和选型流程。这个项目基于Jimeng(即梦)系列LoRA模型&#…...