ICCV 2023 | 小鹏汽车纽约石溪:局部上下文感知主动域自适应LADA
摘要
主动域自适应(ADA)通过查询少量选定的目标域样本的标签,以帮助模型从源域迁移到目标域。查询数据的局部上下文信息非常重要,特别是在域间差异较大的情况下,然而现有的ADA方法尚未充分探索这一点。在本文中,作者提出了一种名为LADA的局部上下文感知ADA框架。为了选择信息丰富的目标域样本,作者设计了一种基于模型预测分布的局部不一致性的新准则。同时,由于标注预算通常较小,仅在查询数据上微调模型相对低效,作者逐步将相邻的置信样本增加到有标记的目标域数据中,并维持类别平衡。实验表明,文中所提出的主动学习准则相比现有的策略能选择更具信息量的目标域样本。此外,本文提出的整体方法在各种基准测试中显著优于现有最好的ADA方法。

论文链接: https://arxiv.org/abs/2208.12856
代码链接: https://github.com/tsun/LADA
01. 引言
无监督域自适应(UDA)需要将源域中的模型迁移到无标记数据的目标域上,这是一个具有挑战性的任务,尤其是当源域和目标域之间存在较大的差异时。近年来,主动域自适应(ADA)颇受关注,它通过查询选定目标域样本的标签来辅助域自适应,可以在最小标记成本下获得优异的性能。虽然ADA取得了进展,但对于查询数据的局部上下文尚未充分探索。传统的主动学习方法,通常选择模型不确定的,或具有代表性的未标记样本进行标签查询。但在ADA中,因为可以使用有标记的源域数据且源域和目标域之间存在分布差异,类似的方法可能效果不佳。利用目标域样本的局部上下文信息可以指导查询样本的选择,在模型微调过程中,也可以降低模型只记住新查询数据的倾向,以便后续的训练轮次聚焦在更难的样本上。在域间差异较大的情况下,利用查询数据的相邻数据也更加可信。
本文提出了Local context-aware Active Domain Adaptation(LADA)框架,即基于局部上下文感知的主动域自适应。首先,作者设计了Local context-aware Active Selection (LAS) 模块,基于模型预测分布的局部不一致性,从不确定区域选择多样化的子集进行标签查询。然后,作者设计了Progressive Anchor-set Augmentation (PAA) 模块以解决可查询数据规模小和数据不平衡的问题,通过逐步增加置信目标域数据进行模型微调。
本文的贡献包括:
1)验证了在ADA中利用查询数据的上下文,可以指导主动选择并改进模型参数更新。
2)设计了LAS模块,提出了基于模型预测分布局部不一致性的主动选择准则,使得模型可以选择比现有主动选择准则信息更丰富的样本。
3)设计了PAA模块,以克服查询数据规模较小的问题,并逐步以类别平衡的方式使用置信样本来增广有标记目标域数据。
02. 本文方法
2.1 问题定义

2.2 方法综述
作者利用查询数据的上下文来选择更具信息量的目标域样本,并改善模型更新。局部上下文感知主动选择(LAS)模块通过模型预测分布的局部不一致性(LI)分数对所有未标记的目标域样本进行排序,然后选择得分最高的一个多样化子集来查询标签;迭代标记数据增广(PAA)模块逐步添加置信目标域样本,并保持类别平衡。这两个模块交替运行,直到用尽标记预算。
2.3 局部上下文感知主动选择

2.4 迭代标记数据增广

03.实验
作者在四个广泛使用的域适应基准测试集上进行了实验:Office-31,Office-Home,VisDA和DomainNet。Office-Home RSUT是Office-Home的一个子集,其构造过程显式地使源域和目标域具有较大的类分布差异。
作者使用预训练的ResNet-50作为骨干网络,并进行5轮主动选择,标记预算B为5%或者10%目标域数据。为了公平比较,作者在统一框架中复现了几种传统的主动学习准则,包括随机选择(RAN),最低置信度(CONF),熵(ENT),预测概率间隔(MAR),CoreSet,BADGE,以及AADA和CLUE等ADA方法。对于最近的一些ADA方法,如S3VAADA ,TQS和LAMDA,作者从相应的论文中获取了结果。
作者在所有数据集上设置置信度阈值 τ 为0.9。对于Office-31,邻域大小 K 为5,其他数据集 K 为10。作者通过经验公式设置 M ,使得大约有12%的未标记目标数据作为候选集。由于VisDA每个类别的数据量巨大,作者将经验值减半。更多的实现细节和分析可以在补充材料中找到。
3.1 主要结果
标准数据集上ADA方法比较。在Office-Home数据集上,使用5%标签预算,结果列在表1中。在各种主动选择准则中,基于不确定性的准则(如ENT和MAR)通常获得比基于代表性的准则(如CoreSet)更高的准确度,表明选择已经与源域对齐的目标域数据是低效的。当使用半监督求解器MME时,这些准则之间的性能差距变小。无论使用哪种策略,作者提出的LAS准则始终获得最好的分数,表明它可以选择更具信息量的目标样本。表2列出了使用10%预算时的结果。在使用微调或CDAC时,LAS的准确度优于其他主动选择准则。与最近的LAMDA方法相比,作者提出的LAS w/LAA作为整体方法提高了2.3%的准确度。


表3显示了在Office-31数据集上使用5%预算的结果。当模型更新方法固定为微调、MME或CDAC时,LAS始终优于其他主动选择准则。当主动选择方法固定为LAS时,作者提出的RAA和LAA始终优于MME、MCC和CDAC。表5列出了在VisDA数据集上使用10%预算的结果。LAS w/ LAA相比LAMDA提升了1.3%。


类分布偏移的数据集上ADA方法比较。源域和目标域之间类别分布不匹配在ADA中会导致一些问题。作者将本文方法与专门用于解决这个问题的LAMDA进行了比较。遵照他们的设置,作者使用了10%标记预算。表4、5列出了比较结果。LAMDA在源域数据上做重要性抽样以匹配源域和目标域的类别分布,这对于类似DANN的域对抗方法特别有用,本文的RAA/LAA属于自训练方法。作者使用类平衡拒绝机制来构造平衡的训练数据。给定LAS,RAA/LAA的准确度高于其他模型更新方法。LAS w/ LAA整体方法比LAMDA提高了1%。
3.2 LAS分析
LAS中不确定性度量。LAS使用LI(Local Inconsistency)分数来发现不确定区域。为了探究其特性,作者将LAS中的LI分数替换为其他不确定性度量方法,同时保持相同的多样性采样过程。比较的度量方法包括预测概率间隔、熵、预测置信度和NAU分数。图4a和图4b显示了不同过采样比例下的性能。
从图中可以看出,使用较大的过采样比例对于所有不确定性度量方法都是有益的,表明在不确定性和多样性之间需要平衡。CLUE和BADGE也是混合方法,但是它们与LAS有所不同。CLUE在所有目标域样本上运行基于熵加权距离的聚类,而BADGE在所有目标域样本上运行基于梯度嵌入的聚类。它们都依赖于整个目标域数据。


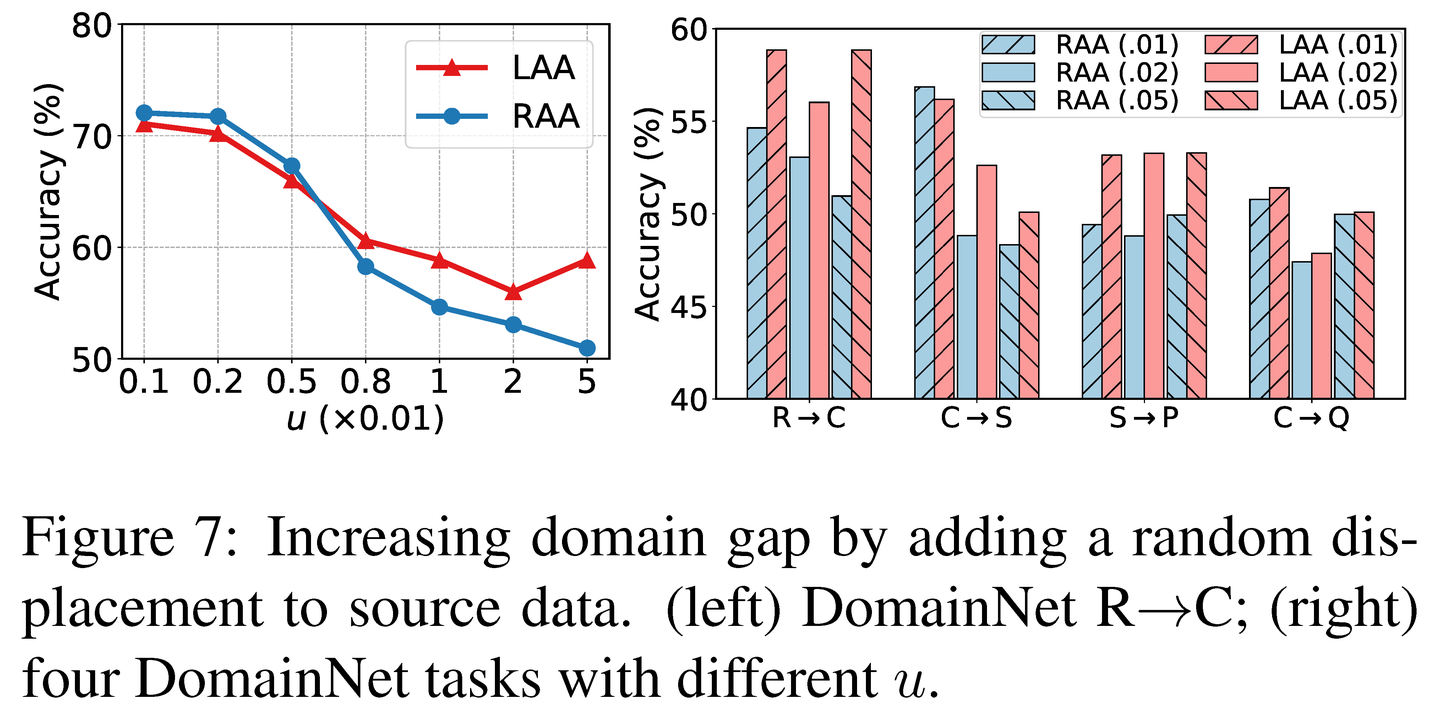
LAS相对于其他主动学习准则的优势。为了更好地展示LAS相对于其他主动学习准则的优势,图5绘制了在不同标记预算和领域自适应方法下的准确率。左图中,无论是使用微调还是MME,LAS始终得到了更好或相当的准确率。当标记预算较小时,性能提升更为显著。中间图绘制了使用5%预算的准确率曲线。LAS在整个训练过程中都优于其他准则。右图中,无论使用何种领域自适应策略,LAS都获得了最佳性能。

为了进一步分析这些不确定性度量之间的差异,图2可视化了Office-31 W→A数据集上的目标域数据特征。作者将所有不确定性分数归一化到[0,1],并根据分数对每个样本进行着色,其中分数最高的10%样本标记为黑色边框。熵和预测概率间隔不考虑局部上下文,因此它们往往包含一些孤立样本,如图2a和图2b所示。NAU定义为NAU = NP×NA,其中NP是邻居样本类别分布的熵,NA是样本与其邻居之间的平均相似性。由于邻居数有限,NP具有离散值且往往较小。如图2c和图2e所示,大多数目标域数据的NAU得分较小。相比之下,不确定样本往往具有较大的LI分数并且更加聚集,在LI的直方图中大约0.8位置可以观察到一个峰值。这也解释了为什么对于LI来说,多样性采样是重要的。在图3放大的可视化中,可以看出LI中的平滑操作有助于去除一些孤立样本。


3.3 RAA/LAA分析
类别平衡拒绝机制的效果。为了解决类别分布不一致的问题,作者在构建标记数据集A的时候通过对多数类和少数类不同的拒绝概率,有效地构造了类别平衡的训练集。图6可视化了 A 中每个类别的样本占比。可以看到,不使用拒绝机制时, A 由多数类主导。相比之下,使用了拒绝机制,来自少数类的样本比例增加。这有助于以更平衡的方式训练每个类别,体现在表6中逐类平均准确率有1.0%的提升。
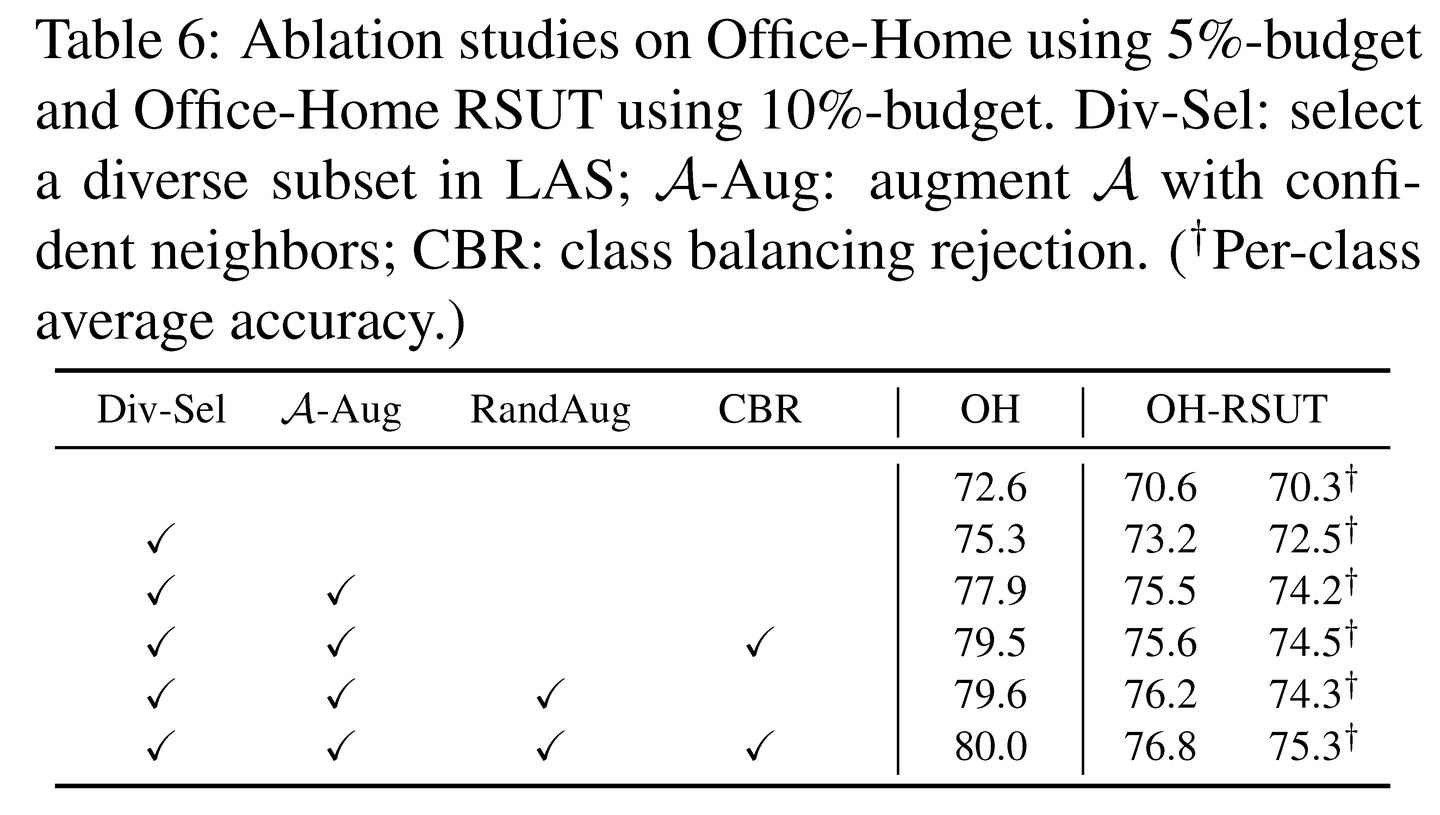

LADA组件消融实验。表6呈现了LADA各个组件的消融实验结果。第二行相较于第一行的改进表明在LAS中选择一个多样化子集至关重要。通过标记集增广,Office-Home上的准确率提高了2.6%,Office-Home RSUT上提高了2.3%。这证实了仅在查询数据上进行模型微调是相对低效的。使用RandAug构造混合图像进一步提升了性能。为了显示类平衡拒绝机制的有效性,作者在Office-Home RSUT上汇报了逐类平均准确率,从最后一行可以看到1.0%的提升。
04. 结论
本文提出利用查询数据的局部上下文进行主动领域自适应。作者首先提出了一种基于模型预测概率局部不一致性的局部上下文感知主动选择方法,相比之前的准则能选择更具信息量的样本。然后,作者提出了一个迭代标记数据增广模块,以解决标记预算较少导致的问题。它利用查询数据及其扩展邻域来更新模型参数,并维持类别平衡。充分的实验证明,本文的完整方法LADA(局部上下文感知主动领域自适应)显著优于现有最好的ADA方法。
作者:吕骋
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区
相关文章:
ICCV 2023 | 小鹏汽车纽约石溪:局部上下文感知主动域自适应LADA
摘要 主动域自适应(ADA)通过查询少量选定的目标域样本的标签,以帮助模型从源域迁移到目标域。查询数据的局部上下文信息非常重要,特别是在域间差异较大的情况下,然而现有的ADA方法尚未充分探索这一点。在本文中&#…...

stable diffusion实践操作-黑白稿线稿上色
系列文章目录 本文专门开一节【黑白稿线稿上色】写相关的内容,在看之前,可以同步关注: stable diffusion实践操作 文章目录 系列文章目录前言一、操作步骤1. 找到黑白线稿图 总结 前言 本章主要介绍黑白稿线稿上色,这是通过Cont…...

Python学习教程:集合操作的详细教程
前言 大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 Python中有两种可以遍历的容器类型: 序列类型:包含字符串、列表、元祖 序列类型是线性表,就像数组一样,是在内存中开辟一块连续空间,连续存储的, 那么查找…...

球球的排列
题目传送门 引 计数DP,好像特别经典,有两种做法,我只会 O ( n 3 ) O(n^3) O(n3),有 O ( n 2 ) O(n^2) O(n2)的 解法 首先, 若 x y p 2 且 x z q 2 , 则 y z ( p q x ) 2 若xyp^2且xzq^2,则yz(\frac{pq}{x} )^2 若xyp2且xzq2,则yz(xpq…...
1783_CMD启动MATLAB同时执行一个脚本
全部学习汇总: GitHub - GreyZhang/g_matlab: MATLAB once used to be my daily tool. After many years when I go back and read my old learning notes I felt maybe I still need it in the future. So, start this repo to keep some of my old learning notes…...

C语言中内存分配的几种方式
目录 C语言中内存分配的几种方式静态内存分配栈内存分配堆内存分配内存映射文件 C语言中内存分配的几种方式 静态内存分配 静态内存分配是在程序编译时分配内存,通常用于全局变量和静态变量。这些变量的内存空间在程序的整个运行期间都是存在的。 栈内存分配 栈内存…...
组相联cache如何快速实现cache line eviction并使用PMU events验证
如何快速实现cache line eviction 一,什么是cache hit、miss、linefill、evict ?1.1 如果要程序员分别制造出cache hit、miss、linefill、evict这四种场景,该怎么做? 二,实现cache line eviction的方法1.1 直接填充法3…...
【Stable Diffusion安装】支持python3.11 window版
前言 主要的安装步骤是参考B站播放量第一的视频,但是那位阿婆主应该是没有编程经验,只强调使用3.10,而python最新版本是3.11。 理论上来说,只是一个小版本的不同,应该是可以安装成功了。自己摸索了下,挺费…...

Anycloud37D平台移植wirelesstools
0. 环境准备 下载 :https://www.linuxfromscratch.org/blfs/view/svn/basicnet/wireless_tools.html 1. 交叉编译wireless_tools tar xzf wireless_tools.29.tar.gz cd wireless_tools.29/打开Makefile,修改配置: ## Compiler to use (mo…...

海康机器人工业相机 Win10+Qt+Cmake 开发环境搭建
文章目录 一. Qt搭建海康机器人工业相机开发环境 一. Qt搭建海康机器人工业相机开发环境 参考这个链接安装好MVS客户端 Qt新建一个c项目 cmakeList中添加海康机器人的库,如下: cmake_minimum_required(VERSION 3.5)project(HIKRobotCameraTest LANG…...
使用MDK5的一些偏僻使用方法和谋个功能的作用
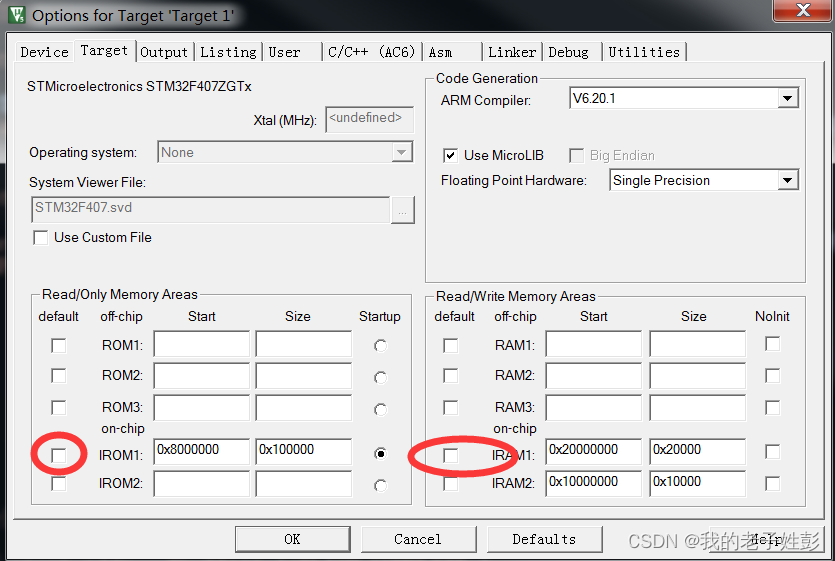
程序下载后无法运行 需要勾选如下库,是优化后的库; MicroLib和标准C库之间的主要区别是: 1、MicroLib是专为深度嵌入式应用程序而设计的。 2、MicroLib经过优化,比使用ARM标准库使用更少的代码和数据内存。 3、MicroLib被设计成在没有操作…...
【实战】十一、看板页面及任务组页面开发(六) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(二十八)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

在 Amazon 搭建无代码可视化的数据分析和建模平台
现代企业常常会有利用数据分析和机器学习帮助解决业务痛点的需求。如制造业中,利用设备采集上来的数据做预测性维护,质量控制;在零售业中,利用客户端端采集的数据做渠道转化率分析,个性化推荐等。 亚马逊云科技开发者…...

Pinely Round 2 (Div. 1 + Div. 2) G. Swaps(组合计数)
题目 给定一个长度为n(n<1e6)的序列,第i个数ai(1<ai<n), 操作:你可以将当前i位置的数和a[i]位置的数交换 交换可以操作任意次,求所有本质不同的数组的数量,答案对1e97取模 思路来源 力扣群 潼神 心得 感…...

elasticSearch+kibana+logstash+filebeat集群改成https认证
文章目录 一、生成相关证书二、配置elasticSearh三、配置kibana四、配置logstash五、配置filebeat六、连接https es的java api 一、生成相关证书 ps:主节点操作 切换用户:su es 进入目录:cd /home/es/elasticsearch-7.6.2 创建文件&#x…...

GPT带我学-设计模式-迭代器模式
1 什么是迭代器设计模式? 迭代器设计模式是一种行为型设计模式,用于提供一种统一的方式来遍历一个集合对象中的元素,而不需要暴露该对象的内部结构。它将集合对象的遍历操作与集合对象本身分离开来,使得遍历操作可以独立于集合对…...
的Python实现)
数学建模--层次分析法(AHP)的Python实现
目录 1.算法流程简介 2.算法核心代码 3.算法效果展示 1.算法流程简介 """ AHP:层次分析法,层次分析法还是比较偏向于主观的判断的,所以在建模的时候尽可能不要去使用层次分析法 不过在某些创新的评价方法上,也是能够运用层次分析使得评价变得全面一些,有可…...

机器学习笔记之最优化理论与方法(三)凸集的简单认识(下)
机器学习笔记之最优化理论与方法——凸集的简单认识[下] 引言回顾:基本定义——凸集关于保持集合凸性的运算仿射变换 凸集基本性质:投影定理点与凸集的分离支撑超平面定理 引言 继续凸集的简单认识(上)进行介绍,本节将介绍凸集的基本性质以及…...
Apipost:API文档、调试、Mock与测试的一体化协作平台
随着数字化转型的加速,API(应用程序接口)已经成为企业间沟通和数据交换的关键。而在API开发和管理过程中,API文档、调试、Mock和测试的协作显得尤为重要。Apipost正是这样一款一体化协作平台,旨在解决这些问题…...

Homebrew下载安装及使用教程
Homebrew是什么? 简单来说,就是用命令行的形式去管理mac系统的包或软件。 安装命令 /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"国内请使用镜像源进行下载 执行上述命令后会要求输入…...
详解与优化实践)
ARM AArch32性能监控寄存器(PMU)详解与优化实践
1. ARM AArch32性能监控寄存器深度解析在嵌入式系统和移动计算领域,性能监控单元(PMU)是处理器微架构中至关重要的组成部分。作为一位长期从事ARM架构开发的工程师,我经常需要深入理解PMU寄存器的工作原理,以优化关键代码段的执行效率。本文将…...
)
别再猜了!手把手教你识别并解码家里那些“身份不明”的红外遥控器(NEC/RC5/RC6初步判断)
红外遥控器协议侦探指南:快速识别NEC/RC5/RC6编码 家里积攒的旧遥控器越来越多,每个按键背后究竟藏着什么秘密?当你试图用智能家居系统整合这些设备时,第一步往往不是学习信号,而是破解这些"黑盒子"的通信语…...

AI学术研究技能包:从论文导读到实验设计的全流程自动化助手
1. 项目概述:一个为AI研究助手打造的学术技能包如果你正在用Claude Code、ChatGPT/Codex CLI或者Gemini CLI这类AI编程助手做研究,大概率遇到过这样的场景:想让AI帮你读篇论文,它却只能泛泛而谈;想让AI设计个实验&…...

GAIA-DataSet:构建智能运维研究的数据基石与算法验证平台
GAIA-DataSet:构建智能运维研究的数据基石与算法验证平台 【免费下载链接】GAIA-DataSet GAIA, with the full name Generic AIOps Atlas, is an overall dataset for analyzing operation problems such as anomaly detection, log analysis, fault localization, …...
知识图谱嵌入模型全解析:从TransE到RotatE的演进与实战指南
1. 项目概述:为什么我们需要重新审视KGE?在信息爆炸的时代,我们每天都在和“关系”打交道:社交网络中的好友关系、电商平台上的购买关系、学术论文间的引用关系。如何让机器理解这些错综复杂的实体与关系,并从中挖掘出…...

[特殊字符] MarkText使用指南
📝 MarkText使用指南 【免费下载链接】marktext 📝A simple and elegant markdown editor, available for Linux, macOS and Windows. 项目地址: https://gitcode.com/gh_mirrors/ma/marktext ⚡ 快速入门教程 ❤️ 高级功能详解 ### 在列表中使…...
)
别再死记硬背了!手把手教你理解UVM寄存器模型中的reg2bus与bus2reg(附APB总线实战代码)
深入解析UVM寄存器模型:揭秘reg2bus与bus2reg的自动化魔法 在芯片验证领域,UVM寄存器模型堪称验证工程师的"瑞士军刀",但其中两个核心转换函数——reg2bus和bus2reg却让不少初学者感到困惑。为什么我们只需要实现这两个函数&#x…...

如何高效配置编程字体:Maple Mono的进阶优化方案
如何高效配置编程字体:Maple Mono的进阶优化方案 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization options. 带连字和控制台图标的圆角等…...

开源AI对话界面chat-ui:快速部署与定制化LLM前端实践
1. 项目概述:一个开源的AI对话界面如果你最近在折腾大语言模型(LLM),不管是想部署一个私有的ChatGPT替代品,还是想给自己训练或微调的模型配一个像样的“脸面”,那你大概率绕不开一个核心问题:前…...

Wand-Enhancer:解锁WeMod全部潜力的开源增强工具
Wand-Enhancer:解锁WeMod全部潜力的开源增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 在游戏辅助工具的世界里,WeMod无…...