自然语言处理:提取长文本进行文本主要内容(文本意思)概括 (两种方法,但效果都一般)
本文主要针对长文本进行文本提取和中心思想概括,原文档放在了附件里面:<科大讯飞公告>
-----------------------------------方法一:jieba分词提取文本(句子赋分法)-------------------------
1、首先导入相关库并读取文档内容:
import pandas as pd
df=pd.read_csv(r'C:\Users\59980\Desktop\peixun\科大讯飞_公告.csv',encoding='GBK')
#df['公告内容']
text=""
for line in df['公告内容'][0]:text+=line
text这里仅作演示所以只读取了文档的第一条数据文本,如果要对每一行文本处理,可以做个for循环,这里就不演示,比较简单。
原文档内容格式:
证券代码:002230 证券简称:科大讯飞 公告编号:2022-001科大讯飞股份有限公司关于合肥连山创新产业投资基金完成备案的公告本公司及董事会全体成员保证信息披露内容真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏。为加快构建人工智能技术应用生态体系,借助专业机构的投资管理经验及其他产业投资人在生命科技、新能源、智能制造、新消费等领域的产业资源优势,深化人工智能技术在新领域应用的探索,进行优质项目的发掘与培育,提升赋能支持能力,并推动人工智能在各行业应用的深度融合和广泛落地,科大讯飞股份有限公司(以下简称 “公司”)与普通合伙人合肥科讯创业投资管理合伙企业(有限合伙),及有限合伙人田明、曹仁贤、陈先保、安徽安科生物工程(集团)股份有限公司、三亚高卓佳音信息科技合伙企业(有限合伙)、郭子珍、魏臻、朱庆龙和吴华峰等共同出资设立合肥连山创新产业投资基金合伙企业(有限合伙)(以下简称“基金”)。其中科大讯飞以自有资金作为基金的有限合伙人出
资 11,000 万元,占基金总认缴出资额的 22%。具体内容详见公司于 2021 年 11 月 19 日在
《证券时报》《中国证券报》《上海证券报》《证券日报》和巨潮资讯网(www.cninfo.com.cn)披露的《关于对外投资的公告》(公告编号:2021-096)。近日,公司接到通知,该基金已根据《证券投资基金法》和《私募投资基金监督管理暂行办法》等法律法规的要求,在中国证券投资基金业协会完成备案手续,并取得《私募投资基金备案证明》。主要情况如下:备案编码:STP473基金名称:合肥连山创新产业投资基金合伙企业(有限合伙)管理人名称:合肥科讯创业投资管理合伙企业(有限合伙)托管人名称:招商银行股份有限公司公司将根据该基金的后续进展情况,按照有关法律法规的规定和要求,及时履行信息披露义务。敬请广大投资者注意投资风险。特此公告。科大讯飞股份有限公司董 事 会二〇二二年一月八日看文本提取的内容:

整理成一行了。
2、数据清洗
#清洗数据
import re
import jieba
text = re.sub(r'[[0-9]*]',' ',text)#去除类似[1],[2]
text = re.sub(r'\s+',' ',text)#用单个空格替换了所有额外的空格
sentences = re.split('(。|!|\!|\.|?|\?)',text)#分句
sentences这部分要安装的库包括:jieba,re,这部分作用是利用正则表达式把文本去除类似于:[数字];空格等符号,并按标点符号进行分句。分完句子后效果如下:
3、加载停用词:
文档已经上传到附件里,利用停用词对上述句子进行切分:
#加载停用词def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwords
stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')停用词内容如图:
4、对句子进行打分,形成最终文档:
#统计词频,首次出现赋值为1,否则统计
word2count = {} #line 1
for word in jieba.cut(text): #对整个文本分词if word not in stopwords:if word not in word2count.keys():word2count[word] = 1else:word2count[word] += 1
for key in word2count.keys():word2count[key] = word2count[key] / max(word2count.values())#根据句子中单词的频率计算每个句子的得分
sent2score = {}#根据句子中单词的频率计算每个句子的得分
for sentence in sentences:#遍历句子for word in jieba.cut(sentence):#对每个句子进行分词if word in word2count.keys():#每个单词,检查它是否存在于word2count字典中if len(sentence)<300:if sentence not in sent2score.keys():sent2score[sentence] = word2count[word]#每个单词,检查它是否存在于word2count字典中else:sent2score[sentence] += word2count[word]#句子已经在sent2score中,则将来自word2count的单词频率的值加到该句子的现有得分上#字典排序
def dic_order_value_and_get_key(dicts, count):# by hellojesson# 字典根据value排序,并且获取value排名前几的keyfinal_result = []# 先对字典排序sorted_dic = sorted([(k, v) for k, v in dicts.items()], reverse=True)tmp_set = set() # 定义集合 会去重元素 --此处存在一个问题,成绩相同的会忽略,有待改进for item in sorted_dic:tmp_set.add(item[1])for list_item in sorted(tmp_set, reverse=True)[:count]:for dic_item in sorted_dic:if dic_item[1] == list_item:final_result.append(dic_item[0])return final_result#摘要输出
final_resul=dic_order_value_and_get_key(sent2score,5)
print(final_resul)最终输出文本内容如图:

为加快构建人工智能技术应用生态体系,借助专业机构的投资管理经验及其他产业投资人在生命科技、新能源、智能制造、新消费等领域的产业资源优势,深化人工智能技术在新领域应用的探索,进行优质项目的发掘与培育,提升赋能支持能力,并推动人工智能在各行业应用的深度融合和广泛落地,科大讯飞股份有限公司(以下简称 “公司”)与普通合伙人合肥科讯创业投资管理合伙企业(有限合伙),及有限合伙人田明、曹仁贤、陈先保、安徽安科生物工程(集团)股份有限公司、三亚高卓佳音信息科技合伙企业(有限合伙)、郭子珍、魏臻、朱庆龙和吴华峰等共同出资设立合肥连山创新产业投资基金合伙企业(有限合伙)(以下简称“基金”)', '主要情况如下: 备案编码:STP473 基金名称:合肥连山创新产业投资基金合伙企业(有限合伙) 管理人名称:合肥科讯创业投资管理合伙企业(有限合伙) 托管人名称:招商银行股份有限公司 公司将根据该基金的后续进展情况,按照有关法律法规的规定和要求,及时履行信息披露义务', '证券代码:002230 证券简称:科大讯飞 公告编号:2022-001 科大讯飞股份有限公司 关于合肥连山创新产业投资基金完成备案的公告 本公司及董事会全体成员保证信息披露内容真实、准确和完整,没有虚假记载、误导性陈述或者重大遗漏', ' 近日,公司接到通知,该基金已根据《证券投资基金法》和《私募投资基金监督管理暂行办法》等法律法规的要求,在中国证券投资基金业协会完成备案手续,并取得《私募投资基金备案证明》', '具体内容详见公司于 2021 年 11 月 19 日在 《证券时报》《中国证券报》《上海证券报》《证券日报》和巨潮资讯网(www'-----------------------------------方法二:封装成界面(句子赋分法)-------------------------
二、把输入和输出封装成界面,最终效果如图:
全代码实现:(不用修改的部分)
import nltk
import jieba
import numpy#pip install pyQt5,需要安装的库#分句
def sent_tokenizer(texts):start=0i=0#每个字符的位置sentences=[]punt_list=',.!?:;~,。!?:;~'#标点符号for text in texts:#遍历每一个字符if text in punt_list and token not in punt_list: #检查标点符号下一个字符是否还是标点sentences.append(texts[start:i+1])#当前标点符号位置start=i+1#start标记到下一句的开头i+=1else:i+=1#若不是标点符号,则字符位置继续前移token=list(texts[start:i+2]).pop()#取下一个字符.pop是删除最后一个if start<len(texts):sentences.append(texts[start:])#这是为了处理文本末尾没有标点符号的情况return sentences#对停用词加载,读取本地文档的停用词
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwords#对句子打分
def score_sentences(sentences,topn_words):#参数 sentences:文本组(分好句的文本,topn_words:高频词组scores=[]sentence_idx=-1#初始句子索引标号-1for s in [list(jieba.cut(s)) for s in sentences]:# 遍历每一个分句,这里的每个分句是分词数组 分句1类似 ['花', '果园', '中央商务区', 'F4', '栋楼', 'B33', '城', ',']sentence_idx+=1 #句子索引+1。。0表示第一个句子word_idx=[]#存放关键词在分句中的索引位置.得到结果类似:[1, 2, 3, 4, 5],[0, 1],[0, 1, 2, 4, 5, 7]..for w in topn_words:#遍历每一个高频词try:word_idx.append(s.index(w))#关键词出现在该分句子中的索引位置except ValueError:#w不在句子中password_idx.sort()if len(word_idx)==0:continue#对于两个连续的单词,利用单词位置索引,通过距离阀值计算族clusters=[] #存放的是几个cluster。类似[[0, 1, 2], [4, 5], [7]]cluster=[word_idx[0]] #存放的是一个类别(簇) 类似[0, 1, 2]i=1while i<len(word_idx):#遍历 当前分句中的高频词CLUSTER_THRESHOLD=2#举例阈值我设为2if word_idx[i]-word_idx[i-1]<CLUSTER_THRESHOLD:#如果当前高频词索引 与前一个高频词索引相差小于3,cluster.append(word_idx[i])#则认为是一类else:clusters.append(cluster[:])#将当前类别添加进clusters=[]cluster=[word_idx[i]] #新的类别i+=1clusters.append(cluster)#对每个族打分,每个族类的最大分数是对句子的打分max_cluster_score=0for c in clusters:#遍历每一个簇significant_words_in_cluster=len(c)#当前簇 的高频词个数total_words_in_cluster=c[-1]-c[0]+1#当前簇里 最后一个高频词 与第一个的距离score=1.0*significant_words_in_cluster*significant_words_in_cluster/total_words_in_clusterif score>max_cluster_score:max_cluster_score=scorescores.append((sentence_idx,max_cluster_score))#存放当前分句的最大簇(说明下,一个分解可能有几个簇) 存放格式(分句索引,分解最大簇得分)return scores;需要修改的部分:(路径修改成自己的)
def results(texts,topn_wordnum,n):#texts 文本,topn_wordnum高频词个数,为返回几个句子stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')#加载停用词sentence = sent_tokenizer(texts) # 分句words = [w for sentence in sentence for w in jieba.cut(sentence) if w not in stopwords iflen(w) > 1 and w != '\t'] # 词语,非单词词,同时非符号wordfre = nltk.FreqDist(words) # 统计词频topn_words = [w[0] for w in sorted(wordfre.items(), key=lambda d: d[1], reverse=True)][:topn_wordnum] # 取出词频最高的topn_wordnum个单词scored_sentences = score_sentences(sentence, topn_words)#给分句打分# 1,利用均值和标准差过滤非重要句子avg = numpy.mean([s[1] for s in scored_sentences]) # 均值std = numpy.std([s[1] for s in scored_sentences]) # 标准差mean_scored = [(sent_idx, score) for (sent_idx, score) in scored_sentences ifscore > (avg + 0.5 * std)] # sent_idx 分句标号,score得分# 2,返回top n句子top_n_scored = sorted(scored_sentences, key=lambda s: s[1])[-n:] # 对得分进行排序,取出n个句子top_n_scored = sorted(top_n_scored, key=lambda s: s[0]) # 对得分最高的几个分句,进行分句位置排序c = dict(mean_scoredsenteces=[sentence[idx] for (idx, score) in mean_scored])c1=dict(topnsenteces=[sentence[idx] for (idx, score) in top_n_scored])return c,c1封装成界面,在界面里输入和输出:
from PyQt5.QtWidgets import QApplication, QWidget, QTextEdit, QVBoxLayout, QPushButton,QLabel,QLineEdit,QFormLayout
import sysclass TextEditDemo(QWidget):def __init__(self, parent=None):super(TextEditDemo, self).__init__(parent)self.setWindowTitle("中文摘要提取")self.resize(500, 570)self.label1 = QLabel('输入文本')self.textEdit1 = QTextEdit()self.lineedit1 = QLineEdit()#请输入高频词数self.lineedit2 = QLineEdit()#请输入返回句子数self.btnPress1 = QPushButton("点击运行")self.textEdit2 = QTextEdit()#方法1显示self.textEdit3 = QTextEdit()#方法2 显示flo = QFormLayout()#表单布局flo.addRow("请输入高频词数:", self.lineedit1)flo.addRow("请输入返回句子数:", self.lineedit2)layout = QVBoxLayout()layout.addWidget(self.label1)layout.addWidget(self.textEdit1)layout.addLayout(flo)layout.addWidget(self.btnPress1)layout.addWidget(self.textEdit2)layout.addWidget(self.textEdit3)self.setLayout(layout)self.btnPress1.clicked.connect(self.btnPress1_Clicked)def btnPress1_Clicked(self):try:text = self.textEdit1.toPlainText() # 返回输入的文本topn_wordnum = int(self.lineedit1.text()) # 高频词 20n = int(self.lineedit2.text()) # 3个返回句子c, c1 = results(str(text), topn_wordnum, n)self.textEdit2.setPlainText(str(c))self.textEdit2.setStyleSheet("font:10pt '楷体';border-width:5px;border-style: inset;border-color:gray")self.textEdit3.setPlainText(str(c1))self.textEdit3.setStyleSheet("font:10pt '楷体';border-width:5px;border-style: inset;border-color:red")except:self.textEdit2.setPlainText('操作失误')self.lineedit1.setText('操作失误,请输入整数')self.lineedit2.setText('操作失误,请输入整数')if __name__ == "__main__":app = QApplication(sys.argv)win = TextEditDemo()win.show()sys.exit(app.exec_())最终效果如图:
总结起来就是没有大模型训练的文本含义提取其效果都比较一般。
下面是上面封装界面代码的在python实现,非封装成界面:
#coding:utf-8
import nltk
import jieba
import numpy#分句
def sent_tokenizer(texts):start=0i=0#每个字符的位置sentences=[]punt_list=',.!?:;~,。!?:;~'#标点符号for text in texts:#遍历每一个字符if text in punt_list and token not in punt_list: #检查标点符号下一个字符是否还是标点sentences.append(texts[start:i+1])#当前标点符号位置start=i+1#start标记到下一句的开头i+=1else:i+=1#若不是标点符号,则字符位置继续前移token=list(texts[start:i+2]).pop()#取下一个字符.pop是删除最后一个if start<len(texts):sentences.append(texts[start:])#这是为了处理文本末尾没有标点符号的情况return sentences#对停用词加载
def stopwordslist(filepath):stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]return stopwords#对句子打分
def score_sentences(sentences,topn_words):#参数 sentences:文本组(分好句的文本,topn_words:高频词组scores=[]sentence_idx=-1#初始句子索引标号-1for s in [list(jieba.cut(s)) for s in sentences]:# 遍历每一个分句,这里的每个分句是 分词数组 分句1类似 ['花', '果园', '中央商务区', 'F4', '栋楼', 'B33', '城', ',']sentence_idx+=1 #句子索引+1。。0表示第一个句子word_idx=[]#存放关键词在分句中的索引位置.得到结果类似:[1, 2, 3, 4, 5],[0, 1],[0, 1, 2, 4, 5, 7]..for w in topn_words:#遍历每一个高频词try:word_idx.append(s.index(w))#关键词出现在该分句子中的索引位置except ValueError:#w不在句子中password_idx.sort()if len(word_idx)==0:continue#对于两个连续的单词,利用单词位置索引,通过距离阀值计算族clusters=[] #存放的是几个cluster。类似[[0, 1, 2], [4, 5], [7]]cluster=[word_idx[0]] #存放的是一个类别(簇) 类似[0, 1, 2]i=1while i<len(word_idx):#遍历 当前分句中的高频词CLUSTER_THRESHOLD=2#举例阈值我设为2if word_idx[i]-word_idx[i-1]<CLUSTER_THRESHOLD:#如果当前高频词索引 与前一个高频词索引相差小于3,cluster.append(word_idx[i])#则认为是一类else:clusters.append(cluster[:])#将当前类别添加进clusters=[]cluster=[word_idx[i]] #新的类别i+=1clusters.append(cluster)#对每个族打分,每个族类的最大分数是对句子的打分max_cluster_score=0for c in clusters:#遍历每一个簇significant_words_in_cluster=len(c)#当前簇 的高频词个数total_words_in_cluster=c[-1]-c[0]+1#当前簇里 最后一个高频词 与第一个的距离score=1.0*significant_words_in_cluster*significant_words_in_cluster/total_words_in_clusterif score>max_cluster_score:max_cluster_score=scorescores.append((sentence_idx,max_cluster_score))#存放当前分句的最大簇(说明下,一个分解可能有几个簇) 存放格式(分句索引,分解最大簇得分)return scores;#结果输出
def results(texts,topn_wordnum,n):#texts 文本,topn_wordnum高频词个数,为返回几个句子stopwords = stopwordslist(r'C:\Users\59980\Desktop\peixun\data_stop_word\stop_words.txt')#加载停用词sentence = sent_tokenizer(texts) # 分句words = [w for sentence in sentence for w in jieba.cut(sentence) if w not in stopwords iflen(w) > 1 and w != '\t'] # 词语,非单词词,同时非符号wordfre = nltk.FreqDist(words) # 统计词频topn_words = [w[0] for w in sorted(wordfre.items(), key=lambda d: d[1], reverse=True)][:topn_wordnum] # 取出词频最高的topn_wordnum个单词scored_sentences = score_sentences(sentence, topn_words)#给分句打分# 1,利用均值和标准差过滤非重要句子avg = numpy.mean([s[1] for s in scored_sentences]) # 均值std = numpy.std([s[1] for s in scored_sentences]) # 标准差mean_scored = [(sent_idx, score) for (sent_idx, score) in scored_sentences ifscore > (avg + 0.5 * std)] # sent_idx 分句标号,score得分# 2,返回top n句子top_n_scored = sorted(scored_sentences, key=lambda s: s[1])[-n:] # 对得分进行排序,取出n个句子top_n_scored = sorted(top_n_scored, key=lambda s: s[0]) # 对得分最高的几个分句,进行分句位置排序c = dict(mean_scoredsenteces=[sentence[idx] for (idx, score) in mean_scored])c1=dict(topnsenteces=[sentence[idx] for (idx, score) in top_n_scored])return c,c1if __name__=='__main__':texts = str(input('请输入文本:'))topn_wordnum=int(input('请输入高频词数:'))n=int(input('请输入要返回的句子个数:'))c,c1=results(texts,topn_wordnum,n)print(c)print(c1)结果如图:

相关文章:
自然语言处理:提取长文本进行文本主要内容(文本意思)概括 (两种方法,但效果都一般)
本文主要针对长文本进行文本提取和中心思想概括,原文档放在了附件里面:<科大讯飞公告> -----------------------------------方法一:jieba分词提取文本(句子赋分法)------------------------- 1、首先导入相关…...
基于SpringCloudAlibaba实现的NacosConfig
概述 Nacos除了实现了服务的注册发现之外,还将配置中心功能整合在了一起。通过Nacos的配置管理功能,我们可以将整个架构体系内的所有配置都集中在Nacos中存储。这样做的好处主要有以下几点: 分离的多环境配置,可以更灵活的管理权…...

景联文科技:高质量AI数据标注助力大语言模型训练,推动人工智能落地应用
大语言模型在各类LLM新技术的融会贯通下,不断加速Instruction-tuning、RLHF、思维链等新技术在大语言模型中的深度应用,人工智能技术以惊人的速度不断进化。 大语言模型(LLM)是一种基于深度学习技术和海量文本数据,它们…...

深度学习(前馈神经网络)知识点总结
用于个人知识点回顾,非详细教程 1.梯度下降 前向传播 特征输入—>线性函数—>激活函数—>输出 反向传播 根据损失函数反向传播,计算梯度更新参数 2.激活函数(activate function) 什么是激活函数? 在神经网络前向传播中&#x…...
)
点云从入门到精通技术详解100篇-点云信息编码(中)
目录 2.4.3 基于预测树结构的几何信息压缩算法 2.5 点云属性信息编码技术...

前端刷题-Promise系列
Promise系列 promise.all // 定义 Promise.all function (promises) {let count 0;let result [];return new Promise((resolve, reject) > {for (let i 0; i < promises.length; i) {promises[i].then((res) > {count;result[i] res;if (count promises.leng…...

3分钟:腾讯云免费SSL证书申请教程_免费HTTPS证书50张
2023腾讯云免费SSL证书申请流程,一个腾讯云账号可以申请50张免费SSL证书,免费SSL证书为DV证书,仅支持单一域名,申请腾讯云免费SSL证书3分钟即可申请成功,免费SSL证书品牌为TrustAsia亚洲诚信,腾讯云百科分享…...
如何快速成为一名优秀的python工程师?
随着人工智能的发展与应用,Python编程语言受到世界各界人士的关注,Python工程师也成为一个热门职业,就业薪资高,发展前景广阔。 Python是一门简单的编程语言,学习相对更加轻松容易,初学者很容易入门&#…...
:Hive导出数据到Oracle)
Sqoop(二):Hive导出数据到Oracle
把Hive中的数据导入Oracle数据库。 1. 解释一下各行代码: sqoop export # 指定要从Hive中导出的表 --table TABLE_NAME # host_ip:导入oracle库所在的ip:导入的数据库 --connect jdbc:oracle:thin:HOST_IP:DATABASE_NAME # oracle用户账号 --username USERNAM…...

HTML数字倒计时效果附源码
HTML页面代码 <!DOCTYPE html> <html><head><meta http-equiv="content-type" content...
以udp协议创建通信服务器
概念图 创建服务器让A,B主机完成通信。 认识接口 socket 返回值:套接字,你可以认为类似fd 参数: domain->:哪种套接字,常用AF_INET(网络套接字)、AF_LOCAL(本地套接字)type->:发送数据类型,常用 …...

【数据结构】队列篇| 超清晰图解和详解:循环队列模拟、用栈实现队列、用队列实现栈
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: 是瑶瑶子啦每日一言🌼: 每一个不曾起舞的日子,都是对生命的辜负。——尼采 目录 一、 模拟实现循环队列二、用栈实现队列⭐三、225. 用队列实现栈 一、…...

js+html实现打字游戏v2
实现逻辑,看jshtml实现打字游戏v1,在此基础之上增加了从文件读取到的单词,随机选取10个单词。 效果演示 上代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8">&l…...
Python之作业(一)
Python之作业(一) 作业 打印九九乘法表 用户登录验证 用户依次输入用户名和密码,然后提交验证用户不存在、密码错误,都显示用户名或密码错误提示错误3次,则退出程序验证成功则显示登录信息 九九乘法表 代码分析 先…...

uni-app 之 v-on:click点击事件
uni-app 之 v-on:click点击事件 image.png <template><!-- vue2的<template>里必须要有一个盒子,不能有两个,这里的盒子就是 view--><view>--- v-on:click点击事件 ---<view v-on:click"onclick">{{title}}<…...

迁移学习:实现快速训练和泛化的新方法
文章目录 迁移学习的原理迁移学习的应用快速训练泛化能力提升 迁移学习的代码示例拓展应用与挑战结论 🎉欢迎来到AIGC人工智能专栏~迁移学习:实现快速训练和泛化的新方法 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页:IT陈寒的博…...
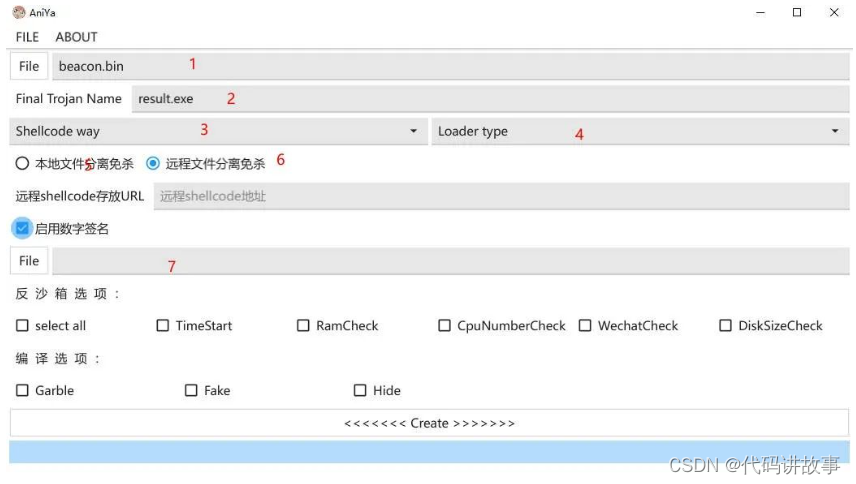
蓝队追踪者工具TrackAttacker,以及免杀马生成工具
蓝队追踪者工具TrackAttacker,以及免杀马生成工具。 做过防守的都知道大HW时的攻击IP量,那么对于这些攻击IP若一个个去溯源则显得效率低下,如果有个工具可以对这些IP做批量初筛是不是更好? 0x2 TrackAttacker获取 https://githu…...
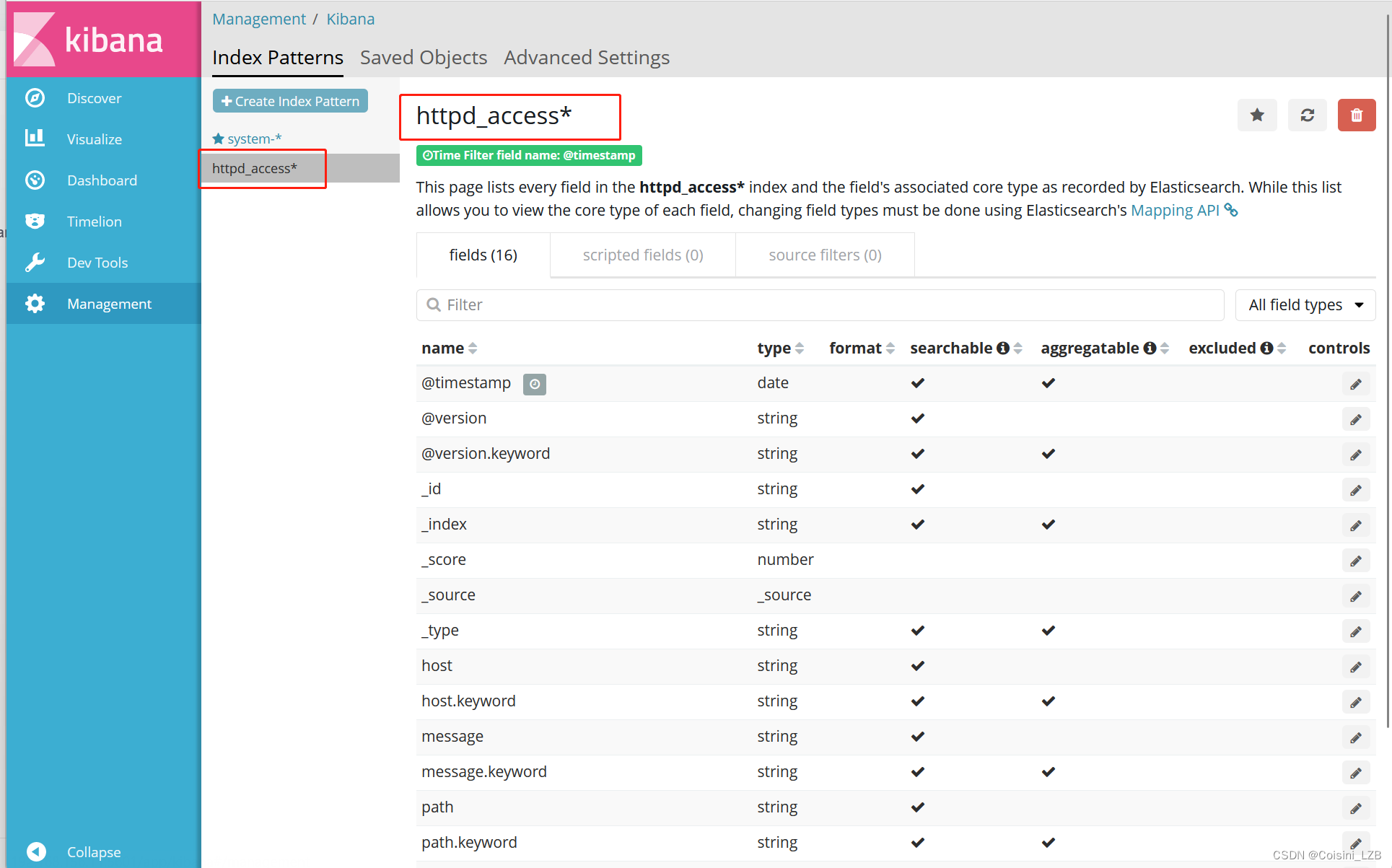
ELK日志收集系统(四十九)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 二、组件 1. elasticsearch 2. logstash 2.1 工作过程 2.2 INPUT 2.3 FILETER 2.4 OUTPUTS 3. kibana 三、架构类型 3.1 ELK 3.2 ELKK 3.3 ELFK 3.5 EF…...
Linux知识点 -- Linux多线程(四)
Linux知识点 – Linux多线程(四) 文章目录 Linux知识点 -- Linux多线程(四)一、线程池1.概念2.实现3.单例模式的线程池 二、STL、智能指针和线程安全1.STL的容器是否是线程安全的2.智能指针是否是线程安全的 三、其他常见的各种锁…...
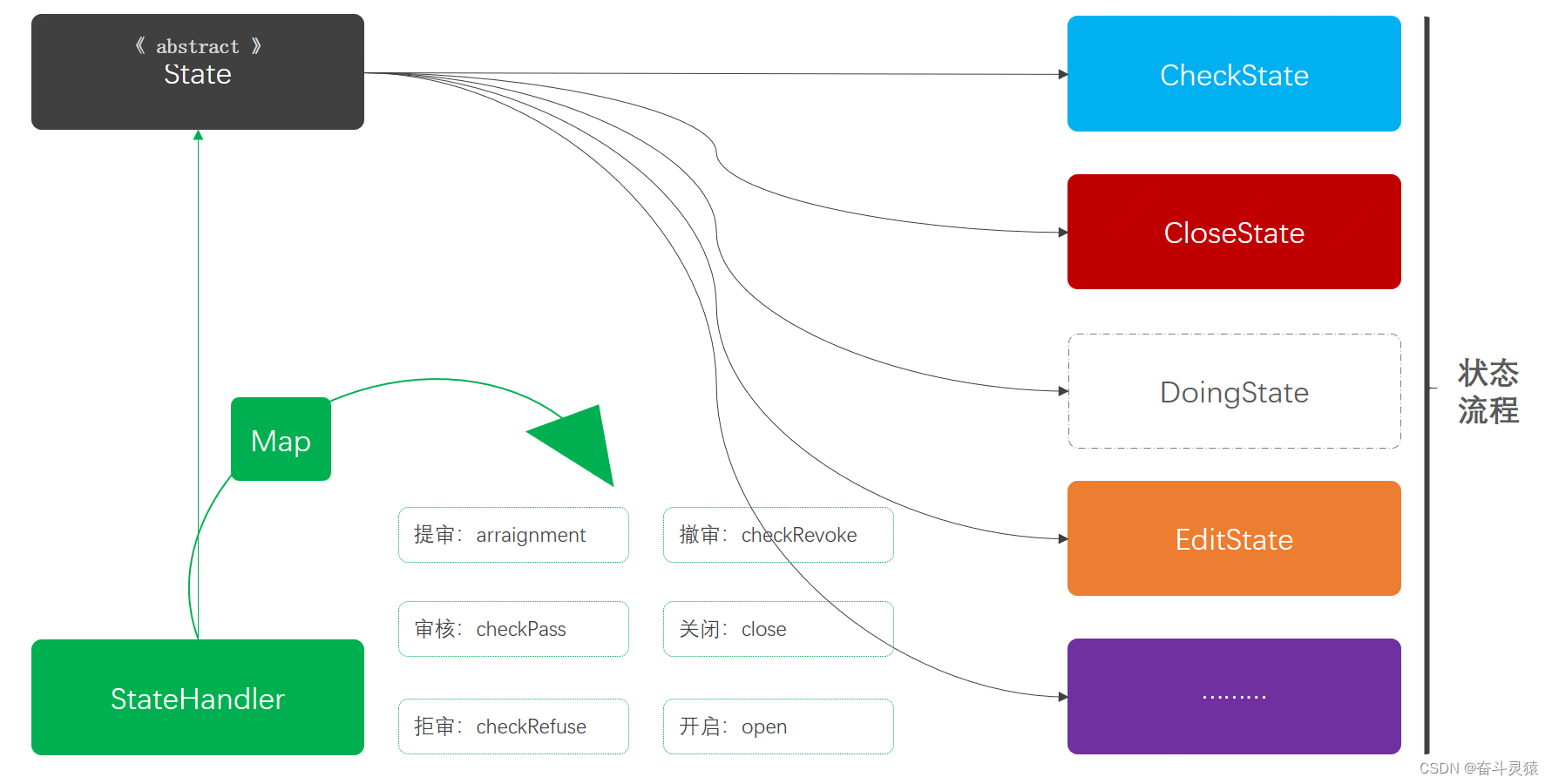
Java设计模式:四、行为型模式-07:状态模式
文章目录 一、定义:状态模式二、模拟场景:状态模式2.1 状态模式2.2 引入依赖2.3 工程结构2.4 模拟审核状态流转2.4.1 活动状态枚举2.4.2 活动信息类2.4.3 活动服务接口2.4.4 返回结果类 三、违背方案:状态模式3.0 引入依赖3.1 工程结构3.2 活…...

SAP ABAP BADI AC_DOCUMENT:跨越VF01/MIRO/AFAB的智能凭证替代实战
1. 为什么需要AC_DOCUMENT BADI? 在SAP标准业务流程中,GGB1提供的凭证替代功能已经能满足大部分常规需求。但实际业务往往更复杂——比如销售开票时,需要根据付款条件动态替换税科目;发票校验时,要根据供应商信息自动填…...

Task Slack集成:团队协作的任务管理终极指南
Task Slack集成:团队协作的任务管理终极指南 【免费下载链接】task A fast, cross-platform build tool inspired by Make, designed for modern workflows. 项目地址: https://gitcode.com/gh_mirrors/ta/task Task 是一款受 Make 启发的快速跨平台构建工具…...

ARM Cortex-R52 GIC架构详解与中断管理实践
1. Cortex-R52 GIC架构概述ARM Cortex-R52处理器采用的通用中断控制器(GIC)架构是嵌入式实时系统的中断管理核心。作为GICv2架构的实现,它通过硬件级的中断路由和优先级管理机制,为多核实时应用提供了确定性的中断响应能力。在汽车电子和工业控制领域&am…...

ScienceClaw:基于Python的学术爬虫工具,高效抓取文献与课程资料
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“ScienceClaw”,作者是beita6969。光看这个名字,你可能觉得有点摸不着头脑——“科学爪”?这到底是干嘛的?作为一个在开源社区混迹多年的老鸟…...

AI应用配置管理实战:从环境变量到多租户架构的工程化解决方案
1. 项目概述:AI配置管理的“瑞士军刀”最近在折腾AI应用开发,特别是那些需要调用不同模型、处理复杂提示词的项目时,配置管理简直是个噩梦。每个模型API的密钥格式不一样,提示词模板散落在各个脚本里,环境变量多得记不…...

收藏!AI时代程序员转型指南:从纯编码到人机协同高手
本文揭示了AI对程序员行业的深刻变革:初级编码岗需求锐减,而AI协作、架构师等高端岗位需求激增。文章提出两个阶段提升竞争力:第一阶段掌握AI工具栈(编码助手、调试工具等)并遵循人机协同法则;第二阶段构建…...

从零构建高效项目脚手架:自动化项目初始化与最佳实践
1. 项目概述:一个为开发者准备的“瑞士军刀”式工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫jpKuji/clawstrate。乍一看这个名字,有点摸不着头脑,既不像常见的框架名,也不像某个具体的应用。点进…...

将Taotoken作为内部AI中台统一对接各类客户端工具
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将Taotoken作为内部AI中台统一对接各类客户端工具 设想一个中型研发团队,内部已经引入了Claude Code、OpenClaw等多种A…...

Windows平台APK部署技术探索:轻量级安卓应用安装实践指南
Windows平台APK部署技术探索:轻量级安卓应用安装实践指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用开发与部署日益普及的今天࿰…...

Bevy引擎拾取系统:从射线检测到事件冒泡的完整交互方案
1. 项目概述与核心价值在构建交互式应用,尤其是游戏或3D编辑器时,一个基础且高频的需求就是让用户能够用鼠标、触摸屏等指针设备与屏幕上的物体进行交互。简单来说,就是“点选”功能。在Bevy引擎的早期版本中,这个看似简单的功能实…...