MySQL 主从复制与读写分离
1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
2、为什么要读写分离呢?
因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的。
但是数据库的“读”(读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
4、主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
5、mysq支持的复制类型
(1)STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制,执行效率高。
(2)ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一遍。
(3)MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。
6、主从复制的工作过程
(1)Master节点将数据的改变记录成二进制日志(bin log),当Master上的数据发生改变时,则将其改变写入二进制日志中。
(2)Slave节点会在一定时间间隔内对Master的二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O线程请求 Master的二进制事件。
(3)同时Master节点为每个I/O线程启动一个dump线程,用于向其发送二进制事件,并保存至Slave节点本地的中继日志(Relay log)中,Slave节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,即解析成 sql 语句逐一执行,使得其数据和 Master节点的保持一致,最后I/O线程和SQL线程将进入睡眠状态,等待下一次被唤醒。
注:
●中继日志通常会位于 OS 缓存中,所以中继日志的开销很小。
●复制过程有一个很重要的限制,即复制在 Slave上是串行化的,也就是说 Master上的并行更新操作不能在 Slave上并行操作。
============MySQL主从复制延迟=============
1、master服务器高并发,形成大量事务
2、网络延迟
3、主从硬件设备导致
cpu主频、内存io、硬盘io
4、本来就不是同步复制、而是异步复制
从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。
从库使用SSD磁盘
网络优化,避免跨机房实现同步
7、MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
8、目前较为常见的 MySQL 读写分离分为以下两种:
1)基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。
优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。
但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
2)基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序。
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。
Master 服务器:192.168.10.15 mysql5.7
Slave1 服务器:192.168.10.14 mysql5.7
Slave2 服务器:192.168.10.16 mysql5.7
Amoeba 服务器:192.168.10.13 jdk1.6、Amoeba
客户端 服务器:192.168.10.13 mysql
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
----------------------搭建 MySQL主从复制--------------------------------
----Mysql主从服务器时间同步----
##主服务器设置##
yum install ntp -y
vim /etc/ntp.conf
--末尾添加--
server 127.127.80.0 #设置本地是时钟源,注意修改网段
fudge 127.127.80.0 stratum 8 #设置时间层级为8(限制在15内)
service ntpd start
##从服务器设置##
yum install ntp ntpdate -y
service ntpd start
/usr/sbin/ntpdate 192.168.80.10 #进行时间同步
crontab -e
*/30 * * * * /usr/sbin/ntpdate 192.168.80.10
----主服务器的mysql配置-----
vim /etc/my.cnf
server-id = 11
log-bin=master-bin #添加,主服务器开启二进制日志
binlog_format = MIXED
log-slave-updates=true #添加,允许slave从master复制数据时可以写入到自己的二进制日志
systemctl restart mysqld
mysql -u root -pabc123
GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.10.%' IDENTIFIED BY '123456'; #给从服务器授权
FLUSH PRIVILEGES;
show master status;
//如显示以下
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| master-bin.000001 | 603 | | |
+-------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
#File 列显示日志名,Position 列显示偏移量
----从服务器的mysql配置----
vim /etc/my.cnf
server-id = 22 #修改,注意id与Master的不同,两个Slave的id也要不同
relay-log=relay-log-bin #添加,开启中继日志,从主服务器上同步日志文件记录到本地
relay-log-index=slave-relay-bin.index #添加,定义中继日志文件的位置和名称,一般和relay-log在同一目录
relay_log_recovery = 1 #选配项
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启。
systemctl restart mysqld
mysql -u root -pabc123
CHANGE master to master_host='192.168.80.10',master_user='myslave',master_password='123456',master_log_file='master-bin.000002',master_log_pos=339; #配置同步,注意 master_log_file 和 master_log_pos 的值要与Master查询的一致
CHANGE master to master_host='192.168.10.15',master_user='myslave',master_password='123456',master_log_file='master-bin.000001',master_log_poss=603;
start slave; #启动同步,如有报错执行 reset slave;
show slave status\G #查看 Slave 状态
//确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes #负责与主机的io通信
Slave_SQL_Running: Yes #负责自己的slave mysql进程
#一般 Slave_IO_Running: No 的可能性:
1、网络不通
2、my.cnf配置有问题
3、密码、file文件名、pos偏移量不对
4、防火墙没有关闭
----验证主从复制效果----
主服务器上进入执行 create database db_test;
去从服务器上查看 show databases;
注:如数据中途加入主从复制的库 需要导出主服务器库 的库文件并且导入到从服务器中
Master 服务器:192.168.10.15 mysql5.7
Slave1 服务器:192.168.10.14 mysql5.7
Slave2 服务器:192.168.10.16 mysql5.7
Amoeba 服务器:192.168.10.13 jdk1.6、Amoeba
客户端 服务器:192.168.10.13 mysql
注:做读写分离实验之前必须有一 主 两从 环境
----------------------搭建 MySQL读写分离--------------------------------
----Amoeba服务器配置----
##安装 Java 环境##
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64
./jdk-6u14-linux-x64.bin
//按yes,按enter
mv jdk1.6.0_14/ /usr/local/jdk1.6
vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile
java -version
##安装 Amoeba软件##
mkdir /usr/local/amoeba
tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功
##配置 Amoeba读写分离,两个 Slave 读负载均衡##
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
grant all on *.* to test@'192.168.80.%' identified by '123.com';
grant all on *.* to test@'192.168.10.%' identified by '123456';
#再回到amoeba服务器配置amoeba服务:
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #修改amoeba配置文件
--30行--
<property name="user">amoeba</property>
--32行--
<property name="password">123456</property>
--115行--
<property name="defaultPool">master</property>
--117-去掉注释-
<property name="writePool">master</property>
<property name="readPool">slaves</property>
cp dbServers.xml dbServers.xml.bak
vim dbServers.xml #修改数据库配置文件
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改
<property name="user">test</property>
--28-30--去掉注释
<property name="password">123456</property>
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.10.15</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.10.14</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.10.16</property>
--65行--修改
<dbServer name="slaves" virtual="true">
--71行--修改
<property name="poolNames">slave1,slave2</property>
/usr/local/amoeba/bin/amoeba start& #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066
----测试读写分离 ----
yum install -y mariadb-server mariadb
systemctl start mariadb.service
在客户端服务器上测试:
mysql -u amoeba -p123456 -h 192.168.10.13 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
在主服务器上:
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));
在两台从服务器上:
stop slave; #关闭同步
use db_test;
//在slave1上:
insert into test values('1','zhangsan','this_is_slave1');
//在slave2上:
insert into test values('2','lisi','this_is_slave2');
//在主服务器上:
insert into test values('3','wangwu','this_is_master');
//在客户端服务器上:
use db_test;
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据
//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;
面试题
1、主从同步复制原理
2、读写分离你们使用什么方式?
3、如何查看主从同步状态是否成功
4、如果I/O不是yes呢,你如何排查?
5、show slave status能看到哪些信息(比较重要)
6、主从复制慢(延迟)会有哪些可能?怎么解决?
总结+面试题
1、主从同步复制原理
2、读写分离你们使用什么方式? amoeba 代理 mycat 代码 sql_proxy
通过amoeba代理服务器,实现只在主服务器上写,只在从服务器上读;
主数据库处理事务性查询,从数据库处理select 查询;
数据库复制被用来把事务查询导致的变更同步的集群中的从数据库
3、如何查看主从同步状态是否成功
在从服务器上内输入 show slave status\G 查看主从信息查看里面有IO线程的状态信息,还有master服务器的IP地址、端口事务开始号。
当 Slave_IO_Running和Slave_SQL_Running都是YES时 ,表示主从同步状态成功
4、如果I/O不是yes呢,你如何排查?
首先排查网络问题,使用ping 命令查看从服务器是否能与主服务器通信
再查看防火墙和核心防护是否关闭(增强功能)
接着查看从服务slave是否开启
两个从服务器的server-id 是否相同导致只能连接一台
master_log_file master_log_pos的值跟master值是否一致
5、show slave status能看到哪些信息(比较重要)
IO线程的状态信息
master服务器的IP地址、端口、事务开始的位置
最近一次的错误信息和错误位置
最近一次的I/O报错信息和ID
最近一次的SQL报错信息和id
6、主从复制慢(延迟)会有哪些可能?怎么解决?
主服务器的负载过大,被多个睡眠或 僵尸线程占用 导致系统负载过大,从库硬件比主库差,导致复制延迟
主从复制单线程,如果主库写作并发太大,来不及传送到从库,就会到导致延迟
慢sql语句过多
网络延迟
mysql主从复制
若主从版本不一致,从的版本一定要高于主,保证可以向下兼容
因为若主的版本更新,低版本的从无法兼容的。
相关文章:

MySQL 主从复制与读写分离
1、什么是读写分离? 读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。 2、为什么…...

Linux环境基础开发工具
xshellssh xshell--充当客户端,提供远程登录服务 yum 背景知识 在Linux下安装软件, 一个通常的办法是下载到程序的源代码, 并进行编译, 得到可执行程序. 但是这样太麻烦了, 于是有些人把一些常用的软件提前编译好, 做成软件包(可以理解成windows上的安装程序)放…...

uni-app+uView实现点击查看大图片的效果
<u-button text"月落" click"imgPreview()"></u-button> //注意:参数urls 是预览图片的链接地址,是个数组 imgPreview() {uni.previewImage({indicator: "none",loop: false,urls: [],}) },参数说…...

Sulfo-CY3 azide在细胞标记与成像中的应用-星戈瑞
Sulfo-CY3azide作为荧光探针在细胞标记与成像中应用,它可以用于实现对细胞内特定分子或细胞结构的标记,从而实现对细胞的可视化和实时成像。以下是Sulfo-CY3azide在细胞标记与成像中的应用: 1.细胞膜标记:Sulfo-CY3azide可以与细…...

js如何遍历对象的key和value
在JavaScript中,可以使用for…in循环来遍历对象的键(key)和值(value)。以下是一个示例: let obj { key1: value1, key2: value2, key3: value3 }; for (let key in obj) { if (obj.hasOwnProperty…...
官方发布:Mac 版 Visual Studio IDE将于明年 8 月 31 日停止支持
近日,微软官方宣布:适用于 Mac 平台的 Visual Studio 集成开发环境(IDE)已经启动 "退休" 进程。Visual Studio for Mac 17.6 将继续支持 12 个月,持续到 2024 年 8 月 31 日。 微软表示在未来的 1 年内将重…...

如何使用CSS实现一个带有动画效果的折叠面板(Accordion)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 带有动画效果的折叠面板(Accordion)⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个…...

HarmonyOS开发:探索动态共享包的依赖与使用
前言 所谓共享包,和Android中的Library本质是一样的,目的是为了实现代码和资源的共享,在HarmonyOS中,给开发者提供了两种共享包,HAR(Harmony Archive)静态共享包,和HSP(H…...

【力扣】45.跳跃游戏 II <贪心>
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处:0 < j < nums[i] ;i j < n 返回到…...
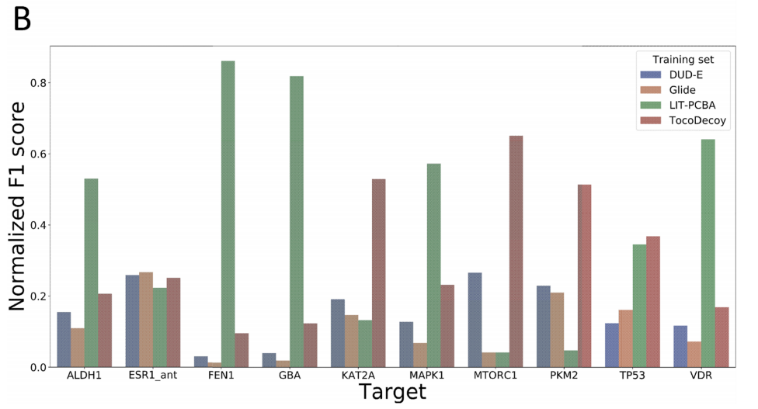
J. Med. Chem 2022|TocoDecoy+: 针对机器学习打分函数训练和测试的无隐藏偏差的数据集构建新方法
原文标题:TocoDecoy: A New Approach to Design Unbiased Datasets for Training and Benchmarking Machine-Learning Scoring Functions 论文链接:https://pubs.acs.org/doi/10.1021/acs.jmedchem.2c00460 论文代码:GitHub - 5AGE-zhang/T…...
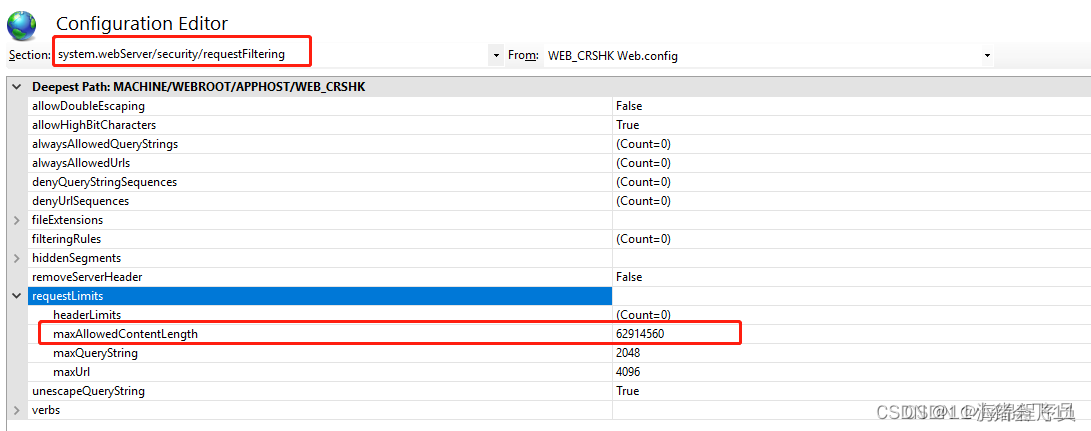
.net core 上传文件大小限制
微软官网文档中给的解释是.net core 默认上传文件大小限制是30M,所以即便你项目里没有限制,这里也有个默认限制。 官网链接地址 总结了一下解决办法: 1.首先项目里添加一个web.config自定义配置文件 在配置文件中加上这段配置 <!--//…...
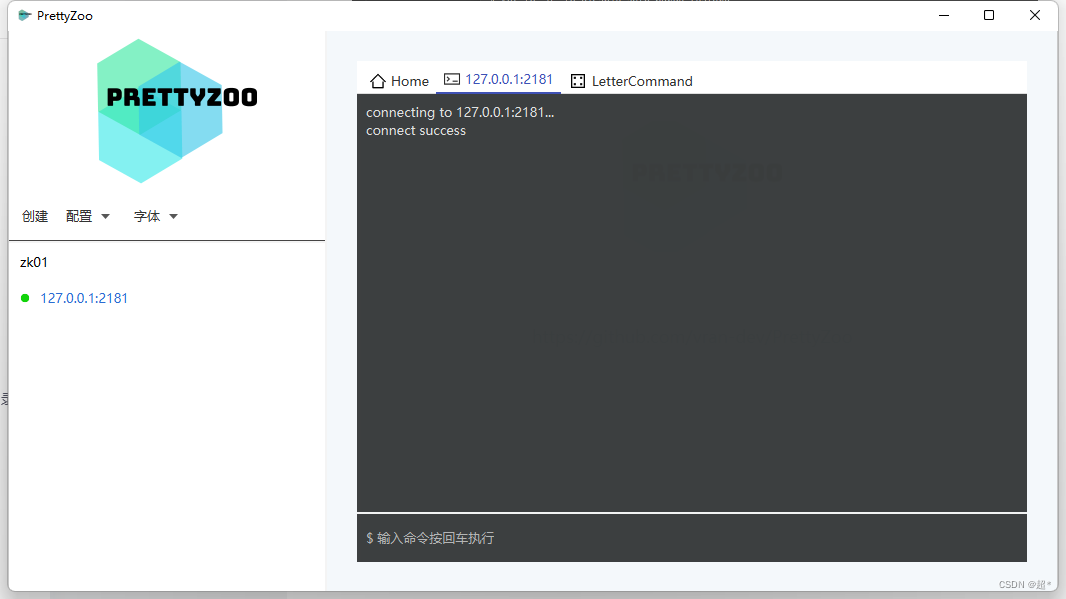
Windows安装单节点Zookeeper
刚学习Dubbo,在Centos7中docker安装的zookeeper3.7.1。然后在启动provider时一直报错,用尽办法也没有解决。然后zookeeper相关的知识虽然以前学习过,但是已经忘记的差不多了。现在学习dubbo只能先降低版本使用了,之后再复习zookee…...

C++ gendrate Gauss noise
手动生成 Marsaglia和Bray在1964年提出,C版本如下: mu是均值,sigma是方差,X服从N(0,1)分布 高斯噪声为加性噪声,在原图的基础上加上噪声即为加噪后的图象。 double generateGaussianNoise(double mu, double sigma) {static double V1, V2, S;static int phase 0;double X;d…...

centos环境下idea开发问题集锦
1、端口不能访问,可能是访问的协议问题或者防火墙拦截为问题导致。 1.1 centos环境下idea直接拉起部署,查看端口信息如下,命令为 [rootlocalhost ~]# lsof -i:8088 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME java …...

C++-list实现相关细节和问题
前言:C中的最后一个容器就是list,list是可以在常数范围内在任意位置进行插入和删除的序列式容器,并且该容器可以前后双向迭代。list的底层是双向链表结构,双向链表中每个元素存储在互不相关的独立节点中,在节点中通过指…...

hadoop学习:mapreduce的wordcount时候,继承mapper没有对应的mapreduce的包
踩坑描述:在学习 hadoop 的时候使用hadoop 下的 mapreduce,却发现没有 mapreduce。 第一反应就是去看看 maven 的路径对不对 settings——》搜索框搜索 maven 检查一下 Maven 路径对不对 OK 这里是对的 那么是不是依赖下载失败导致 mapreduce 没下下…...
windows10上搭建caffe以及踩到的坑
对动作捕捉的几篇论文感兴趣,想复现一下,需要caffe环境就折腾了下!转模型需要python 2.7环境,我顺便也弄了!!! 1. 环境 Windows10 RTX2080TI 11G Anaconda Python2.7 visual studio 2013 cuda…...

大数据Flink(七十):SQL 动态表 连续查询
文章目录 SQL 动态表 & 连续查询 一、SQL 应用于流处理的思路...

「MySQL-04」Linux环境下使用C/C++连接并操纵MySQL
目录 一、准备mysql库:Connector/C 1. 查看是否有mysql相关的库和头文件 2. 安装devel(开发库) 3.到官网下载开发包,并上传到Linux 3.0 须知 3.1 到官网下载开发包 3.2 上传安装包至Linux 二、mysql库:Connector/C 的使用 1. 创建并初始化mys…...
)
【力扣】两数相除(c/c++)
目录 题目 注意: 示例 1: 示例 2: 提示: 题目解析 题目思路 代码思路 数据处理 注意 减法函数 第一次使用的函数 问题 第二次改良后的代码 处理i的值并且返回 总代码 力扣的代码 注意 题目 给你两个整数,被除数 dividend 和…...

基于RK3568的智能家居控制器:硬件选型、架构设计与软件实现全解析
1. 项目概述:为什么选择RK3568作为智能家居控制器的“大脑”?在智能家居这个赛道里摸爬滚打了十来年,我经手过不少方案,从早期的单片机到后来的ARM Cortex-A系列,再到如今百花齐放的各类SoC。每次做产品选型࿰…...

告别串口助手!用手机APP和ESP-01S模块,5分钟搞定51单片机无线控制LED
手机APP直连ESP-01S:零门槛实现51单片机LED无线控制 在物联网原型开发中,摆脱串口助手的束缚,直接用手机APP控制硬件设备,是许多初学者的迫切需求。本文将带你用最常见的ESP-01S模块和任意一款TCP调试APP,在5分钟内搭建…...

深度观察:从静态路牌到智能交互,城市导视系统的三次进化
当我们谈论智慧城市时,往往会聚焦于自动驾驶、智慧安防、数字政务这些宏大的叙事,却常常忽略了一个最贴近普通人生活的基础设施 —— 导视系统。作为城市空间的 "无声语言",导视系统连接着人与空间,影响着每一个人的出行…...

避坑指南:PyCharm 2023.3 + Anaconda 虚拟环境配置,绕开‘解释器路径选择界面消失’的陷阱
PyCharm 2023.3与Anaconda虚拟环境深度配置指南:从原理到实战避坑 在数据科学和机器学习项目的开发过程中,PyCharm与Anaconda的组合堪称黄金搭档。然而,当PyCharm 2023.3遇到Anaconda虚拟环境配置时,不少开发者会陷入"解释器…...

HarmonyOS 6 ArkGraphics 3D精讲:从旋转立方体看鸿蒙原生3D能力
HarmonyOS 6 ArkGraphics 3D精讲:从旋转立方体看鸿蒙原生3D能力 前言:从数字孪生到鸿蒙 3D 大家好,我是你们老朋友木斯佳,熟悉我的朋友们知道,我长期从事物联网、数据可视化相关开发。过去几年里,我在各种平…...

如何高效使用Avogadro 2:5个实用技巧带你掌握开源分子建模软件
如何高效使用Avogadro 2:5个实用技巧带你掌握开源分子建模软件 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, an…...

嵌入式开发避坑:S19/SREC文件地址重映射时,如何避免覆盖有效数据?
嵌入式开发实战:S19文件地址重映射的安全操作指南 在嵌入式系统开发中,固件升级和内存布局调整是工程师经常面临的挑战。当需要将校准参数、配置表等关键数据移动到新的内存区域时,如何确保操作的安全性成为关键问题。许多开发者都曾遇到过这…...

从源头到输出:开关电源纹波与噪声的精准抑制策略
1. 开关电源纹波与噪声的本质解析 第一次拆解开关电源时,我被电路板上密集的元器件和错综复杂的走线震撼到了。作为电源工程师,我们每天都在和这些看不见的"电脉冲"打交道——纹波就像电源的心跳,而噪声则是它偶尔的"咳嗽&qu…...
从Pooling到MetaFormer:深入解析PoolFormer如何用极简算子重塑视觉Transformer架构
1. 为什么说PoolFormer是Transformer的"极简主义革命"? 第一次看到PoolFormer的论文时,我正坐在咖啡馆调试一个复杂的Vision Transformer模型。当读到"用平均池化替代注意力机制"的设计时,差点把咖啡喷在键盘上——这简…...

联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案
联想拯救者工具箱终极指南:完全替代Vantage的轻量级硬件管理方案 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...