【JVM】垃圾收集算法
文章目录
- 分代收集理论
- 标记-清除算法
- 标记-复制算法
- 标记-整理算法
分代收集理论
当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(Generational Collection)[1]的理论进 行设计,分代收集名为理论,实质是一套符合大多数程序运行实际情况的经验法则,它建立在两个分代假说之上:
-
弱分代假说(Weak Generational Hypothesis):绝大多数对象都是朝生夕灭的。
-
强分代假说(Strong Generational Hypothesis):熬过越多次垃圾收集过程的对象就越难以消 亡。
把分代收集理论具体放到现在的商用Java虚拟机里,设计者一般至少会把Java堆划分为新生代 (Young Generation)和老年代(Old Generation)两个区域[2]。顾名思义,在新生代中,每次垃圾收集 时都发现有大批对象死去,而每次回收后存活的少量对象,将会逐步晋升到老年代中存放。
对于分代理论,由于会存在老年代引用新生代的情况,这对于回收对象时的判断会造成性能影响,所以还应该有下面假说
- 跨代引用假说(Intergenerational Reference Hypothesis):跨代引用相对于同代引用来说仅占极少数。
上面条结论可根据前两条假说逻辑推理得出的隐含推论:存在互相引用关系的两个对象,是应该倾向于同时生存或者同时消亡的。
下面是一些常见的分代收集名词
-
部分收集(Partial GC):指目标不是完整收集整个Java堆的垃圾收集,其中又分为:
-
新生代收集(Minor GC/Young GC):指目标只是新生代的垃圾收集。
-
老年代收集(Major GC/Old GC):指目标只是老年代的垃圾收集。目前只有CMS收集器会有单独收集老年代的行为。
-
混合收集(Mixed GC):指目标是收集整个新生代以及部分老年代的垃圾收集。目前只有G1收集器会有这种行为。
-
-
整堆收集(Full GC):收集整个Java堆和方法区的垃圾收集。
标记-清除算法
标记-清除算法(Mark and Sweep Algorithm)是一种经典的垃圾回收算法,用于识别和释放不再被引用的对象,从而回收内存空间。它包括两个主要阶段:标记(Mark)和清除(Sweep)。
下面是标记-清除算法的工作原理:
- 标记(Mark)阶段:
- 从根对象(通常是程序的入口点或全局变量)开始,遍历整个对象图,标记所有可以从根对象访问到的对象。
- 在这个阶段,被标记的对象通常被打上一个标记位或者加入一个"已标记"的集合中,以表示它们是活跃对象,仍然被引用。
- 清除(Sweep)阶段:
- 在清除阶段,垃圾回收器遍历整个堆内存,找到所有未被标记的对象,这些对象是不再被引用的对象。
- 未被标记的对象被认为是垃圾,垃圾回收器会将它们的内存空间标记为可用空闲空间,以供将来的对象分配使用。
- 清除后,堆内存中只剩下被标记的对象,而未被标记的对象的内存已经被释放。
上面有一点需要注意的是,标记对象可以是所有需要回收的对象,在标记完成后,统一回收掉所有被标记的对象,也可以反过来,标记存活的对象,统一回收所有未被标记的对象。
下面是标记-清除算法的示意图
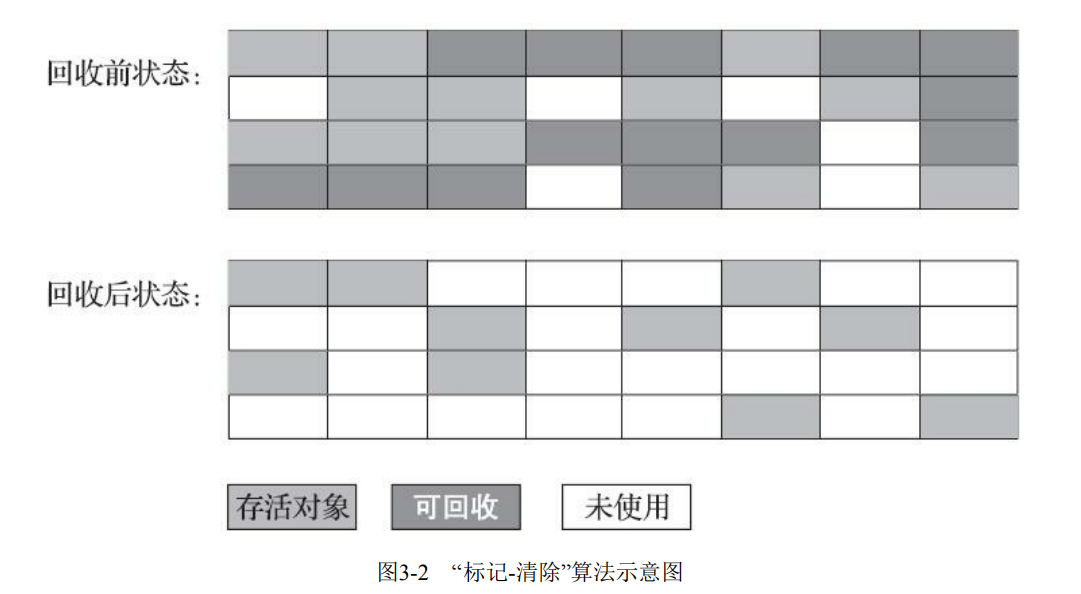
标记-清除算法的优点是它可以回收不再被引用的对象,但它也有一些缺点:
- 碎片问题:标记-清除算法会在内存中留下不连续的空闲块,可能导致内存碎片化问题。这会增加分配大对象时的空间不足问题的风险。
- 效率问题:标记-清除算法需要两次遍历整个堆内存:一次标记,一次清除。这会产生额外的性能开销,尤其是在清除阶段。
- 停顿问题:标记-清除算法在清除阶段需要停止应用程序的执行,因为它需要整个堆内存处于不变状态才能执行清除操作。这可能导致应用程序在垃圾回收期间出现停顿,影响用户体验。
标记-复制算法
标记-复制算法(Mark and Copy Algorithm)是一种用于垃圾回收的算法,它解决了标记-清除算法中出现的内存碎片问题。标记-复制算法主要用于新生代(Young Generation)的垃圾回收,通常分为两个阶段:标记(Mark)和复制(Copy)。
下面是标记-复制算法的工作原理:
-
标记(Mark)阶段:
- 从根对象(通常是程序的入口点或全局变量)开始,遍历整个对象图,标记所有可以从根对象访问到的对象,这些对象被认为是活跃对象。
- 在这个阶段,被标记的对象通常被打上一个标记位或者加入一个"已标记"的集合中,以表示它们是活跃对象,仍然被引用。
-
复制(Copy)阶段:
- 在复制阶段,垃圾回收器会将所有被标记为活跃对象的对象从一个区域(通常称为"From"或"Eden"区)复制到另一个区域(通常称为"To"或"Survivor"区)。
- 复制后,所有被复制的对象都连续排列在一起,没有碎片,而"From"区变成了空的。
-
清理(Clean-Up)阶段:
- 清理阶段不再需要被复制的对象,因此整个"From"区可以被清空,成为新的可用空间,用于将来的对象分配。
示意图如下
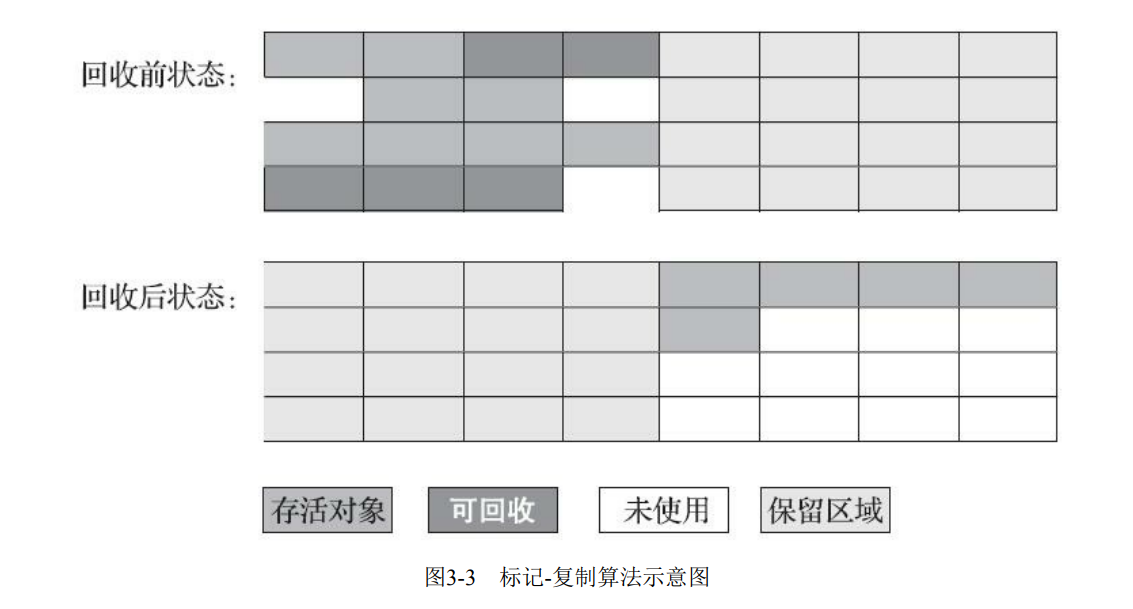
标记-复制算法的主要优点是它有效地解决了内存碎片问题。因为被复制的对象都被整齐地排列在一起,"From"区变为空,所以不会出现内存碎片化的情况。这提高了内存的利用率,减少了分配大对象时可能出现的空间不足问题。缺点就是比较浪费空间。
标记-复制算法主要用于新生代的垃圾回收,而老年代通常使用其他算法,如标记-清除或标记-整理算法。这些不同的垃圾回收算法结合在一起,构成了现代Java虚拟机中的复杂垃圾回收策略,以提高内存管理的效率和性能。
标记-整理算法
标记-整理算法(Mark and Compact Algorithm)是一种用于垃圾回收的算法,通常用于老年代(Old Generation)的内存回收。它是标记-清除算法的改进版本,主要解决了标记-清除算法可能导致的内存碎片问题。
相较于标记-清楚算法只是多了一个整理的过程
整理(Compact)阶段:
- 在整理阶段,垃圾回收器会将所有被标记为活跃对象的对象向一端移动,以便它们连续排列在一起。同时,未被标记/被标记的对象都被认为是垃圾,不再需要,它们的内存空间会被释放。
- 整理后,内存中的活跃对象变得更加紧凑,没有碎片,可以提高内存的利用率。
示意图如下
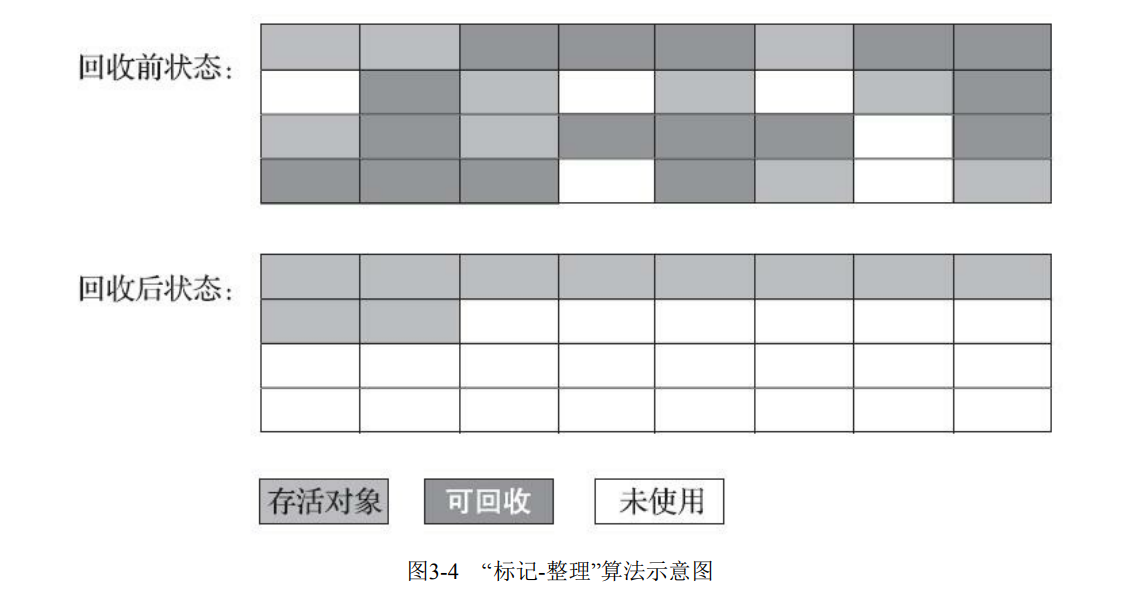
相关文章:
【JVM】垃圾收集算法
文章目录 分代收集理论标记-清除算法标记-复制算法标记-整理算法 分代收集理论 当前商业虚拟机的垃圾收集器,大多数都遵循了“分代收集”(Generational Collection)[1]的理论进 行设计,分代收集名为理论,实质是一套符…...
K8s的Pod出现Init:ImagePullBackOff问题的解决(以calico为例)
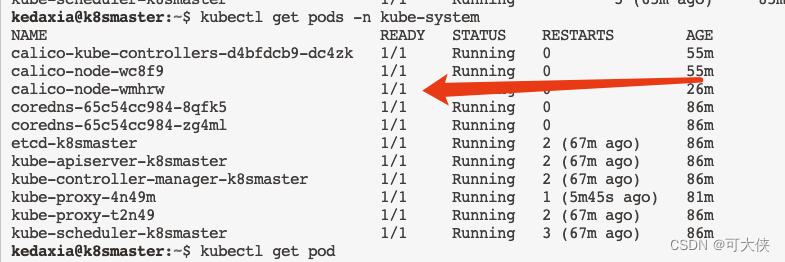
对于这类问题的解决思路应该都差不多,本文以calico插件安装为例,发现有个Pod的镜像没有pull成功 第一步:查看这个pod的描述信息 kubectl describe pod calico-node-wmhrw -n kube-system 从上图发现是docker拉取"calico/cni:v3.15.1&q…...
数据结构 -作用及基本概念
为什么要使用数据结构 学习数据结构是计算机科学和软件工程领域中非常重要的一门课程。以下是学习数据结构的几个重要原因: 组织和管理数据:数据结构提供了一种组织和管理数据的方式。通过学习不同的数据结构,你可以了解如何有效地存储和操作…...
数学建模--时间序列预测模型的七种经典算法的Python实现
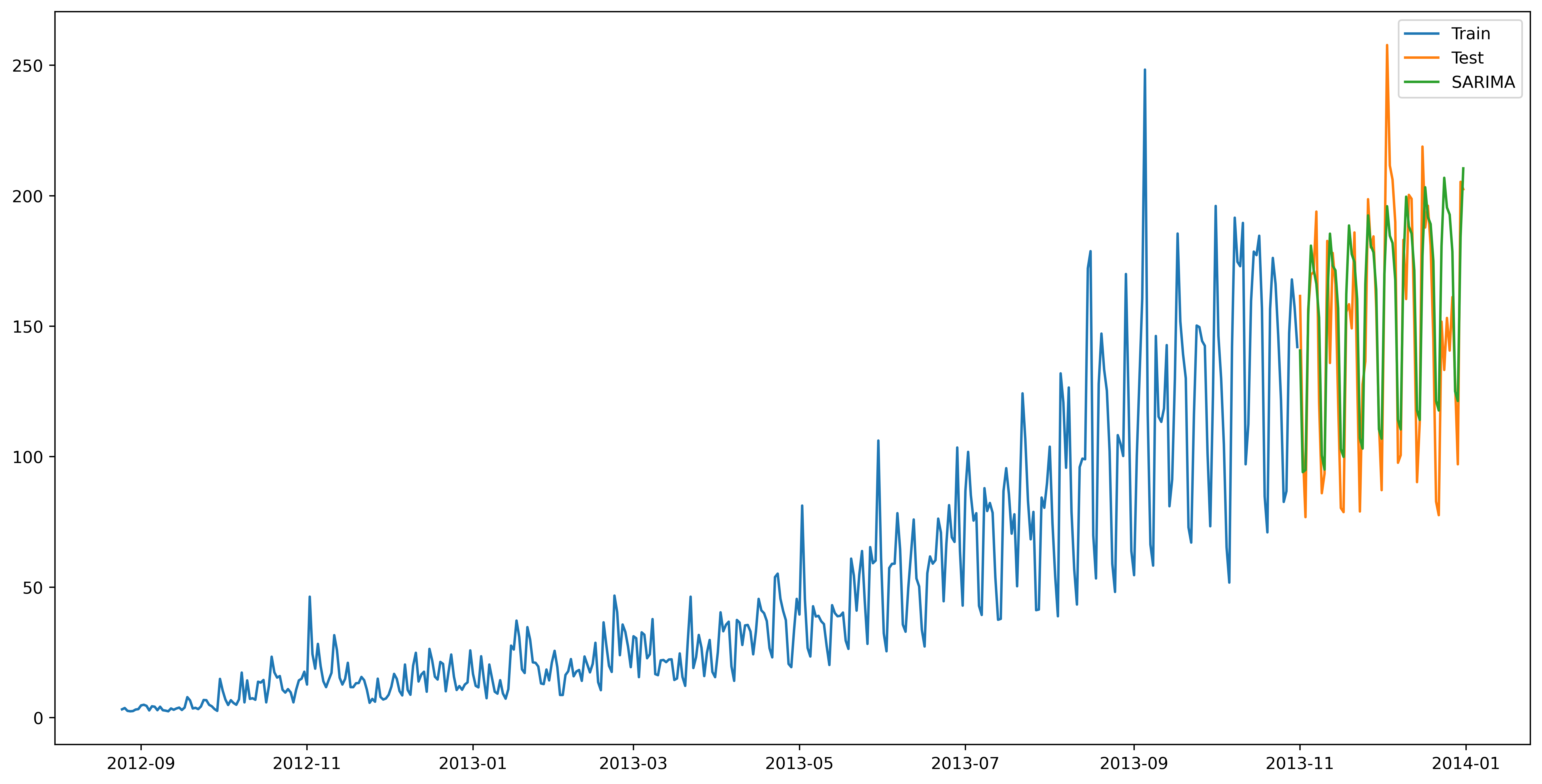
目录 1.开篇版权提示 2.时间序列介绍 3.项目数据处理 4.项目数据划分可视化 5.时间预测序列经典算法1:朴素法 6.时间预测序列经典算法2: 简单平均法 7.时间预测序列经典算法3:移动平均法 8.时间预测序列经典算法4:简单指…...
nginx-反向代理缓存
反向代理缓存相当于自动化动静分离。 将上游服务器的资源缓存到nginx本地,当下次再有相同的资源请求时,直接讲nginx缓存的资源返回给客户端。 本地缓存资源有一个过期时间,当超过过期时间,则重新向上游服务器重新请求获取资源。…...

大模型重塑区域人才培养,飞桨(重庆)人工智能教育创新中心正式启动
2023年8月22日,重庆市高校人工智能产教融合院长研讨会暨飞桨(重庆)人工智能教育创新中心启动仪式在重庆大学成功召开。会上,由百度飞桨、重庆大学组织重庆市二十一所高校共建的飞桨(重庆)人工智能教育创新中…...

PAT 1164 Good in C 测试点3,4
个人学习记录,代码难免不尽人意。 When your interviewer asks you to write “Hello World” using C, can you do as the following figure shows? Input Specification: Each input file contains one test case. For each case, the first part gives the 26 …...
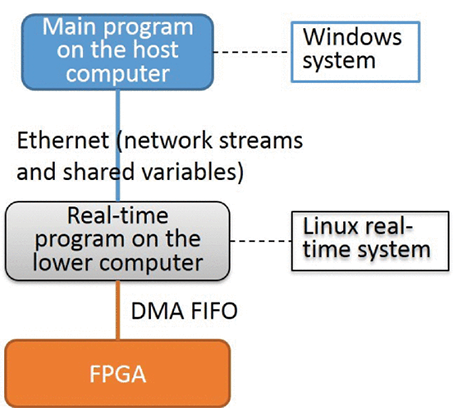
LabVIEW对EAST长脉冲等离子体运行的陀螺稳态运行控制
LabVIEW对EAST长脉冲等离子体运行的陀螺稳态运行控制 托卡马克是实现磁约束核聚变最有希望的解决方案之一。电子回旋共振加热(ECRH是一种对托卡马克有吸引力的等离子体加热方法,具有耦合效率高,功率沉积定位好等优点。陀螺加速器是ECRH系统中…...

Fragment
Fragment是Android开发中的一个重要组件,用于构建灵活且可重用的用户界面模块。它可以作为Activity的一部分来展示用户界面,并且可以嵌套在其他Fragment中,从而形成复杂的界面层级。 以下是一个简单的示例,展示了如何在Android中…...

哈希表-救赎金
Leetcode: https://leetcode.cn/problems/ransom-note/?envTypestudy-plan-v2&envIdtop-interview-150 给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。 如果可以,返回 true …...

vue3+vite+ts项目适配各种分辨率解决方案
现在的电脑屏幕和尺寸越来越多样化,对于前端开发来说,适配各种屏幕成了大难题,开发中一个实际例子:开发一个导航栏,ui给的是1920*60的尺寸,前端开发的时候,在自己电脑缩放比例中开发的ÿ…...
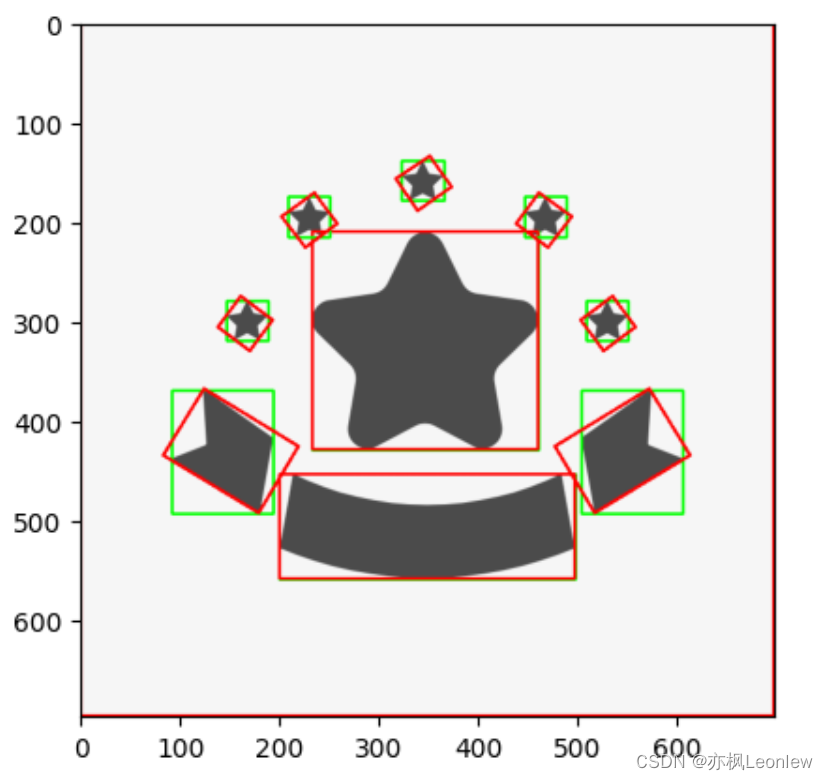
Python Opencv实践 - 矩形轮廓绘制(直边矩形,最小外接矩形)
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/stars.png") plt.imshow(img[:,:,::-1])img_gray cv.cvtColor(img, cv.COLOR_BGR2GRAY) #通过cv.threshold转换为二值图 ret,thresh cv.threshold(img_gray,…...

大数据HBASE的详细使用
摘要:本文将深入探讨大数据HBASE的使用步骤,帮助读者了解和掌握这一强大的分布式数据库系统的基本概念和操作技巧。通过本文的阅读,读者将能够熟悉HBASE的基本设置,了解其核心概念,掌握基本的查询和管理操作࿰…...
Sentinel 流量控制框架
1. Sentinel 是什么? Sentinel是由阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件。 2. 主要优势和特性 轻量级,核心库无多余依赖,性能损耗小。 方便接入,开源生态广泛。 丰富的流量控制场景。 …...

leetcode原题: 跳水板
题目: 你正在使用一堆木板建造跳水板。有两种类型的木板,其中长度较短的木板长度为shorter,长度较长的木板长度为longer。你必须正好使用k块木板。编写一个方法,生成跳水板所有可能的长度。 返回的长度需要从小到大排列。 示例&…...

深度学习入门(Python)学习笔记1
第1章 Python入门 1.1python是什么 Python是一个简单、易读、易记的编程语言,而且是开源的,可以免费地自由使用。 使用Python不仅可以写出可读性高的代码,还可以写出性能高(处理速度快)的代码。 再者,在…...
苏州想要获得融资融券低利率账户的方法?怎么开融资融券账户?
想要获得融资融券低利率账户,可以通过以下几种方式: 选择低费率的券商:不同券商的费率不同,一些券商会提供低利率的融资融券账户,可以通过咨询券商或者比较不同券商的费率来找到最佳账户。 提升自身信用:获…...

【LeetCode周赛】LeetCode第359场周赛
LeetCode第359场周赛 判别首字母缩略词k-avoiding 数组的最小总和销售利润最大化找出最长等值子数组 判别首字母缩略词 给你一个字符串数组 words 和一个字符串 s ,请你判断 s 是不是 words 的 首字母缩略词 。 如果可以按顺序串联 words 中每个字符串的第一个字符…...
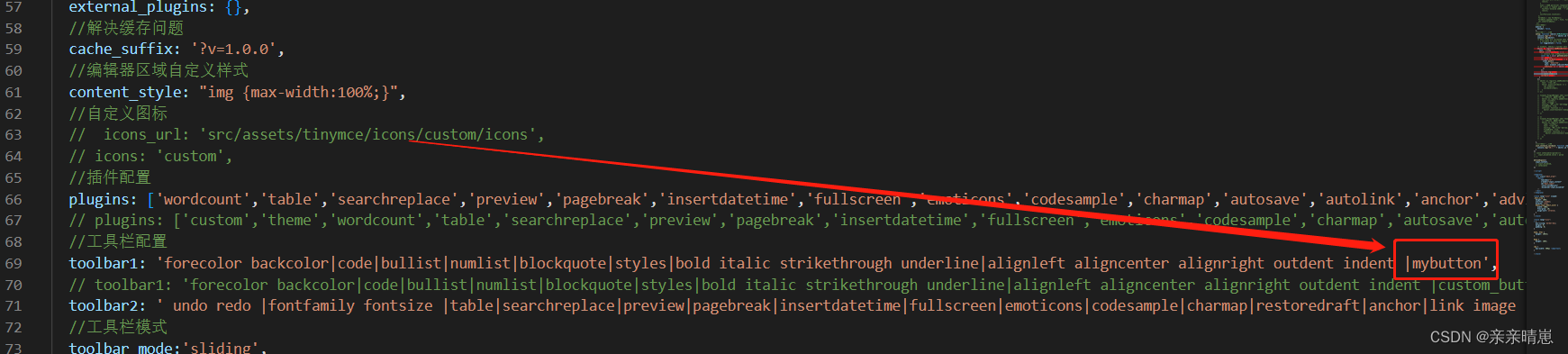
vue3+ts+tinynce在富文本编辑器菜单栏实现下拉框选择
实现效果 代码: <script lang"ts" setup> import Editor from tinymce/tinymce-vue import tinymce from tinymce; import { getIndicator } from /api/data-assets/data-dictoryimport {computed, ref} from "vue"; const props defin…...

前端UI组件库深度解析:构建现代化的用户体验
引言 在当今的前端开发中,UI组件库已经成为了我们工具箱中不可或缺的一部分。这些库可以极大地提高我们的工作效率,同时也使我们能够专注于实现真正的业务逻辑,而不是重复地编写UI代码。本篇博客将详细地探讨UI组件库的核心概念,…...

7天掌握FontForge:免费开源字体编辑器的完整使用指南
7天掌握FontForge:免费开源字体编辑器的完整使用指南 【免费下载链接】fontforge Free (libre) font editor for Windows, Mac OS X and GNULinux 项目地址: https://gitcode.com/gh_mirrors/fo/fontforge 你是否曾梦想设计属于自己的字体?无论是…...
核心参数保姆级解读)
别再死记硬背参数了!Halcon形状匹配(create_shape_model)核心参数保姆级解读
Halcon形状匹配核心参数深度解析:从原理到实战调参指南 在工业视觉检测领域,形状匹配技术一直是定位和识别的核心手段。Halcon作为行业领先的机器视觉软件,其create_shape_model和find_shape_model算子提供了强大的形状匹配能力。然而&#…...

NVIDIA Vera CPU:首款专为Agentic AI设计的CPU架构深度解析
前言 2026年5月18日,NVIDIA正式宣布其首款专为Agentic AI(智能体AI)设计的CPU——Vera,已完成对Anthropic、OpenAI、SpaceX AI及甲骨文云的首批交付。这一里程碑事件标志着AI计算架构从"GPU中心"向"CPU-GPU协同"的重要转型。本文将深入解析Vera CPU的…...

终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题!
终极音频格式转换指南:FlicFlac让音乐文件兼容性不再是难题! 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 还在为不同设备无法…...
)
MIUI手机管家自动任务还能这么玩?手把手教你用备用机+智能插座实现远程打卡(附详细避坑指南)
MIUI自动任务高阶玩法:备用机智能插座打造远程打卡系统全攻略 1. 为什么需要远程打卡解决方案? 早晨8:55分的地铁车厢里,小李盯着手机上的导航地图,红色拥堵路段让他的心跳加速——距离公司打卡截止时间只剩5分钟,而至…...

在RK3568 Android 11上搞定移远EC20 4G模块:从驱动到RIL的完整移植避坑记录
RK3568 Android 11平台EC20 4G模块全流程移植指南:从硬件连接到网络配置 在嵌入式Android开发中,4G模块的集成一直是项目落地的关键环节。本文将基于RK3568平台和Android 11系统,详细解析移远EC20模块从硬件连接到上层应用的全链路移植过程。…...

VAP特效动画创作指南:3步打造跨平台炫酷视觉特效
VAP特效动画创作指南:3步打造跨平台炫酷视觉特效 【免费下载链接】vap VAP是企鹅电竞开发,用于播放特效动画的实现方案。具有高压缩率、硬件解码等优点。同时支持 iOS,Android,Web 平台。 项目地址: https://gitcode.com/gh_mirrors/va/vap 还在为…...

研究生你的救星来了
为了找一个研究方向的核心文献,我要同时打开知网、Web of Science、IEEE Xplore三个数据库,翻几十篇顶刊摘要,还要手动整理每个文献的研究方法、核心结论,熬到凌晨两点,结果还是理不清整个领域的研究脉络。直到上个月朋…...

半年飙到 15.7 万 Star!OpenCode:Claude Code 最强开源对手,模型随便挑
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

告别Mac NTFS读写限制:免费开源的终极解决方案
告别Mac NTFS读写限制:免费开源的终极解决方案 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management for NTFS …...