开源风雷CFD软件多物理场耦合接口开发路线分享!!!
本文将基于开发过程中积累的经验,介绍风雷如何基于preCICE开发适配器。
preCICE是一个开源的多物理场数值模拟耦合库,可以用于多个求解器联合求解一个复杂的多场问题,支持在大规模并行系统上应用,具有良好的并行效率。并且可以对各种支持二次开发的求解器进行快速适配,在开发方面具有高度的灵活性。
风雷适配器可以在风雷求解CFD问题的基础上继续拓展功能,最终目的是实现风雷和其他学科求解器的多物理场耦合计算。基于此目的开发了一个简单的风雷适配器以验证耦合可行性。
由于适配器的开发仅作为验证作用,功能并不完善,文章会在相应位置注明后续可拓展的方向。
下面会对风雷整体的开发思路进行介绍:
求解器功能分析
为了开发风雷适配器,在掌握preCICE相关API功能以外,还需要对风雷求解器的使用和代码架构进行学习。根据开发经验,主要需要学习以下信息:
🔹风雷的使用方法
🔹代码整体结构
🔹求解主流程
🔹网格数据表示方法
🔹物理场数据表示方法
风雷的使用方法
在风雷的算例中,通常包含三个文件夹,其分别为参数文件bin、网格文件grid和结果文件results。下图为风雷的算例文件结构:

图1 风雷算例文件结构
在完成具体配置信息的设置后,直接启动风雷即可。可以参照风雷提供的使用手册来学习。
代码整体结构
代码的整体结构如下图所示:

图2 风雷源代码结构
由图可知,代码主要分为Main、CFD、API、3rdparty、Mesh。其中有两个部分是与开发适配器密切相关的,一个是Main,另一个是API。后面会对这两部分进一步介绍。
求解主流程
求解主流程在Main文件夹的代码中,具体的流程如下图:

图3 风雷CFD求解主流程图
主流程主要分为三部分:
01
各种数据的初始化,包括各种物理场和边界条件的初始化。
02
完成初始化后,开始进行流场的迭代计算。
03
收集并输出流场数据和残差数据。
网格数据表示方法
由于风雷软件支持大规模并行计算,所以内部支持多块网格分区计算,风雷网格相关结构主要分为3个层级:
01
Region层级:
这一层级代表了一个进程,Region能够控制一个进程上的全部分区网格的计算,也就是说一个Region上可以包含多个网格块。
02
Zone层级:
Zone层级代表了一个Region上的一块分区网格,除此之外它还包含了求解器网格流程的求解器。
03
Grid层级:
Grid层级就是Zone包含的网格,在风雷中Grid是存放网格信息的数据结构。
物理场数据表示方法
在Grid内部存放了流场数据结构的成员变量:Data_Field *gField,在不可压缩求解器和可压缩求解器中,物理场的数据都可以通过统一的API接口调用。
目前耦合适配器是基于不可压缩求解器开发的,可压缩和不可压缩求解器获取流场信息时调用API相同,但传递的参数不同,如果对可压缩求解器进行拓展需要注意此问题。
开发思路
在完成风雷运行和代码架构的相关学习后,可以制定一个初步的方案来进行代码接口的设计,可以结合上文介绍内容来设计相应的实现方案。下图描绘了总体开发思路,以及开发思路的详细介绍:

图4 风雷适配器主要功能开发思路
1、耦合配置信息
基于风雷的算例文件结构,可以分析出风雷求解器配置文件的读取在bin文件夹,那么就可以在风雷的参数配置文件中直接添加耦合所需的配置信息。
这样做的目的是可以复用求解器内部已有的配置文件解析功能,不用自己再额外开发一套新的读取配置文件的代码或引入其他库来解析配置文件。
注:目前已经完成耦合配置信息的数据结构,以及使用的接口,暂未开发配置文件的读写功能,可以基于以上思路对配置信息进行拓展。
2、求解主流程
适配器代码主要分为三部分插入到风雷主流程:
第一个是对各种信息的初始化(包括网格、求解器并行信息等),此部分代码在求解器初始化完毕后、开始迭代计算前插入;
第二就是具体的耦合计算(耦合数据的读取和写入,以及推进preCICE进行耦合计算等),此部分代码需要添加在求解循环内部;
第三就是适配器资源的释放,这部分可以添加在风雷释放资源的函数代码处。
3、网格信息
基于风雷求解器的并行求解,需要对网格进行分区处理,由此可知在程序中需要分别处理每个Region上所有Zone的Grid信息。风雷求解器的数据是基于面心存取的,所以需要提供面心(faceCenter)的网格信息;
为了支持流固耦合作用,流固耦合会导致流场网格变形,需要更新节点(faceNode)坐标,所以需要提供网格节点信息。因为耦合功能需要向preCICE注册耦合网格信息,需要在程序内部知道耦合网格的信息,在此可以使用网格的边界名称来识别。
因为preCICE耦合原理是弱耦合,对于求解器而言,通常只需要边界处的网格信息。对于并行的情况,给出的处理办法是将每个进程内参与耦合的边界信息按边界名字区分,最后把同名边界信息合并到一起,提供给preCICE。
注:由于目前风雷求解器本身的限制——风雷暂不支持提供与流场计算相耦合的动网格功能,所以目前暂时无法支持节点坐标的更新,只能耦合流场数据。且暂时未提供结构网格信息提取的功能,后续可以对此功能进行拓展。
4、物理场信息
在完成网格信息提取后,风雷中的物理场信息的提取,就变得十分轻松。风雷中通过GetDataPtr接口,传入数据名称即可获取到相应的物理场。
在物理场中获取耦合网格的物理场数据指针,只需在获取耦合网格信息时额外储存一个网格的索引号,通过每个网格的索引号就可以快速在物理场数据指针获得相应网格块的数据。
在完成网格块数据的提取后,就可以通过preCICE进行相应数据的传输并执行preCICE内置的映射插值算法。
注:preCICE支持显式与隐式计算,目前仅开发了显式计算相关功能,隐式计算还需要对流场数据进行保存和回溯操作,在计算复杂问题时,需要开发隐式耦合功能提高数值稳定性。
在完成这些工作后,就可以直接开始适配器的开发工作了。
开发时使用的风雷API
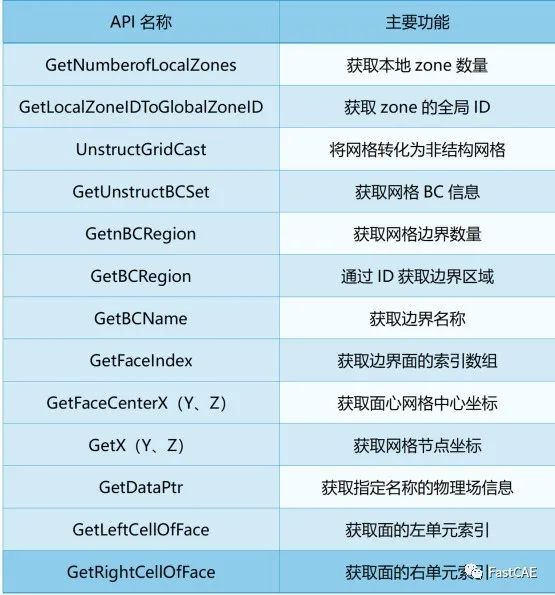
下表为开发风雷适配器时,主要使用的风雷求解器的接口。
表1 开发使用的函数
适配器代码使用介绍
下面的Simulation::SolveSimulation() 是风雷实现主求解循环的函数,在此插入开发的适配器函数,即可实现在风雷求解过程中的耦合计算功能。
在SolveSimulation添加的耦合适配器代码主要分为三部分:
1. 适配器初始化阶段(代码24-29行)
2. 读取/发送耦合数据,推进耦合整体进行(代码37-39行)
3. 释放耦合适配器资源,完成耦合计算(代码49行)
void Simulation::SolveSimulation(){WriteLogFile("Start iterating ...");bool continueSolve = true;int maxSimuStep = PHSPACE::GlobalDataBase::GetIntParaFromDB("maxSimuStep");int isOverset = PHSPACE::GlobalDataBase::GetIntParaFromDB("codeOfOversetGrid");7:int sysGridType = PHSPACE::GlobalDataBase::GetIntParaFromDB("sys_gridtype");//! Wait for all processors here!if (!isOverset || sysGridType == STRUCTGRID){PrintToWindow("Wait for all processors before iteration ... \n");PH_Barrier();PrintToWindow("Wait is over,start iteration ... \n");}int outIterStep = PHSPACE::GlobalDataBase::GetIntParaFromDB("outnstep");if (maxSimuStep == 0){continueSolve = false;}//创建适配器并初始化Adapter* adapter = new Adapter(this->region);adapter->GetCouplingBC();adapter->GetCouplingMeshVertices();adapter->CreatPreciceInterface();adapter->SetMesh();double dt = adapter->PreciceInit();while (continueSolve){UpdateOuterIterationStep(outIterStep);SolveOneOuterStep();//发送数据并推进时间前进adapter->WriteData(dt);dt = adapter->Advance(dt);adapter->ReadData(dt);if (outIterStep >= maxSimuStep && maxSimuStep > 0){continueSolve = false;}}//释放适配器对象adapter->Finaliaze();}
⭐第一阶段主要实现了以下功能:
➤代码24行——使用风雷的Region构造适配器
➤代码25行——获取风雷中耦合所需的边界信息
➤代码26行——获取耦合边界的网格面心/节点坐标信息
➤代码27行——使用并行信息构造preCICE接口对象
➤代码28行——使用获取到的网格信息去初始化preCICE的网格信息
➤代码29行——初始化preCICE,根据分区网格信息建立进程间的通信通道
⭐第二阶段主要实现了以下功能:
➤代码37行——发送所有耦合的数据到preCICE
➤代码38行——推进耦合计算,完成异构网格的映射以及物理量的交换
➤代码39行——从preCICE中读取完成映射的物理量并写入到风雷的物理场数据结构中
⭐第三阶段调用了适配器类以及preCICE的析构函数释放计算机资源。
以上就是在风雷求解器中使用适配器代码介绍,包括适配器成员函数调用的位置以及各个成员函数所完成的主要功能介绍。
相关文章:
开源风雷CFD软件多物理场耦合接口开发路线分享!!!
本文将基于开发过程中积累的经验,介绍风雷如何基于preCICE开发适配器。 preCICE是一个开源的多物理场数值模拟耦合库,可以用于多个求解器联合求解一个复杂的多场问题,支持在大规模并行系统上应用,具有良好的并行效率。并且可以对…...

浅谈Mysql读写分离的坑以及应对的方案 | 京东云技术团队
一、主从架构 为什么我们要进行读写分离?个人觉得还是业务发展到一定的规模,驱动技术架构的改革,读写分离可以减轻单台服务器的压力,将读请求和写请求分流到不同的服务器,分摊单台服务的负载,提高可用性&a…...

最近在对接电商供应链,说说开放平台API接口
B2B电商开放平台的设计需要从以下几面去思考: 开放平台API接口的设计,主要是从功能需求的角度,设计满足业务需求的接口及对应的字段; 平台与商家之间信息的对接,对接的方法有哪些?对接过程中需要可能会遇到…...
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server HBase从C50迁移到6.5.1(02)C50上准备FTP Server登录老集群FusionInsight C50的Manager准备FTP User准备FTP Server HBase从C50迁移到6.5.1(02&am…...

Java操作符学习笔记
1、布尔类型的逻辑操作符和按位操作符 & 和 &&、|| 和 | 其实是两种操作符。在使用逻辑判断时,有时不希望产生短路作用,会对两个布尔类型值使用单个的 & 或 |运算。这让我一直将单个 & 和 | 当成时逻辑操作符的一种,而事…...
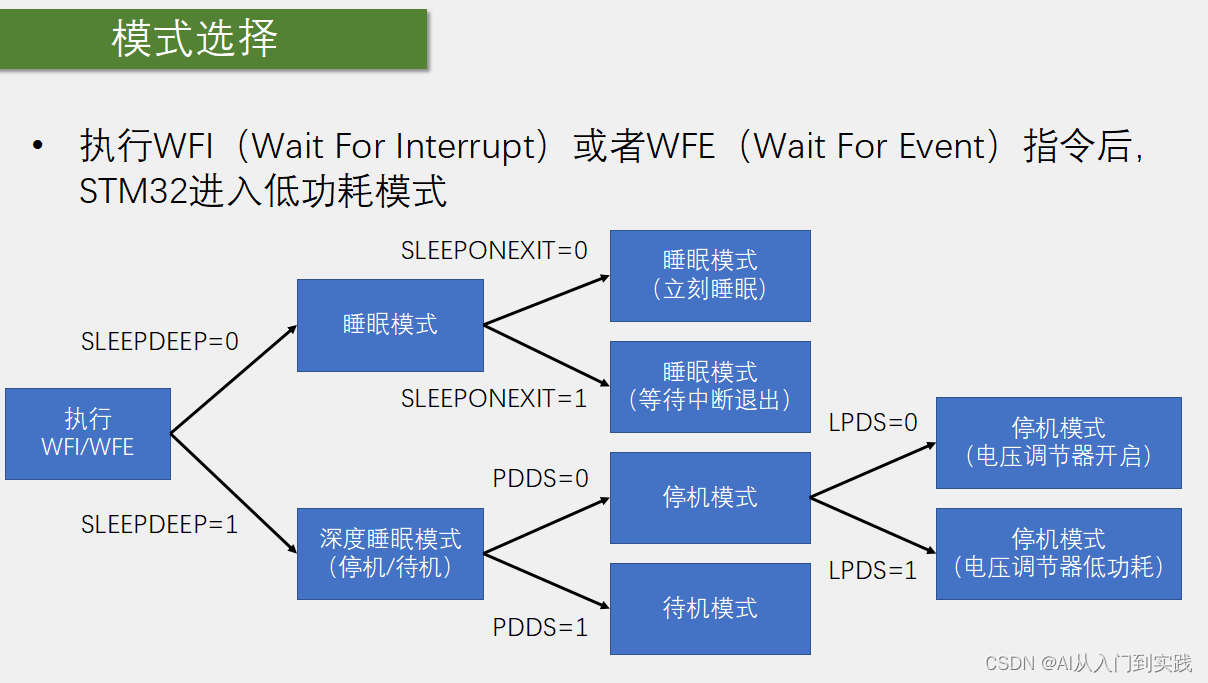
【STM32】学习笔记-PWR(Power Control)电源控制
PWR(Power Control)电源控制 PWR(Power Control)电源控制是一种技术或设备,用于控制电源的开关和输出。它通常用于电源管理和节能,可以通过控制电源的工作状态来延长电子设备的使用寿命,减少能…...
安卓 MeasureCache优化了什么?
安卓绘制原理概览_油炸板蓝根的博客-CSDN博客 搜了一下,全网居然没有人提过 measureCache。 在前文中提到过,measure的时候,如果命中了 measureCache,会跳过 onMeasure,同时会设置 PFLAG3_MEASURE_NEEDED_BEFORE_LAYOU…...

docker save docker export 区别
docker save用于导出镜像到文件,包含镜像元数据和历史信息;docker export用于将当前容器状态导出至文件,类似快照,所以不包含元数据及历史信息,体积更小,此外从容器快照导入时也可以重新指定标签和元数据信…...

音频基础知识
文章目录 前言一、音频基本概念1、音频的基本概念①、声音的三要素②、音量与音调③、几个基本概念④、奈奎斯特采样定律 2、数字音频①、采样②、量化③、编码④、其他相关概念<1>、采样位数<2>、通道数<3>、音频帧<4>、比特率(码率&#…...

TensorFlow(R与Python系列第四篇)
目录 一、TensorFlow介绍 二、张量 三、有用的TensorFlow运算符 四、reduce系列函数实现约减 1-第一种理解方式:引入轴概念后直观可理 2-第二种理解方式:按张量括号层次的方式 参考: 一、TensorFlow介绍 TensorFlow是一个强大的用于数…...

华为数通方向HCIP-DataCom H12-821题库(单选题:261-280)
第261题 以下关于IPv6过渡技术的描述,正确的是哪些项? A、转换技术的原理是将IPv6的头部改写成IPv4的头部,或者将IPv4的头部改写成IPv6的头部 B、使用隧道技术,能够将IPv4封装在IPv6隧道中实现互通,但是隧道的端点需要支持双栈技术 C、转换技术适用于纯IPv4网络与纯IPv…...

论文《基于概率标签估计的半监督日志缺陷检测》翻译
论文《Semi-supervised Log-based Anomaly Detection via Probabilistic Label Estimation》翻译 Semi-supervised Log-based Anomaly Detection via Probabilistic Label Estimation翻译...
ajax day2
1、 2、控制弹框显示和隐藏: 3、右键tr,编辑为html,可直接复制tr部分的代码 4、删除时,点击删除按钮,可以获取图书id: 5、编辑图书 快速赋值表单元素内容,用于回显: 6、hidden …...
)
互联网摸鱼日报(2023-09-04)
互联网摸鱼日报(2023-09-04) 36氪新闻 腾讯游戏的棋中妙手 逐一解读北交所8大改革组合拳 本周双碳大事:全国碳市场清缴履约工作全面展开;宁德时代在成都成立新能源研究院;我国首个万吨级光伏发电直接制绿氢项目投产 你在上海 city walk&a…...
UG\NX CAM二次开发 遍历组中的工序 UF_NCGROUP_ask_member_list
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 遍历组中的工序 UF_NCGROUP_ask_member_list 效果: 代码: void GetAllOperTag(tag_t groupTag, vector<tag_t> &vOperTags) {int count=0;tag_t * list;UF_NCGROUP_ask_member_li…...

适配器、装饰器模式
一、装饰器模式 向一个现有的对象增加其功能而不改变其结构,属于类的包装...

Netty服务端启动的整体流程-基于源码4.1.96Final分析
Netty采用的是主从Reactor多线程的模型,参考Scalable IO in Java,但netty的subReactor为一个组 一、从FileServer服务器示例入手 public final class FileServer {static final boolean SSL System.getProperty("ssl") ! null;// Use the …...

预训练Bert添加new token的问题
问题 最近遇到使用transformers的AutoTokenizer的时候,修改vocab.txt中的[unused1]依然无法识别相应的new token。 实例: 我将[unused1]修改为了[TRI],句子中的[TRI]并没有被整体识别,而是识别为了[,T,RI,]。这明显是有问题的。…...

非常典型和高效的枚举类写法
目录 1、讲讲好处 2、例子 (1)枚举类: (2)DTO类: 3、根据上面例子进行具体讲解 1、讲讲好处 在使用这种标准枚举模式编写业务逻辑时,可以直接通过枚举成员来表示状态,不需要担心底层的 value 或描述信…...

kafka-- kafka集群环境搭建
kafka集群环境搭建 # 准备zookeeper环境 (zookeeper-3.4.6) # 下载kafka安装包 https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz # 上传 : 172.16.144.133 cd /usr/local/softwaretar -zxvf /usr/local/software/kafka_2.12-2.1.0.tgz -C /usr/local…...

嵌入式数据存储终极指南:5分钟快速上手FlashDB超轻量级数据库
嵌入式数据存储终极指南:5分钟快速上手FlashDB超轻量级数据库 【免费下载链接】FlashDB An ultra-lightweight database that supports key-value and time series data | 一款支持 KV 数据和时序数据的超轻量级数据库 项目地址: https://gitcode.com/gh_mirrors/…...

3个关键决策:为什么顶级技术团队选择Arco Design Pro构建企业级应用
3个关键决策:为什么顶级技术团队选择Arco Design Pro构建企业级应用 【免费下载链接】arco-design-pro An out-of-the-box solution to quickly build enterprise-level applications based on Arco Design. 项目地址: https://gitcode.com/gh_mirrors/ar/arco-de…...

2025_NIPS_TradeMaster: A Holistic Quantitative Trading Platform Empowered by Reinforcement Learning
TradeMaster 论文总结与核心内容翻译 一、文章主要内容 TradeMaster 是一款面向强化学习量化交易(RLFT)的全栈开源平台,旨在解决 RL 技术在实际金融市场部署中面临的工程实现难、基准对比难、易用性差三大核心挑战。文章围绕该平台展开全面阐述,核心内容包括: 1. 平台定…...

VK视频下载终极指南:3种方法轻松保存珍贵回忆
VK视频下载终极指南:3种方法轻松保存珍贵回忆 【免费下载链接】VK-Video-Downloader Скачивайте видео с сайта ВКонтакте в желаемом качестве 项目地址: https://gitcode.com/gh_mirrors/vk/VK-Video-Downloade…...

Faster-Whisper + WebSocket实战:给你的Unity游戏或应用加上实时语音交互
Faster-Whisper WebSocket全链路实战:构建Unity实时语音交互系统 在游戏和交互式应用开发中,语音交互正成为提升用户体验的关键功能。想象一下玩家通过语音指令控制角色、VR环境中自然对话交互,或是教育软件中实时语音反馈的场景——这些都需…...

OpenCost:Kubernetes 成本监控,开源的云资源费用分析
OpenCost:Kubernetes 成本监控,开源的云资源费用分析 随着企业将越来越多的工作负载迁移到 Kubernetes,一个新的管理挑战随之浮现:到底哪个团队、哪个应用在花钱? 公有云账单只能告诉你整个集群的月度费用,…...
)
别再到处找汉化包了!PowerDesigner 15.1 保姆级安装与汉化教程(附资源)
PowerDesigner 15.1 完整安装与汉化实战指南 对于数据库设计领域的初学者和专业开发者来说,PowerDesigner无疑是一款功能强大的建模工具。然而,英文界面常常成为非英语母语用户的第一道门槛。本文将提供一份从零开始的完整解决方案,涵盖软件安…...

论文降重与改写:2026 最新降AI率平台测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

SQL server 2017镜像库主从同步架构部署
SQL server 2017镜像库主从同步架构部署 目录: 1.主库配置 2.镜像库配置 3.检查状态 4.手工故障转移测试-主备切换 5.添加见证服务器实现自动主备切换 6.自动故障切换测试-主备切换角色 IP 状态 主机名 主库 192.168.56.120 可读写 sqldb2 镜像库(从库&a…...
)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器(行为级/数据流/门级)
别再只写assign了!用三种Verilog建模风格重构你的三人表决器 三人表决器是数字电路设计中的经典案例,它能直观展示不同抽象层次的Verilog建模风格如何影响代码质量与硬件实现。很多工程师习惯性地使用assign语句完成所有设计,却忽略了Verilo…...