音频基础知识
文章目录
- 前言
- 一、音频基本概念
- 1、音频的基本概念
- ①、声音的三要素
- ②、音量与音调
- ③、几个基本概念
- ④、奈奎斯特采样定律
- 2、数字音频
- ①、采样
- ②、量化
- ③、编码
- ④、其他相关概念
- <1>、采样位数
- <2>、通道数
- <3>、音频帧
- <4>、比特率(码率)
- <5>、音频文件大小的计算:
- <6>、PCM 流
- 3、音频处理基础
- ①、噪声抑制(Noise Suppression)
- ②、回声消除(Acoustic Echo Canceller)
- ③、自动增益控制(Auto Gain Control)
- ④、静音检测(Voice Activity Detection)
- ⑤、舒适噪声产生(Comfortable Noise Generation)
- 4、音频使用场景
- 5、常见音频格式
- 6、混音技术
- ①、混音条件
- ②、回声消除、噪音抑制和静音检测等处理
- ③、音频重采样
- ④、回声消除
- 二、音频编码原理
- 1、音频编码
- ①、压缩编码
- ②、音频编解码常用的三种实现方案
- ③、音频信号压缩编码标准
- ④、音频编码过程
- <1>、音频信号数字化
- <2>、音频编码三类方法
- ⑤、音频压缩
- <1>、音频信号能压缩的基本依据
- <2>、音频信号压缩编码的分类
- 2、音频编码的基本原理讲解
- ①、概述
- ②、静音阈值曲线
- ③、临界频带
- ④、频域上的掩蔽效应
- ⑤、时域上的遮蔽效应
- 3、音频编码基本手段
- ①、编码基本手段之一 —— 量化和量化器
- <1>、基本概念
- <2>、常见的量化器的优缺点
- ②、编码基本手段之二 —— 语音编码器
- <1>、基本概念
- <2>、波形编码器
- 1)、时域编码
- 2)、频域编码
- 3)、声码器
- 4)、混合编码器
- 4、音频压缩格式
- ①、WAV 编码
- ②、mp3 编码
- ③、AAC 编码
- ④、Ogg 编码
- ⑤、FLAC 编码
- 三、音频深度学习
- 1、深度学习在音频信号处理中的进展
- 2、应用
- ①、语音识别
- ②、音乐信息检索
- ③、环境声识别
- ④、定位和跟踪
- ⑤、声源分离
- ⑥、声音增强
- ⑦、生成模型
- 3、十大音频处理任务
- ①、音频分类
- ②、音频指纹识别
- ③、自动音乐标注
- ④、音频分割
- ⑤、音源分离
- ⑥、节拍跟踪
- ⑦、音乐推荐
- ⑧、音乐信息检索
- ⑨、音乐转录(Music Transcription)
- ⑩、音符起始点检测
前言
本节对音频相关知识进行了详细的介绍及讲解。
一、音频基本概念
1、音频的基本概念
①、声音的三要素
声音的三要素:频率、振幅、波形
- 频率:声波的频率,即声音的音调,人类听觉的频率(音调) 范围为 20Hz—20KHz
- 振幅:即声波的响度,通俗的讲就是声音的高低,一般男生的声音振幅(响度) 大于女生。
- 波形:波形决定了其所代表声音的音色。音色不同是因为它们的介质所产生的波形不同
②、音量与音调
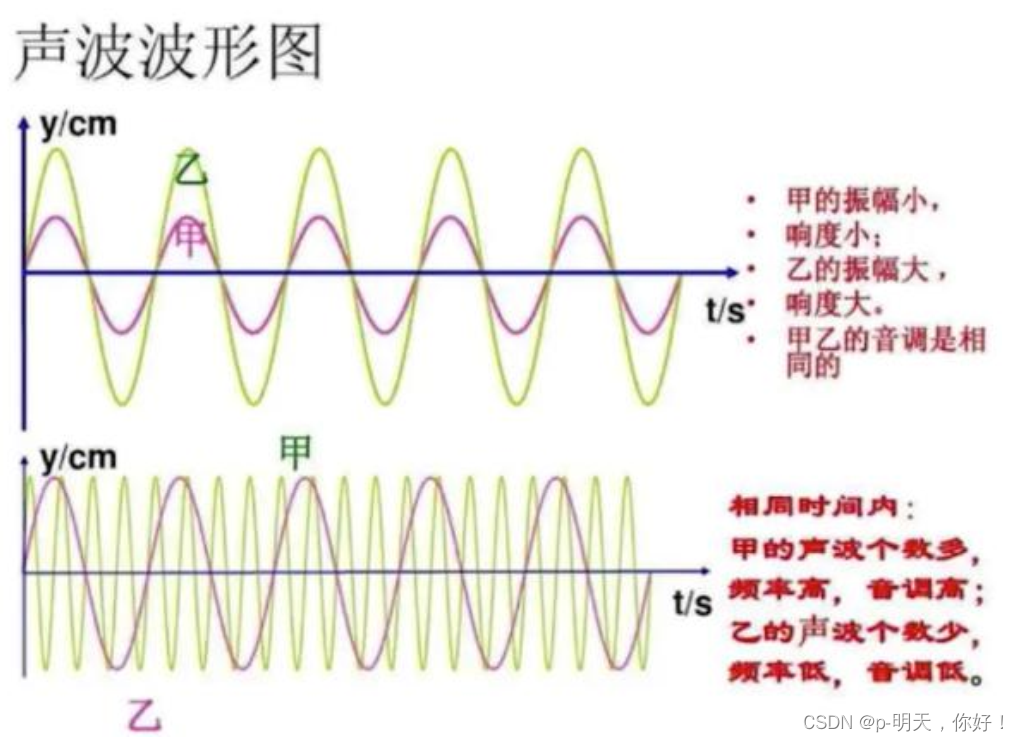
声音的本质(音调、音量、音色)
- 音调:频率
- 音量:振幅
- 音色:与材质有关,谐波(不规则的正弦波)
③、几个基本概念
- 比特率:表示经过编码(压缩)后的音频数据每秒钟需要用多少个比特来表示,单位常为 kbps。
- 响度和强度:声音的主观属性响度表示的是一个声音听来有多响的程度。响度主要随声音的强度而变化,但也受频率的影响。总的说,中频纯音听来比低频和高频纯音响一些。
- 采样和采样率:采样是把连续的时间信号,变成离散的数字信号。采样率是指每秒钟采集多少个样本。
④、奈奎斯特采样定律
Nyquist 采样率大于或等于连续信号最高频率分量的 2 倍时,采样信号可以用来完美重构原始连续信号。
2、数字音频
①、采样
所谓的采样就是只在时间轴上对信号进行数字化。根据奈奎斯特定律(也称作采样定律) ,按照比声音最高频率的 2 倍以上进行采样。
人类听觉的频率(音调) 范围为 20Hz–20KHz。所以至少要大于 40KHz。
采样频率一般为 44.1kHz,这样可保证声音达到 20kHz 也能被数字化。
44.1kHz 就是代表 1 秒会采样 44100 次。
②、量化
具体每个采样又该如何表示呢?这就涉及到量化。量化是指在幅度轴上对信号进行数字化。如果用 16 比特位的二进制信号来表示一个采样,那么一个采样所表示的范围即为 [-32768, 32767] 。
下图为音频量化过程:
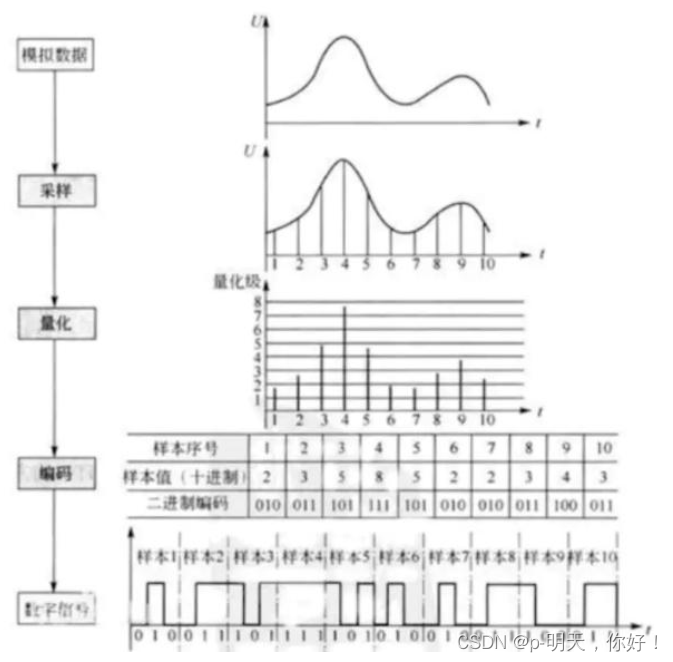
③、编码
每一个量化都是一个采样,将这么多采样进行存储就叫做编码。
所谓编码,就是按照一定的格式记录采样和量化后的数字数据,比如顺序存储或者压缩存储,等等。
通常所说的音频裸数据格式就是脉冲编码调制(PCM)数据。
描述一段 PCM 数据通常需要以下几个概念:量化格式(位深, 通常 16bit) 、采样率、声道数
对于声音格式,还有一个概念用来描述它的大小,即比特率,即 1 秒内的比特数目,用来衡量音频数据单位时间内的容量大小。
④、其他相关概念
<1>、采样位数
采样位数也叫采样大小或者量化位数。量化深度表示每个采样点用多少比特表示,音频的量化深度一般为 8、16、32 位等。
例如:量化深度为 8bit 时,每个采样点可以表示 256 个不同的量化值,而量化深度为 16bit 时,每个采样点可以表示 65536 个不同的量化值。
量化深度的大小影响到声音的质量,显然,位数越多,量化后的波形越接近原始波形,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。
CD 音质采用的是 16 bits。
<2>、通道数
即声音的通道数目, 常见的有单声道和双声道或者立体声道。
- 单声道的声音只能使用一个扬声器发声,或者也可以处理成两个扬声器输出同一个声道的声音,当通过两个扬声器回放单声道信息的时候,我们可以明显感觉到声音是从两个音箱中间传递到我们耳朵里的,无法判断声源的具体位置。
- 双声道就是有两个声音通道,其原理是人们听到声音时可以根据左耳和右耳对声音相位差来判断声源的具体位置。声音在录制过程中被分配到两个独立的声道,从而达到了很好的声音定位效果。
记录声音时,如果每次生成一个声波数据,称为单声道;每次生成两个声波数据,称为双声道(立体声)。立体声(双声道)存储大小是单声道文件的两倍。
<3>、音频帧
音频跟视频不太一样,视频的每一帧就是一副图像,但是因为音频是流式的,本身是没有一帧的概念的。
比如对于 PCM 流来说,采样率为 44100Hz,采样位数为 16,通道数为 2,那么一秒的音频固定大小的:44100162 / 8 字节。
但是人们可以规定一帧的概念,比如 amr 帧比较简单,它规定每 20ms 的音频是一帧。
<4>、比特率(码率)
指音频每秒钟播放的数据量,单位为 bit,例如对于 PCM 流,采样率为 44100Hz,采样大小为 16,声道数为 2,那么码率为:44100* 16 * 2 = 1411200 bps。
<5>、音频文件大小的计算:
文件大小 = 采样率 * 录音时间 * 采样位数 / 8 * 通道数。
<6>、PCM 流
PCM 流就是原始收录声音时,数据会保存到一串 buffer 中,这串 buffer,就采用了 PCM 格式存储的。
通常把音频采样过程也叫做脉冲编码调制编码,即 PCM(Pulse Code Modulation) 编码,采样值也叫 PCM 值
编码过程:模拟信号 -> 抽样 -> 量化 -> 编码 -> 数字信号
3、音频处理基础
①、噪声抑制(Noise Suppression)
手机等设备采集的原始声音往往包含了背景噪声,影响听众的主观体验,降低音频压缩效率。以 Google 著名的开源框架 Webrtc 为例,我们对其中的噪声抑制算法进行严谨的测试,发现该算法可以对白噪声和有色噪声进行良好的抑制。满足视频或者语音通话的要求。其他常见的噪声抑制算法如开源项目 Speex 包含的噪声抑制算法,也有较好的效果,该算法适用范围较 Webrtc 的噪声抑制算法更加广泛,可以在任意采样率下使用。
②、回声消除(Acoustic Echo Canceller)
在视频或者音频通话过程中,本地的声音传输到对端播放之后,声音会被对端的麦克风采集,混合着对端人声一起传输到本地播放,这样本地播放的声音包含了本地原来采集的声音,造成主观感觉听到了自己的回声。
③、自动增益控制(Auto Gain Control)
手机等设备采集的音频数据往往有时候响度偏高,有时候响度偏低,造成声音忽大忽小,影响听众的主观感受。
自动增益控制算法根据预先配置的参数对输入声音进行正向/负向调节,使得输出的声音适宜人耳的主观感受。
④、静音检测(Voice Activity Detection)
静音检测的基本原理:计算音频的功率谱密度,如果功率谱密度小于阈值则认为是静音,否则认为是声音。静音检测广泛应用于音频编码、AGC、AECM 等。
⑤、舒适噪声产生(Comfortable Noise Generation)
舒适噪声产生的基本原理:根据噪声的功率谱密度,人为构造噪声。
广泛适用于音频编解码器。
它的应用场景:完全静音时,为了创造舒适的通话体验,在音频后处理阶段添加随机白噪声。
4、音频使用场景
在现实生活中,音频(audio)主要用在两大场景中:语音(voice)和音乐(music)。
音频开发的主要应用:
- 音频播放器
- 录音机
- 语音电话
- 音视频监控应用
- 音视频直播应用
- 音频编辑/处理软件(ktv 音效、 变声, 铃声转换)
- 蓝牙耳机/音箱
音频开发的具体内容:
- 音频采集/播放;
- 音频算法处理(去噪、VAD 检测、回声消除、音效处理、功放/增强、混音/分离, 等等);
- 音频的编解码和格式转换;
- 音频传输协议的开发(SIP, A2DP、 AVRCP, 等等);
5、常见音频格式
- WAV :压缩率低
- MIDI(Musical Instrument Digital Interface):又称作乐器数字接口, 是数字音乐/电子合成乐器的统一国际标准
- MP3(MPEG-1 Audio Layer 3):MP3 能够以高音质、低采样率对数字音频文件进行压缩。应用最普遍
- MP3Pro:MP3Pro 可以在基本不改变文件大小的情况下改善原先的 MP3 音乐音质。它能够在用较低的比特率压缩音频文件的情况下,最大程度地保持压缩前的音质。
- WMA (Windows Media Audio):WMA 格式是以减少数据流量但保持音质的方法来达到更高的压缩率目的, 其压缩率一般可以达到 1:18
- RealAudio:最大的特点就是可以实时传输音频信息,尤其是在网速较慢的情况下,仍然可以较为流畅地传送数据,因此 RealAudio 主要适用于网络上的在线播放
- Audible:拥有四种不同的格式: Audible1、2、3、4。格式 1、2 和 3采用不同级别的语音压缩,而格式 4 采用更低的采样率和 MP3 相同的解码方式,所得到语音吐辞更清楚,而且可以更有效地从网上进行下载
- AAC:高级音频编码的缩写,AAC 的音频算法在压缩能力上远远超过了以前的一些压缩算法(比如 MP3 等)。它还同时支持多达 48 个音轨、15 个低频音轨、更多种采样率和比特率、多种语言的兼容能力、更高的解码效率。 总之,AAC 可以在比 MP3 文件缩小 30% 的前提下提供更好的音质。
- Ogg Vorbis:它是完全免费 、开放和没有专利限制的,同样位速率(Bit Rate)编码的 OGG 与 MP3 相比听起来更好一些
- APE:是一种无损压缩音频格式,在音质不降低的前提下,大小压缩到传统无损格式WAV 文件的一半
- FLAC(Free Lossless Audio Codec):是一套著名的自由音频无损压缩编码,其特点是无损压缩。
6、混音技术
混音, 顾名思义,就是把两路或者多路音频流混合在一起,形成一路音频流。
混流,则是指音视频流的混合,也就是视频画面和声音的对齐,也称混流。
①、混音条件
两路音视频流,必须符合以下条件才能混合:
- 格式相同, 要解压成 PCM 格式。
- 采样率相同,要转换成相同的采样率。主流采样率包括:16kHz、32kHz、44.1kHz 和 48kHz。
- 帧长相同,帧长由编码格式决定,PCM 没有帧长的概念,开发者自行决定帧长。为了和主流音频编码格式的帧长保持一致,推荐采用 20ms 为帧长。
- 位深(Bit-Depth)或采样格式 (Sample Format) 相同,承载每个采样点数据的 bit 数目要相同。
- 声道数相同,必须同样是单声道或者双声道 (立体声)。 这样,把格式、 采样率、 帧长、位深和声道数对齐了以后,两个音频流就可以混合了。
②、回声消除、噪音抑制和静音检测等处理
在混音之前,还需要做回声消除、噪音抑制和静音检测等处理。在编码之前,采集、语音前处理、混音之前的处理、混音和混音之后的处理应该按顺序进行。
③、音频重采样
重采样即是将音频进行重新采样得到新的采样率的音频。
重采样的原因
音频系统中可能存在多个音轨,而每个音轨的原始采样率可能是不一致的。
比如在播放音乐的过程中,来了一个提示音,就需要把音乐和提示音都混合到 codec 输出,音乐的原始采样率和提示音的原始采样率可能是不一致的。
问题来了,如果 codec 的采样率设置为音乐的原始采样率的话,那么提示音就会失真。
因此最简单见效的解决方法是:codec 的采样率固定一个值(44.1KHz/48KHz) ,所有音轨都重采样到这个采样率,然后才送到 codec,保证所有音轨听起来都不失真。
④、回声消除
回声消除就是在 Mic 采集到声音之后,将本地音箱播放出来的声音从 Mic 采集的声音数据中消除掉,使得 Mic 录制的声音只有本地用户说话的声音。
传统的回声消除都是采用硬件方式,在硬件电路上集成 DSP 处理芯片,如我们常用的固定电话、手机等都有专门的回音消除处理电路,而采用软件方式实现回声消除一直存在技术难点,包括国内应用最广泛的 QQ 超级语音,便是采用国外的 GIPS 技术,由此可见一般。
回声消除已经成为即时通讯中提供全双工语音的标准方法
回声消除的基本原理是以扬声器信号与由它产生的多路径回声的相关性为基础,建立远端信号的语音模型,利用它对回声进行估计,并不断修改滤波器的系数,使得估计值更加逼近真实的回声。然后,将回声估计值从话筒的输入信号中减去,从而达到消除回声的目的。
二、音频编码原理
1、音频编码
①、压缩编码
即压缩编码,其原理是压缩掉冗余的信号,冗余信号是指不能被人耳感知到的信号,包括人耳听觉范围之外的音频信号以及被掩蔽掉的音频信号。
模拟音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码,根据不同的量化策略,产生了许多不同的编码方式,常见的编码方式有:PCM 和 ADPCM,这些数据代表着无损的原始数字音频信号,添加一些文件头信息,就可以存储为 WAV 文件了,它是一种由微软和 IBM 联合开发的用于音频数字存储的标准, 可以很容易地被解析和播放。
②、音频编解码常用的三种实现方案
- 采用专用的音频芯片对语音信号进行采集和处理,音频编解码算法集成在硬件内部,如 MP3 编解码芯片、语音合成分析芯片等。 使用这种方案的优点就是处理速度块,设计周期短;缺点是局限性比较大,不灵活,难以进行系统升级。
- 是利用 A/D 采集卡加上计算机组成硬件平台,音频编解码算法由计算机上的软件来实现。使用这种方案的优点是价格便宜, 开发灵活并且利于系统的升级;缺点是处理速度较慢,开发难度较大。
- 使用高精度、高速度的 A/D 采集芯片来完成语音信号的采集,使用可编程的数据处理能力强的芯片来实现语音信号处理的算法,然后用 ARM 进行控制。采用这种方案的优点是系统升级能力强,可以兼容多种音频压缩格式甚至未来的音频压缩格式,系统成本较低;缺点是开发难度较大,设计者需要移植音频的解码算法到相应的 ARM 芯片中去
③、音频信号压缩编码标准
- ITU/CCITT 的 G 系列:G.711 、G.721 、G.722 、G.723 、G.728 、G.729;
- MPEG 系列的:MPEG-l ,MPEG-2 ,MPEG-4 ,MPEG-7 中的音频编码;
- DOLBY( 杜比 ) 实验室的 AC 系列: AC-1 , AC-2 , AC-3 等。
④、音频编码过程
<1>、音频信号数字化
将连续的模拟信号转换成离散的数字信号,完成采样、量化和编码三个步骤。又称为脉冲编码调制(Pulse Code Modulation) ,通常由 A/D 转换器来实现。
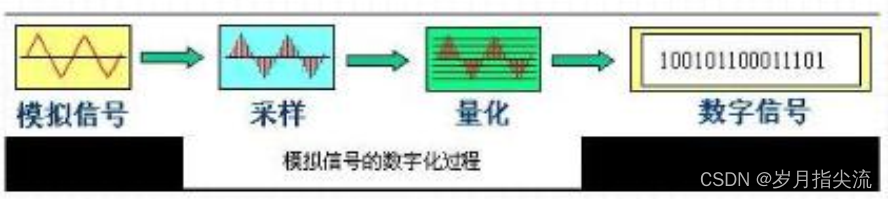
Nyquist 采样定律:采样率大于或等于连续信号最高频率分量的 2 倍时,采样信号可以用来完美重构原始连续信号。
三要素:采样频率、量化位数、声道数
<2>、音频编码三类方法
- 波形编码是尽量保持输入波形不变,即重建的语音信号基本上与原始语音信号波形相同,压缩比较低;
- 参数编码是要求重建的信号听起来与输入语音一样,但其波形可以不同,它是以语音信号所产生的数学模型为基础的一种编码方法,压缩比较高;
- 混合编码是综合了波形编码的高质量潜力和参数编码的高压缩效率的混合编码的方法,这类方法也是目前低码率编码的方向。
⑤、音频压缩
<1>、音频信号能压缩的基本依据
- 声音信号中存在大量的冗余度;
- 人的听觉具有强音能抑制同时存在的弱音现象。
<2>、音频信号压缩编码的分类
- 无损压缩(熵编码):霍夫曼编码、算术编码、行程编码
- 有损压缩
- 波形编码–PCM、DPCM、ADPCM 、子带编码、矢量量化
- 参数编码–LPC
- 混合编码–MPLPC、CELP
2、音频编码的基本原理讲解
①、概述
语音编码致力于:降低传输所需要的信道带宽, 同时保持输入语音的高质量。
语音编码的目标在于:设计低复杂度的编码器以尽可能低的比特率实现高品质数据传输。
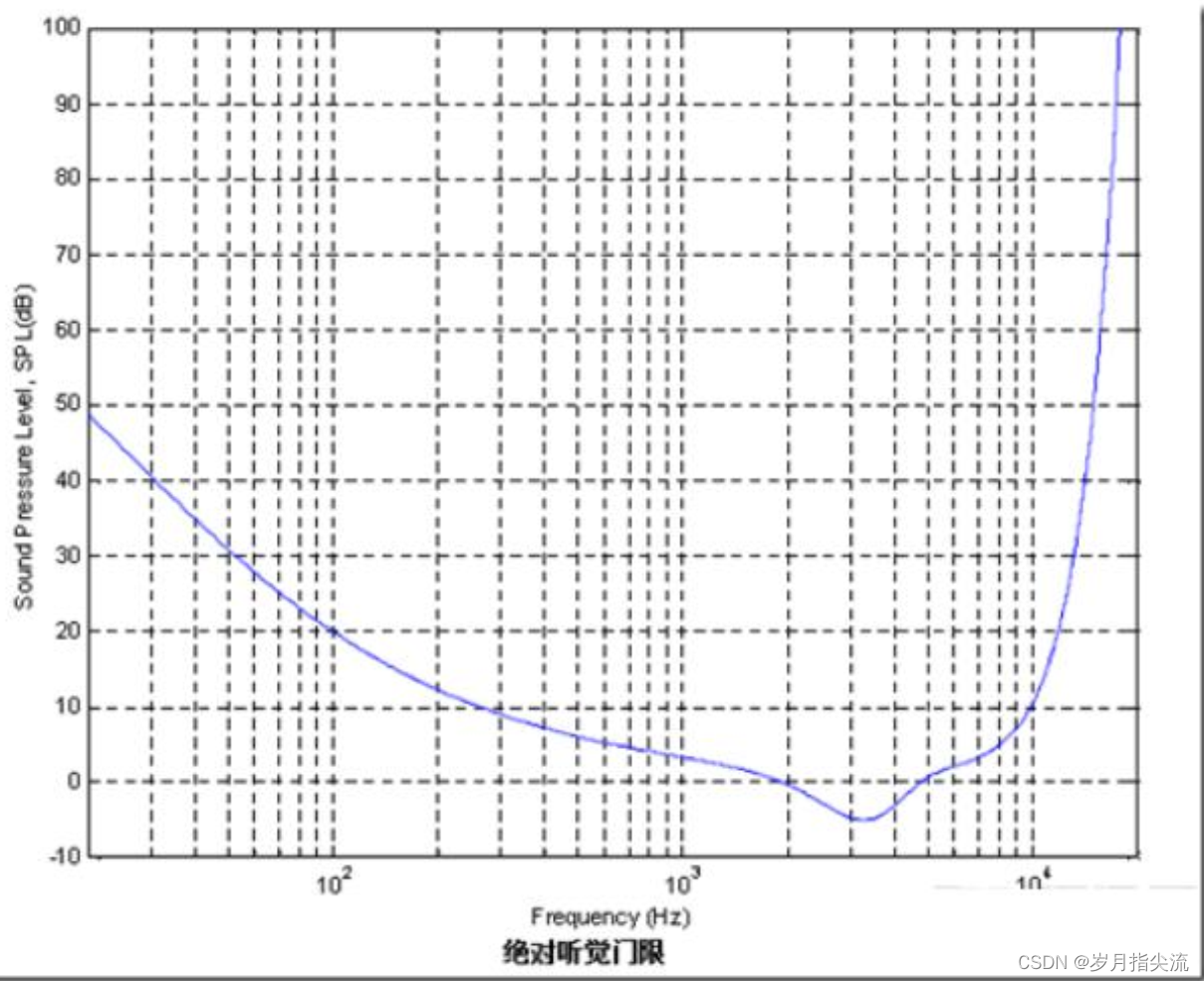
②、静音阈值曲线
指在安静环境下,人耳在各个频率能听到声音的阈值。
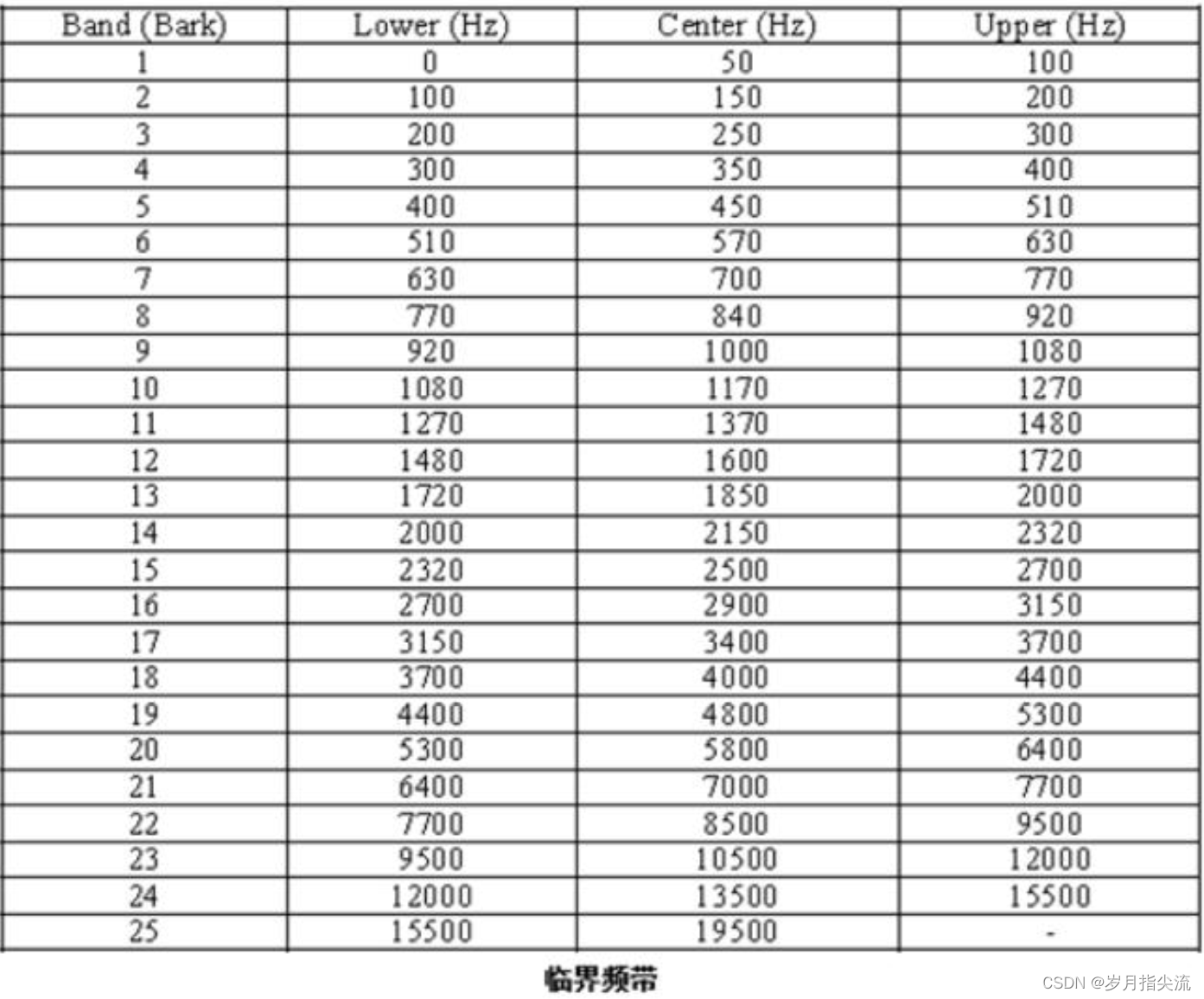
③、临界频带
由于人耳对不同频率的解析度不同,MPEG1/Audio 将 22khz 内可感知的频率范围,依不同编码层,不同取样频率,划分成 23~26 个临界频带。
下图列出理想临界频带的中心频率与频宽。图中可看到,人耳对低频的解析度较好。
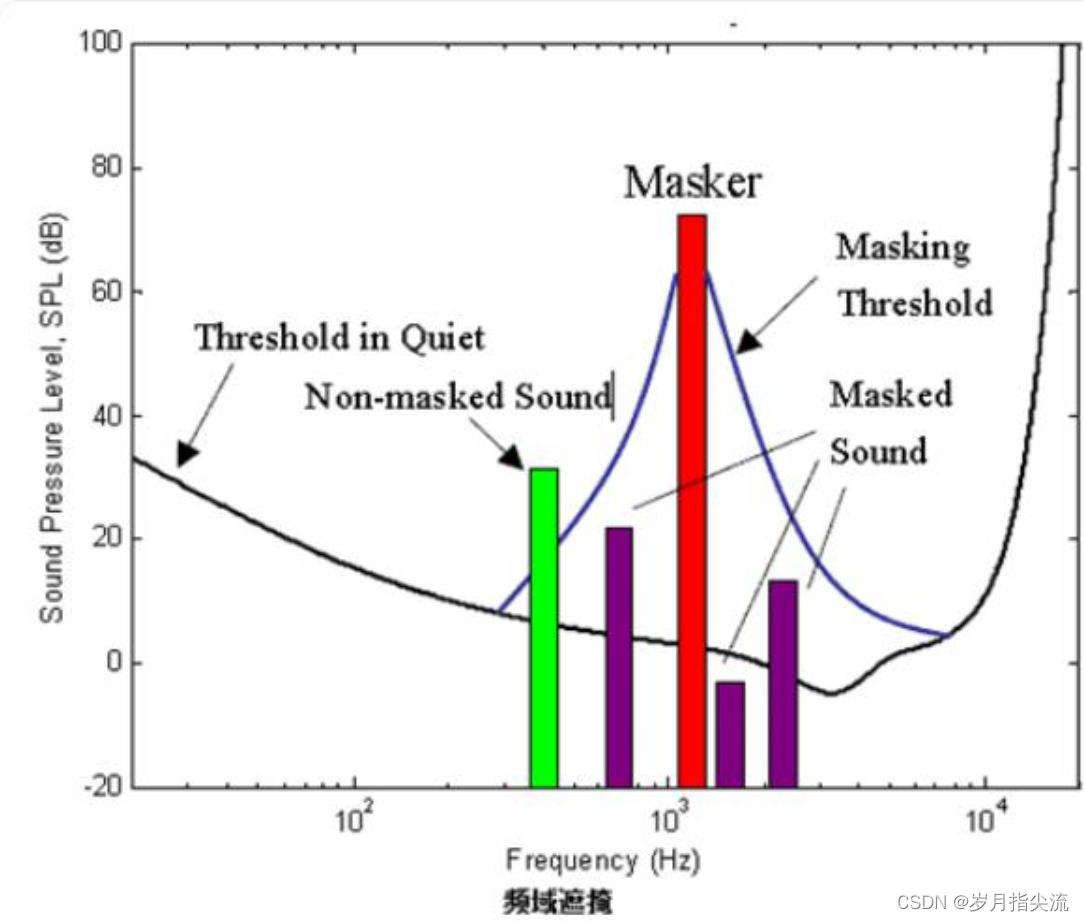
④、频域上的掩蔽效应
幅值较大的信号会掩蔽频率相近的幅值较小的信号,如下图:
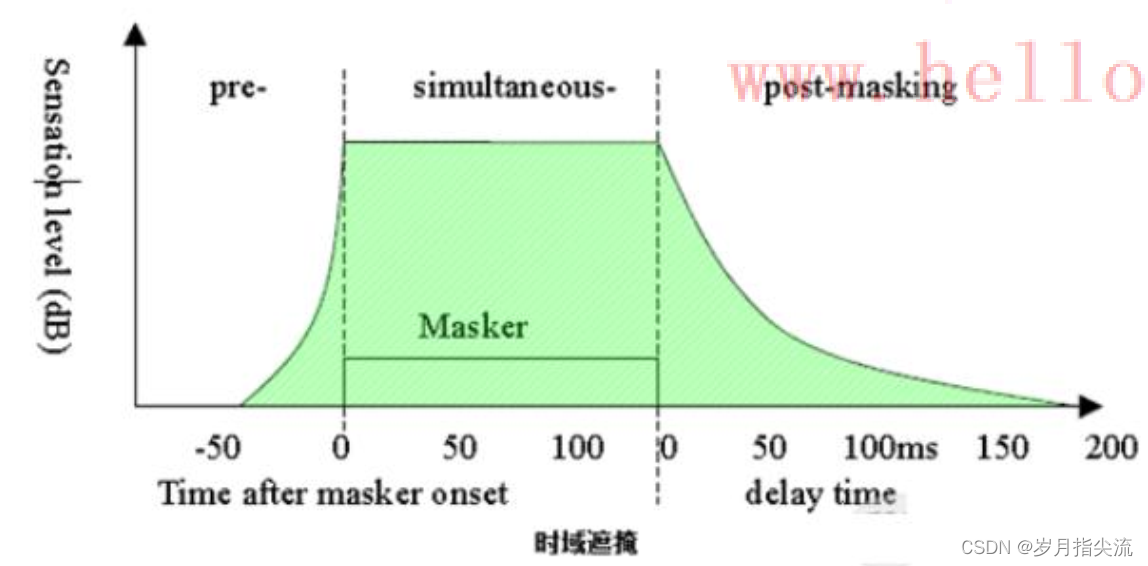
⑤、时域上的遮蔽效应
在一个很短的时间内,若出现了 2 个声音,SPL(sound pressure level) 较大的声音会掩蔽 SPL 较小的声音。
时域掩蔽效应分前向掩蔽(pre-masking)和后向掩蔽(post-masking),其中 post-masking的时间会比较长,约是 pre-masking 的 10 倍。
时域遮蔽效应有助于消除前回音。
3、音频编码基本手段
①、编码基本手段之一 —— 量化和量化器
<1>、基本概念
- 量化和量化器:量化是把离散时间上的连续信号,转化成离散时间上的离散信号。
- 常见的量化器有:均匀量化器,对数量化器,非均匀量化器。
- 量化过程追求的目标是:最小化量化误差,并尽量减低量化器的复杂度(这 2 者本身就是一个矛盾)
<2>、常见的量化器的优缺点
- 均匀量化器:最简单,性能最差,仅适应于电话语音。
- 对数量化器:比均匀量化器复杂,也容易实现,性能比均匀量化器好。
- 非均匀(Non-uniform)量化器:根据信号的分布情况,来设计量化器。信号密集的地方进行细致的量化,稀疏的地方进行粗略量化。
②、编码基本手段之二 —— 语音编码器
<1>、基本概念
语音编码器分为三种类形:(a)波形编码器 、(b)声码器 、(c)混合编码器 。
- 波形编码器以构造出背景噪单在内的模拟波形为目标。作用于所有输入信号,因此会产生高质量的样值并且耗费较高的比特率。
- 声码器 (vocoder) 不会再生原始波形。这组编码器会提取一组参数 ,这组参数被送到接收端,用来导出语音产生模形。声码器语音质量不够好。
- 混合编码器, 它融入了波形编码器和声码器的长处。
<2>、波形编码器
波形编码器的设计常独立于信号,所以适应于各种信号的编码而不限于语音。
1)、时域编码
- PCM:pulse code modulation,是最简单的编码方式。仅仅是对信号的离散和量化,常采用对数量化。
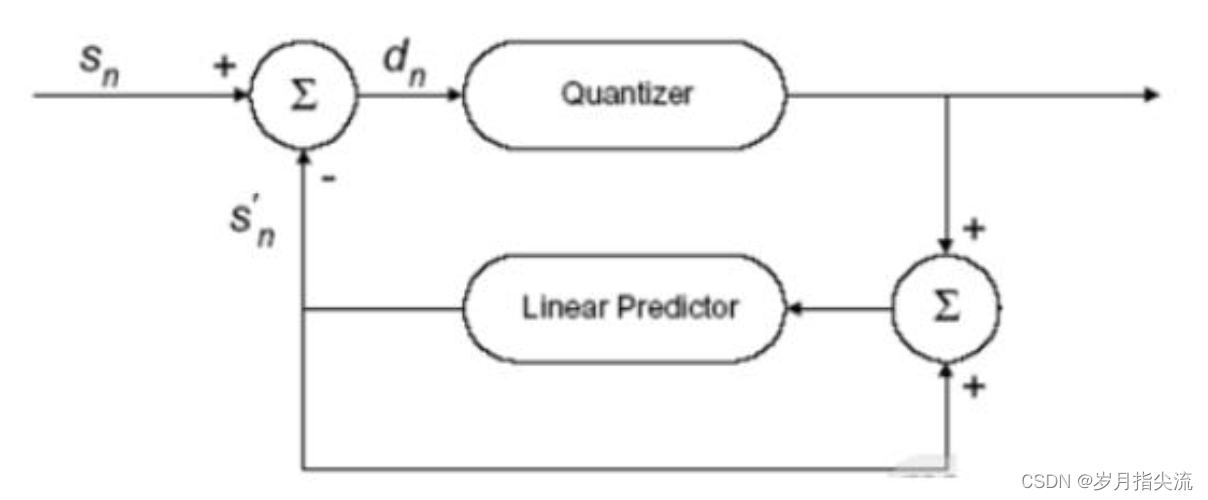
- DPCM:differential pulse code modulation,差分脉冲编码,只对样本之间的差异进行编码。前一个或多个样本用来预测当前样本值。 用来做预测的样本越多,预测值越精确。 真实值和预测值之间的差值叫残差,是编码的对象。
- ADPCM:adaptive differential pulse code modulation,自适应差分脉冲编码。即在 DPCM 的基础上,根据信号的变化,适当调整量化器和预测器,使预测值更接近真实信号,残差更小,压缩效率更高。
2)、频域编码
频域编码是把信号分解成一系列不同频率的元素,并进行独立编码。
-
sub-band coding:子带编码是最简单的频域编码技术。
是将原始信号由时间域转变为频率域, 然后将其分割为若干个子频带, 并对其分别进行数字编码的技术。
它是利用带通滤波器(BPF)组把原始信号分割为若干(例如 m 个)子频带(简称子带)。 将各子带通过等效于单边带调幅的调制特性, 将各子带搬移到零频率附近, 分别经过 BPF(共 m个)之后,再以规定的速率(奈奎斯特速率)对各子带输出信号进行取样,并对取样数值进行通常的数字编码,其设置 m 路数字编码器。
将各路数字编码信号送到多路复用器,最后输出子带编码数据流。对不同的子带可以根据人耳感知模型,采用不同量化方式以及对子带分配不同的比特数。 -
transform coding:DCT 编码。
离散余弦代码转换
3)、声码器
- channel vocoder:利用人耳对相位的不敏感。
- homomorphic vocoder:能有效地处理合成信号。
- formant vocoder:以用语音信号的绝大部分信息都位于共振峰的位置与带宽上。
- linear predictive vocoder:最常用的声码器。
4)、混合编码器
波形编码器试图保留被编码信号的波形,能以中等比特率(32kbps) 提供高品质语音,但无法应用在低比特率场合。声码器试图产生在听觉上与被编码信号相似的信号,能以低比特率提供可以理解的语音,但是所形成的语音听起来不自然。
混合编码器结合了 2 者的优点:
- RELP:在线性预测的基础上,对残差进行编码
- 机制为:只传输小部分残差,在接受端重构全部残差(把基带的残差进行拷贝)。
- MPC:multi-pulse coding,对残差去除相关性
- 用于弥补声码器将声音简单分为 voiced 和 unvoiced,而没有中间状态的缺陷。
- CELP: codebook excited linear prediction
- 用声道预测其和基音预测器的级联,更好逼近原始信号。
- MBE: multiband excitation
- 多带激励,目的是避免 CELP 的大量运算,获得比声码器更高的质量。
4、音频压缩格式
①、WAV 编码
WAV 编码是在 PCM 数据格式的前面加上 44 字节,分别用来描述 PCM 的采样率、声道数、数据格式等信息。
特点:音质非常好、大量软件都支持。
使用场景:多媒体开发的中间文件、保存音乐和音效素材等。

②、mp3 编码
MP3 具有不错的压缩比,使用 LAME 编码的中高码率的 MP3 文件,听感上非常接近源 WAV 文件。
特点:音质在 128Kbps 以上表现还不错,压缩比比较高,兼容性好。
使用场景:高比特率下对兼容性有要求的音乐欣赏
③、AAC 编码
AAC 是新一代的音频有损压缩技术,它通过一些附加编码技术( 如 PS、 SBR 等),衍生出 LC-AAC、HE-AAC、HE-AAC V2 三中主要编码格式。
特点:在小于 128kbps 码率下表现优异,且多用于视频中的音频编码。
适用场景:128Kbps 码率下的音频编码, 多用于视频中的音频轨的编码。
④、Ogg 编码
Ogg 编码音质好、完全免费。可以用更小的码率达到更好的音质,128Kbps 的 Ogg 比 192Kbps 甚至更高的 MP3 还要出色。 但是目前媒体软件支持上还是不够友好。
特点:高中低码率下都有良好的表现,兼容性不够好,流媒体特性不支持。
使用场景:语音聊天的音频消息场景。
⑤、FLAC 编码
FLAC 中文可解释为无损音频压缩编码。
FLAC 是一套著名的自由音频压缩编码,其特点是无损压缩。不同于其他有损压缩编码如 MP3 及 AAC,它不会破坏任何原有的音频信息,所以可以还原音乐光盘音质。
2012 年以来它已被很多软件及硬件音频产品( 如 CD 等) 所支持。
特点: 无损压缩、压缩率高于普通文件夹压缩格式( ZIP、 rar 等)。使用场景:高品质音乐等。
三、音频深度学习
1、深度学习在音频信号处理中的进展
主要从语音(Speech) 、音乐(Music) 和环境声(Environmental Sounds) 三个领域出发,分析它们之间的相似点和不同点,以及一些跨领域的通用方法描述。
2、应用
①、语音识别
语音识别指的是将语音信号转化为文字序列,它是所有基于语音交互的基础。对于语音识别而言,高斯混合模型(GMM)和马尔科夫模型(HMM)曾占据了几十年的发展历史。
②、音乐信息检索
和语音不同, 音乐通常包含很广泛的声源信息, 并且在不同音乐源之间存在这复杂的依赖关系。
③、环境声识别
有关环境声的任务主要有三类:声音场景识别、声音事件检测和标注。
④、定位和跟踪
利用多通道信号可以对声源位置进行跟踪和定位。跟踪和定位的主要设备条件是麦克风阵列,通常包含线性阵列、环形阵列和球形阵列等。
⑤、声源分离
指的是在多声源混合的信号中提取单一的目标声源。主要应用在一些鲁棒声音识别的预处理以及音乐编辑和重谱。
⑥、声音增强
通常为语音增强, 指的是通过减小噪声来提高语音质量。 主要技术是去噪自编码器、CNN、RNN、GAN(SEGAN) 等。
⑦、生成模型
根据数据集中的声音属性特征来生成新的数据,要求这些数据不能和原始数据集一样、要具有多样性并且训练和生成时间要很小,理想情况下是实时的。
3、十大音频处理任务
①、音频分类
音频分类是语音处理领域的一个基本问题,从本质上说,它就是从音频中提取特征,然后判断具体属于哪一类。
②、音频指纹识别
音频指纹识别的目的是从音频中提取一段特定的数字摘要,用于快速识别该段音频是否来自音频样本,或从音频库中搜索出带有相同数字摘要的音频。
③、自动音乐标注
音乐标注是音频分类的升级版。它包含多个类别,一个音频可以同时属于不同类,也就是有多个标签。自动音乐标注的潜在应用是为音频创建元数据,以便日后的搜索,在这上面,深度学习在一定程度上有用武之地。
④、音频分割
根据定义的一组特征将音频样本分割成段。
⑤、音源分离
音源分离就是从一堆混合的音频信号中分离出来自不同音源的信号,它最常见的应用之一就是识别同时翻译音频中的歌词(如卡拉 OK) 。
⑥、节拍跟踪
节拍跟踪的目标就是跟踪音频文件中每个节拍的位置。
⑦、音乐推荐
⑧、音乐信息检索
这是音频处理中最困难的任务之一, 它实质上是要建立一个基于音频数据的搜索引擎。
⑨、音乐转录(Music Transcription)
音乐转录是另一个非常有挑战性的音频处理任务。 它包括注释音频和创建一个“表”, 以便于之后用它生成音乐
⑩、音符起始点检测
音符起始点检测是分析音频/建立音乐序列的第一步,对于以上提到的大多数任务而言,执行音符起始点检测是必要的(简单任务不需要)
我的qq:2442391036,欢迎交流!
相关文章:
音频基础知识
文章目录 前言一、音频基本概念1、音频的基本概念①、声音的三要素②、音量与音调③、几个基本概念④、奈奎斯特采样定律 2、数字音频①、采样②、量化③、编码④、其他相关概念<1>、采样位数<2>、通道数<3>、音频帧<4>、比特率(码率&#…...

TensorFlow(R与Python系列第四篇)
目录 一、TensorFlow介绍 二、张量 三、有用的TensorFlow运算符 四、reduce系列函数实现约减 1-第一种理解方式:引入轴概念后直观可理 2-第二种理解方式:按张量括号层次的方式 参考: 一、TensorFlow介绍 TensorFlow是一个强大的用于数…...

华为数通方向HCIP-DataCom H12-821题库(单选题:261-280)
第261题 以下关于IPv6过渡技术的描述,正确的是哪些项? A、转换技术的原理是将IPv6的头部改写成IPv4的头部,或者将IPv4的头部改写成IPv6的头部 B、使用隧道技术,能够将IPv4封装在IPv6隧道中实现互通,但是隧道的端点需要支持双栈技术 C、转换技术适用于纯IPv4网络与纯IPv…...

论文《基于概率标签估计的半监督日志缺陷检测》翻译
论文《Semi-supervised Log-based Anomaly Detection via Probabilistic Label Estimation》翻译 Semi-supervised Log-based Anomaly Detection via Probabilistic Label Estimation翻译...
ajax day2
1、 2、控制弹框显示和隐藏: 3、右键tr,编辑为html,可直接复制tr部分的代码 4、删除时,点击删除按钮,可以获取图书id: 5、编辑图书 快速赋值表单元素内容,用于回显: 6、hidden …...
)
互联网摸鱼日报(2023-09-04)
互联网摸鱼日报(2023-09-04) 36氪新闻 腾讯游戏的棋中妙手 逐一解读北交所8大改革组合拳 本周双碳大事:全国碳市场清缴履约工作全面展开;宁德时代在成都成立新能源研究院;我国首个万吨级光伏发电直接制绿氢项目投产 你在上海 city walk&a…...
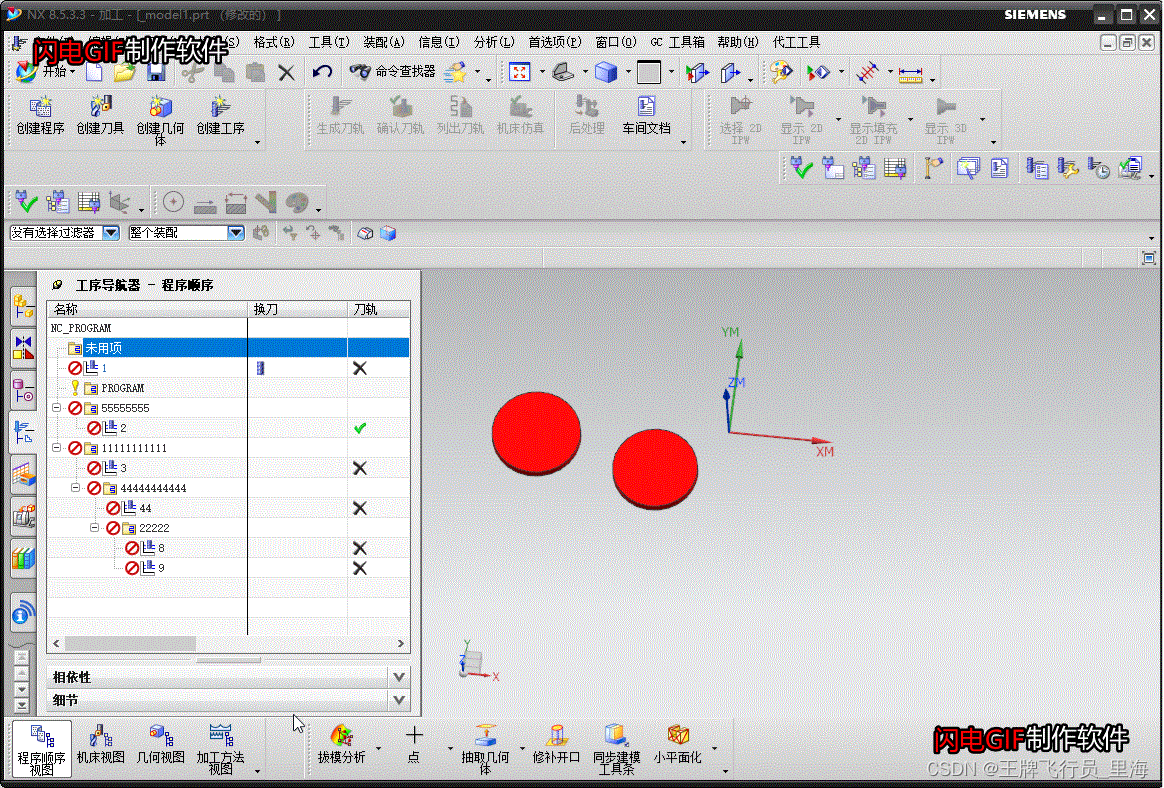
UG\NX CAM二次开发 遍历组中的工序 UF_NCGROUP_ask_member_list
文章作者:代工 来源网站:NX CAM二次开发专栏 简介: UG\NX CAM二次开发 遍历组中的工序 UF_NCGROUP_ask_member_list 效果: 代码: void GetAllOperTag(tag_t groupTag, vector<tag_t> &vOperTags) {int count=0;tag_t * list;UF_NCGROUP_ask_member_li…...

适配器、装饰器模式
一、装饰器模式 向一个现有的对象增加其功能而不改变其结构,属于类的包装...

Netty服务端启动的整体流程-基于源码4.1.96Final分析
Netty采用的是主从Reactor多线程的模型,参考Scalable IO in Java,但netty的subReactor为一个组 一、从FileServer服务器示例入手 public final class FileServer {static final boolean SSL System.getProperty("ssl") ! null;// Use the …...

预训练Bert添加new token的问题
问题 最近遇到使用transformers的AutoTokenizer的时候,修改vocab.txt中的[unused1]依然无法识别相应的new token。 实例: 我将[unused1]修改为了[TRI],句子中的[TRI]并没有被整体识别,而是识别为了[,T,RI,]。这明显是有问题的。…...

非常典型和高效的枚举类写法
目录 1、讲讲好处 2、例子 (1)枚举类: (2)DTO类: 3、根据上面例子进行具体讲解 1、讲讲好处 在使用这种标准枚举模式编写业务逻辑时,可以直接通过枚举成员来表示状态,不需要担心底层的 value 或描述信…...

kafka-- kafka集群环境搭建
kafka集群环境搭建 # 准备zookeeper环境 (zookeeper-3.4.6) # 下载kafka安装包 https://archive.apache.org/dist/kafka/2.1.0/kafka_2.12-2.1.0.tgz # 上传 : 172.16.144.133 cd /usr/local/softwaretar -zxvf /usr/local/software/kafka_2.12-2.1.0.tgz -C /usr/local…...

3.flask-sqlalchemy ORM库
介绍 Flask-SQLAlchemy是一个用于Flask的扩展,它提供了一个便捷的方式来处理数据库操作。Flask-SQLAlchemy基于SQLAlchemy,一个功能强大的Python SQL工具包和对象关系映射(ORM)系统 官网文档:http://www.pythondoc.com/flask-sql…...

mac 安装 homebrew
摘要: 本文主要是下载安装包安装homebrew,然后配置环境变量Path。检验是否安装成功。 homebrew地址:macOS(或 Linux)缺失的软件包的管理器 — Homebrew 在终端命令下载安装: /bin/bash -c "$(curl…...

R语言应用interactionR包进行亚组相加交互作用分析
在统计分析中交互作用是指某因素的作用随其他因素水平变化而变化,两因素共同作用不等于两因素单独作用之和(相加交互作用)或之积(相乘交互作用)。相互作用的评估是尺度相关的:乘法或加法。乘法尺度上的相互作用意味着两次暴露的综合效应大于(…...

mysql 数据库面试题整理
Mysql 中 MyISAM 和 InnoDB 的区别 1、InnoDB 支持事务MyISAM 不支持 2、InnoDB 支持外键MyISAM 不支持 3、InnoDB 是聚集索引,MyISAM 是非聚集索引 4、InnoDB 不保存表的具体行数 5、InnoDB 最小的锁粒度是行锁,MyISAM是表锁 mysql中有就更新…...

LeetCode-435-无重叠区间
题目链接: 力扣435 -无重叠区间 解题思路:和之前的合并区间、汇总区间都比较相似, 先对二维数组排序,按照左边界升序;当 当前区间的左区间 < 前一个区间的右区间,说明有重叠,res1,还要更新当…...
)
记录深度学习常用指令(一)
一、创建Conda虚拟Python环境 conda create -n [仓库名字] python[版本]二、激活环境 conda activate [仓库名字]三、安装PyTorch PyTorch官方 GPU: conda install pytorch1.11.0 torchvision0.12.0 torchaudio0.11.0 cudatoolkit11.3 -c pytorchCPU࿱…...

Shell脚本练习——系统应用相关
显示系统信息 [rootwenzi data]#cat systemInfo.sh #/bin/bash RED"\E[1;31m" GREEN"\E[1;32m" END"\E[0m" echo -e "$GREEN----------------------Host systeminfo--------------------$END" echo -e "HOSTNAME: $REDho…...

同创永益入选首批“金融数字韧性与混沌工程实践试点机构”
8月16日下午,由北京国家金融科技认证中心、北京国家金融标准化研究院联合主办的“传递信任 服务发展”金融科技标准认证生态大会在太原成功举办。中国金融电子化集团有限公司党委书记、董事长周逢民,中国科学院院士冯登国,中国工商银行首席技…...

LabVIEW TCP通讯实战:从零搭建一个工业数据采集服务器
1. LabVIEW TCP通讯在工业数据采集中的应用价值 工业现场的数据采集系统对通讯稳定性有着近乎苛刻的要求。记得我第一次参与某汽车生产线改造项目时,产线上的PLC和传感器每分钟要上传近万条数据,传统的串口通讯根本吃不消。当时团队尝试了多种方案&#…...

企业级部署警告:Perplexity事实核查功能未开启溯源审计模式的5大合规风险,GDPR/CCPA双认证团队紧急通告
更多请点击: https://codechina.net 第一章:Perplexity事实核查功能的核心机制与合规定位 Perplexity 的事实核查功能并非依赖单一模型输出,而是构建于多层验证架构之上:实时检索增强生成(RAG)、跨源可信度…...

3大策略掌握Avidemux视频编辑:从源码编译到专业级处理
3大策略掌握Avidemux视频编辑:从源码编译到专业级处理 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款开源跨平台视频编辑工具,专注于快速剪辑、编码转换和批…...

使用curl命令直接测试taotoken api的连通性与基础功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用curl命令直接测试taotoken api的连通性与基础功能 基础教程类,面向需要快速验证或在不便安装SDK的环境中进行操作的…...

网盘直链下载助手完整教程:免费获取八大平台真实下载地址,告别限速烦恼
网盘直链下载助手完整教程:免费获取八大平台真实下载地址,告别限速烦恼 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里…...

CANN/asc-devkit Erfc接口文档
Erfc 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...

在macOS上轻松运行Windows应用:Whisky完整使用指南
在macOS上轻松运行Windows应用:Whisky完整使用指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 想在Apple Silicon Mac上直接运行Windows软件和游戏,又不想…...
4大技术支柱:构建Pixelle-Video的模块化AI视频生成系统
4大技术支柱:构建Pixelle-Video的模块化AI视频生成系统 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 传统视频制作流程需要…...

终极Il2CppDumper使用指南:从原理到实战的Unity逆向工程利器
终极Il2CppDumper使用指南:从原理到实战的Unity逆向工程利器 【免费下载链接】Il2CppDumper Unity il2cpp reverse engineer 项目地址: https://gitcode.com/gh_mirrors/il/Il2CppDumper Il2CppDumper是一款强大的Unity il2cpp逆向工程工具,能够帮…...

Realtime-VLA V2——从让π0实时抓取下落的钢笔到让 VLA 运行得更快、更平滑且更精确
前言今天在朋友圈刷到一则新闻,称《开普勒机器人被A股公司收购,前任CEO已离职创业》我仔细看了全文,还是多有感慨其实对双足,3-5家今年可继续卷跳舞 跑步 打拳及比赛/陪练(乒乓球/网球/羽毛球等)而3-5家之外的双足,得另…...