[github-100天机器学习]day4+5+6 Logistic regression
https://github.com/MLEveryday/100-Days-Of-ML-Code/blob/master/README.md
逻辑回归
逻辑回归用来处理不同的分类问题,这里的目的是预测当前被观察的对象属于哪个组。会给你提供一个离散的二进制输出结果,一个简单例子:判断一个人是否会在选举中投票。
how to work
逻辑回归使用基础逻辑函数通过估算概率来测量因变量和自变量间的关系。
做出预测
这些概率值必修转换成二进制数,以便实际中进行预测。这是逻辑函数sigmoid的任务,然后使用阈值分类器将(0,1)范围的值转换为0和1的值来表示结果。
区别
逻辑回归给出离散的输出
线性回归给出连续的输出
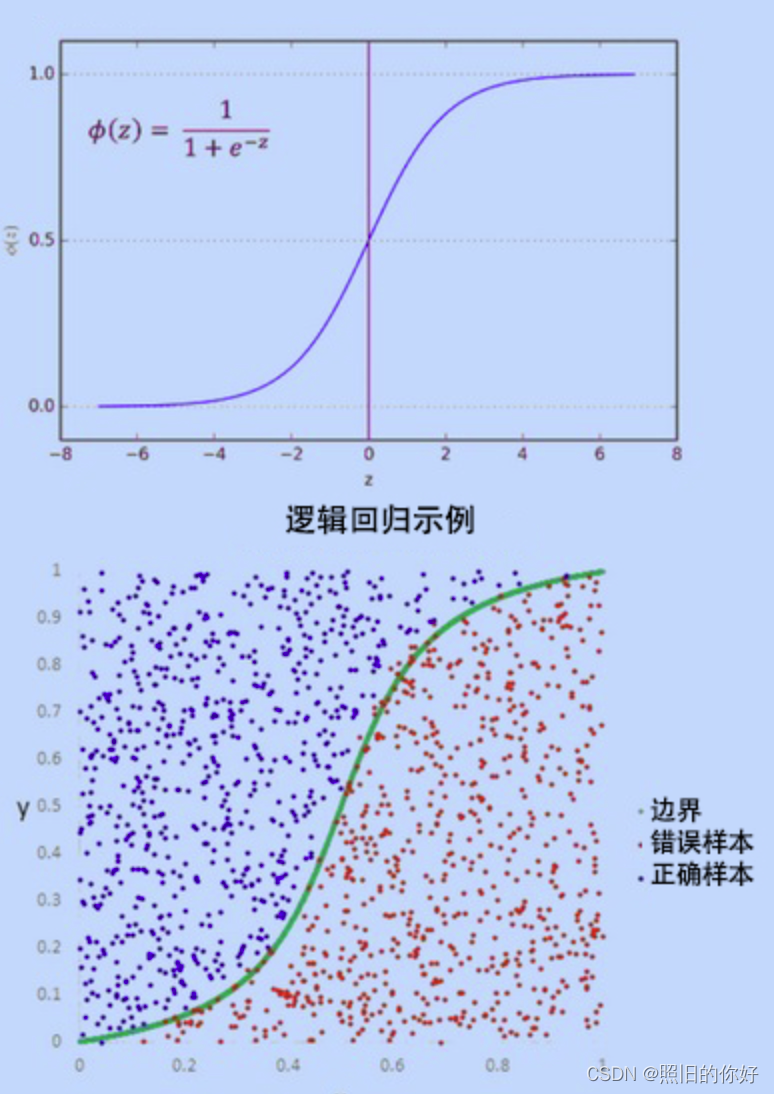
sigmoid函数
一个S型曲线,可以实现将任意真实值映射为值域范围为0-1的值
θ ( s ) = \theta(s)= θ(s)= 1 1 + e − s {1\over 1+e^{-s}} 1+e−s1
极大似然估计–Maximum Likelihood Estimation
利用已知样本结果,反推最有可能导致这样结果的参数值。
用于估计参数,使得观测数据在给定模型下的概率最大化。
极大似然估计的核心思想是,选择使观测数据出现的概率最大的参数值,因为这些参数值使数据出现的可能性最高。
基本原理
- 定义模型:首先,需要定义一个概率模型,通常用参数化的概率分布表示。这个模型包括一个参数向量(或参数集),需要估计。
- 建立似然函数:似然函数是关于模型参数的函数,它描述了给定参数值时观测数据的可能性。似然函数通常用 L ( θ ∣ x ) L(θ|x) L(θ∣x), θ θ θ是要估计的参数, x x x是观测数据。
- 最大化似然函数:通过找到使似然函数最大化的参数 θ θ θ,来进行估计。这通常可以通过计算似然函数的梯度,并使用数值优化方法(如梯度下降或牛顿法)来实现。
- 估计结果:得到最大似然估计就可以用它来代表参数的估计值。通常,估计的参数值具有使观测数据出现的可能性最大化的性质。
特征缩放
StandardScaler通过以下方式进行特征缩放:
计算每个特征的均值(mean)和标准差(standard deviation)。
对每个特征进行标准化,使其具有均值为0和标准差为1的分布。具体计算方式是将每个特征的值减去均值,然后除以标准差。
###1
import numpy as np
import matplotlib.pyplot as plt
import pandas as pddataset = pd.read_csv('Social_Network_Ads.csv')
X = dataset.iloc[:, [2, 3]].values ## 选取2,3两列--Age+ salary
y = dataset.iloc[:, 4].values ## 选取最后一列#from sklearn.cross_validation import train_test_split#old
from sklearn.model_selection import train_test_split, cross_val_score#new
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)# 特征缩放是数据预处理的一个重要步骤,它有助于确保不同特征之间的尺度一致,避免某些特征对模型训练产生过大的影响。
from sklearn.preprocessing import StandardScaler ##特征缩放
sc = StandardScaler()# 使用了StandardScaler类来标准化特征
X_train = sc.fit_transform(X_train)
# 在训练集上计算均值和标准差,并进行特征缩放
X_test = sc.transform(X_test)
# 在测试集上使用相同的均值和标准差进行特征缩放### 2
from sklearn.linear_model import LogisticRegression
# 使用了scikit-learn(sklearn)库中的逻辑回归(Logistic Regression)模型,
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
# X_train 是训练集的特征数据,y_train 是对应的训练集目标(标签)。
# 通过拟合(fitting)逻辑回归模型,模型会学习如何根据输入特征来预测目标变量 y。
### 3
y_pred = classifier.predict(X_test)# 使用训练好的模型进行预测
# predict 方法接受测试数据作为输入,然后返回模型根据输入数据的特征所做的预测。
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
# 对预测结果进行评估
# 使用了 confusion_matrix 函数来计算混淆矩阵,以便对分类模型的性能进行评估。
# 混淆矩阵是评估分类模型的一个重要工具,它显示了模型的预测结果与实际标签之间的关系
具体来说,混淆矩阵包含以下四个关键指标:
真正例(True Positives,TP):模型正确预测为正类别的样本数量。
假正例(False Positives,FP):模型错误预测为正类别的样本数量。
真负例(True Negatives,TN):模型正确预测为负类别的样本数量。
假负例(False Negatives,FN):模型错误预测为负类别的样本数量。
通过这些指标,您可以计算各种性能指标,如准确率、召回率、精确度和F1分数
# 计算准确率
accuracy = (TP + TN) / (TP + TN + FP + FN)# 计算召回率
recall = TP / (TP + FN)# 计算精确度
precision = TP / (TP + FP)# 计算F1分数
f1_score = 2 * (precision * recall) / (precision + recall)# 绘制分类器的决策边界和数据点的可视化
# 使用了matplotlib库来创建决策区域图,并将测试集的样本点可视化
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.colors import ListedColormapdef plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):# setup marker generator and color mapmarkers = ('s', 'x', 'o', '^', 'v')colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')cmap = ListedColormap(colors[:len(np.unique(y))])# plot the decision surfacex1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)Z = Z.reshape(xx1.shape)plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)plt.xlim(xx1.min(), xx1.max())plt.ylim(xx2.min(), xx2.max())# plot class samplesfor idx, cl in enumerate(np.unique(y)):plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],alpha=0.8, c=cmap(idx),marker=markers[idx], label=cl)# highlight test samplesif test_idx:X_test, y_test = X[test_idx, :], y[test_idx]plt.scatter(X_test[:, 0], X_test[:, 1], c='', alpha=1.0, linewidth=1, marker='o', s=55, label='test set')plot_decision_regions(X_test, y_pred, classifier=classifier)
plt.xlabel('age')
plt.ylabel('salary')
plt.legend(loc='upper left')
plt.title("Test set")
plt.show()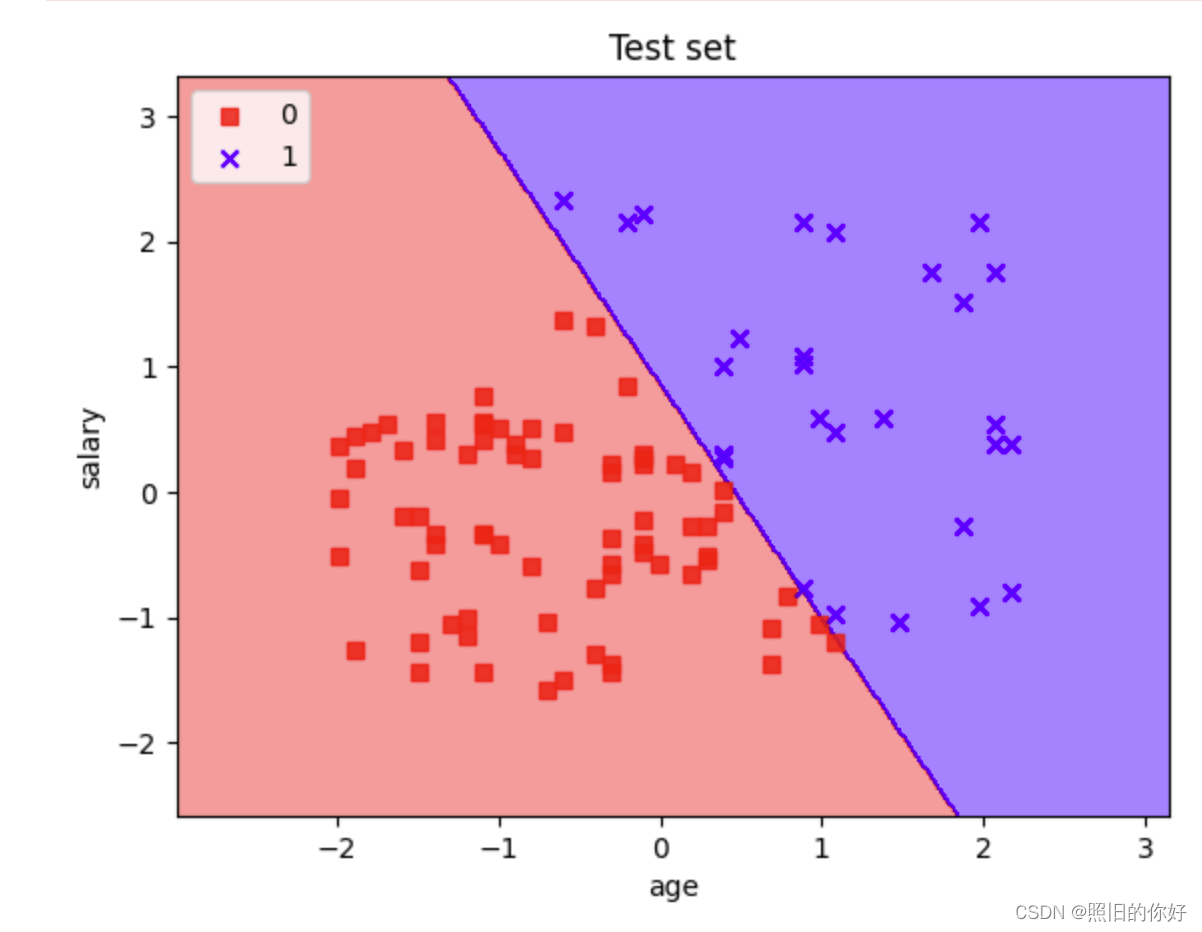
相关文章:
[github-100天机器学习]day4+5+6 Logistic regression
https://github.com/MLEveryday/100-Days-Of-ML-Code/blob/master/README.md 逻辑回归 逻辑回归用来处理不同的分类问题,这里的目的是预测当前被观察的对象属于哪个组。会给你提供一个离散的二进制输出结果,一个简单例子:判断一个人是否会在…...

【菜鸡学艺–Vue2–001】模板语法声明式渲染
【菜鸡学艺–Vue2–001】模板语法&声明式渲染 🦖我是Sam9029,一个前端 Sam9029的CSDN博客主页:Sam9029的博客_CSDN博客-JS学习,CSS学习,Vue-2领域博主 **🐱🐉🐱🐉恭喜你,若此文你认为写…...
LabVIEW开发感应电机在线匝间短路故障诊断系统
LabVIEW开发感应电机在线匝间短路故障诊断系统 工业中使用的超过85%的电动机是三相感应电动机。它们因其可靠性、设计便利性、高性能和过载能力而被广泛用于不同的应用,例如制造、加工、电力系统、运输等。无论它们的能力如何,它们都被认为是现代工业学…...

Deepin / UOS 安装自带的Qt
Deepin / UOS 安装自带的Qt 安装Qt版本可从官网下载也可以使用Deepin / UOS 自己维护的Qt版本,好处是针对Deepin/UOS系统进行了针对性的优化,比如QtCreator的界面和系统UI保持一致。 查询Qt版本及是否安装 sudo apt policy qtbase5-devsudo apt polic…...

vite+vue3+element-plus
vitevue3element-plus 1.开始 npm create vitelatest app -- --template vuenpm installlnpm run dev2.引入element-ui npm install element-plus修改main.js import ElementPlus from element-plus import element-plus/dist/index.css createApp(App).use(ElementPlus).m…...
uni-app 之 tabBar 底部切换按钮
uni-app 之 tabBar 底部切换按钮 1693289945724.png {"pages": [ //pages数组中第一项表示应用启动页,参考:https://uniapp.dcloud.io/collocation/pages{"path": "pages/home/home","style": {"navigatio…...
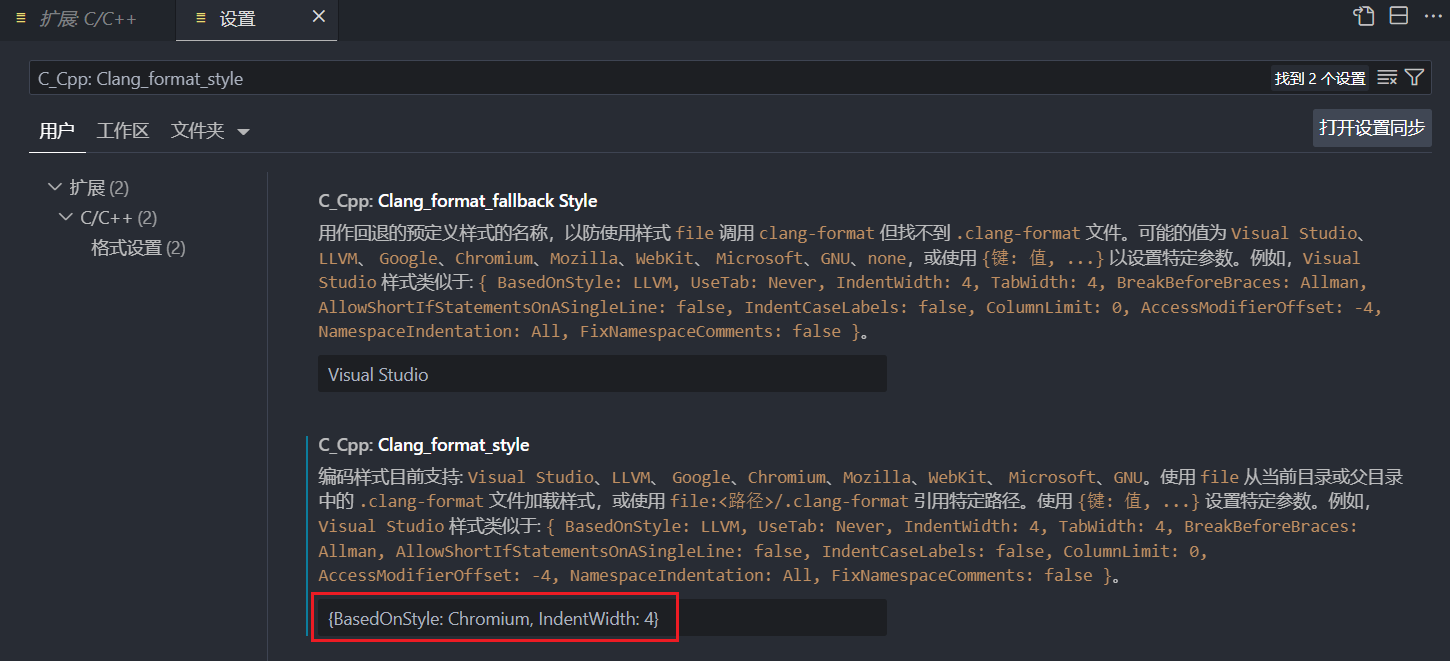
VSCode 配置 C 语言编程环境
目录 一、下载 mingw64 二、配置环境变量 三、三个配置文件 四、格式化代码 1、安装插件 2、保存时自动格式化 3、左 { 不换行 上了两年大学,都还没花心思去搭建 C 语言编程环境,惭愧,惭愧。 一、下载 mingw64 mingw64 是著名的 C/C…...

LeetCode 热题 100——找到字符串中所有字母异位词(滑动窗口)
题目链接 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 题目解析 该题目的意思简而言之就是说,从s字符串中寻找与p字符串含有相同字符(次数和种类均相同)的子串,并且将他们的首字符下标集合进数组中进行返回。 滑动窗口解…...

uniapp从零到一的学习商城实战
涵盖的功能: 安装开发工具HBuilder:HBuilderX-高效极客技巧 创建项目步骤: 1.右键-项目: 2.选择vue2和默认模板: 3.完整的项目目录: 微信开发者工具调试: 1.安装微信开发者工具 2.打开…...

应广单片机实现跑马灯
应广单片机处处体现其mini的特性,非常适合做各种方案开发,特别是点灯,什么跑马灯,氛围灯,遥控灯,感应灯,拍拍灯等,用应广都OK。 跑马灯是基础中的基础,我搭了一个框架&am…...
关于el-input和el-select宽度不一致问题解决
1. 情景一 单列布局 对于上图这种情况,只需要给el-select加上style"width: 100%"即可,如下: <el-select v-model"fjForm.region" placeholder"请选择阀门类型" style"width: 100%"><el-o…...

【Unity3D赛车游戏优化篇】【八】汽车实现镜头的流畅跟随,以及不同角度的切换
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

VScode连接远程JupyterNotebook显示点云ply文件
1. remote ssh的配置文件config中添加 Host Jupyter-ServerHostName <IP>ForwardX11 yesForwardX11Trusted yesForwardAgent yesUser <Username> 2. 在远程服务器的.sshd_config中把X11forward的开关打开为yes 3. 在home文件夹中更改.bashrc,加入以下…...
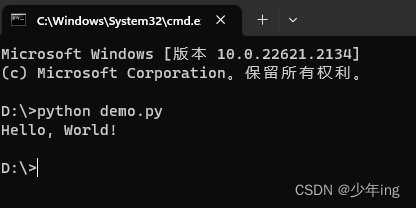
python安装wind10
一、下载: 官网:Python Releases for Windows | Python.org 二、安装 双击下载的安装程序文件。这将打开安装向导。安装界面图下方两个框的" Use admin privileges wheninstalling py. exe和” Add python. exe to PATH"都要勾选,一定要勾选!一定要勾选…...

uni-app 中 swiper 轮播图高度自适应
方法一 1、首先 swiper 标签的宽度是 width: 100% 2、swiper 标签存在默认高度是 height: 150px ;高度无法实现由内容撑开,在默认情况下,图片的高度显示总是 150px swiper 宽度 / swiper 高度 原图宽度 / 原图高度 swiper 高度 swiper …...
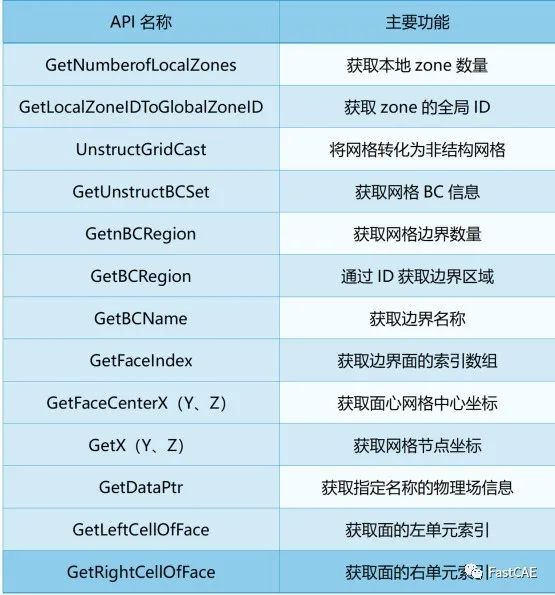
开源风雷CFD软件多物理场耦合接口开发路线分享!!!
本文将基于开发过程中积累的经验,介绍风雷如何基于preCICE开发适配器。 preCICE是一个开源的多物理场数值模拟耦合库,可以用于多个求解器联合求解一个复杂的多场问题,支持在大规模并行系统上应用,具有良好的并行效率。并且可以对…...

浅谈Mysql读写分离的坑以及应对的方案 | 京东云技术团队
一、主从架构 为什么我们要进行读写分离?个人觉得还是业务发展到一定的规模,驱动技术架构的改革,读写分离可以减轻单台服务器的压力,将读请求和写请求分流到不同的服务器,分摊单台服务的负载,提高可用性&a…...

最近在对接电商供应链,说说开放平台API接口
B2B电商开放平台的设计需要从以下几面去思考: 开放平台API接口的设计,主要是从功能需求的角度,设计满足业务需求的接口及对应的字段; 平台与商家之间信息的对接,对接的方法有哪些?对接过程中需要可能会遇到…...
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server
【FusionInsight 迁移】HBase从C50迁移到6.5.1(02)C50上准备FTP Server HBase从C50迁移到6.5.1(02)C50上准备FTP Server登录老集群FusionInsight C50的Manager准备FTP User准备FTP Server HBase从C50迁移到6.5.1(02&am…...

Java操作符学习笔记
1、布尔类型的逻辑操作符和按位操作符 & 和 &&、|| 和 | 其实是两种操作符。在使用逻辑判断时,有时不希望产生短路作用,会对两个布尔类型值使用单个的 & 或 |运算。这让我一直将单个 & 和 | 当成时逻辑操作符的一种,而事…...

瑞德克斯的本地团队反应是否积极?地区化支持完不完善?
瑞德克斯的本地团队反应是否积极?地区化支持完不完善?本地化服务是面向全球客户的金融机构必须重视的部分。瑞德克斯在多个区域市场都建立了本地化团队,让客户可以在熟悉的语言、文化背景下获得贴心的支持。瑞德克斯的本地化不仅停留在语言翻…...
)
DeepSeek SSO性能压测实录:单集群支撑5000+并发登录的4大调优阈值(含Prometheus监控指标基线)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek SSO单点登录性能压测全景概览 DeepSeek SSO 作为企业级统一身份认证中枢,其在高并发场景下的响应延迟、会话稳定性与令牌签发吞吐能力直接决定下游所有业务系统的可用性边界。本章…...

大模型应用开发指南:从入门到实践,收藏这份从Demo到生产落地的完整攻略
本文分享了AI应用开发中从Demo到生产落地的完整实践,涵盖技术选型、架构设计、核心算法优化及部署经验。通过LangGraph、RAGFlow和Langfuse等工具,解决上下文超限、Prompt管理混乱等问题,最终实现准确率提升25%的工业级AI系统。适合程序员和小…...

CANN/asc-devkit DropOut高阶API
DropOut 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

告警爆炸,根因定位困难?用DevOps Agent帮你自动查!
随着企业在亚马逊云科技上的工作负载日益复杂——Amazon EC2集群、Amazon RDS数据库、Amazon ECS/EKS容器、Amazon Lambda函数、网络与负载均衡等多种服务交织运行——运维团队面临严峻挑战:告警爆炸:Amazon CloudWatch、第三方监控(Datadog、…...

观察不同模型在Taotoken平台上的实际响应速度与效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察不同模型在Taotoken平台上的实际响应速度与效果差异 在开发与创作过程中,我们常常需要调用大模型API来完成文本生成…...

对比官方原价Taotoken活动价带来的Token成本优化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方原价与Taotoken活动价带来的Token成本优化感受 1. 引言:开发者视角下的模型调用成本 对于频繁使用大模型API进…...

【DeepSeek×GCP联合认证部署方案】:谷歌云架构师与DeepSeek官方工程师联名验证的3种生产级拓扑
更多请点击: https://codechina.net 第一章:DeepSeek GCP部署指南 在Google Cloud Platform上部署DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)需兼顾计算性能、存储效率与网络低延迟。本指南基于GCP的Vertex AI平台与…...

终极指南:掌握WinPmem Windows内存取证采集核心技术
终极指南:掌握WinPmem Windows内存取证采集核心技术 【免费下载链接】WinPmem The multi-platform memory acquisition tool. 项目地址: https://gitcode.com/gh_mirrors/wi/WinPmem WinPmem作为Windows平台物理内存采集的标杆工具,为安全分析师和…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...