使用Akka的Actor模拟Spark的Master和Worker工作机制
使用Akka的Actor模拟Spark的Master和Worker工作机制
Spark的Master和Worker协调工作原理
在 Apache Spark 中,Master 和 Worker 之间通过心跳机制进行通信和保持活动状态。下面是 Master 和 Worker 之间心跳机制的工作流程:
- Worker 启动后,会向预先配置的 Master 节点发送注册请求。
- Master 接收到注册请求后,会为该 Worker 创建一个唯一的标识符(Worker ID)并将其信息保存在内存中。
- Master 向 Worker 发送包含 Master URL、Worker ID 等信息的注册响应。
- Worker 收到注册响应后,会启动一个定时器并开始周期性地向 Master 发送心跳消息。
- Worker 的心跳消息中包含当前的负载状况、可用资源等信息。
- Master 接收到心跳消息后,更新该 Worker 的最近心跳时间,并根据需要对集群进行动态调整,例如添加新的任务或删除故障的 Worker。
- 如果 Master 在一段时间内没有收到某个 Worker 的心跳消息,它将把该 Worker 标记为失效,并将其相应的资源标记为可用以供后续使用。
具体原理如下:
- Worker 通过网络向 Master 发送心跳消息,通常使用基于 TCP 的长连接。这些心跳消息可以包含有关 Worker 健康状况、资源利用情况等的信息。
- Master 使用一个内部的心跳管理组件来处理接收到的心跳消息,并维护每个 Worker 的状态。它根据心跳消息的频率和时间戳来判断 Worker 是否正常运行。
- 如果 Master 在预定的时间内没有收到 Worker 的心跳消息,它会将该 Worker 标记为失效并触发一系列的故障处理机制,例如重新分配任务给其他可用的 Worker。
- Worker 定期发送心跳消息,以确保在网络故障、Worker 故障或其他问题发生时能够及时通知 Master。
通过心跳机制,Master 能够实时监控 Worker 的状态,并根据需要进行集群的动态管理和资源调度,从而实现高可用性和容错性。
使用Akka的Actor模拟Spark的Master和Worker工作机制
- worker注册到Master, Master完成注册,并回复worker注册成功。
- worker定时发送心跳,并在Master接收到。
- Master接收到worker心跳后,要更新该worker的最近一次发送心跳的时间。
- 给Master启动定时任务,定时检测注册的worker有哪些没有更新心跳,并将其从hashmap中删除。
- master worker 进行分布式部署(Linux系统)-》如何给maven项目打包->上传linux。
- 创建SparkMaster类继承Actor特质,实现Receive方法,并定义对应的伴生对象,在伴生对象中创建SparkMaster-actor引用,并启动Actor发送消息。服务端Master对worker进行心跳监测,发现6秒内无法获取worker心跳,将异常的Worker的实例从HashMap中移除。若能正常获取到心跳,则获取心跳信息后更新心跳时间。定时保持心跳机制。
代码实现:
class SparkMaster extends Actor {//定义个hashMap,管理workers(所有worker的实例)val workers = mutable.Map[String, WorkerInfo]()override def receive: Receive = {case "start" => {println("master服务器启动了...")//这里开始。。self ! StartTimeOutWorker}case RegisterWorkerInfo(id, cpu, ram) => {//接收到worker注册信息if (!workers.contains(id)) {//创建WorkerInfo 对象val workerInfo = new WorkerInfo(id, cpu, ram)//加入到workersworkers += ((id, workerInfo))println("服务器的workers=" + workers)//回复一个消息,说注册成功sender() ! RegisteredWorkerInfo}}case HeartBeat(id) => {//更新对应的worker的心跳时间//1.从workers对应的HashMap中取出WorkerInfo,然后更新worker心跳时间val workerInfo = workers(id)workerInfo.lastHeartBeat = System.currentTimeMillis()println("master更新了 " + id + " 心跳时间...")}case StartTimeOutWorker => {println("开始了定时检测worker心跳的任务")import context.dispatcher//说明//1. 0 millis 不延时,立即执行定时器//2. 9000 millis 表示每隔3秒执行一次//3. self:表示发给自己//4. RemoveTimeOutWorker 发送的内容context.system.scheduler.schedule(0 millis, 9000 millis, self, RemoveTimeOutWorker)}//对RemoveTimeOutWorker消息处理//这里需求检测哪些worker心跳超时(now - lastHeartBeat > 6000),并从map中删除case RemoveTimeOutWorker => {//首先将所有的 workers 的 所有WorkerInfoval workerInfos = workers.valuesval nowTime = System.currentTimeMillis()//先把超时的所有workerInfo,删除即可workerInfos.filter(workerInfo => (nowTime - workerInfo.lastHeartBeat) > 6000).foreach(workerInfo => workers.remove(workerInfo.id))println("当前有 " + workers.size + " 个worker存活的")}}
}object SparkMaster {def main(args: Array[String]): Unit = {//这里我们分析出有3个host,port,sparkMasterActorif (args.length != 3) {println("请输入参数 host port sparkMasterActor名字")sys.exit()}val host = args(0)val port = args(1)val name = args(2)//先创建ActorSystemval config = ConfigFactory.parseString(s"""|akka.actor.provider="akka.remote.RemoteActorRefProvider"|akka.remote.netty.tcp.hostname=${host}|akka.remote.netty.tcp.port=${port}""".stripMargin)val sparkMasterSystem = ActorSystem("SparkMaster", config)//创建SparkMaster -actorval sparkMasterRef = sparkMasterSystem.actorOf(Props[SparkMaster], s"${name}")//启动SparkMastersparkMasterRef ! "start"}
}- 定义SparkWorker类继承Actor特质,实现Receive方法,在方法中实现向master发送注册信息的请求,获取到服务端Master注册成功的消息后,定义定时任务发送心跳包给Master。
class SparkWorker(masterHost:String,masterPort:Int,masterName:String) extends Actor{//masterProxy是Master的代理/引用refvar masterPorxy :ActorSelection = _val id = java.util.UUID.randomUUID().toStringoverride def preStart(): Unit = {println("preStart()调用")//初始化masterPorxymasterPorxy = context.actorSelection(s"akka.tcp://SparkMaster@${masterHost}:${masterPort}/user/${masterName}")println("masterProxy=" + masterPorxy)}override def receive:Receive = {case "start" => {println("worker启动了")//发出一个注册消息masterPorxy ! RegisterWorkerInfo(id, 16, 16 * 1024)}case RegisteredWorkerInfo => {println("workerid= " + id + " 注册成功~")//当注册成功后,就定义一个定时器,每隔一定时间,发送SendHeartBeat给自己import context.dispatcher//说明//1. 0 millis 不延时,立即执行定时器//2. 3000 millis 表示每隔3秒执行一次//3. self:表示发给自己//4. SendHeartBeat 发送的内容context.system.scheduler.schedule(0 millis, 3000 millis, self, SendHeartBeat)}case SendHeartBeat =>{println("worker = " + id + "给master发送心跳")masterPorxy ! HeartBeat(id)}}
}object SparkWorker {def main(args: Array[String]): Unit = {if (args.length != 6) {println("请输入参数 workerHost workerPort workerName masterHost masterPort masterName")sys.exit()}val workerHost = args(0)val workerPort = args(1)val workerName = args(2)val masterHost = args(3)val masterPort = args(4)val masterName = args(5)val config = ConfigFactory.parseString(s"""|akka.actor.provider="akka.remote.RemoteActorRefProvider"|akka.remote.netty.tcp.hostname=${workerHost}|akka.remote.netty.tcp.port=${workerPort}""".stripMargin)//创建ActorSystemval sparkWorkerSystem = ActorSystem("SparkWorker",config)//创建SparkWorker 的引用/代理val sparkWorkerRef = sparkWorkerSystem.actorOf(Props(new SparkWorker(masterHost, masterPort.toInt,masterName)), s"${workerName}")//启动actorsparkWorkerRef ! "start"}
}- 分别定义发送注册信息的RegisterWorkerInfo的样例类,WorkerInfo消息类,定义注册成功的消息样例对象RegisteredWorkerInfo,心跳信息样例类HeartBeat,以及确认发送心跳信息样例对象SendHeartBeat,触发超时work的样例对象StartTimeOutWorker,移除超时worker的样例对象RemoveTimeOutWorker。
代码如下:
// worker注册信息 //MessageProtocol.scala
case class RegisterWorkerInfo(id: String, cpu: Int, ram: Int)// 这个是WorkerInfo, 这个信息将来是保存到master的 hm(该hashmap是用于管理worker)
// 将来这个WorkerInfo会扩展(比如增加worker上一次的心跳时间)
class WorkerInfo(val id: String, val cpu: Int, val ram: Int) {var lastHeartBeat : Long = System.currentTimeMillis()
}// 当worker注册成功,服务器返回一个RegisteredWorkerInfo 对象
case object RegisteredWorkerInfo//worker每隔一定时间由定时器发给自己的一个消息
case object SendHeartBeat
//worker每隔一定时间由定时器触发,而向master发现的协议消息
case class HeartBeat(id: String)//master给自己发送一个触发检查超时worker的信息
case object StartTimeOutWorker
// master给自己发消息,检测worker,对于心跳超时的.
case object RemoveTimeOutWorker运行效果:
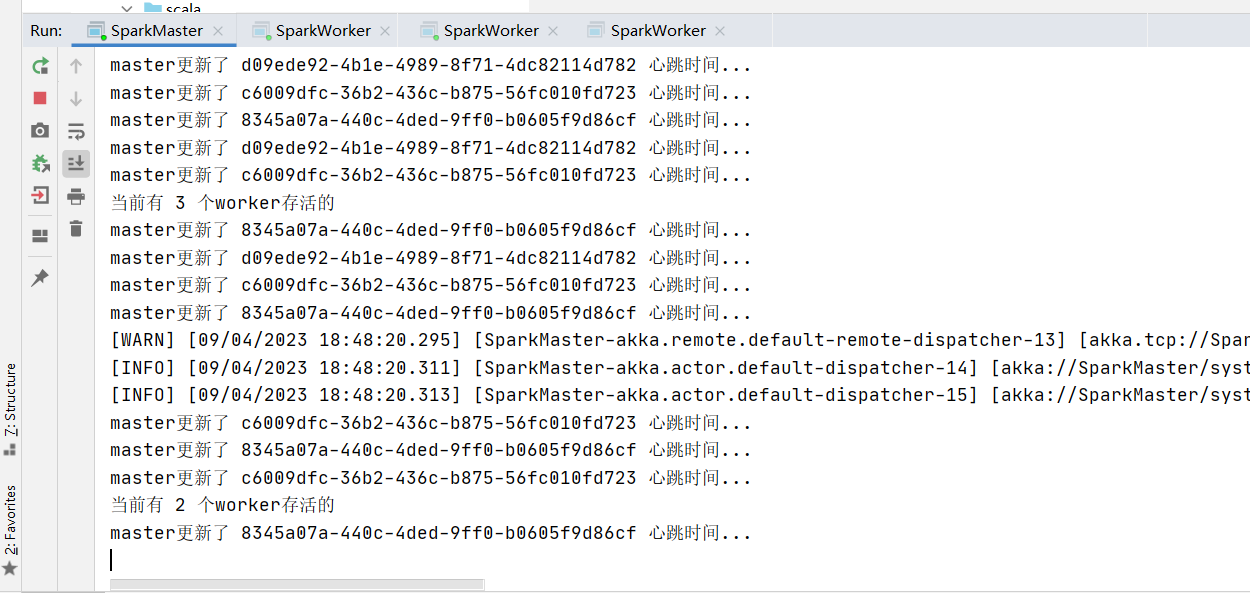
通过这个案例我们可以深入理解Spark的Master和Worker的通讯机制,为了方便以后对Spark的底层源码的学习,命名的方式和源码保持一致.(如: 通讯消息类命名就是一样的);同时也加深了我们对主从服务心跳检测机制(HeartBeat)的理解,方便以后spark源码二次开发。
相关文章:
使用Akka的Actor模拟Spark的Master和Worker工作机制
使用Akka的Actor模拟Spark的Master和Worker工作机制 Spark的Master和Worker协调工作原理 在 Apache Spark 中,Master 和 Worker 之间通过心跳机制进行通信和保持活动状态。下面是 Master 和 Worker 之间心跳机制的工作流程: Worker 启动后,…...
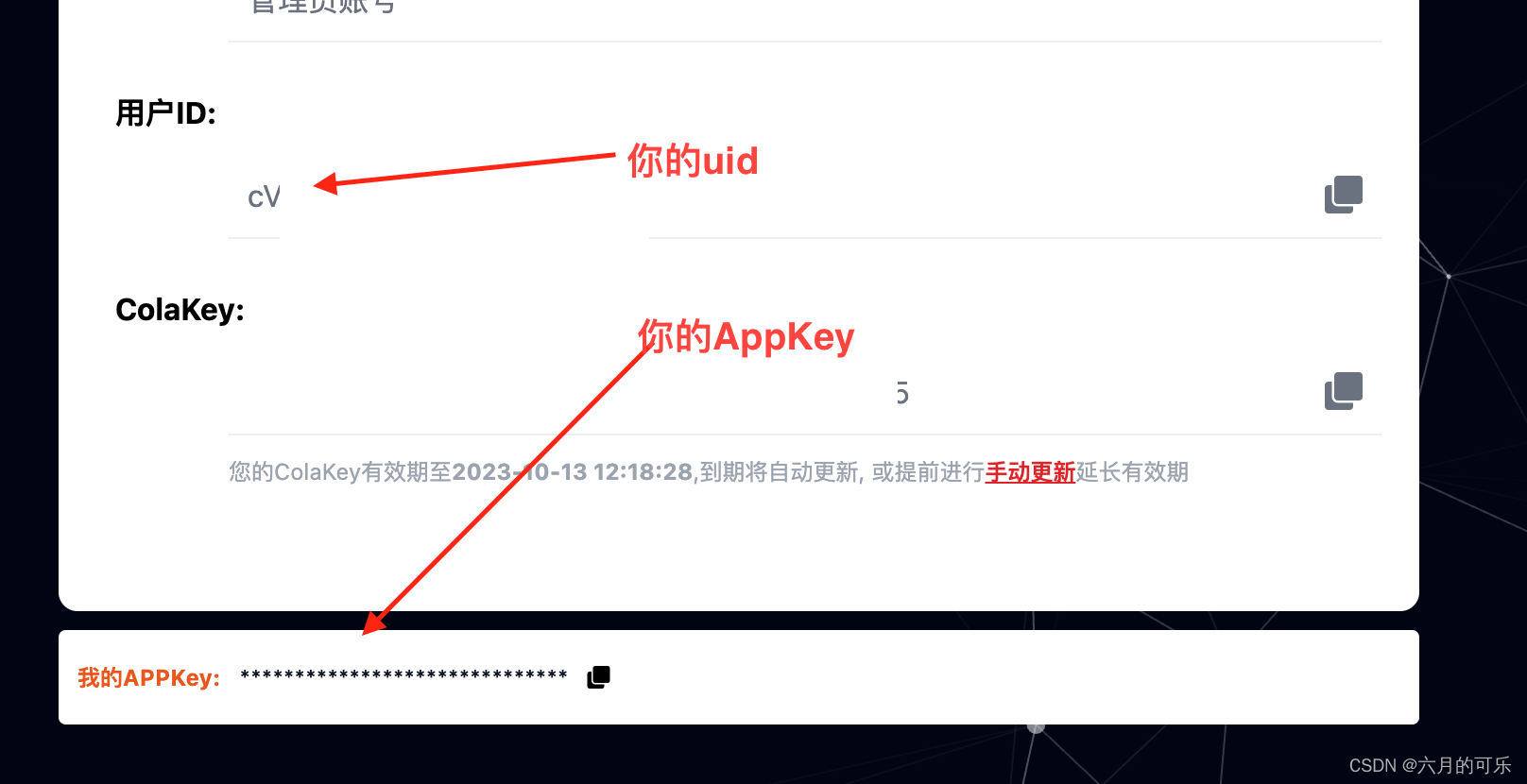
文心一言api接入如何在你的项目里使用文心一言
文心一言api接入在项目里接入文心一言 一、百度文心一言API二、使用步骤1、接口2、请求参数3、请求参数示例4、接口 返回示例 三、 如何获取appKey和uid1、申请appKey:2、获取appKey和uid 四、重要说明 一、百度文心一言API 基于百度文心一言语言大模型的智能文本对话AI机器人…...
)
Python匿名函数lambda(R与Python第五篇)
目录 一、为什么要引入“lambda函数”? 二、匿名函数的两种用法 参考: 本文来源:《Python全案例学习与实践》(2019年9月出版,电子工业出版社) Python允许使用一种无名的函数,称其为匿名函数…...

【2023校园招聘】 钉钉AI应用开发平台开始校招拉~
【岗位职责】 负责钉钉AI Paas 产品化研发落地,包含但不限于: 1. 用户意图理解、任务规划、服务推荐等算法的设计和开发 2. 基于大模型落地各种落地应用,缩短大模型与真实应用场景的距离 3. 负责算法的工程化落地,包括算法的代…...

Linux系统gdb调试常用命令
GDB(GNU调试器)是一款常用的调试工具,用于调试C、C等编程语言的程序。以下是一些常用的GDB命令: 1. 启动程序: - gdb <executable>:启动GDB调试器,并加载可执行文件。 2. 设置断点&a…...
Sumo中Traci.trafficlight详解(上)
Sumo中Traci.trafficlight详解(上) 记录慢慢学习traci的每一天,希望也能帮到你 文章目录 Sumo中Traci.trafficlight详解(上)Traci.trafficlight信号灯参数讲解1.getAllProgramLogics(self,tlsID)2.getBlockingVehicle…...

手写Mybatis:第13章-通过注解配置执行SQL语句
文章目录 一、目标:注解配置执行SQL二、设计:注解配置执行SQL三、实现:注解配置执行SQL3.1 工程结构3.2 注解配置执行SQL类图3.3 脚本语言驱动器3.3.1 脚本语言驱动器接口3.3.2 XML语言驱动器 3.4 注解配置构建器3.4.1 定义增删改查注解3.4.2…...

spring security - 快速整合 springboot
1.引入依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spr…...

NPM 常用命令(二)
目录 1、npm bugs 1.1 配置 browser registry 2、npm cache 2.1 概要 2.2 详情 2.3 关于缓存设计的说明 2.4 配置 cache 3、 npm ci 3.1 描述 3.2 配置 install-strategy legacy-bundling global-style omit strict-peer-deps foreground-scripts ignore-s…...
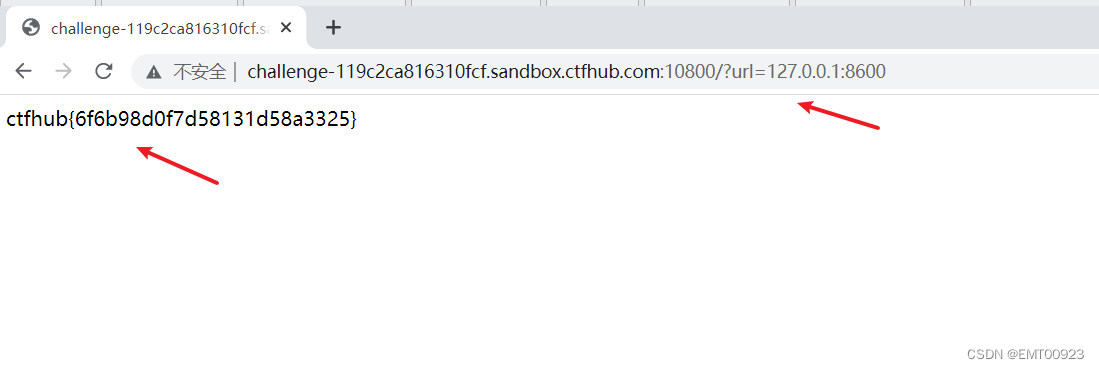
ctfhub ssrf(3关)
文章目录 内网访问伪协议读取文件扫描端口 内网访问 根据该题目,是让我们访问127.0.0.1/falg.php,访问给出的链接后用bp抓包,修改URL,发送后得到flag: 伪协议读取文件 这题的让我们用伪协议,而网站的目录…...

跨源资源共享(CORS)Access-Control-Allow-Origin
1、浏览器的同源安全策略 没错,就是这家伙干的,浏览器只允许请求当前域的资源,而对其他域的资源表示不信任。那怎么才算跨域呢? 请求协议http,https的不同域domain的不同端口port的不同 好好好,大概就是这么回事啦&…...

【嵌入式软件开发 】学习笔记
本文主要记录 【嵌入式软件开发】 学习笔记,参考相关大佬的文章 1.RTOS 内功修炼笔记 RTOS内功修炼记(一)—— 任务到底应该怎么写? RTOS内功修炼记(二)—— 优先级抢占式调度到底是怎么回事?…...

CentOS 7上安装Python 3.11.5,支持Django
CentOS 7上安装Python 3.11.5,支持Django 今天安装django,报了“Django - deterministicTrue requires SQLite 3.8.3 or higher upon running python manage.py runserver”。查了一番资料,记录下来。 参考链接: 参考链接: Django的web项目…...

COMPFEST 15H「组合数学+容斥」
Problem - H - Codeforces 题意: 定义一个集合S为T的孩子是,对于S中的每一个元素x,在T中都能找到x1。 给定n,k,每一个集合中的元素x必须满足 1 < x < k 1<x<k 1<x<k且 c n t [ x ] < 1 cnt[x…...
react快速开始(三)-create-react-app脚手架项目启动;使用VScode调试react
文章目录 react快速开始(三)-create-react-app脚手架项目启动;使用VScode调试react一、create-react-app脚手架项目启动1. react-scripts2. 关于better-npm-runbetter-npm-run安装 二、使用VScode调试react1. 浏览器插件React Developer Tools2. 【重点】用 VSCode …...
【C++入门】string类常用方法(万字详解)
目录 1.STL简介1.1什么是STL1.2STL的版本1.3STL的六大组件1.4STL的缺陷 2.string类的使用2.1C语言中的字符串2.2标准库中的string类2.3string类的常用接口说明 (只讲解最常用的接口)2.3.1string类对象的常见构造2.3.2 string类对象的容量操作2.3.3string…...

大数据错误
question1 : Could not locate Hadoop executable: D:\hadoop-3.3.1\bin\winutils.exe - 【已解决】Could not locate executable E:\Hadoop\bin\winutils.exe in the Hadoop binaries._could not locate executable e:\hadoop-3.3.1\bin\wi_君问归期魏有期的博客-CSDN博客 q…...

【Node.js】Express-Generator:快速生成Express应用程序的利器
在Node.js世界中,Express是一个广泛使用的、强大的Web应用程序框架。它为开发者提供了一系列的工具和选项,使得创建高效且可扩展的Web应用程序变得轻而易举。然而,对于初学者来说,配置和初始化Express应用程序可能会有些困难。为了…...

SpringMVC的工作流程及入门
目录 一、概述 ( 1 ) 是什么 ( 2 ) 作用 二、工作流程 ( 1 ) 流程 ( 2 ) 步骤 三、入门实例 ( 1 ) 入门实例 ( 2 ) 静态资源处理 给我们带来的收获 一、概述 ( 1 ) 是什么 SpringMVC是一个基于Java的Web应用开发框架,它是Spring Framework的一部…...
】)
logging.level的含义及设置 【java 日志 (logback、log4j)】
日志级别 trace<debug<info<warn<error<fatal 常用的有:debug,info,warn,error 通常我们想设置日志级别,会用到 logging.level.rootinfo logging.level设置日志级别,后面跟生效的区域。r…...

AgiBot X1实时内核配置:Linux实时补丁与性能优化终极指南
AgiBot X1实时内核配置:Linux实时补丁与性能优化终极指南 【免费下载链接】agibot_x1_infer The inference module for AgiBot X1. 项目地址: https://gitcode.com/gh_mirrors/agi/agibot_x1_infer AgiBot X1是一款先进的人形机器人,其infer模块&…...

Spingboot企业员工信息管理系统—免费毕设源码分享28210
摘要本论文介绍了基于Spring Boot框架开发的“传奇今生企业员工信息管理系统”。系统提高企业人力资源管理的效率和精确度,通过数字化手段优化员工信息管理流程,提升企业管理水平。系统分为用户端和管理员端,提供了丰富的功能模块。用户端功能…...

技术人如何找到自己的“甜蜜点”?一个四象限模型帮你定位
在软件测试这条“越走越深”的路上,每个从业者早晚都会撞上一堵墙——技能焦虑。自动化框架层出不穷,性能工具日新月异,安全左移、精准测试、AI 辅助……每一样看起来都很重要,每一样又都学不完。于是有人拼命考证,有人…...

2026终极测评:16款降AIGC工具横评,论文降重降ai率终极答案!
随着AI写作技术的迅猛发展,越来越多的学术创作者开始依赖各类生成工具提升效率。然而,2026年各大高校与科研机构对AIGC内容的检测标准愈发严格,论文中的一丝AI痕迹都可能成为被质疑的导火索。面对日益严峻的查重与AIGC检测压力,如…...

3DS Pokémon ROM 编辑器 pk3DS:新手入门完全指南
3DS Pokmon ROM 编辑器 pk3DS:新手入门完全指南 【免费下载链接】pk3DS Pokmon (3DS) ROM Editor & Randomizer 项目地址: https://gitcode.com/gh_mirrors/pk/pk3DS pk3DS 是一款功能强大的任天堂 3DS 平台 Pokmon 系列游戏 ROM 编辑器和随机化工具&…...

Windows环境5步搞定OpenCore引导盘:Hackintosh安装终极指南
Windows环境5步搞定OpenCore引导盘:Hackintosh安装终极指南 【免费下载链接】OpenCore-Install-Guide Repo for the OpenCore Install Guide 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Install-Guide 想要在普通PC上体验macOS的流畅与优雅吗&am…...

如何用Python快速接入Taotoken并调用多模型API完成数据清洗任务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken并调用多模型API完成数据清洗任务 对于需要处理客户数据的开发者而言,数据清洗与结构化是…...

小白程序员必看:收藏这份分词知识框架,轻松入门大模型!
分词是NLP和大型语言模型处理文本的第一步。本文系统介绍了分词的基本概念,详细解析了英文和中文的分词方法,包括词级、字符级和子词级分词的原理与区别。特别强调了子词级分词(如BPE、WordPiece)在解决OOV问题和保留语义结构方面…...

QMCDecode:3步解锁QQ音乐加密音频的终极macOS工具
QMCDecode:3步解锁QQ音乐加密音频的终极macOS工具 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结…...

终极指南:如何在macOS上使用QMCDecode免费转换QQ音乐加密格式
终极指南:如何在macOS上使用QMCDecode免费转换QQ音乐加密格式 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录࿰…...