第六章.卷积神经网络(CNN)—CNN的实现(搭建手写数字识别的CNN)
第六章.卷积神经网络(CNN)
6.2 CNN的实现(搭建手写数字识别的CNN)
1.网络构成
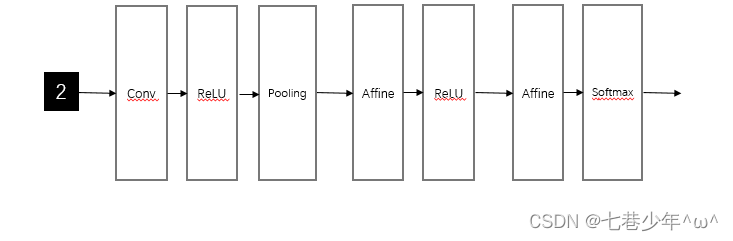
2.代码实现
import pickle
import matplotlib.pyplot as plt
import numpy as np
import sys, ossys.path.append(os.pardir)from dataset.mnist import load_mnist
from collections import OrderedDict# 从图像到矩阵
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):N, C, H, W = input_data.shapeout_h = (H + 2 * pad - filter_h) // stride + 1out_w = (W + 2 * pad - filter_w) // stride + 1img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))for y in range(filter_h):y_max = y + stride * out_hfor x in range(filter_w):x_max = x + stride * out_wcol[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)return col# 从矩阵到图像
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):N, C, H, W = input_shapeout_h = (H + 2 * pad - filter_h) // stride + 1out_w = (W + 2 * pad - filter_w) // stride + 1col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)img = np.zeros((N, C, H + 2 * pad + stride - 1, W + 2 * pad + stride - 1))for y in range(filter_h):y_max = y + stride * out_hfor x in range(filter_w):x_max = x + stride * out_wimg[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]return img[:, :, pad:H + pad, pad:W + pad]class SGD:def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key]class Momentum:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]params[key] += self.v[key]class Nesterov:def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] *= self.momentumself.v[key] -= self.lr * grads[key]params[key] += self.momentum * self.momentum * self.v[key]params[key] -= (1 + self.momentum) * self.lr * grads[key]class AdaGrad:def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)class RMSprop:def __init__(self, lr=0.01, decay_rate=0.99):self.lr = lrself.decay_rate = decay_rateself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] *= self.decay_rateself.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)class Adam:def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.iter = 0self.m = Noneself.v = Nonedef update(self, params, grads):if self.m is None:self.m, self.v = {}, {}for key, val in params.items():self.m[key] = np.zeros_like(val)self.v[key] = np.zeros_like(val)self.iter += 1lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)for key in params.keys():# self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]# self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)# unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias# unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias# params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)# 激活函数Relu
class Relu:def __init__(self):self.mask = Nonedef forward(self, x):self.mask = (x <= 0)out = x.copy()out[self.mask] = 0return outdef backward(self, dout):dout[self.mask] = 0dx = doutreturn dx# 卷积层
class Convolution:def __init__(self, W, b, stride=1, pad=0):self.W = Wself.b = bself.stride = strideself.pad = pad# 中间数据(backward时使用)self.x = Noneself.col = Noneself.col_W = None# 权重和偏置参数的梯度self.dW = Noneself.db = None# 正向传播def forward(self, x):FN, C, FH, FW = self.W.shapeN, C, H, W = x.shapeout_h = int((H + 2 * self.pad - FH) / self.stride) + 1out_w = int((W + 2 * self.pad - FW) / self.stride) + 1col = im2col(x, FH, FW, self.stride, self.pad)col_W = self.W.reshape(FN, -1).Tout = np.dot(col, col_W) + self.bout = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)self.x = xself.col = colself.col_W = col_Wreturn out# 反向传播def backward(self, dout):FN, C, FH, FW = self.W.shapedout = dout.transpose(0, 2, 3, 1).reshape(-1, FN)self.db = np.sum(dout, axis=0)self.dW = np.dot(self.col.T, dout)self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)dcol = np.dot(dout, self.col_W.T)dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)return dx# 池化层
class Pooling:def __init__(self, pool_h, pool_w, stride=1, pad=0):self.pool_h = pool_hself.pool_w = pool_wself.stride = strideself.pad = padself.x = Noneself.arg_max = None# 正向传播def forward(self, x):N, C, H, W = x.shapeout_h = int(1 + (H - self.pool_h) / self.stride)out_w = int(1 + (W - self.pool_w) / self.stride)col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)col = col.reshape(-1, self.pool_h * self.pool_w)arg_max = np.argmax(col, axis=1)out = np.max(col, axis=1)out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)self.x = xself.arg_max = arg_maxreturn out# 反向传播def backward(self, dout):dout = dout.transpose(0, 2, 3, 1)pool_size = self.pool_h * self.pool_wdmax = np.zeros((dout.size, pool_size))dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()dmax = dmax.reshape(dout.shape + (pool_size,))dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)return dx# Affine层
class Affine:def __init__(self, W, b):self.W = Wself.b = bself.x = Noneself.original_x_shape = None# 权重和偏置参数的导数self.dW = Noneself.db = Nonedef forward(self, x):# 对应张量self.original_x_shape = x.shape # 例如:x.shape=(209, 64, 64, 3)x = x.reshape(x.shape[0], -1) # x=(209, 64*64*3)self.x = xout = np.dot(self.x, self.W) + self.breturn outdef backward(self, dout):dx = np.dot(dout, self.W.T)self.dW = np.dot(self.x.T, dout)self.db = np.sum(dout, axis=0)dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)return dx# 输出层
class SoftmaxWithLoss:def __init__(self):self.loss = None # 损失self.y = None # softmax的输出self.t = None # 监督数据(one_hot vector)# 输出层函数:softmaxdef softmax(self, x):if x.ndim == 2:x = x.Tx = x - np.max(x, axis=0)y = np.exp(x) / np.sum(np.exp(x), axis=0)return y.Tx = x - np.max(x) # 溢出对策return np.exp(x) / np.sum(np.exp(x))# 交叉熵误差def cross_entropy_error(self, y, t):if y.ndim == 1:t = t.reshape(1, t.size)y = y.reshape(1, y.size)# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引if t.size == y.size:t = t.argmax(axis=1)batch_size = y.shape[0]return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size# 正向传播def forward(self, x, t):self.t = tself.y = self.softmax(x)self.loss = self.cross_entropy_error(self.y, self.t)return self.loss# 反向传播def backward(self, dout=1):batch_size = self.t.shape[0]if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况dx = (self.y - self.t) / batch_sizeelse:dx = self.y.copy()dx[np.arange(batch_size), self.t] -= 1dx = dx / batch_sizereturn dxclass Trainer:"""进行神经网络的训练的类"""def __init__(self, network, x_train, t_train, x_test, t_test,epochs=20, mini_batch_size=100,optimizer='SGD', optimizer_param={'lr': 0.01},evaluate_sample_num_per_epoch=None, verbose=True):self.network = networkself.verbose = verboseself.x_train = x_trainself.t_train = t_trainself.x_test = x_testself.t_test = t_testself.epochs = epochsself.batch_size = mini_batch_sizeself.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch# optimzeroptimizer_class_dict = {'sgd': SGD, 'momentum': Momentum, 'nesterov': Nesterov,'adagrad': AdaGrad, 'rmsprpo': RMSprop, 'adam': Adam}self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)self.train_size = x_train.shape[0]self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)self.max_iter = int(epochs * self.iter_per_epoch)self.current_iter = 0self.current_epoch = 0self.train_loss_list = []self.train_acc_list = []self.test_acc_list = []def train_step(self):batch_mask = np.random.choice(self.train_size, self.batch_size)x_batch = self.x_train[batch_mask]t_batch = self.t_train[batch_mask]grads = self.network.gradient(x_batch, t_batch)self.optimizer.update(self.network.params, grads)loss = self.network.loss(x_batch, t_batch)self.train_loss_list.append(loss)if self.verbose: print("train loss:" + str(loss))if self.current_iter % self.iter_per_epoch == 0:self.current_epoch += 1x_train_sample, t_train_sample = self.x_train, self.t_trainx_test_sample, t_test_sample = self.x_test, self.t_testif not self.evaluate_sample_num_per_epoch is None:t = self.evaluate_sample_num_per_epochx_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]train_acc = self.network.accuracy(x_train_sample, t_train_sample)test_acc = self.network.accuracy(x_test_sample, t_test_sample)self.train_acc_list.append(train_acc)self.test_acc_list.append(test_acc)if self.verbose: print("=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(test_acc) + " ===")self.current_iter += 1def train(self):for i in range(self.max_iter):self.train_step()test_acc = self.network.accuracy(self.x_test, self.t_test)if self.verbose:print("=============== Final Test Accuracy ===============")print("test acc:" + str(test_acc))# 手写数字识别CNN的实现类: conv - relu - pool - affine - relu - affine - softmax
class SimpleConvNet:def __init__(self, input_dim=(1, 28, 28), conv_param={'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},hidden_size=100, output_size=10, weight_int_std=0.01):filter_num = conv_param['filter_num']filter_size = conv_param['filter_size']filter_pad = conv_param['pad']filter_stride = conv_param['stride']input_size = input_dim[1]conv_output_size = (input_size + 2 * filter_pad - filter_size) / filter_stride + 1pool_output_size = int(filter_num * (conv_output_size / 2) * (conv_output_size / 2))# 初始化权重self.params = {}self.params['W1'] = weight_int_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)self.params['b1'] = np.zeros(filter_num)self.params['W2'] = weight_int_std * np.random.randn(pool_output_size, hidden_size)self.params['b2'] = np.zeros(hidden_size)self.params['W3'] = weight_int_std * np.random.randn(hidden_size, output_size)self.params['b3'] = np.zeros(output_size)# 生成层self.layers = OrderedDict()self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], filter_stride, filter_pad)self.layers['Relu1'] = Relu()self.layers['pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])self.layers['Relu2'] = Relu()self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])self.last_layer = SoftmaxWithLoss()# 推理函数def predict(self, x):for layer in self.layers.values():x = layer.forward(x)return x# 损失函数def loss(self, x, t):y = self.predict(x)return self.last_layer.forward(y, t)# 识别精度def accuracy(self, x, t, batch_size=100):if t.ndim != 1: t = np.argmax(t, axis=1)acc = 0.0for i in range(int(x.shape[0] / batch_size)):tx = x[i * batch_size:(i + 1) * batch_size]tt = t[i * batch_size:(i + 1) * batch_size]y = self.predict(tx)y = np.argmax(y, axis=1)acc += np.sum(y == tt)return acc / x.shape[0]def numerical_gradient(f, x):h = 1e-4 # 0.0001grad = np.zeros_like(x)it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])while not it.finished:idx = it.multi_indextmp_val = x[idx]x[idx] = float(tmp_val) + hfxh1 = f(x) # f(x+h)x[idx] = tmp_val - hfxh2 = f(x) # f(x-h)grad[idx] = (fxh1 - fxh2) / (2 * h)x[idx] = tmp_val # 还原值it.iternext()return grad# 数值微分def numerical_gradient(self, x, t):loss_w = lambda w: self.loss(x, t)grads = {}for idx in (1, 2, 3):grads['W' + str(idx)] = self.numerical_gradient(loss_w, self.params['W' + str(idx)])grads['b' + str(idx)] = self.numerical_gradient(loss_w, self.params['b' + str(idx)])return grads# 误差反向传播法求梯度def gradient(self, x, t):self.loss(x, t)dout = 1dout = self.last_layer.backward(dout)layers = list(self.layers.values())layers.reverse()for layer in layers:dout = layer.backward(dout)# 设定grads = {}grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].dbgrads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].dbgrads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].dbreturn grads# 保存参数def save_param(self, file_name='params.pkl'):params = {}for key, val in self.params.items():params[key] = valwith open(file_name, 'wb') as f:pickle.dump(params, f)# 加载参数def load_param(self, file_name='params.pkl'):with open(file_name, 'rb') as f:params = pickle.load(f)for key, val in params.items():self.params[key] = valfor i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):self.layers[key].W = self.params['W' + str(i + 1)]self.layers[key].b = self.params['b' + str(i + 1)]#加载数据
(x_train,t_train),(x_test,t_test)=load_mnist(flatten=False)#较少数据
x_train,t_train=x_train[:5000],t_train[:5000]
x_test,t_test=x_test[:1000],t_test[:1000]max_epoch=20
network=SimpleConvNet( input_dim=(1, 28, 28), conv_param={'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},hidden_size=100, output_size=10, weight_int_std=0.01)trainer=Trainer(network, x_train, t_train, x_test, t_test,epochs=max_epoch, mini_batch_size=100,optimizer='Adam', optimizer_param={'lr': 0.001},evaluate_sample_num_per_epoch=1000)trainer.train()#保存参数
network.save_param("params.pkl")
print("Save Network Parameters!")#绘制图像
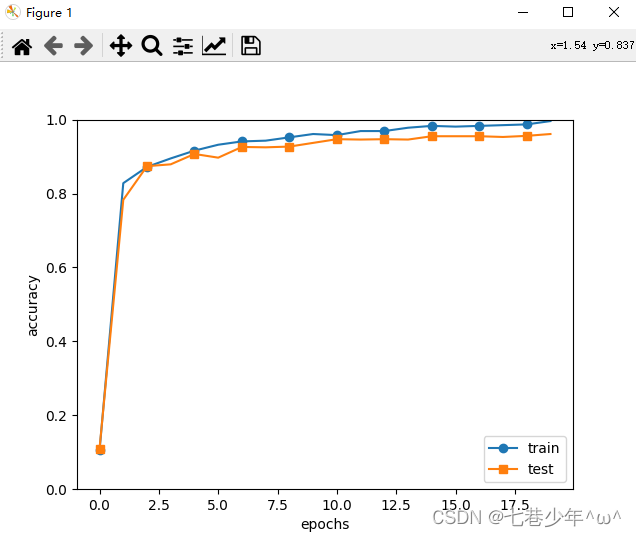
x=np.arange(max_epoch)
plt.plot(x,trainer.train_acc_list,marker='o',label='train',markevery=2)
plt.plot(x,trainer.test_acc_list,marker='s',label='test',markevery=2)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
3.结果展示
4.CNN的代表性网络
1).LeNet
-
传统的CNN & LeNet的差异:
①.激活函数不同:LeNet使用sigmoid函数,传统的CNN网络使用的是Relu函数
②.原始的LeNet中使用子采样缩小中间数据的大小,传统的CNN网络主要使用Max池化。
2).AlexNet
-
LeNet & AlexNet的差异:
①.激活函数不同:LeNet使用sigmoid函数,AlexNet使用Relu函数
②.使用进行局部正则化的LRN(Local Response Normalization)层
③.使用Dropout
相关文章:
第六章.卷积神经网络(CNN)—CNN的实现(搭建手写数字识别的CNN)
第六章.卷积神经网络(CNN) 6.2 CNN的实现(搭建手写数字识别的CNN) 1.网络构成 2.代码实现 import pickle import matplotlib.pyplot as plt import numpy as np import sys, ossys.path.append(os.pardir)from dataset.mnist import load_mnist from collections import Order…...

【go】defer底层原理
defer的作用 defer声明的函数在当前函数return之后执行,通常用来做资源、连接的关闭和缓存的清除等。 A defer statement pushes a function call onto a list. The list of saved calls is executed after the surrounding function returns. Defer is commonly u…...

TypeScript 学习笔记
最近在学 ts 顺便记录一下自己的学习进度,以及一些知识点的记录,可能不会太详细,主要是用来巩固和复习的,会持续更新 前言 想法 首先我自己想说一下自己在学ts之前,对ts的一个想法和印象,在我学习之前&a…...
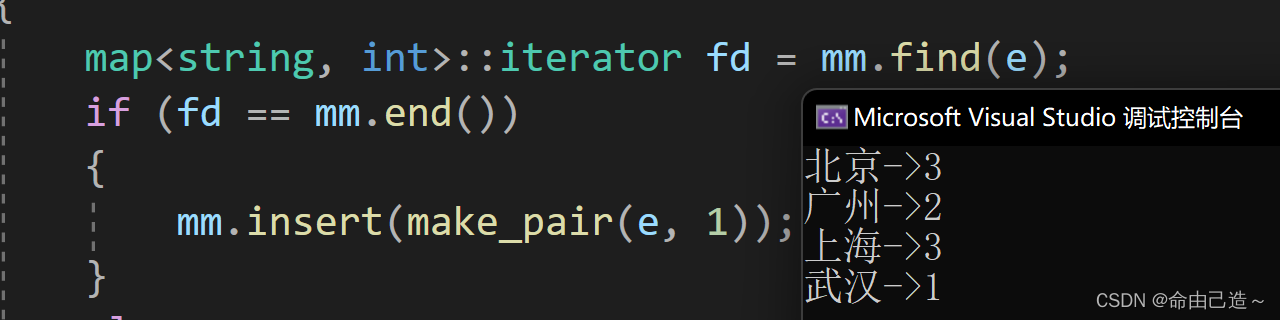
【C++】map和set的使用
map和set一、set1.1 set的介绍1.2 set的使用1.2.1 set的构造1.2.2 set的迭代器1.2.3 set的修改1.2.3.1 insert && find && erase1.2.3.2 count1.3 multiset二、map2.1 map的介绍2.2 map的使用2.2.1 map的修改2.2.1.1 insert2.2.1.2 统计次数2.3 multimap一、se…...

微电影广告具有哪些特点?
微电影广告是广告主投资的,以微电影为形式载体,以新媒体为主要传播载体,综合运用影视创作手法拍摄的集故事性、艺术性和商业性于一体的广告。它凭借精彩的电影语言和强大的明星效应多渠道联动传播,润物细无声地渗透和传递着商品信…...
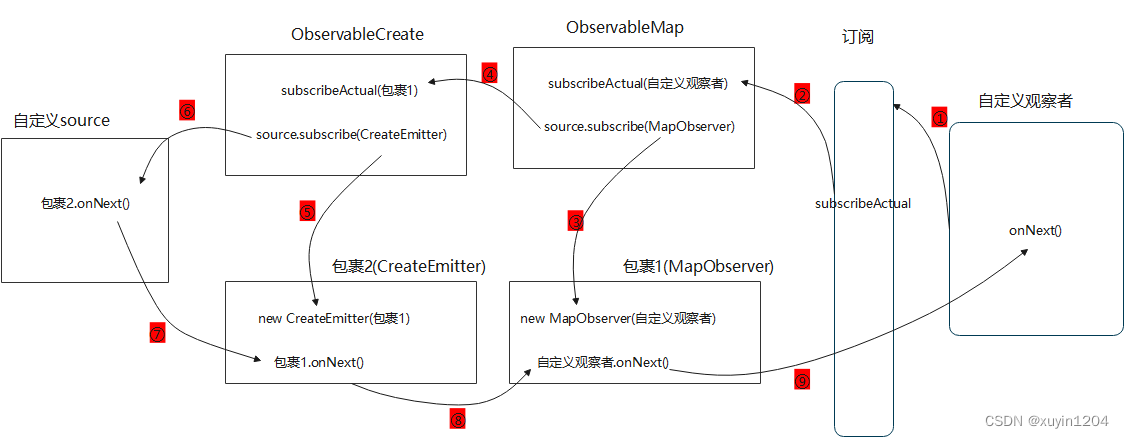
Android RxJava框架源码解析(四)
目录一、观察者Observer创建过程二、被观察者Observable创建过程三、subscribe订阅过程四、map操作符五、线程切换原理简单示例1: private Disposable mDisposable; Observable.create(new ObservableOnSubscribe<String>() {Overridepublic void subscribe(…...

Linux信号-进程退出状态码
当进程因收到信号被终止执行退出后,父进程可以通过wait或waitpid得到它的exit code。进程被各信号终止的退出状态码总结如下:信号编号信号名称信号描述默认处理方式Exit code1SIGHUP挂起终止12SIGINT终端中断终止23SIGQUIT终端退出终止、coredump1314SIG…...
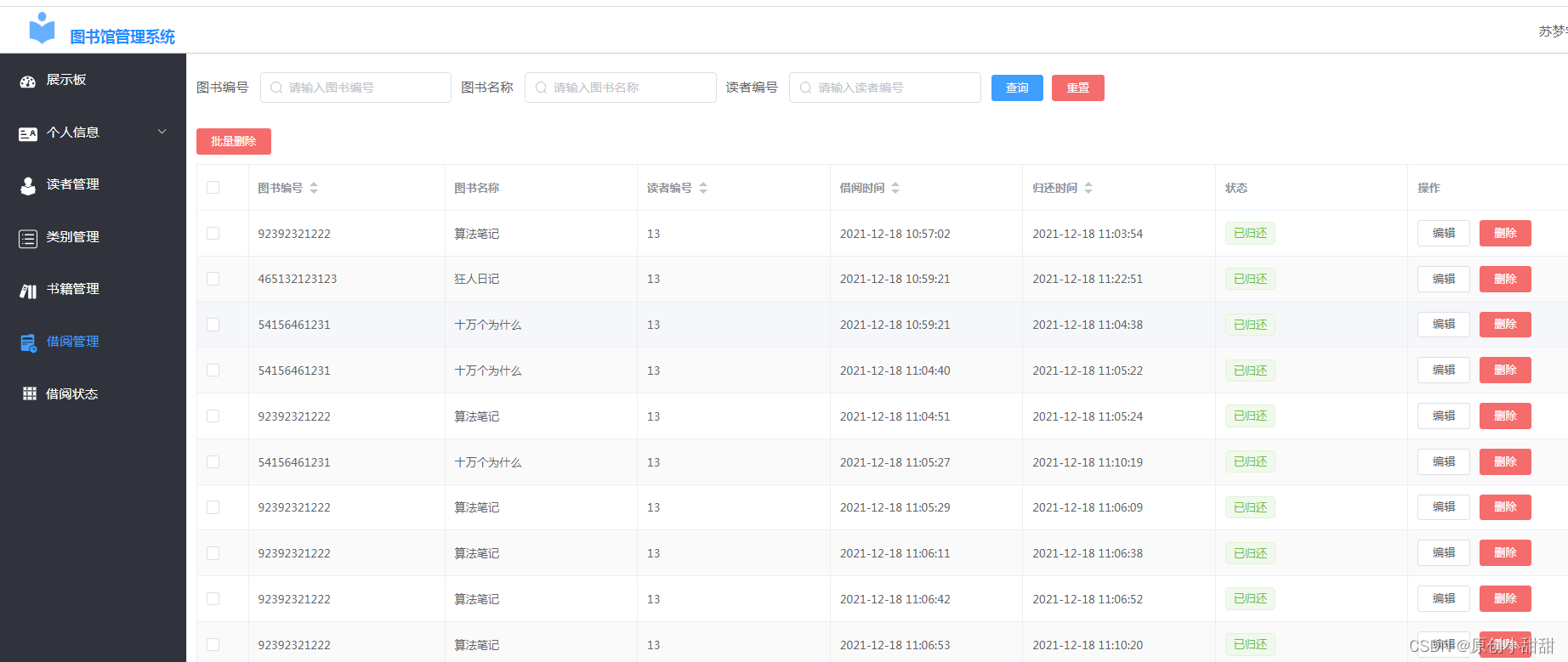
springcloud+vue实现图书管理系统
一、前言: 今天我们来分享一下一个简单的图书管理系统 我们知道图书馆系统可以有两个系统,一个是管理员管理图书的系统,管理员可以(1)查找某一本图书情况、(2)增加新的图书、(3&…...

GEE学习笔记 六十:GEE中生成GIF动画
生成GIF动画这个是GEE新增加的功能之一,这一篇文章我会简单介绍一下如何使用GEE来制作GIF动画。 相关API如下: 参数含义: params:设置GIF动画显示参数,详细的参数可以参考ee.data.getMapId() callback:回调…...

react中的useEffect
是函数组件中执行的副作用,副作用就是指每次组件更新都会执行的函数,可以用来取代生命周期。 1. 基本用法 import { useEffect } from "react"; useEffect(()>{console.log(副作用); });2. 副作用分为需要清除的和不需要清除 假如设置…...
 复制)
故障安全(Crash-Safe) 复制
二进制日志记录是故障安全的:MySQL 仅记录完成的事件或事务使用 sync-binlog 提高安全性默认值是1,最安全的,操作系统在每次事务后写入文件将svnc-binloq 设置为0,当操作系统根据其内部规则写入文件的同时服务器崩溃时性能最好但事务丢失的可…...

Spring aop之针对注解
前言 接触过Spring的都知道,aop是其中重要的特性之一。笔者在开发做项目中,aop更多地是要和注解搭配:在某些方法上加上自定义注解,然后要对这些方法进行增强(很少用execution指定,哪些包下的哪些方法要增强)。那这时就…...

【JavaScript速成之路】JavaScript数据类型转换
📃个人主页:「小杨」的csdn博客 🔥系列专栏:【JavaScript速成之路】 🐳希望大家多多支持🥰一起进步呀! 文章目录前言数据类型转换1,转换为字符串型1.1,利用“”拼接转换成…...

21-绑定自定义事件
绑定自定义事件 利用自定义事件获取子组件的值 父组件给子组件绑定一个自定义事件,实际上是绑定到了子组件的实例对象vc上: <!-- 自定义myEvent事件 --> <Student v-on:myEventgetStudentName/>在父组件中编写getStudentName的实现&#…...

【Mysql】触发器
【Mysql】触发器 文章目录【Mysql】触发器1. 触发器1.1 介绍1.2 语法1.2.1 创建触发器1.2.2 查看触发器1.2.3 删除触发器1.2.4 案例1. 触发器 1.1 介绍 触发器是与表有关的数据库对象,指在insert、update、delete之前(BEFORE)或之后(AFTER),触发并执行…...

CODESYS开发教程11-库管理器
今天继续我们的小白教程,老鸟就不要在这浪费时间了😊。 前面一期我们介绍了CODESYS的文件读写函数库SysFile。大家可能发现了,在CODESYS的开发中实际上是离不开各种库的使用,其中包括系统库、第三方库以及用户自己开发的库。实际…...
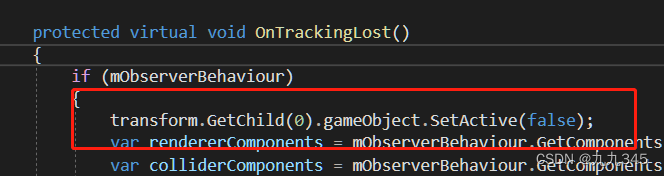
【UnityAR相关】Unity Vuforia扫图片成模型具体步骤
1 资产准备 导入要生成的fbx模型(带有材质), 你会发现导入fbx的材质丢失了: 选择Standard再Extract Materials导出材质到指定文件夹下(我放在Assets->Materials了 ok啦! 材质出现了, 模型…...

2023年全国最新保安员精选真题及答案2
百分百题库提供保安员考试试题、保安职业资格考试预测题、保安员考试真题、保安职业资格证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 21.一般来说,最经济的巡逻方式是()。 A:步巡 B:…...
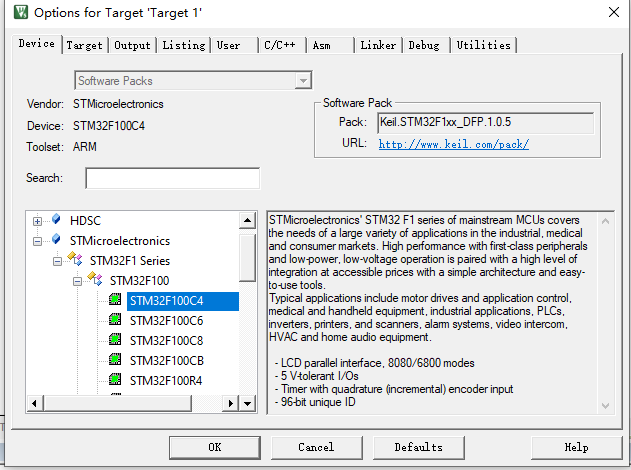
keil5安装了pack包但是还是不能选择device
一开始,我以为是keil5无法安装 STM32 芯片包,打开device倒是可以看到stm公司的芯片包,但是没有我想要的stm32f1。 我按照网上的一些说法,找到了这个STM32F1 的pack芯片包,但是我双击安装的时候,它的安装位…...

秒杀系统设计
1.秒杀系统的特点 瞬时高并发 2.预防措施 2.1.流量限制 对于一个相同的用户,限制请求的频次对于一个相同的IP,限制请求的频次验证码,减缓用户请求的次数活动开启之前,按钮先置灰,防止无效的请求流入系统࿰…...

隧道裂缝剥落病害AI识别系统
我国现有公路隧道超2.5万座,总里程超2.8万公里,其中运营超过15年的老旧隧道占比达35%。据交通运输部2025年统计,年均因隧道结构病害导致的交通中断超1200次,直接经济损失超45亿元。传统检测模式暴露四大核心痛点:检测周…...

【DeepSeek-R1代码相似度引擎解密】:3层语义比对机制、Token归一化偏差修正与Jaccard阈值黄金分割点
更多请点击: https://kaifayun.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力与泛化…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

[智能体-81]:工程化智能体 = 模型做脑力拆解 + 框架做流程落地。前者是决策者,后者是管理者,tools/function call是内部员工;mcp server是外部资源;
一、全角色人设 & 对应技术组件角色定位对应技术模块核心职责决策者(脑力大脑)大模型 LLM理解目标、任务拆解、逻辑判断、分支决策、内容生成,负责 “想方案、定步骤”管理者(流程总管)智能体编排框架(…...

1901-2022年中国气温变化分析实战:用这份1km栅格数据我们能发现什么?
1901-2022年中国气温变化分析实战:如何从1km栅格数据中挖掘气候演变规律当一份覆盖122年、分辨率精确到1公里的气温栅格数据摆在面前时,我们看到的不仅是数字矩阵,更是一部写在经纬度坐标里的气候变迁史诗。这份由逐月数据聚合生成的逐年气温…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

Unity中实现深度遮挡:LingBot-Depth实战接入与优化
1. 这不是“加个插件就完事”的AR效果——为什么LingBot-Depth在Unity里值得专门写一篇实战教程你肯定见过那种AR应用:虚拟椅子摆在真实地板上,但当你绕到椅子后面,它依然完整显示,完全无视身后那堵真实的墙;或者一只3…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...

QQ群数据采集终极教程:5分钟掌握批量抓取技巧
QQ群数据采集终极教程:5分钟掌握批量抓取技巧 【免费下载链接】QQ-Groups-Spider QQ Groups Spider(QQ 群爬虫) 项目地址: https://gitcode.com/gh_mirrors/qq/QQ-Groups-Spider 还在为手动收集QQ群信息而烦恼吗?QQ-Groups…...

温差发电驱动轻型电动车:热电模块与催化燃烧器的系统集成实践
1. 项目概述:用温差发电驱动轻型电动车最近在琢磨一个挺有意思的玩意儿:能不能给那些轻型的电动车,比如高尔夫球车、园区巡逻车或者小型载货三轮,换上一套不一样的“心脏”?传统的方案,要么背着一大块死沉死…...