10.(Python数模)(预测模型二)LSTM回归网络(1→1)
LSTM回归网络(1→1)
长短期记忆网络 - 通常只称为“LSTM” - 是一种特殊的RNN,能够学习长期的规律。 它们是由Hochreiter&Schmidhuber(1997)首先提出的,并且在后来的工作中被许多人精炼和推广。他们在各种各样的问题上应用得非常好,现在被广泛的使用。
LSTM简介
有一串时间序列数据[112,118,132,129,121,135],训练的本质是用后一个步长的数据作为Y去对应当前的X。
用一个步长预测一个,监督学习数据类型1->1
X Y
112 118
118 132
132 129
129 121
121 135
问题描述
所给的数据文件是1949-1960每月的航班乘客数量

源代码
# LSTM for international airline passengers problem with regression framing
import numpy
import matplotlib.pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
"""
用一个步长预测一个,监督学习数据类型1->1
X Y
112 118
118 132
132 129
129 121
121 135
"""
# 将数据截取成1->1的监督学习格式
def create_dataset(dataset, look_back=1):dataX, dataY = [], []for i in range(len(dataset)-look_back-1):a = dataset[i:(i+look_back), 0]dataX.append(a)dataY.append(dataset[i + look_back, 0])return numpy.array(dataX), numpy.array(dataY)
# 定义随机种子,以便重现结果
numpy.random.seed(7)
# 加载数据
dataframe = read_csv('airline-passengers.csv', usecols=[1], engine='python')
dataset = dataframe.values
dataset = dataset.astype('float32')
# 缩放数据
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# 分割2/3数据作为测试
train_size = int(len(dataset) * 0.67)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:]
# 预测数据步长为1,一个预测一个,1->1
look_back = 1
trainX, trainY = create_dataset(train, look_back)
testX, testY = create_dataset(test, look_back)
# 重构输入数据格式 [samples, time steps, features] = [93,1,1]
trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))
# 构建 LSTM 网络
model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# 对训练数据的Y进行预测
trainPredict = model.predict(trainX)
# 对测试数据的Y进行预测
testPredict = model.predict(testX)
# 对数据进行逆缩放
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform([testY])
# 计算RMSE误差
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(testY[0], testPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))# 构造一个和dataset格式相同的数组,共145行,dataset为总数据集,把预测的93行训练数据存进去
trainPredictPlot = numpy.empty_like(dataset)
# 用nan填充数组
trainPredictPlot[:, :] = numpy.nan
# 将训练集预测的Y添加进数组,从第3位到第93+3位,共93行
trainPredictPlot[look_back:len(trainPredict)+look_back, :] = trainPredict# 构造一个和dataset格式相同的数组,共145行,把预测的后44行测试数据数据放进去
testPredictPlot = numpy.empty_like(dataset)
testPredictPlot[:, :] = numpy.nan
# 将测试集预测的Y添加进数组,从第94+4位到最后,共44行
testPredictPlot[len(trainPredict)+(look_back*2)+1:len(dataset)-1, :] = testPredict# 画图
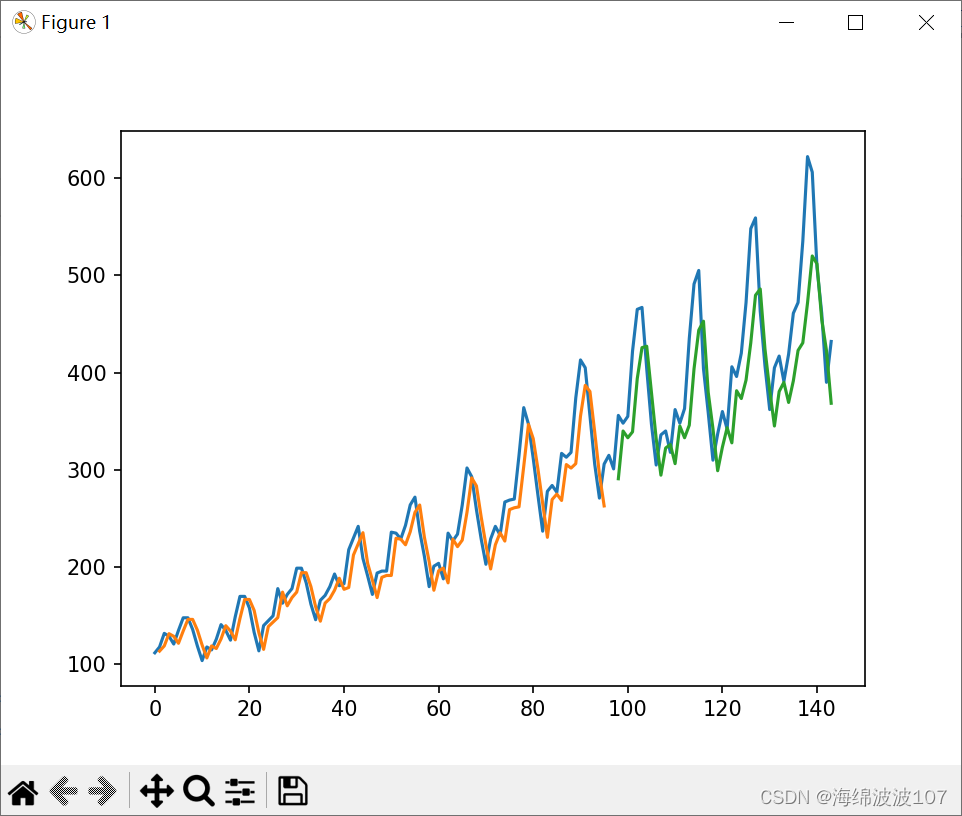
plt.plot(scaler.inverse_transform(dataset))
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()
代码注释
1、scaler = MinMaxScaler(feature_range=(0, 1))。这段代码的意思是使用MinMaxScaler对数据进行归一化处理,将特征值缩放到0到1的范围内。
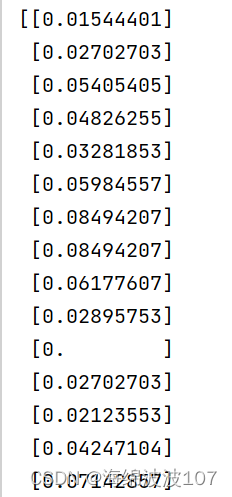
2、dataset = scaler.fit_transform(dataset)。这是一个常见的数据预处理步骤,将数据集进行归一化(或标准化)。在这个过程中,scaler是一个用于缩放数据的对象,可以使用fit_transform方法来对数据集进行归一化处理。这个方法会计算数据集的均值和标准差,并将数据进行转换,使得数据的分布符合均值为0,标准差为1的正态分布。通过归一化可以使得数据的不同特征在相同的尺度上进行比较和分析。转换后的部分数据如下:
3、model = Sequential()
model.add(LSTM(4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss=‘mean_squared_error’, optimizer=‘adam’)
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)。
这段代码是使用Keras库构建了一个简单的循环神经网络(LSTM)模型。模型使用一个LSTM层,输入形状为(1, look_back),其中look_back是用于预测的时间步数。然后,通过添加一个全连接层(Dense)来输出预测结果。模型使用均方误差作为损失函数,优化器选择Adam。训练时使用了trainX作为输入数据,trainY作为目标数据,通过100个epochs进行训练,每个batch的大小为1,并且设置verbose=2打印训练过程的日志信息。
结果
参考博文
LSTM模型介绍
相关文章:
10.(Python数模)(预测模型二)LSTM回归网络(1→1)
LSTM回归网络(1→1) 长短期记忆网络 - 通常只称为“LSTM” - 是一种特殊的RNN,能够学习长期的规律。 它们是由Hochreiter&Schmidhuber(1997)首先提出的,并且在后来的工作中被许多人精炼和推广。…...

mac常见问题(五) Mac 无法开机
在mac的使用过程中难免会碰到这样或者那样的问题,本期为您带来Mac 无法开机怎么进行操作。 1、按下 Mac 上的电源按钮。每台 Mac 电脑都有一个电源按钮,通常标有电源符号 。然后检查有没有通电迹象,例如: 发声,例如由风…...

WebSocket与SSE区别
一,websocket WebSocket是HTML5下一种新的协议(websocket协议本质上是一个基于tcp的协议) 它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯的目的 Websocket是一个持久化的协议 websocket的原理 …...
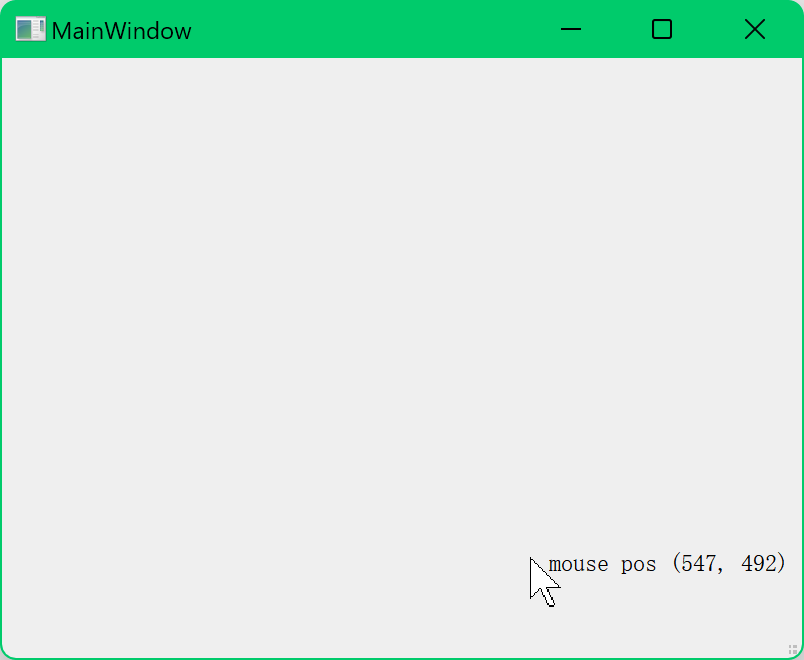
Qt鼠标点击事件处理:显示鼠标点击位置(完整示例)
Qt 入门实战教程(目录) 前驱文章: Qt Creator 创建 Qt 默认窗口程序(推荐) 什么是事件 事件是对各种应用程序需要知道的由应用程序内部或者外部产生的事情或者动作的通称。 事件(event)驱动…...

OpenCV:实现图像的负片
负片 负片是摄影中会经常接触到的一个词语,在最早的胶卷照片冲印中是指经曝光和显影加工后得到的影像。负片操作在很多图像处理软件中也叫反色,其明暗与原图像相反,其色彩则为原图像的补色。例如,颜色值A与颜色值B互为补色&#…...

HZOJ#237. 递归实现排列型枚举
题目描述 从 1−n这 n个整数排成一排并打乱次序,按字典序输出所有可能的选择方案。 输入 输入一个整数 n。(1≤n≤8) 输出 每行一组方案,每组方案中两个数之间用空格分隔。 注意每行最后一个数后没有空格。 样例…...

C++ PIMPL 编程技巧
C PIMPL 编程技巧 文章目录 C PIMPL 编程技巧什么是pimpl?pimpl优点举例实现 什么是pimpl? Pimpl (Pointer to Implementation) 是一种常见的 C 设计模式,用于隐藏类的实现细节,从而减少编译依赖和提高编译速度。它的基本思想是将…...

一个通用的EXCEL生成下载方法
Excel是一个Java开发中必须会用到的东西,之前博主也发过一篇关于使用Excel的文章,但是最近工作中,发现了一个更好的使用方法,所以,就对之前的博客进行总结,然后就有了这篇新的,万能通用的方法说…...

介绍 TensorFlow 的基本概念和使用场景。
TensorFlow(简称TF)是由Google开发的开源机器学习框架,它具有强大的数值计算和深度学习功能,广泛用于构建、训练和部署机器学习模型。以下是TensorFlow的基本概念和使用场景: 基本概念: 张量(T…...
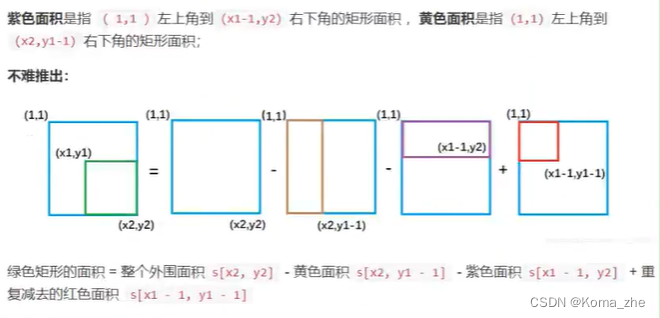
【力扣】304. 二维区域和检索 - 矩阵不可变 <二维前缀和>
目录 【力扣】304. 二维区域和检索 - 矩阵不可变二维前缀和理论初始化计算面积 题解 【力扣】304. 二维区域和检索 - 矩阵不可变 给定一个二维矩阵 matrix,以下类型的多个请求: 计算其子矩形范围内元素的总和,该子矩阵的 左上角 为 (row1, …...
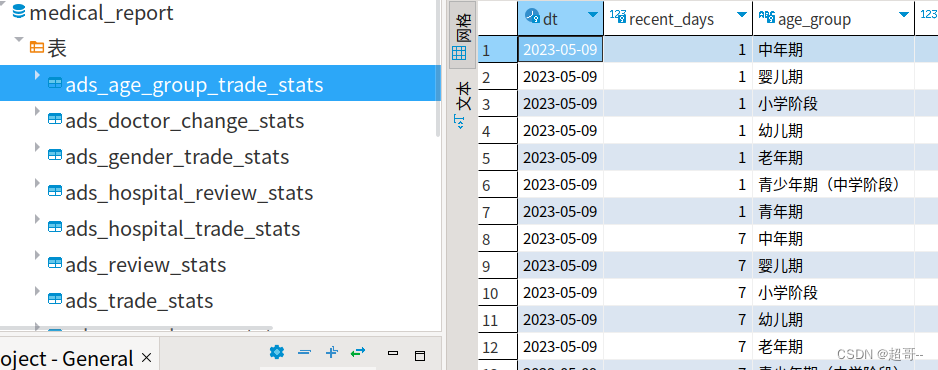
线上问诊:数仓开发(三)
系列文章目录 线上问诊:业务数据采集 线上问诊:数仓数据同步 线上问诊:数仓开发(一) 线上问诊:数仓开发(二) 线上问诊:数仓开发(三) 文章目录 系列文章目录前言一、ADS1.交易主题1.交易综合统计2.各医院交易统计3.各性…...
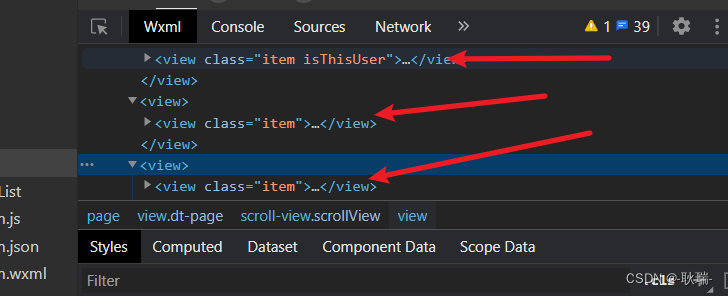
微信小程序 通过响应式数据控制元素class属性
我想大家照这个和我最初的目的一样 希望有和vue中v-bind:class一样方便的指令 但答案不太尽人意 这里 我们只能采用 三元运算符的形式 参考代码如下 <view class"item {{ userId item.userId ? isThisUser : }}"> </view>这里 我们判断 如果当前ite…...

linux并发服务器 —— linux网络编程(七)
网络结构模式 C/S结构 - 客户机/服务器;采用两层结构,服务器负责数据的管理,客户机负责完成与用户的交互;C/S结构中,服务器 - 后台服务,客户机 - 前台功能; 优点 1. 充分发挥客户端PC处理能力…...

Java后端开发面试题——企业场景篇
单点登录这块怎么实现的 单点登录的英文名叫做:Single Sign On(简称SSO),只需要登录一次,就可以访问所有信任的应用系统 JWT解决单点登录 用户访问其他系统,会在网关判断token是否有效 如果token无效则会返回401&am…...
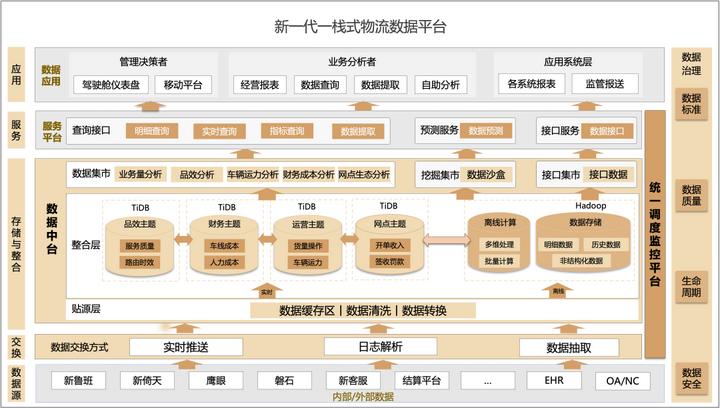
TiDB x 安能物流丨打造一栈式物流数据平台
作者:李家林 安能物流数据库团队负责人 本文以安能物流作为案例,探讨了在数字化转型中,企业如何利用 TiDB 分布式数据库来应对复杂的业务需求和挑战。 安能物流作为中国领先的综合型物流集团,需要应对大规模的业务流程ÿ…...

负载均衡算法实现
负载均衡算法实现 负载均衡介绍 负责均衡主要有以下五种方法实现: 1、轮询法 将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载; 2、随机法 通过系统的随机算法&#…...

Flutter 完美的验证码输入框 转载
刚开始看到这个功能的时候一定觉得so easy,开始的时候我也是这么觉得的,这还不简单,然而真正写的时候才发现并没有想象的那么简单。 先上图,不上图你们都不想看,我难啊,到Github: https://gith…...
)
SpringBoot整合Jpa实现增删改查功能(提供Gitee源码)
前言:在日常开发中,总是撰写一些简单的SQL会非常耗时间,Jpa可以完美的帮我们提高开发的效率,对于常规的SQL不需要我们自己撰写,相对于MyBatis有着更简单易用的功能,但是MyBatis自由度相对于Jpa会更高一些&a…...

微服务[Nacos]
CAP 1)一致性(Consistency) (所有节点在同一时间具有相同的数据) 2)可用性(Availability)(保证每个请求不管成功或者失败都有响应) 3)分区容错(Partition tolerance)(系统中任意信息的丢失或失败不会影响系统的继续运作) 一、虚拟机镜像准备 …...

8K视频来了,8K 视频编辑的最低系统要求
当今 RED、Canon、Ikegami、Sony 等公司的 8K 摄像机以及 8K 电视,许多视频内容制作人和电影制作人正在认真考虑 8K 拍摄、编辑和后期处理,需要什么样的系统来处理如此海量的数据? 中央处理器(CPU) 首先,…...

在 Hermes Agent 项目中集成 Taotoken 实现自定义模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Hermes Agent 项目中集成 Taotoken 实现自定义模型调用 对于正在使用 Hermes Agent 框架构建智能体应用的开发者而言࿰…...

教育科技项目如何通过Taotoken平衡AI功能效果与接口成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育科技项目如何通过Taotoken平衡AI功能效果与接口成本 在在线教育或培训类应用的开发与运营中,文本生成与总结功能已…...

如何掌握AMD Ryzen硬件调试:面向初学者的完整指南与3个实战场景
如何掌握AMD Ryzen硬件调试:面向初学者的完整指南与3个实战场景 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: h…...

STL转STEP格式转换终极指南:5分钟掌握专业3D模型转换技巧
STL转STEP格式转换终极指南:5分钟掌握专业3D模型转换技巧 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾经遇到过这样的困扰?精心设计的3D打印模型在STL格式下…...

从设备树到内核启动:一步步拆解Linux内核中CMA连续内存区域的创建与初始化全过程
Linux内核CMA连续内存分配器深度解析:从设备树配置到伙伴系统整合 引言 在现代嵌入式系统和多媒体设备开发中,大块连续物理内存的获取一直是开发者面临的棘手问题。当摄像头需要处理4K视频流、GPU渲染复杂场景或硬件编解码器处理高码率内容时ÿ…...

如何构建专业级电子签名:现代前端解决方案指南
如何构建专业级电子签名:现代前端解决方案指南 【免费下载链接】smooth-signature H5带笔锋手写签名,支持PC端和移动端,任何前端框架均可使用 项目地址: https://gitcode.com/gh_mirrors/smo/smooth-signature 在数字化办公时代&#…...

Suno.cn从工具到生态,AI音乐平台的崛起、挑战与本土化之路
2026年,Suno已从一款“文字生成音乐”的玩具,成长为估值25亿美元、年营收超3亿美元的全球AI音乐巨头。然而,在版权风暴与本土化浪潮中,它的故事远未结束。 🚀 一、市场地位与商业成功:Suno的狂飙突进 Suno在2026年的增长堪称现象级。其首席执行官Mikey Shulman宣布,平…...
保姆级安装避坑指南)
告别SU冲突!雷电模拟器9.0.20+新版Magisk Delta(狐狸面具)保姆级安装避坑指南
雷电模拟器9.0.20Magisk Delta深度适配指南:从冲突根源到完美兼容 当你在雷电模拟器9.0.20及以上版本尝试安装Magisk Delta(狐狸面具)时,是否遇到过Root权限反复失效、SU冲突提示不断弹出的困境?这背后隐藏着新版模拟器…...

智慧树刷课插件:如何用自动化工具解放你的学习时间
智慧树刷课插件:如何用自动化工具解放你的学习时间 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 你是否曾经花费大量时间在智慧树平台上手动点击视频、处…...
)
深入GD32F427的ENET外设:如何为你的LAN8720 PHY芯片选择正确的RMII时钟模式(REF_CLK In vs Out)
深入解析GD32F427与LAN8720的RMII时钟架构设计 在嵌入式以太网开发中,时钟信号的稳定性往往决定着整个通信系统的可靠性。当GD32F427微控制器通过RMII接口与LAN8720 PHY芯片协同工作时,REF_CLK时钟模式的选择不仅影响硬件成本,更直接关系到信…...