Scala集合常用函数与集合计算简单函数,高级计算函数Map和Reduce等
Scala集合常用函数与集合计算简单函数
1.Scala集合常用函数
基本属性和常用操作
1.常用函数:
- (1) 获取集合长度
- (2) 获取集合大小
- (3) 循环遍历
- (4) 迭代器
- (5) 生成字符串
- (6) 是否包含
- 代码示例:
object Test11_CommonOp {def main(args: Array[String]): Unit = {val list = List(1,3,5,7,2,89)val set = Set(23,34,423,75)// (1)获取集合长度println(list.length)// (2)获取集合大小println(set.size)// (3)循环遍历for (elem <- list)println(elem)set.foreach(println)// (4)迭代器for (elem <- list.iterator) println(elem)println("====================")// (5)生成字符串println(list)println(set)println(list.mkString("--"))// (6)是否包含println(list.contains(23))println(set.contains(23))}
}2. 衍生集合
- 对某个集合操作返回一个新的集合
- 常用的函数:
(1) 获取集合的头
(2) 获取集合的尾(不是头的就是尾)
(3) 集合最后一个数据
(4) 集合初始数据(不包含最后一个)
(5) 集合元素反转
(6) 取前(后)n 个元素
(7) 去掉前(后)n 个元素
(8) 并集
(9) 交集
(10) 差集
(11) 拉链
(12) 滑窗 - 代码示例:
object Test12_DerivedCollection {def main(args: Array[String]): Unit = {val list1 = List(1,3,5,7,2,89)val list2 = List(3,7,2,45,4,8,19)println("----------------------------")println("list1: " + list1)println("list2: " + list2)// (1)获取集合的头println("head: => "+ list1.head)// (2)获取集合的尾(不是头的就是尾)println("tail: => "+ list1.tail)// (3)集合最后一个数据println("last: => "+ list2.last)// (4)集合初始数据(不包含最后一个)println("init: => "+ list2.init)// (5)反转println("reverse: => "+ list1.reverse)// (6)取前(后)n个元素println("take:取前3个元素 => "+ list1.take(3))println("take:取后4个元素 => "+ list1.takeRight(4))// (7)去掉前(后)n个元素println("drop: 去掉前3个元素 => "+ list1.drop(3))println("dropRight: 去掉后4个元素 => "+ list1.dropRight(4))println("=========================")println("list1: " + list1)println("list2: " + list2)println("============ 并集 =============")// (8)并集val union = list1.union(list2)println("两个List集合并集,union: => " + union)//使用符号方法合并两个集合,三冒号:::println(list1 ::: list2)// 如果是set做并集,会去重val set1 = Set(1,3,5,7,2,89)val set2 = Set(3,7,2,45,4,8,19)val union2 = set1.union(set2)println("两个set集合的union: " + union2)println("两个set集合,并集符号操作"+ set1 ++ set2)println("-----------交集------------")println("list1: " + list1)println("list2: " + list2)// (9)交集val intersection = list1.intersect(list2)println("交集intersection: " + intersection)println("---------差集--------------")println("list1: " + list1)println("list2: " + list2)// (10)差集,存在于一个集合,而不属于另一个集合的元素,例如:属于list1,而不属于list2的元素,叫list1对list2的差集val diff1 = list1.diff(list2)val diff2 = list2.diff(list1)println("差集diff1: " + diff1)println("差集diff2: " + diff2)println("-----------拉链------------")println("list1: " + list1)println("list2: " + list2)// (11)拉链println("list1拉链list2, zip: " + list1.zip(list2))println("list2拉链list1, 拉链zip: " + list2.zip(list1))println("================ 滑窗 ==================")println("list1: " + list1)println("list2: " + list2)/*(12)滑窗,按照规定的窗口大小,滑动获取元素,比如3个元素大小的滑动窗口,依次获得取出元素进行操作,滑动窗口获取的是一个迭代器集合.例如: list1: List(1, 3, 5, 7, 2, 89)这个集合,滑动窗口为3,窗口步长为1:获取的集合分别为:List(1, 3, 5)List(3, 5, 7)List(5, 7, 2)List(7, 2, 89)*/println(list1.sliding(3))println("----------遍历窗口大小为3的滑动窗口获取的元素:-------------")for (elem <- list1.sliding(3))println(elem)println("-----------------------")/** 这个集合list2: List(3, 7, 2, 45, 4, 8, 19),假设滑动窗口大小为4,步长为2,获取的集合分别为:* List(3, 7, 2, 45)List(2, 45, 4, 8)List(4, 8, 19)*/println("---------- 遍历滑动窗口大小为4,步长为2的滑动窗口获取的集合分别为 -------------")for (elem <- list2.sliding(4, 2))println(elem)println("---------- 遍历滑动窗口大小为3,步长为3的滑动窗口获取的集合分别为 -------------")for (elem <- list2.sliding(3, 3))println(elem)}
}- 控制台效果
----------------------------
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
head: => 1
tail: => List(3, 5, 7, 2, 89)
last: => 19
init: => List(3, 7, 2, 45, 4, 8)
reverse: => List(89, 2, 7, 5, 3, 1)
take:取前3个元素 => List(1, 3, 5)
take:取后4个元素 => List(5, 7, 2, 89)
drop: 去掉前3个元素 => List(7, 2, 89)
dropRight: 去掉后4个元素 => List(1, 3)
=========================
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
============ 并集 =============
两个List集合并集,union: => List(1, 3, 5, 7, 2, 89, 3, 7, 2, 45, 4, 8, 19)
List(1, 3, 5, 7, 2, 89, 3, 7, 2, 45, 4, 8, 19)
两个set集合的union: Set(5, 89, 1, 2, 45, 7, 3, 8, 19, 4)
两个set集合,并集符号操作 Set(5, 89, 1, 2, 45, 7, 3, 8, 19, 4)
-----------交集------------
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
交集intersection: List(3, 7, 2)
---------差集--------------
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
差集diff1: List(1, 5, 89)
差集diff2: List(45, 4, 8, 19)
-----------拉链------------
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
list1拉链list2, zip: List((1,3), (3,7), (5,2), (7,45), (2,4), (89,8))
list2拉链list1, 拉链zip: List((3,1), (7,3), (2,5), (45,7), (4,2), (8,89))
================ 滑窗 ==================
list1: List(1, 3, 5, 7, 2, 89)
list2: List(3, 7, 2, 45, 4, 8, 19)
<iterator>
----------遍历窗口大小为3的滑动窗口获取的元素:-------------
List(1, 3, 5)
List(3, 5, 7)
List(5, 7, 2)
List(7, 2, 89)
-----------------------
---------- 遍历滑动窗口大小为4,步长为2的滑动窗口获取的集合分别为 -------------
List(3, 7, 2, 45)
List(2, 45, 4, 8)
List(4, 8, 19)
---------- 遍历滑动窗口大小为3,步长为3的滑动窗口获取的集合分别为 -------------
List(3, 7, 2)
List(45, 4, 8)
List(19)
3. 集合计算简单函数
1.常见函数:
(1) 求和
(2) 求乘积
(3) 最大值
(4) 最小值
(5) 排序:
- ① sorted 对一个集合进行自然排序,通过传递隐式的Ordering
- ② sortBy 对一个属性或多个属性进行排序,通过它的类型。
- ③ sortWith 基于函数的排序,通过一个 comparator 函数,实现自定义排序的逻辑。
- 代码示例:
object Test13_SimpleFunction {def main(args: Array[String]): Unit = {val list = List(5,1,8,2,-3,4)val list2 = List(("a", 5), ("b", 1), ("c", 8), ("d", 2), ("e", -3), ("f", 4))// (1)求和var sum = 0for (elem <- list){sum += elem}println("list集合求和" + sum)println("list集合求和sum函数" + list.sum)// (2)求乘积println("list集合求乘积product函数" + list.product)// (3)最大值println("list集合求max最大值" + list.max)/** list2集合:List(("a", 5), ("b", 1), ("c", 8), ("d", 2), ("e", -3), ("f", 4))* 对于这种集合,集合内部是一些二元组,那么我们如何根据二元组的第二个数值进行判断取最大值呢?这就是需要使用MaxBy()函数了,* MaxBy()函数需要传一个函数作为参数,所传的函数是对数据最大值判断逻辑* 例如:list2.maxBy( (tuple: (String, Int)) => tuple._2 ),其中tuple._2表示取二元组的第二个元素进行判断* 也可以简化成:list2.maxBy( _._2 ),当函数的参数类型一定的情况下,参数类型可以省略,函数体是对元组取第二个值,* 可以使用_作为通配符表示元组对象本身,_2表示元组对象的第二个元素。*/println(list2.maxBy( (tuple: (String, Int)) => tuple._2 ))println(list2.maxBy( _._2 ))// (4)最小值println("list集合求min最小值" + list.min)//MinBy()函数传一个函数作为参数,用于定义最小值的判断规则println(list2.minBy(_._2))println("========================")// (5)排序// 5.1 sorted 默认从小到大排序val sortedList = list.sorted //list是不可变List集合,我们把排序好的新集合赋值给一个值保存println("list集合sorted排序: " + sortedList)// 从大到小逆序排序println("从大到小逆序排序: "+ list.sorted.reverse)// 传入隐式参数,Ordering[Int],这个类型是排序类型Ordering[Int]println(list.sorted(Ordering[Int].reverse))println(list2.sorted)// 5.2 sortBy, 这个函数可以传一个函数作为参数,用于指定排序的元素,比如指定为元组的第二个元素,_2println(list2.sortBy(_._2))//传入隐式参数,实现倒序排列println(list2.sortBy(_._2)(Ordering[Int].reverse))// 5.3 sortWith,这个函数需要传一个函数作为参数,函数定义的是比较规则,类似于Java的Compare方法//下面这个是Lambad表达式,表示传入的函数为 :(a: Int, b: Int) => {a < b} 大括号里面是比较规则println(list.sortWith( (a: Int, b: Int) => {a < b} ))//由于参数a和b,以及函数体中参数均是出现一次,可以使用_通配符代替,下面为简化的写法:println(list.sortWith( _ < _ ))//这个是从大到小排序println(list.sortWith( _ > _))}
}Ordering[Int]类型
在 Scala 中,Ordering[Int] 是一个类型类(type class),用于指定整数类型的比较规则。它提供了对整数的比较操作,可以用于排序、查找最大值和最小值等操作。
在标准库中,Scala 已经为 Int 类型提供了默认的比较规则。因此,当你使用 Ordering[Int] 时,实际上使用的是默认的比较规则。
以下是使用 Ordering[Int] 的一些常见操作:
- 比较两个整数的大小:
val a = 5
val b = 10if (Ordering[Int].compare(a, b) < 0) {println("a 小于 b")
} else if (Ordering[Int].compare(a, b) > 0) {println("a 大于 b")
} else {println("a 等于 b")
}
- 对整数列表进行排序:
val numbers = List(5, 3, 1, 4, 2)
val sortedNumbers = numbers.sorted(Ordering[Int])
println(sortedNumbers) // 输出 List(1, 2, 3, 4, 5)
- 查找最大值和最小值:
val numbers = List(5, 3, 1, 4, 2)
val maxNumber = numbers.max(Ordering[Int])
val minNumber = numbers.min(Ordering[Int])
println(maxNumber) // 输出 5
println(minNumber) // 输出 1
上述代码中,Ordering[Int] 被用于进行整数的比较、排序和查找最值操作。
需要注意的是,Ordering[Int] 是一个隐式值(implicit value),因此在大多数情况下,你不需要显式地提供它。Scala 编译器会自动查找可用的 Ordering[Int] 实例。
4. 集合高级计算函数
- 说明
(1) 过滤 filter,遍历一个集合并从中获取满足指定条件的元素组成一个新的集合。
(2) 转化/映射(map)将集合中的每一个元素映射到某一个函数
(3) 扁平化
(4)扁平化+映射 注:flatMap 相当于先进行 map 操作,在进行 flatten 操作集合中的每个元素的子元素映射到某个函数并返回新集合。
(5) 分组(group)按照指定的规则对集合的元素进行分组
(6) 简化(归约)Reduce。
(7) 折叠fold
在 Scala 中,集合计算的高级函数是指那些可以对集合进行高阶操作和转换的函数。这些高级函数是函数式编程的核心概念之一,可以让我们以简洁而优雅的方式处理集合数据。
以下是 Scala 中常用的几个集合计算的高级函数:
- map:map 函数可以将一个集合中的每个元素通过指定的函数进行转换,生成一个新的集合。它适用于对集合中的每个元素做一种映射转换的场景。
val numbers = List(1, 2, 3, 4, 5)
val squares = numbers.map(x => x * x) // 对每个元素求平方
- filter:filter 函数可以根据指定的条件筛选出集合中符合条件的元素,生成一个新的集合。它适用于对集合进行过滤的场景。
val numbers = List(1, 2, 3, 4, 5)
val evenNumbers = numbers.filter(x => x % 2 == 0) // 筛选出偶数
- reduce/reduceLeft/reduceRight:reduce 函数可以将集合中的元素通过指定的二元操作函数进行聚合计算,得到一个结果。它适用于对集合中的元素进行累加、求和等操作的场景。
val numbers = List(1, 2, 3, 4, 5)
val sum = numbers.reduce((x, y) => x + y) // 所有元素求和
- fold/foldLeft/foldRight:fold 函数是 reduce 的变种,它可以指定一个初始值,并将该初始值与集合中的元素通过指定的二元操作函数进行聚合计算,得到一个结果。它适用于对集合中的元素进行累加、求和等操作,并且支持指定初始值的场景。
val numbers = List(1, 2, 3, 4, 5)
val sum = numbers.fold(0)((x, y) => x + y) // 所有元素求和,初始值为0
除了以上几个常用的高级函数,Scala 还提供了更多丰富的集合计算函数,比如 flatMap、groupBy、sortBy、zip 等,它们可以满足更多不同的集合操作需求。
flatMap、groupBy、sortBy、zip 这几个函数的作用和用法:
- flatMap:flatMap 函数可以对集合中的每个元素应用一个函数,并将结果展平成一个新的集合。它结合了 map 和 flatten 两个操作,常用于对嵌套集合进行扁平化操作。
val words = List("Hello", "World")
val letters = words.flatMap(word => word.toList) // 将每个单词转换为字符列表,并展平为一个字符列表
- groupBy:groupBy 函数可以根据指定的分类函数将集合中的元素分组,生成一个 Map,其中键是根据分类函数计算的结果,值是对应的元素列表。
val numbers = List(1, 2, 3, 4, 5)
val grouped = numbers.groupBy(number => number % 2) // 根据奇偶性分组
执行上述代码后,grouped 的结果为 Map(0 -> List(2, 4), 1 -> List(1, 3, 5)),其中键 0 表示偶数,键 1 表示奇数。
- sortBy:sortBy 函数可以根据指定的排序函数对集合中的元素进行排序,并生成一个新的排序后的集合。
val numbers = List(5, 3, 1, 4, 2)
val sorted = numbers.sortBy(number => number) // 按照升序排序
- zip:zip 函数可以将两个集合按照索引位置一对一地进行配对,并生成一个新的元素对集合。如果两个集合长度不一致,则生成的新集合长度为较短的集合长度。
val letters = List('A', 'B', 'C')
val numbers = List(1, 2, 3)
val zipped = letters.zip(numbers) // [('A', 1), ('B', 2), ('C', 3)]
上述代码中,letters 和 numbers 分别配对形成了 zipped,根据索引位置一一对应。
这些高级函数可以帮助我们在处理集合数据时更加灵活和高效。通过使用它们,我们可以以更简洁的方式完成常见的集合操作。
高级计算函数的一些代码示例
Map映射,扁平化,分组操作
object Test14_HighLevelFunction_Map {def main(args: Array[String]): Unit = {val list = List(1,2,3,4,5,6,7,8,9)// 1. 过滤// 选取偶数val evenList = list.filter( (elem: Int) => {elem % 2 == 0} )println(evenList)// 选取奇数println(list.filter( _ % 2 == 1 ))println("=======================")// 2. 映射map// 把集合中每个数乘2println(list.map( elem => elem * 2 ))//简化如下:println(list.map(_ * 2))println(list.map( x => x * x))println("=======================")// 3. 扁平化val nestedList: List[List[Int]] = List(List(1,2,3),List(4,5),List(6,7,8,9))val flatList = nestedList(0) ::: nestedList(1) ::: nestedList(2)println(flatList)val flatList2 = nestedList.flattenprintln(flatList2)println("=========先对集合map映射操作,然后扁平化flatten操作:==============")// 4. 扁平映射// 将一组字符串进行分词,并保存成单词的列表val strings: List[String] = List("hello world", "hello scala", "hello java", "we study")val splitList: List[Array[String]] = strings.map( _.split(" ") ) // 分词val flattenList = splitList.flatten // 打散扁平化println(flattenList)println("------------直接使用flatMap函数扁平化-----------------")// 使用flatMap函数,可以直接对字符串数组进行打散,然后扁平化。参数是函数,定义打散的规则,也就是切词规则val flatmapList = strings.flatMap(_.split(" "))println(flatmapList)println("========================")/*5. 分组groupBy函数,返回的是一个不可变Map集合:immutable.Map[K, Repr]groupBy函数解读:函数用于根据指定的分类函数将集合中的元素分组,并生成一个不可变的 Map,其中键是根据分类函数计算的结果,值是对应的元素列表。例子:val groupMap2: Map[String, List[Int]] = list.groupBy( data => if (data % 2 == 0) "偶数" else "奇数")*/// 分成奇偶两组val groupMap: Map[Int, List[Int]] = list.groupBy( _ % 2)println("分组不指定分类函数计算结果对应的键值: " + groupMap)/*** 打印的结果是:Map(1 -> List(1, 3, 5, 7, 9), 0 -> List(2, 4, 6, 8))*/val groupMap2: Map[String, List[Int]] = list.groupBy( data => if (data % 2 == 0) "偶数" else "奇数")println(groupMap2)// 给定一组词汇,按照单词的首字母进行分组val wordList = List("china", "america", "alice", "canada", "cary", "bob", "japan")println( wordList.groupBy( _.charAt(0) ) )}
}- 控制台打印结果:
List(2, 4, 6, 8)
List(1, 3, 5, 7, 9)
=======================
List(2, 4, 6, 8, 10, 12, 14, 16, 18)
List(2, 4, 6, 8, 10, 12, 14, 16, 18)
List(1, 4, 9, 16, 25, 36, 49, 64, 81)
=======================
List(1, 2, 3, 4, 5, 6, 7, 8, 9)
List(1, 2, 3, 4, 5, 6, 7, 8, 9)
=========先对集合map映射操作,然后扁平化flatten操作:==============
List(hello, world, hello, scala, hello, java, we, study)
------------直接使用flatMap函数扁平化-----------------
List(hello, world, hello, scala, hello, java, we, study)
========================
分组不指定分类函数计算结果对应的键值: Map(1 -> List(1, 3, 5, 7, 9), 0 -> List(2, 4, 6, 8))
Map(奇数 -> List(1, 3, 5, 7, 9), 偶数 -> List(2, 4, 6, 8))
Map(b -> List(bob), j -> List(japan), a -> List(america, alice), c -> List(china, canada, cary))
- groupBy分组函数scala底层源码
def groupBy[K](f: A => K): immutable.Map[K, Repr] = {val m = mutable.Map.empty[K, Builder[A, Repr]]for (elem <- this) {val key = f(elem)val bldr = m.getOrElseUpdate(key, newBuilder)bldr += elem}val b = immutable.Map.newBuilder[K, Repr]for ((k, v) <- m)b += ((k, v.result))b.result}
源码解读:
这段代码是 Scala 标准库中的 groupBy 函数的实现。groupBy 函数用于根据指定的分类函数将集合中的元素分组,并生成一个不可变的 Map,其中键是根据分类函数计算的结果,值是对应的元素列表。
让我们逐行解释这段代码的含义:
-
def groupBy[K](f: A => K): immutable.Map[K, Repr] = {:这是一个泛型方法定义,接受一个类型为A => K的函数f,返回一个不可变的 Map。 -
val m = mutable.Map.empty[K, Builder[A, Repr]]:创建一个空的可变 Mapm,用于存储分组后的元素。 -
for (elem <- this) {:对集合中的每个元素执行循环。 -
val key = f(elem):使用分类函数f对当前元素elem进行计算,得到分类的键key。 -
val bldr = m.getOrElseUpdate(key, newBuilder):从 Mapm中获取键为key的值,如果不存在则创建一个新的 Builder,并将其存储到 Mapm中,然后将其赋值给变量bldr。 -
bldr += elem:将当前元素elem加入到对应键所对应的 Builder 中。 -
val b = immutable.Map.newBuilder[K, Repr]:创建一个新的不可变 Map 的建造器b。 -
for ((k, v) <- m):对 Mapm中的每个键值对执行循环。 -
b += ((k, v.result)):将键值对(k, v.result)加入到不可变 Map 的建造器b中,其中v.result是 Builder 中存储的元素的结果(即分组后的元素列表)。 -
b.result:获取不可变 Map 的最终结果,并返回。
总之,以上代码实现了将集合中的元素根据分类函数进行分组,并生成一个不可变的 Map。这个函数在实际开发中非常有用,可以方便地进行数据分组和聚合操作。
reduce和fold操作
- 示例2:
object Test15_HighLevelFunction_Reduce {def main(args: Array[String]): Unit = {val list = List(1,2,3,4)// 1. reduceprintln(list.reduce( _ + _ ))println(list.reduceLeft(_ + _))println(list.reduceRight(_ + _))println("===========================")val list2 = List(3,4,5,8,10)println(list2.reduce(_ - _)) // -24println(list2.reduceLeft(_ - _))println(list2.reduceRight(_ - _)) // 3 - (4 - (5 - (8 - 10))), 6println("===========================")// 2. foldprintln(list.fold(10)(_ + _)) // 10 + 1 + 2 + 3 + 4println(list.foldLeft(10)(_ - _)) // 10 - 1 - 2 - 3 - 4println(list2.foldRight(11)(_ - _)) // 3 - (4 - (5 - (8 - (10 - 11)))), -5}
}reduce源码解读:
reduce 方法是 Scala 集合中的一个高阶函数,用于将集合中的元素进行聚合。下面是 reduce 方法的源码解读:
def reduce[A1 >: A](op: (A1, A1) => A1): A1 = {if (isEmpty)throw new UnsupportedOperationException("empty.reduce")var first = truevar acc: A1 = 0.asInstanceOf[A1]for (x <- self) {if (first) {acc = xfirst = false}else acc = op(acc, x)}acc
}
首先,reduce 方法接受一个二元函数 op,类型为 (A1, A1) => A1,用于将集合中的元素进行聚合。在 Scala 中,二元函数是一种函数类型,接受两个相同类型的参数,返回一个与参数类型相同的结果值。
二元函数是一个接受两个相同类型参数并返回相同类型结果的函数。在 fold 方法中,二元函数 op 用于将集合中的元素进行聚合、累积或操作。
如果集合为空,则会抛出 UnsupportedOperationException 异常。
接着,方法定义了一个名为 first 的变量,初值为 true,表示当前聚合的是第一个元素。另外,定义了一个名为 acc 的变量,初值为 0,它表示聚合的结果。
接下来,reduce 方法使用 for 循环遍历集合中的每个元素。对于第一个元素,将其赋值给 acc 变量。对于第二个及之后的元素,将它们分别与 acc 变量进行二进制操作,更新 acc 变量的值。
最后,reduce 方法返回聚合的结果。
例如,以下代码使用 reduce 表示计算所有元素的和:
val list = List(1, 2, 3, 4, 5)
val sum = list.reduce(_ + _)
println(sum) // 输出 15
这里的 _ + _ 表示一个匿名函数,它接受两个整数参数并返回它们的和。
需要注意的是,reduce 方法的工作原理是将集合中的元素两两进行操作,因此操作符必须是可交换和关联的。否则,聚合结果可能会出现意外的错误。
二元函数是一个接受两个相同类型参数并返回相同类型结果的函数。在 fold 方法中,二元函数 op 用于将集合中的元素进行聚合、累积或操作。
如果集合为空,则会抛出 UnsupportedOperationException 异常。
fold函数源码解读:
fold 是 Scala 集合中提供的一个高阶函数,用于将集合中的元素进行折叠(折叠也可以称为累积、聚合)操作。下面是 fold 方法的源码解读:
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = {var acc = zfor (x <- self) acc = op(acc, x)acc
}
首先,fold 方法接受两个参数:一个初始值 z 和一个二元函数 op。初始值 z 表示折叠的起始值,而二元函数 op 表示对两个相同类型的值进行操作并返回结果。
然后,方法定义了一个名为 acc 的变量,用于存储折叠的结果。初始时,将 acc 的值设置为初始值 z。
接下来,fold 方法使用 for 循环遍历集合中的每个元素,并使用二元函数 op 对当前元素和 acc 进行操作,更新 acc 变量的值。
最后,fold 方法返回折叠的结果。
例如,以下代码使用 fold 方法计算所有元素的乘积:
val list = List(1, 2, 3, 4, 5)
val product = list.fold(1)(_ * _)
println(product) // 输出 120
这里的 1 是初始值,表示折叠的起始值。而 _ * _ 表示一个匿名函数,它接受两个整数参数并返回它们的乘积。
需要注意的是,fold 方法可以用于任何类型的集合,包括数组、列表、映射等。它提供了一种通用的方式来对集合进行折叠操作。
使用fold函数将两个集合合并
代码示例
object Test16_MergeMap {def main(args: Array[String]): Unit = {val map1 = Map("a" -> 1, "b" -> 3, "c" -> 6)val map2 = mutable.Map("a" -> 6, "b" -> 2, "c" -> 9, "d" -> 3)// println(map1 ++ map2)/*** def foldLeft[B](z: B)(op: (B, A) => B): B ={...}* foldLeft( 初始化值map2 )( (mergedMapResult 当前聚合的结果, KV是 map1中的kv键值对 ) => {} )**/val map3 = map1.foldLeft(map2)((mergedMapResult, kv) => {val key = kv._1val value = kv._2// 从当前聚合的结果Map集合中通过key获取值,如果有这个可以则将对应map1的相同key的值累加,没有对应的key默认值为0mergedMapResult(key) = mergedMapResult.getOrElse(key, 0) + valuemergedMapResult})println(map3)}
}相关文章:

Scala集合常用函数与集合计算简单函数,高级计算函数Map和Reduce等
Scala集合常用函数与集合计算简单函数 1.Scala集合常用函数 基本属性和常用操作 1.常用函数: (1) 获取集合长度(2) 获取集合大小(3) 循环遍历(4) 迭代器(…...
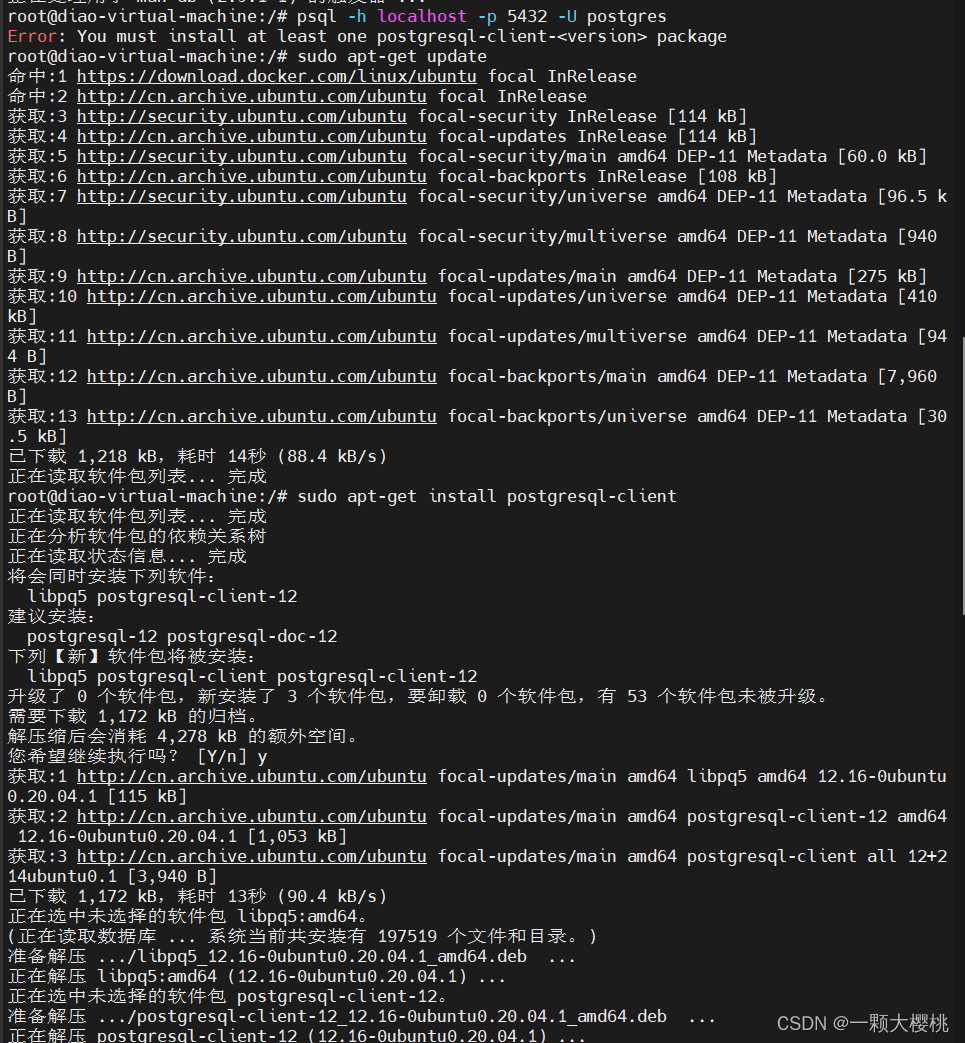
You must install at least one postgresql-client-<version> package
使用主机上的映射端口来连接到 PostgreSQL 数据库。例如,使用以下命令连接到数据库: psql -h localhost -p 5432 -U postgres出现下面的问题: 分析: 如果您在运行 psql 命令时遇到错误消息 You must install at least one pos…...

爬虫源码---爬取自己想要看的小说
前言: 小说作为在自己空闲时间下的消遣工具,对我们打发空闲时间很有帮助,而我们在网站上面浏览小说时会被广告和其他一些东西影响我们的观看体验,而这时我们就可以利用爬虫将我们想要观看的小说下载下来,这样就不会担…...

【AGC】云数据库API9开发问题汇总
【问题描述】 云数据库HarmonyOS API9 SDK已经推出了一段时间了,下面为大家汇总一些在集成使用中遇到的问题和解决方案。 【问题分析】 1. 报错信息:数据库初始化失败:{“message”:“The object type list and permission …...

ASP.NET Core IOC容器
//IOC容器支持依赖注入{ServiceCollection serviceDescriptors new ServiceCollection();serviceDescriptors.AddTransient<IMicrophone, Microphone>();serviceDescriptors.AddTransient<IPower, Power>();serviceDescriptors.AddTransient<IHeadphone, Headp…...
入门力扣自学笔记277 C++ (题目编号:42)(动态规划)
42. 接雨水 题目: 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组…...
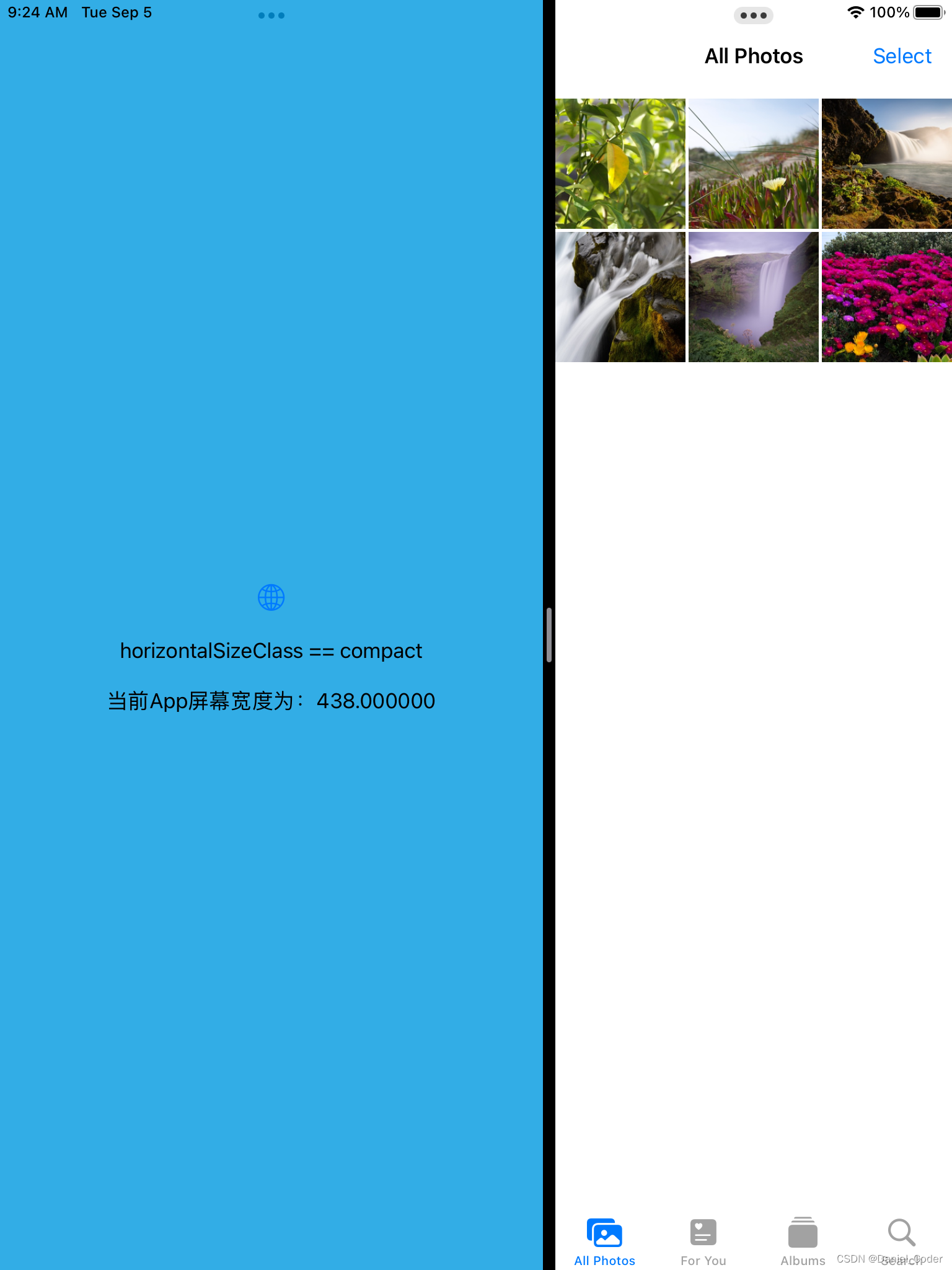
SwiftUI实现iPad多任务分屏
1. 概述 iPadOS引入了多任务分屏功能,使用户能够同时在一个屏幕上使用多个应用程序。这为用户提供了更高效的工作环境,可以在同一时间处理多个任务。 iPad多任务分屏有两种常见的模式:1/2分屏和Slide Over(滑动覆盖)…...
maven依赖,继承
依赖的范围 compile引入的依赖 对main目录下的代码有没有效,main目录下的代码能不能用compile引入的依赖中的类等 以test引入的依赖,在main中是否可以使用 provided(已提供),有了就不要带到服务器上,打包…...
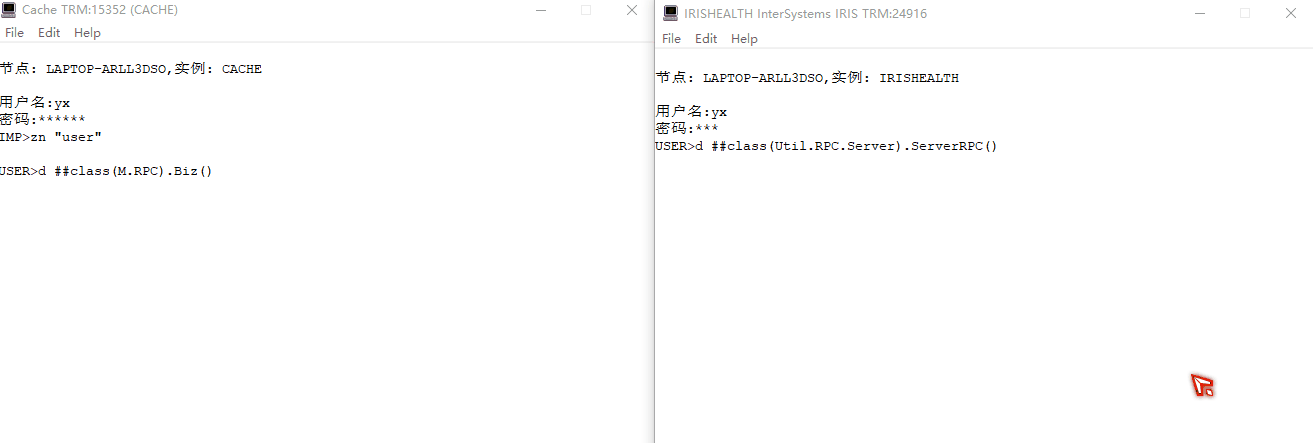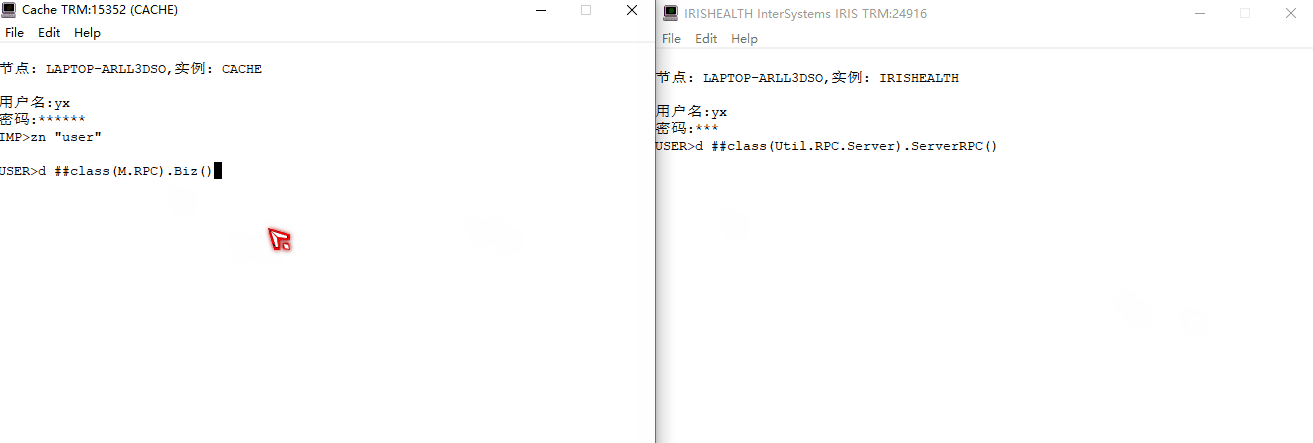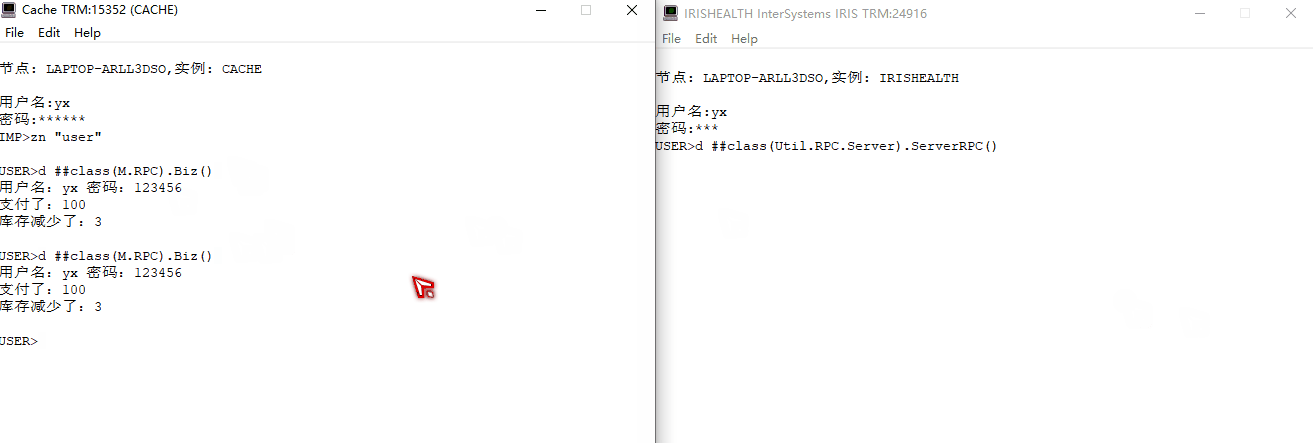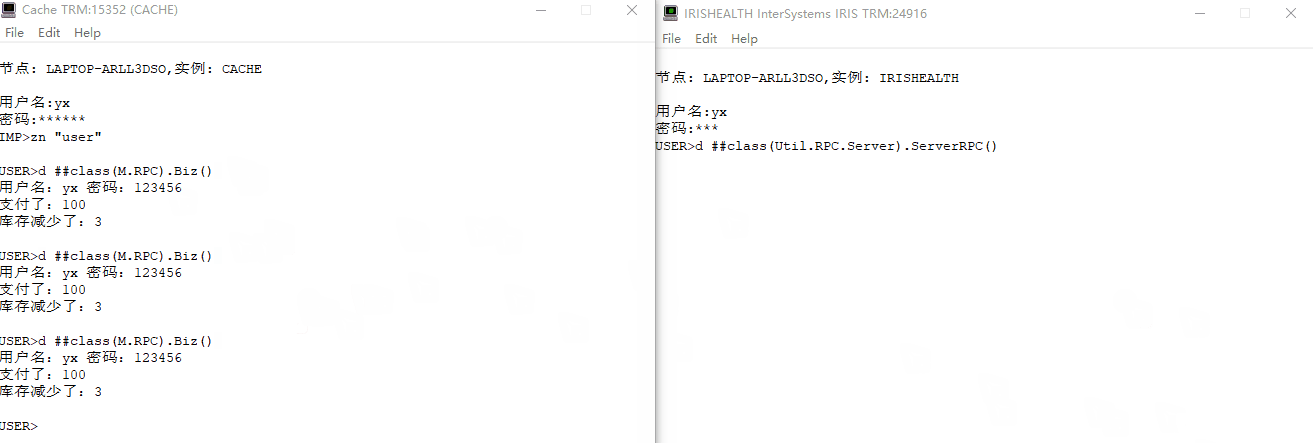
仿`gRPC`功能实现像调用本地方法一样调用其他服务器方法
文章目录 仿gRPC功能实现像调用本地方法一样调用其他服务器方法 简介单体架构微服务架构RPCgPRC gRPC交互逻辑服务端逻辑客户端逻辑示例图 原生实现仿gRPC框架编写客户端方法编写服务端方法综合演示 仿 gRPC功能实现像调用本地方法一样调用其他服务器方法 简介 在介绍gRPC简介…...
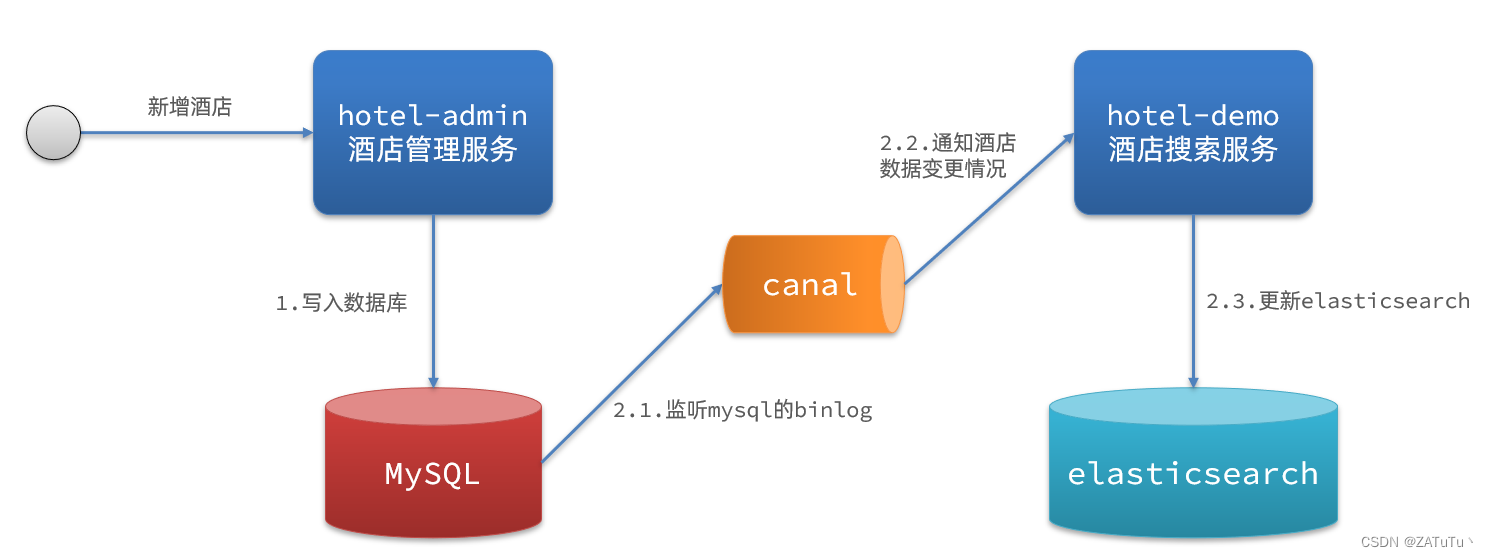
分布式环境下的数据同步
一般而言elasticsearch负责搜索(查询),而sql数据负责记录(增删改),elasticsearch中的数据来自于sql数据库,因此sql数据发生改变时,elasticsearch也必须跟着改变,这个就是…...

无涯教程-Flutter - 数据库
SQLite" class"css-1occaib">SQLite数据库是基于事实和标准SQL的嵌入式数据库引擎,它是小型且经过时间考验的数据库引擎,sqflite软件包提供了许多函数,可以有效地与SQLite数据库一起使用,它提供了操作SQLite数据…...
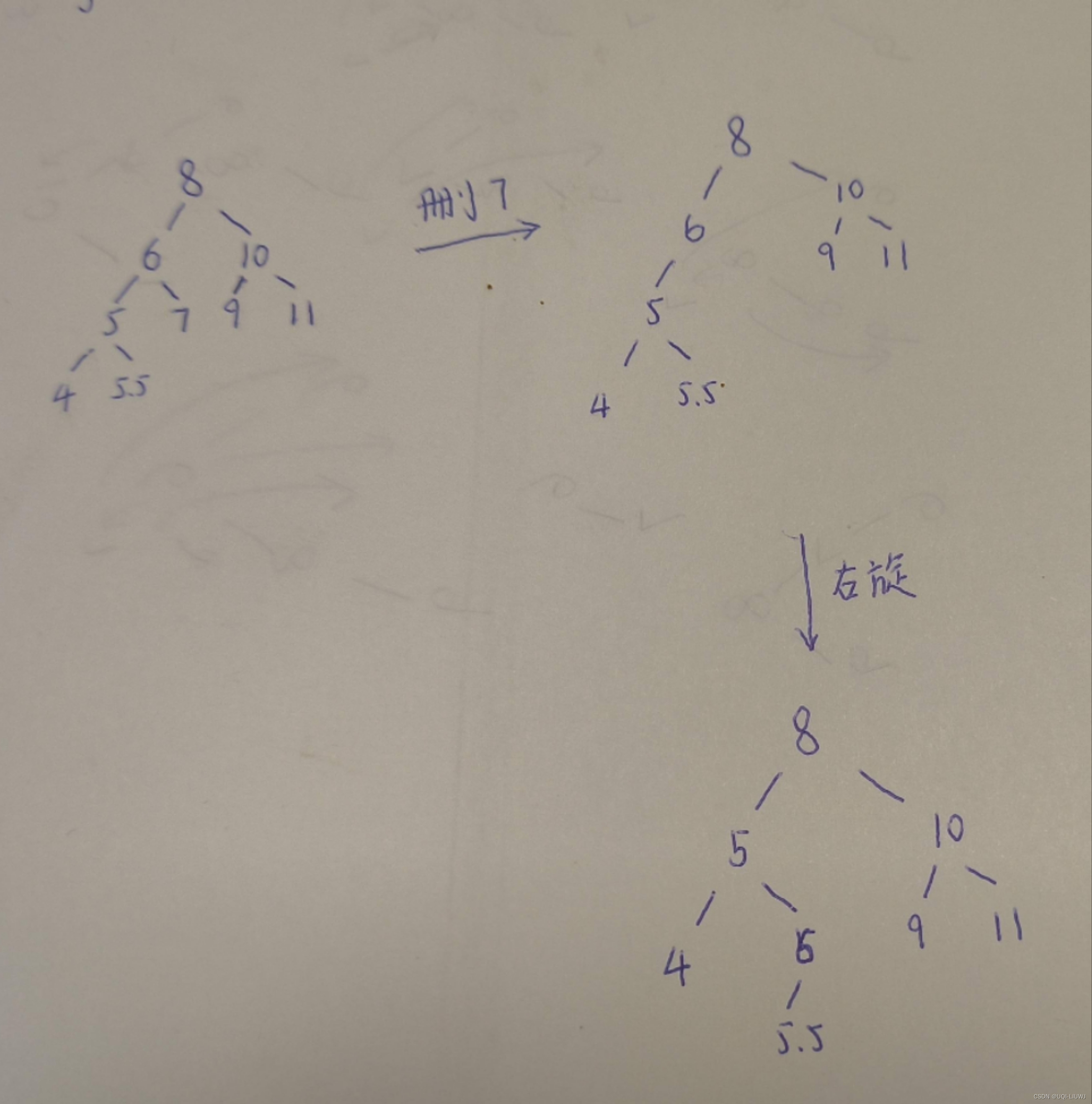
算法笔记:平衡二叉树
1 介绍 平衡二叉树(AVL树)是一种特殊的二叉搜索树(BST),它自动确保树保持低高度,以便实现各种基本操作(如添加、删除和查找)的高效性能。 ——>时间都维持在了O(logN)它是一棵空…...

redis 通用命令
目录 通用命令是什么 SET & GET keys EXISTS DEL EXPIRE TTL redis 的过期策略 定时器策略 基于优先级队列定时器 基于时间轮的定时器 TYPE 通过 redis 客户端和 redis 服务器交互。 所以需要使用 redis 的命令,但是 redis 的命令非常多。 通用命令…...
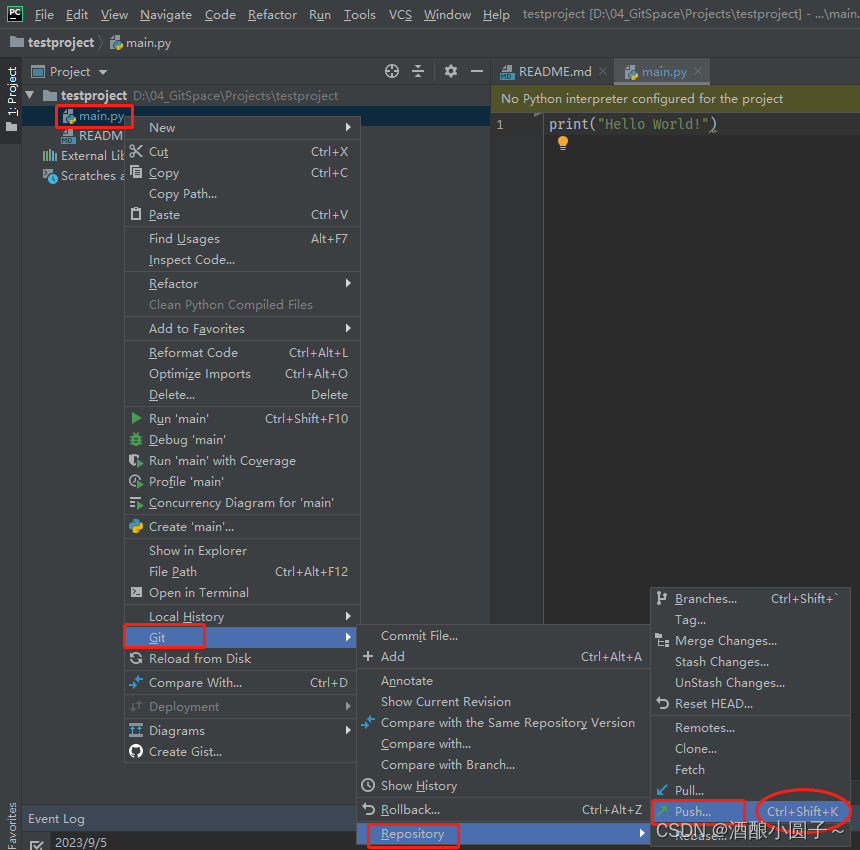
Pycharm配置及使用Git教程
文章目录 1. 安装PyCharm2. 安装Git3. 在PyCharm中配置Git插件4. 连接远程Gtilab仓库5. Clone项目代码6. 将本地文件提交到远程仓库6.1 git add6.2 git commit6.3 git push6.4 git pull 平时习惯在windows下开发,但是我们又需要实时将远方仓库的代码clone到本地&…...
CSS transition 过渡
1 前言 水平居中、垂直居中是前端面试百问不厌的问题。 其实现方案也是多种多样,常叫人头昏眼花。 水平方向可以认为是内联方向,垂直方向认为是块级方向。 下面介绍一些常见的方法。 2 内联元素的水平垂直居中 首先,常见内联元素有&…...

Unity中Shader的UV扭曲效果的实现
文章目录 前言一、实现的思路1、在属性面板暴露一个 扭曲贴图的属性2、在片元结构体中,新增一个float2类型的变量,用于独立存储将用于扭曲的纹理的信息3、在顶点着色器中,根据需要使用TRANSFORM_TEX对Tilling 和 Offset 插值;以及…...
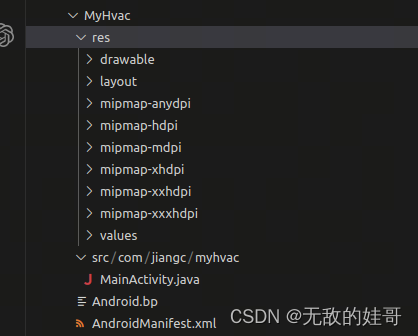
Automotive 添加一个特权APP
Automotive 添加一个特权APP platform: android-13.0.0_r32 一. 添加一个自定义空调的app为例 路径:packages/apps/Car/MyHvac app内容可以自己定义,目录结构如下: 1.1 Android.bp package {default_applicable_licenses: ["Andr…...

自定义TimeLine
自定义TimeLine 什么是TimeLineData(数据)Clip(片段)Track(轨道)Mixer(混合) 什么是TimeLine 在 Unity 中,TimeLine(时间轴)是一种用于创建和管理…...

如何使用SQL系列 之 如何在SQL中使用WHERE条件语句
引言 在结构化查询语言 (SQL)语句中,WHERE子句限制了给定操作会影响哪些行。它们通过定义特定的条件(称为搜索条件)来实现这一点,每一行都必须满足这些条件才能受到操作的影响。 本指南将介绍WHERE子句中使用的通用语法。它还将概述如何在单个WHERE子句…...
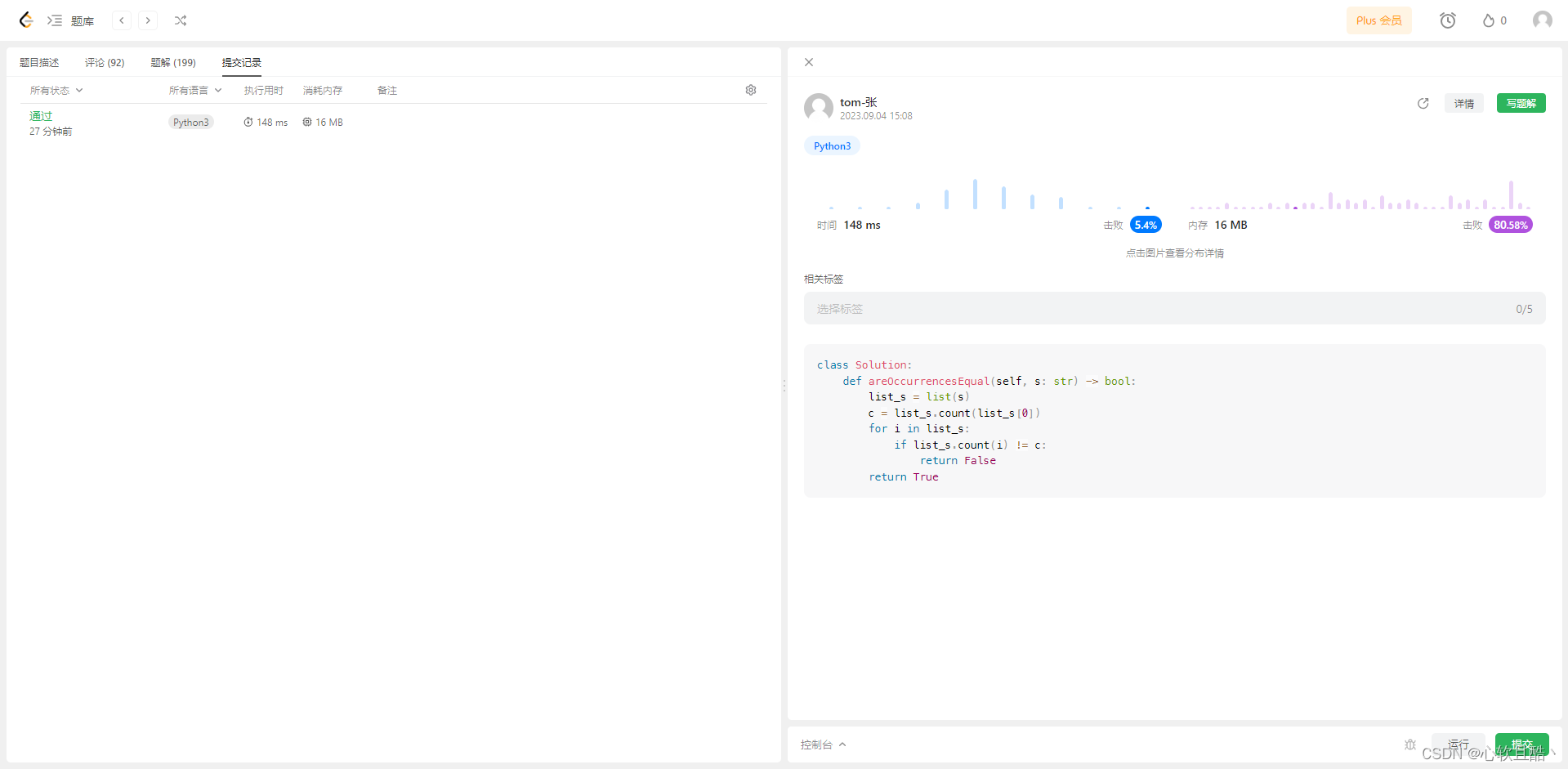
leetcode:1941. 检查是否所有字符出现次数相同(python3解法)
难度:简单 给你一个字符串 s ,如果 s 是一个 好 字符串,请你返回 true ,否则请返回 false 。 如果 s 中出现过的 所有 字符的出现次数 相同 ,那么我们称字符串 s 是 好 字符串。 示例 1: 输入:s…...

C#上位机如何连接西门子S7-1500的Modbus服务器?从PLC配置到.NET代码实战
C#上位机连接西门子S7-1500 Modbus服务器全流程解析 在工业自动化领域,上位机与PLC的通信是实现数据采集和设备控制的关键环节。西门子S7-1500系列PLC作为当前主流控制器,其Modbus TCP服务器功能为C#开发者提供了标准化的通信接口。本文将深入探讨如何从…...

一键解决Windows运行库问题:Visual C++ AIO完整安装指南
一键解决Windows运行库问题:Visual C AIO完整安装指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过这样的困扰:新下载…...

Sora之后的真相:2026年真正落地的8款工业级AI视频引擎,含API吞吐量、帧间PSNR均值与商用SLA承诺明细
更多请点击: https://intelliparadigm.com 第一章:Sora之后的真相:2026年真正落地的8款工业级AI视频引擎,含API吞吐量、帧间PSNR均值与商用SLA承诺明细 Sora发布两年后,工业界已摒弃“演示即产品”的幻觉。截至2026年…...

思源宋体完全指南:免费开源中文字体的终极解决方案
思源宋体完全指南:免费开源中文字体的终极解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中的中文字体授权费用而烦恼吗?或者在不同平台…...

5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器
5分钟学会在PowerPoint中插入LaTeX公式:科研工作者的高效神器 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 还在为PowerPoint里输入复杂的数学公式而头疼吗?作为科研人员、教师或…...

Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理
Avidemux:开源视频剪辑神器,5分钟学会专业级视频处理 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你知道吗?在开源视频编辑领域,有一款轻量级但功…...

终极MifareOneTool完整指南:Windows平台最简单的一键NFC卡片管理方案
终极MifareOneTool完整指南:Windows平台最简单的一键NFC卡片管理方案 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool 你是否曾…...

Keil MDK 项目迁移避坑指南:当你的旧工程遇到‘Default Compiler Version 5 is not available’
Keil MDK项目迁移实战:编译器版本冲突的工程级解决方案 当你从同事手中接过一个历史遗留的Keil MDK项目,或从版本控制系统拉取多年前的嵌入式工程时,最令人头疼的莫过于打开工程后迎面而来的编译器报错。其中"Default Compiler Version …...

如何用5分钟将B站视频变成文字稿:bili2text终极指南
如何用5分钟将B站视频变成文字稿:bili2text终极指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾经为了整理B站视频笔记而反复暂停、回…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...